通过概率正 - 未标记网络从医学图像的特定感兴趣区域中学习|文献速递-深度学习人工智能医疗图像
Title
题目
Learning from certain regions of interest in medical images via probabilisticpositive-unlabeled networks
通过概率正 - 未标记网络从医学图像的特定感兴趣区域中学习
01
文献速递介绍
医学图像分割的研究背景与所提方法阐述 医学图像分割(MIS)在临床上具有巨大需求,它为分析体内组织、病灶及器官提供了定量工具(Mo和Zhang,2017;Liu等人,2021;Yuan等人,2021;Ke等人,2023;Dong等人,2023;Tang等人,2024;Huang等人,2024c)。尽管深度学习为该领域带来了变革,但高昂的标注成本无法支撑大量精准的训练标签,导致其在实际应用中的性能不尽如人意。尤其在医学图像中,受成像精度有限、术语定义抽象等因素影响,图像存在显著的模糊性,这使得专家对感兴趣区域(ROI)的解读存在差异(Kohl等人,2018;Ji等人,2021;Huang等人,2024b)。这种固有的模糊性进一步加剧了标签获取的难度。因此,在标注资源有限且存在模糊性的情况下,训练深度模型需要在标签质量与标签数量之间进行权衡。 如图1所示,多标注者标注或许能解决模糊性问题并逼近真实标签(Armato III等人,2011;Almazroa等人,2017),但这种方式需要耗费大量人力,且仅能获取小规模标签。另一方面,常用的做法是采用单一标注者的标签以增加标签数量,然而这无法保证标签的准确性。此外,这些方法均要求标注者对难以明确判定的区域(尤其是边界区域)进行ROI勾勒,这不仅会给模型带来错误监督,而且标注效率低下。 与之相反,本研究提出了一种新的学习范式,即仅从确定区域中学习分割模型。这意味着标注者只需对能够明确识别的ROI进行标注,省去了在边界区域“反复修正”的时间。同时,现有软件已提供便捷工具,支持用户快速勾勒确定的ROI,例如Slicer软件中的水平追踪功能[图1(b)]。通过这种方式,既能提高标注效率,又能保证标签准确性。 由此,我们面临的挑战既包括带噪声标签学习,也包括不确定性估计。具体而言,前者可进一步归为正-未标记(PU)分割问题(Lejeune和Sznitman,2021)——在该问题中,所有已标注像素均为正样本,而其余未标注像素既可能是正样本,也可能是负样本;后者的目标则是模拟人类的解读过程,提供多种合理的结果,从而降低模糊性(Rahman等人,2023)。 PU学习在二分类任务中已得到广泛研究,现有研究构建了多种具有可靠理论依据的无偏风险估计器(Elkan和Noto,2008;Kiryo等人,2017;Jiang等人,2023)。因此,从理论保障角度而言,PU学习在医学图像分割领域具有巨大潜力,模型可基于部分标签进行无偏学习。然而,目前仅有少数研究探索了这一方向(Lejeune和Sznitman,2021;Zhang和Zhuang,2022;Wu和Zhuang,2022),且这些研究均未探讨PU学习方法在哪些情况下可行。本文将深入研究分割任务中的PU学习假设,并尝试揭示以往PU分割(PU-S)研究场景与从确定ROI中学习这一场景之间的差异。 为解决数据模糊性问题,现有医学图像分割研究通过利用模型参数的随机性来估计预测不确定性,所采用的技术包括深度集成(Tarvainen和Valpola,2017)、蒙特卡洛 dropout(Yu等人,2019)以及基于贝叶斯的方法(Kohl等人,2018;Rahman等人,2023)。部分研究还通过证据深度学习量化不确定性(Huang等人,2023)。这些方法均借助无偏观测到的标签来推导不确定性,但本研究面临的条件更为苛刻——真实标签仅被部分观测到。因此,我们需要一种既能从部分标签中学习,又能估计预测不确定性的解决方案。 本文提出概率正-未标记分割网络(ProPU-Net),以实现从确定区域中学习的目标。具体而言,在我们的研究场景中,真实ROI仅被部分观测到,因此我们采用期望最大化(EM)算法来最大化生成数据的似然性,并逐步估计未知的真实标签。在此过程中,为降低PU分割的计算复杂度,我们提出了像素联合独立性假设。另一方面,我们将合理的分割变体编码到潜在空间中,以助力不确定性估计。更值得关注的是,通过最大似然估计(MLE),该潜在空间可自然地嵌入到PU学习框架中。依托这一理论扎实的框架,能够无偏地预测真实ROI,因此我们进一步设计了半监督PU(SSPU)分割方法,利用伪标签训练模型,旨在通过未标记数据进一步提升模型性能。 我们在两个多标注者数据集(LIDC(Armato III等人,2011)和RIGA(Almazroa等人,2017))以及一个基准3D医学图像分割数据集(LA(Xiong等人,2021))上开展了大量实验。实验结果证实了所提方法的优越性与实际应用前景。 本文的贡献总结如下: (1)据我们所知,本研究首次提出从确定ROI中学习,并将该问题转化为PU分割任务来解决;同时,我们还深入探讨了在医学图像分割中应用PU学习方法的前提条件,这一问题此前尚未被研究。 (2)提出ProPU-Net,同时解决PU分割与不确定性估计问题。在该框架中,我们通过像素联合独立性条件,以像素级形式给出EM目标函数,并基于MLE理论将PU学习与不确定性估计统一到单一框架中。 (3)提出半监督PU分割方法SSPU,该方法不仅能从确定区域中学习,还能充分利用未标记数据,进一步提升模型的泛化能力。
Abatract
摘要
The laborious annotation process and inherent image ambiguity exacerbate difficulties of data acquisition formedical image segmentation, leading to suboptimal performance in practice. This paper proposes a workaroundagainst these challenges aiming to learn unbiased models solely from certainties. Concretely, during thelabeling stage, only regions of interest confidently discerned by annotators are required to be labeled, not onlyincreasing label quantity but also improving label quality. This approach formulates the positive-unlabeled (PU)segmentation problem and motivates to capture uncertainty in ambiguous regions. We thus delve into datagenerating assumptions in the PU segmentation context and propose Probabilistic PU Segmentation Networks(ProPU-Nets) to tackle problems abovementioned. This framework employs the expectation–maximizationalgorithm to gradually estimate true masks, and more importantly, by encoding plausible segmentation variantsin a latent space, uncertainty estimation can be naturally embedded into the PU segmentation framework.Benefitting from the framework’s unbiasedness, a semi-supervised PU segmentation method is also proposed,which can further excavate performance gains from unlabeled data. We conduct extensive experiments onLIDC, RIGA, and LA datasets, and comprehensively compared with state-of-the-art methods in label-efficientmedical image segmentation. The results justify the method’s effectiveness and practical prospect.
医学图像分割中,繁琐的标注过程与图像固有的模糊性加剧了数据获取的难度,导致实际应用中的性能欠佳。本文针对这些挑战提出了一种解决方案,旨在仅从确定区域中学习无偏模型。具体而言,在标注阶段,仅要求标注者对能够明确识别的感兴趣区域进行标注,这不仅增加了标注数量,还提升了标注质量。该方法将问题构建为正-未标记(PU)分割问题,并致力于捕捉模糊区域中的不确定性。为此,我们深入研究了PU分割场景下的数据生成假设,提出了概率正-未标记分割网络(ProPU-Nets),以解决上述问题。该框架采用期望最大化算法逐步估计真实掩码,更重要的是,通过在潜在空间中对合理的分割变体进行编码,可将不确定性估计自然地融入PU分割框架中。得益于该框架的无偏性,本文还提出了一种半监督PU分割方法,该方法能够进一步从未标记数据中挖掘性能提升空间。我们在LIDC、RIGA和LA数据集上开展了大量实验,并与医学图像分割领域中标签高效型的主流方法进行了全面对比。实验结果证实了该方法的有效性与实际应用前景。
Method
方法
We follow the practice of the censoring setting, and employ avariable 𝑆 ∈ {0, 1}𝐷 to indicate the labeling mask of data 𝑋 ∈ R𝐷.Correspondingly, 𝑌 ∈ {0, 1}𝐷 represents the true mask. Let 𝑌 ′ , 𝑆 ′(where 𝑌 ′ , 𝑆′ ∈ {0, 1}) be the variables of 𝑌 , 𝑆 for a single pixel,respectively. By definitions, if a positive pixel is confidently labeled,then 𝑆 ′ = 1 and 𝑌 ′ = 1; otherwise, 𝑆 ′ = 0 yet 𝑌 ′ is unknown. LetP(𝑋, 𝑌 , 𝑆) be the joint distribution, and 𝑝(𝐱, 𝐲,𝐬) be the correspondingdensity, where 𝐱, 𝐲, 𝐬 represent instances of 𝑋, 𝑌 , 𝑆, respectively.Suppose = {(𝐱𝑖,𝐬𝑖 )}𝑁 𝑖=1 is a dataset with 𝑁 observations from P, thegoal of this study is to construct a network 𝜃 maximizing a likelihoodof stochastic processes generating observations in max𝜃P(𝑆|𝑋; , 𝜃) s.t. 𝑆 being dependent on (𝑋, 𝑌 ). (2)
The dependency of 𝑆 implies labeling masks are affected by both imagefeatures and true labels, as ROIs with more evident features are morelikely to be confidently annotated.In the following section, we will first introduce how to learn fromcertainties (Section 4.1) and how to model the predictive uncertainty(Section 4.2). Practical implementations are presented in Section 4.3,and in Section 4.4, the method to leverage unlabeled data is introduced.
公式与研究目标阐述 我们采用“审查(censoring)”设定的常规做法,引入变量(𝑆 ∈ {0, 1}^𝐷)来表示数据(𝑋 ∈ \mathbb{R}^𝐷)的标注掩码。相应地,(𝑌 ∈ {0, 1}^𝐷)代表真实掩码。设(𝑌'、𝑆')(其中(𝑌'、𝑆' ∈ {0, 1}))分别为单个像素对应的(𝑌、𝑆)变量。根据定义,若某一正样本像素被明确标注,则(𝑆' = 1)且(𝑌' = 1);反之,若(𝑆' = 0),则(𝑌')取值未知。设(P(𝑋, 𝑌, 𝑆))为联合分布,(𝑝(𝐱, 𝐲, 𝐬))为对应的概率密度(其中(𝐱、𝐲、𝐬)分别表示(𝑋、𝑌、𝑆)的实例)。假设数据集(\mathcal{D} = {(𝐱i, 𝐬i)}{i=1}^N)包含(N)个来自分布(P)的观测样本,本研究的目标是构建网络(\theta),以最大化生成数据集中观测样本的随机过程的似然性,即: [ \max{\theta} P(𝑆|𝑋; \mathcal{D}, \theta) \quad \text{s.t.} \quad 𝑆 \text{ 依赖于 } (𝑋, 𝑌) \tag{2} ] (𝑆)的依赖性表明,标注掩码同时受图像特征与真实标签的影响——因为特征更明显的感兴趣区域(ROI)更有可能被明确标注。 在后续章节中,我们将首先介绍如何从确定区域中学习(4.1节)以及如何对预测不确定性进行建模(4.2节);4.3节将阐述具体实现方法;4.4节则介绍利用未标记数据的策略。
Conclusion
结论
This paper handles a particular learning scenario where only ROIsconfidently annotated are used for training. This scheme benefits fromboth high label-efficiency and dense supervision. We propose ProPUNet, which concurrently addresses PU segmentation and uncertaintyestimation in this scenario. Encouragingly, the two issues are unifiedinto a single framework via the maximum likelihood estimation principle. Moreover, this method garners fair merits from the well-foundedtheory in PU learning; it prompts a straightforward semi-supervisedPU segmentation method, facilitating gains from massive unlabeleddata. The comprehensive experiments on three datasets justify theeffectiveness of the proposed methods, and shows great prospects inenhancing the generalizability of neural networks for medical imagesegmentation.While our method demonstrates theoretical advantages, its computational complexity highlights the need for further optimization.Bi-level learning is one potential solution that we will try in the future.Additionally, we plan to extend validation to more challenging multiclass scenarios, e.g., the multi-organ segmentation task with arbitrarilymissing annotations.
本文针对一种特定的学习场景展开研究,即仅使用经明确标注的感兴趣区域(ROI)进行训练。该方案兼具高标注效率与密集监督的双重优势。我们提出了概率正-未标记分割网络(ProPU-Net),可在此场景下同时解决正-未标记分割(PU分割)与不确定性估计问题。令人鼓舞的是,通过最大似然估计原理,这两个问题被统一到了单一框架中。此外,该方法还充分借鉴了正-未标记学习(PU学习)领域完善的理论基础,进而提出了一种简洁的半监督正-未标记分割方法,能够借助大规模未标记数据提升模型性能。在三个数据集上开展的全面实验验证了所提方法的有效性,且该方法在提升医学图像分割神经网络泛化能力方面展现出良好前景。 尽管我们的方法在理论上具有优势,但其计算复杂度较高,仍需进一步优化。双层学习(Bi-level learning)是我们未来将尝试的一种潜在解决方案。此外,我们计划将验证范围扩展到更具挑战性的多类别场景,例如存在任意标注缺失的多器官分割任务。
Figure
图
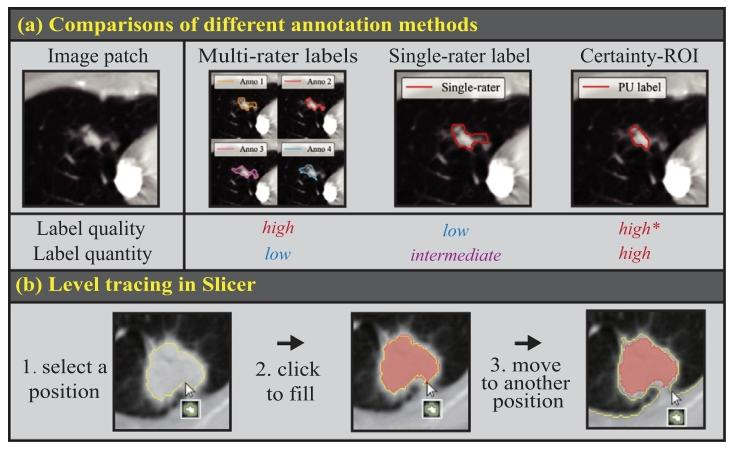
Fig. 1. Motivation of learning from certainties. (a) Disparities exist in multi-raterlabels and single-rater labels are inaccurate at boundaries. Labeling certainty-ROIs hasrelatively high efficient and accuracy (*w.r.t. labeled regions). (b) Labeling certaintiespossibly has high label efficiency using level tracing1 by just one click.
图1从确定区域中学习的动机示意图:(a)多标注者标注存在差异,且单一标注者标注在边界处准确性不足;而对确定感兴趣区域(certainty-ROIs)进行标注,具有更高的效率与准确性(*针对已标注区域而言)。(b)利用水平追踪工具
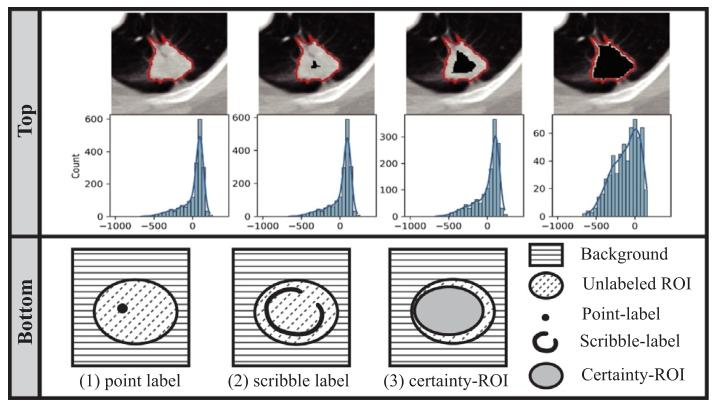
Fig. 2. Interpretation of data generation assumptions in PU-S. Top: Excluding labeledpixels (within black holes) will change data distribution correspondingly. For bettervisualization, the histograms only display HU values of unlabeled positives (within redlines and outside black holes). Bottom: Point-level and scribble-level labels are sparsewhile certainty-ROI labels are much dense.
图2 正-未标记分割(PU-S)中数据生成假设的解读: 上方:排除已标注像素(黑色孔洞内)会相应改变数据分布。为便于可视化,直方图仅展示未标记正样本(红色线条内、黑色孔洞外区域)的HU值(CT值)。 下方:点级标注与涂鸦级标注(样本)较为稀疏,而确定感兴趣区域(certainty-ROI)标注(样本)则密集得多。
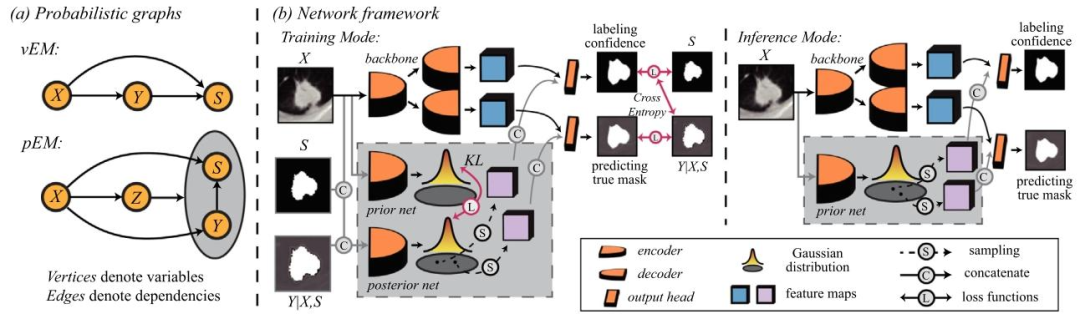
Fig. 3. (a) Probabilistic processes of vEM and pEM. (b) The overall framework of ProPU-Net. Posterior/prior nets and their relevant flows (marked by light gray regions/lines)are introduced for uncertainty estimation. (𝑋: image; 𝑆: labeling mask; 𝑌 |𝑋, 𝑆: an estimation of 𝑌 given (𝑋, 𝑆)).
图3 (a)变分期望最大化(vEM)与概率期望最大化(pEM)的概率过程示意图; (b)概率正-未标记分割网络(ProPU-Net)的整体框架图。为实现不确定性估计,引入后验网络/先验网络及其相关流程(以浅灰色区域/线条标注)。 (注:图中符号含义:(X)代表图像,(S)代表标注掩码,(Y|X,S)代表给定((X,S))条件下对真实掩码(Y)的估计。)
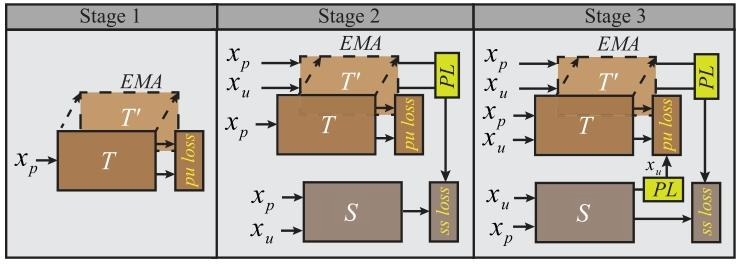
Fig. 4. Schematic of SSPU. The teacher model ( ) is supervised by PU loss definedin Eq. (6) or Eq. (7). An EMA teacher ( ′ ) is kept to produce pseudo labels (PL) fortraining the student model (). The combination of Dice and cross-entropy is employedas the loss criterion of , namely, the semi-supervised (SS) loss. In stage 3, ROIs of 𝐱*𝑢*confidently predicted by are served as pseudo certainties labels for training
图4 半监督正-未标记分割(SSPU)示意图: 教师模型((\mathcal{T}))由公式(6)或公式(7)定义的正-未标记(PU)损失函数监督训练;同时维护一个指数移动平均(EMA)教师模型((\mathcal{T}')),用于生成伪标签(PL)以训练学生模型((\mathcal{S}))。学生模型的损失函数采用Dice损失与交叉熵损失的组合,即半监督(SS)损失。在第3阶段,学生模型((\mathcal{S}))对未标记图像(\mathbf{x}_u)所做的高置信度预测对应的感兴趣区域(ROI),将作为“伪确定区域标签”,用于训练教师模型((\mathcal{T}))。
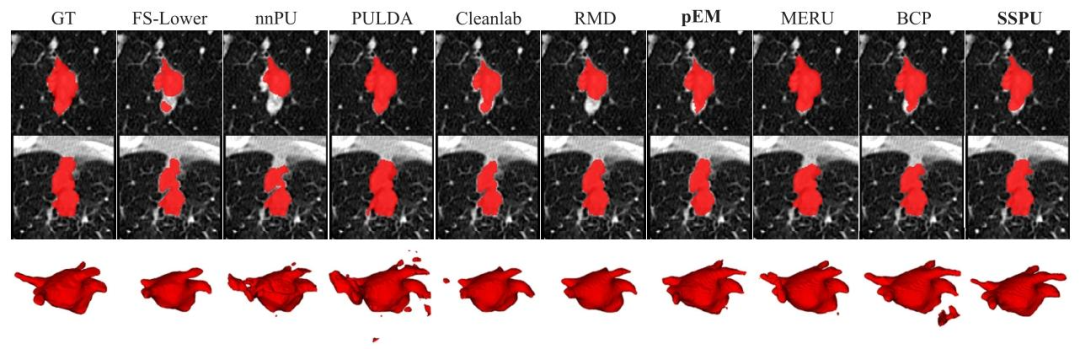
Fig. 5. Masks predicted by different methods. The 2–7 columns are methods trained by PU labels, and 8–10 columns are with the semi-supervised setting
图 5 不同方法的预测掩码对比图:
第 2-7 列为采用正 - 未标记(PU)标签训练的各方法的预测掩码;第 8-10 列为采用半监督(semi-supervised)设置训练的各方法的预测掩码。
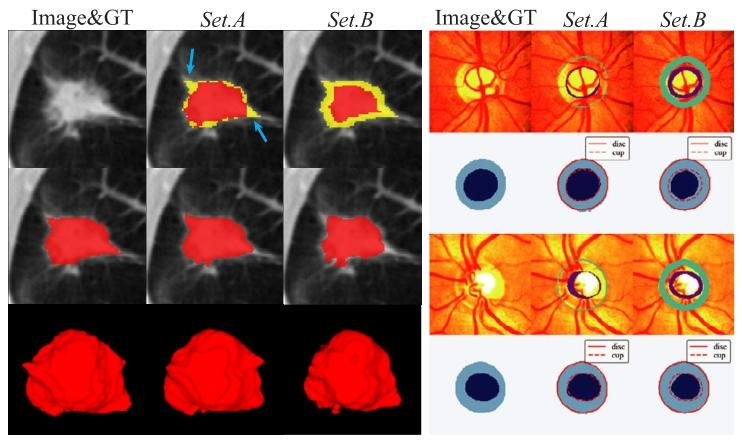
Fig. 6. Comparison of different PU labels on multi-rater datasets. For the LIDC image,unlabeled GT regions appear at boundaries (masked in yellow), while for RIGA data,masks on the images are represent unlabeled GTs for the disk and cup classes. Allpredictions are generated using pEM
图6 多标注者数据集上不同正-未标记(PU)标签的对比图 对于LIDC数据集的图像,真实标签(GT)中的未标记区域位于边界处(以黄色掩码标注);对于RIGA数据集的数据,图像上的掩码代表视盘类与视杯类的真实未标记区域。所有预测结果均通过概率期望最大化(pEM)方法生成。

Fig. 7. Cell-scale attention heatmaps by the proposed method in malignancy prediction on cell blocks of pleural effusion.
图7 所提方法在胸膜积液细胞块恶性肿瘤预测中的细胞级注意力热力图
Table
表
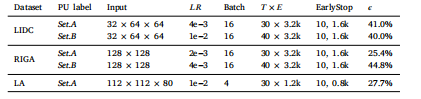
Table 1Overview of training settings. Values in the 7-th column are early stopping patiencein iteration (left) and optimizing steps (right). 𝜖 denotes the average noise rate withinthe GT
表1 训练设置概览 第7列中的数值分别代表迭代过程中的早停容忍次数(左侧)与优化步数(右侧)。其中,\(\boldsymbol{\epsilon}\)表示真实标签(GT)内的平均噪声率。
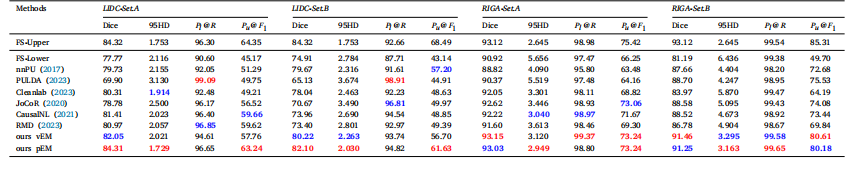
Table 2Results on multi-rater datasets using two label settings. Note that 𝑃𝑙@𝑅 and 𝑃𝑢@𝐹1 of FS-Upper are computed from corresponding PU labels. The best and second-best valuesare highlighted
表 2 两种标签设置下多标注者数据集的实验结果
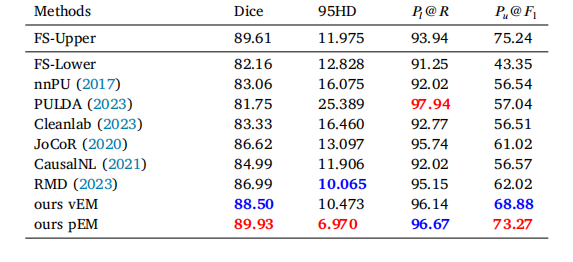
Table 3Results on the LA dataset. The best and second-best values are highlighted.
表 3 LA 数据集上的实验结果最佳与次佳结果已用高亮标注。
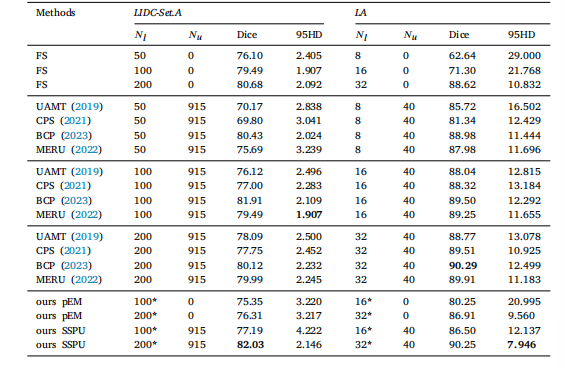
Table 4Results of semi-supervised learning on the LIDC and LA datasets. The asterisk (*)suggests that data are with certain-ROI labels.
表4 LIDC数据集与LA数据集上的半监督学习实验结果 星号(*)表示数据带有确定感兴趣区域(certain-ROI)标签。
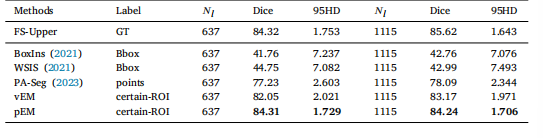
Table 5Results on the LIDC dataset compared with inexact-supervised learning methods. 𝑁𝑙represents the number of labeled data
表5 LIDC数据集上与非精确监督学习方法的对比结果 其中,(\boldsymbol{N_l})代表带标注数据的数量。
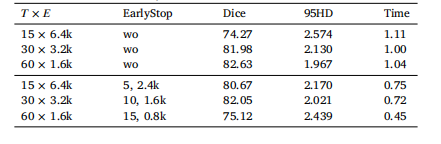
Table 6Results of training schedule under the case of LIDC-Set.A using vEM. The EarlyStopcolumn represents training without (wo) early stopping or early terminating withpatience in iteration (left) and steps (right). We employ the training time of 30 × 3.2kas the baseline, which is set by 1
表 6 LIDC-Set.A 数据集上基于变分期望最大化(vEM)的训练流程实验结果“早停(EarlyStop)” 列表示两种训练情况:无早停(wo),或采用早停策略(括号内左侧为迭代容忍次数,右侧为优化步数)。本实验以 30×3.2k 的训练时间为基准,并将该基准值设为 1(用于归一化对比不同训练流程的时间成本)。
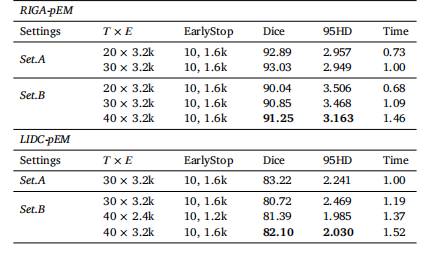
Table 7Comparison of different label settings in the same dataset. We use the schedule30 × 3.2k as the baseline training cost for both datasets.
表 7 同一数据集下不同标签设置的对比结果本实验中,两个数据集均以 30×3.2k 的训练流程(或训练成本)作为基准训练成本。
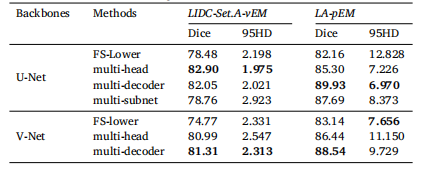
Table 8Results of different network configurations
表 8 不同网络配置的实验结果
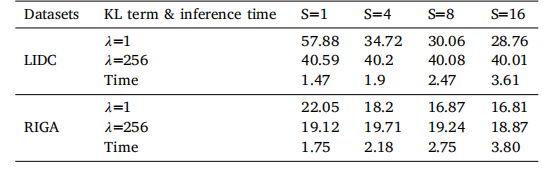
Table 9GED metrics and inference time compared to the vanilla U-Net under different samplesizes (represented by S)
表 9 不同样本量(以 S 表示)下,与基础 U-Net(vanilla U-Net)在 GED 指标及推理时间上的对比结果
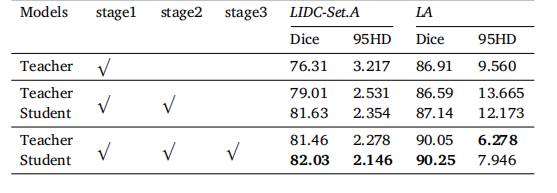
Table 10Ablation study of three training stages in SSPU.
表 10 半监督正 - 未标记分割(SSPU)中三个训练阶段的消融实验结果