力扣 30 天 JavaScript 挑战 第40天 (第十一题)对纯函数和记忆函数有了更深理解

力扣官方题解
开始答题
/*** @param {Function} fn* @return {Function}*/
function memoize(fn) {let cache = {}return function (...args) {const key = args.toString()if(cache[key] !== undefined) return cache[key]else {const result = fn(...args)cache[key] = resultreturn result}}
}/** * let callCount = 0;* const memoizedFn = memoize(function (a, b) {* callCount += 1;* return a + b;* })* memoizedFn(2, 3) // 5* memoizedFn(2, 3) // 5* console.log(callCount) // 1 */
因为上一道题的官方题解里面有记忆函数的知识点,所以这道题写出来了。
学习官方题解
知识点
1. 记忆函数只对纯函数有效。
纯函数: 相同的输入,会产生相同的输出。不会函数外部世界产生了影响,或者依赖了外部世界的状态
举例子:
例子一:相同的输入,没有产生相同的输出的函数Date.now()
/*** @param {Function} fn* @return {Function}*/
function memoize(fn) {let cache = {}return function() {const key = JSON.stringify(arguments)if (cache[key]!== undefined){return cache[key]}else{const result = fn(...arguments)cache[key] = resultreturn result}}
}
const getCurrentTimeMemoized = memoize(Date.now);console.log("memoized-1:", getCurrentTimeMemoized()); // 真正调用 Date.now()
console.log("normal-1:", Date.now()); // 普通调用setTimeout(() => {console.log("memoized-2:", getCurrentTimeMemoized());console.log("normal-2:", Date.now());
}, 20); // 延时20毫秒
输出为
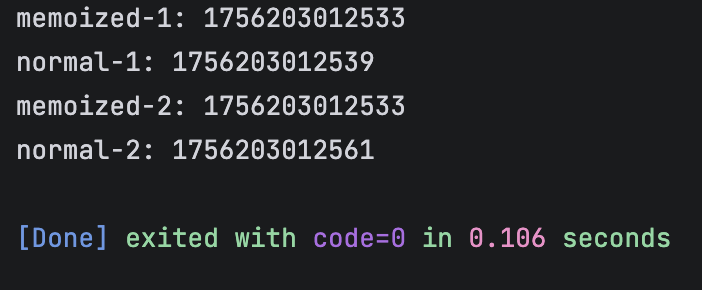
从输出可以看见,memoized-1,memoized-2应用了记忆函数,memoized-2的调用结果与memoized-1是相同的。但是Date.now()本来时得到时间戳的函数,不同的时间调用,输出还相同这就没有意义了。所以相同的输入,没有产生相同的输出的函数不能应用记忆函数。
例子二:对函数外部世界产生影响。上传数据(数据库多了数据)。
/*** @param {Function} fn* @return {Function}*/
function memoize(fn) {let cache = {}return function() {const key = JSON.stringify(arguments)if (cache[key]!== undefined){return cache[key]}else{const result = fn(...arguments)cache[key] = resultreturn result}}
}
function uploadRow(row) {// 上传逻辑
}const memoizedUpload = memoize(uploadRows);
memoizedUpload('Some Data'); // 成功上传
memoizedUpload('Some Data'); // 第二次调用,由于有相同的输入,所以什么都不会发生。
第一次调用memoizedUpload时,数据将正确上传到数据库,但每次后续调用都不会再上传数据了。这样写明显是不合理的。所以对函数外部世界产生了影响,或者依赖了外部世界的状态的函数不可以应用记忆函数。
2. 在Web开发中的记忆化用途
- 缓存网站文件。
网站通常是由js文件组成的,访问网站的不同页面时候,会动态下载这些文件。有时会采用一种模式,其中文件名基于文件内容的哈希值。这样,当 Web 浏览器请求已经在之前请求过的文件名时,它可以从磁盘上本地加载文件,而不必重新下载它。 - React 组件
React 是一个非常流行的用于构建用户界面的库,尤其适用于单页面应用程序。其核心原则之一是将应用程序分解为单独的 组件。每个组件负责渲染应用程序HTML的不同部分。
例如,你可能有一个组件如下:
const TitleComponent = (props) => {return <h1>{props.title}</h1>;
};
上面的函数将在每次父组件渲染时调用,即使 title 没有更改。通过在其上调用 React.memo,可以提高性能,避免不必要的渲染。
const TitleComponent = React.memo((props) => {return <h1>{props.title}</h1>;
});
现在,TitleComponent 只有在 title 发生变化时才会重新渲染,从而提高了应用程序的性能。
3. 缓存 API 调用
假设你有一个函数,用于向API发送网络请求以访问数据库中的键值对。
async function getValue(key) {// 数据库请求逻辑
}
const getValueMemoized = memoize(getValue);
现在,getValueMemoized 将仅为每个键进行一次网络请求,可能大大提高性能。可是我们之前说了,依赖与外部环境的函数不可以用记忆函数,原因是,当数据库发生变化后去请求数据的时候,拿到的还是原来的数据,所以要有额外的操作来确保得到最新的数据。
通常有三种方法。
- 方法一:始终发出api请求,询问是否值已经发生了变化。
这里指的是 做一个“条件请求”。
比如 HTTP 协议里有 ETag 或 Last-Modified 机制:
请求时带上 “上次拿到的版本号” 或 “修改时间”。
服务器会返回:
如果值没变:返回 304 Not Modified,告诉你可以继续用缓存。
如果值变了:返回新的数据。
👉 优点:数据总是最新的。
👉 缺点:每次还是要发请求,只是有时能节省响应体流量。 - 方法二:使用 WebSocket 订阅数据库中值的更改
思路:让服务器主动“推送变化”。
例如:
前端通过 WebSocket 订阅 “user:123” 的值。
数据库一旦更新了 “user:123”,服务器就立刻通过 WebSocket 通知前端。
前端收到消息后,更新缓存里的数据。
👉 优点:数据实时、同步更新。
👉 缺点:要额外维护 WebSocket 连接,系统复杂度增加。 - 方法三:为值提供过期时间
即缓存里加一个“有效期”。
例如:
第一次请求 “user:123” 时缓存下来,并记录“5分钟后过期”。
5分钟内重复请求,直接用缓存。
超过 5分钟,再请求时就重新向 API 获取新值,并刷新缓存。
👉 优点:实现简单,减少频繁请求。
👉 缺点:在过期时间内,数据可能仍然是旧的。
3. 算法中的记忆化
记忆化的一个经典应用是动态规划,动态规划是将一个问题分解成若干个小问题,这些小问题可以为函数的调用,当一个函数被多次调用且有相同输入的时候,使用记忆函数可以提高性能。斐波那契函数是一个很好的例子。
function fib(n) {if (n <= 1) return n;return fib(n - 1) + fib(n - 2);
}
fib(100); // 耗时多年
上面的代码非常低效,时间复杂度为 O(1.6 的n次方)(1.6是黄金比率)。时间复杂度为啥是它我是真的没有搞明白,太难了。
但是,通过不再使用相同的输入两次调用 fib,我们可以在 O(n) 的时间内计算斐波那契数。这个原因我知道,通过记忆化,每个 fib(k)(0≤k≤n)只会被实际计算一次,总计算量是 O (n) 级别的,因此时间复杂度优化到了 O (n)。
const cache = new Map();
function fib(n) {if (n <= 1) return n;if (cache.has(n)) {return cache.get(n);}const result = fib(n - 1) + fib(n - 2);cache.set(n, result);return result;
}
fib(100); // 几乎立即解决
这里还会有一个问题,为什么这个斐波那契记忆化的写法不行上述写个memorize()函数,调用memorize再返回一个函数来实现,就像下面的写法。
// 通用记忆化工具:包装一个函数,让其结果被缓存
function memoize(fn) {const cache = new Map();return function(n) {if (cache.has(n)) return cache.get(n);const result = fn(n); // 调用原始函数cache.set(n, result);return result;};
}// 原始的、不带缓存的fib
function fib(n) {if (n <= 1) return n;// 关键:这里调用的fib是"原始的、不带缓存的fib"return fib(n - 1) + fib(n - 2);
}// 用memoize包装原始fib,得到"记忆化版本"
const memoizedFib = memoize(fib);
此时如果调用memoizedFib(100),会发生什么?
- memoizedFib(100)会先查自己的缓存(空),然后调用fib(100)(原始函数)。
- 原始fib(100)会递归调用fib(99)和fib(98)—— 但注意:这里的fib是原始的、不带缓存的 fib(不是memoizedFib)。
- 因此,fib(99)和fib(98)的计算完全没有缓存,会继续递归调用更小编号的fib(都是原始版本),导致所有子问题重复计算。
- 最终,memoizedFib的缓存里只会存一个键(100),但所有子问题(99、98、…、2)都没有被缓存,效率和原始版本一样低(O (1.6ⁿ))。
核心原因:函数的 “自我引用” 无法被外部包装修改
原始fib函数内部的递归调用写的是fib(n-1),这个fib指向的是定义时的原始函数,以为没有给他套一层memorizedFib函数。
就像:你给一个人(原始fib)穿了件外套(memoizedFib),但这个人做事时(递归调用),还是用自己的手(原始fib),而不是外套的手(memoizedFib)。外套只能管最外层的调用,管不了里面的动作。
学习官方的解题方法
方法 1:使用 Rest/Spread 语法 + JSON.stringify()
function memoize(fn) {const cache = {};return function(...args) {const key = JSON.stringify(args);if (key in cache) {return cache[key];}const functionOutput = fn(...args);cache[key] = functionOutput;return functionOutput;}
}
方法 2:使用参数语法
function memoize(fn) {const cache = {};return function() {// 将参数转换为字符串let key = '';for (const arg of arguments) {key += ',' + arg;}if (key in cache) {return cache[key];}const functionOutput = fn(...arguments);cache[key] = functionOutput;return functionOutput;}
}
方法 3:基于数字约束进行优化 + Function.apply
假设你有两个数字 a 和 b,a,b不会大于 100,000,并且希望将它们转换为一个唯一的数字,使得没有其他值的a和b映射到相同的数字。你可以使用公式 key = a + (b * 100001)。
function memoize(fn) {const cache = new Map();return function() {let key = arguments[0];if (arguments[1]) {key += arguments[1] * 100001;}const result = cache.get(key);if (result !== undefined) {return result;}const functionOutput = fn.apply(null, arguments);cache.set(key, functionOutput);return functionOutput;}
}
这里的fn.apply也可以不同,因为fn函数并不需要使用this,用了也不会出错。
方法四:一行代码
为了展示 JavaScript 提供的一些语法,以下是一种一行代码的解决方案。让我们看看代码的不同部分,以了解它是如何工作的。
- var memoize = (fn, cache = {}) => (…args) => 定义了 memoize 函数,它接受两个参数:一个函数 fn 和一个可选的缓存对象 cache。由于永远不会传递第二个参数,cache将始终设置为一个空对象 {}。
- memoize 函数继续返回另一个函数,它接受任意数量的参数。
- ?? 这是 Nullish 合并运算符。仅当左侧的第一个操作数不为 null 或 undefined 时,它才会返回左侧的第一个操作数。否则,它将返回右侧的第二个操作数。
- cache[args.join()] 将参数转换为逗号分隔的字符串,并返回与该键关联的值。如果值不存在,则返回 undefined(导致函数返回右侧的值)。
- (cache[args.join()] = fn(…args)) 将缓存中的键设置为提供的函数的输出。然后返回该值。如果存在缓存未命中,将执行此代码。
var memoize = (fn, cache = {}) => (...args) => cache[args.join()] ?? (cache[args.join()] = fn(...args))
作者:力扣官方题解
链接:https://leetcode.cn/problems/memoize/solutions/2505885/ji-yi-han-shu-by-leetcode-solution-jtop/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:力扣官方题解
链接:https://leetcode.cn/problems/memoize/solutions/2505885/ji-yi-han-shu-by-leetcode-solution-jtop/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。