K8s服务日志收集方案文档
一、背景说明
1.1 项目背景
在Kubernetes环境中,日志收集和管理是一个重要且具有挑战性的任务。我们需要一个可靠、高效、易于扩展的日志收集方案,以满足以下需求:
- 统一的日志收集和存储
- 保证日志的完整性和顺序性
- 支持多服务独立管理
- 便于问题排查和系统监控
- 灵活的扩展性
1.2 技术选型
- 采集层:Filebeat(轻量级、资源占用少)
- 传输层:Kafka(高吞吐、可靠性好)
- 处理层:Logstash(功能强大、配置灵活)
- 存储层:文件系统(简单可靠、易于管理)
二、整体架构
2.1 架构图
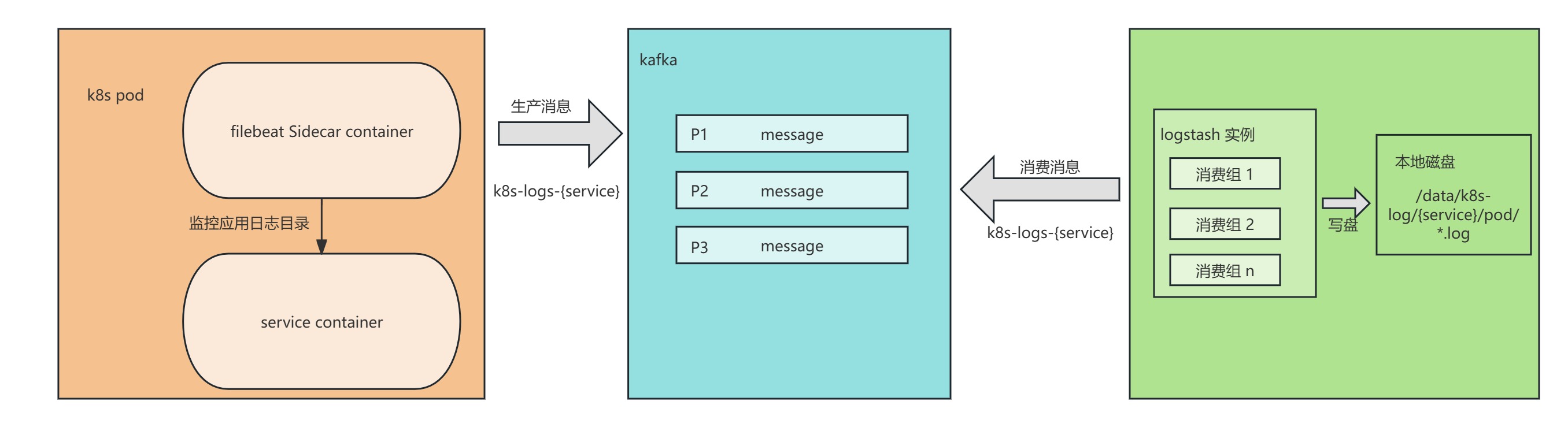
2.2 架构说明
- 采集层(Pod + Filebeat)
- 每个Pod配置 Filebeat Sidecar
- 实时监控应用日志目录
- 支持多行日志合并
- 数据压缩传输
- 传输层(Kafka)
- 每个服务独立Topic
- 多分区保证并行处理
- 数据持久化保证可靠性
- 支持水平扩展
- 处理层(Logstash)
- 多消费组并行处理
- 自定义数据处理逻辑
- 灵活的输出配置
- 支持动态配置更新
- 存储层(文件系统)
- 按服务分目录存储
- 按Pod隔离存储
- 支持日志轮转
- 自动清理过期日志
三、详细配置说明
3.1 Filebeat配置(Sidecar)
3.1.1 关键配置项说明
filebeat.inputs:- type: logenabled: truepaths:- /home/log/*/*/*.log # 匹配三层目录结构- /home/log/*/*.log # 匹配两层目录结构- /home/log/*.log # 匹配单层目录结构fields:service_name: "${SERVICE_NAME}"pod_name: "${POD_NAME}"node_name: "${NODE_NAME}"scan_frequency: 10signore_older: 48hclose_inactive: 50hclean_inactive: 72hmultiline:pattern: '^\d{4}-\d{2}-\d{2}'negate: truematch: after# 简化 processors,只保留必要的处理
processors:- drop_fields:fields: ["agent", "ecs", "input", "host", "@metadata"] # 删除不需要的字段- rename:fields:- from: "log.file.path"to: "filename"ignore_missing: true- script:lang: javascriptsource: |function process(event) {var path = event.Get("filename");if (path) {event.Put("filename", path.split("/").pop());}}output.kafka:hosts: ["192.168.150.248:9092"]topic: "k8s-logs-%{[fields.service_name]}" # 使用单个 topicpartition_key: "%{[fields.pod_name]}" # 确保同一个 pod 的消息进入同一分区,保证顺序性required_acks: -1compression: gzipmax_message_bytes: 10000003.1.2 优化建议
- 根据日志量调整 scan_frequency
- 合理设置 ignore_older 和 clean_inactive
- 优化 multiline 配置避免误匹配
- 启用压缩减少网络传输
3.2 Kafka配置
3.2.1 Topic设计
- 命名规范:k8s-logs-{service-name}
- 分区数:根据服务日志量设置(建议3-6个)
- 副本数:建议2个保证可用性
- 保留策略:根据存储容量设置
3.2.2 优化建议
# Topic创建示例
kafka-topics.sh --create \--bootstrap-server kafka:9092 \--topic k8s-logs-[new-service] \--partitions 3 \--replication-factor 2 \--config retention.hours=36 \--config segment.bytes=10737418243.3 Logstash配置
3.3.1 Pipeline配置
此配置根据业务需求,自定义即可,以下仅供参考
input {kafka {bootstrap_servers => "192.168.150.248:9092"topics => ["k8s-logs-zxqa-advanced-ai"]group_id => "zx-log-consumer"client_id => "zx-log-consumer"codec => jsonauto_offset_reset => "latest"consumer_threads => 4 # Kafka消费线程数fetch_max_bytes => "5242880" # 每次拉取最大字节数max_poll_records => "5000" # 每次拉取最大记录数decorate_events => false # 不添加Kafka元数据}
}filter {mutate {add_field => {"service_name" => "%{[fields][service_name]}""pod_name" => "%{[fields][pod_name]}""log_filename" => "%{[filename]}"}}ruby {code => 'time = Time.nowdate_str = time.strftime("%Y%m%d")pod_name = event.get("pod_name")if pod_nameevent.set("pod_dir", "#{date_str}-#{pod_name}")end'}
}output {file {path => "/data/k8s-log/%{service_name}/%{pod_dir}/%{log_filename}"codec => line { format => "%{message}" }flush_interval => 500 # 文件写入刷新间隔(ms)gzip => false # 是否压缩}
}3.3.2 性能优化
- 调整pipeline.workers和pipeline.batch.size
- 优化JVM配置
- 使用持久化队列
- 合理设置flush_interval
3.3.3 logstash 部署
链接:二进制方式安装部署 Logstash
四、新服务接入流程
4.1 准备工作
- 确认服务日志目录结构
- 评估日志量级
- 规划Kafka分区数
- 准备相关配置文件
4.2 具体步骤
4.2.1 创建Kafka Topic
# 1. 创建Topic
kafka-topics.sh --create \--bootstrap-server kafka:9092 \--topic k8s-logs-[new-service] \--partitions 3 \--replication-factor 2# 2. 验证Topic
kafka-topics.sh --describe \--bootstrap-server kafka:9092 \--topic k8s-logs-[new-service]4.2.2 创建 Filebeat ConfigMap
此处对于 k8s 集群服务,可以使用:kubectl -n jiujiu-assistant create cm assistant-master-filebeat-config --from-file=filebeat.yaml
filebeat.inputs:- type: logenabled: truepaths:- /home/log/*/*/*.log # 匹配三层目录结构- /home/log/*/*.log # 匹配两层目录结构- /home/log/*.log # 匹配单层目录结构fields:service_name: "${SERVICE_NAME}"pod_name: "${POD_NAME}"node_name: "${NODE_NAME}"scan_frequency: 10signore_older: 48hclose_inactive: 50hclean_inactive: 72hmultiline:pattern: '^\d{4}-\d{2}-\d{2}'negate: truematch: after# 简化 processors,只保留必要的处理
processors:- drop_fields:fields: ["agent", "ecs", "input", "host", "@metadata"] # 删除不需要的字段- rename:fields:- from: "log.file.path"to: "filename"ignore_missing: true- script:lang: javascriptsource: |function process(event) {var path = event.Get("filename");if (path) {event.Put("filename", path.split("/").pop());}}output.kafka:hosts: ["192.168.150.248:9092"]topic: "k8s-logs-%{[fields.service_name]}" # 使用单个 topicpartition_key: "%{[fields.pod_name]}" # 确保同一个 pod 的消息进入同一分区,保证顺序性required_acks: -1compression: gzipmax_message_bytes: 10000004.2.3 修改Deployment配置
此处重点描述 filebeat 日志采集相关配置,其他配置遵循业务具体需求
apiVersion: apps/v1
kind: Deployment
metadata:name: new-service
spec:template:spec:containers:- name: new-servicevolumeMounts:- name: app-logsmountPath: /home/service/log #注意根据业务情况选择挂载目录- name: filebeatimage: registry.cmri.cn/leban/filebeat:7.12.2args: ["-c", "/etc/filebeat/filebeat.yml", "-e"]env:- name: SERVICE_NAMEvalue: "new-service" #注意修改- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeNamevolumeMounts:- name: app-logsmountPath: /home/log- name: filebeat-configmountPath: /etc/filebeatvolumes:- name: app-logsemptyDir: {}- name: filebeat-configconfigMap:name: general-filebeat-cm #通用配置4.2.4 更新Logstash配置
- 修改input配置,添加新 Topic
vim /etc/logstash/conf.d/k8s-logs.conf
# 在 topics 列表中增加新的 topic- 重新加载Logstash配置
方法一:使用 systemd 重启服务(推荐)
systemctl restart logstash方法二:使用配置自动重载(需要在启动参数中添加 --config.reload.automatic)
# 在 systemd 服务配置中添加自动重载参数
vim /usr/lib/systemd/system/logstash.service# 确保 ExecStart 行包含以下参数
ExecStart=/opt/logstash/bin/logstash --path.settings /etc/logstash -f /etc/logstash/conf.d/k8s-logs.conf --config.reload.automatic --config.reload.interval=3s# 重新加载 systemd 配置并重启服务
systemctl daemon-reload
systemctl restart logstash- 验证配置是否生效
# 检查 Logstash 日志
tail -f /var/log/logstash/logstash-plain.log# 检查进程状态
systemctl status logstash# 验证新Topic是否正在被消费
curl -XGET 'localhost:9600/_node/stats/pipelines?pretty'注意事项:
- 配置自动重载可能会影响性能,建议在生产环境谨慎使用
- 重启服务会导致短暂的日志收集中断,建议在低峰期操作
- 建议在测试环境先验证配置变更
4.2.5 验证配置
- 检查Filebeat日志
- 验证Kafka消息
- 确认Logstash输出
- 检查日志文件生成
4.3 注意事项
- Topic创建要在服务部署前完成
- 配置更新要注意顺序性
- 建议先在测试环境验证
- 准备回滚方案
五、运维管理
5.1 监控指标
5.1.1 Filebeat监控
- CPU和内存使用率
- 日志采集延迟
- 错误率统计
- 输出队列状态
5.1.2 Kafka监控
- 消息积压情况
- 分区延迟统计
- 磁盘使用率
- 消费组状态
5.1.3 Logstash监控
- Pipeline延迟
- 处理速率
- 错误统计
- 资源使用率
5.2 日常维护
5.2.1 日志清理
# 自动清理脚本
#!/bin/bash
find /data/k8s-log/ -type d -name "202*-*" -mtime +30 -exec rm -rf {} \;5.2.2 性能优化
- 定期检查系统性能
- 优化配置参数
- 清理无用数据
- 升级组件版本
5.2.3 故障处理
- 日志采集异常
- 检查Filebeat状态
- 验证配置正确性
- 确认权限设置
- 消息队列异常
- 检查Kafka集群状态
- 验证Topic配置
- 确认网络连接
- 日志处理异常
- 检查Logstash状态
- 验证Pipeline配置
- 确认磁盘空间
5.3 最佳实践
- 定期备份配置
- 保持版本一致性
- 做好容量规划
- 建立监控告警
- 制定应急预案
六、常见问题
6.1 性能问题
- 日志延迟高
- 检查网络带宽
- 优化批处理参数
- 增加处理线程
- 资源占用高
- 调整JVM配置
- 优化采集频率
- 清理历史数据
6.2 可靠性问题
- 日志丢失
- 启用持久化队列
- 配置副本策略
- 增加重试机制
- 日志重复
- 检查消费组配置
- 优化提交策略
- 实现去重逻辑