(论文速读)RADIOv2.5:聚合式视觉基础模型
论文题目:RADIOv2.5: Improved Baselines for Agglomerative Vision Foundation Models(RADIOv2.5:改进的凝聚视觉基础模型基线)
会议:CVPR2025
摘要:聚集模型最近作为一种训练视觉基础模型的强大方法出现,利用来自现有模型(如CLIP、DINO和SAM)的多教师蒸馏。这一策略能够有效地创建鲁棒的模型,结合个别教师的优势,同时显著减少计算和资源需求。在本文中,我们深入分析了最先进的聚集模型,确定了关键的挑战,包括解决模式转变、教师失衡、特殊的教师工件和过多的输出令牌。为了解决这些问题,我们提出了几种新的解决方案:多分辨率训练、马赛克增强和改进的教师损失函数平衡。具体来说,在视觉语言模型的上下文中,我们引入了一种令牌压缩技术,以在固定的令牌计数内保持高分辨率信息。我们在多个尺度(-B, -L, -H和-g)上发布了性能最好的变体,以及推理代码和预训练的权重。
引言
在人工智能快速发展的今天,如何有效整合多个专业化的视觉模型来创建一个统一、强大的视觉基础模型,一直是计算机视觉领域的重要挑战。
背景:什么是聚合式视觉基础模型?
聚合式视觉基础模型是一种通过多教师蒸馏技术,将多个专业化模型(如CLIP、DINO、SAM)的知识整合到单一学生模型中的方法。这种方法的优势在于:
- 综合能力:结合不同模型的优势
- 计算效率:只需运行一个模型而非多个
- 资源节约:减少部署和维护成本
然而,现有方法如AM-RADIO存在一些关键问题,RADIOv2.5正是为了解决这些问题而生。
核心挑战:现有方法的四大问题
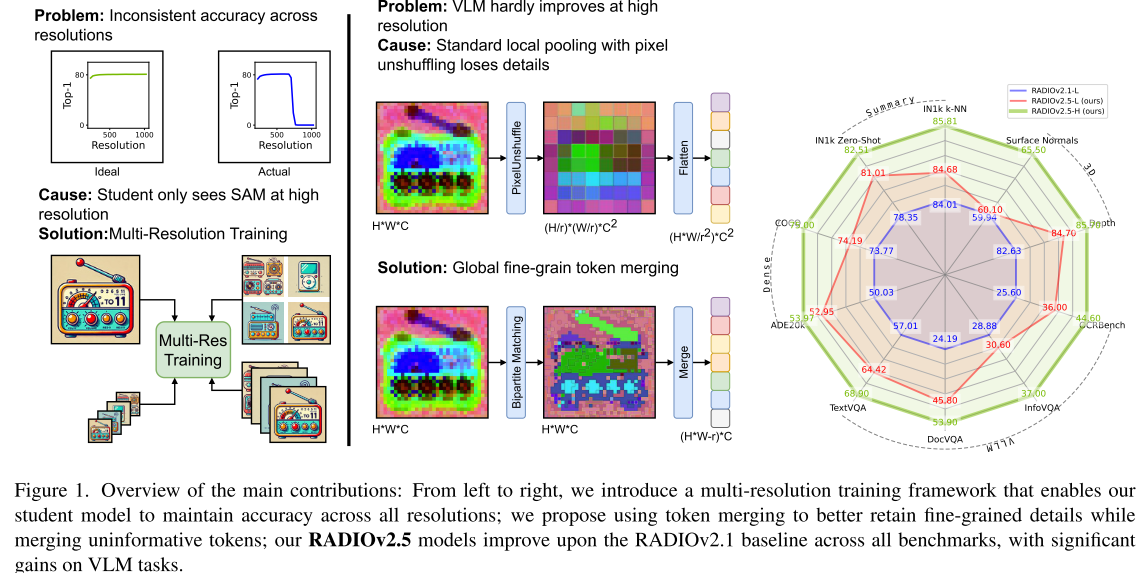
1. 分辨率模式转换问题

问题描述:现有的AM-RADIO模型在不同输入分辨率下表现出"人格分裂"现象:
- 低分辨率(≤512px):表现像DINOv2,关注语义和深度信息
- 高分辨率(>512px):表现像SAM,专注于轮廓和分割
根本原因:训练时学生模型只在特定分辨率下看到特定教师的特征,导致分辨率依赖性。
2. 教师模型不平衡
不同教师模型的激活幅度差异巨大,SAM的激活往往会压制CLIP和DINOv2的贡献,导致训练不平衡。
3. 教师特异性伪影
每个教师模型都会引入自己的偏见和伪影,如位置编码伪影等。
4. Token数量爆炸
高分辨率处理会产生大量视觉token,在视觉-语言模型中造成:
- 二次计算复杂度增长
- 内存占用激增
- 推理速度下降
创新解决方案:RADIOv2.5的四大法宝
1. 多分辨率训练策略
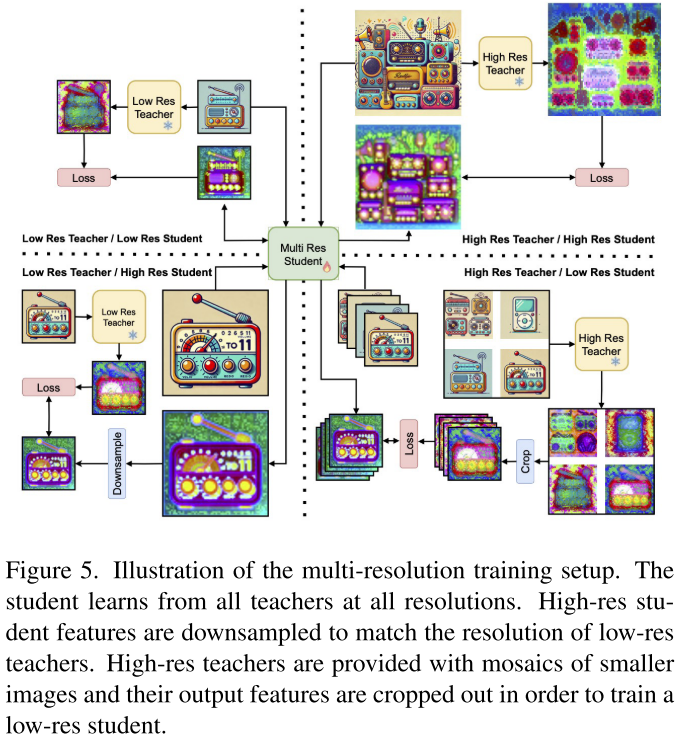
核心思想:让学生模型在多个分辨率下同时学习所有教师的知识。高分辨率的学生特征被下采样以匹配低分辨率教师的分辨率。为高分辨率教师提供较小图像的马赛克,并裁剪出其输出特征,以训练低分辨率学生。
技术实现:
- 第一阶段:低分辨率(256²)训练300k次迭代
- 第二阶段:中分辨率(432²)训练300k次迭代
- 第三阶段:同时在432²和1024²分辨率训练300k次迭代
效果:消除模式转换现象,实现跨分辨率的一致性能。
2. 马赛克数据增强
问题:为了在低分辨率下训练SAM,传统方法需要将小图像填充到1024²,计算成本高昂。
解决方案:创建k×k小图像的马赛克,然后在1024²分辨率下运行SAM,提取k²个独立特征图。
优势:
- 大幅降低计算成本
- 增加图像位置多样性
- 减少位置编码伪影
马赛克增强大大降低了与向高分辨率教师学习相关的培训成本,并消除了对特征插值的需要。通过这种优化,学生的质量甚至得到了提高。
3. PHI-S教师损失平衡
技术原理:使用PCA-Hadamard各向同性标准化来平衡不同教师的激活分布。
数学表示:
X'ᵢ = φᵢ⁻¹RᵢXᵢ
Rᵢ = HcUᵢᵀ
φᵢ = √(1/C ∑λⱼ)
效果:确保每个教师的贡献得到平等对待,避免某个教师主导训练过程。
4. ToMe Token压缩
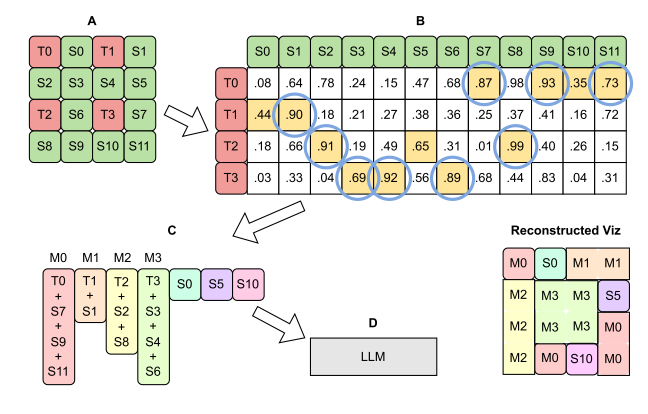
核心技术:基于二分图软匹配的token合并策略。
工作原理:
- 使用条纹分区确保每个图像区域都有代表
- 计算token之间的亲和度
- 合并相似的token,保留最多样化的信息
创新点:
- 直接使用特征而非注意力键进行匹配
- 在视觉编码器输出处应用,而非增量式应用
- 对RADIOv2.5的效果比SigLIP更显著
实验结果:全面超越基线
消融实验结果
| 配置 | 目标 | ImageNet零样本 | ADE20k | VLM平均分 |
|---|---|---|---|---|
| A: RADIOv2.1-L | 基线 | 78.35 | 50.03 | 30.14 |
| B: A + 多分辨率 | 消除模式转换 | 81.21 | 52.84 | 32.71 |
| C: B + SigLIP | 改进VLM | 81.01 | 52.95 | 39.22 |
| D: C + ViT-H | 更大骨干网络 | 82.51 | 53.97 | 42.49 |
| E: D + Token合并 | 改进VLM | - | - | 48.39 |
与其他聚合式模型比较
RADIOv2.5在所有尺寸上都显著超越了现有的聚合式模型:
- SAM-CLIP:在语义分割上提升10+ mIoU
- Theia:在多个3D理解任务上领先
- UNIC:在视觉-语言任务上大幅改进
VLM性能对比
| 视觉编码器 | 分辨率 | TextVQA | ChartQA | DocVQA | 平均分 |
|---|---|---|---|---|---|
| OpenAI-CLIP | 336² | 63.2 | 49.2 | 43.4 | 58.55 |
| SigLIP-SO400M | 384² | 64.8 | 55.7 | 47.9 | 60.95 |
| RADIOv2.5-H | 768² | 68.8 | 61.6 | 54.2 | 63.19 |
技术深度解析
尺度等变性分析
论文通过量化尺度等变性来评估模型的跨分辨率稳定性:
| 模型 | 细粒度等变性 | 粗粒度等变性 |
|---|---|---|
| DINOv2-g-reg | 0.126 | 0.178 |
| AM-RADIO-L | 0.357 | 0.476 |
| RADIOv2.5-H | 0.119 | 0.193 |
数值越小表示跨尺度一致性越好,RADIOv2.5接近DINOv2的表现。
Token压缩效果分析
在相同的256 token预算下:
| 方法 | TextVQA | DocVQA | InfoVQA |
|---|---|---|---|
| 2×2像素反混洗 | 65.0 | 45.7 | 32.9 |
| ToMe (r=768) | 65.7 | 49.7 | 34.9 |
Token合并在所有基准上都优于传统的像素反混洗方法。
实际应用价值
1. 统一的视觉处理管道
RADIOv2.5可以作为统一的视觉特征提取器,支持:
- 图像分类
- 语义分割
- 实例分割
- 深度估计
- 表面法向量预测
- 视觉问答
2. 高效的VLM集成
通过Token压缩技术,RADIOv2.5能够:
- 在固定计算预算下处理更高分辨率图像
- 减少VLM的推理延迟
- 保持高质量的视觉理解能力
3. 灵活的分辨率支持
模型支持从256²到1024²的任意分辨率输入,无需重训练或微调。
局限性与未来展望
当前局限
- 计算资源需求:大模型变种仍需要substantial计算资源
- 教师模型依赖:性能上限受限于教师模型质量
- 训练复杂度:多阶段训练策略增加了训练复杂度
未来方向
- 更多教师模型:整合更多专业化模型的知识
- 自适应压缩:根据图像内容动态调整token压缩率
- 端到端优化:与下游任务联合优化
- 效率优化:进一步减少计算和内存需求
结论
RADIOv2.5代表了聚合式视觉基础模型的重要进展。通过系统性地解决分辨率不一致、教师不平衡、token爆炸等关键问题,该研究为构建真正通用的视觉基础模型指明了方向。
这项工作的意义不仅在于技术创新,更在于展示了如何通过工程化的方法系统性地解决复杂的多模型整合问题。随着更多专业化视觉模型的出现,这种聚合式方法将变得越来越重要。
对于研究者和工程师来说,RADIOv2.5提供了一个强大的起点,可以进一步探索多模态理解、机器人视觉、自动驾驶等应用场景。同时,其开源的代码和预训练权重也为社区贡献了宝贵的资源。