Lora与QLora
一、为什么需要LoRA和QLoRA?——大模型微调的“痛点”
在当今人工智能蓬勃发展的浪潮中,大模型已然成为推动众多领域进步的核心力量。然而,大模型的微调过程却长期面临着资源消耗巨大的难题,恰似一座难以逾越的高山,阻挡着众多开发者和研究人员前行的步伐。就在此时,LoRA(Low-Rank Adaptation,低秩适应)与 QLoRA(Quantized Low-Rank Adaptation,量化低秩适应)技术应运而生,如同划破夜空的璀璨星辰,为大模型微调带来了全新的曙光。这两项技术极大地降低了大模型微调的门槛,让更多人能够参与到这一激动人心的领域之中,探索无限的可能。接下来,让我们深入探究 LoRA 与 QLoRA 技术的奥秘,揭开它们的神秘面纱。
下面举一个简单的例子让我们简单的认识一下Lora和QLora:一个130亿参数的大模型,全量微调一次要花上万元,普通开发者根本玩不起。这时候,LoRA和QLoRA就登场了——它们像给房子“局部改造”,只换关键家具(调整少量参数),既省钱又不破坏原有布局,让普通人也能玩转大模型微调。

二、LoRA:用“低秩矩阵”给大模型“打补丁”
1. LoRA是什么?
LoRA的全称是“Low-Rank Adaptation”(低秩适配),核心思想很简单:不直接修改大模型的原始参数,而是给它加个“小补丁”。
想象大模型的核心参数是一块“大黑板”(比如1024×1024的权重矩阵),上面写满了预训练学到的通用知识。全量微调要擦了重写,而LoRA只在黑板旁边贴一块“小便利贴”(低秩矩阵),上面写着领域专属知识(比如医疗术语、法律条文)。推理时,把“黑板内容”和“便利贴内容”加起来,就是适配后的效果。
2. LoRA的核心原理
这里需要一点简单的数学概念(别怕,用例子讲明白):
- 原始权重矩阵:比如维度是1024×1024,需要1024×1024=1,048,576个参数;
- LoRA的“补丁”:拆成两个小矩阵A(1024×16)和B(16×1024),总共只要1024×16 + 16×1024=32,768个参数;
- 参数减少:32,768 ÷ 1,048,576 ≈ 3%,相当于只花3%的参数就实现了适配!
讲完例子这里我们上干货:
LoRA(Low-Rank Adaptation)通过低秩分解实现参数高效微调。假设预训练模型的权重矩阵为:[W0∈Rd×k][ W_0 \in \mathbb{R}^{d \times k} ][W0∈Rd×k]其权重更新量 (\Delta W) 分解为两个低秩矩阵的乘积:
[ΔW=BA其中B∈Rd×r, A∈Rr×k][ \Delta W = B A \quad \text{其中} \quad B \in \mathbb{R}^{d \times r}, \ A \in \mathbb{R}^{r \times k} ][ΔW=BA其中B∈Rd×r, A∈Rr×k]秩 (r)( r )(r) 满足 (r≪min(d,k))( r \ll \min(d,k) )(r≪min(d,k))。
微调后的权重矩阵表示为:
[W=W0+α⋅BA][ W = W_0 + \alpha \cdot BA ][W=W0+α⋅BA]
缩放系数 α\alphaα 控制适应强度。在Transformer结构中,LoRA通常作用于以下矩阵:
- 注意力层的 (Q/K/V)( Q/K/V )(Q/K/V) 权重: (Wq,Wk,Wv∈Rdmodel×dhead)( W_q, W_k, W_v \in \mathbb{R}^{d_{model} \times d_{head}} )(Wq,Wk,Wv∈Rdmodel×dhead)
- 前馈网络的中间层: (Wffn∈Rdmodel×dff)( W_{ffn} \in \mathbb{R}^{d_{model} \times d_{ff}} )(Wffn∈Rdmodel×dff)
冻结原始参数 (W0)( W_0 )(W0) 仅训练 (A,B)( A,B )(A,B),参数量从 (d×k)( d \times k )(d×k) 降至 (r×(d+k))( r \times (d+k) )(r×(d+k))。例如当 (r=8)( r=8 )(r=8) 时,可减少98%的可训练参数。
核心优势:
- 计算效率:反向传播仅需计算低秩矩阵梯度
- 内存优化:无需存储全参数梯度
- 模块化设计:不同任务可叠加独立LoRA模块
- 数学等价性:当 ( r \to \min(d,k) ) 时可还原完整参数更新
典型应用中 (α)( \alpha )(α) 取 (1/r)( 1/r )(1/r),初始时 (A)( A )(A) 采用零初始化而 (B)( B )(B) 用随机高斯分布,确保初始状态 (ΔW=0)( \Delta W = 0 )(ΔW=0)。实验表明,即使 (r)( r )(r) 小至4-32,也能达到全参数微调90%以上的性能。
为什么叫“低秩”?因为矩阵A和B的“秩”(可以理解为信息的“浓缩度”)只有16,远低于原始矩阵的1024,所以能大幅压缩参数。
训练机制解析:
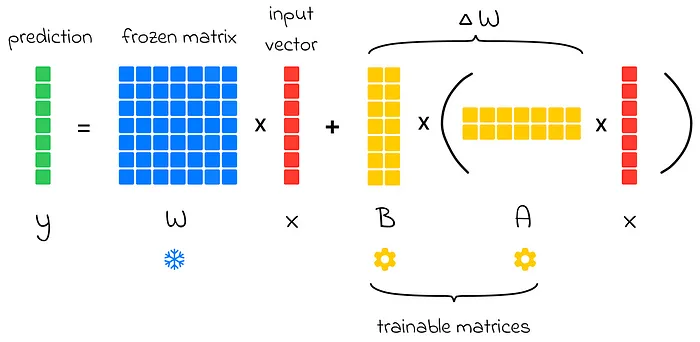
假设输入向量x传递至全连接层,原始权重矩阵为W,输出计算式为y = Wx。在微调过程中,我们通过增量矩阵ΔW进行参数调整,表达式变为y = (W + ΔW)x = Wx + ΔWx。通过引入矩阵分解BA代替ΔW,最终得到y = Wx + BAx。此时冻结原始权重W,仅需优化低秩矩阵A(n×k)和B(k×m)的参数——其参数量远小于原始ΔW矩阵。
矩阵运算优化技巧:
原式BAx的直接计算存在效率瓶颈,因为BA的矩阵相乘运算量较大。为此,LoRA巧妙利用矩阵乘法结合律,将其重构为B(Ax)的运算顺序:先将维度压缩的A与x相乘,再进行升维运算。这种分步计算策略显著提升了前向传播效率。
3. LoRA演示
以微调一个“医疗问答模型”为例,用Python代码演示(基于Hugging Face工具):
第一步:准备工具和模型
先安装必要的库,加载一个通用大模型(比如Alpaca-7B):
# 安装工具库
!pip install transformers peft torch datasets# 加载通用大模型和分词器
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model# 选择基座模型(70亿参数,普通电脑也能跑)
model_name = "chavinlo/alpaca-native"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
第二步:配置LoRA参数
告诉模型“补丁”要怎么加(调整哪些部分、加多大的补丁):
lora_config = LoraConfig(r=16, # 低秩矩阵的“秩”,越大效果越好但参数越多(常用8-32)lora_alpha=32, # 缩放因子,控制补丁的“影响力”target_modules=["q_proj", "v_proj"], # 只调整注意力层的关键参数lora_dropout=0.05, # 防止过拟合的“随机擦除”bias="none", # 不调整偏置参数task_type="CAUSAL_LM" # 任务类型:因果语言模型(文本生成)
)# 给模型加“补丁”
model = get_peft_model(model, lora_config)
# 查看可训练参数占比(通常只有0.1%-3%)
model.print_trainable_parameters()
# 输出:trainable params: 31,744,000 || all params: 7,039,004,672 || trainable%: 0.45
第三步:用医疗数据微调
准备少量医疗问答数据(比如1000条“症状→诊断建议”的样本),训练模型:
# 加载医疗数据集(这里用模拟数据举例)
from datasets import Dataset# 模拟医疗数据:症状→回答
data = [{"instruction": "用户说自己发烧38.5℃、咳嗽,该怎么建议?", "output": "建议多喝水、物理降温,若持续2天以上或出现胸闷,及时就医检查血常规。"}# 实际用1000+条类似数据
]
dataset = Dataset.from_list(data)# 数据预处理:把文本转成模型能懂的格式
def process_data(examples):prompts = [f"### 指令:{inst}\n### 回答:{out}" for inst, out in zip(examples["instruction"], examples["output"])]return tokenizer(prompts, truncation=True, max_length=512)dataset = dataset.map(process_data, batched=True)# 开始微调(简单训练3轮)
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir="./medical_lora_model", # 模型保存路径per_device_train_batch_size=4, # 每次处理4个样本(根据电脑内存调整)num_train_epochs=3, # 训练3轮learning_rate=3e-4, # 学习率(LoRA用较高学习率更有效)logging_steps=10, # 每10步打印一次进度fp16=False # 普通GPU关闭半精度训练
)trainer = Trainer(model=model,args=training_args,train_dataset=dataset
)# 开始训练(普通RTX 3090约1小时完成)
trainer.train()# 保存LoRA补丁(只有几十MB,方便分享)
model.save_pretrained("./medical_lora_patch")
第四步:用微调后的模型回答
加载“原始模型+LoRA补丁”,测试医疗问答效果:
# 加载补丁并合并到原始模型
from peft import PeftModel# 重新加载原始模型
base_model = AutoModelForCausalLM.from_pretrained(model_name)
# 加载LoRA补丁
lora_model = PeftModel.from_pretrained(base_model, "./medical_lora_patch")# 测试医疗问题
prompt = "### 指令:用户说自己胃痛、反酸,该怎么建议?\n### 回答:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = lora_model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# 输出:建议避免辛辣油腻食物,饭后不要立即平躺,若持续1周以上,建议做胃镜检查排除胃炎或胃溃疡。
4. LoRA的优缺点:什么时候用LoRA?
| 优点 | 缺点 |
|---|---|
| 参数量少(0.1%-3%),普通GPU就能跑 | 极复杂任务(如量子物理计算)效果不如全量微调 |
| 训练快(1-2小时完成),省钱 | 只能调整部分层,无法修改模型整体结构 |
| 不破坏原始模型,可随时切换领域(换个补丁就行) | 对“低秩假设”敏感(若领域知识无法用低秩表示,效果差) |
适用场景:中小规模模型(7B-13B)、垂直领域适配(医疗、教育、客服)、资源有限的开发者。
三、QLoRA
1. QLoRA是什么?——“量化+LoRA”的双重省钱方案
QLoRA的全称是“Quantized LoRA”(量化低秩适配),可以理解为“更省资源的LoRA”。它解决了LoRA的一个小痛点:即使LoRA只调整3%参数,原始模型(如7B)还是要占十几GB显存,普通笔记本电脑跑不动。
QLoRA的核心 trick 是**“量化”**:把模型的参数从32位浮点数(FP32)压缩成4位整数(4-bit),就像把高清图片压缩成小尺寸,体积变小但清晰度损失很少。
举个例子:7B模型的显存占用对比
- 全量微调(FP32):约28GB
- LoRA(FP16):约10GB
- QLoRA(4-bit):约4GB
普通笔记本的RTX 3060(6GB显存)就能跑QLoRA,真正实现“人人都能微调大模型”!
2. QLoRA的关键技术:为什么4位量化还能保精度?
很多人会问:“把32位压缩到4位,信息不会丢吗?” QLoRA用了两个黑科技解决这个问题:
(1)NF4量化:专门为大模型设计的“压缩算法”
传统4位量化是“均匀分配”(比如把0-1分成16等份),而NF4(NormalFloat4)是根据大模型参数的“正态分布”设计的——参数集中在中间值,就多分配几个档位;极端值少,就少分配档位,像“精准裁剪”一样保留关键信息。
(2)双精度计算:“存储用4位,计算用16位”
QLoRA只是“存储时用4位”节省显存,训练时会临时把参数恢复成16位(BF16)计算,既省空间又不丢精度。就像把压缩包解压缩后再用,用完再压缩回去。
3. QLoRA怎么用?——比LoRA多一步“量化配置”
QLoRA的代码和LoRA很像,只需要加个量化配置,小白也能快速上手:
第一步:安装量化工具
!pip install bitsandbytes # 用于4位量化的库
第二步:加载量化后的模型
from transformers import BitsAndBytesConfig# 配置4位量化参数
bnb_config = BitsAndBytesConfig(load_in_4bit=True, # 启用4位加载bnb_4bit_use_double_quant=True, # 双重量化(进一步压缩)bnb_4bit_quant_type="nf4", # 用NF4量化bnb_4bit_compute_dtype=torch.bfloat16 # 计算时用16位
)# 加载4位量化的模型(显存占用仅4GB左右)
model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config, # 启用量化device_map="auto" # 自动分配显存(CPU+GPU混合用)
)
第三步:后续步骤和LoRA完全一样
配置LoRA参数、加载数据、训练、测试,代码和前面的LoRA示例完全相同。唯一的区别是:现在即使是笔记本电脑,也能轻松跑起来!
4. QLoRA的优缺点:什么时候用QLoRA?
| 优点 | 缺点 |
|---|---|
| 显存占用极低(4GB就能跑7B模型) | 量化/反量化会增加一点计算时间(约慢10%-20%) |
| 完全兼容LoRA的所有功能,无需改代码 | 超大模型(如33B)仍需10GB+显存,笔记本可能不够 |
| 精度损失小(和LoRA效果几乎一样) | 依赖bitsandbytes库,部分旧GPU不支持 |
适用场景:笔记本电脑、显存小于8GB的GPU、想尝试微调大模型的新手。
四、LoRA与QLoRA的对比与选择
1.显存与计算资源需求对比
LoRA在显存需求方面相对较高,它更适合于中等规模模型,如参数在100亿 - 300亿之间的模型。以单张24GB显存的显卡为例,使用LoRA可以较为流畅地对一些规模适中的模型进行微调,如GPT - 3的部分变体模型。这是因为LoRA虽然在参数更新上采用了低秩矩阵的高效方式,但预训练模型权重仍需以FP16(16位浮点)或BF16(Brain Floating Point)格式存储,这在一定程度上限制了其对大规模模型的处理能力。
相比之下,QLoRA在显存需求上展现出了无可比拟的优势。它通过4位量化技术,将预训练模型权重压缩至极致,使得单卡48GB显存即可轻松应对650亿参数模型的微调任务。这一特性使得在资源有限的场景下,如学术研究机构可能仅有少量高性能GPU,或者中小企业预算有限无法购置大量高端硬件设备,QLoRA成为了实现大规模模型微调的唯一可行方案。
2.精度与速度表现差异
LoRA在计算过程中保持全精度计算,如FP16格式。这使得在推理阶段,LoRA能够直接将低秩更新合并到原始权重,推理延迟极低,几乎可以忽略不计。这种特性使得LoRA在对实时性要求极高的任务中表现出色,例如智能客服系统,用户输入问题后需要模型立即给出回答,LoRA能够保证快速响应,为用户提供流畅的交互体验。
QLoRA由于采用了4位量化存储权重,在计算时需要将量化后的权重动态反量化为16位进行前向和反向传播,这一过程虽然在内存占用上实现了巨大优化,但不可避免地引入了一定的计算开销。相比LoRA,QLoRA的训练速度通常会慢15% - 30%左右。不过,在推理阶段,通过巧妙的优化,QLoRA的推理延迟增加并不明显,依然能够满足大多数实际应用的需求。而且,在许多复杂任务中,虽然QLoRA存在一定的量化误差,但由于其在模型结构和训练方法上的优化,整体性能依然能够接近甚至超越全参数微调的模型。
3.模型规模适应性分析
LoRA在百亿参数以下的模型中表现最为出色。对于这类模型,LoRA能够在保证微调效果的同时,充分发挥其参数效率高、易于实现等优势。以常见的文本分类任务为例,使用BERT模型(参数规模相对较小)进行微调时,LoRA能够快速调整模型参数,使其适应不同领域的文本分类需求,如新闻分类、情感分析等。在这些场景下,LoRA能够在较短的时间内完成训练,并且模型性能稳定,能够达到与全量微调相近的准确率。
QLoRA则是唯一能够支持单卡训练超大规模模型的技术。当模型参数规模达到数十亿甚至上百亿时,传统的微调方法往往因显存不足而无法进行,而QLoRA凭借其强大的量化和优化技术,能够在有限的硬件资源下对这些超大规模模型进行高效微调。例如,在训练一个用于全球金融市场分析的超大规模模型时,模型需要处理海量的金融数据和复杂的市场关系,参数规模庞大。此时,QLoRA能够在单张高端消费级GPU上完成微调,使得金融机构能够利用自身有限的硬件资源,对模型进行定制化训练,以适应不断变化的金融市场环境。
4.应用场景选择建议
- 优先选择LoRA的场景:
- 多任务快速切换:在智能客服系统中,客服人员可能需要同时处理咨询、投诉、订单查询等多种不同类型的任务。通过LoRA,只需为每个任务训练一个独立的LoRA模块,然后在不同任务之间快速切换这些模块,即可实现“一机多用”。这就像一个多功能的瑞士军刀,根据不同的需求切换不同的工具头,快速高效地完成各种任务。
- 高精度要求任务:在法律文书生成领域,每一个用词和表述都需要精确无误,因为这可能会影响到法律的执行和当事人的权益。在科研论文润色中,对于专业术语的准确表达和逻辑的严谨性也有着极高的要求。LoRA能够保持原始模型的高精度,确保在这些对精度要求苛刻的任务中,生成的文本准确、专业,符合行业标准。
- 边缘设备部署:在手机APP中的实时翻译功能中,需要模型能够在有限的设备资源下快速运行。LoRA在推理时可以直接将权重合并,模型体积小,能够轻松部署到边缘设备上,并且保证翻译的实时性和准确性。这就好比在手机这个小小的“战场”上,LoRA是一位小巧灵活的战士,能够迅速响应并完成任务。
- 优先选择QLoRA的场景:
- 超大规模模型微调:当需要对650亿参数的医疗问答大模型进行微调时,由于模型规模巨大,传统方法往往无法实现。而QLoRA能够在单卡的情况下完成这样的艰巨任务,通过对医疗领域的专业知识和大量病例数据的学习,使模型能够为患者提供更加精准、专业的医疗咨询服务。
- 显存严重受限环境:对于学生或小型研究团队来说,可能只有消费级显卡(如RTX 4090),但又希望能够进行行业知识库的训练。QLoRA的低显存需求使得他们能够在有限的硬件条件下开展研究工作,为行业知识的整理和应用提供了可能。
- 长期迭代项目:在智能语音助手的长期迭代过程中,需要不断根据用户的反馈和新的数据对模型进行调整。QLoRA的分页优化器能够有效避免内存溢出问题,保证模型在多次训练和更新过程中的稳定性,使得智能语音助手能够持续提升服务质量,为用户提供更加优质的语音交互体验。
五、LoRA和QLoRA怎么选?——一张表帮你做决策
| 对比维度 | LoRA | QLoRA |
|---|---|---|
| 显存需求 | 10GB(7B模型) | 4GB(7B模型) |
| 训练速度 | 快(无量化开销) | 略慢(需量化/反量化) |
| 精度 | 高(16位计算) | 很高(接近LoRA,误差<5%) |
| 硬件要求 | 中端GPU(如RTX 3090) | 入门GPU/笔记本(如RTX 3060) |
| 适用模型规模 | 7B-13B | 7B(33B需中端GPU) |
| 最佳场景 | 追求速度、有中端GPU | 资源有限、新手入门 |
决策指南:
- 如果你有RTX 3060/4050等入门GPU,直接用QLoRA;
- 如果你有RTX 3090/4090等高端GPU,想快一点就用LoRA;
- 不管选哪个,先从7B模型开始练手,熟悉后再尝试13B模型。
六、常见问题
1. 微调后模型“答非所问”怎么办?
- 检查数据:确保训练数据的“指令-回答”对应正确(比如别把“发烧”的回答写成“头痛”的);
- 增加数据量:如果只有100条数据,模型没学够,至少准备500-1000条;
- 调整LoRA参数:把r从16改成32,增加“补丁”的影响力。
2. 训练时提示“显存不足”怎么办?
- 降低batch size:把
per_device_train_batch_size从4改成2; - 用更小的模型:比如把13B模型换成7B模型;
- 启用梯度检查点:在加载模型时加
gradient_checkpointing_enable=True,牺牲一点速度换显存。
3. 微调后的模型怎么分享给别人?
- LoRA/QLoRA只需要分享“补丁文件”(几十MB),别人加载原始模型+补丁就能用,不用分享整个模型(几个GB);
- 分享命令:
peft_model.save_pretrained("补丁文件夹"),别人用PeftModel.from_pretrained(base_model, "补丁文件夹")加载。
总结
以前,大模型微调是“大厂专属”——需要百万级预算和专业团队;现在,有了LoRA和QLoRA,普通开发者用几千元的GPU就能给大模型“定制技能”:
- 学生可以微调一个“考研问答模型”,帮自己复习;
- 小公司可以微调一个“产品客服模型”,自动回复客户问题;
- 医生可以微调一个“科普模型”,给患者解释病情。
LoRA和QLoRA的核心价值,不是“技术多复杂”,而是“让AI技术更接地气”。如果你是小白,建议从QLoRA开始,用自己的笔记本电脑微调一个简单模型(比如“小说续写”“美食推荐”),亲自感受大模型的“可塑性”——这比看10篇理论文章都有用!