【自然语言处理与大模型】如何进行大模型多模态微调
要想理解多模态大模型如何进行微调,首先肯定要知道多模态的基础架构。
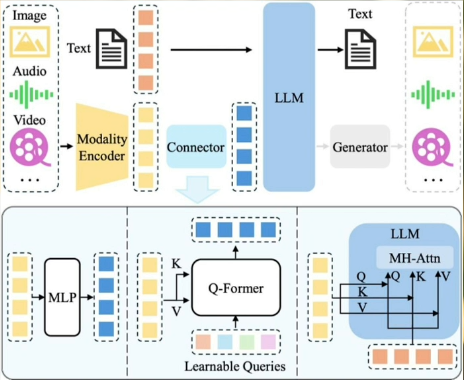
图中的Modality Encoder(模态编码层)是多模态语言模型中第一个关键组成部分。在视觉多模态模型中被叫做“视觉投影器”。他的作用是将视觉嵌入(Visual embeddings)等输入映射到文本空间(Text Embeddings),实现不同模态间的对齐。
图中 的Connector(模态融合层)是多模态语言模型的中第二个关键组成部分。它又被叫做“投影层”。借助投影层的作用是把高维向量转化为语言模型能够理解的token。将多模态特征向量与语言模型(LLM)的文本特征向量对齐融合,解决模态间“语义鸿沟”问题:
- 通过多模态对齐机制(如交叉注意力、特征映射),让不同模态信息在语义层面统一;
- 输出融合后的特征向量,传递给语言模型。
一、如何进行大模型多模态微调?
投影层是整个多模态大模型的关键组件,虽然参数量很少,但对模型的性能影响很大。同时投影层也是绝大多数大模型多模态微调的切入点。
多模态大模型微调的核心方法在于重新训练投影层。投影层充当着视觉世界与语言世界之间的"翻译桥梁",其质量直接影响图像特征能否被语言模型准确理解。预训练阶段的投影层通常面向通用场景设计,但在医疗影像诊断、图表解析或工业检测等具体任务中,这种通用设计往往难以实现精准的信息对齐。因此,常见的多模态微调策略是冻结视觉编码器和语言模型,仅对投影层进行全量微调,使其能够针对特定领域实现更精确的特征转换。
除了重新训练投影层,我们还可以借助LoRA或QLoRA微调多模态模型的语言模型参数,以获得更优效果。这是因为投影层仅负责"将图像转换为文字",而不会改变语言模型的表达方式。如果下游任务需要生成专业领域内容,如医学报告、金融分析或学术风格的图文解读,仅优化投影层是不够的,还需要让语言模型"重新学习表达方式"。这时,我们会在语言模型的关键层插入LoRA模块,仅更新少量参数,使模型既能保留通用能力,又能更好地适应特定领域的语言需求。
二、多模态微调的数据集该怎么构建?
多模态微调数据准备的关键在于实现图文精准对齐。常见的数据形式采用"图片+对应文字描述"的配对格式,例如一张图表需要搭配其详细的文字说明。值得注意的是,在多模态微调中,数据质量的重要性远胜于数量——高质量的小规模数据集通常比低质量的大规模数据更具效果。
三、多模态微调的典型应用场景有哪些?
常见场景包括:
视觉问答,(VQA) 这是计算机视觉和自然语言处理的交叉应用,系统能够根据输入的图像和自然语言问题,生成相应的答案。例如,用户上传一张街景照片并提问"图中最显眼的建筑是什么颜色?",系统会识别图像中的主要建筑并回答其颜色。VQA在智能客服、教育辅助等领域有广泛应用。
图像文字理解,包括场景文字识别(Scene Text Recognition)和文档图像分析。典型应用如:自动识别路牌信息、提取商品包装上的文字、扫描文件转换为可编辑文本等。其中OCR(光学字符识别)技术是核心,现代系统还能理解文字的语义和上下文关系。
图表到文档解析,将各类图表(柱状图、折线图、饼图等)自动转换为结构化描述或分析报告。例如,财务系统可以自动读取季度报表中的图表,生成业绩分析摘要;教育系统可帮助学生理解复杂的数据可视化内容。
跨模态检索,实现图像和文本之间的相互检索。比如以图搜文:上传一张风景照,找到描写类似场景的文学作品。或者以文搜图:输入"夕阳下的海滩",返回相关图片 电商平台常用此技术提升商品搜索体验。
医学影像诊断报告生成,结合医学影像(X光、CT、MRI等)和临床数据,自动生成初步诊断报告。系统能识别病灶特征(如肿瘤大小、位置),并用专业医学术语描述。这能辅助医生提高工作效率,在偏远地区医疗资源不足时尤其有价值。需注意的是,这类系统通常作为辅助工具,最终诊断仍需专业医师确认。