NVFP4量化技术深度解析:4位精度下实现2.3倍推理加速
大型语言模型的参数规模和复杂度持续增长,量化技术已成为优化推理效率的核心手段,这一点在消费级和企业级硬件部署中尤为关键。NVIDIA推出的NVFP4格式在众多量化方案中表现突出,其与Blackwell GPU架构的深度集成实现了显著的性能提升,同时保持了模型精度的稳定性。

本文将从技术角度深入分析NVFP4与主流4位量化方法(AWQ、AutoRound、bitsandbytes)的性能对比,并探讨在Blackwell GPU环境下采用NVFP4方案的实际价值。
通过对公开模型和自定义量化变体的全面测试,本文将在精度、模型大小和推理吞吐量等维度提供详实的评估数据。同时,我们将分享NVFP4模型在vLLM框架下的部署实践,并重点分析激活量化对性能优化的关键作用。
NVFP4技术原理:双重缩放机制的FP4量化
技术架构解析
NVFP4的详细技术实现可参考NVIDIA官方文档:Introducing NVFP4 for Efficient and Accurate Low-Precision Inference
Blackwell GPU架构原生支持多种数值精度格式,涵盖FP64、FP32/TF32、FP16/BF16、INT8/FP8、FP6到FP4的完整精度谱系。这种多精度支持为开发者提供了根据具体工作负载需求精确匹配计算精度的能力。
NVFP4作为Blackwell架构中最先进的FP4实现,采用了全新的微浮点标准设计,专门针对4位精度下的模型精度保持进行优化。
E2M1格式与数值表示
NVFP4基于极致紧凑的4位浮点格式E2M1构建,每个数值的4位分配如下:符号位1位(正负性)、指数位2位(数值量级)、尾数位1位(精度控制)。
这种格式的原生数值范围约为-6到+6,在没有额外缩放机制的情况下,这一范围显然无法满足LLM的数值需求。
双重缩放系统
NVFP4通过创新的双重缩放机制解决了数值范围限制问题:
微块级缩放(局部优化):系统将数值分组为16个元素的微块单位,每个微块共享一个E4M3格式的FP8缩放因子。相比传统的2次幂缩放方式(如MXFP4),E4M3格式支持分数倍缩放(1.5×、2.5×等),显著提升了缩放精度,使量化后的数值更接近原始分布。
张量级缩放(全局协调):针对数值分布跨度极大的张量,NVFP4在整个张量层面应用FP32高精度缩放因子。这一全局缩放确保了在数值差异悬殊的情况下,每个微块的FP8缩放依然能够发挥最佳效果。
双重缩放机制通过16值微块的精细FP8缩放与全张量FP32全局缩放的协同作用,大幅降低了量化舍入误差,保留了关键数值特征,使模型能够在4位精度下运行,且精度损失远低于早期FP4格式。
微块尺寸从MXFP4的32值缩减至16值,进一步增强了对异构张量数值的适应能力,有效防止了大数值对小幅但重要变化的掩盖效应。在实际计算中,微块内每个4位编码值xq通过公式x = xq × s重构,其中s为动态计算的E4M3缩放因子,该因子的选择以最小化块内误差为目标。
精度验证与基准测试
NVIDIA的官方基准测试验证了NVFP4的精度保持能力。DeepSeek-R1-0528模型从FP8到NVFP4的后训练量化结果显示,在七项评估任务中几乎没有性能退化:MMLU-Pro、GPQA Diamond、LIVECODEBENCH等基准测试的精度差异均控制在1%以内,SCICODE和Math-500则保持完全一致的结果。
AIME 2024基准测试中,NVFP4相比FP8提升了2%,但考虑到AIME测试的固有方差,这一差异并无统计学意义,实际表明两者性能相当。
内存效率与计算吞吐量优化
NVFP4的存储结构为每16值微块配置一个4位数值、一个共享FP8缩放因子以及每张量一个FP32缩放因子,平均每值占用约4.5位。虽然相比标准INT4量化模型(通常采用128的块大小)略高,但与FP16相比仍实现了3.5倍的内存占用减少,相比FP8约节省1.8倍存储空间。
NVFP4的核心技术优势在于Blackwell GPU的原生硬件加速支持。传统INT4量化在推理过程中无法直接处理4位数值,必须先将INT4权重反量化为16位数值才能进行计算,这一额外步骤虽然在SGLang和vLLM等现代推理框架中已经高度优化,但仍然产生计算开销并限制了整体速度。
NVFP4彻底消除了这一性能瓶颈。Blackwell Tensor Core原生支持NVFP4运算,张量在整个推理流程中保持4位格式,前提是权重和激活均采用NVFP4量化。无需反量化操作,所有NVFP4运算均享受硬件加速,计算效率显著提升。实测结果表明,NVFP4模型的推理吞吐量超越了INT4模型,而后者本身已经比标准16位模型快很多。
在软件生态方面,NVFP4已完整集成到主流工具链中。开发者可使用llm-compressor完成NVFP4格式量化,随后通过支持NVFP4模型执行的vLLM实现高效推理部署。
NVFP4量化实践:LLM-Compressor工作流程
本文所有测试均在RTX 6000 Pro上完成。NVFP4技术依赖Blackwell架构特性,预期无法在前代GPU(Hopper、Ada等)上正常工作。
首先安装LLM Compressor:
pip install llmcompressor
NVIDIA已发布多个NVFP4格式的预量化模型。为进行对比分析,我们选择了已有官方NVFP4版本的Llama 3.3 Instruct进行重新量化测试。
模型加载过程中无需将完整模型载入GPU内存。原始Llama 3.3通常需要两个80GB GPU,但NVFP4量化只需单个RTX 6000 Pro,同时要求足够的CPU RAM存放无法装入GPU的模型部分。
MODEL_ID = "meta-llama/Llama-3.3-70B-Instruct" model = AutoModelForCausalLM.from_pretrained(MODEL_ID, torch_dtype="auto") tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
校准数据集配置
量化过程需要少量校准样本。测试中使用512个样本,最少可降至128个而不影响显著效果。理论上增加样本数量可能略微改善量化精度,但超过1024个样本后收益递减明显。
序列长度建议不低于2048。虽然更长序列能够改善长上下文推理的校准效果,但会显著增加量化计算成本,需要在校准质量与计算效率间做出权衡。
from datasets import load_dataset
NUM_CALIBRATION_SAMPLES=512
MAX_SEQUENCE_LENGTH=2048
# Load dataset.
ds = load_dataset("HuggingFaceH4/ultrachat_200k", split=f"train_sft[:{NUM_CALIBRATION_SAMPLES}]")
ds = ds.shuffle(seed=42) # Preprocess the data into the format the model is trained with.
def preprocess(example): return {"text": tokenizer.apply_chat_template(example["messages"], tokenize=False,)}
ds = ds.map(preprocess)
# Tokenize the data (be careful with bos tokens - we need add_special_tokens=False since the chat_template already added it).
def tokenize(sample): return tokenizer(sample["text"], padding=False, max_length=MAX_SEQUENCE_LENGTH, truncation=True, add_special_tokens=False) ds = ds.map(tokenize, remove_columns=ds.column_names)
量化执行
# Configure the quantization algorithm to run.
recipe = QuantizationModifier(targets="Linear", scheme="NVFP4", ignore=["lm_head"])
# Apply quantization.
oneshot( model=model, dataset=ds, recipe=recipe, max_seq_length=MAX_SEQUENCE_LENGTH, num_calibration_samples=NUM_CALIBRATION_SAMPLES, )
NVFP4方案同时量化权重和激活,使权重在整个推理过程中保持NVFP4格式,因为激活采用相同数据类型。无需反量化操作直接带来了更高的推理吞吐量。
如果希望保持激活精度以最大化模型准确性,可选择NVFP4A16方案,该方案仅量化权重,通常无需校准数据集。
recipe = QuantizationModifier(targets="Linear", scheme="NVFP4A16", ignore=["lm_head"]) # Apply quantization. oneshot(model=model, recipe=recipe)
NVFP4A16方案在运行时需要反量化权重,与INT4模型类似,因此推理吞吐量显著降低,基本丧失了NVFP4的性能优势。
vLLM推理部署实践
本文基于vLLM v0.10.0进行测试,NVFP4模型加载基本做到开箱即用。
技术问题与解决方案
测试过程中遇到FlashInfer库的兼容性问题。FlashInfer用于加速vLLM推理中的采样过程,默认会启用但可能会导致NVFP4模型崩溃。临时解决方案是卸载该库(
pip uninstall flashinfer-python
),要等FlashInfer修复后NVFP4推理性能有望进一步提升。
另一个重要问题是标准
pip install vllm
无法为Blackwell GPU正确安装vLLM。尽管这个问题令人意外,但确实需要从源码编译vLLM:
git clone https://github.com/vllm-project/vllm.git cd vllm python use_existing_torch.py pip install -r requirements/build.txt pip install setuptools_scm mkdir ./tmp MAX_JOBS=10 CCACHE_DIR=./tmp python setup.py develop
性能评估:精度、内存与吞吐量分析
NVIDIA官方测试主要对比了NVFP4与FP8,结果显示NVFP4在多数任务上仅略有性能损失。但与已被主流推理框架广泛支持的成熟量化方法相比结果如下:
使用公开模型以及两个自定义NVFP4变体:NVFP4A16和完整NVFP4方案(与NVIDIA官方模型相似)。
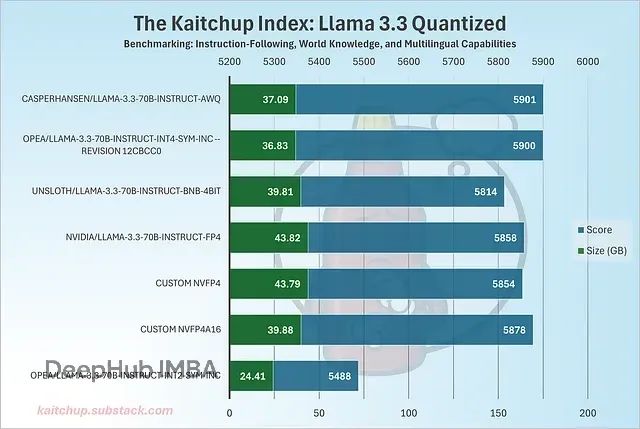
精度对比结果
AWQ和AutoRound等4位量化模型(如OPEA发布版本)在精度上略优于NVFP4模型,包括NVIDIA官方版本。值得注意的是,NVFP4还对激活进行量化,但精度基本保持稳定,特别是与仅量化权重的NVFP4A16相比差异很小。
内存占用分析
NVFP4模型体积增加约7GB,主要原因是采用了更小的分组大小(16 vs 128),需要存储更多缩放参数。这一增长通过NVFP4使用较低位宽缩放因子(FP8 vs AWQ/AutoRound的更高精度)得到部分抵消。
考虑到4位量化在Llama 3.3等大型模型上已经接近全精度性能,NVFP4与INT4模型间的精度差异并不显著。真正的差异可能在小于10B参数的模型上更加明显,这将是一个值得深入研究的方向。
本来还计划将NVFP4与其他FP4格式(如GPT-OSS模型使用的MXFP4)进行对比,但LLM Compressor目前不支持MXFP4,无法验证NVFP4是否为当前最优FP4量化方案。
推理性能突破
尽管NVFP4在压缩率和精度方面并无显著优势,但在推理速度上表现卓越,大幅超越测试中的所有其他量化模型:
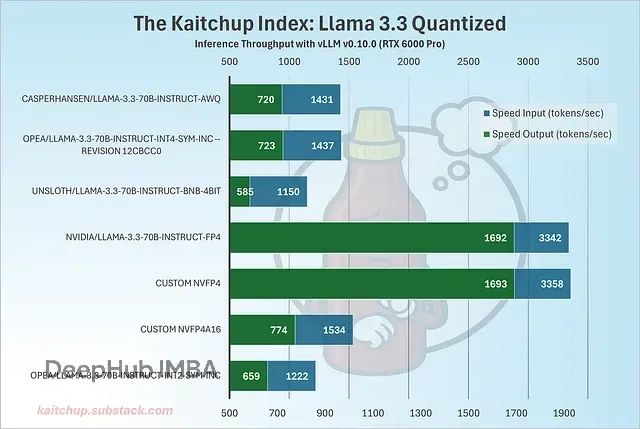
得益于Blackwell GPU对NVFP4数据类型的原生加速,NVFP4模型比INT4模型快2.35倍。测试结果还证实了激活量化对保持速度优势的关键作用——仅量化权重的NVFP4A16模型速度提升有限,仅略快于INT4模型。
总结
对于拥有Blackwell GPU的用户,NVFP4量化是一个高度推荐的选择。在精度满足需求的前提下,推理吞吐量的显著提升具有重要的实用价值。
从技术角度看,NVFP4模型的QLoRA微调是完全可行。NVFP4本质上只是一种数据类型和量化格式,QLoRA可以应用于任何格式和数据类型的量化模型。
但目前尚无框架原生支持NVFP4模型的QLoRA,但在Hugging Face的TRL和PEFT中实现相对简单,因为这些库已经集成了其他量化格式的支持。预计这一功能可能会在近期得到支持。
https://avoid.overfit.cn/post/655bb29f1c3f4e3c984951fa1c6bc2d0
作者:Benjamin Marie