卷积神经网络(一):卷积神经网络基础
文章目录
- 卷积神经网络卷积基础
- 一、卷积操作
- 二、卷积后图片大小计算
- 三、卷积模块参数计算
- 1. 权重数量
- 2. 偏置数量
- 四、卷积乘法计算次数
- 五、分组卷积
- 六、感受野
- 七、膨胀卷积(空洞卷积)
- 八、卷积基本的算法实现
卷积神经网络卷积基础
一、卷积操作
- 本质:通过卷积核对输入数据进行滑动窗口计算,提取局部特征(如边缘、纹理)
- 过程:卷积核在输入上滑动,逐位置计算局部区域与卷积核的元素积之和
什么是卷积?直接看这一张图就知道了,卷积核对原图进行滑动卷积获取值后得到值,每一层就是一个卷积核卷积后的结果。(以下所有图片仅供学习参考)

二、卷积后图片大小计算
-
公式:输出大小 = (输入大小 + 2P - 卷积核大小) / S + 1
- P:padding(边缘填充像素数)
- S:stride(步幅,每次滑动像素数)
- 规则:结果为小数时向下取整(floor)
通常步长 stride 为多少,则图片缩小多少倍。
-
示例:
输入 64×64,卷积核 3×3,S=1,P=0 → (64+0-3)/1+1=62 → 输出 62×62
三、卷积模块参数计算
1. 权重数量
- 常规卷积:
权重数 = 卷积核宽 × 卷积核高 × 输入通道数 × 输出通道数
例:3×3 核,输入 3 通道,输出 8 通道 → 3×3×3×8=216 - 全连接层对比:
权重数 = 输入数量 × 输出数量(参数规模通常远大于卷积)
2. 偏置数量
- 公式:偏置数 = 输出通道数(每个输出通道对应 1 个偏置)
例:输出 8 通道 → 8 个偏置
四、卷积乘法计算次数
- 单步卷积:卷积核体积 = 卷积核宽 × 卷积核高 × 输入通道数
- 单个卷积核:单步乘法次数 × 水平滑动次数 × 竖直滑动次数
(水平 / 竖直滑动次数 = 对应维度的输出大小) - 多个卷积核:单个卷积核乘法次数 × 输出通道数(卷积核数量 = 输出通道数)
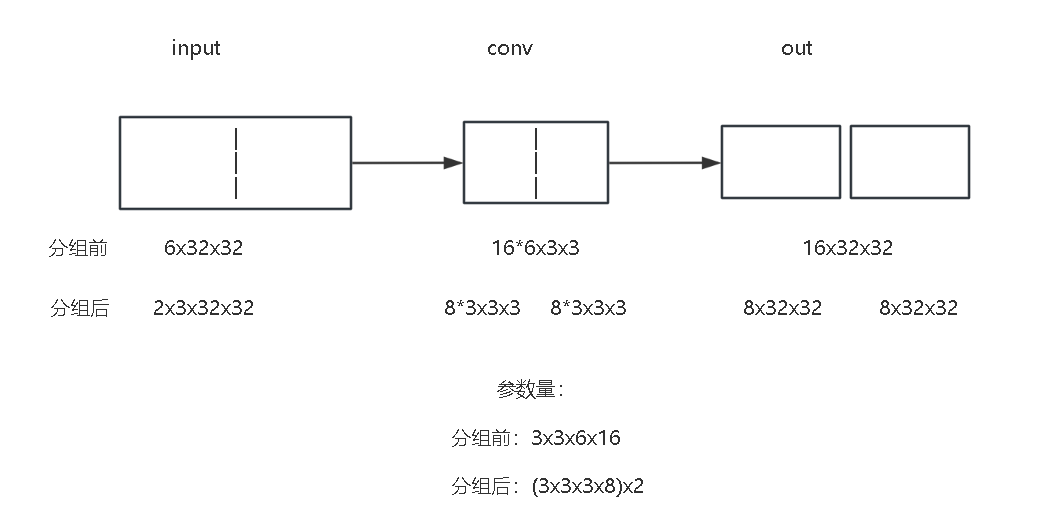
五、分组卷积
- 定义:将输入通道分成若干组,每组独立与对应输出通道的卷积核计算
- 权重数量:
(卷积核宽 × 卷积核高 ×(输入通道数 / 分组数)×(输出通道数 / 分组数)) × 分组数 - 可以计算得出:减少参数和计算量,增强通道独立性
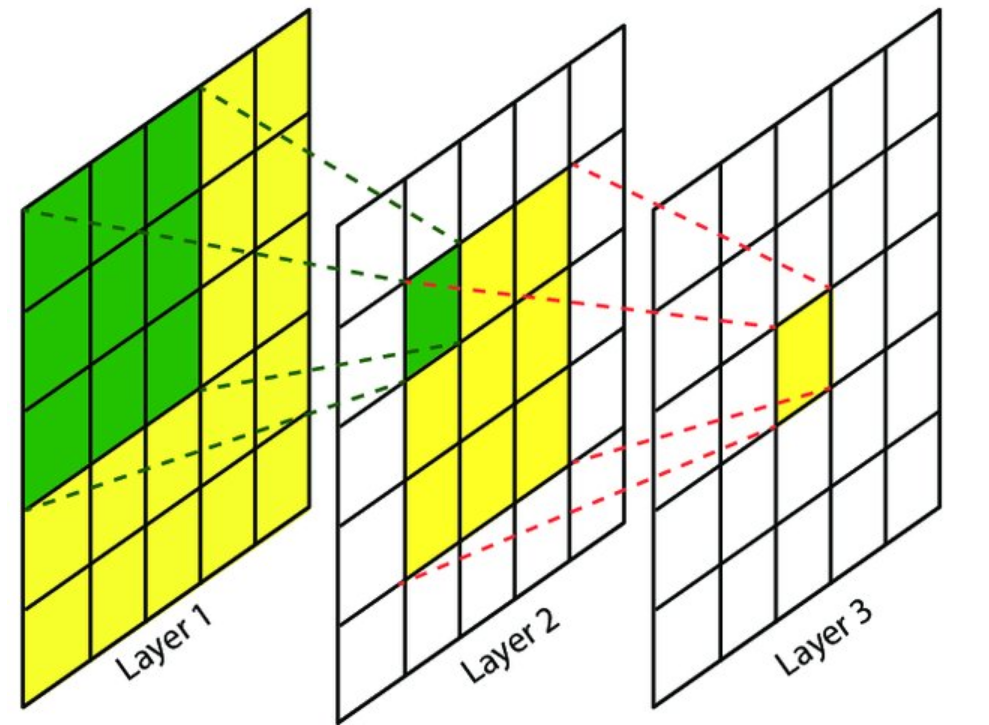
六、感受野
- 定义:输出特征图上一个像素对应输入图像的区域大小
- 计算:从后往前迭代,依赖卷积核大小、步幅和前层感受野
- 意义:深层特征对应更大感受野,捕捉全局信息
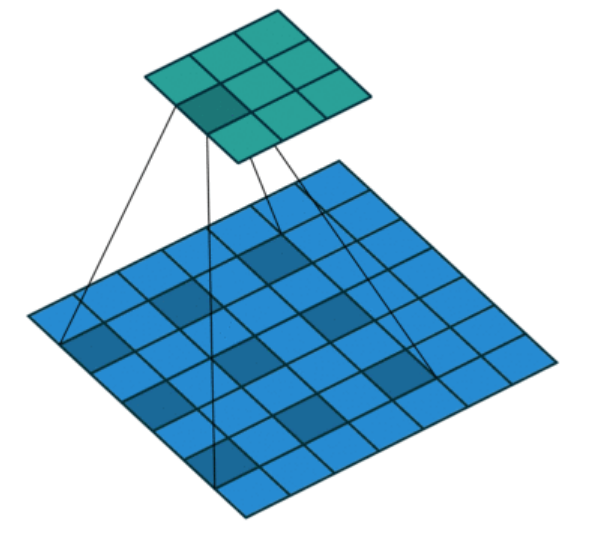
七、膨胀卷积(空洞卷积)
- 定义:卷积核元素间插入空洞(零填充),扩大感受野而不增加参数
- 有效核大小:k + (k-1)×(d-1)(k 为原核大小,d 为膨胀率)
- 应用:语义分割(无需下采样即可获得大感受野)
- 例如 kernel_size=3, dilation=2, 则感受野变为 5x5,从而计算卷积后图片大小时,将 5x5 作为卷积核大小运算
八、卷积基本的算法实现
import torch
from torch import nnclass Convolution(nn.Module):def __init__(self, in_channel, out_channel, kernel_size):super().__init__()self.in_channel = in_channelself.out_channel = out_channelself.kernel_size = kernel_size if isinstance(kernel_size, tuple) else (kernel_size, kernel_size)# 初始化卷积核(输出通道×输入通道×核高×核宽)self.kernels = nn.Parameter(torch.randn(out_channel, in_channel, *self.kernel_size))def forward(self, x):N = x.shape[0] # 批次大小H, W = x.shape[2:] # 输入高、宽kernel_h, kernel_w = self.kernel_size# 计算输出尺寸row_count = W - kernel_w + 1 # 水平滑动次数col_count = H - kernel_h + 1 # 竖直滑动次数out = torch.zeros(N, self.out_channel, row_count, col_count)# 逐通道、逐位置卷积计算for i in range(self.out_channel):kernel = self.kernels[i] # 取第i个卷积核for _y in range(col_count):for _x in range(row_count):# 提取输入局部区域inp = x[:, :, _y:_y+kernel_h, _x:_x+kernel_w]# 元素积求和(卷积操作)out[:, i, _y, _x] = (inp * kernel).flatten(start_dim=1).sum(dim=1)return out# 测试
tensor_img = torch.rand(3, 64, 64) # 3通道,64×64
conv = Convolution(3, 8, 3) # 3→8通道,3×3核
output = conv(tensor_img.unsqueeze(0).expand(5, -1, -1, -1)) # 批次5
print(output.shape) # 输出:torch.Size([5, 8, 62, 62])(64-3+1=62)