论文阅读:GOAT: GO to Any Thing
地址:GOAT: GO to Any Thing
摘要
在家庭、仓库等部署场景中,移动机器人需能长时间自主导航,并无缝执行人类操作员可直观理解的指令所描述的任务。本文提出 “通用目标导航系统”(GO To Any Thing, GOAT),该系统可满足上述需求,具备三大核心特征:
- 多模态(Multimodal):可处理通过类别标签、目标图像及语言描述指定的导航目标;
- 终身式(Lifelong):能利用在同一环境中的过往经验提升性能;
- 平台无关(Platform Agnostic):可快速部署于不同物理结构的机器人上。
GOAT 的实现依赖于模块化系统设计与持续扩充的实例感知语义记忆—— 该记忆除跟踪类别级语义外,还能记录物体从不同视角呈现的外观,从而区分同一类别的不同实例,实现基于图像和语言描述的目标导航。
在实验中,GOAT 在 9 个不同家庭环境中累计运行超 90 小时,完成了涵盖 200 + 不同物体实例的 675 个导航目标任务。结果显示,GOAT 的整体成功率达 83%,较现有方法及对照实验(Ablation)绝对提升 32%;且其性能随环境经验积累逐步提升,从首个目标的 60% 成功率提升至充分探索后的 90% 成功率。此外,本文还验证了 GOAT 可直接应用于拾取 - 放置、社交导航等下游任务。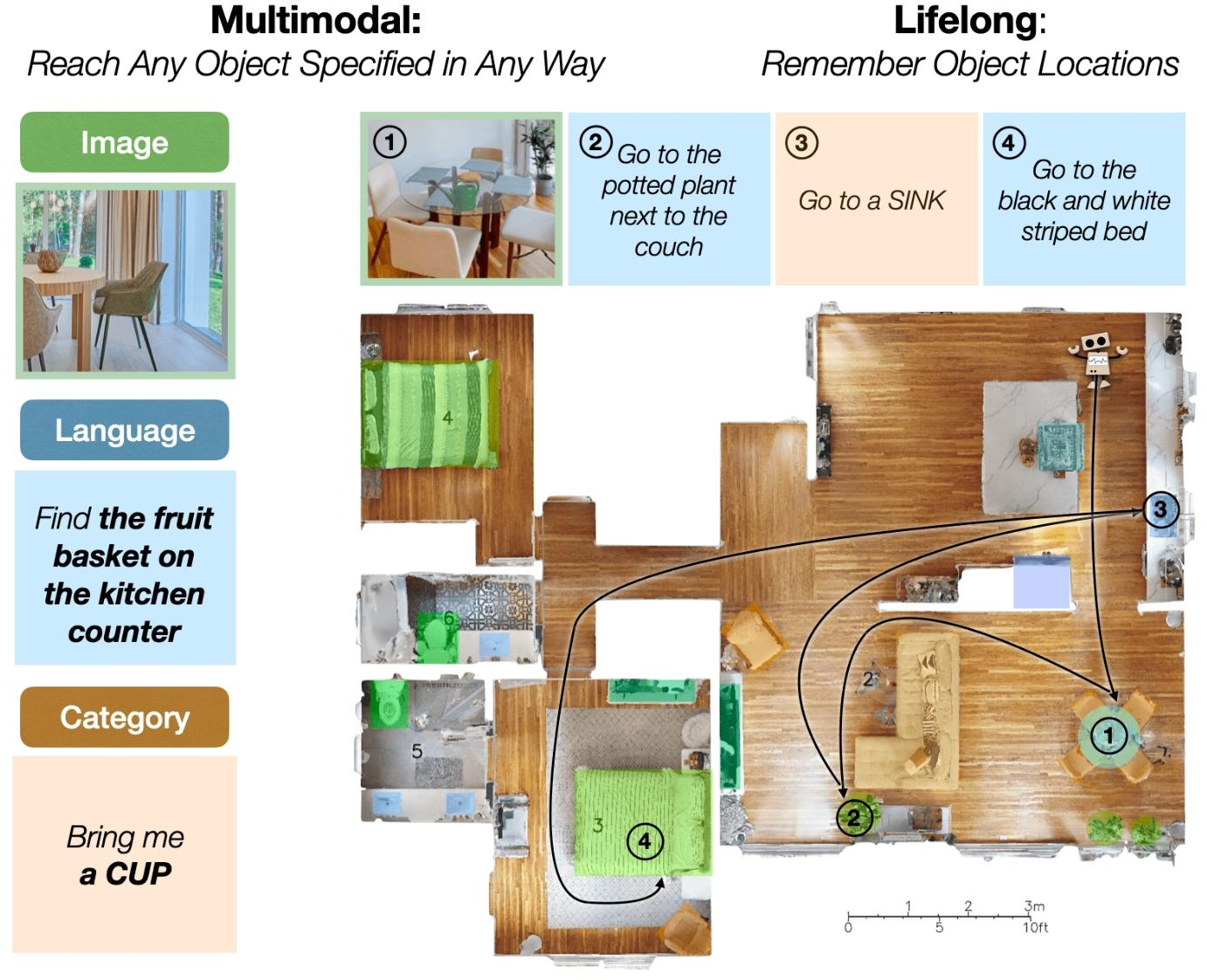
一、概述
1. 研究背景与动机
GOAT 的设计灵感源于动物与人类导航的核心发现,旨在解决现有导航方法的三大局限(单模态、非终身式、依赖特定平台 / 仿真环境):
- 认知地图(Cognitive Maps):动物通过海马体构建环境的内部空间表征,证明纯反应式、无记忆的导航系统存在不足;
- 路径知识构建认知地图:人类通过 “路径级知识”(如起点、终点、途经点)逐步整合为全局地图,启发机器人需通过 “终身学习” 持续优化内部空间表征;
- 视觉地标依赖:动物与人类导航依赖地标视觉外观,而非仅依赖几何位置,因此机器人需维护多模态环境表征。
现有导航方法多存在 “单模态(如仅支持类别目标)”“单目标任务(无法利用过往经验)”“仅在仿真中验证” 等问题,GOAT 则在这三方面均实现突破,在真实环境中支持多模态目标的终身式导航。
2. 核心设计与关键技术
(1)系统核心特征
| 特征 | 具体能力 |
|---|---|
| 多模态 | 支持 “类别目标”(如 “找一个水槽”)、“图像目标”(如 “找与这张图片一致的盆栽”)、“语言目标”(如 “找沙发旁的盆栽”) |
| 终身式 | 通过 “实例感知语义记忆” 存储过往观察到的物体实例,避免重复探索,提升后续目标导航效率 |
| 平台无关 | 仅依赖机器人的 RGB-D 相机、位姿传感器(SLAM)及基础运动指令(前进、左转、右转),无需为新平台重新训练 |
(2)关键技术选型
| 技术模块 | 所用模型 / 方法 | 功能用途 |
|---|---|---|
| 目标检测与实例分割 | Mask R-CNN(ResNet50 backbone,预训练于 MS-COCO) | 实现物体实例的检测与分割,性能优于 Detic 等开放词汇模型(鲁棒性更高) |
| 单目深度估计 | MiDaS | 填充深度图像中的孔洞(如反光物体导致的深度缺失),生成稠密深度图 |
| 图文匹配 | CLIP(Contrastive Language-Image Pretraining) | 计算语言描述与物体视图的 CLIP 特征余弦相似度,实现语言目标匹配 |
| 图像 - 图像匹配 | SuperGlue | 基于关键点匹配,实现目标图像与物体视图的精准匹配(优于 CLIP 特征匹配) |
| 探索策略 | 前沿探索(Frontier-based Exploration) | 当目标未在记忆中定位时,选择最近的未探索区域作为临时目标 |
| 路径规划 | 快速行进法(Fast Marching Method) | 基于语义地图规划从当前位置到目标的路径 |
(3)实验设计与结果
-
实验环境:9 个真实家庭环境(无预计算地图或物体位置),部署于波士顿动力 Spot(定量实验)和 Hello Robot Stretch(定性实验);
-
实验任务:每个家庭 10 个实验序列,每个序列含 5-10 个目标(类别、图像、语言目标各占 1/3),共 200 + 物体实例、675 个目标;
-
基线方法:
- CLIP on Wheels:通过 CLIP 特征匹配所有过往图像,无实例区分能力;
- GOAT w/o Instances:不区分同一类别的不同实例,仅导航至最近类别物体;
- GOAT w/o Memory:每个目标后重置语义地图与实例记忆,无终身学习能力;
-
核心结果:
指标 GOAT CLIP on Wheels GOAT w/o Instances GOAT w/o Memory 平均成功率(SR) 83.0%±0.7 50.7%±1.0 49.4%±0.8 60.3%±0.8 平均路径效率(SPL) 0.642±0.007 0.418±0.008 0.398±0.007 0.188±0.012 类别目标成功率 94.3%±0.8 65.3%±1.5 94.1%±0.8 76.4%±1.3 图像目标成功率 86.4%±1.1 46.1%±1.8 28.6%±1.7 59.4%±1.5 语言目标成功率 68.2%±1.5 40.8%±1.9 27.6%±1.6 45.3%±1.6 -
关键趋势:GOAT 性能随目标数量增加逐步提升,从首个目标的 60% 成功率(0.2 SPL)提升至 5-10 个目标的 90% 成功率(0.8 SPL),而 “无记忆版 GOAT” 无性能提升,CLIP on Wheels 则早于平台期且性能更低。
(4)下游应用验证
- 开放词汇移动操作(Pick and Place):结合波士顿动力机器人的内置拾取功能,完成 “从咖啡桌拿起马克杯并放到水槽” 等任务,物体与容器的定位成功率分别达 79% 和 87%;
- 社交导航(Social Navigation):将人类视为 “PERSON 类别” 的动态实例,可避开移动人类(成功率 81%)并跟踪人类(成功率 83%,接近静态图像目标的 86%)。
(5)局限性与未来方向
- 开放词汇检测性能不足:Detic 等开放词汇模型的鲁棒性不如 2017 年的 Mask R-CNN,原因可能是 “为通用性牺牲鲁棒性” 及 “训练数据缺乏机器人真实环境交互数据”;
- 语言目标匹配精度较低:语言目标成功率(68%)低于图像目标(86%),因 CLIP 特征难以捕捉细粒度实例属性(如 “带绿色枕头的床”),而 SuperGlue 可通过几何特征精准匹配。
二、研究动机
论文的研究动机源于真实场景中移动机器人导航的核心需求与现有导航方法的关键局限,同时受动物与人类导航认知机制的启发,具体可分为三方面:
1. 真实场景对导航系统的实用需求
在家庭、仓库等部署场景中,移动机器人需满足两大核心需求:
- 长时间自主与直观交互:需自主导航 extended periods(长时间),且能执行人类以 “直观方式”(如 “找沙发旁的盆栽” 这类语言、“找与照片一致的杯子” 这类图像)指定的任务,而非仅接受机器可理解的 “类别标签” 或 “坐标”;
- 环境经验复用:在同一环境中多次执行任务时,需复用过往探索经验(如记住已发现的水槽位置),避免重复探索,提升效率。
现有方法难以同时满足这些需求,需设计支持 “多模态目标、终身经验复用” 的导航系统。
2. 现有导航方法的三大关键局限
现有导航研究存在显著短板,无法支撑真实场景落地:
- 单模态局限:多数方法仅支持单一类型目标(如仅类别目标 “找水槽”、仅图像目标 “找与图片一致的物体”),无法统一处理 “类别 - 图像 - 语言” 多模态输入,不符合人类交互习惯;
- 非终身式局限:多数方法将每个导航任务视为独立 episode,完成后重置环境记忆,导致在同一环境中重复探索(如首次找床后,再次找沙发仍需重新遍历),效率极低;
- 仿真与平台依赖局限:① 多数方法仅在仿真环境(如 Habitat)中验证,未在真实家庭的复杂场景(光照变化、物体遮挡、动态人类)中测试,实际部署性能大幅下降;② 端到端方法需针对特定机器人硬件(轮式 / 四足式)重新训练,无法快速适配不同平台。
3. 动物与人类导航认知机制的启发
导航是动物与人类的基础能力,其核心认知发现为机器人导航提供了关键思路:
- 认知地图(Cognitive Maps):诺贝尔 Prize 相关研究发现,动物通过海马体构建环境的内部空间表征(非纯几何或拓扑),证明 “无记忆、纯反应式” 导航系统(如仅依赖实时传感器避障)不足以为复杂环境导航;
- 路径知识构建全局地图:人类通过 “route-based 知识”(如日常活动中的起点、终点、途经点),逐步将多段经验整合为全局环境地图,这启发机器人需通过 “终身学习” 持续优化内部空间表征;
- 视觉地标依赖:动物与人类导航不仅依赖位置的几何配置,更依赖地标的视觉外观(如 “以红房子为参照”),因此机器人需维护 “视觉 - 语义 - 空间” 多模态环境表征,而非仅存储几何信息。
三、方法架构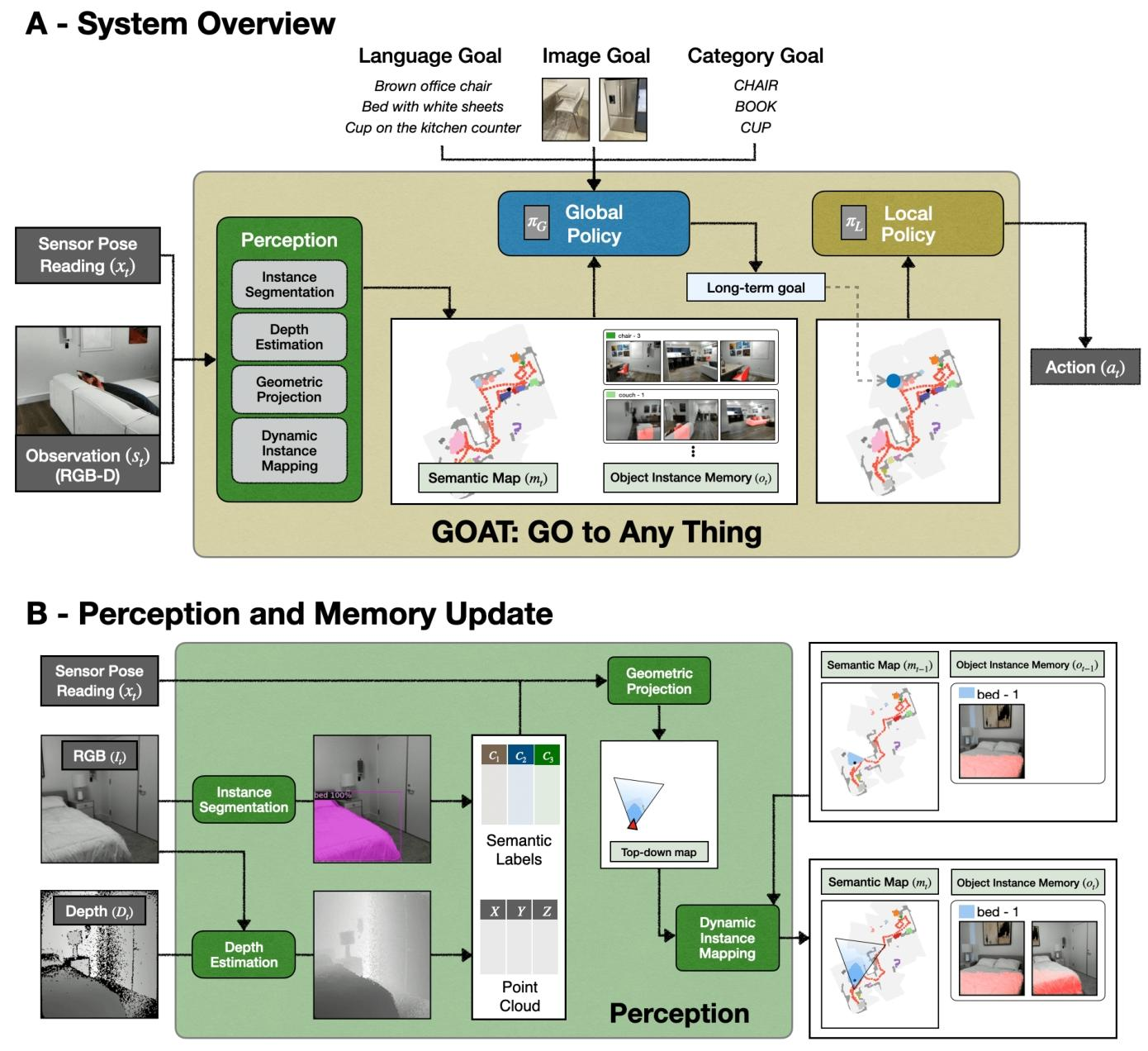
1. 感知模块(Perception)
(1)核心功能
处理机器人传感器输入(RGB 图像It、深度图像Dt、位姿xt),输出实例分割结果与稠密深度图,为语义地图构建与实例记忆更新提供数据。
(2)关键步骤与原理
- 实例分割:使用 Mask R-CNN 检测 RGB 图像中的物体实例,输出每个实例的边界框、语义类别标签;
- 深度图像填充(解决孔洞问题):
- 第一步:用 MiDaS 模型从 RGB 图像It生成单目深度估计Xt,i(仅含相对深度);
- 第二步:通过最小二乘优化求解缩放因子A和偏移b,将相对深度映射为绝对深度,公式如下:
其中,Dt,i为深度传感器输出的第i个像素的真实深度值,Xt,i为 MiDaS 估计的对应像素深度值; - 第三步:用优化后的绝对深度填充Dt中的孔洞,生成稠密深度图;
- 语义地图投影:将 RGB 图像的实例分割结果与稠密深度图结合,投影为 3D 语义体素图,再沿高度方向求和,得到 2D 实例地图mt。
2. 语义地图表示(Semantic Map)
(1)地图结构
语义地图为K×M×M的整数矩阵,各维度含义如下:
- M×M:地图空间尺寸,每个单元格对应物理世界的25
(5cm×5cm);
- K=C+4:地图通道数,其中C为物体类别数,4 个额外通道分别记录 “障碍物”“已探索区域”“机器人当前位置”“机器人过往位置”;
- 矩阵值含义:非零值表示对应单元格存在 “特定类别物体实例”“障碍物” 或 “已探索区域”,零值表示未探索区域。
(2)初始化与更新
- 初始化:实验开始时地图全为零,机器人从地图中心朝东方向启动;
- 更新:随机器人移动,感知模块持续将新检测到的实例投影到地图中,更新实例位置、障碍物及已探索区域标记。
3. 实例感知语义记忆(Object Instance Memory)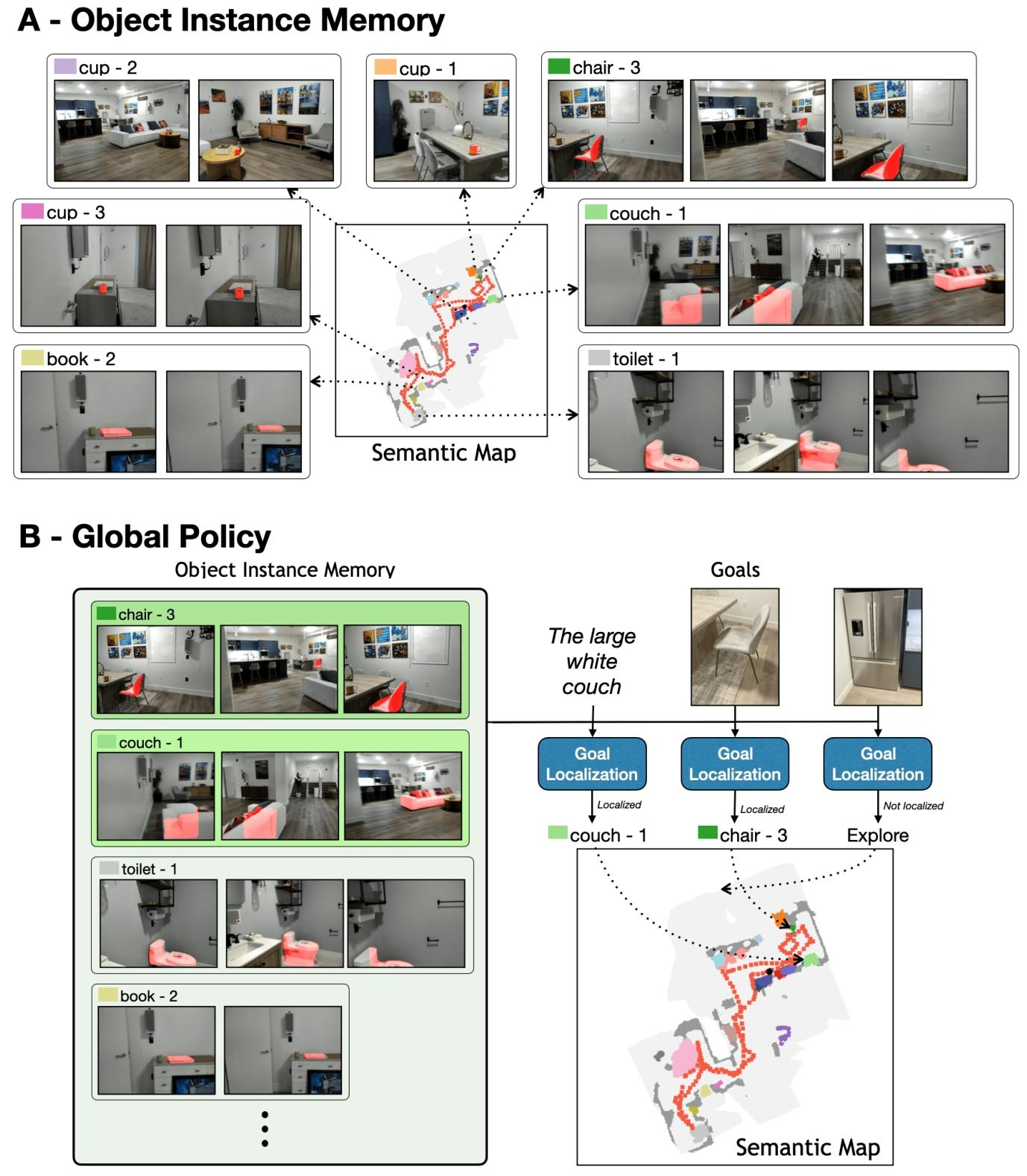
(1)核心作用
存储环境中所有物体实例的 “视觉 - 空间 - 类别” 信息,是 GOAT “终身学习” 与 “实例区分” 的核心,结构如下表:
| 存储内容 | 描述 |
|---|---|
| 实例地图单元格集合Ci | 记录第i个实例在语义地图中的空间位置(单元格集合) |
| 实例视图集合Mi | 存储第i个实例的带上下文边界框图像(而非特征,便于后续多模态匹配) |
| 语义类别Si | 记录第i个实例的类别标签(如 “couch”“sink”) |
(2)实例聚类与更新规则
当感知模块检测到新物体实例d时,按以下规则更新记忆:
- 对新实例d的地图位置Cd进行 “膨胀操作”(dilate by p units),得到Dd;
- 检查记忆中是否存在 “类别相同且位置重叠” 的实例i:若Sd=Si且
,则将新实例的位置与视图合并到现有实例中(Ci←Ci∪Cd,Mi←Mi∪{Id});
- 若不存在匹配实例,则新增一个实例条目,存储Cd、Id与Sd。
4. 全局策略(Global Policy)
(1)核心功能
根据 “目标模态” 查询实例记忆,判断目标是否已定位:若已定位则输出 “长期导航目标”,若未定位则输出 “探索目标”。
(2)多模态目标匹配逻辑
| 目标类型 | 匹配步骤 |
|---|---|
| 类别目标(如 “SINK”) | 直接查询语义地图,判断是否存在该类别的实例,选择最近实例作为目标 |
| 语言目标(如 “沙发旁的盆栽”) | 1. 用 Mistral 7B 从语言描述中提取类别(如 “potted plant”); 2. 仅查询该类别的实例,计算语言描述与实例视图的 CLIP 特征余弦相似度; 3. 探索阶段:相似度 > 0.28 则匹配;探索完成后:选择相似度最高的实例 |
| 图像目标(如 “某盆栽照片”) | 1. 用 Mask R-CNN 从目标图像中提取类别; 2. 仅查询该类别的实例,用 SuperGlue 计算目标图像与实例视图的关键点匹配分数; 3. 探索阶段:分数 > 6.0 则匹配;探索完成后:选择分数最高的实例 |
(3)探索策略
采用 “前沿探索(Frontier-based Exploration)”:将 “已探索区域与未探索区域的边界” 定义为 “前沿”,选择最近的前沿作为临时探索目标,直至定位到导航目标。
5. 局部策略(Local Policy)
(1)核心功能
将全局策略输出的 “长期目标” 转化为机器人可执行的运动指令,确保避障并高效到达目标。
(2)路径规划与运动控制
- 路径规划:用 “快速行进法(Fast Marching Method)” 在语义地图上规划从当前位置到目标的最优路径(避开障碍物);
- 运动控制:
- 波士顿动力 Spot:调用内置的点导航控制器,沿路径执行 - waypoint 导航;
- Hello Robot Stretch:无内置控制器时,沿路径规划第一个基础动作(如 “前进 50cm”“左转 30°”)。
四、数据集:
1. 实验环境与物体实例
- 环境选择:9 个 “未见过的租赁家庭”(unseen rented homes),环境具有视觉多样性(如不同户型、家具布局、装修风格),且实验前无预计算的地图或物体位置信息,完全模拟真实世界机器人部署场景。
- 物体实例覆盖:实验涉及 200 + 个不同物体实例,涵盖 15 个常见室内物体类别,具体类别包括:
chair(椅子)、couch(沙发)、potted plant(盆栽)、bed(床)、toilet(马桶)、tv(电视)、dining table(餐桌)、oven(烤箱)、sink(水槽)、refrigerator(冰箱)、book(书)、vase(花瓶)、cup(杯子)、bottle(瓶子)、teddy bear(泰迪熊)。
2. 目标任务数据
实验中的导航目标分为 “类别目标”“图像目标”“语言目标” 三类,数据生成方式如下:
- 类别目标:直接从上述 15 个类别中随机选择,目标为 “该类别下的任意物体实例”(如 “找一个水槽”);
- 图像目标:按照 Krantz et al. [32] 的实验协议,对每个物体实例拍摄一张图像作为目标查询(如 “找与这张盆栽照片一致的实例”),示例可见图 9和图 10;
- 语言目标:为每个物体实例人工标注 3 条唯一识别性语言描述(如 “沙发旁带红叶的盆栽”),确保描述能区分同一类别的不同实例,示例可见图 9和图 10。
3. 实验序列数据
- 序列生成:每个家庭环境中生成 10 个实验序列(episode),每个序列包含 5-10 个连续导航目标,三类目标在序列中均匀分配(各占 1/3 左右);
- 数据规模:实验累计运行超 90 小时,共完成 675 个导航目标任务(9 个家庭 ×10 个序列 × 平均 7.5 个目标 / 序列),所有数据均为机器人在真实环境中实时采集的传感器数据(RGB 图像、深度图像、位姿数据)。
五、基线设计
为验证 GOAT 核心功能(实例感知、终身记忆、多模态匹配)的有效性,论文设计了3 个基线(Baseline) 与 GOAT 进行对比,各对照组的设计逻辑、核心差异及验证目标如下表所示:
| 对照组名称 | 核心设计逻辑 | 与 GOAT 的核心差异 | 验证目标 |
|---|---|---|---|
| CLIP on Wheels [18] | 跟踪机器人见过的所有图像,通过 CLIP 特征匹配目标(语言 / 图像)与过往图像 | 无 “实例感知语义记忆”,仅匹配全局图像特征,不区分同一类别的不同实例;无类别筛选逻辑 | 验证 GOAT“实例级记忆 + 类别筛选” 相比 “全局图像特征匹配” 的优势 |
| GOAT w/o Instances | 仅将目标视为 “类别标签”,不区分同一类别的不同实例,始终导航至最近的类别物体 | 移除 “实例感知” 能力,无法处理 “图像目标”“细粒度语言目标”(如 “沙发旁的盆栽”) | 验证 “实例区分” 对多模态目标(尤其是图像 / 语言目标)导航的必要性 |
| GOAT w/o Memory | 完成每个目标后,重置语义地图与实例记忆,无法利用过往探索经验 | 移除 “终身学习” 能力,每次目标均需重新探索环境,无法复用历史实例位置信息 | 验证 “终身记忆” 对提升导航效率(减少重复探索)和成功率的作用 |
 六、实验评价指标
六、实验评价指标
论文采用两个核心指标评价导航性能,均按 “每个目标(per goal)” 计算,避免序列级指标掩盖单目标性能差异,指标定义、计算方法及判定标准如下:
1. 成功率(Success Rate, SR)
- 定义:衡量机器人 “在时间预算内到达正确目标实例” 的比例,是导航任务的核心有效性指标。
- 成功判定标准:
- 机器人在200 步时间预算内调用 “停止动作”;
- 停止位置与 “正确目标实例” 的距离小于 1 米;
- 目标实例的类别与任务指定类别一致(若为图像 / 语言目标,需匹配到正确实例);
- 统计方式:按 “整体” 和 “目标类型(图像 / 语言 / 类别)” 分别统计,结果带两倍标准差(±2σ) 误差棒,确保可靠性。
2. 路径效率(Success Weighted by Path Length, SPL)
- 定义:结合 “成功率” 与 “路径合理性”,衡量导航的效率 —— 成功到达目标时,SPL 越高表示路径越接近最优;失败时 SPL 为 0。
- 计算公式:
SPL={0min(1,机器人实际路径长度最优路径长度)若目标失败若目标成功
其中:- 最优路径长度:机器人当前位置到 “距离前一个目标最近的正确实例” 的测地线距离(沿可通行区域的最短路径);
- 机器人实际路径长度:机器人从启动到停止的实际移动距离;
- 意义:SPL 避免 “成功但绕远路” 的情况被误判为高性能,更全面反映导航系统的实用性。
七、实验结论
1. GOAT 系统实现高性能多模态终身导航
GOAT 在真实场景中展现出优异的导航能力,核心性能指标显著优于基线方法:
- 整体成功率与优势:GOAT 的整体导航成功率达 83%,较 CLIP on Wheels(50.7%)、GOAT w/o Instances(49.4%)、GOAT w/o Memory(60.3%)等基线方法绝对提升 32%,且性能随环境经验积累持续提升 —— 从首个目标的 60% 成功率,提升至充分探索后的 90% 成功率;
- 分模态性能:在三类目标中表现均衡:① 类别目标成功率最高(94.3%),因无需区分实例;② 图像目标成功率次之(86.4%),依赖 SuperGlue 的几何匹配优势;③ 语言目标成功率为 68.2%,虽低于前两者,但仍显著优于基线(CLIP on Wheels 语言目标成功率仅 40.8%);
- 路径效率:GOAT 的平均路径效率(SPL)达 0.642,远高于基线(CLIP on Wheels 0.418、GOAT w/o Instances 0.398、GOAT w/o Memory 0.188),证明其不仅能成功导航,还能规划高效路径。
2. 核心设计(实例记忆、模块化)是性能关键
- 实例感知语义记忆的必要性:移除 “实例区分能力” 的基线(GOAT w/o Instances),其图像目标成功率仅 28.6%、语言目标成功率仅 27.6%,远低于 GOAT 的 86.4% 和 68.2%;移除 “终身记忆” 的基线(GOAT w/o Memory)需重复探索,SPL 仅 0.188(GOAT 为 0.642),证明 “实例级记忆 + 终身复用” 是多模态导航与效率提升的核心;
- 模块化设计的有效性:GOAT 的模块化架构(感知 - 记忆 - 全局策略 - 局部策略)实现两大优势:① 平台无关性:无需重新训练即可部署于波士顿动力 Spot(四足)与 Hello Robot Stretch(轮式);② 组件灵活替换:感知模块可替换为不同实例分割模型,匹配模块可适配 CLIP/SuperGlue,且无需修改整体框架;
- 多模态匹配策略的优势:① 图像匹配(SuperGlue)比语言匹配(CLIP)可靠,前者成功率比后者高 23%,因 SuperGlue 可捕捉几何特征,CLIP 难以区分细粒度实例属性;② 按 “目标类别筛选实例” 可使匹配精度提升 23%,“带背景的扩展边界框” 可使匹配精度提升 22。
3. GOAT 可直接支撑下游实用任务
作为通用导航原语,GOAT 无需大幅修改即可集成到下游任务,验证了其扩展性:
- 开放词汇移动操作(拾取 - 放置):结合机器人抓取功能(如波士顿动力 Spot 的内置技能),在 30 个 “拾取 - 放置” 任务(如 “把咖啡杯从茶几放到水槽”)中,物体定位成功率达 79%、容器定位成功率达 87%;
- 社交导航:将人类视为 “PERSON 类别动态实例”,可实现 “避障人类” 与 “跟踪人类”:① 存在移动人类时,导航成功率仍保持 81%;② 搜索并跟踪人类的成功率达 83%,接近静态图像目标的 86% 成功率
八、创新点分析
1. 提出 “实例感知语义记忆”:支撑终身式多模态导航
这是 GOAT 实现 “终身学习” 与 “实例区分” 的核心创新,其设计突破传统 “类别级语义记忆” 的局限:
- 记忆内容:不仅存储物体的类别标签,还记录每个物体实例的 “多视角外观(带上下文的边界框图像)” 与 “3D 空间位置”,可区分同一类别的不同实例(如 “沙发旁的盆栽” 与 “窗边的盆栽”);
- 更新机制:机器人移动时,实时将新检测到的物体实例与记忆中已有实例比对(基于类别一致性与空间位置重叠性),若为同一实例则合并多视角数据,若为新实例则新增记录,实现记忆的 “持续扩充”;
- 多模态适配:记忆中存储 “原始图像” 而非 “预提取特征”,可灵活调用 CLIP(语言 - 图像匹配)、SuperGlue(图像 - 图像匹配)等模型,支撑多模态目标查询,避免单一特征对匹配模态的限制。
2. 模块化系统架构:实现平台无关性与下游任务扩展性
GOAT 采用 “感知 - 记忆 - 决策 - 控制” 模块化设计,突破传统端到端方法的平台依赖局限:
- 模块解耦:
- 感知模块:处理 RGB-D 数据与位姿数据,输出实例分割结果与稠密深度图(模型可替换,如 Mask R-CNN、MiDaS);
- 记忆模块:存储实例数据,与硬件无关;
- 全局策略:负责目标匹配与探索决策;
- 局部策略:负责路径规划与运动控制(适配不同机器人的运动指令);
- 平台适配性:仅需机器人具备 “RGB-D 相机 + 位姿传感器 + 基础运动能力”,无需重新训练即可部署(如 Spot 调用内置导航控制器,Stretch 采用自定义动作规划);
- 下游扩展性:作为通用导航原语,可直接集成到拾取 - 放置(结合机器人抓取功能)、社交导航(将人类视为动态实例)等任务,无需修改核心模块,在 30 个拾取 - 放置任务中物体 / 容器定位成功率达 79%/87%,社交导航成功率达 81%-83%。
3. 精准的多模态目标匹配策略:提升实例级匹配精度
针对不同模态目标的特性,设计差异化匹配逻辑,解决 “语言目标匹配精度低”“图像目标误匹配” 等问题:
- 类别筛选预优化:匹配前先从目标(语言 / 图像)中提取类别(如从 “沙发旁的盆栽” 提取 “potted plant”),仅在记忆中筛选同类别实例进行匹配,减少无关计算并降低误匹配率(精度提升 23%);
- 模态化匹配模型:
- 语言目标:用 CLIP 计算 “语言文本特征 - 实例图像特征” 的余弦相似度,探索阶段设阈值(0.28),探索完成后取最高分实例;
- 图像目标:用 SuperGlue 进行关键点匹配(几何特征更鲁棒),探索阶段设阈值(6.0),探索完成后取最高分实例;
- 上下文增强匹配:匹配时使用 “带背景的扩展边界框图像”(而非仅物体本身),利用背景信息区分相似实例(如 “厨房水槽” 的背景是橱柜,“浴室水槽” 的背景是镜子),匹配精度提升 22%。
4. 深度图像填充方法:修复传感器数据缺陷,提升定位精度
针对 RGB-D 相机深度图像的 “孔洞” 问题(如反光物体导致的深度缺失),提出基于单目深度估计的填充方法,公式如下:
- 用 MiDaS 模型从 RGB 图像It生成稠密相对深度图Xt,i(i为像素索引);
- 通过最小二乘优化求解缩放因子A与偏移量b,将相对深度校准为绝对深度(与原始深度图Dt的有效像素对齐):A,bargmin∑i∥Dt,i−AXt,i−b∥2
其中Dt,i为原始深度图中第i个像素的真实深度值,Xt,i为 MiDaS 估计的对应像素深度值🔶1-77、; - 用校准后的绝对深度填充原始深度图的孔洞,生成完整稠密深度图,为 3D 空间定位与路径规划提供可靠数据支撑。
5. 基于动物导航认知的设计:融合跨学科理论提升导航合理性
GOAT 的设计灵感源于动物与人类导航的核心认知发现,突破传统 “纯几何导航” 的局限:
- 认知地图启发:借鉴动物海马体的 “认知地图” 机制,构建包含语义与实例信息的环境表征,而非仅依赖几何坐标,提升导航的全局规划能力;
- 路径知识整合:参考人类通过 “路径级经验”(起点、终点、途经点)构建全局地图的过程,设计 “终身记忆” 机制,让机器人通过连续任务逐步完善环境认知,而非每次从零开始;
- 视觉地标依赖:结合动物导航对 “视觉地标” 的依赖(而非仅几何位置),在记忆中重点存储物体的多视角外观,提升复杂环境中(如相似户型)的导航鲁棒性。
九、相关工作
1. 经典几何导航方法
- 核心思路:基于几何推理实现导航,仅关注环境的空间几何属性(如位置、距离、障碍物分布),不涉及语义信息(如物体类别、外观)。
- 代表性工作:
- Thrun et al. [56, 57] 提出的 “概率机器人” 框架,采用 occupancy grid(占据栅格)进行环境建模,通过 SLAM 实现定位与地图构建,是经典几何导航的基础;
- Elfes [14] 的占据栅格地图(Occupancy Grids),为移动机器人感知与导航提供了早期几何表征范式。
- 局限:仅能处理 “几何目标”(如 “导航到坐标 (x,y)”),无法理解人类直观的语义指令(如 “找沙发”),缺乏与环境的语义交互能力。
2. 语义导航方法(单模态为主)
随着视觉 - 语义理解技术的发展,研究者开始将语义信息融入导航,但多数方法仅支持单一模态目标,且存在 “非终身式、仿真验证为主” 的局限,具体可分为三类:
(1)类别目标导航(仅支持 “找某类物体”)
- 核心思路:通过语义推理识别物体类别,导航至任意该类物体,无需区分实例(如 “找任意一个水槽”)。
- 代表性工作:
- Gupta et al. [21] 的 “认知地图与规划”(Cognitive Mapping and Planning),首次将语义融入视觉导航,提升未知环境探索效率;
- Chaplot et al. [143] 的 “目标导向语义探索”(Object Goal Navigation using Goal-Oriented Semantic Exploration),通过语义探索优化类别目标定位;
- 其他如 [3, 6, 8, 34, 46, 53] 等工作,均围绕 “类别级语义目标” 展开,聚焦如何高效找到某类物体。
- 局限:无法区分同一类别的不同实例(如无法区分 “厨房水槽” 与 “浴室水槽”),无法处理图像或语言指定的细粒度目标。
(2)图像目标导航(仅支持 “找与图像一致的物体”)
- 核心思路:以图像作为目标查询,通过图像匹配定位物体实例,需解决 “图像与真实场景物体的视角差异、光照变化” 问题。
- 代表性工作:
- Zhu et al. [63] 的 “目标驱动视觉导航”,首次尝试基于深度强化学习处理图像目标,但仅在仿真环境验证;
- Krantz et al. [32, 33] 的 “实例特定图像目标导航”,提出图像目标匹配的基础范式,但仅支持单一图像目标,且未在真实场景大规模验证;
- 其他如 [10, 22, 33] 等工作,虽关注图像目标,但多局限于仿真或单任务场景。
- 局限:仅支持图像模态,无法理解语言指令;且多数方法未实现 “终身学习”,每次任务需重新探索。
(3)语言目标导航(仅支持 “按语言指令找物体”)
- 核心思路:将自然语言指令转化为导航目标,需解决 “语言与物理空间的视觉接地”(如将 “沙发旁的盆栽” 映射到真实物体)。
- 代表性工作:
- Anderson et al. [38] 的 “视觉 - 语言导航”(Vision-and-Language Navigation),开创了语言驱动导航的研究方向,需按连续语言指令导航;
- Min et al. [179] 的 “FILM” 框架,通过模块化方法处理语言指令,但仅支持单任务,且依赖仿真环境;
- Gadre et al. [18] 的 “CLIP on Wheels”,尝试用 CLIP 实现零样本语言目标导航,但仅通过全局图像特征匹配,无实例区分能力,成功率低(GOAT 实验中仅 50.7%)。
- 局限:多数方法仅支持 “单条语言指令导航”,无法复用过往经验;且语言理解局限于粗粒度类别,难以处理细粒度实例描述(如 “带红色枕头的床”)。
3. 环境记忆与表征相关工作
现有研究在 “环境记忆” 设计上分为参数化表征(如神经网络特征)与非参数化表征(如图像集合),但均未实现 “实例感知 + 多模态适配 + 终身扩充” 的结合:
- 参数化表征:
- Chaplot et al. [145] 的 “神经拓扑 SLAM”(Neural Topological SLAM),将环境编码为神经网络特征,支持图像目标导航,但特征固定,无法终身更新;
- Bolte et al. [140] 的 “USA-Net”,构建语义与功能的统一表征,但依赖预训练模型参数,无法灵活适配多模态目标。
- 非参数化表征:
- Kuipers et al. [174] 的 “拓扑表征”,通过节点与边描述环境结构,但缺乏语义与视觉信息;
- Savinov et al. [189] 的 “半参数拓扑记忆”,存储图像作为拓扑节点,但无法区分物体实例,多模态匹配能力弱。
- GOAT 的突破:融合两类表征优势 —— 构建 “语义地图(参数化空间表征)+ 实例图像记忆(非参数化视觉表征)”,实现 “空间 - 语义 - 视觉” 的统一记忆,且支持终身扩充。
4. 现有方法的共同局限
论文明确指出,现有相关工作存在三大核心局限,而 GOAT 正是针对这些局限提出的解决方案:
- 单模态局限:多数方法仅支持类别、图像、语言中的一种目标类型,无法满足人类多样化交互需求;
- 非终身式局限:仅处理单目标任务(one goal per episode),完成后重置记忆,无法复用同一环境的过往经验;
- 仿真与平台依赖:多数方法仅在仿真环境(如 Habitat、AI2-THOR)验证,少数真实场景实验也仅支持单目标,且端到端方法需针对特定硬件重新训练。