Deeplizard 深度学习课程(四)—— 模型构建
前言
我们正在利用pytorch实现CNN。主要分为四个小部分:数据预处理、神经网络pytorch设计、训练神经网络 和 神经网络实验。
本节主要是构建模型,模型即网络,我们希望近似一个 能够将输入图像 映射到 正确输出类的函数。
1. 面向对象编程及应用
1.1 面向对象知识回顾
面向对象编程 是python最显著的特点,它让代码模块化封装,其中最重要的是区分 类(class) 和 对象(object) ,类是对一个事物的描述或者蓝图,而对象是事物本身。简单来说就是 class 是 object 的一个模板。
当我们创建一个类的对象时,我们将该对象称为实例。所有实例都具有两个核心:方法(method)和属性(attribute)。我们可以理解 方法是对象的行为,而属性是对象的特征。
# 构建一个简单的蜥蜴类,演示 类 如何封装代码和数据class Lizard: def __init__(self, name): # class constructorself.name = name def set_name(self, name): # methodself.name = name
- 在Python中,__init__方法通常被称为类的构造器(constructor),它是一个特殊的方法,用于在创建对象时初始化类的实例。
- self 参数代表类实例本身(谁调用,就是谁),该参数在调用时自动传递,无需我们指定
# 构造一个类实例,看下区别lizard = Lizard('deep') # 调用类构造器(初始化)
print(lizard.name)
# 输出:deeplizard.set_name('lizard') # 调用类方法
print(lizard.name)
# 输出:lizard1.2 面向对象在pytorch中的应用
| Pytorch | 作用 | 备注 |
torch.nn 包 | pytorch的神经网络库 | import torch.nn as nn |
| nn.Module 类 | 所有包含层的神经网络模块 的基类 | 每个layer由 transform(代码) 和 weight(权重) 构成 |
| forward( ) 方法 | tensor通过网络向前传播 | 每个 nn.Module 实例都有一个forward方法,它是实际的transformation |
| nn.functional 包 | 实现forward方法时,会用到的函数操作 |
有了这些,我们可以知道在 PyTorch 中构建神经网络的步骤:
step1 创建一个扩展的
nn.Module基类step2 在类构造函数中,使用
torch.nn中的预先构建的层 将layer定义为类属性。step3 使用layer属性以及
nn.functionalAPI 中的操作 来定义网络的前向传播。
创建一个简单的神经网络例子:
# 一个简单的神经网络的例子
import torch.nn as nnclass Network(nn.Module): # 继承nn.Module基类def __init__(self):super().__init__() # 调用父类(nn.Module)的init,确保父类的属性被正确初始化self.layer = None # 将layer定义为类属性def forward(self,t):t = self.layer(t) # 通过定义的layer对tensor t进行转换,传递return t# self.layer = None 这里可以替换为具体的层,这些layer都定义为类属性
# 卷积层
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
# 全连接层/线性层
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
# 输出层
self.out = nn.Linear(in_features=60, out_features=10)1.3 实例化网络及override
我们可以对1.2中的网络进行实例化,得到一个名为network的object。然后print,输出如下
network = Network()
print(network)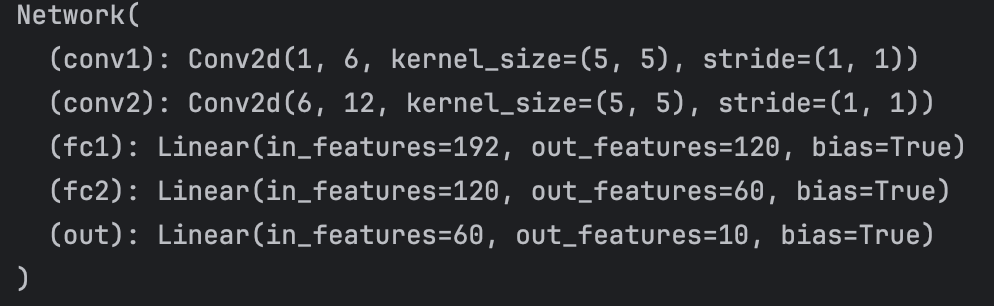
这个输出为一串字符信息,描述了网络架构和参数。之所以有这样的功能,是因为这个网络继承了 nn.Module 中的 __repr__(self) 函数。
当我们扩展一个类时,我们会得到这个类的所有功能,我们可以添加额外的函数去补充其他功能,也可以重写(override)函数去覆盖现有功能。
例如,如果在上述网络中,加入以下函数,重新print,结果就会改变。
def __repr__(self):return "lizardnet"
2. CNN layer —— 网络架构
2.1 Linear 类
上面在定义 layer 的时候其实也是用扩展PyTorch类的办法实现的,我们可以简单看一下 Linear 类的源码。
class Linear(Module):def __init__(self, in_features, out_features, bias=True):super(Linear, self).__init__()self.in_features = in_featuresself.out_features = out_features# 权重tensorself.weight = Parameter(torch.Tensor(out_features,in_features))if bias:self.bias = Parameter(torch.Tensor(out_features)else:self.register_parameter('bias',None)self.reset_parameter()# 前向函数def forward(self, input):return F.linear(input, self.weight, self,bias)对于每个layer,内部封装了两个主要项目—— weight 属性 和 forward 函数。
其中,每个layer的权重(weight)是保存在layer类中的属性,Module 父类会跟踪每层内的权重tensor,因此该属性会随着网络的训练进行更新。由于我们在构建网络过程中,会实例化layer类,因此layer会继承该属性,能够在训练中跟踪并更新参数。
2.2 超参数
- parameter vs argument
parameter 在函数定义中用作占位符,可以理解为参数的名称 或者 位于函数内部的局部变量 ;argument 是 传递给函数的实际值。
- Hyperparameters (超参数) vs Data dependent hyperparameters(数据依赖型超参数)
超参数(hyperparameters)指的是需要在构建网络之初就要手工设定的参数,而且这些参数不会像权值一样随着模型的训练进行优化,需要我们基于试验选择,会直接影响model的性能。
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)以卷积层为例,可以看到我们有三个 parameters ,其中后两个为 hyperparameter,具体含义如下
| parameters | 作用 |
kernel_size 超参数 | 设置 filter 的像素尺寸,一般为n * n ,所以指定一个数即可 |
| out_channels 超参数 | 又称为 feature map,指 filter 的个数(种类) |
| in_channels 数据依赖型超参数 | 输入卷积层的通道数 |

数据依赖型超参数(Data dependent hyperparameters)是指其值依赖于数据的参数。
以下面这个网络架构为例,每个层的 in_channel 都与 上一层的 out_channel 有关,其中黄框是因为 从卷积层衔接到线性层(原本的高阶张量需要 flatten 为一阶张量),输出了12个 feature map,每个map的大小为 4*4(有池化层影响)。
我们可以发现,两个红框,即:第一层网络的 in_channel 与输出层的 out_channel,是与我们的数据有关的超参数。原因是:输入图像为灰度图像,所以第一层网络的 in_channel 为1,而最终需要分为10个类别,所以输出层的 out_channel 为10。

2.3 可学习参数
可学习参数(learnable parameter)是在训练过程中学习的参数。它通常以一种任意的值开始,在训练过程中迭代更新,目的是使得损失函数最小化。
- 访问layer
之前说过,权值保存在每一层的内部,并且随着网络的训练而更新。因此我们先访问layer,可以用1.3中的 print 或者 使用点表示法访问对象的属性和方法。
> print(network)
Network((conv1): Conv2d(in_channels=1, out_channels=6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(in_channels=6, out_channels=12, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=192, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=60, bias=True)(out): Linear(in_features=60, out_features=10, bias=True)
)
> print(network.conv1)
Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))> print(network.fc1)
Linear(in_features=192, out_features=120, bias=True)对于卷积层,stride这个参数我们之前没有介绍,这个参数在定义layer时可以设置,这里是用的是默认值,是指 卷积操作后 filter 滑动的距离。(1,1) 是指每次向右移动1个像素,扫面完一行之后再回到最左边并下移1个像素。
对于线性层,这里有一个额外的参数 bias,用于控制是否在计算中添加偏置项(bias term),即 y=Wx +b ,W为可学习参数,b就是所谓的偏置项。
- 访问layer中的weight
其实1.3中的__repr__方法其实提供了每一层的字符串表示,在print(network)时,网络类只是将所有的表示整合为一个整体输出,所以要访问layer中的weight,我们仍可以使用点表示法。
print(network.conv1.weight)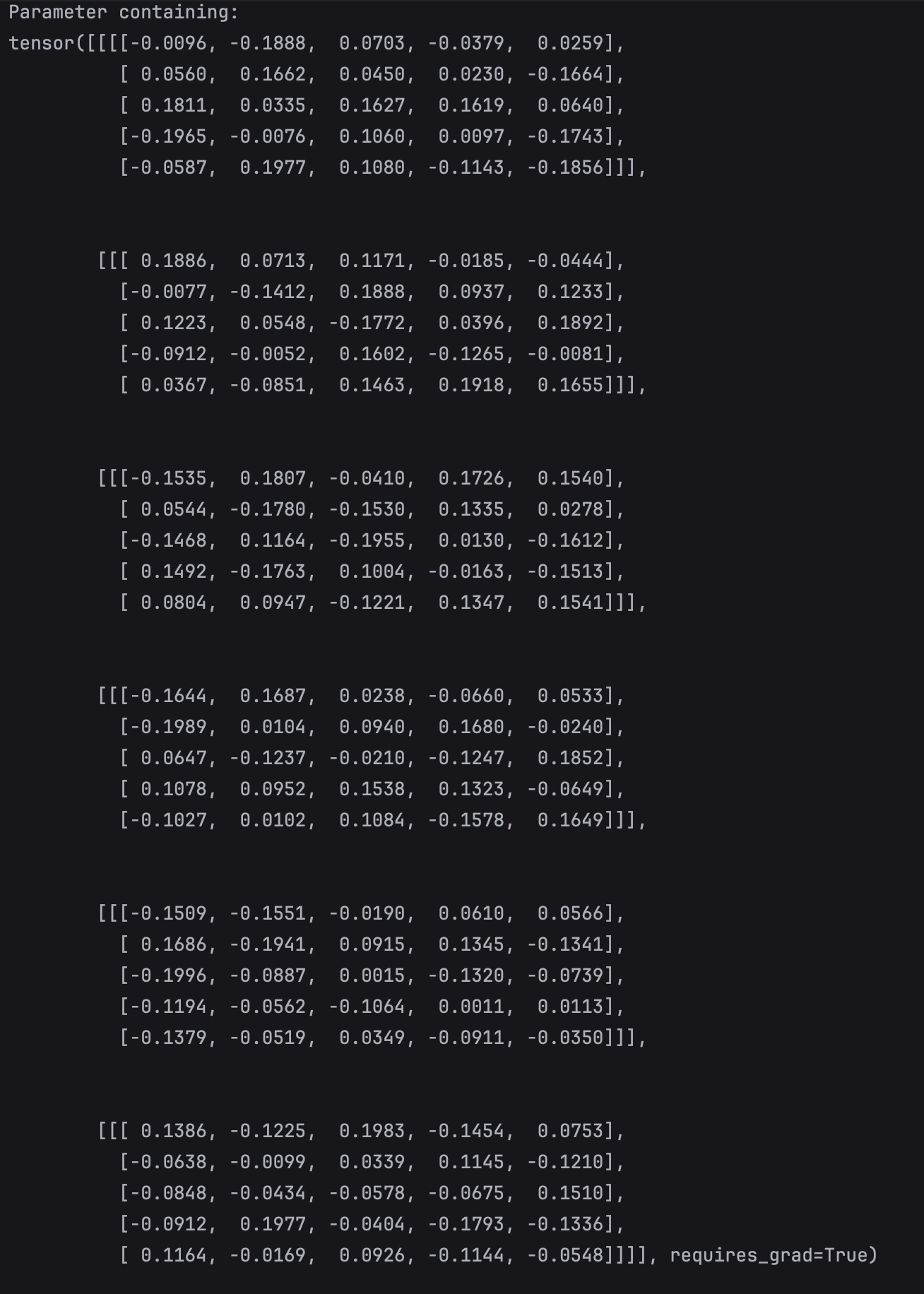
与常规tensor的输出不同的是,在最顶端有一个 “ Parameter containing:” 的字样,这是因为这里的 tensor 是一种可以不断学习并更新的 special tensor。为了追踪网络层中的参数变化,pytorch 中有一个 Parameter 类,这个类扩展了 torch.Tensor 类,网络层中的参数 special tensor 就是Parameter 类的实例化。
Parameter类 中重写了 __repr__ 方法。__repr__ 方法 是 Python 中的一个 “魔术方法” ,用于定义一个对象的“官方字符串表示”,也就是对象输出时的样子。
def __repr__(self):return 'Parameter containing:\n' + super(Parameter, self).__repr__()# 添加了一个前缀:"Parameter containing:\n"
# super().__repr__() 调用了父类的__repr__()方法,因为Parameter继承自Tensor类,所以实际调用的是Tensor类的__repr__()方法- layer weight shape
conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5)
# 对于这个卷积层,有一个颜色通道,包含6个5*5的滤波器,产生6个输出通道print(network.conv1.weight.shape)
# 输出:torch.Size([6, 1, 5, 5])可以看到,conv1层中的weight是一个形状为 [6, 1, 5, 5] 的tensor,说明一共有 6个 filter(6个输出channel),每个filter深度 / 层数为1(1个输入channel),每个filter 为 5*5 的形状。
# fc1 = nn.Linear(in_features=192, out_features=120)print(network.fc1.weight.shape)
# 输出:torch.Size([120, 192])对于全连接层,在此之前会先将tensor其展平为 192 * 1 ,然后利用size为 [120, 192] 的权重矩阵(Weight Matrix),就可以将输出映射为 120 * 1 的shape
access network parameter
for name,param in network.named_parameters():print(name,'\t\t',param.shape)# 输出:
# conv1.weight torch.Size([6, 1, 5, 5])
# conv1.bias torch.Size([6])
# conv2.weight torch.Size([12, 6, 5, 5])
# conv2.bias torch.Size([12])
# fc1.weight torch.Size([120, 192])
# fc1.bias torch.Size([120])
# fc2.weight torch.Size([60, 120])
# fc2.bias torch.Size([60])
# out.weight torch.Size([10, 60])
# out.bias torch.Size([10])需要注意的是,每一层我们都有一个权重向量和bias向量,默认情况下,每一层都有偏置。
即:y = act_func (W⋅x +b) 或者 y = act_func ( Conv2D(x,W) + b ) , b就是其中的偏置。
2.4 call方法 与 forward函数
在线性层中,我们的 input 会和 weight matrix 做一个矩阵乘法,进而完成矩阵的变换,得到想要的output。例如下面使用的 .matmul( ) 函数
import torch
import torch.nn as nnin_features = torch.tensor([1,2,3,4], dtype=torch.float32)weight_matrix = torch.tensor([[1,2,3,4],[2,3,4,5],[3,4,5,6]
], dtype=torch.float32)weight_matrix.matmul(in_features)# 输出:tensor([30., 40., 50.])但是在pytorch的许多模型中,我们可以直接用 output = model(xxx) 来调用forward函数进行前向传播(如下),这里的权重矩阵就存在于pytorch的线性层中。
import torch
import torch.nn as nnfc = nn.Linear(in_features=4, out_features=3)
input = torch.tensor([1,2,3,4],dtype=torch.float32)
output = fc(input)# 输出:tensor([ 2.5692, 1.9266, -0.3958], grad_fn=<ViewBackward0>)
其原因就是因为定义了call方法,可以直接便捷的调用layer中的forward函数。call方法的作用是让类在实例化之后,自动调用__call__方法,例如下述线性层实例化后,在使用时会自动调用call方法中定义的函数,进而调用forward函数。
下面我们在output = fc(input) 处进行断点测试。

首先,可以看到在nn.Module中,__call__方法首先调用了_wrapped_call_impl 这个函数,

然后,这里会输入fc以及input的信息,并选择调用 _compiled_call_impl 或者 _call_impl 这两个函数之一,这里是调用了后者。
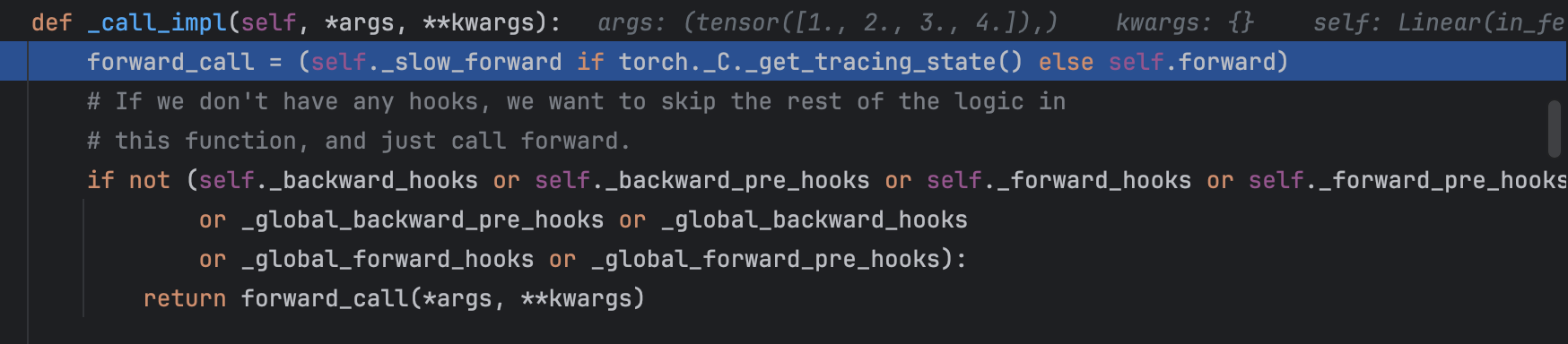
进一步我们不难发现,这里 forward_call 会调用 _slow_forward 或者 self.forward(), 而_slow_forward中也会调用 self.forward()。
另外,我们也可以在这个案例中理解__call__方法:

2.5 CNN Forward方法 代码实现
在之前的1.2/1.3中,我们通过扩展nn.Module基类,创建了我们自己定义的网络。在我们的类构造函数中,我们将网络的层定义为类属性;现在我们希望定义前向传播函数(该函数接受一个tensor作为输入,然后输出一个tensor,相当于调用自己定义的layer进行tensor转换,以获得输出预测)
import torch
import torch.nn.functional as Fclass Network(nn.Module):def __init__(self):super(Network,self).init() # 调用父类(nn.Module)的init,确保父类的属性被正确初始化self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)self.fc1 = nn.Linear(in_features=12*4*4, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=60)self.out = nn.Linear(in_features=60, out_features=10)def forward(self,t)# (1)input layert = t #一般默认不写# (2)hidden conv1 layert = self.conv1(t)t = nn.ReLu(t) # 激活层t = F.max_pool2d(t,kernel_size=2,stride=2) # 池化层 # kernel_size池化窗口(滤波器大小)2*2# stride 步长,每次滑动距离# (3)hidden conv2 layert = self.conv2(t)t = nn.ReLu(t)t = F.max_pool2d(t,kernel_size=2,stride=2)# (4)hidden linear1 layert = t.reshape(-1,12*4*4) # 过线性层之前,需要先展平,-1是会自动计算,这里相当于重塑为(1,192)t = self.fc1(t) t = nn.ReLu(t)# (5)hidden linear2 layert = self.fc2(t) t = nn.ReLu(t)# (6)output layert = self.out(t)# t = F.softmax(t,dim=1) # softmax:将原始的分数(logits)转换为合为1的概率分布# dim 指定对行(dim=1)还是列(dim=0)进行操作return t
这里有几个需要注意的地方,forward函数更像是在描述数据传输的过程。
- 在卷积后,一般需要接一个池化的操作,去进一步压缩特征,这会影响到tensor的形状
- 过线性层之前,需要先展平tensor
- 最后输出层一般会接一个softmax进行多分类任务,但这里我们不需要,因为我们采用的损失函数是交叉熵损失函数,即 nn.functional 包中的
F.cross_entropy(),这个函数自动对输入值先进行一步 softmax 操作。
两次卷积对特征shape的影响:
卷积操作不会补零(zero padding),5*5 的 filter 按默认stride=1滑动,会变成 24*24;再经过一个 2*2 且 stride=2 的 max pooling 变成 12*12。再进下一层卷积层,经卷积操作变成 8*8,再经池化就变成了 4*4
2.6 CNN 图像批处理代码实现(完整)
# 一个简单的神经网络的例子
import torch
import torch.nn as nn
import torch.nn.functional as Fimport torchvision
import torchvision.transforms as transformstorch.set_printoptions(linewidth=120) # 更改PyTorch的全局打印设置, 横向最多120字符class Network(nn.Module): # 继承nn.Module基类def __init__(self):super().__init__() # 调用父类(nn.Module)的init,确保父类的属性被正确初始化# 卷积层self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)# 全连接层/线性层self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)self.fc2 = nn.Linear(in_features=120, out_features=60)# 输出层self.out = nn.Linear(in_features=60, out_features=10)def forward(self,t):t = self.conv1(t)t = F.relu(t)t = F.max_pool2d(t, kernel_size=2, stride=2)t = self.conv2(t)t = F.relu(t)t = F.max_pool2d(t, kernel_size=2, stride=2)t = t.reshape(-1,12*4*4)t = self.fc1(t)t = F.relu(t)t = self.fc2(t)t = F.relu(t)t =self.out(t)return t# 网络实例化
network = Network()# 导入训练数据
train_set = torchvision.datasets.FashionMNIST(root = './data', # 数据下载位置train = True, # 是否为训练集download = True, # 是否下载transform = transforms.Compose([ # 对dataset元素执行tensor转换操作的组合transforms.ToTensor()])
)# 关闭梯度计算
torch.set_grad_enabled(False) # 是否进行梯度跟踪,以便执行反向传播来更新模型参数。一般训练时打开,推理时关闭# # 单个数据处理
# sample = next(iter(train_set))
# image, label = sample
# output = network(image.unsqueeze(0)) # unsqueeze(0) 相当于补充 batch_size=1,shape:(1,28,28) -> (1,1,28,28)
# print(output)# 定义DataLoader进行批处理
dataloader = torch.utils.data.DataLoader(train_set, batch_size = 10, shuffle = True)
batch = next(iter(dataloader)) # 从 data_loader 提取出一个 batch
images, labels = batch
print(images.shape)
print(labels.shape)# 进行预测
preds = network(images)
print(preds.shape) # 输出:torch.Size([10, 10])# 结果分析
print(preds.argmax(dim=1)) # 返回每一行最大值对应的索引,对应预测结果
print(labels) # 每个样本的实际标签
# tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# tensor([0, 0, 9, 7, 8, 0, 2, 1, 6, 8])# 对上面两者进行比较
print(preds.argmax(dim=1).eq(labels))
print(preds.argmax(dim=1).eq(labels).sum())
# tensor([ True, True, False, False, False, True, False, False, False, False])
# tensor(3)# 也可以把这个定义成一个函数来进行调用
def get_num_correct(preds, labels):return preds.argmax(dim=1).eq(labels).sum().item()