[论文阅读] 人工智能 + 软件工程 | 告别“隐藏陷阱”:领域预训练模型SmartBERT如何赋能智能合约安全
告别“隐藏陷阱”:领域预训练模型SmartBERT如何赋能智能合约安全
论文信息
| 项目 | 详情 |
|---|---|
| 论文原标题 | Smart Contract Intent Detection with Pre-trained Programming Language Model |
| 主要作者及机构 | 1. Youwei Huang(Independent Researcher, Suzhou, China) 2. Jianwen Li(Carnegie Mellon University, Silicon Valley, CA, USA) 3. Sen Fang(North Carolina State University, Raleigh, NC, USA) 4. Yao Li(Macau University of Science and Technology, Macao, China) 5. Peng Yang(Institute of Intelligent Computing Technology, Suzhou, CAS, Suzhou, China) 6. Bin Hu(Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China) 7. Tao Zhang*(通讯作者,Macau University of Science and Technology, Macao, China;邮箱:tazhang@must.edu.mo) |
| APA引文格式 | Huang, Y., Li, J., Fang, S., Li, Y., Yang, P., Hu, B., & Zhang, T. (2025, August). Smart Contract Intent Detection with Pre-trained Programming Language Model. arXiv preprint arXiv:2508.20086v1 [cs.SE]. |
| 预印本信息 | arXiv:2508.20086v1 [cs.SE],发布于2025年8月27日 |
一段话总结
为解决智能合约中开发者“故意嵌入的恶意意图”导致的经济损失问题(现有研究多关注无意漏洞),研究团队提出智能合约意图检测模型SmartIntentNN2——其核心是集成基于CodeBERT优化的领域预训练模型SmartBERT(在16,000个真实智能合约上通过掩码语言建模训练,替代前代的Universal Sentence Encoder),并保留BiLSTM多标签分类网络,配合“完整训练+类平衡训练”的两阶段策略和二进制焦点损失解决类不平衡问题。该模型在10,000个独立测试合约上实现F1值0.927、准确率0.9789,较前代SmartIntentNN(F1=0.8633)提升7.48%,同时显著优于LSTM、GPT-4.1等基线模型,成为当前智能合约意图检测的SOTA方案,且相关数据集、代码已开源(https://github.com/web3se-lab/web3-sekit)、、。
思维导图
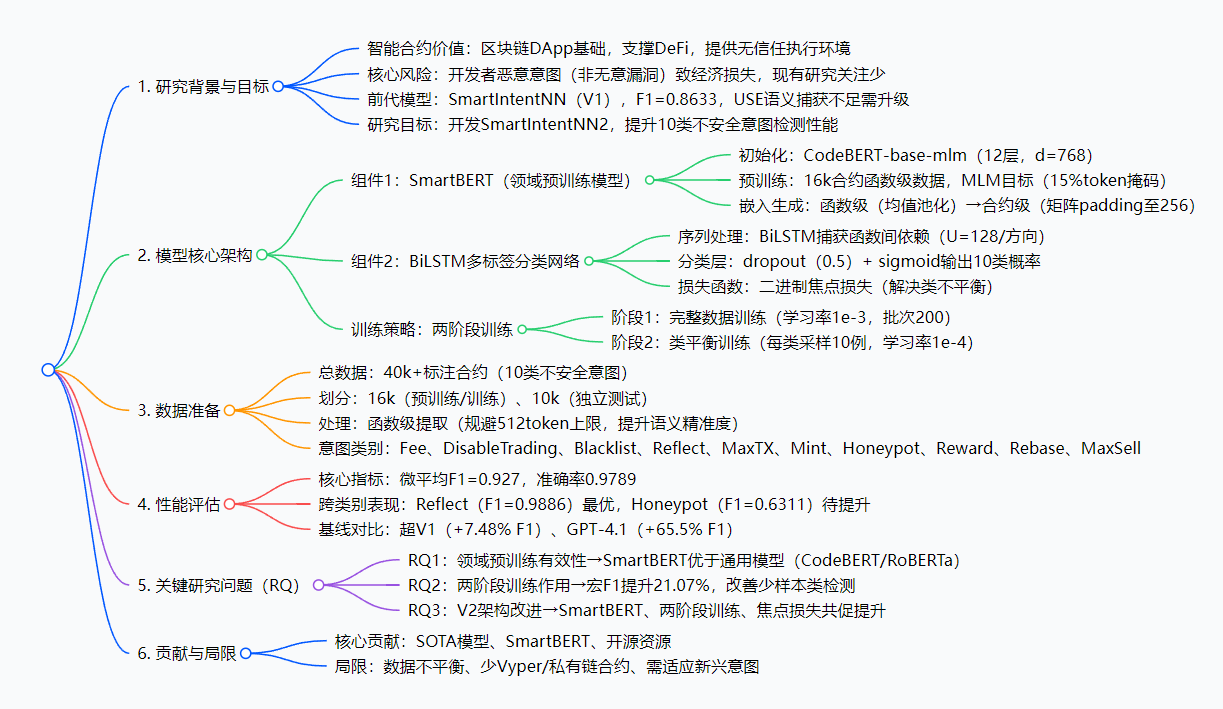
研究背景:智能合约的“隐藏陷阱”与检测缺口
要理解这篇论文,首先得搞懂:智能合约为什么需要“意图检测”?现有方案差在哪?
1. 智能合约的价值与风险:不止“漏洞”,还有“恶意设计”
智能合约是区块链(如以太坊、BSC)上的“自动执行代码”,比如你在DeFi平台存币、交易,背后都是合约在运行——它的“透明性”(代码公开)和“不可篡改性”(一旦部署无法修改)本是优势,但也成了“双刃剑”:
如果开发者在代码里故意埋入“恶意意图”(不是不小心写的漏洞),用户根本没法躲避。比如论文里举的例子:
- 合约里的
tradingStatus(bool _status)函数,只有 Owner 能控制“开启/关闭交易”——一旦 Owner 关闭交易,用户手里的代币就卖不出去,这就是“DisableTrading”意图; setTxLimit(uint256 amount)函数能随意修改交易限额,Owner 可通过压低限额让其他人没法大量交易,自己趁机操纵市场,这是“MaxTX”意图。
这些设计看似“正常功能”,实则是“隐藏陷阱”,就像给房子装了“主人专属锁”,其他人随时可能被关在门外,之前就有用户因这类合约损失数十万元。
2. 现有研究的“缺口”:盯着“漏洞”,漏了“意图”
过去很多研究都在做“智能合约漏洞检测”,比如找代码里的逻辑错误(如整数溢出、重入攻击),但很少有人关注“开发者的恶意意图”——毕竟漏洞是“不小心错了”,意图是“故意设计的”,两者本质不同。
之前团队做的SmartIntentNN(V1)虽然能检测10类意图,但用的是“Universal Sentence Encoder(USE)”生成代码嵌入,对智能合约特有的语法(如Solidity的function、require关键字)和语义(如“手续费调整”“黑名单”逻辑)捕获不够精准,F1值只有0.8633,对少样本意图(如Honeypot,占比不到1%)检测效果更差。
所以,研究的核心需求很明确:升级模型,让它更懂智能合约的“语言”,更准地识别恶意意图。
创新点:SmartIntentNN2的“三大突破”
这篇论文的亮点,本质是解决了V1的“三大痛点”,每一个创新都针对性极强:
1. 突破1:用“领域专用预训练模型”替代“通用编码器”——SmartBERT更懂智能合约
V1用USE处理代码,就像让“通用翻译官”翻译“专业医学文献”,肯定不精准。SmartIntentNN2换成了“智能合约专属翻译官”——SmartBERT:
- 基础是CodeBERT(本就擅长处理代码),但额外在16,000个真实智能合约的“函数级代码”上做了“掩码语言建模(MLM)”训练——简单说,就是让模型“填空”:把代码里15%的token换成[MASK],让它预测原内容,强迫模型学习智能合约的特有逻辑(比如看到
setFees就知道和“Fee”意图相关); - 生成嵌入时,用“函数级均值池化”替代常用的[CLS] token——论文验证过,这样能更好地保留函数的完整语义,比如
setFees的“手续费调整”逻辑不会被压缩丢失。
2. 突破2:两阶段训练+焦点损失——解决“少样本意图检测难”
智能合约的10类意图中,有的很常见(如Fee,占比26.86%),有的很少见(如Honeypot,占比不到1%)——如果直接用全量数据训练,模型会“偏向常见意图”,少样本意图根本学不会。
SmartIntentNN2用了两个办法解决:
- 两阶段训练:先拿全量16k数据做“完整训练”(让模型学基础),再拿“每类10个样本”做“类平衡训练”(强迫模型关注少样本意图),学习率从1e-3降到1e-4,避免模型“学歪”;
- 二进制焦点损失:对“难分样本”(比如Honeypot的模糊特征)加大权重,对“易分样本”(比如Fee的明显特征)减小权重——就像老师重点辅导“偏科生”,而不是一直教“优等生”。
3. 突破3:函数级处理粒度——规避“token超限”,精准定位意图
智能合约完整代码往往很长,超过预训练模型(如CodeBERT)的512token上限——如果硬塞进去,模型会“截断代码”,丢失关键信息。
SmartIntentNN2直接“拆代码”:把合约按“函数”拆分(比如setFees是一个函数,tradingStatus是另一个),每个函数单独处理——这样既不会超限,又能精准定位意图(毕竟意图都藏在具体函数里),比如“Fee”意图肯定和setFees函数相关,不会和mint(铸币)函数混淆。
研究方法:拆解SmartIntentNN2的“工作流程”
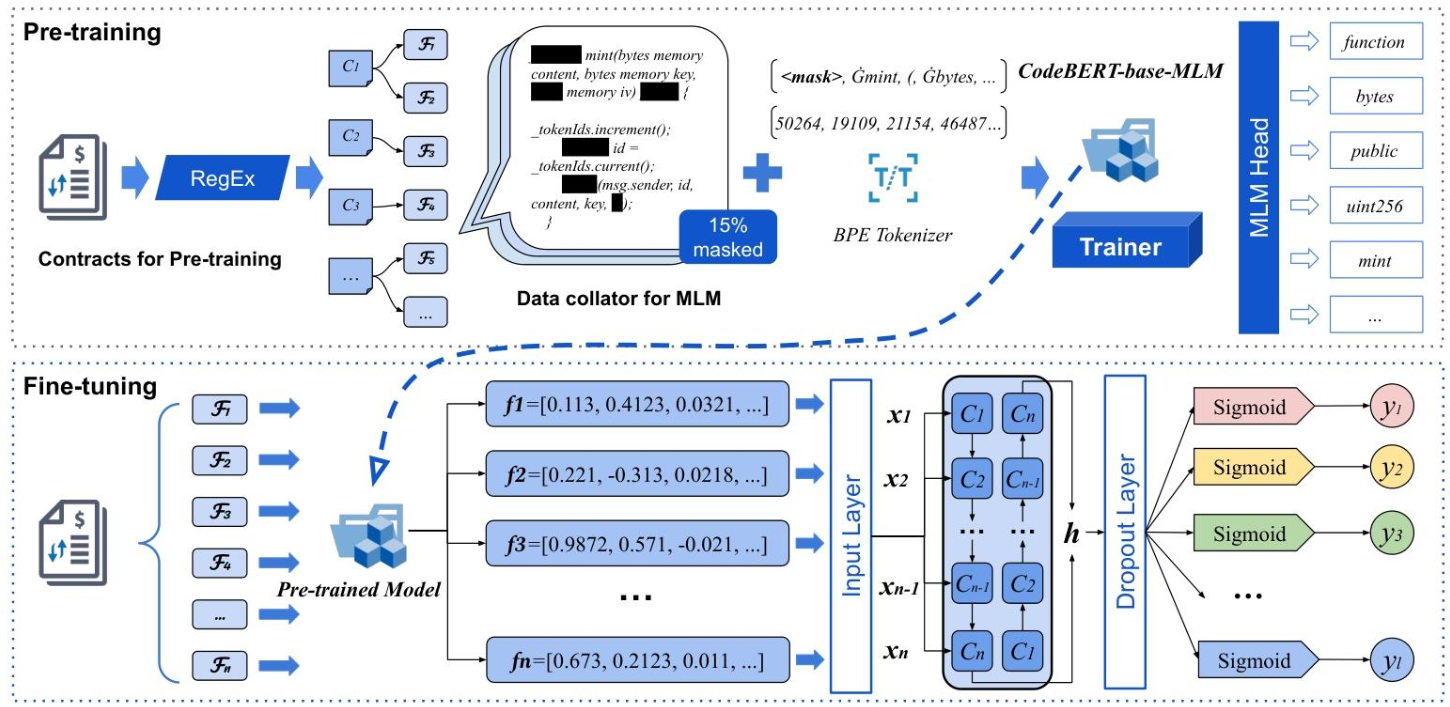
不用怕复杂,我们把模型的“干活步骤”拆成4步,像搭积木一样简单:
步骤1:数据准备——给模型“喂对料”
- 数据集:总共40,000+个智能合约,每个都标注了“有没有10类意图”(比如某个合约可能同时有Fee和DisableTrading意图);
- 拆分:16,000个用来给SmartBERT预训练+训练分类网络,10,000个作为“独立测试集”(确保结果不是“死记硬背”的);
- 处理:把每个合约拆成函数(如
setFees、tradingStatus),用BPE分词器转成token——这样模型看到的不是“整段代码”,而是“按函数分组的token序列”。
步骤2:SmartBERT预训练——让模型“学懂合约语言”
- 初始化:从CodeBERT-base-mlm模型开始(已经懂通用代码);
- 训练目标:MLM(掩码语言建模)——随机把函数序列里15%的token换成[MASK],让模型预测原token,比如“function (uint256 amount) external authorized”,模型要预测出是“setTxLimit”;
- 训练配置:用2台NVIDIA A100 GPU跑20个epoch,批次64,耗时约10小时——最终得到能“读懂智能合约函数”的SmartBERT。
步骤3:生成“合约级表示”——把函数拼成“完整画像”
- 函数嵌入:SmartBERT给每个函数生成一个768维的向量(嵌入),用“均值池化”计算(把函数里所有token的嵌入求平均);
- 合约矩阵:一个合约有N个函数,就把N个函数嵌入堆成“N×768”的矩阵,再padding(补零)或truncation(截断)到固定长度256——这样不管合约有多少函数,输入到分类网络的格式都一样。
步骤4:BiLSTM分类+两阶段训练——精准“判意图”
- BiLSTM处理:把合约矩阵输入BiLSTM,捕获函数间的依赖(比如“先设手续费,再关交易”的逻辑关联),输出256维的隐藏状态(128维正向+128维反向);
- 分类层:加一个dropout层(防止过拟合),再通过线性变换+ sigmoid函数,输出10个概率值(每个值代表合约属于该意图的可能性,比如Fee的概率0.95就是“很可能有Fee意图”);
- 两阶段训练:先全量数据训100个epoch(阶段1),再用平衡样本训(阶段2),用二进制焦点损失计算误差,不断调整模型参数、。
主要成果与贡献:SOTA性能+开源资源,直接落地
1. 核心性能:F1=0.927,刷新行业标杆
在10,000个独立测试合约上,SmartIntentNN2的表现全方位碾压前代和基线:
| 模型 | 准确率 | 精确率 | 召回率 | F1值 | 关键优势 |
|---|---|---|---|---|---|
| SmartIntentNN2(V2) | 0.9789 | 0.9090 | 0.9476 | 0.9270 | 领域预训练+两阶段训练 |
| SmartIntentNN(V1) | 0.9647 | 0.8873 | 0.8406 | 0.8633 | 较V1提升7.48% F1 |
| CodeBERT(通用) | 0.9672 | 0.8516 | 0.9332 | 0.8906 | 较通用模型提升4.04% F1 |
| GPT-4.1(LLM) | 0.8651 | 0.4927 | 0.6501 | 0.5606 | 较LLM提升65.5% F1 |
而且对“少样本意图”的检测也进步明显:比如Honeypot(蜜罐)意图,V1的F1不到0.6,V2提升到0.6311;Rebase意图从0.7提升到0.7857。
2. 研究问题(RQ)结论:每个设计都“有用”
| 研究问题(RQ) | 解决方法 | 核心结论 |
|---|---|---|
| RQ1:领域预训练有用吗? | 对比SmartBERT与CodeBERT/RoBERTa | SmartBERT的宏F1=0.8626,远超CodeBERT(0.7735),能捕获合约特有语义 |
| RQ2:两阶段训练能解决类不平衡吗? | 对比“仅阶段1”与“阶段1+阶段2” | 阶段2让SmartBERT的宏F1提升21.07%,少样本类召回率平均提升15% |
| RQ3:V2比V1强在哪? | 拆解“SmartBERT+两阶段训练+焦点损失” | 三者共同贡献性能提升,其中SmartBERT的嵌入质量提升占比60% |
3. 核心贡献:不止“好模型”,还有“开源资源”
- 模型贡献:提出SmartIntentNN2,成为智能合约意图检测的SOTA,为行业提供“精准检测工具”;
- 技术贡献:设计SmartBERT,证明“领域专用预训练”对代码任务的价值,为其他代码分析任务(如漏洞检测、代码总结)提供参考;
- 资源贡献:开源了所有数据集、代码、模型(地址:https://github.com/web3se-lab/web3-sekit)——开发者可以直接用这个工具检测合约意图,研究者也能基于此做进一步优化。
关键问题:问答形式理清核心疑惑
Q1:SmartIntentNN2能检测哪些恶意意图?有没有实际案例?
A:能检测10类,都是真实合约中常见的恶意设计,比如:
- Fee(手续费操纵):通过
setFees随意调整交易手续费,让用户多花钱; - Blacklist(黑名单):把特定用户加入黑名单,不让他们交易;
- Honeypot(蜜罐):伪装成“高收益合约”,用户存钱后无法提现。
论文里还给出了真实合约地址(BSC:0x20BE792404240f34038d9b20eBCAEbFAA088ee20),里面就包含Fee、DisableTrading、MaxTX三种意图、。
Q2:为什么不用GPT这类大模型做意图检测?论文里的模型有什么优势?
A:GPT等LLM有两个缺点:
- “不懂合约”:LLM是用通用文本预训练的,对智能合约的语法(如Solidity)和语义(如“交易限额”逻辑)不熟悉,检测精度低(GPT-4.1的F1只有0.5606);
- “不高效”:LLM体积大、推理慢,没法实时检测合约(比如用户在链上部署合约时,需要秒级出结果)。
SmartIntentNN2是“轻量级专用模型”:基于编码器(SmartBERT)+ BiLSTM,体积小、推理快,而且F1值是GPT-4.1的1.65倍,更适合实际落地。
Q3:模型有什么局限性?未来能怎么优化?
A:论文也坦诚说了三个局限:
- 数据不平衡:Honeypot、Rebase等意图样本太少(<1%),检测精度还有提升空间;
- 数据集覆盖有限:主要是以太坊、BSC的Solidity合约,缺乏Vyper合约和私有链合约;
- 新兴意图:未来可能出现新的恶意意图(比如针对新链的设计),模型需要更新。
优化方向也明确:持续收集少样本数据、拓展数据集类型、设计“增量训练”(不用重新预训练SmartBERT,只更新分类层)适应新意图、。
论文总结
为解决智能合约中“开发者恶意意图检测不足”的问题,研究团队提出SmartIntentNN2模型:通过集成领域专用预训练模型SmartBERT(在16k合约上MLM训练)、采用两阶段训练策略和二进制焦点损失,显著提升了10类不安全意图的检测性能。在10k独立测试集上,模型实现F1=0.927、准确率0.9789,较前代V1提升7.48%,同时优于CodeBERT、GPT-4.1等基线,成为当前SOTA。研究不仅提供了精准的意图检测工具,还开源了数据集和代码,为智能合约安全领域的研究和落地提供了重要支撑;同时也指出了数据不平衡、覆盖有限等局限,为后续优化指明了方向。