Kafka应用过程中的高频问题
目录
1.如何防止消息丢失?
一、 针对发送方:
二、针对接收方:
2.如何防止消息的重复消费?
3.如何做到顺序消费?
4.如何解决消息积压的问题?
5.如何实现延迟队列?
6.Kafka如做到机上百万的高吞吐量呢?
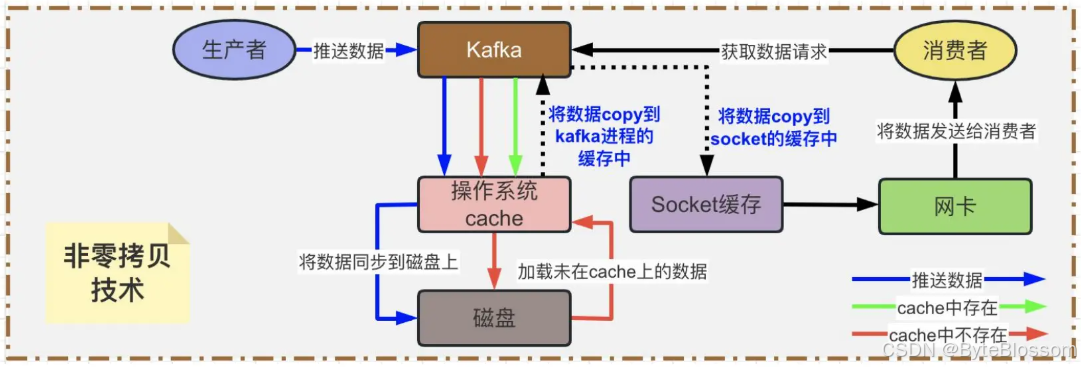
非零拷贝技术:
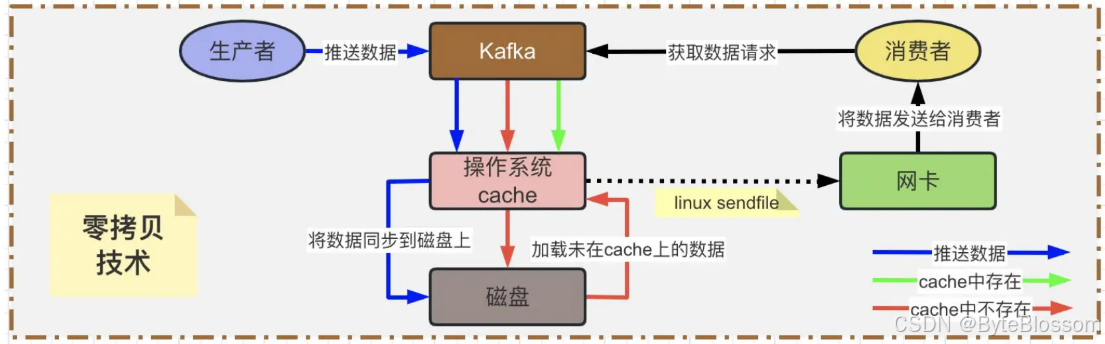
零拷贝技术:
1.如何防止消息丢失?
一、 针对发送方:
将ack设置为1或者-1/all可以防止消息丢失,如果要做到99.9999%,ack要设置为-1/all,并把min.insync.replicas配置成分区备份数。
| acks | 消息持久化机制 |
| -1/alll | 表示kafka ISR列表中所有的副本同步数据成功,才返回消息给客户端,这是最强的数据保证。min.insync.replicas 这个配置是用来设置同步副本个数的下限的, 并不是只有 min.insync.replicas 个副本同步成功就返回ack。而是,只要acks=all就意味着ISR列表里面的副本必须都要同步成功。 |
| 0 | 表示producer不需要等待任何broker确认收到消息的ACK回复,就可以继续发送下一条消息。性能最高,但是最容易丢失消息 |
| 1 | 表示至少等待leader已经成功将数据写入本地日志,但是不需要等待所有follower都写入成功,就可以继续发送下一条消息。 |
二、针对接收方:
把自动提交修改为手动提交(enable-auto-commit)。
2.如何防止消息的重复消费?
一条消息被消费者消费多次,如果为了不消费到重复的消息,我们需要在消费端增加幂等性处理,例如:① 通过mysql插入业务id作为主键,因为主键具有唯一性,所以一次只能插入一条业务数据。② 使用redis或zk的分布式锁,实现对业务数据的幂等操作。
3.如何做到顺序消费?
前提:在单个分区上来保持消息的有序性
一、针对发送方:在发送时将ack配置为非0,确保消息至少同步到leader之后再返回ack继续发送。但是,只能保证分区内部的消息是顺序的,而无法保证一个Topic下的多个分区总的消息是有序的。
二、针对接收方:消息发送到一个分区中,只配置一个消费组的消费者来接收消息,那 么这 个 Consumer所接收到的消息就是有顺序的了,不过这也就牺牲掉了性能。
4.如何解决消息积压的问题?
消息积压会导致很多问题,比如:磁盘被打满、Producer发送消息导致kafka性能过慢,然后就有可能发生服务雪崩。解决的方案如下所示:① 提升一个Consumer的处理能力。即:在一个消费者中启动多个线程,让多线程加快消费的速度。② 提升总体Consumer的处理能力。增加Consumer的数量从而提高消费能力。③ 如果业务运行,设定某个时间内,如果消息仍没有被消费,那么Consumer收到消息后,直接废弃掉,不执行下面的业务逻辑。
5.如何实现延迟队列?
应用场景:订单创建成功后如果超过30分钟没有付款,则需要取消订单。① 创建一个表示“订单30分钟未支付”的Topic,如:order_not_paid_30min,表示延迟30分钟的消息队列。② Producer发送消息的时候,消息内容要带上订单生成的时间create_time。③ Consumer消费Topic中的消息,如果发现now减去create_time不足30分钟,则不去消费;记录当前的offset,不去消费当前以及之后的消息。④ 通过记录的offset去获取消息,如果发现消息已经超过30分钟且订单状态是“未支付”,那么则将订单状态设置为“取消”,然后获取下一个offset的消息。
6.Kafka如做到机上百万的高吞吐量呢?
- 写入数据:主要是依靠页面缓存技术 + 磁盘顺序写实现的。
- 读取数据:主要依靠零拷贝技术实现的。
非零拷贝技术:
通过下图过程的描述,很明显可以看到存在两次没必要的copy,一次是从OS Cache里拷贝到Kafka进程的缓存里,接着又从Kafka进程的缓存里拷贝回OS的Socket缓存里。而且为了进行这两次拷贝,中间还发生了好几次上下文切换,一会儿是Kafka进程在执行,一会儿上下文切换到操作系统来执行,所以这种方式来读取数据是比较消耗性能的。
零拷贝技术:
Kafka为了解决非零拷贝这个问题,在读数据的时候是引入零拷贝技术。也就是说,通过OS的sendfile技术直接让OS Cache中的数据发送到网卡后传输给下游的消费者,中间跳过了两次拷贝数据的步骤。通过零拷贝技术,就不需要把OS Cache里的数据拷贝到应用缓存,再从应用缓存拷贝到 Socket 缓存了,两次拷贝都省略了,所以叫做零拷贝。