性能测试-jmeter7-元件提取器
课程:B站大学
记录软件测试-性能测试学习历程、掌握前端性能测试、后端性能测试、服务端性能测试的你才是一个专业的软件测试工程师
性能测试-jmeter元件提取器
- 接口之间如何通信和关联?
- 常用的关联方式
- 正则表达式提取器
- XPath提取器
- JSO提取器
- 如何全局变量通信呢?
- 跨线程组关联
- 为什么需要跨线程组关联?
- 两种引用变量方式
- 1. 使用属性(Properties)共享数据(最常用方法)
- 2.在目标线程组中通过属性引用数据
- 实践是检验真理的唯一标准
接口之间如何通信和关联?
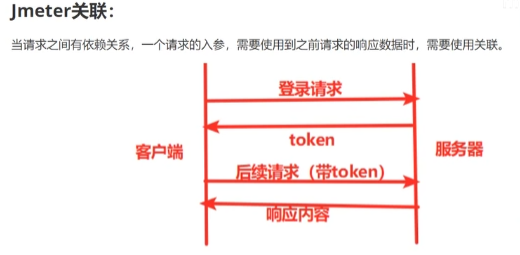
当请求之间有依赖关系,比如一个请求的入参是另一个请求返回的数据,这时候就需要用到关联处理。通过一些组件来处理关联。
常用的关联方式
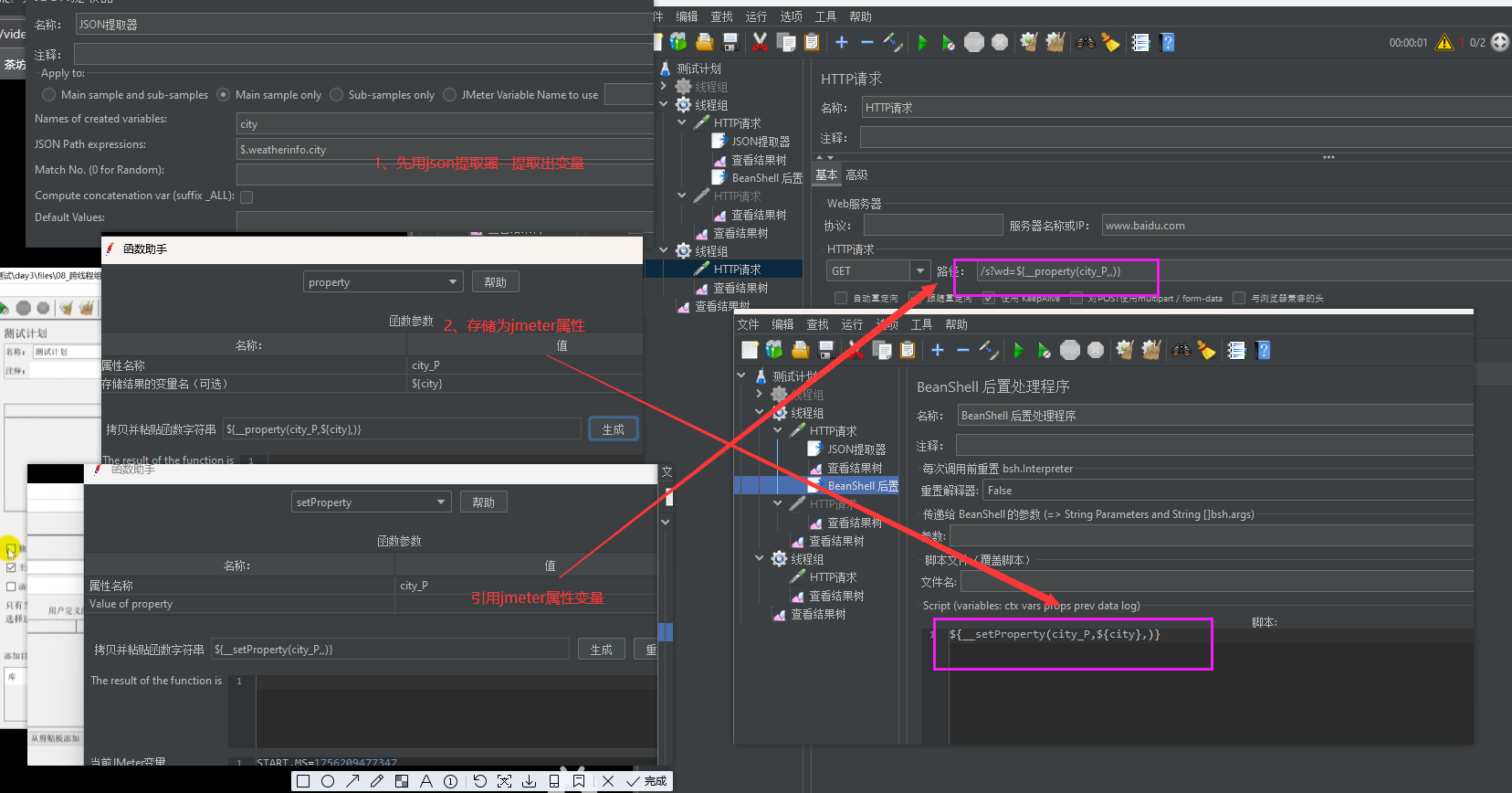
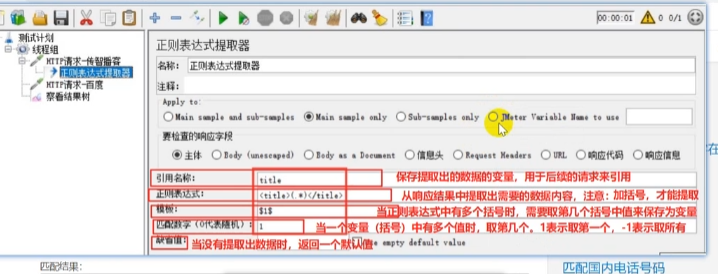
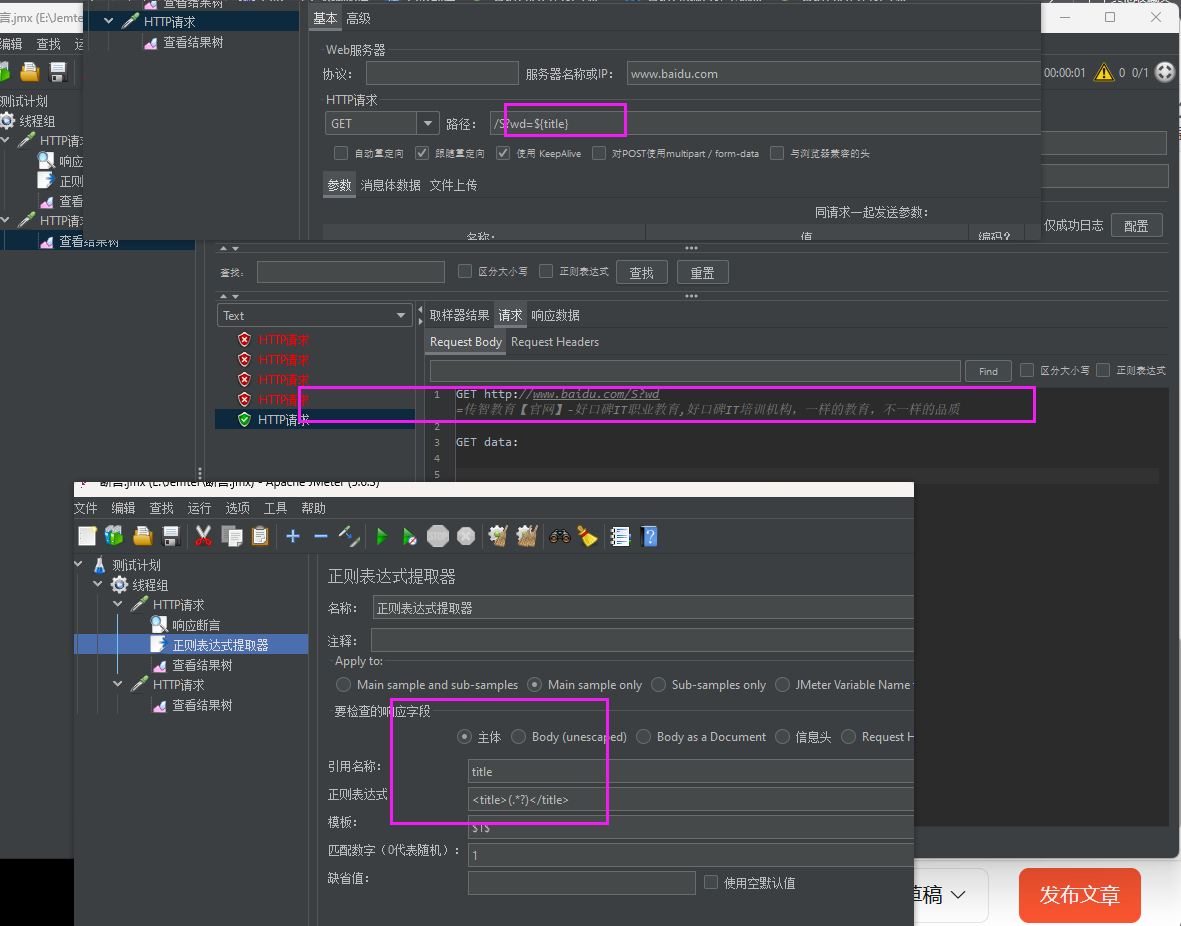
正则表达式提取器
正则表达式提取器是JMeter的后置处理器,用于从服务器返回的响应数据(如HTML、JSON、文本等)中提取指定内容(如ID、Token、动态参数等),并将提取的值保存为JMeter变量,供后续请求引用。
简单工作流程
1.触发:在需要提取数据的请求后添加此提取器(如登录接口返回的Token需提取)。
2.提取:根据正则表达式从响应内容中匹配目标数据(如 “token”:"(.+?)"匹配 “token”:"abc123"中的 abc123)。
3.存储:将匹配到的值(如 abc123)保存到变量(如 ${token})。
4.复用:后续请求通过 ${token}直接引用该值(如传参到其他接口)。
正则表达式介绍:
<title>百度一下,你就知道</title><title>百度一下,你就知道</title><title>. *?</title>. : 是通配符,可以代表任意字符(除换行回车)*: 代表前面的字符出现0次或者多次.*匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找左边界和右边
实验:

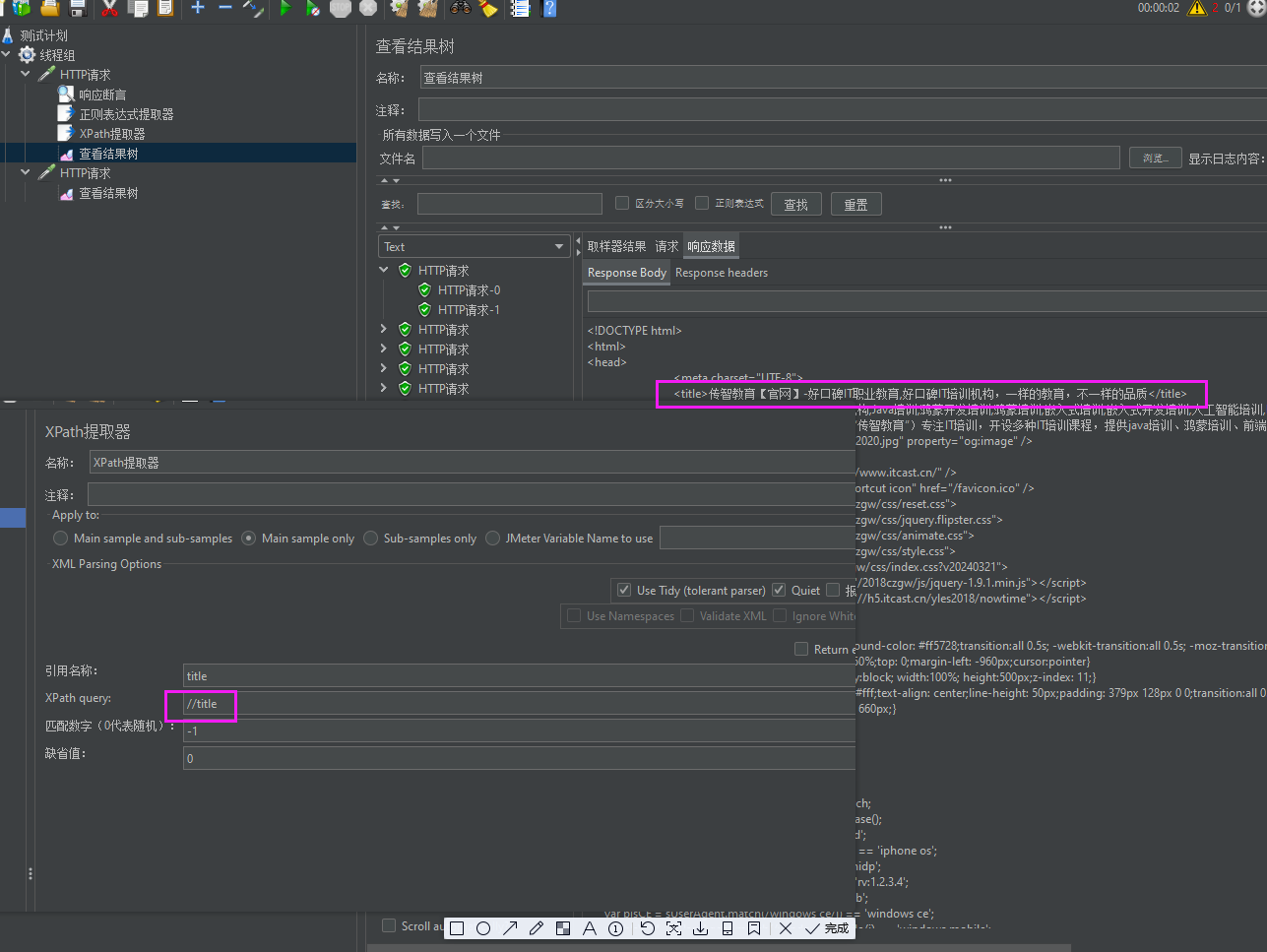
XPath提取器
XPath(XML Path Language) 是一种用于在 XML/HTML 文档中定位节点(元素、属性、文本等)的语言,通过路径表达式精准查找目标数据。在 JMeter 中,它被广泛用于 XPath 提取器,从接口返回的 XML 或 HTML 响应中提取关键信息(如 Token、用户 ID、动态参数等)。
一、基础语法回顾
•节点选择:
•/从根节点开始逐级查找(绝对路径)
•//从任意层级查找(相对路径,不关心父节点结构)
•属性筛选:[@属性名=‘属性值’](如 [@id=‘username’])
•文本内容提取:/text()(获取节点内的纯文本)
•多条件组合:用 and(如 [@class=‘item’ and @status=‘active’])
JSO提取器
JSON 提取器(JSON Extractor) 是 JMeter 的后置处理器,专门用于从 JSON 格式的响应数据(如接口返回的 { “key”: “value” })中提取指定字段的值,并将提取结果保存为 JMeter 变量,供后续请求或断言使用。
(1)基础符号
- $:表示 JSON 数据的根节点(所有路径从这里开始)。
- .或 []:访问对象的属性或数组的元素。
- 对象属性:$.key(如 $.name提取 { “name”: “Alice” }中的 Alice)。
- 数组元素:$.array[0](如 $.users[0].id提取数组 users的第一个元素的 id)。
| JSON 示例 | 目标字段 | JSONPath 表达式 | 说明 |
|---|---|---|---|
{ "token": "abc123", "status": "success" } | 提取 token 的值 | $.token | 直接取根节点下的 token 字段。 |
{ "data": { "userId": 1001, "name": "Bob" } } | 提取 data 下的 userId | $.data.userId | 嵌套对象:用 . 逐级访问。 |
{ "users": [ { "id": 1, "name": "Alice" }, { "id": 2, "name": "Bob" } ] } | 提取第一个用户的 name | $.users[0].name | 数组索引从 0 开始([0] 是第一个)。 |
{ "products": [ { "id": 101, "price": 99 }, { "id": 102, "price": 199 } ] } | 提取所有产品的 id | $.products[*].id | [*] 表示数组所有元素。 |
{ "code": 200, "message": "OK" } | 提取 message | $.message | 根节点下的直接字段。 |
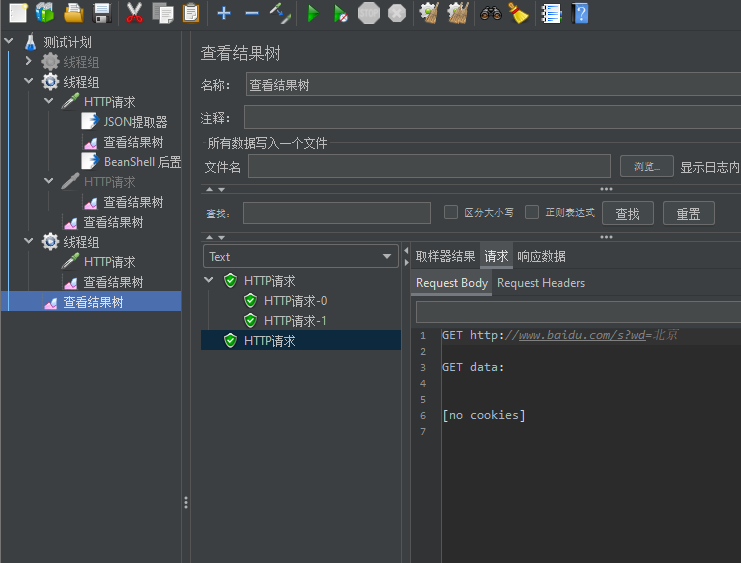
实验:

重点:json提取器,xpath提取器,正则表达式提取器都是在同一个线程组进行保存变量提取的
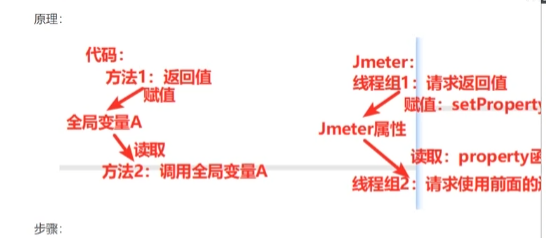
如何全局变量通信呢?
跨线程组关联
跨线程组关联是指在JMeter测试计划中,将一个线程组(Thread Group)中获取的动态数据(如Token、用户ID等)传递给另一个线程组使用,以实现不同线程组之间的数据共享和关联。
为什么需要跨线程组关联?
在复杂的测试场景中,经常有以下需求:
- 登录线程组获取的Token需要在后续业务线程组中使用
- 用户注册线程组生成的用户ID需要在用户信息查询线程组中引用
- 多个线程组模拟完整业务流程,前序线程组产生的数据被后续线程组依赖
两种引用变量方式
1. 使用属性(Properties)共享数据(最常用方法)
// BeanShell/JSR223脚本示例(JSR223推荐使用Groovy语言)
vars.put("extractedToken", "your_extracted_value"); // 先存到变量
props.put("globalToken", vars.get("extractedToken")); // 再存到属性
2.在目标线程组中通过属性引用数据
${__P(globalToken,)}
${__property(globalToken)}
常用的方式:推荐使用JSR223 + Groovy:性能优于BeanShell
实验:

自动化代码和jmeter的本质核心:
操作步骤: