深度学习网络结构搭建
目录
任务抽象与网络结构设计
深度学习之迁移学习
Pytorch 模型调参
Dropout
调参经验
超参数
优化方法
编辑
Pytorch 使用案例
1. 模型定义
2. 模型初始化,设置优化器,设置损失函数
3.模型训练:Training Loop 和 Evaluate Model
Training Loop (训练循环)
Evaluate Model (模型评估)
完整流程总结
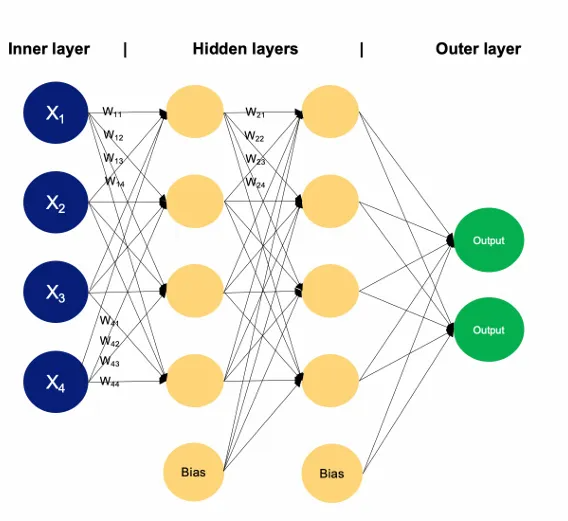
任务抽象与网络结构设计
深度学习的网络是最重要的超参数,深度学习的网络搭建,决定如下效果
- 模型的复杂度:复杂度越高,能力可能越强
- 模型的能力
- 模型过拟合的可能性: 模型越复杂,越容易过拟合(over fit)(也有一定可能欠拟合(under fit))
深度学习的网络是端到端的网络,深度学习网络结构的设计步骤如下:
- 优先关注输入和输出
- 损失函数和训练超参数
- 考虑是否有可参考的模型
- 最后关注调参细节
- 前面的层提取特征,增加维度,后面的层将特征转换为输出,可能是降低维度(这样设计比较好)
深度学习之迁移学习
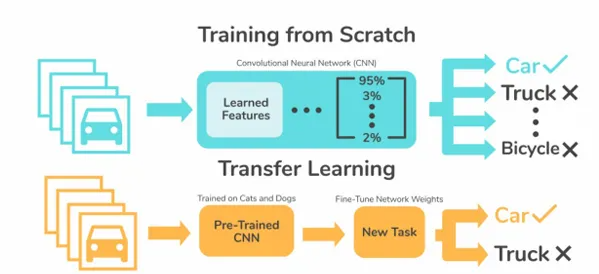
- 迁移学习是⼀种机器学习⽅法,其核⼼思想是将在⼀个任务(源任务)上学到的知识,应⽤到 另⼀个相关任务(⽬标任务)上。迁移学习⽅法旨在解决深度学习中的训练难题,例如数据量 不⾜或训练时间过⻓等问题。
- 特征提取 (Feature Extraction):
- 保留预训练模型(在源任务上训练好的模型)的⼤部分层(通常是前⾯⽤于提取特征 的层),并冻结它们的权重,使其在新的任务上不再更新。
- 仅⽤这些固定的层来提取新任务数据的特征。
- 之后,在模型顶部添加⼀个新的分类器或回归层,并在⽬标数据集上训练这个新加的 层。
- 微调 (Fine-tuning):
- 在特征提取的基础上,对预训练模型的部分甚⾄全部参数进⾏微调。
- 这意味着在⽬标数据集上,不仅训练新加的层,还以⼀个⾮常⼩的学习率继续训练 (更新)预训练模型的权重
Pytorch 模型调参
深度学习的调参,是一种比较困难的问题,其本质是非凸优化问题的调优
- 损失函数是非凸的:由于模型结构复杂(多层嵌套、非线性激活函数),损失函数 L(W, b) 在这个高维参数空间中的形状不是一個光滑的碗状(凸函数),而是一个极其复杂的崎岖地貌,充满了:
- 局部最优点:周围的点都比它差,但它不是全局最好的。
- 鞍点:在某些方向上是谷底,在另一些方向上是山峰。在高维空间中,鞍点的数量远远多于局部最优点,成为优化的主要障碍。
- 平坦区域:梯度非常小,学习速度极慢。
- 悬崖区域:梯度突然变得巨大,可能导致训练崩溃。
结论:深度学习的训练过程,就是在这样一个超高维、极其复杂崎岖的地形上,蒙着眼睛,试图找到最低点的过程。 “调参”的本质,就是为我们选择的“登山者”(优化算法)制定一套最有效的搜索策略。
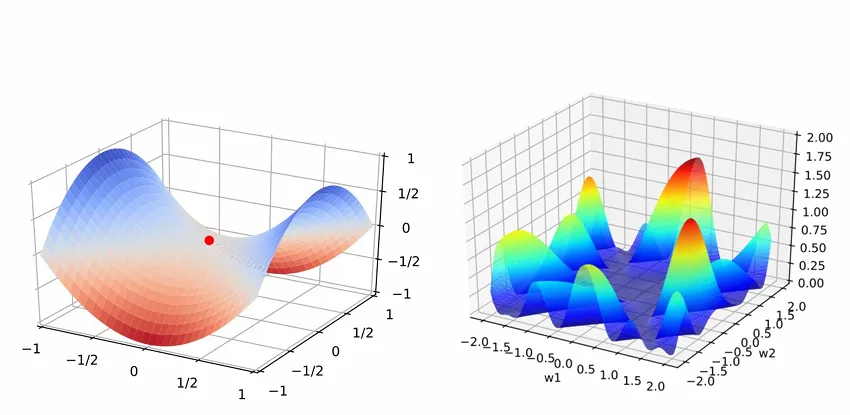
在深度学习的调优中,往往不追求全局最优,更倾向于寻找一个合适的局部最优。调优方向如下
- 参数初始化:初始参数的选择对于训练过程⾄关重要。如果初始化不当,训练可能收敛到不好的局部最优 解,甚⾄导致梯度消失或梯度爆炸,使训练失败
- 逃离局部最优:传统的优化算法(如梯度下降SGD)容易在训练过程中陷⼊损失曲⾯上的局部最⼩值。即使找到了⼀个局部最⼩值,它也不⼀定是全局最优解,导致模型性能不佳。引入动量(SGD with Momentum):模拟物理中的动量。损失值不仅看当前坡度,还会考虑之前的方向。这有助于穿过狭窄的谷底、平坦区域和鞍点。
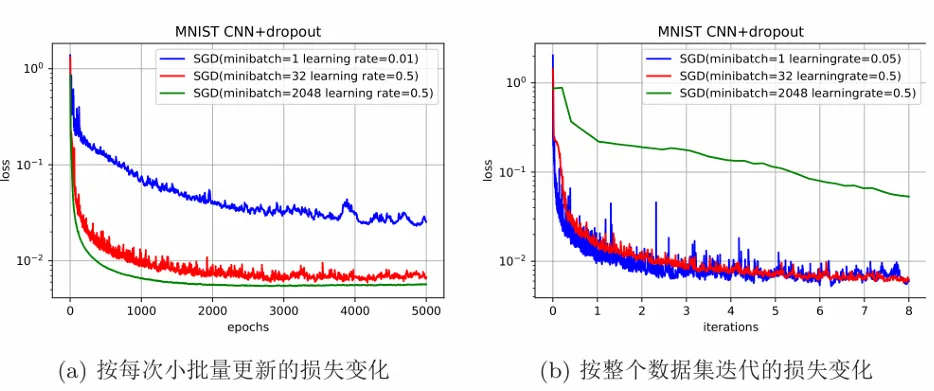
Epoch、Batch、Learning Rate 设置
- 一般规律:当 Batch Size 增加时,Learning Rate 也应该相应地增加。
- 迭代次数: 迭代次数 per epoch = 训练集 大小 / batch_size
| 超参数 | 作用 | 设置策略 | 经验值/范围 |
|---|---|---|---|
| Batch Size | 一次参数更新使用的样本数 | 在GPU内存允许下尽可能大;小批量可能泛化更好 | 32, 64, 128 |
| Learning Rate | 参数更新的步长 | 最重要,必须实验搜索;与Batch Size正相关 | Adam: ~3e-4; SGD: 0.01-0.1 |
| Epoch | 完整遍历数据的次数 | 不要手动设死,使用早停技术 | 由早停的 patience 参数间接控制 |
- 根据GPU内存,设定 batch_size=64 。
- 进行学习率搜索,找到最佳初始 learning_rate 。
- 设置一个很大的总 epoch 数(如 200),但配合早停( patience=20 )和学习率调度(如 Cosine Annealing )来实际控制训练过程。
- 如果后来调整了 batch_size (比如增大到 128),记得将 learning_rate 也相应增大(比如翻倍)。
动态学习率 (Dynamic Learning Rate)指的是在训练过程中,根据预设的策略或模型表现动态 调整学习率。此外学习率衰减 (Learning rate decay)是⼀种常⻅的动态学习率策略。随着训 练的进⾏,学习率会逐步减⼩。这有助于模型在训练初期快速收敛,并在后期更精细地微调参 数,避免震荡。
⾃适应学习率 (Adaptive Learning Rate)指的是⼀类更先进的优化算法,它们可以为每个参数 ⾃动调整其学习率。这意味着不同的参数可能有不同的学习率。
- Adagrad:为稀疏参数提供更⼤的学习率。
- Adadelta:是对Adagrad的改进,解决了其学习率持续衰减的问题。
- RMSprop:也是对Adagrad的改进,通过使⽤指数加权移动平均来解决学习率持续衰 减的问题。
- Adam:它结合了RMSprop和Momentum,是最受欢迎的⾃ 适应学习率优化器之⼀。
Dropout
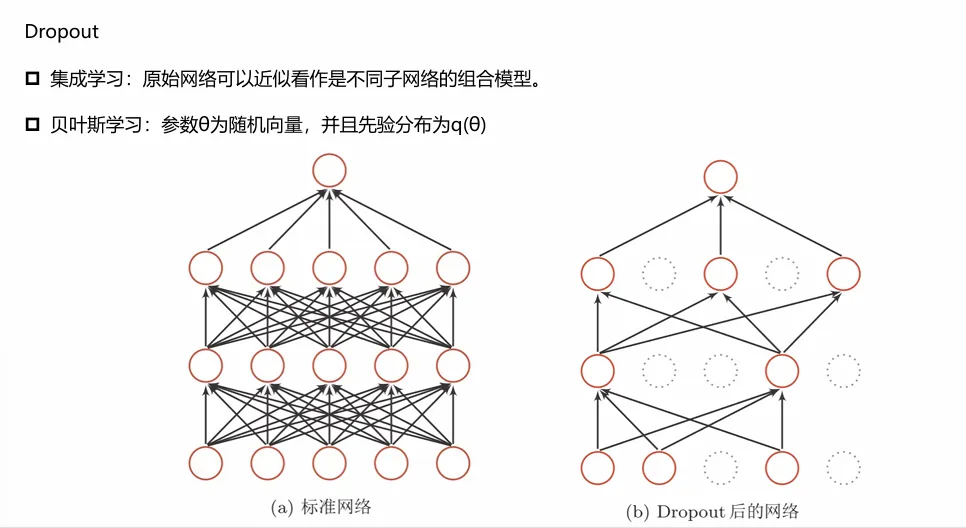
Dropout 是⼀种⽤于深度学习的正则化技术,旨在防⽌模型过拟合。它的⼯作原理是在训练过 程中,以⼀定的概率随机地“丢弃”(即将其激活值设置为零)神经⽹络中的⼀部分神经元。这 迫使⽹络不能过度依赖任何特定的神经元,从⽽学习到更具鲁棒性和泛化能⼒的特征。
在测试阶段,所有的神经元都会被激活。为了补偿训练时神经元数量的减少,需要对所有神经 元的权重进⾏缩放。通常的做法是将训练好的权重乘以丢弃概率的倒数(例如,如果丢弃概率 为0.5,则权重乘以0.5),以确保测试时的输出与训练时⼤致处于同⼀数量级。
调参经验
在大多数情况下都有效的“最佳实践”或“技巧”。它们能显著提升模型性能、加速收敛并防止过拟合。
- ✓ 用 ReLU 作为激活函数:默认选择。计算简单,能有效缓解梯度消失问题(在正区间)。注意可能出现的“Dead ReLU”问题,其变体如Leaky ReLU、PReLU可作备选。
- ✓ 分类时用交叉熵作为损失函数:分类任务的黄金标准。它比传统的均方误差(MSE)对于分类问题在数学上更合理,梯度更大,学习速度更快。
- ✓ SDG+mini-batch:最基础的优化算法组合。使用小批量随机梯度下降,在计算效率和梯度稳定性之间取得了最佳平衡。现在是更高级优化器(如Adam)的基础。
- ✓ 每次迭代都重新随机排序:在每个Epoch开始前打乱数据顺序,可以防止模型学习到因数据顺序带来的偏差,让训练过程更稳定。
- ✓ 数据预处理(标准归一化):至关重要的一步。将输入数据减去均值再除以标准差,使其均值为0,方差为1。这使优化地形更平滑,加速收敛,是所有模型的第一步。
- ✓ 动态学习率(越来越小):学习率调度。训练初期用较大学习率快速下降,后期用较小学习率精细调参。常见策略:Step Decay、Cosine Annealing等。
- ✓ 用 L1 或 L2 正则化(跳过前几轮):通过对大权重进行惩罚来防止过拟合。L2更常用。“跳过前几轮”意味着训练开始时先不加正则化,让模型自由探索,后期再加入约束进行精细化。
- ✓ 逐层归一化:尤其是Batch Normalization。它对每一层的输入进行归一化,可以极大地改善损失函数的凹凸性,允许使用更大的学习率,减少对初始化的依赖,并有一定正则化效果。是训练深层网络的“神器”。
- ✓ dropout:一种强大的正则化技术。随机让一部分神经元失活,强迫网络不依赖于任何单个神经元,让模型更加鲁棒。相当于训练了多个子模型并集成。
- ✓ 数据增强:从现有数据中创建新的训练样本(如图像的旋转、裁剪、变色)。相当于免费扩大了数据集,是防止过拟合、提升模型泛化能力最有效的手段之一。
超参数
这部分是需要在训练前手动或自动设定的参数,它们决定了模型的结构和训练方式。找到最优组合是调参的核心任务。
- 层数:模型的深度。通常越深能力越强,但也更难训练(梯度消失/爆炸、过拟合)。
- 每层神经元个数:模型的宽度。宽度和深度共同决定了模型的容量(拟合能力)。
- 激活函数:如ReLU、tanh、sigmoid等,为网络引入非线性。ReLU是默认起点。
- 学习率(以及动态调整算法):最重要的超参数。控制参数更新的步长。其调度策略(如衰减率、步长)本身也是超参数。
- 正则化系数:控制L1/L2正则化惩罚项的强度。权衡拟合训练数据和保持模型简单。
- mini-batch 大小:影响梯度下降的方向和稳定性,也与学习率设置紧密相关。
优化方法
这部分是如何高效地搜索超参数最优组合的策略。由于超参数空间巨大,穷举(网格搜索)效率低下,需要更智能的方法。
- 网格搜索:最基础的方法。为每个超参数设定一个候选值列表,尝试所有可能的组合。简单但计算成本极高,不推荐用于深度学习。
- 随机搜索:比网格搜索更高效。从每个超参数的分布中随机采样值进行尝试。实践表明,它能找到更好的配置,因为更重要的超参数有机会得到更充分的探索。
- 贝叶斯优化:更高级的自动化调参方法。它构建一个概率模型(代理模型)来预测哪些超参数组合可能表现好,并基于此选择下一组要尝试的参数。用历史信息指导未来搜索,效率远高于随机搜索。
- 动态资源分配:核心思想是“早停”。不对所有超参数组合都训练到最大epoch,而是快速评估哪些组合更有潜力,只将计算资源分配给这些有希望的组合。例如Hyperband算法。
- 神经架构搜索:自动化机器学习的终极目标之一。使用强化学习、进化算法或其他优化策略来自动搜索最佳的网络结构(即超参数中的“层数”、“每层神经元个数”等),而不仅仅是调参。

Pytorch 使用案例
1. 模型定义
这一步的目标是:定义网络的结构,即数据从输入到输出要经过哪些层(Layer)。
- 做什么:
- 创建一个类,继承自 torch.nn.Module (PyTorch) 或 tf.keras.Model (TensorFlow/Keras)。
- 在 __init__ 方法中定义网络所需要的所有层(如全连接层 Linear ,卷积层 Conv2d ,循环层 LSTM , dropout 层等)。
- 在 forward (PyTorch) 或 call (TensorFlow) 方法中定义数据的前向传播路径,即各层如何连接。
- 代码示例 (PyTorch):
import torch.nn as nnimport torch.nn.functional as Fclass MyNeuralNet(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(MyNeuralNet, self).__init__()# 定义网络层self.fc1 = nn.Linear(input_size, hidden_size) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 隐藏层到输出层# 注意:这里没有使用 softmax,因为损失函数会包含它def forward(self, x):# 定义数据流向out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out- 为什么:这是构建模型的蓝图。它决定了模型的容量(能学习多复杂的关系)和结构。
2. 模型初始化,设置优化器,设置损失函数
在模型定义好后,需要实例化它,并为其配置训练所需的“工具”。
- a) 模型初始化:
- 做什么:创建模型对象,并将其移动到GPU(如果可用)。
- 代码:
# 超参数input_size = 784 # 例如,28x28的MNIST图像展平后的大小hidden_size = 500num_classes = 10learning_rate = 0.001# 初始化模型model = MyNeuralNet(input_size, hidden_size, num_classes)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device) # 将模型参数和缓冲区移动到GPU- b) 设置损失函数:
- 做什么:选择一个衡量模型输出与真实标签之间差异的函数。损失函数的选择取决于任务类型。
- 常见选择:
- 分类任务:交叉熵损失 nn.CrossEntropyLoss (同时包含Softmax)
- 二分类任务:二元交叉熵损失 nn.BCEWithLogitsLoss (包含Sigmoid)
- 回归任务:均方误差损失 nn.MSELoss
- 代码:
criterion = nn.CrossEntropyLoss() # 用于多分类- c) 设置优化器:
- 做什么:选择一个算法来更新模型的权重,以最小化损失函数。它需要传入模型的参数 model.parameters() 和学习率。
- 常见选择:
- torch.optim.Adam :最常用、效果不错的默认选择,自适应学习率。
- torch.optim.SGD :通常配合动量使用 (momentum=0.9) ,需要更多调参但可能达到更好性能。
- 代码:
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 或者optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)- 为什么:优化器和损失函数共同定义了如何根据模型的错误来更新模型。
3.模型训练:Training Loop 和 Evaluate Model
这是核心循环,通常包含多个Epoch,每个Epoch又包含训练和评估两个阶段。
Training Loop (训练循环)
- 做什么:让模型在训练数据上学习。
- 步骤:
- 设置为训练模式: model.train() 。这会启用Dropout、BatchNorm等层的训练行为。
- 遍历数据加载器 ( DataLoader ),获取一个batch的数据和标签。
- 将数据移动到GPU。
- 前向传播:将数据传入模型,得到预测输出。
- 计算损失:用损失函数比较预测输出和真实标签。
- 反向传播: loss.backward() 。计算损失相对于每个参数的梯度。
- 更新参数: optimizer.step() 。优化器根据梯度更新模型权重。
- 清空梯度: optimizer.zero_grad( ) 。为下一个batch的计算做准备。
- 代码:
num_epochs = 10
total_steps = len(train_loader) # train_loader 是您的训练数据加载器for epoch in range(num_epochs):model.train() # 设置为训练模式for i, (images, labels) in enumerate(train_loader):# 移动数据到设备images = images.to(device)labels = labels.to(device)# 前向传播 -> 计算损失outputs = model(images)loss = criterion(outputs, labels)# 反向传播与优化optimizer.zero_grad() # 清空历史梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新参数# ... 可以在这里打印一些日志信息
Evaluate Model (模型评估)
- 做什么:在验证集/测试集上评估模型的性能,检查是否过拟合,并选择最佳模型。
- 步骤:
- 设置为评估模式: model.eval() 。这会禁用Dropout、并固定BatchNorm的统计量。
- 用 torch.no_grad() 包裹:禁止计算梯度,大幅节省内存和计算资源。
- 遍历验证/测试数据加载器,进行前向传播,计算损失和准确率等指标。
- 保存性能最好的模型。
- 代码:
# 在训练循环的每个epoch结束后,进行评估model.eval() # 设置为评估模式with torch.no_grad(): # 禁用梯度计算correct = 0total = 0for images, labels in test_loader: # test_loader 是您的测试数据加载器images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1) # 获取预测类别total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Epoch [{epoch+1}/{num_epochs}], Test Accuracy: {100 * correct / total} %')# 可以在这里保存准确率最高的模型# torch.save(model.state_dict(), 'best_model.pth')
完整流程总结
- 定义模型结构(用什么层,如何连接)。
- 实例化模型,并为其配备优化器(如何更新)和损失函数(如何衡量错误)。
- 循环进行:
- 训练模式:用训练数据计算梯度并更新权重。
- 评估模式:用测试数据评估性能,不更新权重。
- 根据评估结果决定是否停止训练或保存模型。