【资讯】国内免费/开源大模型对比及获得途径总结
📚前言
「在中国可免费使用」的大模型分成两类:
-
可下载权重、本地离线部署(真正“免费”且可控);
-
云端 API 有免费额度(更省事,但受配额与网络影响)。
一、可本地部署的免费/开源权重模型(推荐入门从这类开始)
综合比较
注:显存/内存是经验值,以常见 4bit/8bit 量化推理为参考;上下文长度取自官方模型卡或技术博文;许可证只列出官方声明要点,实际以模型卡为准。
| 模型(组织) | 典型规模 | 上下文长度 | 许可证/商用 | 入门硬件建议(大致) | 优点 | 可能的短板 |
|---|---|---|---|---|---|---|
| Qwen2.5-Instruct(阿里) | 7B / 14B / 32B… | 多数 128K;另有 1M 长上下文变体 | 多数 Apache-2.0;少数用 Qwen 许可 | 7B:4bit≈6–8GB;14B:4bit≈12–16GB | 中文综合能力强、工具/结构化输出好,长上下文选择多 | 14B 以上对显存和推理引擎配置更讲究。 Hugging Face+1Qwenqianwen-res.oss-cn-beijing.aliyuncs.com |
| InternLM2.5(书生·浦语)(上科大/上研院等) | 1.8B / 7B / 20B | 提供 1M 上下文版本 | 开源权重(详见模型卡) | 7B:4bit≈6–8GB;20B:4bit≥20GB(更建议多卡) | 推理/数学强,中文表现佳;有官方 LMDeploy 适配 | 20B 本地部署门槛较高。 Hugging Face+1GitHub |
| GLM-4-9B(智谱) | 9B | 模型卡标注 128K | 自有许可证(可下载使用) | 4bit≈10–12GB;8bit≈18GB | ChatGLM 系列迭代,中文友好,工程生态成熟 | 9B 量级对 8GB 显存略吃紧。 Hugging Face+1 |
| Yi-1.5(零一万物 01.AI) | 9B / 34B | (官方长上下文版本可选;以模型卡为准) | Yi License | 9B:4bit≈10–12GB;34B:4bit≥24GB | 中文流畅、长文本/写作稳健,社区生态活跃 | 34B 对显存与推理性能要求较高。 GitHubHugging Face |
| Baichuan 2(百川) | 7B / 13B | (以模型卡为准) | 明确可商用(见仓库声明) | 7B:4bit≈6–8GB;13B:4bit≈12–16GB | 经典中文模型,指令遵循稳定 | 相比新一代模型,推理与代码能力略弱。 Reddit |
| MiniCPM-3(OpenBMB) | 4B | (以模型卡为准) | 声称适配消费级 GPU/本地端侧 | 4bit≈4–6GB;可 CPU 跑但较慢 | 体量小、门槛低,适合轻量设备与入门 | 复杂推理与长上下文能力有限。 Hugging Face |
| XVERSE-13B(深圳元象) | 13B | (以模型卡为准) | Apache-2.0 | 4bit≈12–16GB | 中文知识覆盖好,许可证宽松 | 代际稍老,长上下文与工具生态相对一般。 Hugging Face |
| ERNIE 4.5(部分)(百度) | 0.3B(稠密)/ MoE 变体 | (见技术博文/模型卡) | Apache-2.0(官方宣称) | 0.3B:可 CPU ;大型 MoE 需多卡 | 官方宣布开源一系列模型,Paddle/FastDeploy 工具链完善 | 大型 MoE 本地部署门槛高;PyTorch/Paddle双生态需选型。 yiyan.baidu.com |
| DeepSeek-Coder 系列(深度求索) | 1.3B–33B | (以模型卡为准) | MIT/自有许可并存(看具体卡) | 7B 左右 4bit≈6–8GB | 代码任务强、中文注释/讨论好 | 通用对话能力需结合别的通用模型。 知乎专栏 |
关于显存的两个实用经验(适合快速估算,不依赖特定模型):
-
7B 参数:4bit 推理通常需要 ~6–8GB 显存;8bit 约 ~10–12GB。13–14B 则翻倍到 ~12–16GB(4bit)。
-
长上下文会额外吃显存(KV Cache 占用与输入序列长度成正比);把
max_tokens、batch_size适当收紧能显著降低占用。
(以上为通用部署经验,实际取决于推理引擎与量化方案)
部分模型不同型号硬件资源一览表
| 模型名称 | 参数量(约) | 最低内存要求 (Q4量化) | 硬盘空间 (Q4量化) | 硬件依赖 (最低配置) | 主要特点与优势 | 主要局限性与劣势 | 中文能力 | 许可证 |
|---|---|---|---|---|---|---|---|---|
| Qwen1.5-0.5B | 5亿 | 1 GB | 0.4 GB | CPU (近5年产品) | 极致轻量,中文优化好,老旧设备也能运行 | 能力相对简单,复杂任务处理有限 | ⭐⭐⭐⭐ | Apache 2.0 |
| Qwen1.5-7B | 70亿 | 6 GB | 4.1 GB | GPU (6GB VRAM) 或 CPU (8GB RAM) | 在中文任务上表现非常优秀,综合能力强于同尺寸模型 | 相对更大的资源消耗 | ⭐⭐⭐⭐⭐ | Apache 2.0 |
| DeepSeek LLM-7B | 70亿 | 6 GB | 4.1 GB | GPU (6GB VRAM) 或 CPU (8GB RAM) | 代码和数学推理能力突出,通用对话能力也不错 | 非多模态 | ⭐⭐⭐⭐ | MIT License |
| ChatGLM3-6B | 62亿 | 6 GB | 3.8 GB | GPU (6GB VRAM) 或 CPU (8GB RAM) | 支持工具调用(Function Call)和智能体(Agent)任务,对话流畅自然 | 复杂推理和能力相对较弱 | ⭐⭐⭐⭐ | Apache 2.0 |
| InternLM2-7B | 70亿 | 6 GB | 4.1 GB | GPU (6GB VRAM) 或 CPU (8GB RAM) | 在长文本理解(可达200K上下文)和知识问答方面有优势,通用能力均衡 | 创作和代码能力相对非顶尖 | ⭐⭐⭐⭐ | Apache 2.0 |
| Gemma-2B | 20亿 | 2 GB | 1.4 GB | CPU (4GB RAM) | Google出品,架构先进,英语能力优异,非常适合教育研究和入门体验 | 中文能力相对较弱,需额外优化 | ⭐⭐ | Apache 2.0 |
| Microsoft Phi-3-mini | 38亿 | 4 GB | 2.2 GB | CPU (4GB RAM) 或 GPU (4GB VRAM) | “小钢炮”之王,3.8B参数带来7B级模型的体验,代码和推理能力强劲2 | 在非常复杂的多步推理上可能仍有不足 | ⭐⭐⭐ | MIT License |
| 枫清科技Fabarta智能体 | 未公开 | 未公开 | 未公开 | 支持纯本地部署1 | 聚焦用户个性化AI需求,支持纯本地部署保障数据安全,提供知识库问答、长文写作等功能1 | 目前公开信息较少,模型能力和社区生态待评估 | (待评估) | (需查阅用户协议) |
🧠 关于“量化”的说明
表格中的“最低内存要求”通常指经过4位整数(Q4)量化后的需求。量化是一种模型压缩技术,能在轻微损失模型性能的情况下,显著降低模型对内存和存储空间的需求,使得大模型在消费级硬件上运行成为可能。
二、硬件需求详解
大模型本地部署的硬件需求,主要取决于你选择以 CPU模式 还是 GPU模式 运行。
1. CPU模式 (纯CPU运行)
这是门槛最低的方式,几乎所有电脑都能尝试。
-
内存 (RAM):这是最重要的指标。模型会完全加载到内存中。
-
计算公式:所需内存 ≈ 模型参数量 * 量化位数 / 82
-
例如,一个Q4量化(4-bit)的7B模型:
7 * 10^9 * 4 / 8 = 3.5 GB。加上系统和推理开销,需要至少 6-8 GB 的物理内存2。 -
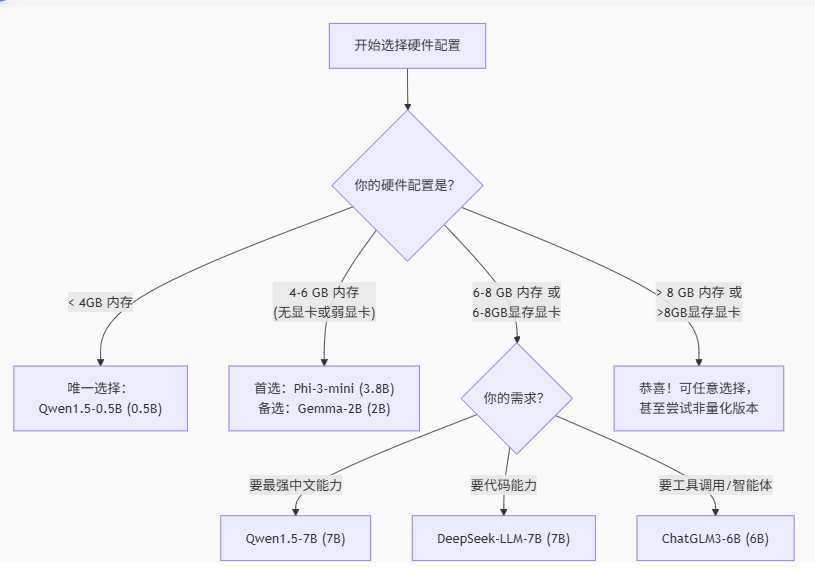
建议:8GB内存是运行7B以下模型的舒适起点。4GB内存可运行2B以下的模型(如Qwen1.5-0.5B或Gemma-2B)。
-
-
中央处理器 (CPU):核心数越多,推理速度越快。现代CPU(Intel i5/i7/R5/R7,近5年产品)均可。
-
建议:支持AVX2指令集的CPU会有显著加速效果(绝大多数2013年后的CPU都支持)。
-
-
硬盘:只需存放模型文件的空间,通常为1GB至6GB不等。
2. GPU模式 (有入门级显卡)
利用GPU可以显著提升推理速度。
-
显存 (VRAM):模型会全部加载到显存中,显存大小直接决定了你能运行什么模型。
-
Q4量化模型显存占用公式:所需显存(GB) ≈ 模型参数量(B) * 0.52
-
7B模型 ≈ 3.5 GB,8B模型 ≈ 4 GB。
-
“甜品级”显卡:NVIDIA GTX 1660、RTX 2060、RTX 3060 (12GB版)。它们的显存在6GB-12GB,是运行这些轻量级模型的性价比之王。
-
-
GPU:必须是NVIDIA显卡(因其CUDA生态)。显卡架构越新(如30系、40系),效率越高。
你可以参考下面的流程图,快速判断自己的设备适合运行哪个类型的模型2:
三、大模型获取与下载(官方渠道与直链)
3.1 各模型下载综合说明
- ChatGLM-6B
- 简介:由清华大学知识工程实验室(KEG)与智谱 AI 联合打造的支持中英双语对话的语言模型,62 亿参数。经量化后可用消费级显卡部署,INT4 量化下仅需 6GB 显存。
- 获取方式:能通过 Git 克隆其 GitHub 仓库或从 Hugging Face 下载预训练模型等。Git 克隆指令为
git clone https://github.com/thudm/chatglm-6b。若遇 GitHub 网络问题,可用 GitCode 镜像,指令是git clone https://gitcode.com/applib/ChatGLM-6B.git。还能借助transformers库的from_pretrained方法,从thudm/chatglm-6b获取。
- VisualGLM-6B
- 简介:创新多模态对话模型,语言部分基于 ChatGLM-6B,共 78 亿参数,可理解图像并依据内容对话回复。
- 获取方式:其代码与相关资源可于 GitHub 项目地址 https://github.com/thudm/visualglm-6b 获取,模型文件能参考项目文档从指定存储平台按指引下载。
- DeepSeek-R1
- 简介:有 1.5B 至 32B 等多种参数版本,针对中文场景优化,可免费用于研究或商业场景。1.5B 版本最低需 4GB 显存,32B 版本需 24GB 以上显存。
- 获取方式:能通过 Ollama 工具便捷下载部署,如运行
ollama run deepseek-r1:7b可下载运行 7B 版本。也能从其官方或可信来源下载 GGUF 等适配格式,在 LM Studio 等工具中使用,LM Studio 官网为 LM Studio - Download and run LLMs on your computer。
- MOSS
- 简介:支持中英双语与多种插件,“moss-moon” 系列 160 亿参数。适配有对应资源支持的复杂任务,对硬件显存、内存要求较高。
- 获取方式:可访问官方 GitHub 地址 https://github.com/OpenLMLab/MOSS 了解部署及获取模型文件的说明,依据其介绍下载所需特定版本模型组件。
- DB-GPT
- 简介:以数据库为基础的开源项目,确保数据交互的隐私安全,可构建数据库相关私有大模型方案。
- 获取方式:能通过克隆其开源项目地址获取相关文件,再按需下载适配的基础模型等,其 GitHub 链接为 https://github.com/csunny/DB-GPT。
3.2 一键/命令行获取示例(适用于多数模型)
# 1) 使用 ModelScope Python API
pip install -U modelscope
python - <<'PY'
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct', cache_dir='./models')
print(model_dir)
PY# 2) 使用 Hugging Face CLI(备选)
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen2.5-7B-Instruct --local-dir ./models/Qwen2.5-7B-Instruct --exclude "*/original/*"# 3) GGUF(适合 CPU / llama.cpp / Ollama)
# Qwen2.5 提供 GGUF 变体(也常见于各模型库中的 GGUF 分发)
# 说明文档(含 GGUF/AWQ 规格与引擎支持):
# https://inference.readthedocs.io/en/v1.1.0/models/builtin/llm/qwen2.5-instruct.html
(Qwen 2.5 的 GGUF/AWQ 规格与可用引擎在文档中列出;可用 vLLM、Transformers、llama.cpp、SGLang 等。inference.readthedocs.io)
3.3 使用 Ollama(推荐新手和快速入门)
Ollama是一个开源的大型语言模型服务工具,简化了在本地运行和管理大语言模型的过程4。
-
操作步骤:
-
下载安装:访问 Ollama官网,下载并安装对应操作系统的客户端24。
-
拉取模型:安装完成后,在终端(命令行)中输入一行命令即可下载并运行模型。Ollama会自动下载优化好的模型版本。
-
交互使用:之后便可与模型进行交互。
你可以使用下表所示的命令来获取不同的模型:
-
| 模型名称 | Ollama拉取命令 | 备注 |
|---|---|---|
| Qwen1.5-0.5B | ollama run qwen:0.5b | |
| Qwen1.5-7B | ollama run qwen:7b | |
| DeepSeek LLM-7B | ollama run deepseek-llm:7b | 注意不是 deepseek-coder |
| ChatGLM3-6B | ollama run chatglm3 | |
| InternLM2-7B | ollama run internlm2:7b | |
| Gemma-2B | ollama run gemma:2b | |
| Microsoft Phi-3-mini | ollama run phi3 |
-
最新UI界面:Ollama目前已发布图形化UI界面,安装后可通过浏览器访问
http://localhost:11434进行操作和管理,告别命令行4。
3.4 使用 Hugging Face Transformers(推荐开发者)
Hugging Face是最大的AI模型社区,提供了最直接的模型下载和代码调用方式。
-
操作步骤:
-
访问仓库:访问 Hugging Face官网,在搜索框中输入模型名称(如 "Qwen1.5-7B")。
-
找到模型页:进入对应的模型仓库页面(例如 https://huggingface.co/Qwen/Qwen1.5-7B)。
-
下载模型:
-
方式一(代码自动下载):使用
snapshot_download库或git lfs命令。 -
方式二(手动下载):在仓库页面找到 "Files and versions" 选项卡,手动下载需要的模型文件(通常是
.safetensors或.bin文件以及配置文件)。
-
-
代码调用:使用
transformers库加载模型。
-
Python代码示例:
# 示例:使用 transformers 调用 Qwen1.5-7B
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen1.5-7B" # 替换为你想用的模型ID
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto") # device_map="auto" 可自动分配至GPUinputs = tokenizer("北京的景点有:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))3.5 其他方式
-
ModelScope(模搭):阿里达摩院推出的中文模型社区,对国产模型支持友好,下载速度可能更快。官网链接
-
vLLM:一个专为高效推理服务设计的高吞吐量推理引擎。如果你关注推理速度和高并发,可以尝试vLLM。GitHub链接
3.6 国内下载的几个方面
1). 国内可访问的主流模型下载渠道
| 渠道 | 网址 | 特点 | 适用模型 | 获取示例 |
|---|---|---|---|---|
| Hugging Face 镜像站 | hf-mirror.com | Hugging Face 国内加速镜像,支持 .gguf、PyTorch 等格式,速度快 | Qwen、DeepSeek、LLaMA、Baichuan 等 | bash\ export HF_ENDPOINT=https://hf-mirror.com\ huggingface-cli download deepseek-ai/DeepSeek-R1-Distill --local-dir ./models |
| 阿里魔搭社区(ModelScope) | modelscope.cn | 国内最大开源模型平台,免翻墙,支持在线体验+本地下载 | Qwen、ChatGLM、InternLM、Baichuan 等 | python\ from modelscope.hub import snapshot_download\ snapshot_download('qwen/Qwen2.5-7B-Instruct', cache_dir='./models') |
| Gitee AI | ai.gitee.com | 国内代码托管平台的 AI 子站,部分模型镜像 | ChatGLM、Baichuan、InternLM 等 | 网页直接下载或 git clone |
| 始智 AI(WiseModel) | wisemodel.cn | 模型资源丰富,下载速度快 | Qwen、DeepSeek、MiniCPM 等 | 网页直链下载 |
| AI 快站 | aifasthub.com | Hugging Face 模型加速下载服务 | Hugging Face 上的各类模型 | 按网站提供的命令执行 |
2). 常见开源模型及直达页面
| 模型 | 国内直达地址 | 说明 |
|---|---|---|
| Qwen 2.5 系列 | ModelScope Qwen | 阿里出品,中文/中英双语强,支持多模态 |
| DeepSeek R1-Distill | HF 镜像 DeepSeek | 推理与代码能力强,量化后低显存可跑 |
| ChatGLM3/GLM4 | ModelScope ChatGLM | 中文对话优化,低显存友好 |
| Baichuan 2 系列 | ModelScope Baichuan | 中文语料扎实,商用需申请 |
| Yi 系列 | ModelScope Yi | 长文本能力好,许可友好 |
| InternLM 2.5 | ModelScope InternLM | 研发文档全,科研与工程兼顾 |
| MiniCPM | WiseModel MiniCPM | 轻量高效,端侧友好 |
3). 下载与部署小贴士
-
优先选国内镜像:Hugging Face 镜像站、ModelScope、WiseModel 等,避免直连
huggingface.co。 -
量化优先:下载
.gguf(llama.cpp 系)或 INT4/INT8 量化权重,显存占用大幅降低。 -
目录规划:建议统一放在
~/models或D:\AI\models,方便多工具共用。 -
工具链配合:
-
Windows GUI:LM Studio、Open WebUI(配 Ollama)
-
命令行:
llama.cpp、text-generation-webui、vLLM
-
-
校验文件完整性:下载后用
sha256sum或平台提供的哈希值验证,防止权重损坏。
3.7 典型模型下载途径推荐
建议优先使用 ModelScope(魔搭):支持断点续传、在国内速度更稳定;同时给出 Hugging Face 备选。
Qwen 2.5(通义千问)
# ModelScope(推荐)
https://www.modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct https://www.modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct # 1M 长上下文 https://www.modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct-1M https://www.modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M # Hugging Face 备选 https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
https://huggingface.co/Qwen/Qwen2.5-14B-Instruct
(Qwen 2.5 介绍与 1M 上下文说明见官方博客;Qwen 仓库含许可与生态指引。ModelScope+2ModelScope+2ModelScopeHugging Face+1QwenGitHub)
InternLM2 / InternLM2.5(书生·浦语)
# ModelScope
https://www.modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-7b https://www.modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-chat-20b https://www.modelscope.cn/models/Shanghai_AI_Laboratory/internlm2_5-7b-chat-1m # GitHub(发布/文档)
https://github.com/InternLM/InternLM
(模型卡提到超长上下文、版本与规格;GitHub 为官方入口。ModelScope+2ModelScope+2GitHub)
GLM 系列(智谱)
# ChatGLM3-6B(门槛低)
https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b-base # GLM-4-9B(对话/多语言/长上下文)
https://www.modelscope.cn/models/ZhipuAI/glm-4-9b-chat-1m # GLM-4-Voice-9B(端到端语音)
https://www.modelscope.cn/models/ZhipuAI/glm-4-voice-9b
(GLM-4-9B 模型卡含 1M/128K 长上下文与功能描述;ChatGLM3-6B 提供基础/对话权重。ModelScope+2ModelScope+2)
Yi(01.AI)
# Hugging Face(官方组织)
https://huggingface.co/01-ai
(Yi-6B/9B/34B 多版本集中在 01-ai 组织下。ModelScope)
Baichuan2(百川)
# ModelScope
https://www.modelscope.cn/models/baichuan-inc/Baichuan2-7B-Base https://www.modelscope.cn/models/baichuan-inc/Baichuan2-13B-Base
(Baichuan2 系列开放 7B/13B 的 Base/Chat 权重。ModelScope)
XVERSE(元象)
# ModelScope(组织页)
https://www.modelscope.cn/organization/xverse
(组织页可进入 XVERSE-7B/13B/32B 等模型详情与下载。ModelScope)
MiniCPM(OpenBMB)
# ModelScope(组织页,含 MiniCPM 各代)
https://www.modelscope.cn/organization/OpenBMB
(MiniCPM 主打轻量端侧,适合低资源场景。Hugging Face)
DeepSeek(开源蒸馏系列)
# Hugging Face(官方组织)
https://huggingface.co/deepseek-ai
(含 R1-Distill-Qwen-7B/14B、V3 等多款可下载权重。Hugging Face)
四、国内可用的免费额度 API(更省事)
| 平台 | 代表模型 | 免费情况(以官方说明为准) | 适合人群 |
|---|---|---|---|
| 阿里云 Model Studio(百炼/通义) | Qwen 家族、工具链 | 提供免费体验额度(需账号/实名认证);也提供托管推理与模型市场 | 想先云端试跑 Qwen,不想自己配环境的用户。 阿里云帮助中心 |
| 腾讯混元 | Hunyuan | 有免费额度与多种付费档位(按需/订阅) | 想用微信/企业生态集成与腾讯云资源的团队。 main.qcloudimg.com |
| 火山引擎·豆包 | Doubao 系列 | 文档明确提供免费额度(不同模型/地域有差异) | 抖音/字节生态与向量/多模态一体化调用。 火山引擎 |
| 百度千帆 | 文心(ERNIE)系列 | ERNIE 4.0 无免费额度(其他型号以控制台为准) | 想用文心生态/飞桨工具链的团队。 千帆大模型平台 |
部署成本对比
| 模型类型 | 免费额度 | 付费成本(每千 Token) | 私有化部署成本(月 / 节点) |
|---|---|---|---|
| 文心一言 | 100 万 Token / 月 | 0.05 元 | 5 万元(RTX 4090*4) |
| 通义千问 | 100 万 Token / 月 | 0.04 元 | 4.2 万元(A100*2) |
| 讯飞星火 | 50 万 Token / 月 + 100 小时语音 | 0.06 元 | 6 万元(RTX 6000 Ada*1) |
| ChatGLM | 无限制(开源) | 0 | 1.2 万元(RTX 3090*1) |
| DeepSeek-R1 | 450 元体验金(约 1 亿 Token) | 0.03 元 | 8 万元(H100*4) |
五、选择参考
依据硬件(新手参考)
-
只有 CPU 或 ≤6GB 显存笔记本 → 先试 MiniCPM-3(4B)、或 Qwen/InternLM 的 GGUF 4bit(用 llama.cpp/LM Studio/Ollama)。追求中文对话顺滑,尽量选 Instruct 变体。 Hugging Face+2Hugging Face+2
-
8–12GB 显存(如 RTX 3060/4060 笔记本) → Qwen2.5-7B-Instruct(4bit) 或 InternLM2.5-7B-Chat(4bit),上下文需求高可试 128K/1M 版本(注意显存)。 Hugging Face+1
-
16–24GB 显存(如 RTX 3090/4090 单卡) → 升级到 Qwen2.5-14B / Yi-1.5-9B 的更高精度(8bit 或混合精度),中文写作/工具使用会更稳。 Hugging FaceGitHub
-
不想本地折腾 → 直接选阿里/硅基的免费额度 API先调通,再考虑迁移到本地或自建推理。
选型要点(避坑清单)
-
许可证与商用:Qwen2.5 多数 Apache-2.0,但部分型号采用 Qwen License / Research License;Yi 采用 Yi License;Baichuan2 仓库声明可商用。商业上线前务必核对具体模型卡与许可证。 QwenGitHubReddit
-
长上下文 ≠ 随便拉满:Qwen/InternLM 都有 1M 上下文版本,但推理引擎(如 vLLM/LMDeploy)默认可能只开到 32K,需要按文档启用扩展策略,并留意显存压力。 RedditHugging Face
-
推理引擎影响巨大:vLLM(CUDA)、LMDeploy、llama.cpp(GGUF)各有优劣;量化方案(GPTQ/AWQ/GGUF)也会改变显存与速度。官方模型卡/文档通常给出建议与示例启动参数。
推理引擎与量化建议(本地部署)
-
LMDeploy:上手简单、推理/裁剪/量化工具链完善,适配 InternLM/Qwen 等,国内用户口碑好。Hugging Face
-
vLLM:高吞吐常用,适配 AWQ/GPTQ/bnb-4bit;适合服务化部署。
-
llama.cpp / Ollama:GGUF(q4_k_m 等)在 CPU/低显存设备也能跑;桌面友好。
-
TensorRT-LLM:NVIDIA GPU 上追求极致性能时考虑。
按用途给初学者的具体推荐
-
通用中文对话与写作:
-
本地: Qwen-7B/14B Instruct、Baichuan-13B、Yi-9B。
-
API: 通义千问、文心一言、混元。
-
理由: 中文指令遵循稳、生态资料多、上手顺滑。
-
-
代码与推理/数学:
-
本地: DeepSeek-R1-Distill-7B/14B、GLM 家族(9B/6B)。
-
API: DeepSeek、GLM 平台。
-
理由: 测试集中在链式推理、代码补全与错误纠正上表现更佳。
-
-
长文档与检索增强:
-
本地: Yi-34B(高配)、Qwen 长上下文变体。
-
API: Kimi、通义(带检索/工具)。
-
理由: 长上下文与检索插件成熟,摘要与结构化提取效率高。
-
-
轻量端侧/低资源设备:
-
本地: MiniCPM-2B/7B、Qwen-2B/0.5B、GLM3-6B。
-
理由: 低显存/CPU 也能用,适合移动/边缘与离线场景。
-
💎六、 总结与建议
-
如果你是初学者或硬件资源有限:
-
从 Ollama 开始,它是最简单的方式。
-
模型选择上,可以优先考虑 Qwen1.5-0.5B(硬件极差)或 Microsoft Phi-3-mini(平衡性能与资源)。
-
-
如果你有不错的硬件(≥8GB内存/显存)并追求综合能力:
-
Qwen1.5-7B 是中文任务上的强力选择。
-
DeepSeek-LLM-7B 则在代码和数学方面更胜一筹。
-
ChatGLM3-6B 适合想体验工具调用和智能体功能的用户。
-
-
如果你是研究者或开发者:
-
直接通过 Hugging Face 或 ModelScope 获取原始模型,可以获得最大的灵活性和控制权。
-
仔细阅读模型的官方文档和许可证协议,特别是商用限制。
-
-
通用建议:
-
首次尝试时,都从量化版本(如Q4)开始。
-
关注模型的许可证,特别是是否有商业使用的限制。
-
本地部署大模型需要耐心,下载模型文件和调试环境是正常过程。
-
以上为不同AI模型提供内容汇总,仅供参考。