机器学习 - Kaggle项目实践(6)Dogs vs. Cats Redux: Kernels Edition 猫狗二分类
Dogs vs. Cats Redux: Kernels Edition | Kaggle
任务:给定猫狗图像数据集 进行二分类。
Cats or Dogs - using CNN with Transfer Learning | Kaggle(参考)
Cats or Dogs | Kaggle (我的kaggle)
本文介绍了使用ResNet50预训练模型进行猫狗图像分类的完整流程。
数据预处理、模型构建、训练评估和预测输出,展示了迁移学习在图像分类任务中的高效应用。
首先从Kaggle数据集解压图片并处理数据,将文件名转换为独热标签(猫[0,1],狗[1,0])。
然后构建ResNet50模型,移除原始分类层并改为二分类softmax输出,使用ImageNet预训练权重初始化。
模型在训练集上训练20个epoch后,在验证集上准确率达到98%以上。
1. zip 图片提取与 文件名标签提取
从zip文件提取出 train 地址列表和 test 地址列表
import zipfile
import oswith zipfile.ZipFile('/kaggle/input/dogs-vs-cats-redux-kernels-edition/train.zip', 'r') as z:z.extractall('.') # 将ZIP文件中的所有内容解压到当前目录train_image_list = z.namelist() # 获取名称列表train_image_list = os.listdir("./train/") # 进一步解压with zipfile.ZipFile('/kaggle/input/dogs-vs-cats-redux-kernels-edition/test.zip', 'r') as z:z.extractall('.')test_image_list = z.namelist()test_image_list = os.listdir("./test/")print(train_image_list[0],test_image_list[0]) # 文件名 train格式 类别+数字 test只有数字把train文件夹地址和图像文件名列表,拼凑出完整的地址;
cv2读取出图片;文件名提取出标签 二分类概率 猫为[0,1] 狗为[1,0]
from random import shuffle
from tqdm import tqdm
import cv2
import numpy as np
import pandas as pdRANDOM_STATE = 2018
IMG_SIZE = 224
def process_data(data_image_list, DATA_FOLDER, isTrain):data_df = []for img in tqdm(data_image_list):if(isTrain):label = [1,0] if img.split('.')[0] == 'cat' else [0,1] # 根据文件名 转换独热标签else:label = img.split('.')[0]path = os.path.join(DATA_FOLDER,img) # 拼接为完整路径img = cv2.imread(path,cv2.IMREAD_COLOR) # 读取img = cv2.resize(img, (IMG_SIZE,IMG_SIZE)) # 设定大小data_df.append([np.array(img),np.array(label)]) # 拼在一起返回shuffle(data_df) # 打乱return data_dftrain = process_data(train_image_list, './train/', True)
test = process_data(test_image_list, './test/', False)
2. EDA 图片探索 训练集图片展示
展示 5*5 张训练集图片和测试集图片
def show_images(data, isTest=False):f, ax = plt.subplots(5,5, figsize=(15,15))for i,data in enumerate(data[:25]):img_data,img_num = data[0],data[1]label = np.argmax(img_num) # 独热向量 [0,1] 为狗 转换为文字标签if label == 1: str_label='Dog'elif label == 0: str_label='Cat'if(isTest):str_label="None"ax[i//5, i%5].imshow(img_data)ax[i//5, i%5].axis('off')ax[i//5, i%5].set_title("Label: {}".format(str_label))plt.show()show_images(train)
show_images(test,True)
3. 建立模型 ResNet
残差神经网络ResNet预训练参数 迁移学习
移除原始ResNet50最后的1000类分类层,改为softmax 激活函数二分类
使用在ImageNet上预训练的权重(好的初始化快速收敛)允许训练微调
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Densemodel = Sequential()
model.add(ResNet50(include_top=False, # 移除原始ResNet50最后的1000类分类层pooling='max', # 在卷积特征上添加全局最大池化,将特征图转换为向量weights='imagenet' # 使用在ImageNet上预训练的权重
))
model.add(Dense(2, activation='softmax')) # softmax 激活函数二分类model.layers[0].trainable = True # 允许训练微调
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()4. 准备数据并训练
X = np.array([data[0] for data in train]).reshape(-1,IMG_SIZE,IMG_SIZE,3)
y = np.array([data[1] for data in train])
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.25, random_state=RANDOM_STATE)
train_model = model.fit(X_train, y_train, batch_size=64, epochs=20, verbose=1, validation_data=(X_val, y_val))verbose=1 训练进度展示
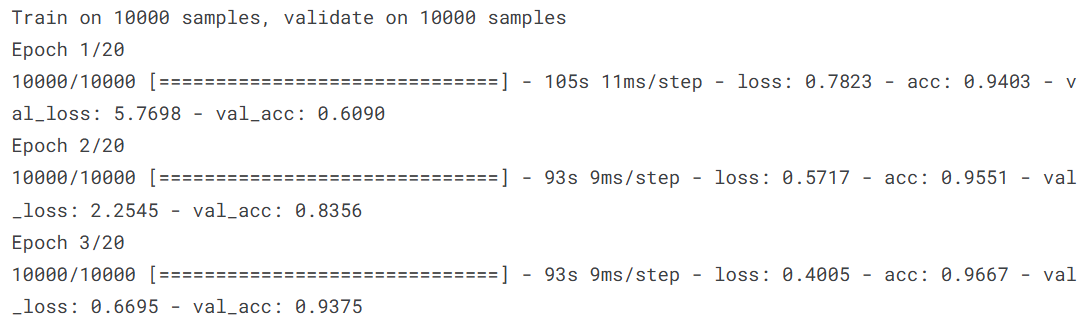
5. 预测+评估
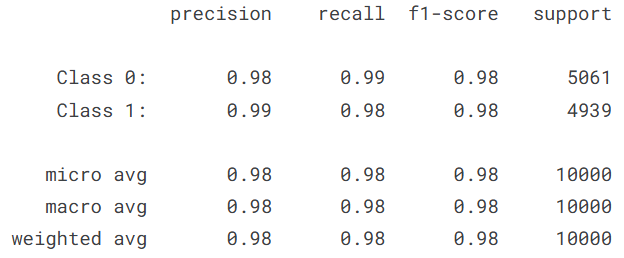
模型评估:model.evaluate 评估分数; 验证集真实和预测 分类报告
score = model.evaluate(X_val, y_val, verbose=0) # 评估分数
print('Validation loss:', score[0])
print('Validation accuracy:', score[1])predicted_classes = model.predict_classes(X_val) # 预测
y_true = np.argmax(y_val,axis=1) # 实际from sklearn.metrics import classification_report # 分类报告
print(classification_report(y_true, predicted_classes, target_names=["Cat", "Dog"]))
这三个指标均达到 98%以上
还可以 可视化部分验证集结果(人眼看是否差不多分类正确)
f, ax = plt.subplots(5, 5, figsize=(15, 15))for i, (img_data, _) in enumerate(test[:25]):prediction = model.predict(img_data.reshape(-1, IMG_SIZE, IMG_SIZE, 3))[0]label = 'Dog' if np.argmax(prediction) == 1 else 'Cat'ax[i//5, i%5].imshow(img_data)ax[i//5, i%5].axis('off')ax[i//5, i%5].set_title(f"Predicted: {label}")plt.show()
预测并保存结果
pred_list = []
img_list = []
for img in tqdm(test):data = img[0].reshape(-1,IMG_SIZE,IMG_SIZE,3)pred_list.append(model.predict([data])[0][1])img_list.append(img_idx[1])submission = pd.DataFrame({'id':img_list , 'label':pred_list})
submission.to_csv("submission.csv", index=False)