实时平台Flink热更新技术——实现不停机升级!
挑战:为何“停止-重启”模式已无法满足现代业务需求?
在实时计算领域,数据流永不停歇,业务决策刻不容缓。然而,传统的 Flink 任务运维模式——“停止-修改-重启”——正日益成为业务连续性的瓶颈。当需要调整任务并行度、修改 SQL 逻辑或更新配置参数时,这一流程不仅会导致数据处理中断,还可能因集群重启耗时过长而错失关键的业务时机。
典型业务场景:大促期间的实时风控
某电商平台在大促期间,实时风控系统需应对激增的交易流量。原定并行度为50,但高峰期系统出现处理延迟,风险告警。若采用传统方式调整并行度:
-
停止任务并等待 Checkpoint 完成:约3分钟
-
修改配置并重启任务:约8分钟
总计11分钟的停机时间,意味着数以万计的风险交易可能无法被实时拦截,造成不可估量的损失。这暴露了传统运维模式在敏捷性和业务连续性上的严重不足。
为了解决这一痛点,袋鼠云实时计算平台深入 Flink 内核,创新性地提出了“热更新”技术方案,旨在实现任务参数的动态调整和逻辑的快速迭代,将运维操作对业务的影响降至最低。
统⼀解决⽅案:Flink 热更新技术详解
袋鼠云的 Flink 热更新技术,是一个统一的解决方案。它能够智能区分变更类型,并采用最优策略执行,从而实现效率最大化。该技术主要包含两种核心处理模式:
-
零停机调参:针对无需改变作业拓扑图(JobGraph)的参数调整,如任务并行度、Checkpoint 配置等。它通过 Flink 的 REST API 或 CLI 直接作用于正在运行的任务,实现秒级生效、业务零中断。
-
快速重启更新:针对需要改变作业拓扑图的修改,如 SQL 逻辑变更。它在 Flink Per-Job 模式下,通过复用现有 Flink 集群资源(如 JobManager、TaskManager),避免了重新申请资源和拉起集群的耗时,将原本分钟级的重启过程缩短至亚分钟级,极大提升了迭代效率。
这两种模式共同构成了热更新技术的完整能力,覆盖了从简单参数调优到复杂逻辑更新的绝大多数场景,为用户提供了兼具灵活性与稳定性的运维体验。
技术核⼼(⼀):零停机动态调参
热更新技术的核心能力之一,是在不中断任务数据流的前提下,动态修改正在运行的 Flink 作业的某些配置。这对于应对突发流量、优化资源利用率等场景至关重要。
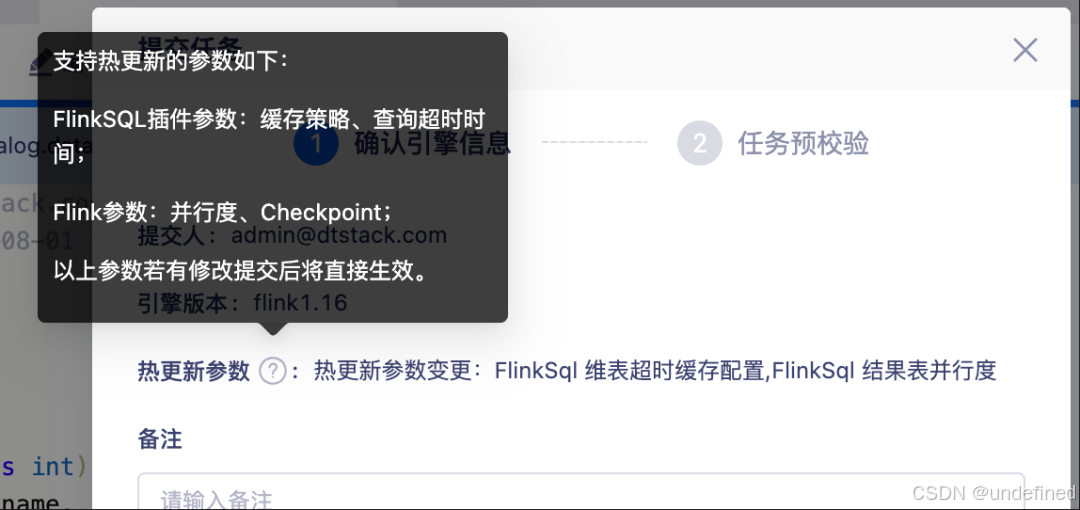
⽀持的参数范围
实时计算平台目前支持对以下两类关键参数进行零停机更新:
-
Flink SQL 操作参数:如维表缓存策略(例如从 all 切换到 lru )、异步查询超时时间等。
-
Flink 核心参数:如任务并行度、Checkpoint 间隔与超时时间等。
技术实现机制
零停机调参主要依赖 Flink 自身提供的管理接口。平台后端服务会智能识别用户提交的修改请求,并调用相应的接口。
并⾏度热更新
通过调⽤ Flink 的 RESTAPI,向指定 Job 发送 PATCH 请求即可动态调整并⾏度。
// 通过 REST API 动态调整并行度public void updateParallelism(String jobId, int newParallelism) {String url = String.format("%s/jobs/%s/parallelism", flinkRestUrl, jobId);Map<String, Integer> request = Collections.singletonMap("parallelism", newParallelism);restTemplate.patchForObject(url, request, Void.class);}
Checkpoint 参数更新
利用 Flink 命令行工具(CLI)的 modify-job 命令,可以方便地更新 Checkpoint 相关配置。
# 使用Flink CLI更新checkpoint配置flink modify-job <job-id> \--checkpoint-interval <new-interval> \--checkpoint-timeout <new-timeout> \--checkpoint-mode <EXACTLY_ONCE/AT_LEAST_ONCE>
平台架构与流程
为了提供无缝的用户体验,我们在平台层面设计了清晰的交互与处理逻辑:
(1)用户在管理界面提交参数修改请求。
(2)后端系统自动识别哪些是可零停机更新的参数,哪些需要通过快速重启
(3)在确认页面明确告知用户,哪些参数将“实时生效”,哪些将触发“快速重启流程”。
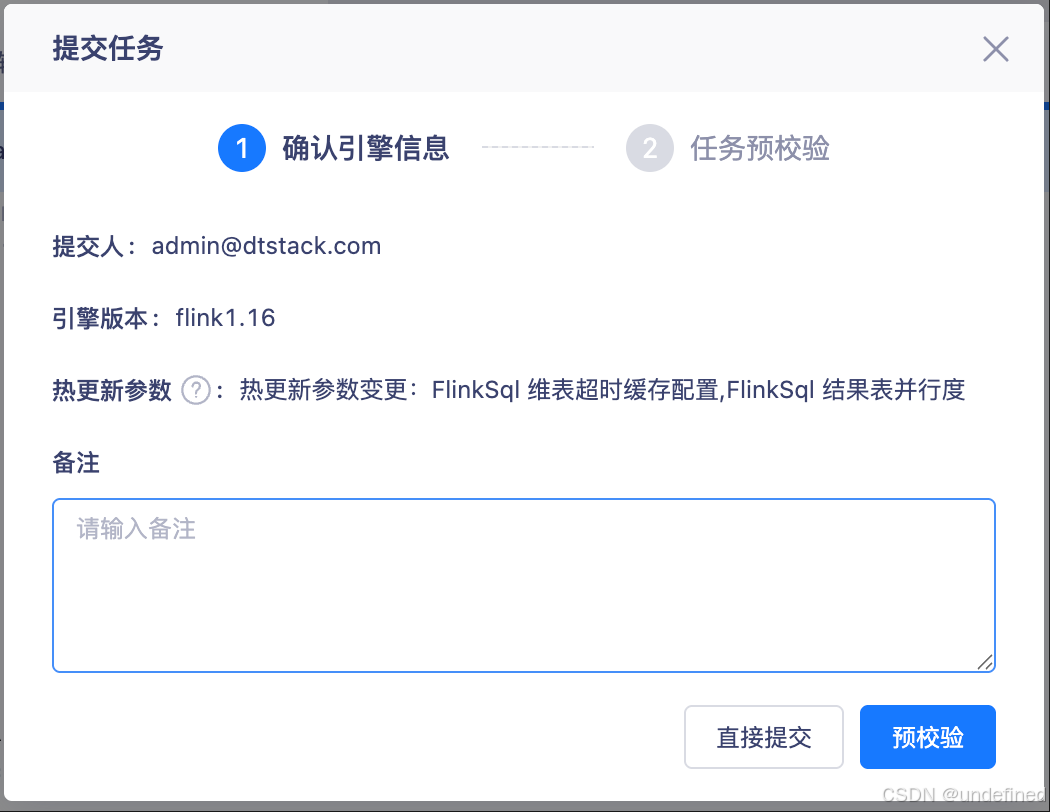
(4)用户确认后,系统分发任务:零停机参数通过 API/CLI 即时应用,其他参数则进入快速重启流程。
这一设计不仅提升了运维效率,也通过明确的标识减少了用户的困惑和误操作。
技术核⼼(⼆):快速重启 ,⾰新复杂变更的部署效率
对于需要修改 SQL 逻辑等伤筋动骨的操作,完全的零中断无法实现。此时,优化的重点便转向如何最大限度地缩短停机时间。热更新技术中的“快速重启”能力正是为此而生,它彻底改变了 Flink Per-Job 模式下的任务更新体验。
Per-Job 模式的传统困境
在标准的 Per-Job 模式下 ,每个Flink 任务都独享⼀个临时集群。更新任务意味着销毁旧集群、创建新集群 ,其耗时主要在于:
-
客户端打包、上传 Jar 文件和依赖到 HDFS。
-
向 Yarn/K8s 申请资源并启动 JobManager (AppMaster)。
-
JobManager 启动后,再向资源管理器申请 TaskManager。
整个过程耗时可达3-5 分钟,对于需要频繁迭代的开发和测试场景来说,效率极低。
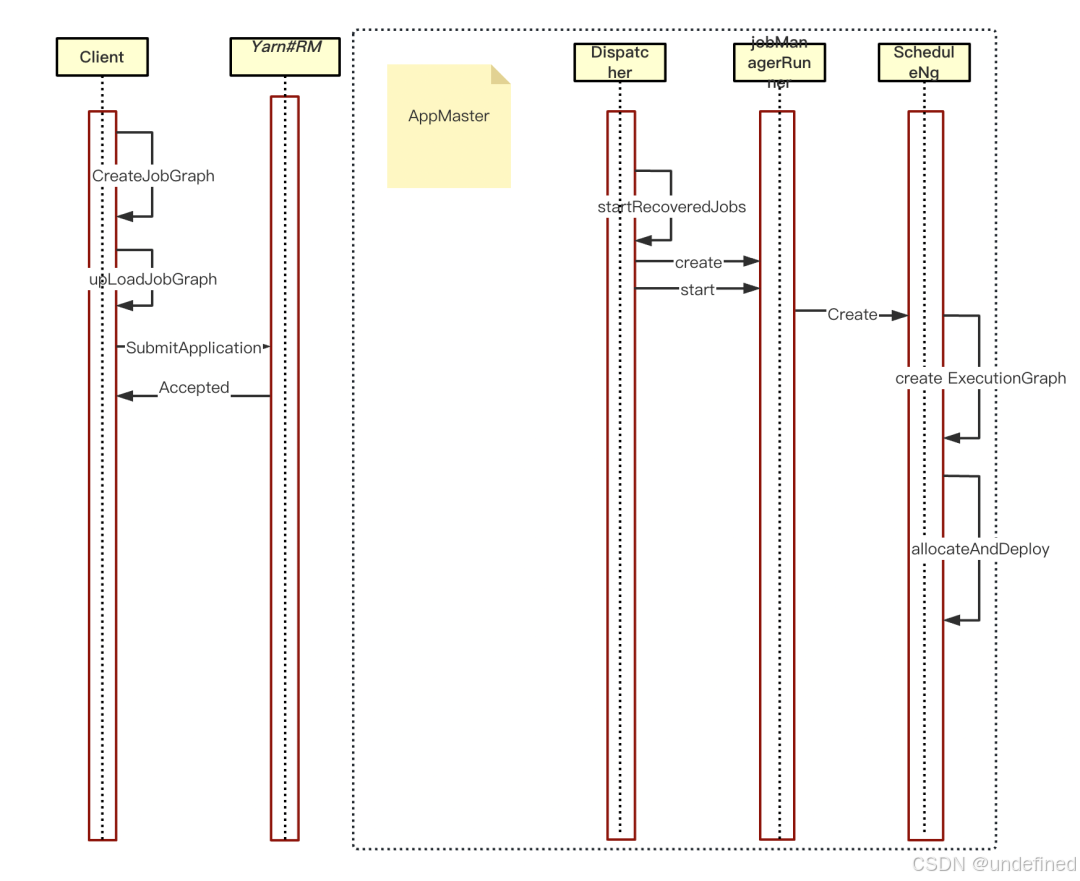
图1:传统的Per-Job任务流程
快速重启的技术创新:复⽤⼀切可复⽤之资源
快速重启的核心思想是:尽可能复用当前 Per-Job 集群的已有组件和资源,将“创建新集群”变为“在原集群内更新作业图”。这使得 Per-Job 模式具备了类似 Session 模式的快速提交能力。
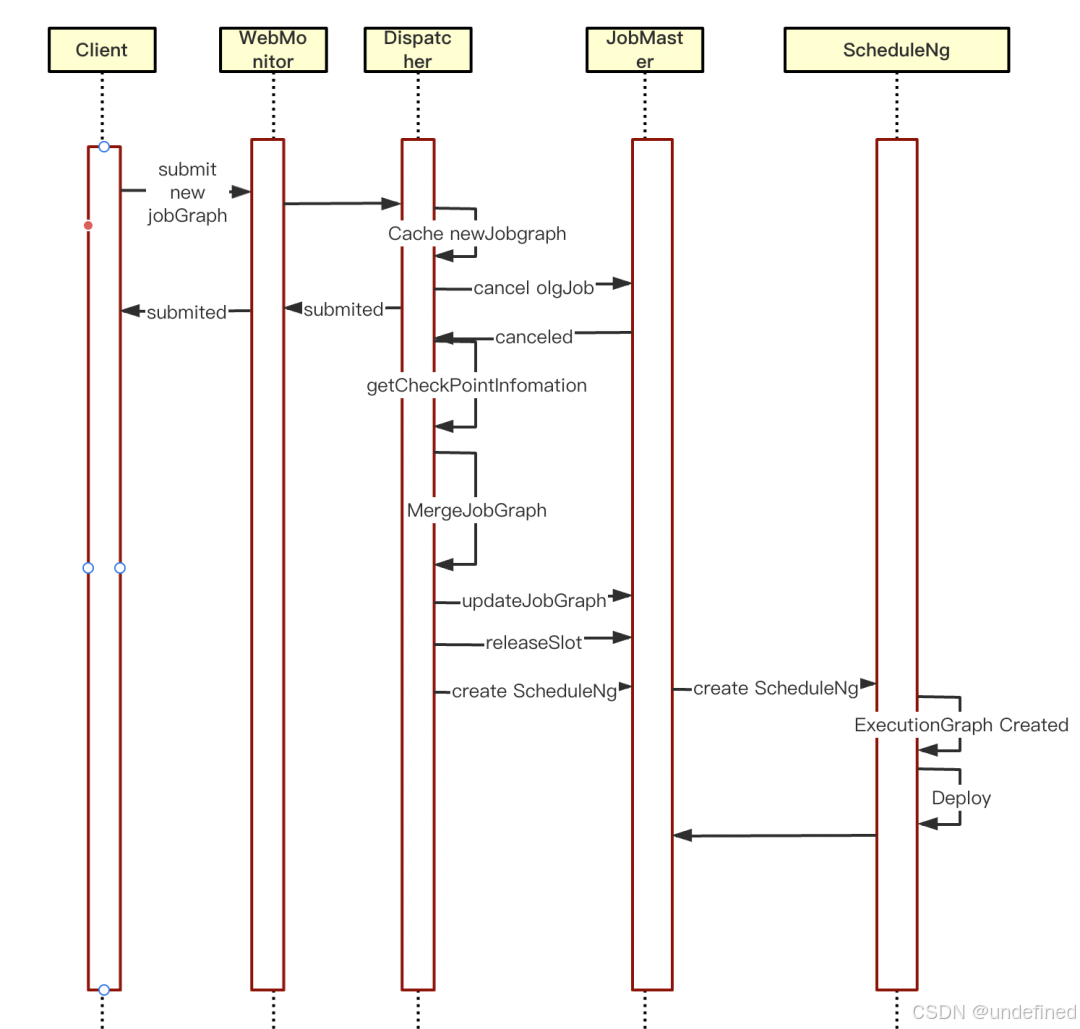
图2:采⽤快速重启技术改造后的流程
关键组件改造详解
WebMonitor 改造:打通提交入口
标准的 Per-Job 集群 WebMonitor 不接受新的任务提交。我们对其进行了改造,增加了 JobSubmitHandler,使其能够像 Session 集群一样接收新的 JobGraph。这样,客户端只需生成并提交新的作业图,无需再走一遍漫长的集群启动流程。
Dispatcher 改造:实现优雅“换核”
Dispatcher 是快速重启的指挥中心。其改造后的处理流程堪称精妙:
(1)当收到新的JobGraph提交请求时,Dispatcher 并不立即创建新任务,而是将其缓存起来。
(2)接着,它会向当前正在运行的旧任务发送cancel命令。
(3)在任务取消的异步回调(CompletableFuture)中,执行核心的重启逻辑:
-
检查是否存在缓存的新
JobGraph。 -
获取旧任务成功取消前的最后一个 Checkpoint 位点。
-
将此 Checkpoint 信息填充到新
JobGraph的恢复设置中,确保数据不丢不重。 -
通过反射等方式,将 JobMaster 中持有的旧
JobGraph替换为新JobGraph。 -
重新创建
ScheduleNG调度器,并用新的作业图来调度任务。其余组件(如 JobMaster、ResourceManager)均被复用。
通过这一系列操作,我们实现了在同一个 Flink 集群内对作业的无缝替换。
Slot 资源复用:解决资源识别难题
一个关键细节是 Slot 资源的复用。当旧任务取消后,其占用的 TaskManager Slot 会被 JobMaster 内的 SlotPool 标记为可用。但此时 TaskExecutor 内部记录的 JobID 仍然是旧的。如果新任务直接复用这些 Slot,会导致 TaskExecutor 因 JobID 不匹配而拒绝执行。
我们的解决方案是:在快速重启过程中,主动清空 JobMaster 的 SlotPool 内部缓存。这样,SlotPool 会认为自己没有可用资源,从而重新向 ResourceManager 申请 Slot。ResourceManager 收到请求后,会复用那些物理上并未释放的 TaskManager Slot,并通过 RPC 将新的 JobID 注册到 TaskExecutor 中。这样就完美解决了 Slot 的识别问题,实现了真正的资源复用。
业务价值与应⽤场景
技术创新的最终目的是服务于业务。热更新技术为企业带来了实实在在的价值。
显著的效率提升与成本节约
| 场景 | 传统方式耗时 | 袋鼠云方案耗时 | 业务影响 |
| 调整并行度应对流量高峰 | ~11 分钟 | ~30 秒 | 从业务中断到零中断 |
| 修改SQL逻辑并重新部署 | ~4-5 分钟 | < 1 分钟 | 迭代效率提升400%以上 |
核心应用场景
-
电商与直播:在大促或热门活动期间,使用热更新的“零停机调参”能力动态调整并行度,平稳应对流量洪峰,保障用户体验。
-
金融风控与安全:发现新的攻击模式时,通过热更新的“快速重启”能力更新风控规则(SQL),将风险敞口时间从分钟级缩短到秒级。
-
物联网(IoT):在设备数据分析场景中,频繁迭代分析模型和算法,通过“快速重启”大幅提升研发效率。
-
敏捷开发与测试:开发人员可以快速验证 SQL 逻辑的修改,无需漫长等待,加速产品上线周期。
最佳实践与未来展望
为了确保新功能的稳定可靠,我们建议在实施时遵循以下最佳实践:
-
权限管控:热更新是高权限操作,需配置严格的审批和审计日志。
-
兼容性测试:在上线前,充分测试不同 Flink 版本和参数组合下的兼容性。
-
用户通知:为用户提供清晰的操作成功/失败反馈,以及参数生效的提示。
-
回滚机制:提供一键回滚到上一个稳定配置的能力,以应对意外情况。
展望未来,袋鼠云实时计算团队将继续深化 Flink 技术创新:
-
扩大热更新范围:支持更多核心参数和算子属性的动态修改。
-
支持代码更新:探索在快速重启场景下,如何实现 Jar 包的动态更新。
-
智能化运维:开发参数修改的模拟测试与影响评估功能,为用户决策提供数据支持。
-
云原生增强:深度结合 Kubernetes Operator,实现更智能的资源动态伸缩与调度。
通过对 Flink 热更新技术的深度实践,袋鼠云实时计算平台正努力为用户构建一个更敏捷、更稳定、更高效的数据处理基石,让实时计算真正成为驱动业务增长的强大引擎。