详解flink SQL基础(四)
文章目录
- 1.Flink SQL介绍
- 2.streaming SQL&watermarks使用
- 3.窗口聚合(window aggregations)
- 4.over aggregations
- 5.FlinkSQL 流连接(Streaming join)
- 6.使用MATCH_RECOGNIZE 进行模式识别和复杂事件处理
- 7.变更记录(changelog)处理以及变更更新错误排查
- 8.使用explain进行故障排除
- 9.参考文档
1.Flink SQL介绍
OLTP 对比 OLAP

SQL查询原理:
视图&物化表


物化视图刷新策略:
-
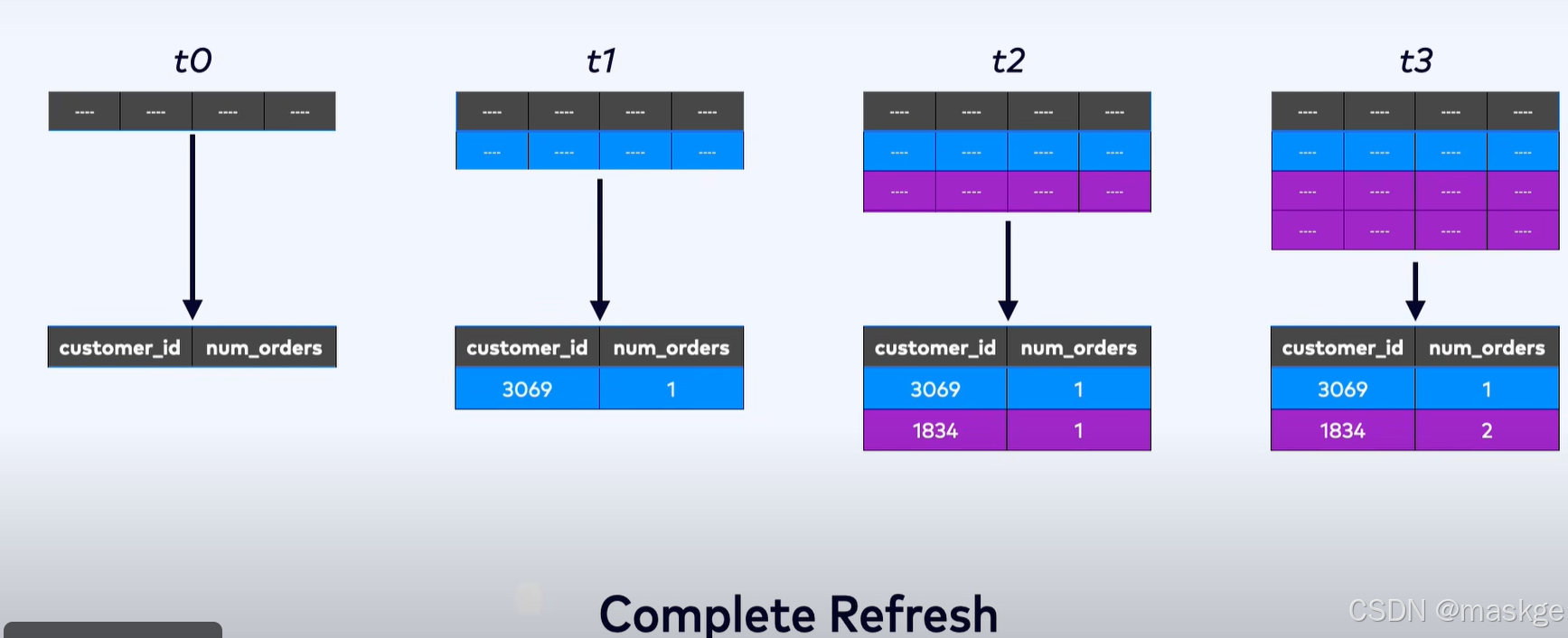
全量刷新
-
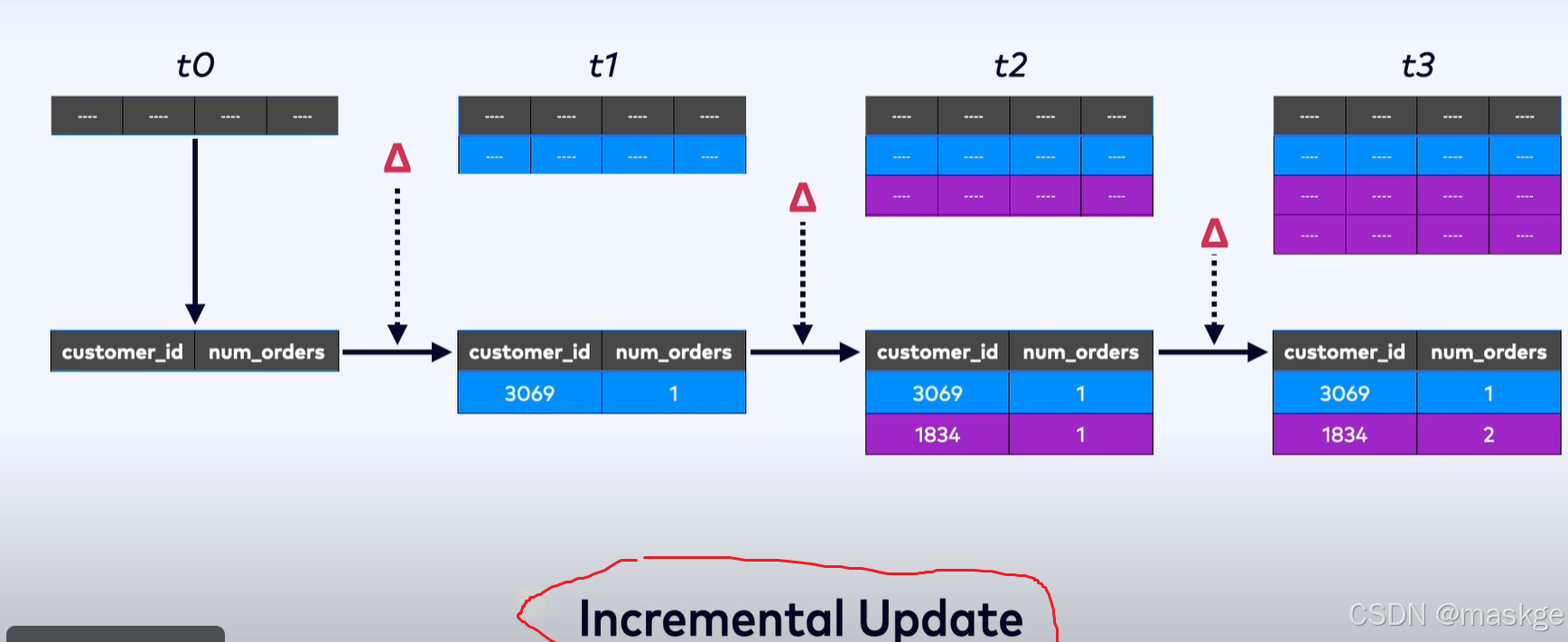
增量刷新
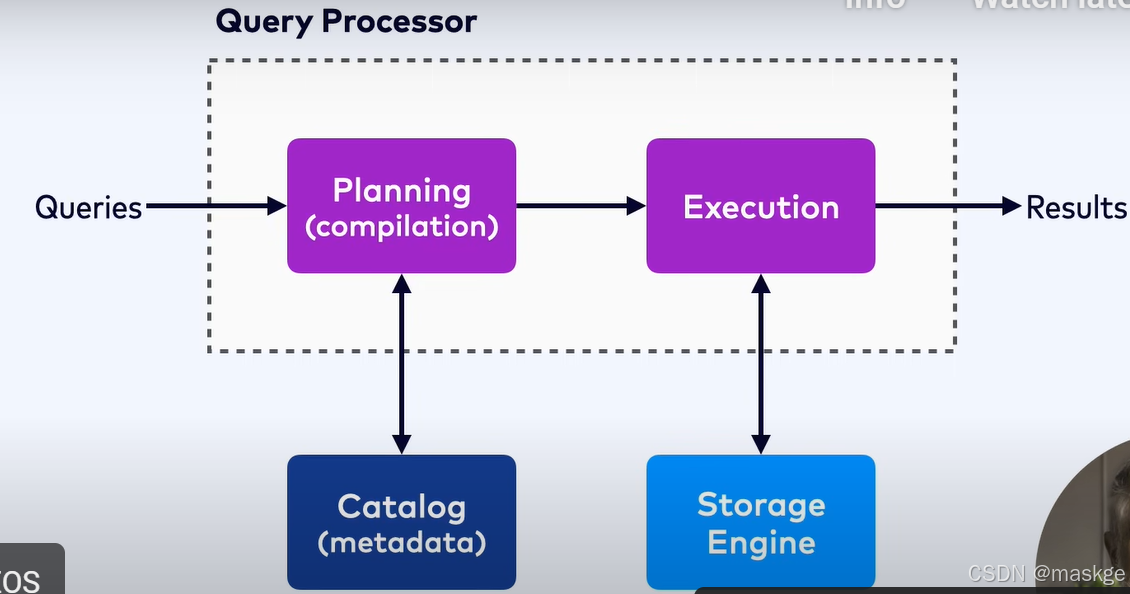
Flink SQl查询原理

-
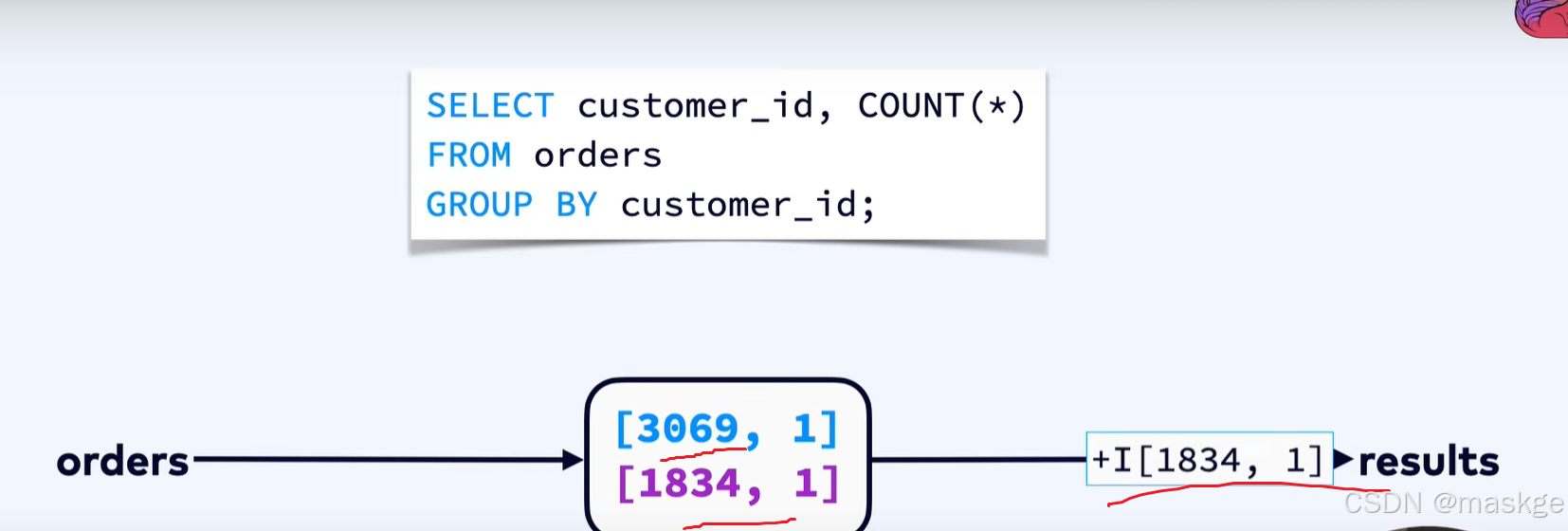
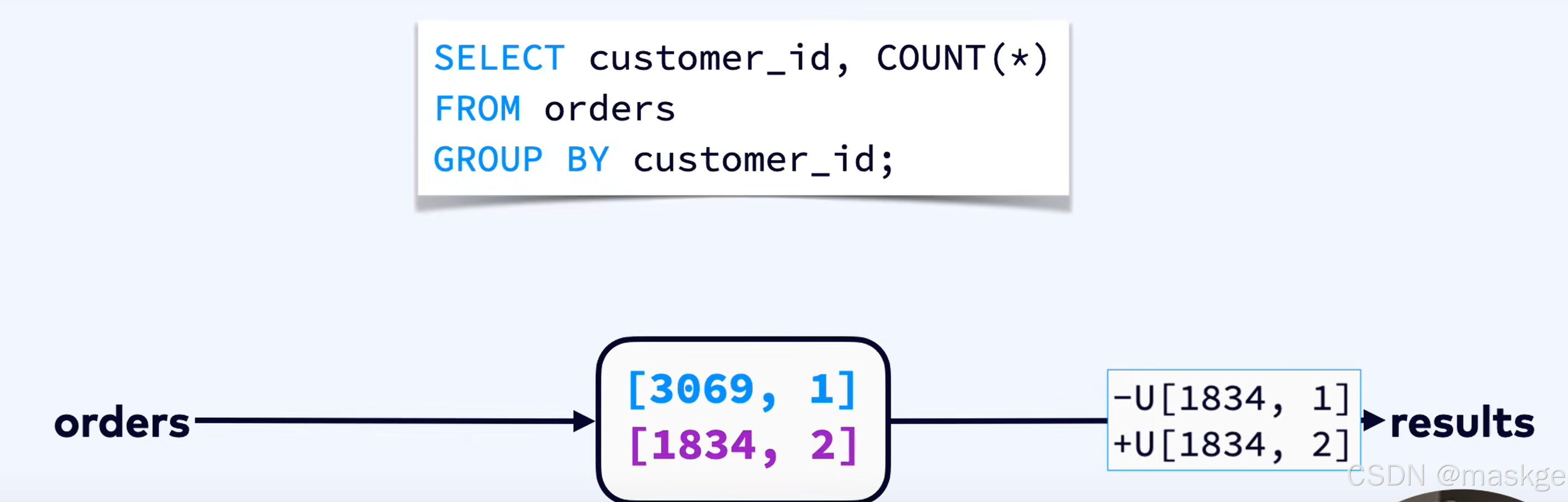
Flink SQL内部不维护物化视图,维护状态,保存分布式键值存储,会运行时优化,保存尽量小的状态
-
Flink使用incremental updates 策略,而非complete refresh 策略
-
Flink SQL不是一个数据库,是一个SQL 查询处理器(SQL Query Processor)
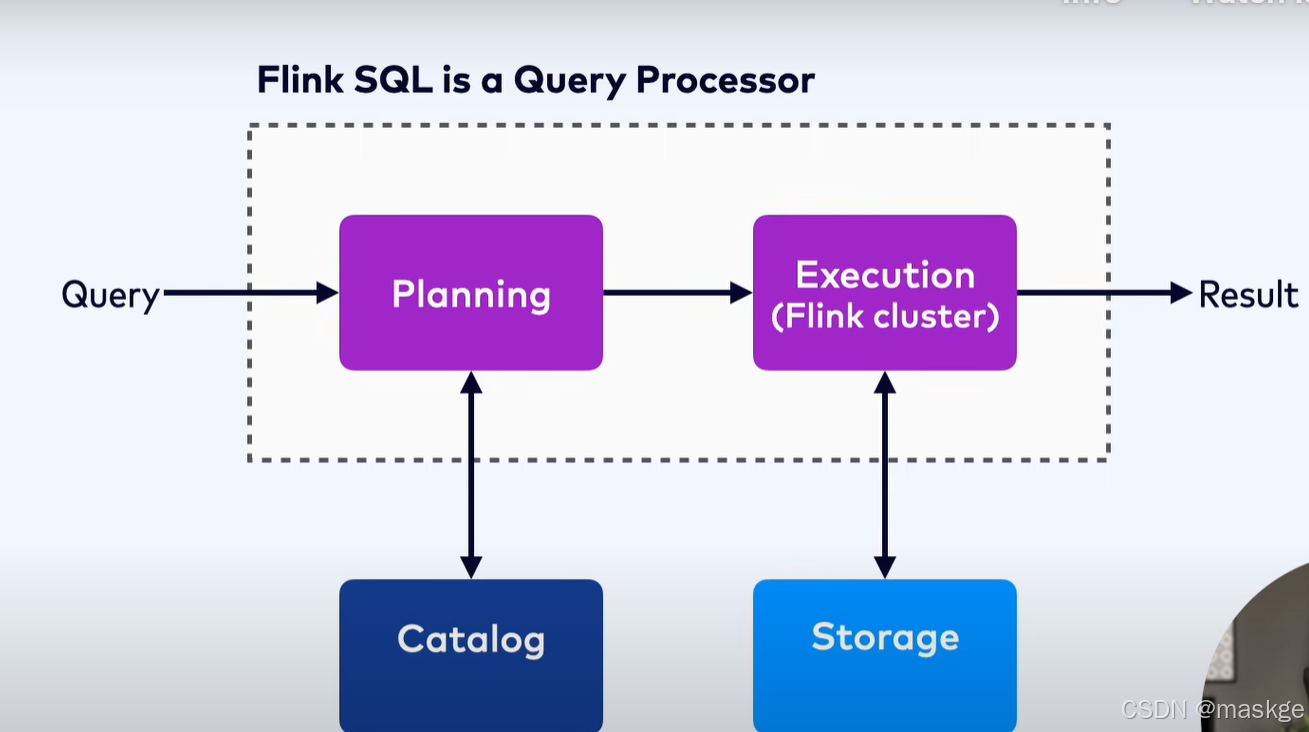
Flink SQL查询计划编译查询语句成为一个flink job,然后job被在flink集群上执行
Flink SQL提供了exactly-once(完全准确的数据流,无丢失、不重复) 、at-least-once(有可能流数据重复) 确保外部系统如何存储输入输出数据到表中;



flink exactly-once确保数据相当于ACID在单key事务
Flink SQl VS SQL database对比

Flink SQL常用操作命令
use catalog examples;show catalogs;use marketplace;#使用marketplace数据库show databases;show tables;describe extended `examples`.`marketplace`.`clicks`;describe clicks; #显示表结构select * from orders where price < 20;select distinct brand from products;use catalog `sql-course_environment`; #使用catalog:sql-course_environment
use `sql-course_kafka-cluster`; #使用数据库:sql-course_kafka-cluster#创建表
create table `small-orders` (`order_id` STRING NOT NULL,`customer_id` INT NOT NULL,`product_id` STRING NOT NULL,`price` DOUBLE NOT NULL
);#显示表结构
show create table `small-orders`;#把从orders表查询出来的数据插入small-orders中
insert into `small-orders`select * from `examples`.`marketplace`.`orders` where price < 20;
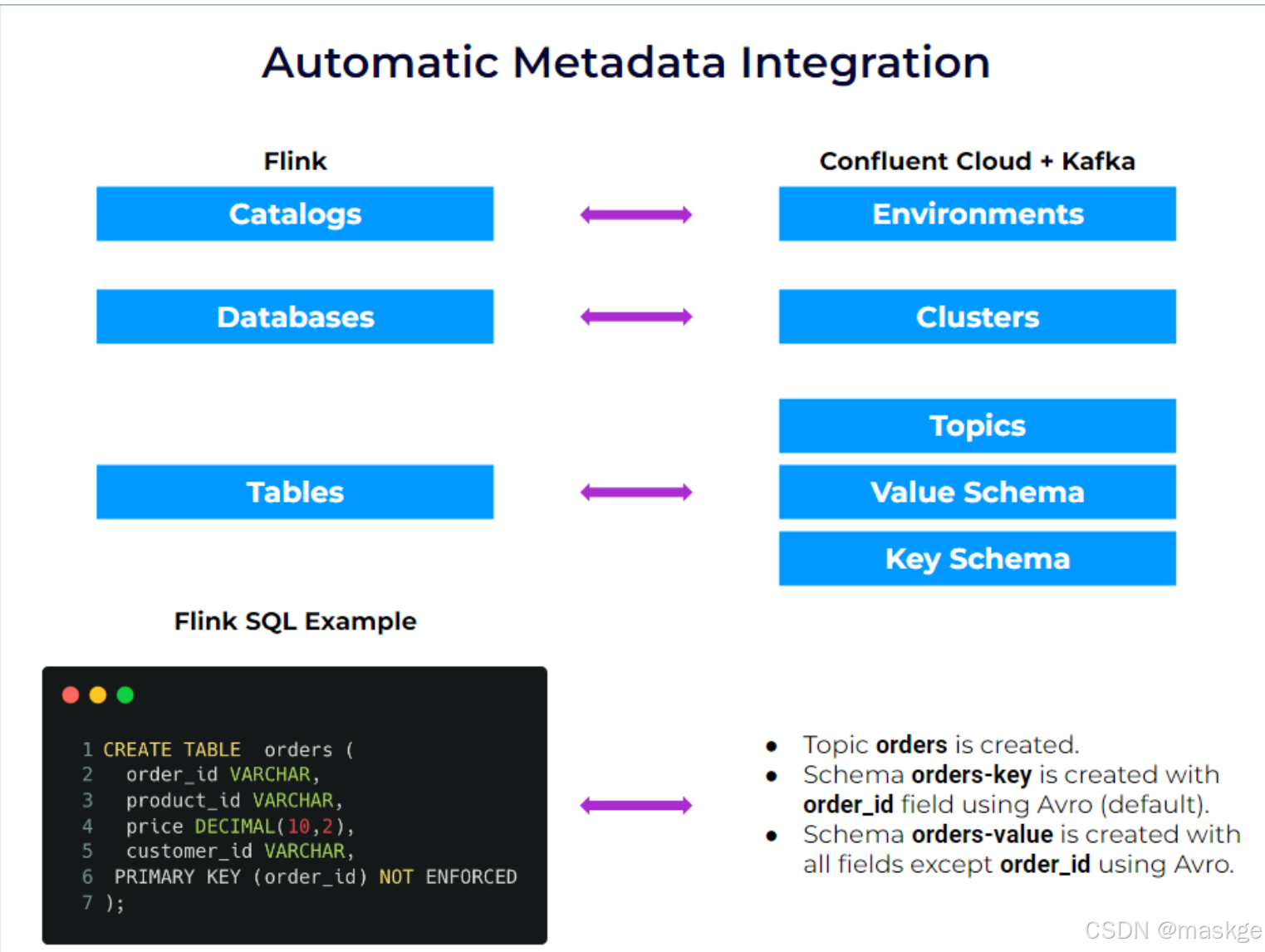
kafka 环境、clusters(集群)、topics(主题)与 schemas、Flink SQL之间的关系:
| Kafka | Flink | Notes |
|---|---|---|
| Environment | Catalog | Flink can query and join data that are in any environments/catalogs |
| Cluster | Database | Flink can query and join data that are in different clusters/databases |
| Topic + Schema | Table | Kafka topics and Flink tables are always in sync. You never need to to declare tables manually for existing topics. Creating a table in Flink creates a topic and the associated schema. |
2.streaming SQL&watermarks使用
watermarks
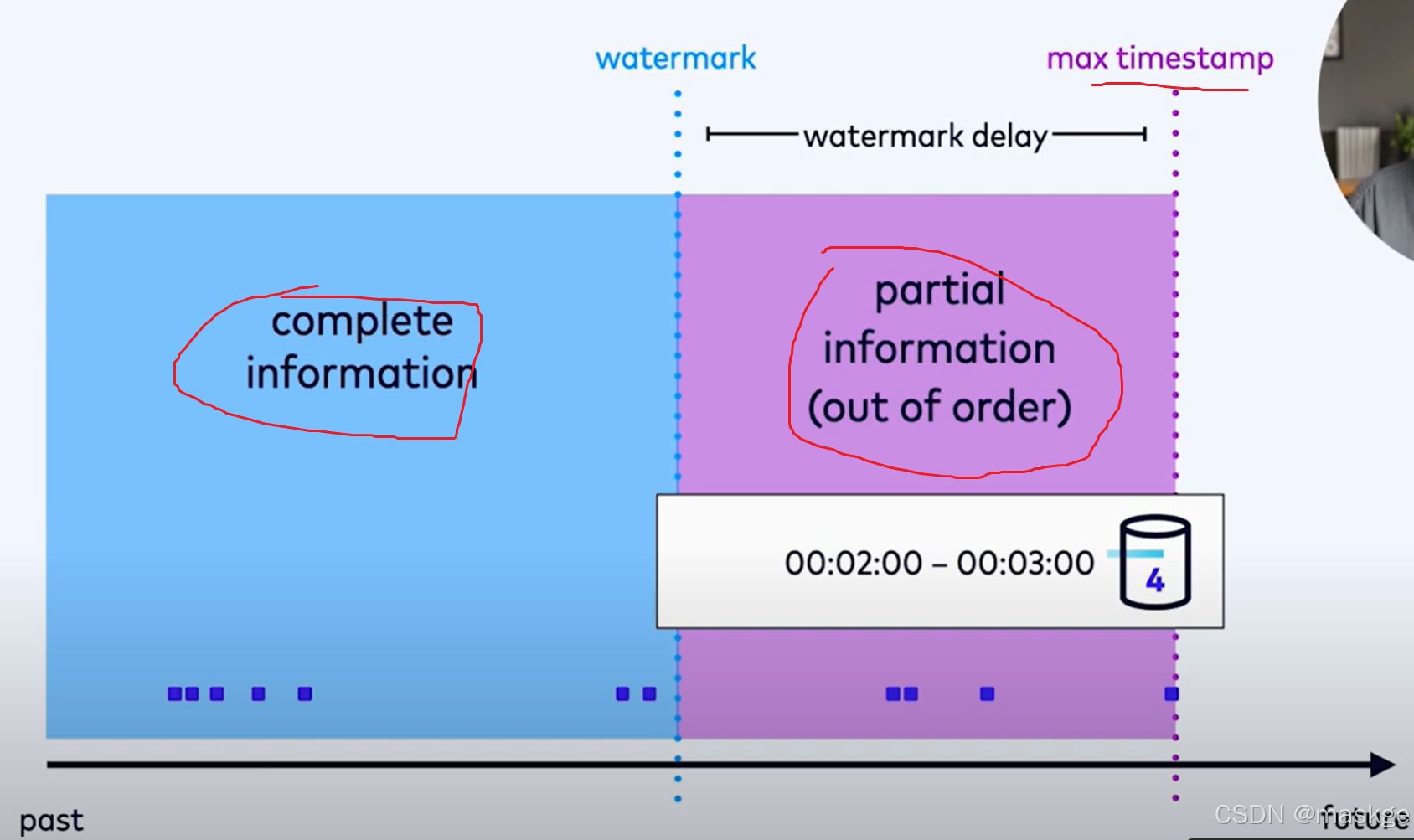
- watermarks(水印)可以标记过去的一段时间的记录,可以触发垃圾回收(GC),可以估算完整数据流信息和部分数据流信息的边界,flinkSQL依靠水印(watermarks)触发各种基于时间的操作并产生结果,知道运行时存储的数据流何时失效;支持流操作的状态管理
- 逻辑时间通过事件中的timestamps时间戳测量
Flink SQl中所有基于时间的操作都依赖水印
- windows
- Interval joins
- Temporal joins
- MATCH_RECOGNIZE(pattern matching)
watermark多source流整合过程
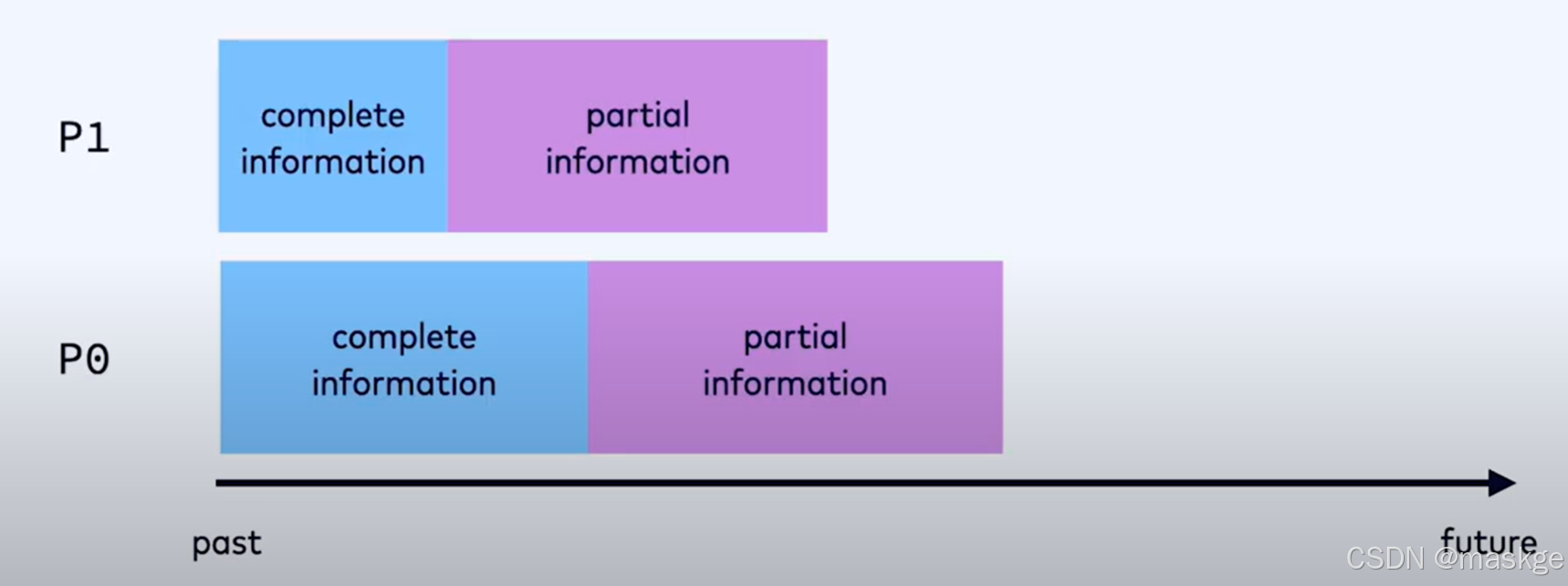
水印会为每个分区或独立的流生成水印
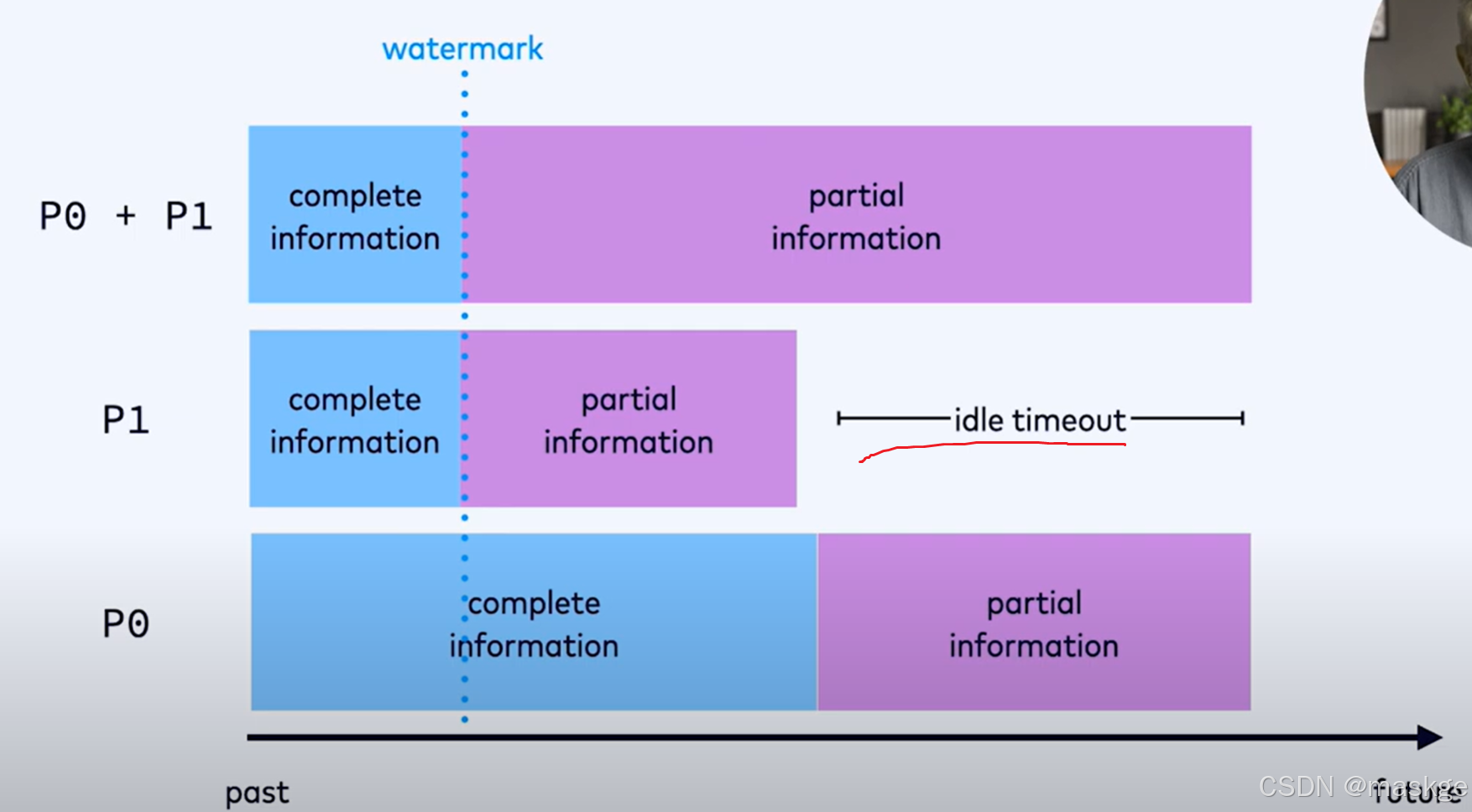
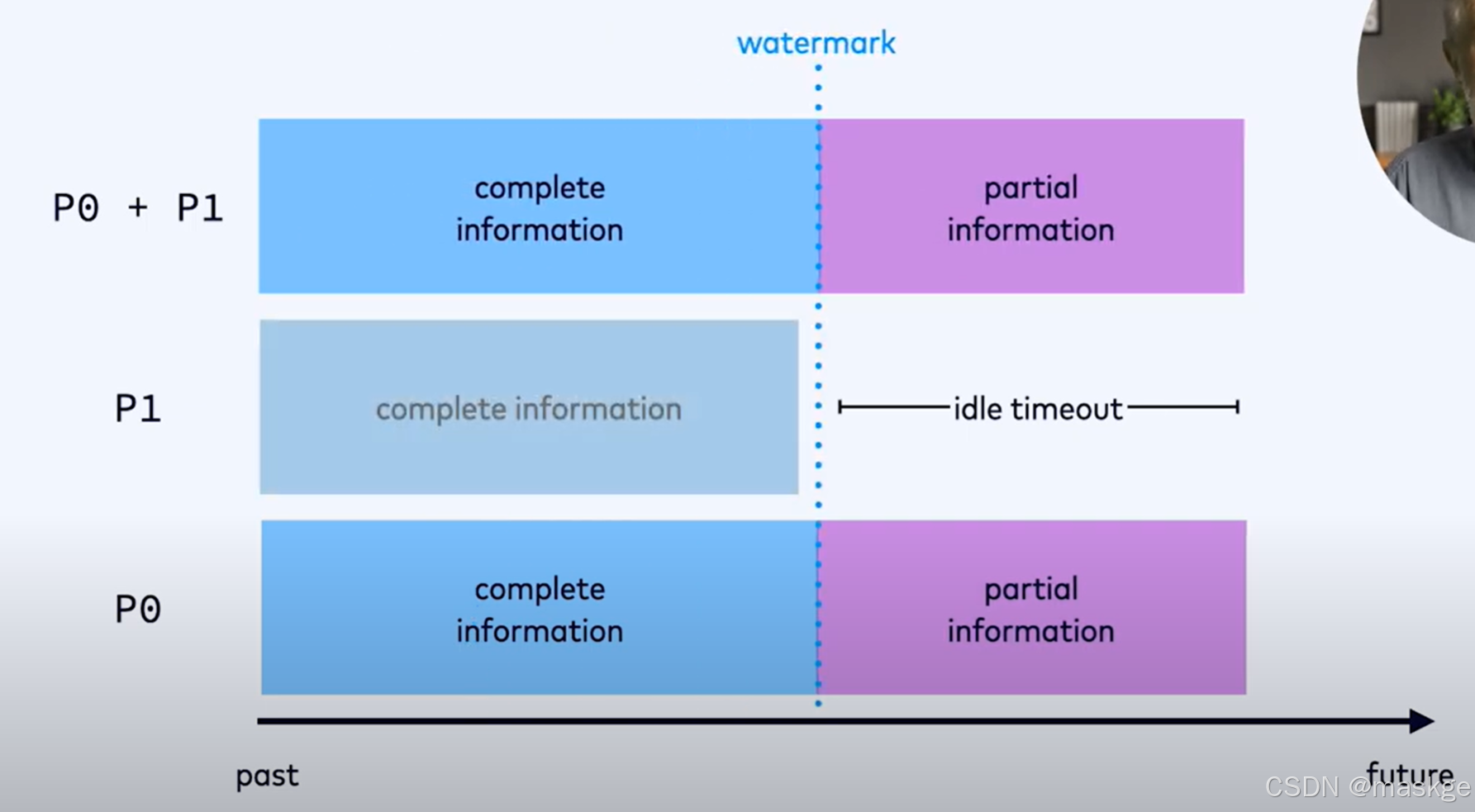
当p0继续的时候,p1已经处于空闲,可以设置idle time
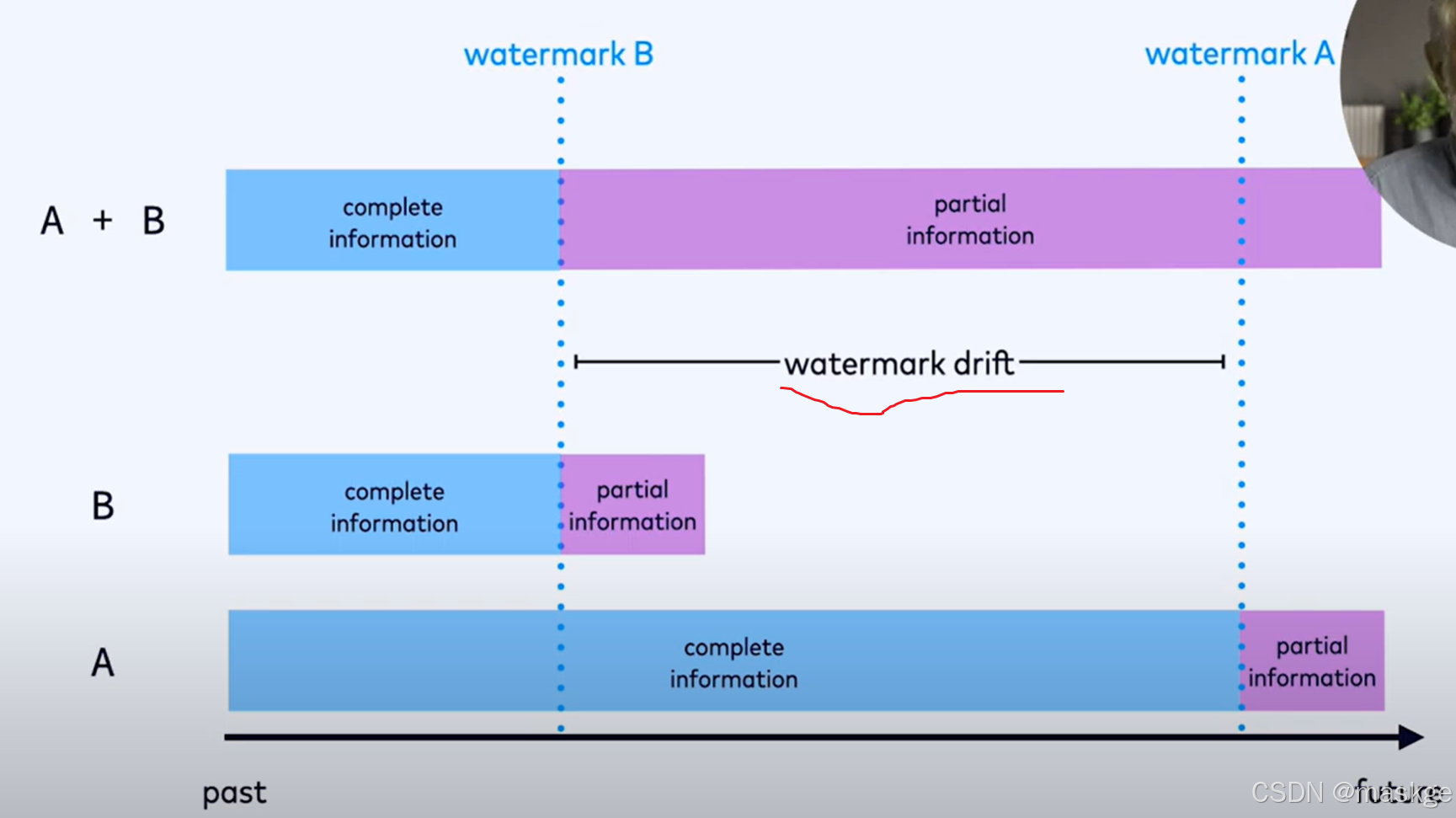
watermark drift(水印偏移)会导致越来越多的部分信息被缓冲起来导致性能问题与运营困难对于flink集群运行的job;要解决这个问题就需要约束大的水印偏移,可以通过配置maxAllowedWatermarkDrift
定义watermarks考虑点:
- watermark delay(out-of-orderness)
- idle timeout
- max allowed watermark drift
- 使用timestamp
自定义水印的确定场景:
- 当topic数据非常少
- 当默认的水印处理产生过多延迟事件时,允许增加的延迟来降低延迟事件发生的可能性
必须使用watermark的场景:
Processing time(wall clock time:挂钟时间) vs event time:
使用处理时间(也称为挂钟时间)作为时间信息的来源,而非事件中存储的时间戳,那么水印就不是必需的。不过,不建议使用处理时间,因为它会引入非确定性,且可能使生成的结果难以解释。Confluent Cloud 不支持处理时间。
watermark支持流操作的状态管理:
对于批处理水印不是必须的,对于流处理工作负载,只有那些关注过去时间的流操作才需要水印。这些时间操作包括:
-
window aggregations
-
interval and temporal joins
-
sorting (by time), and any operation that involves time-based sorting, including
- ORDER BY
- OVER aggregations, including deduplication(去重) and top-n
- pattern matching with MATCH_RECOGNIZE
只使用 SELECT 和 WHERE 子句的查询不需要水印。上述列出的时间操作需要水印的原因是,所有这些操作都是有状态的,需要利用水印来确定何时可以安全地丢弃部分状态。
常规聚合(与窗口聚合相对)和常规连接(与间隔连接和时间连接相对)不使用水印,但使用时应谨慎,因为它们不仅是有状态的,还会使用无限量的状态。
时间属性(time atrribute):
时间属性是一个定义了水印的时间戳列。例如:查询在进行基于时间的窗口操作,时间属性的时间戳将用于确定每个事件应分配到哪个窗口,而水印将决定每个窗口何时完成。
一个 Flink表可以有多个时间戳列。例如,一个 “订单” 表可能包含指示订单下单时间和订单发货时间的时间戳列。水印只能应用于其中一个时间戳列,而这个特殊的列将成为时间属性。这进而意味着,所有这些时间操作只能应用于选择用于水印的那个时间戳列。
如果觉得是一种限制,可以,以不同的方式对数据进行建模。例如,将发货时间信息从 “订单” 表中分离出来,放到单独的 “发货” 表中,这会带来更大的灵活性。
-
current_watermark(时间戳):通过限制输出行数,可以在结果中上下翻页;可以有益于有关水印的问题调试,但只能交互用于append-only 表
select user_id, url, $rowtime, current_watermark($rowtime) as wm from `examples`.`marketplace`.`clicks` limit 500;create table `some_clicks` (`partition_key` INT,`user_id` INT NOT NULL,`url` STRING NOT NULL,`event_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' ) distributed by hash(`partition_key`) into 2 buckets;insert into `some_clicks` select1 as partition_key, user_id,url,$rowtime as event_time from `examples`.`marketplace`.`clicks` limit 500; -
SOURCE_WATERMARK()
-
定义watermark
create table `ooo_clicks` (`user_id` INT NOT NULL,`url` STRING NOT NULL,`event_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp',watermark for `event_time` as `event_time` - INTERVAL '1' SECOND );insert into `ooo_clicks` selectuser_id,url,TIMESTAMPADD(SECOND, rand_integer(6), $rowtime) as event_time from `examples`.`marketplace`.`clicks`;with a_thousand_clicks as (select * from ooo_clicks limit 1000) select count(*) from a_thousand_clicks where event_time <= current_watermark(event_time);selectcount(*) as total_events,sum(case when event_time <= current_watermark(event_time) then 1 else 0 end) as late_events from ooo_clicks;设置水印的空闲时间:sql.tables.scan.idle-timeout
CREATE TABLE AS SELECT (CTAS):通过select创建表
-- Equivalent to the following CREATE TABLE and INSERT INTO statements.
CREATE TABLE my_ctas_table
AS SELECT id, name, age FROM source_table WHERE mod(id, 10) = 0;flink sql 数据分配策略:
- 无状态、顺序保留 →
Forward; - 负载均衡 →
Rebalance(轮训)/Rescale(缩放分配); - 彻底打散 →
Shuffle(随机分配); - 全局数据分发 →
Broadcast; - 按 Key 聚合 / 状态处理 →
Key Group(哈希)(keyBy)。
-
Forward(正向分配)
原理:上游算子的第 i 个并行任务(Subtask)仅将数据发送到下游算子的第 i 个并行任务。
约束:上下游算子的并行度必须相同(parallelism 一致)
特点:数据顺序严格保留(同一条流的顺序不变),无网络 shuffle 开销,性能最优。
适用场景:上下游算子逻辑上是 “一对一” 处理,且无需数据重分配(如简单的 map、filter后直接传递 -
Shuffle(随机分配)
原理:上游每个任务随机将数据发送到下游的任意任务(无固定规则)。
特点:数据被完全打散,可能导致下游任务负载不均(极端情况下),但能打破数据局部性。
适用场景:需要彻底打乱数据分布的场景(如批处理中的 sample 采样、随机化处理) -
Rebalance(轮询分配)
原理:上游每个任务通过 “轮询”(Round-Robin)方式将数据均匀分配到下游所有任务。
特点:能强制平衡下游任务的负载,避免数据倾斜(上游数据按顺序依次发送到下游每个任务)
适用场景:上游数据可能存在倾斜,需要下游任务负载均衡(如 reduce 前的预处理) -
Rescale(缩放分配)
原理:上游任务仅将数据发送到下游的 “部分任务”(而非全部),具体分配范围由并行度比例决定。
例:上游并行度为 2,下游为 4,则上游任务 0 发送到下游 0、1,上游任务 1 发送到下游 2、3;
若上游 4、下游 2,则上游 0、1 发送到下游 0,上游 2、3 发送到下游 1。
特点:相比 Rebalance 减少网络传输范围(仅在部分任务间通信),适合上下游并行度成比例的场景。
适用场景:需要局部负载均衡,且上下游并行度有明确比例关系(如多层 map 级联) -
Broadcast(广播分配)
原理:上游每个任务将数据复制并发送到下游所有任务(下游每个任务都能收到完整数据)。
特点:数据量会随下游并行度线性膨胀,仅适合小数据集(如配置信息、规则表)。
适用场景:下游任务需要基于全局数据做计算(如用广播的规则表过滤流数据)。 -
Key Group(按 Key 分组分配)
原理:通过 keyBy() 算子指定 Key 后,Flink会将相同 Key 的数据分配到同一个下游任务(保证 “Key 一致性”)
实现:先对 Key 哈希,映射到固定数量的 “Key Group”(默认 128 个,可配置),再将 Key Group 分配给下游任务(每个任务负责多个 Key Group)
特点:确保相同 Key 的数据在同一任务处理,是状态一致性(如 ValueState)和窗口计算(Window)的基础。
适用场景:需要基于 Key 做聚合(sum、reduce)、状态存储或窗口计算的场景(几乎所有有状态处理)
3.窗口聚合(window aggregations)
1.滚动窗口(tumbling window)
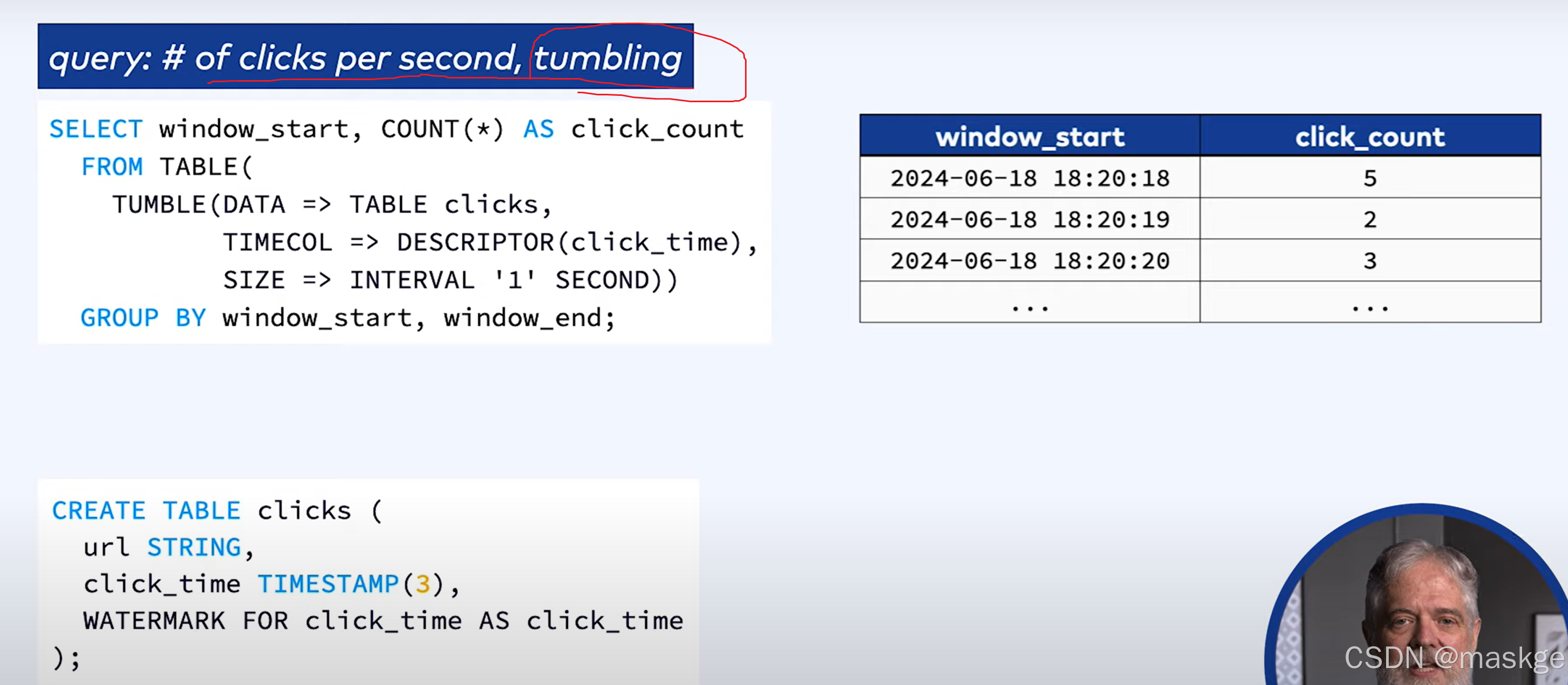
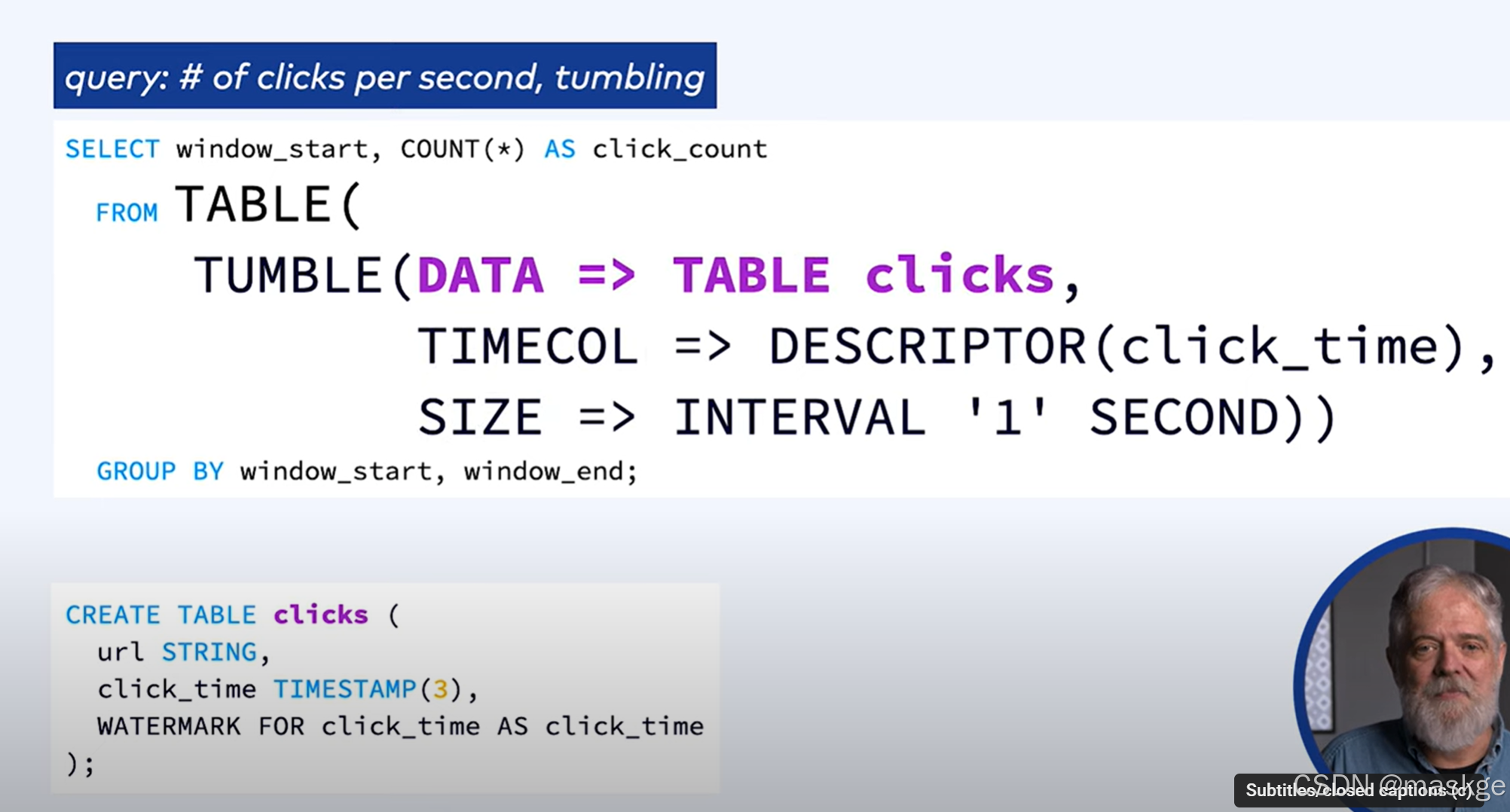

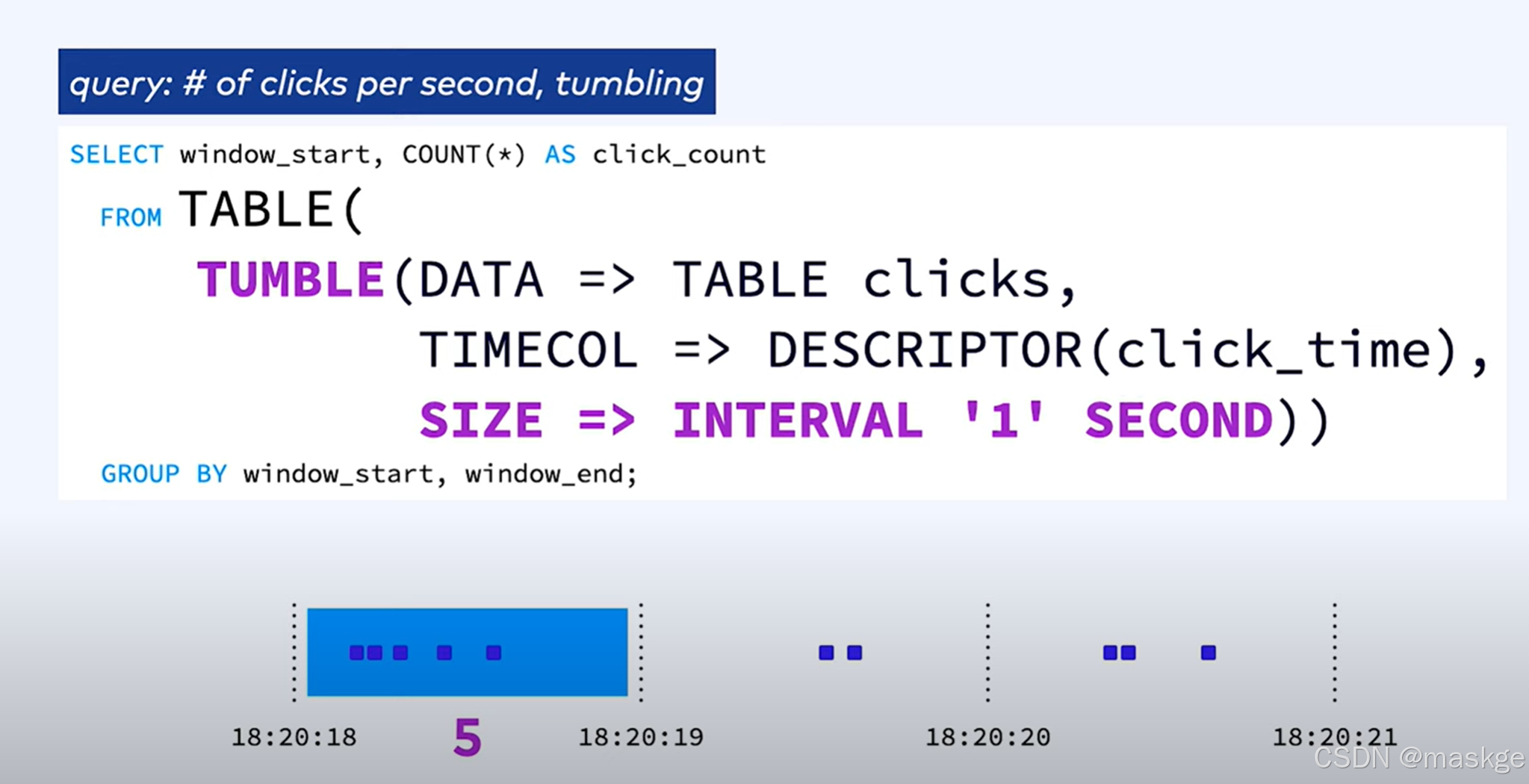
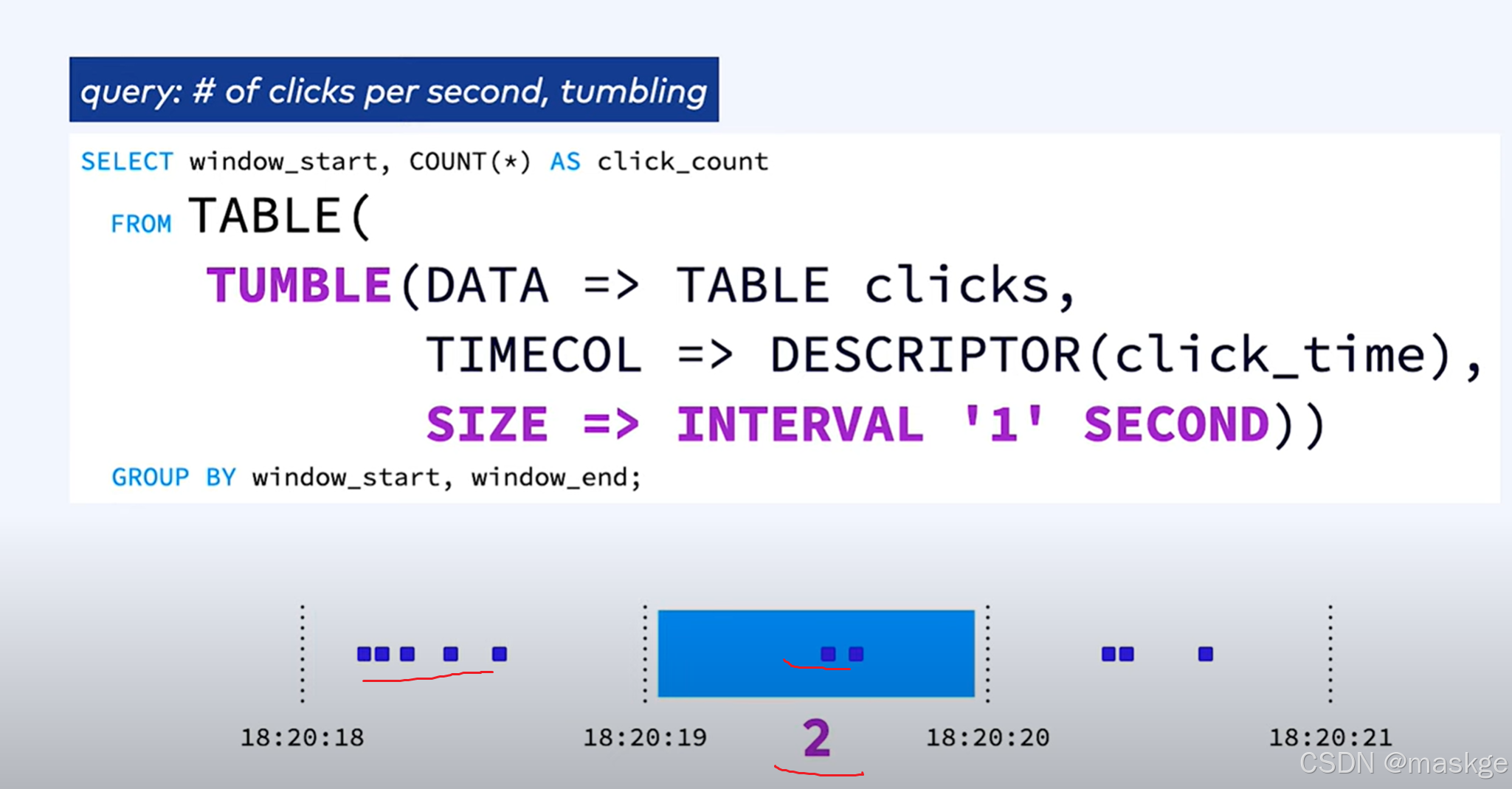

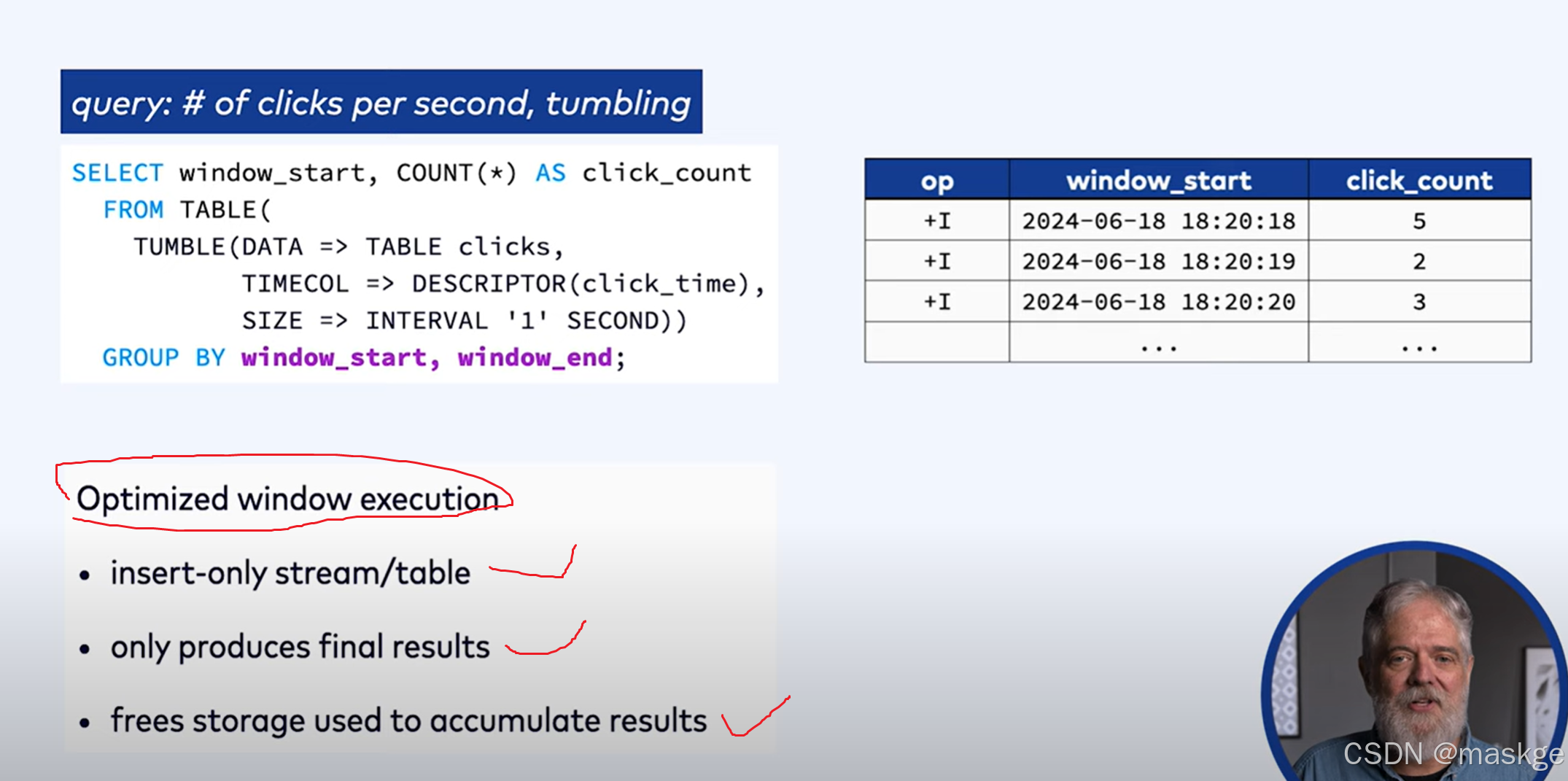
2.跳跃窗口(hopping window)

3.累加窗口(accumulate window)

4.会话窗口(session window)

window table-valued functions (TVF)分类:
- 将表中的元素划分为窗口:
- Tumble Windows
- Hop Windows
- Cumulate Windows
- Session Windows (not supported in batch mode)
- 使用频次计算:
- Window Aggregation
- Window TopN
- Window Join
- Window Deduplication
4.over aggregations
SELECT product_id,price,COUNT(price) OVER w AS num_prices,AVG(price) OVER w AS avg_price
FROM `examples`.`marketplace`.`orders`
WHERE product_id < 1010
WINDOW w AS (PARTITION BY product_idORDER BY $rowtimeROWS BETWEEN 2 PRECEDING AND CURRENT ROW # 在前2行与当前行之间
);
Flink SQL 还支持将去重、Top-N 和窗口化 Top-N 查询作为 OVER 窗口的特殊情况。
5.FlinkSQL 流连接(Streaming join)
Streaming SQL -> continuous queiries;some continuous queries need to keep some state
3种SQL 操作:




Streaming join一直查询:
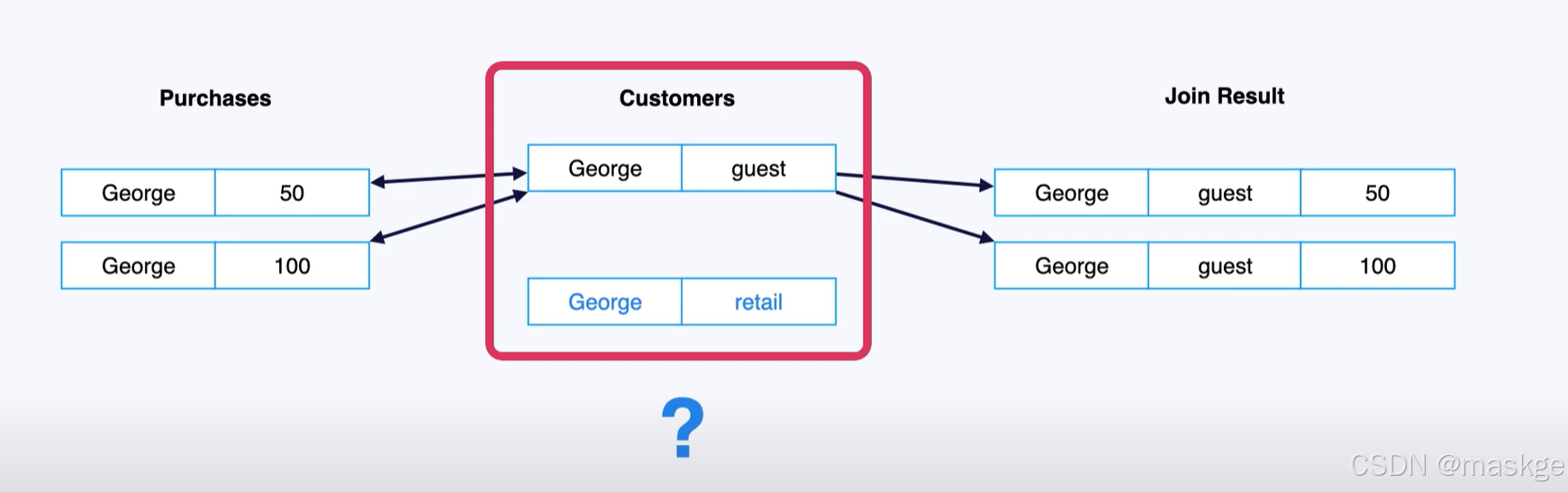
1.table updating


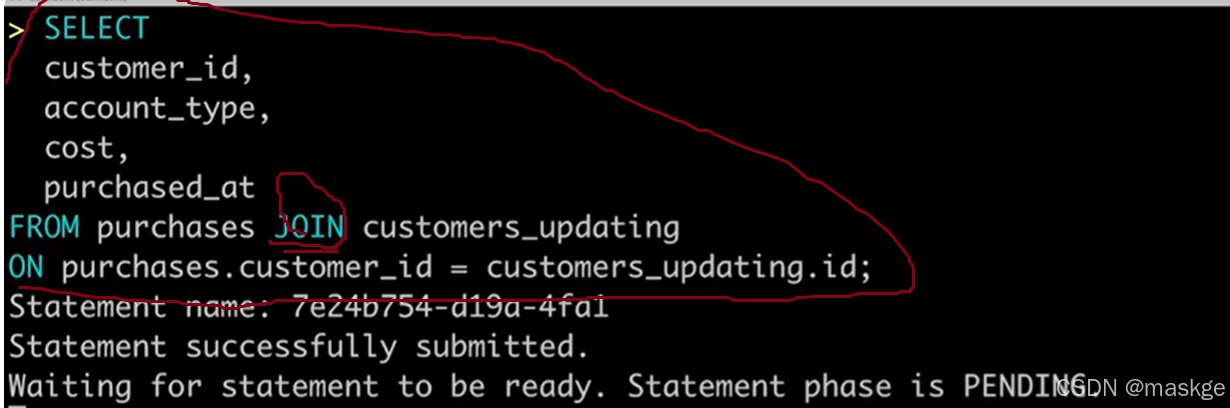

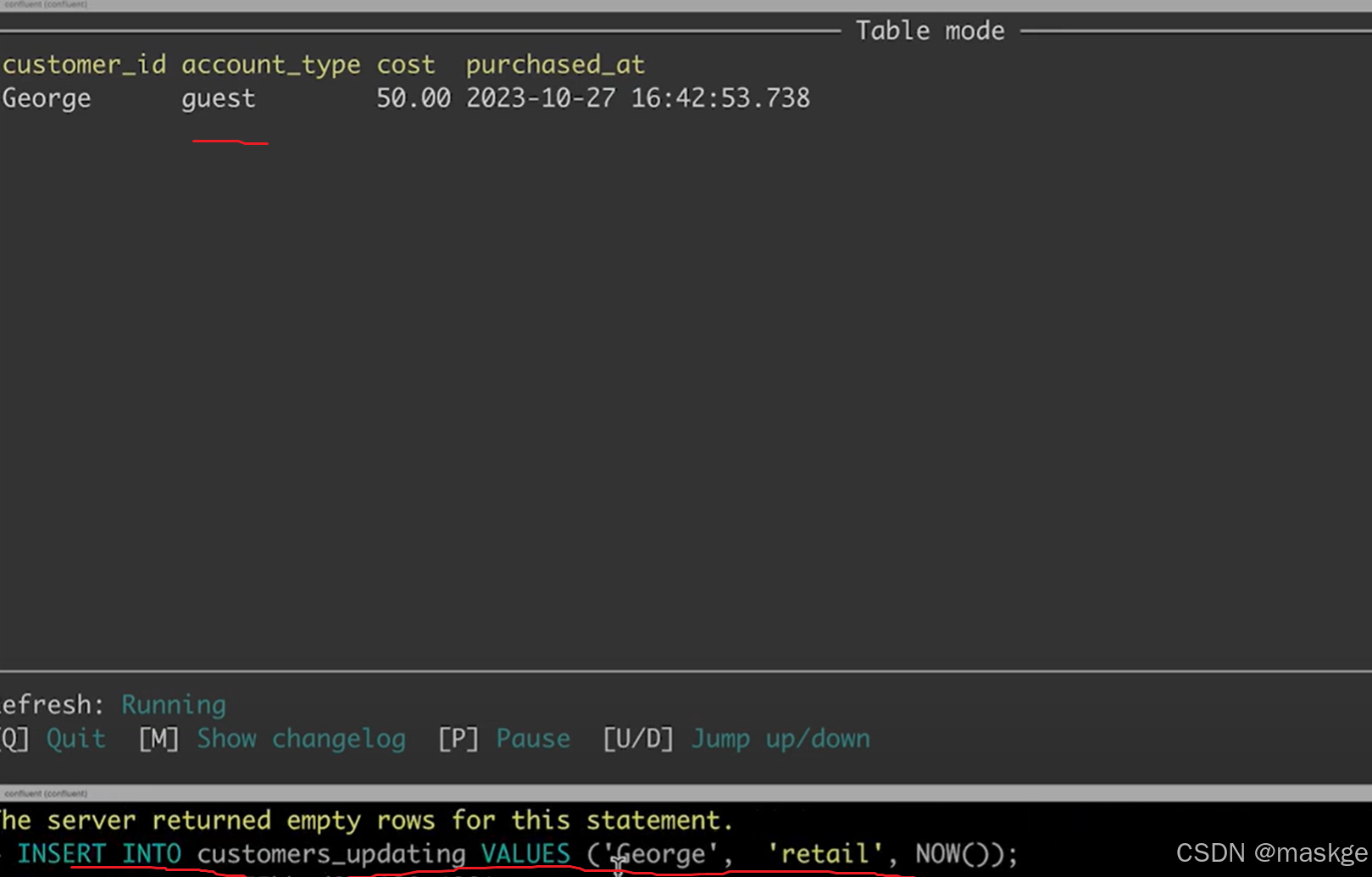
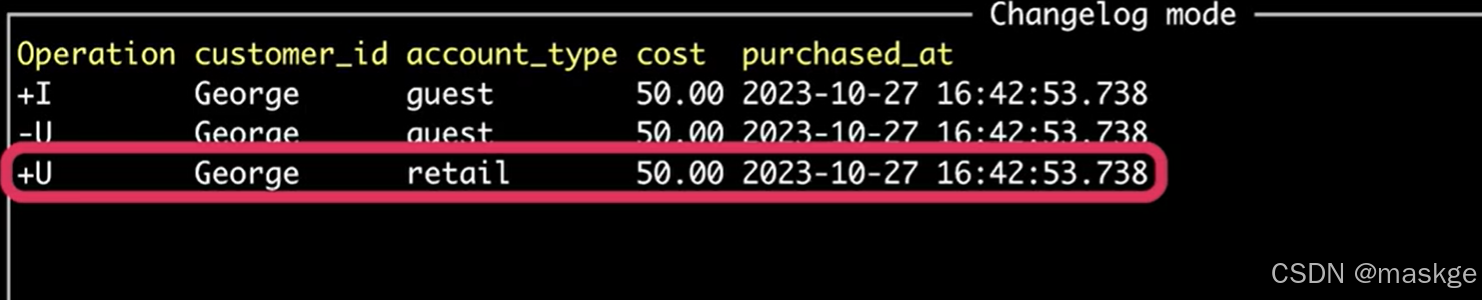
show changelog:显示变更记录
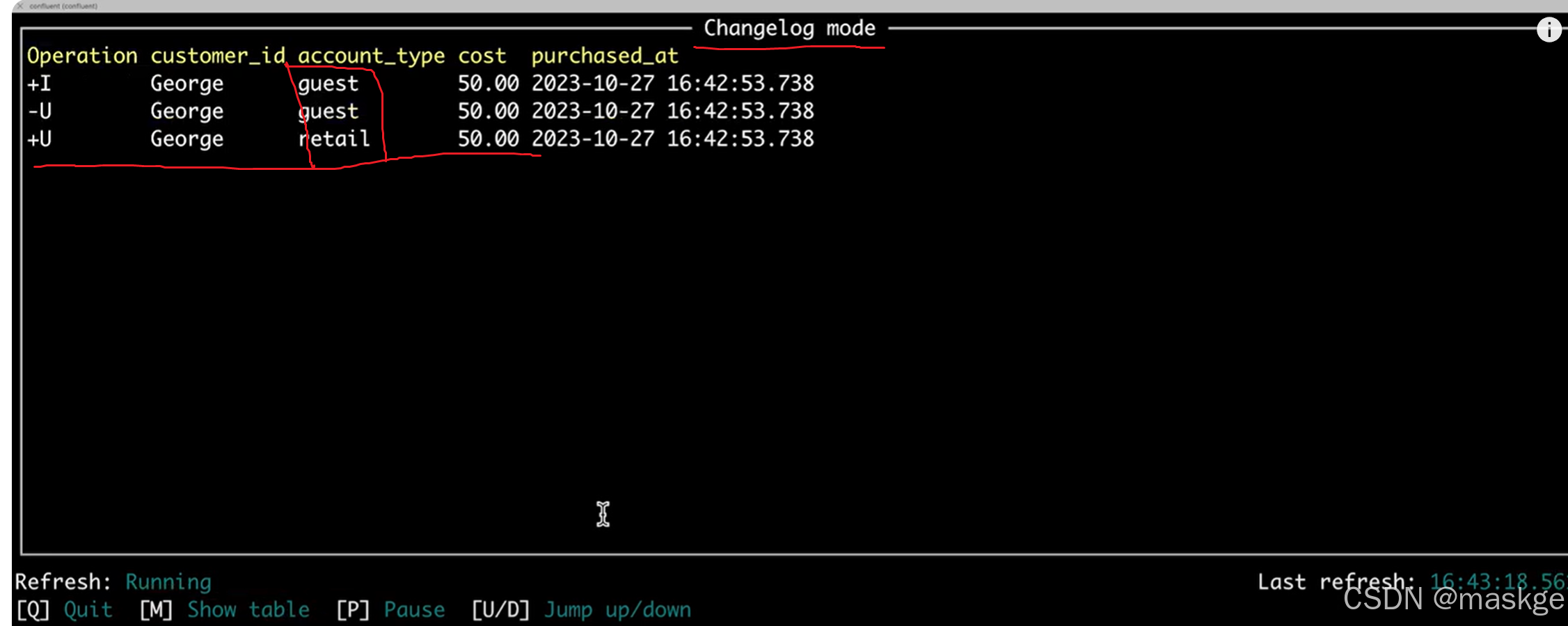

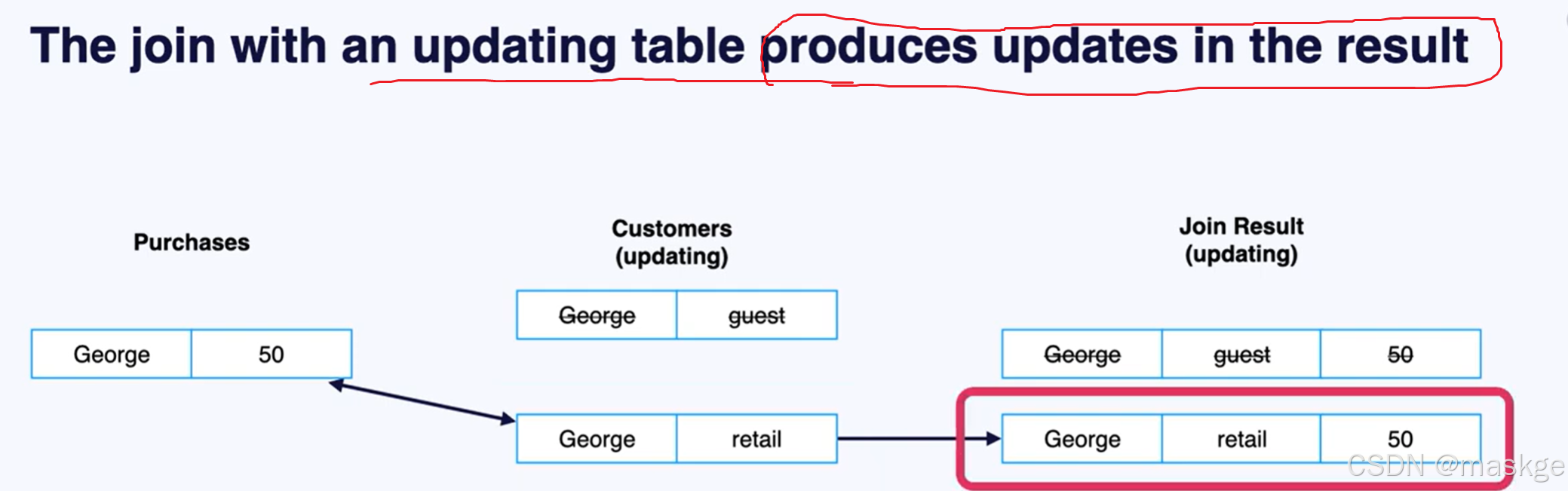
2. table appending

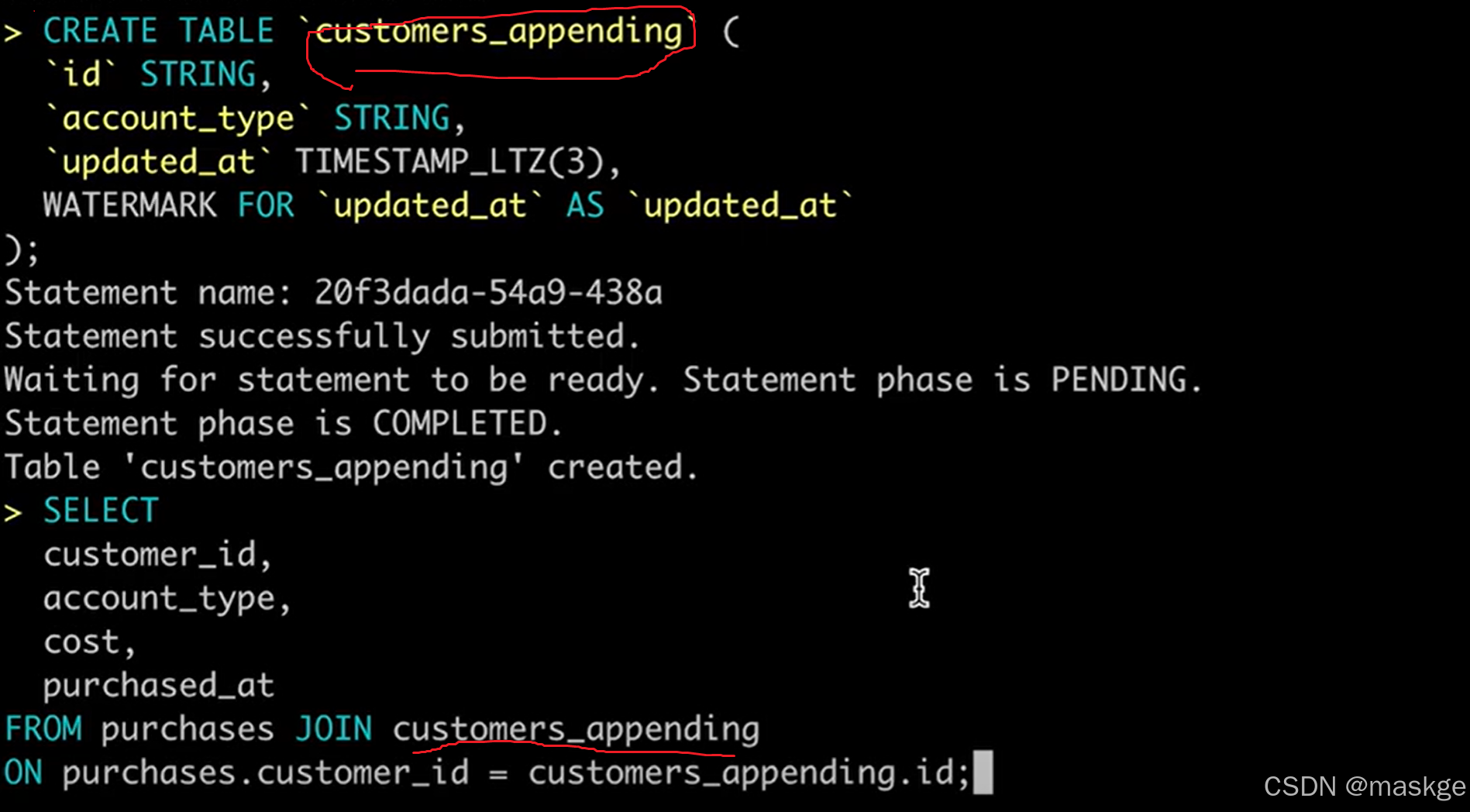
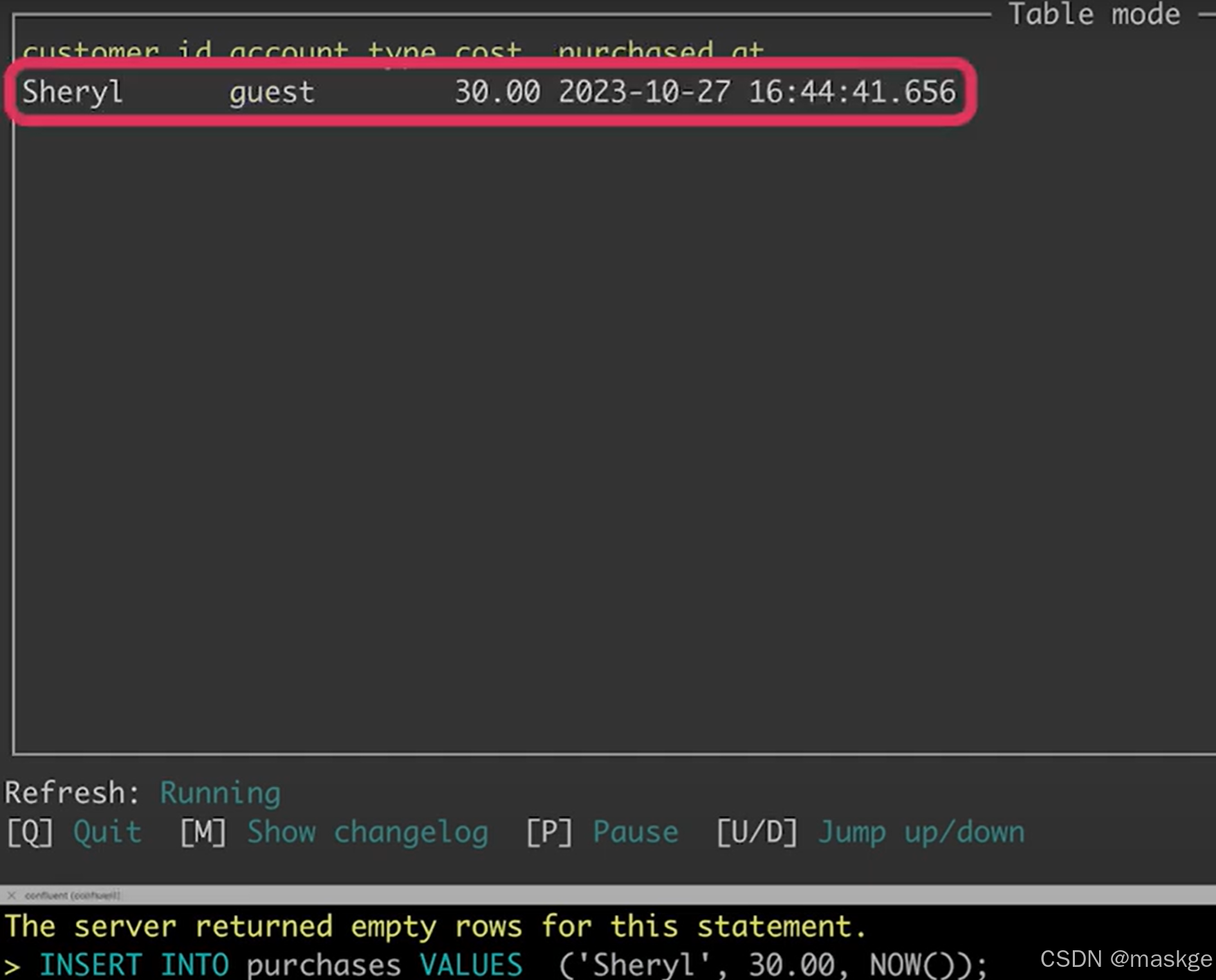
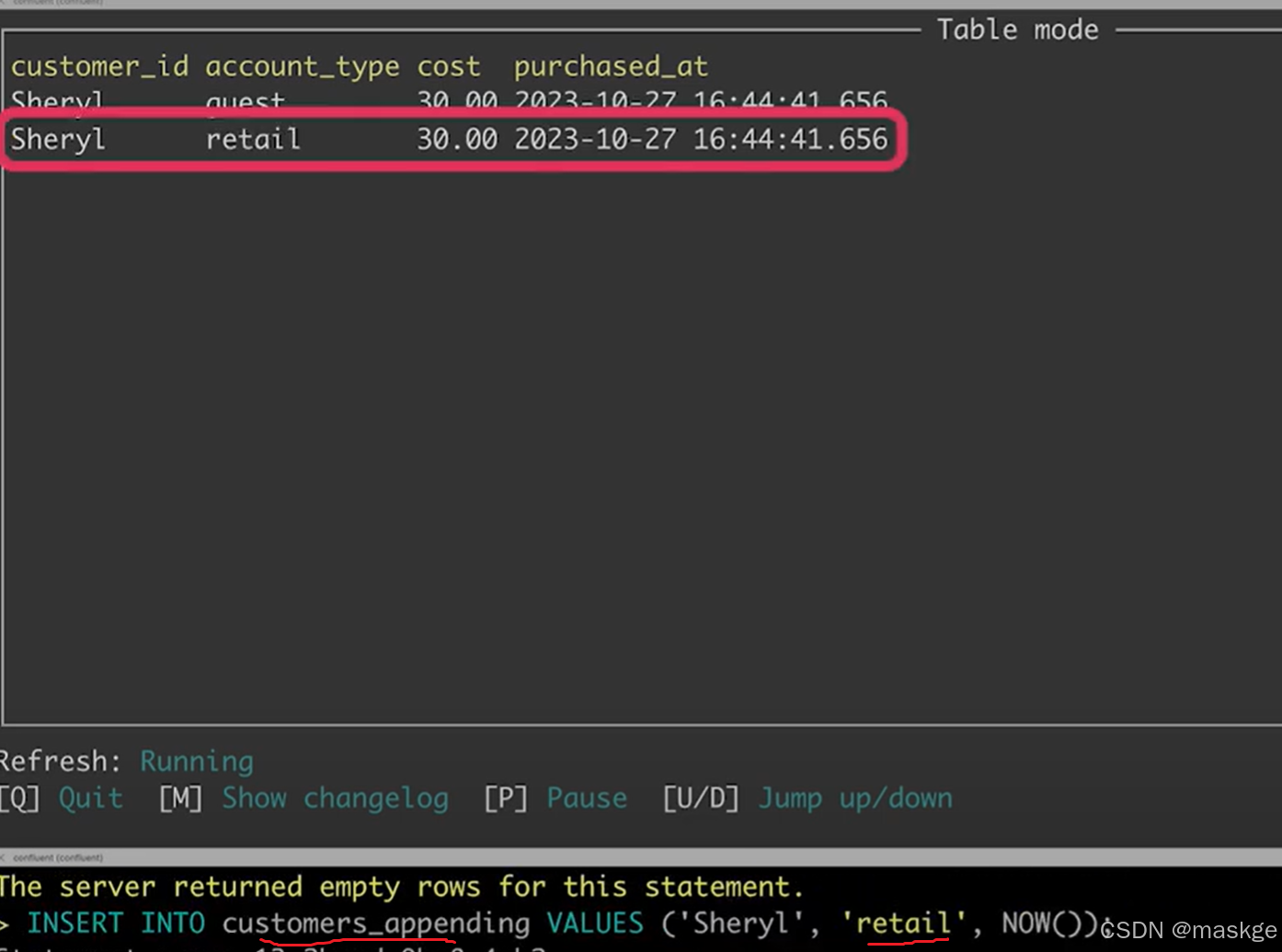
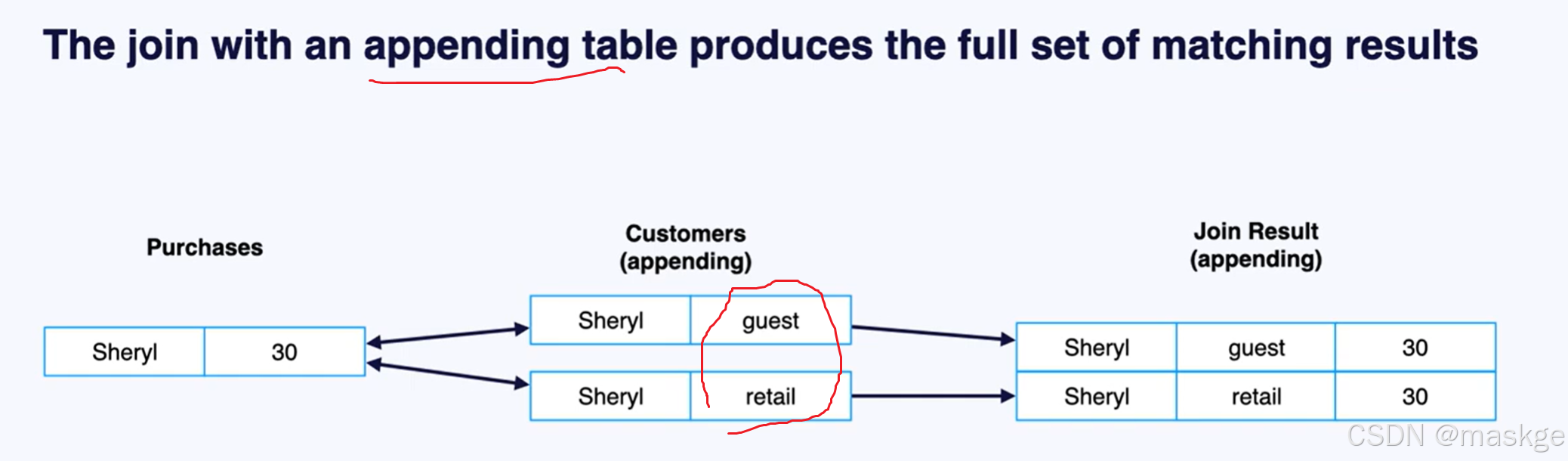
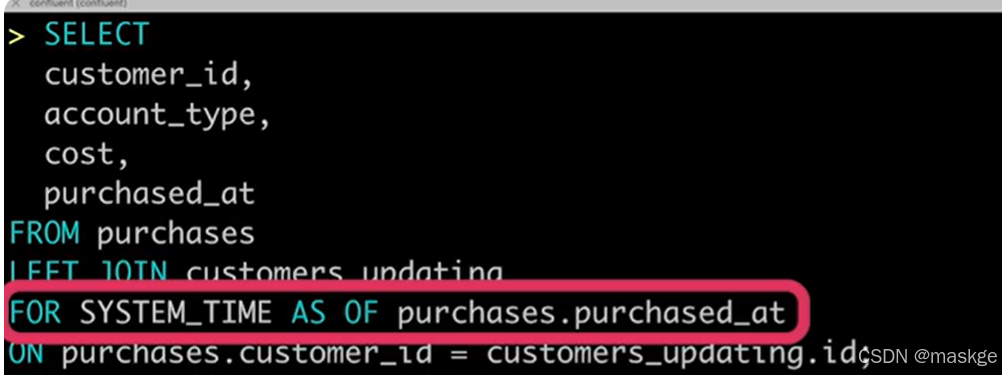
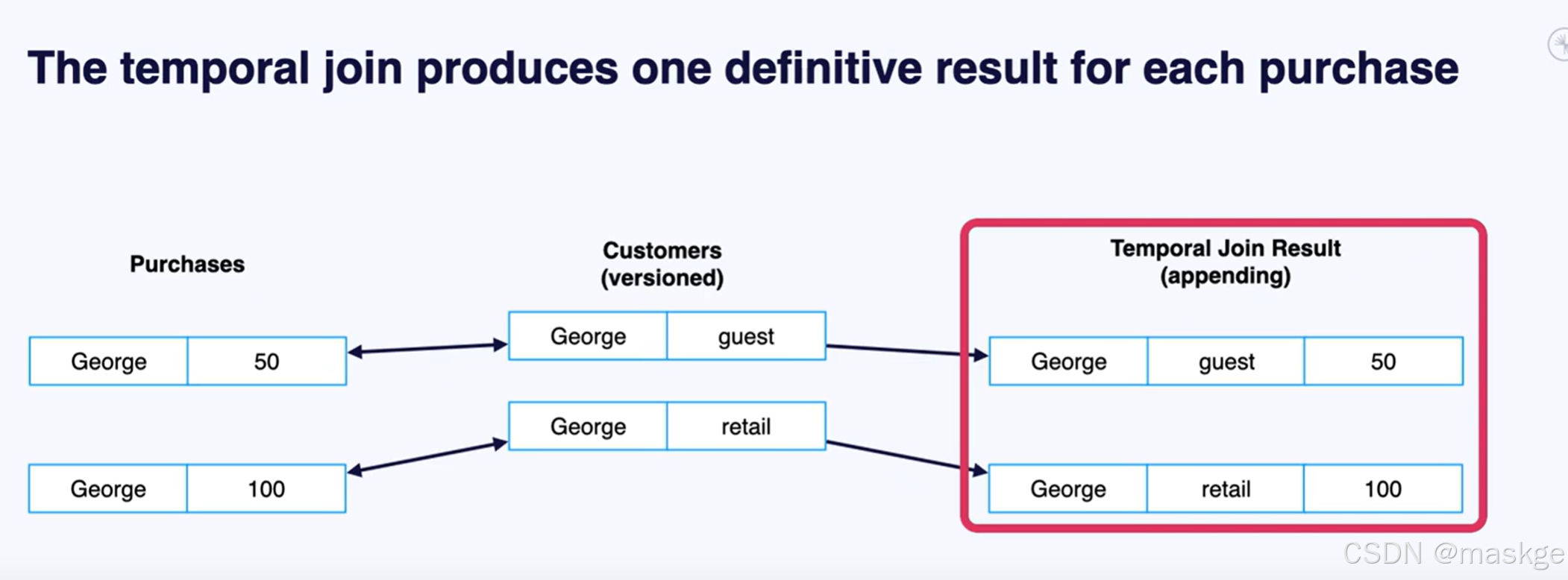

Flink join table的记录变更主要依赖水印(Temporal join的结果)
Flink 支持传统的内连、外连、左连、右连;但是大多数这样的结果是错误的,因为与流连接方式有关;
Flink 的流处理SQL运行处理查询的方法:在任何时间点,流处理 SQL 查询的结果都将与在传统的面向批处理的数据库中对相同数据运行相同查询所得到的结果一致。
Flink 的面向流处理的运行时会保留它所需的任何状态,这样当每一行额外的输入数据被处理时,结果就可以被增量更新
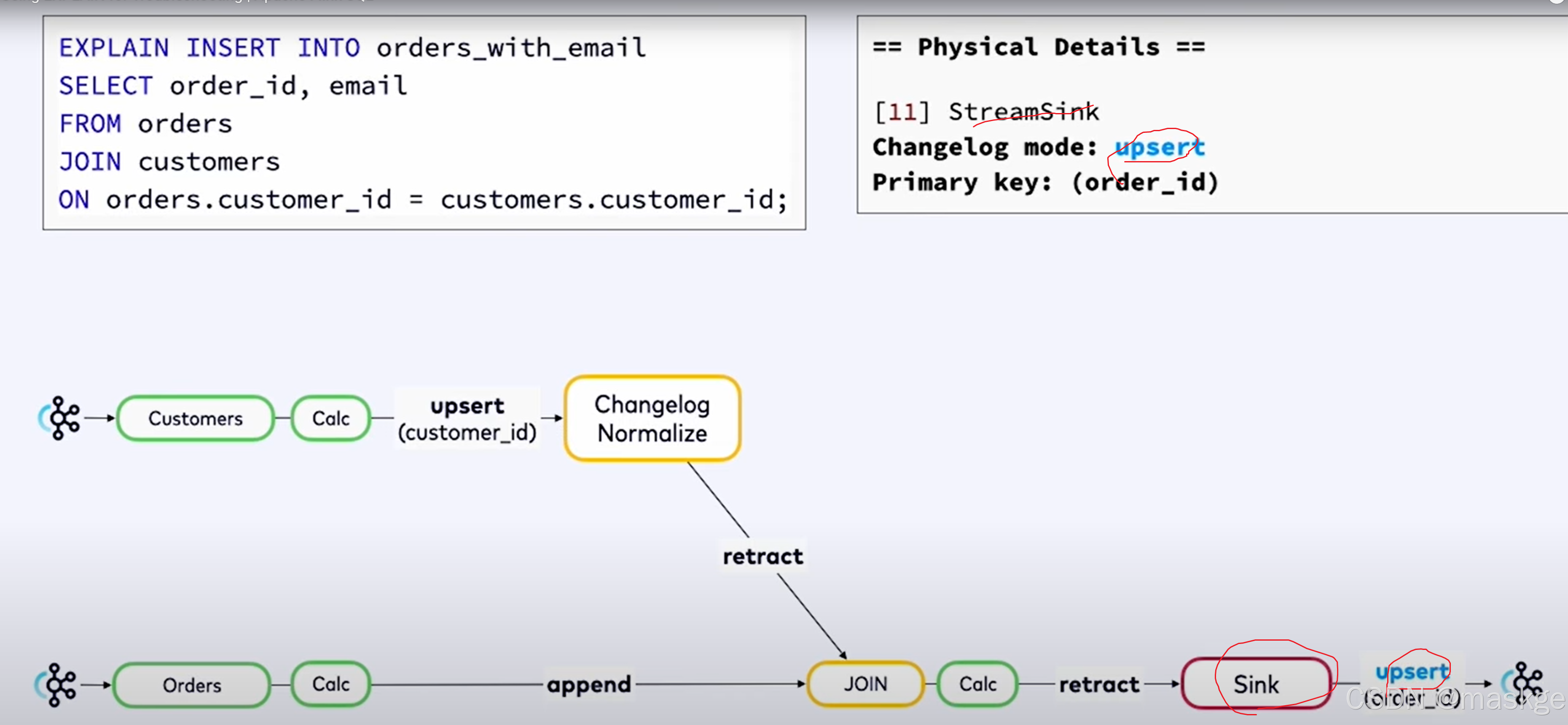
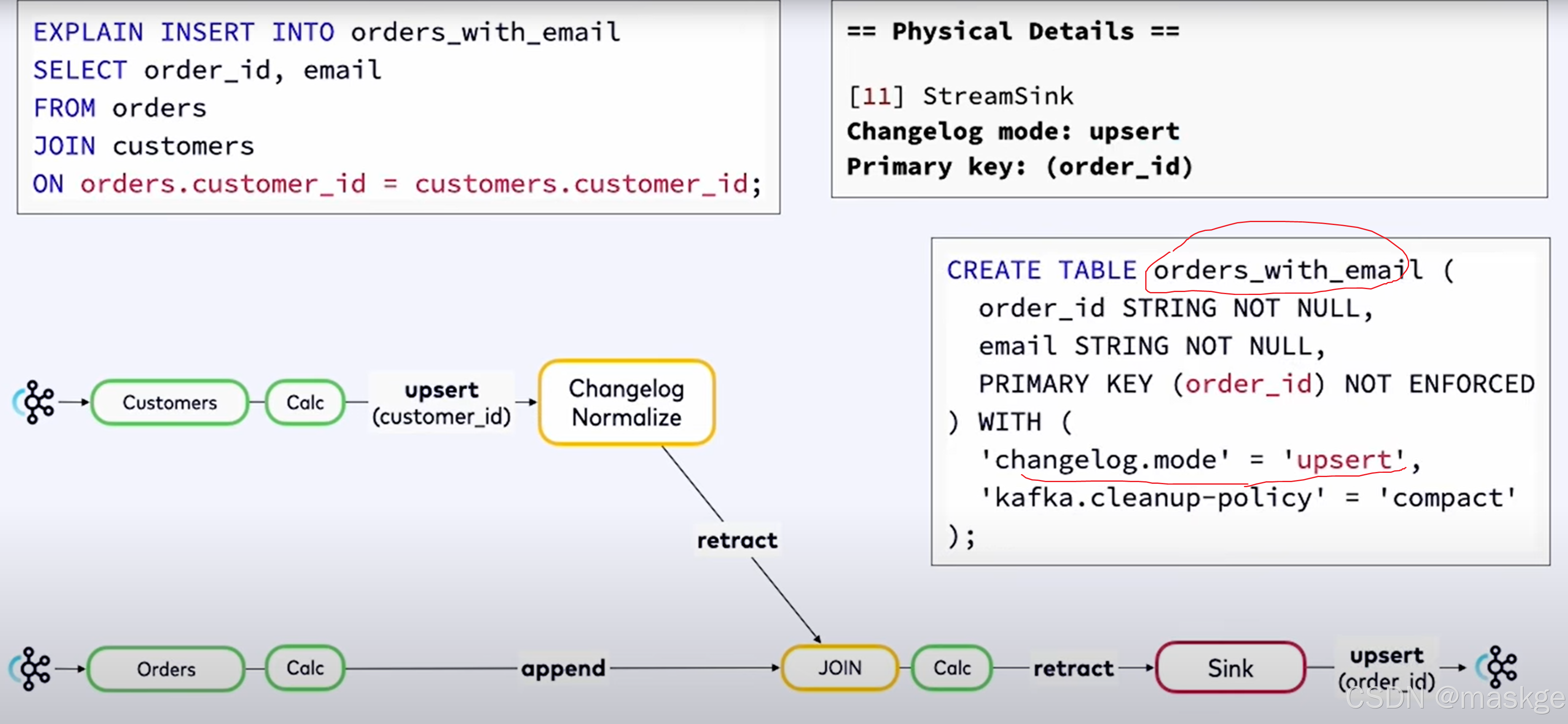
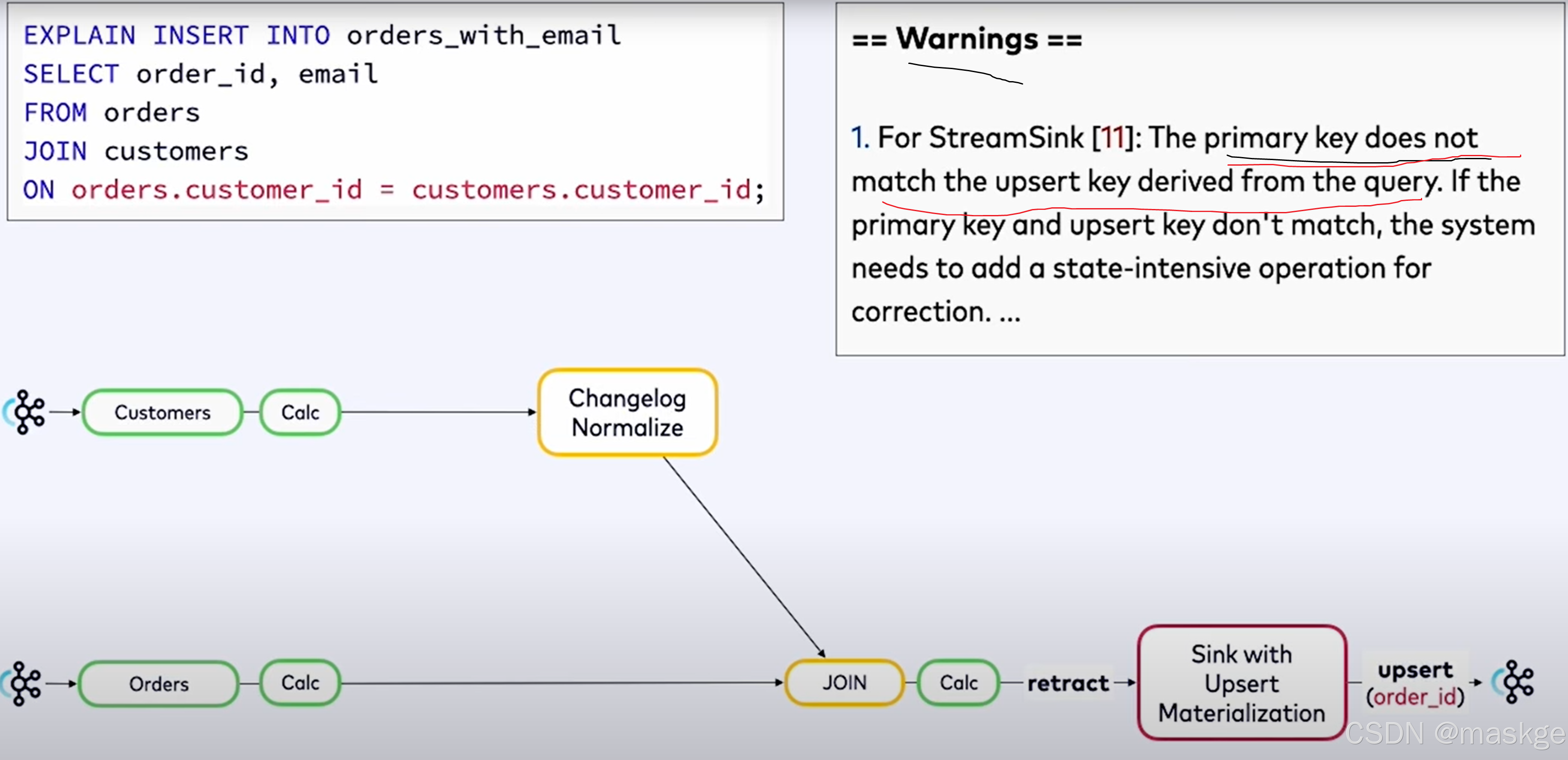
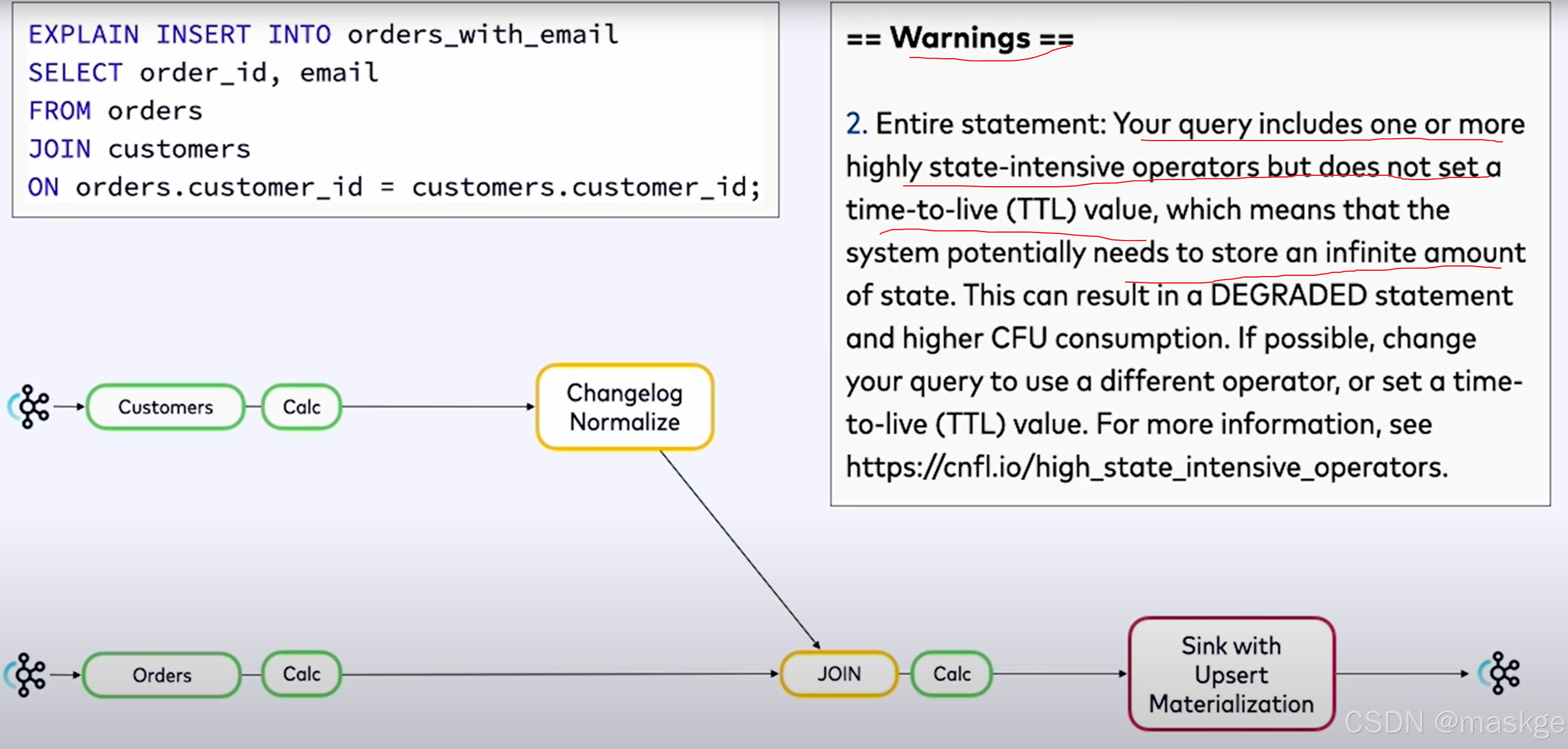
错误消息如下:
XXX doesn't support consuming update and delete changes which is produced by node YYY
原因分析:这表明 XXX 是一种无法接受更新流作为输入的操作,而 YYY 是一种会生成更新流的操作。解决这类问题的一种方法是将 YYY 改为同一操作的基于时间的版本:例如,用临时连接替换常规连接,或者用窗口去重替换去重。
错误消息如下:
he window function requires the timecol is a time attribute type, but is a TIMESTAMP(3).
原因分析:提供的作为窗口划分依据的时间戳列没有关联水印
6.使用MATCH_RECOGNIZE 进行模式识别和复杂事件处理



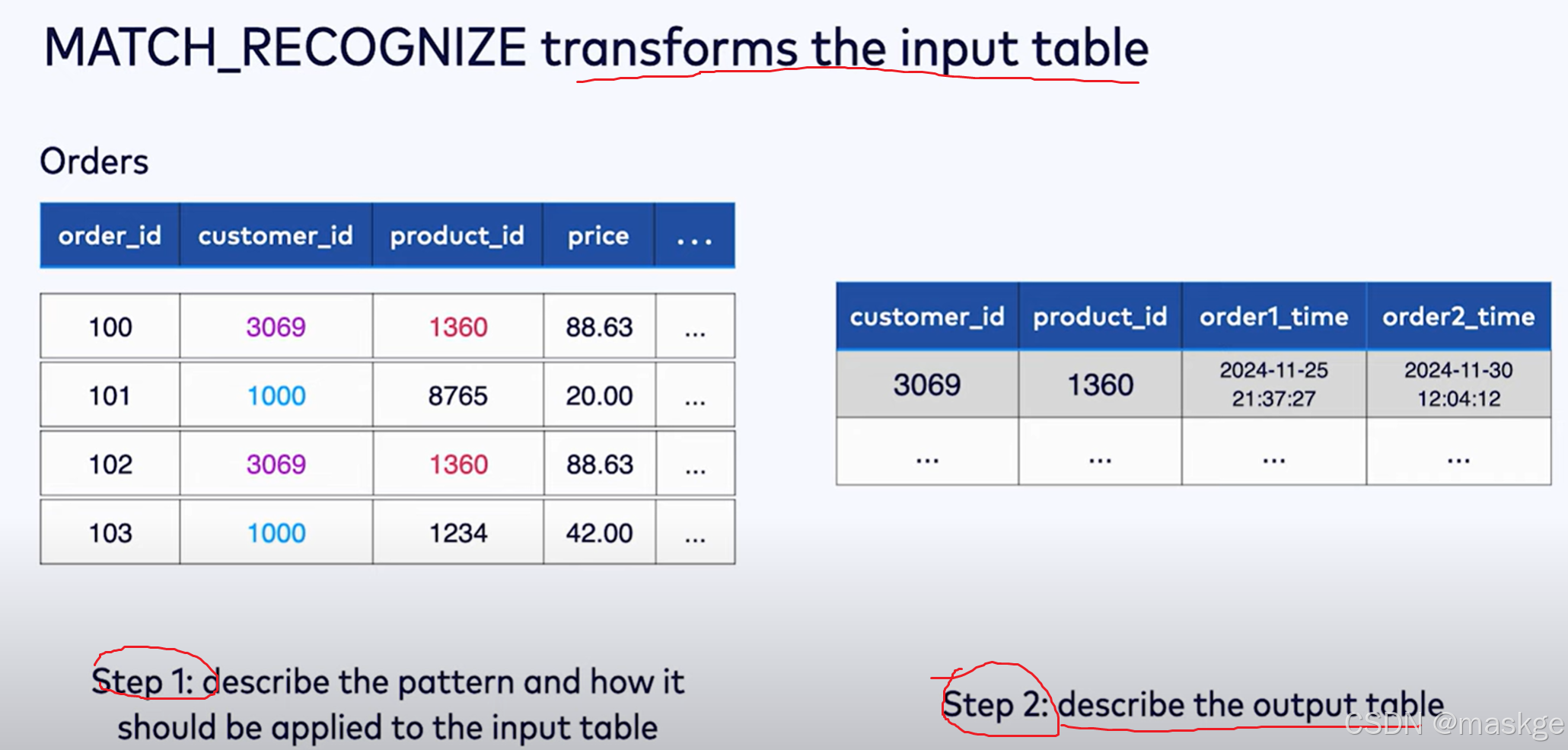
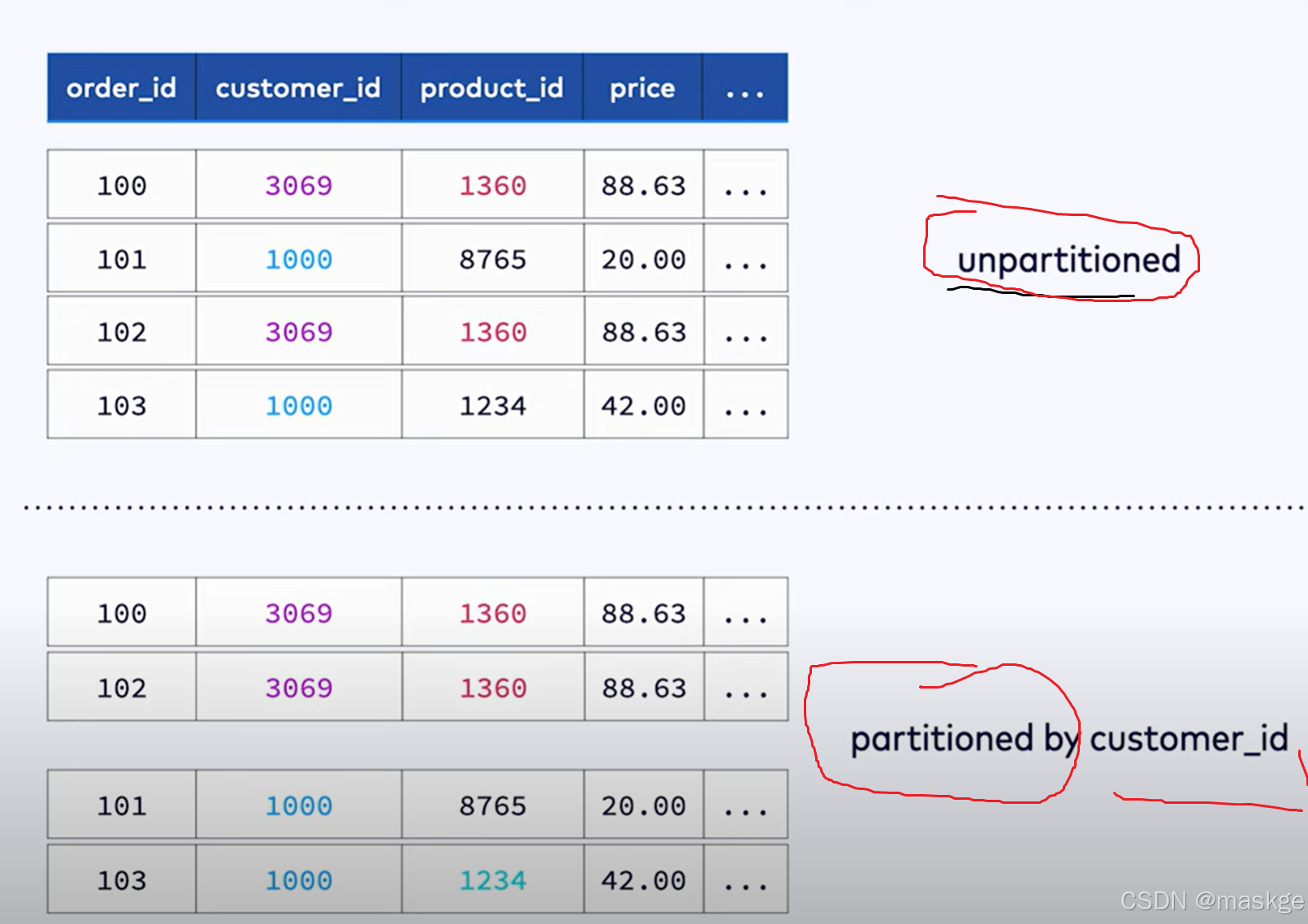
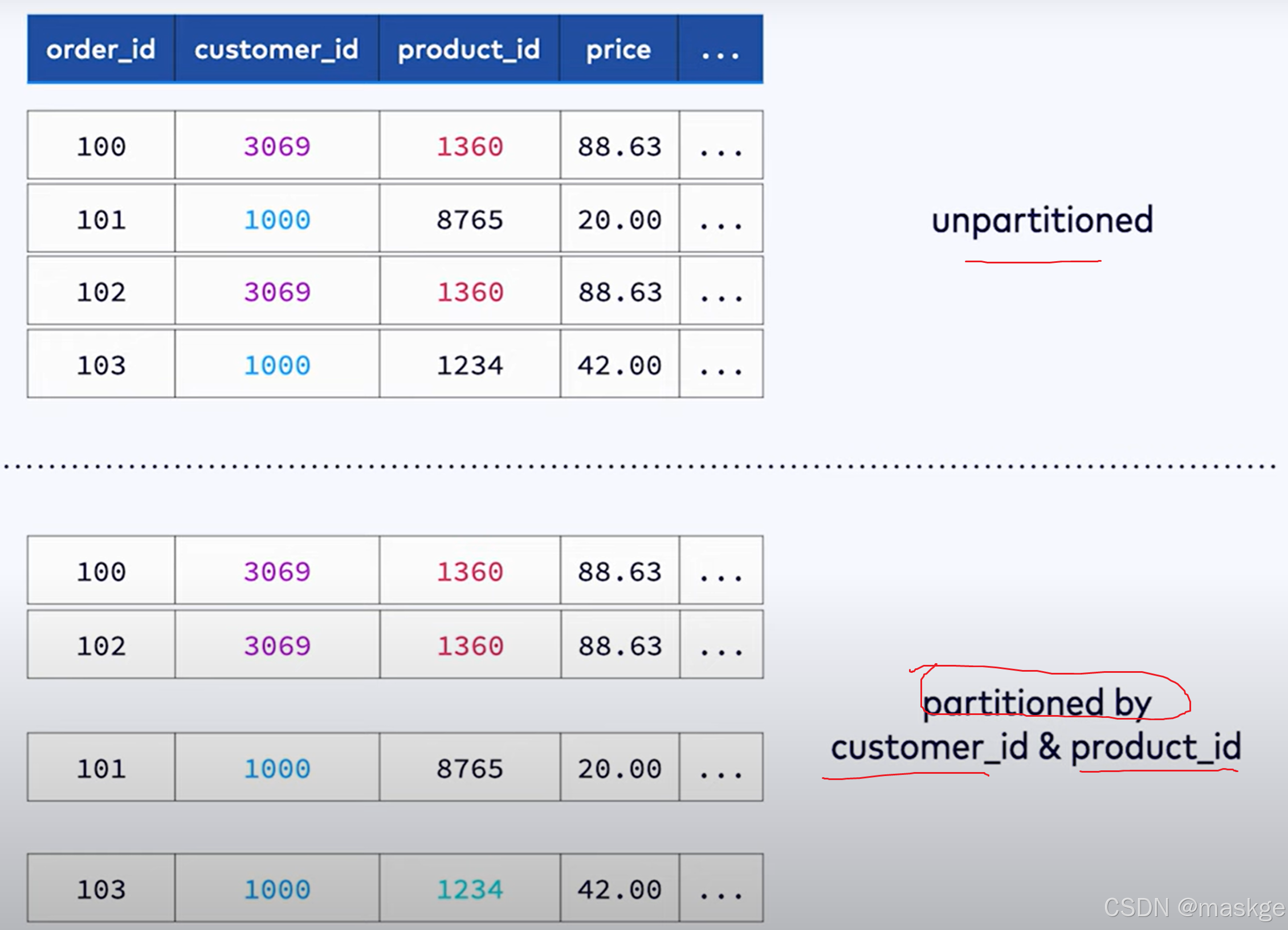


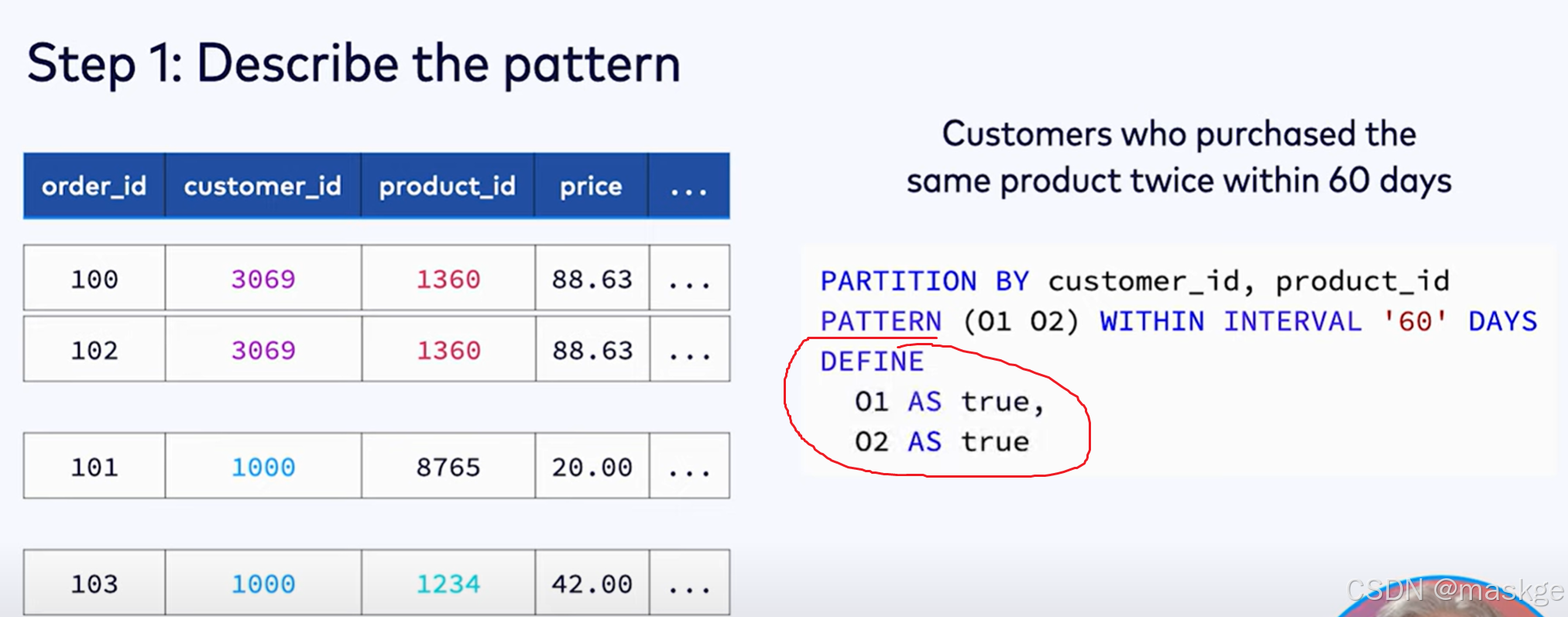
必须根据时间属性排序
flink仅支持match_recognize在streaming模式下,以及输入流的排序根据输入表的时间属性

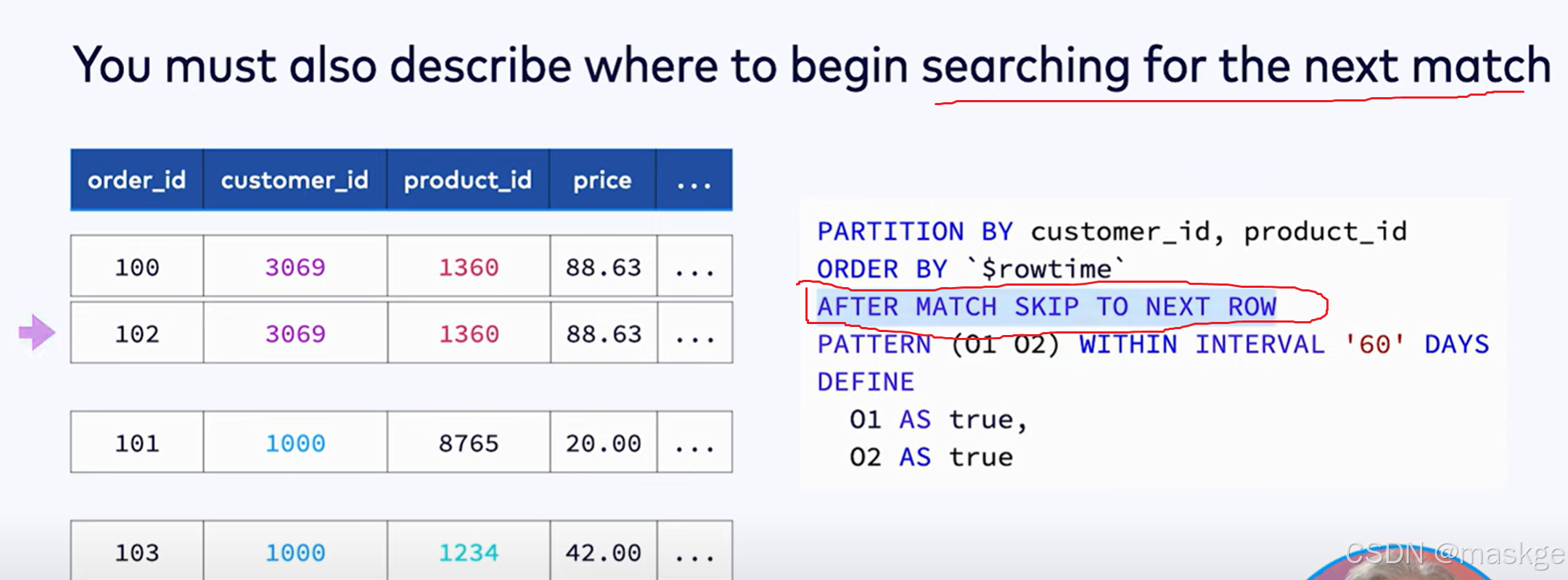














上面这种模式在有界流的模式下,一旦匹配会产生一个最终的结果,但是如果是无界流,这种模式永远不会完全匹配;
要修复这种无法完全匹配模式,可以采用如下模式:

模式匹配的应用

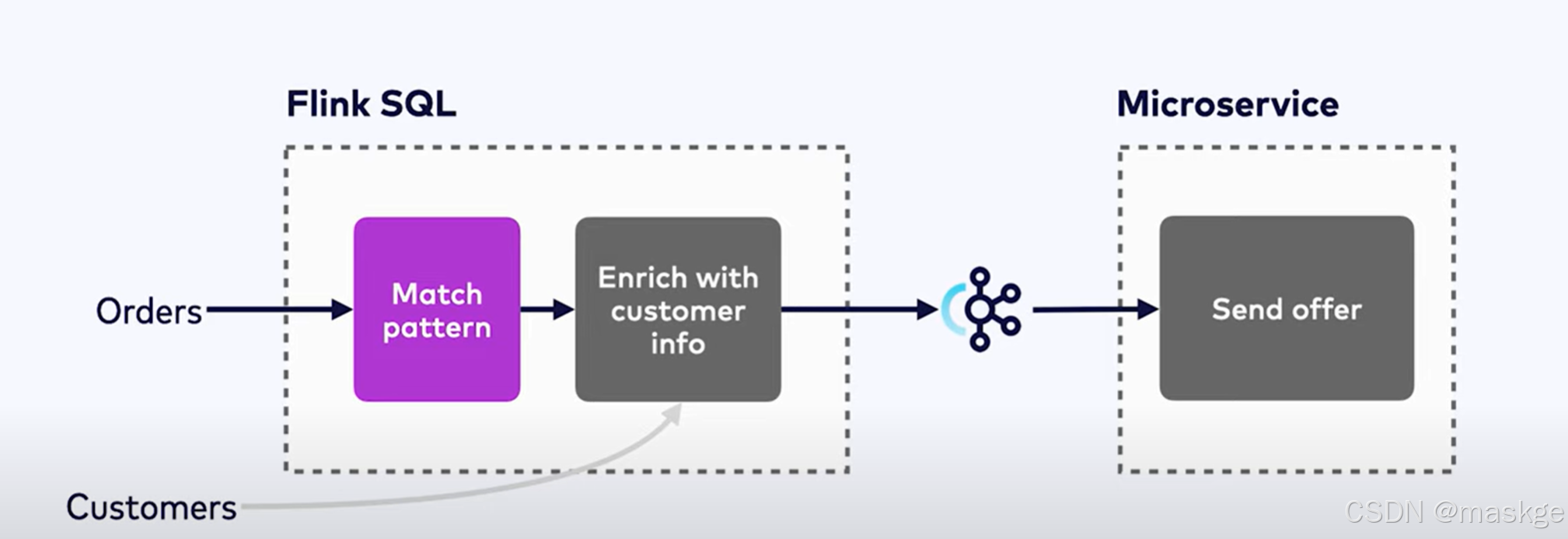




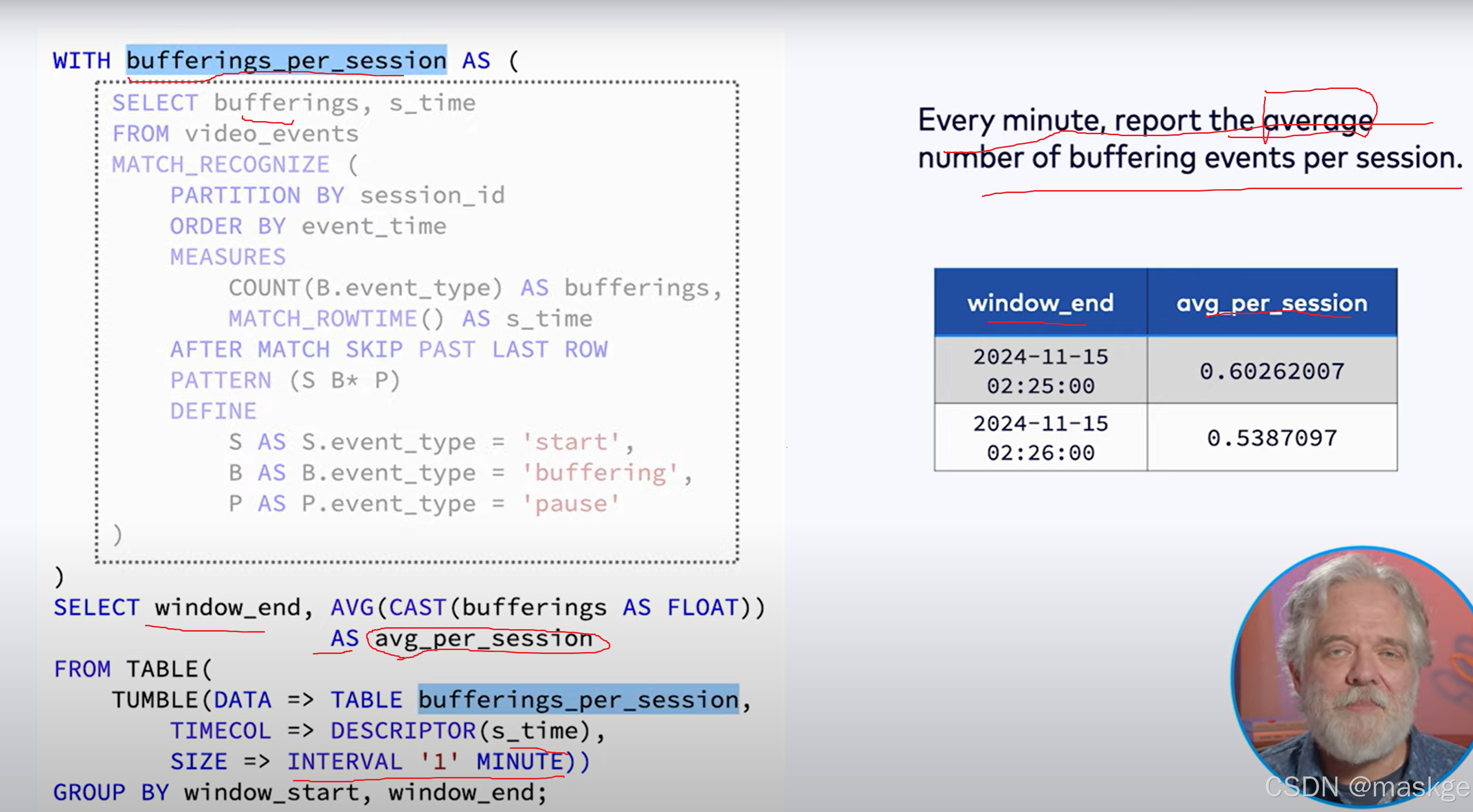
Match_recognize实践考虑点:
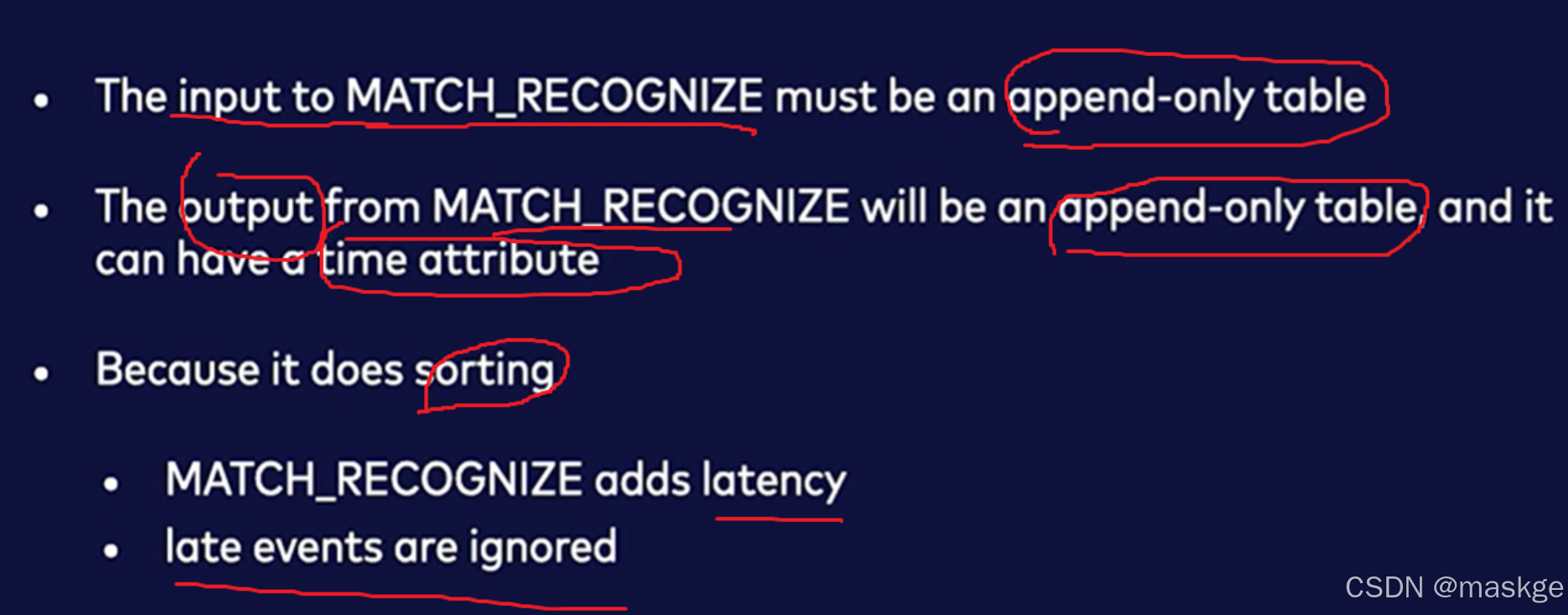
MATCH_RECOGNIZE最佳实践:



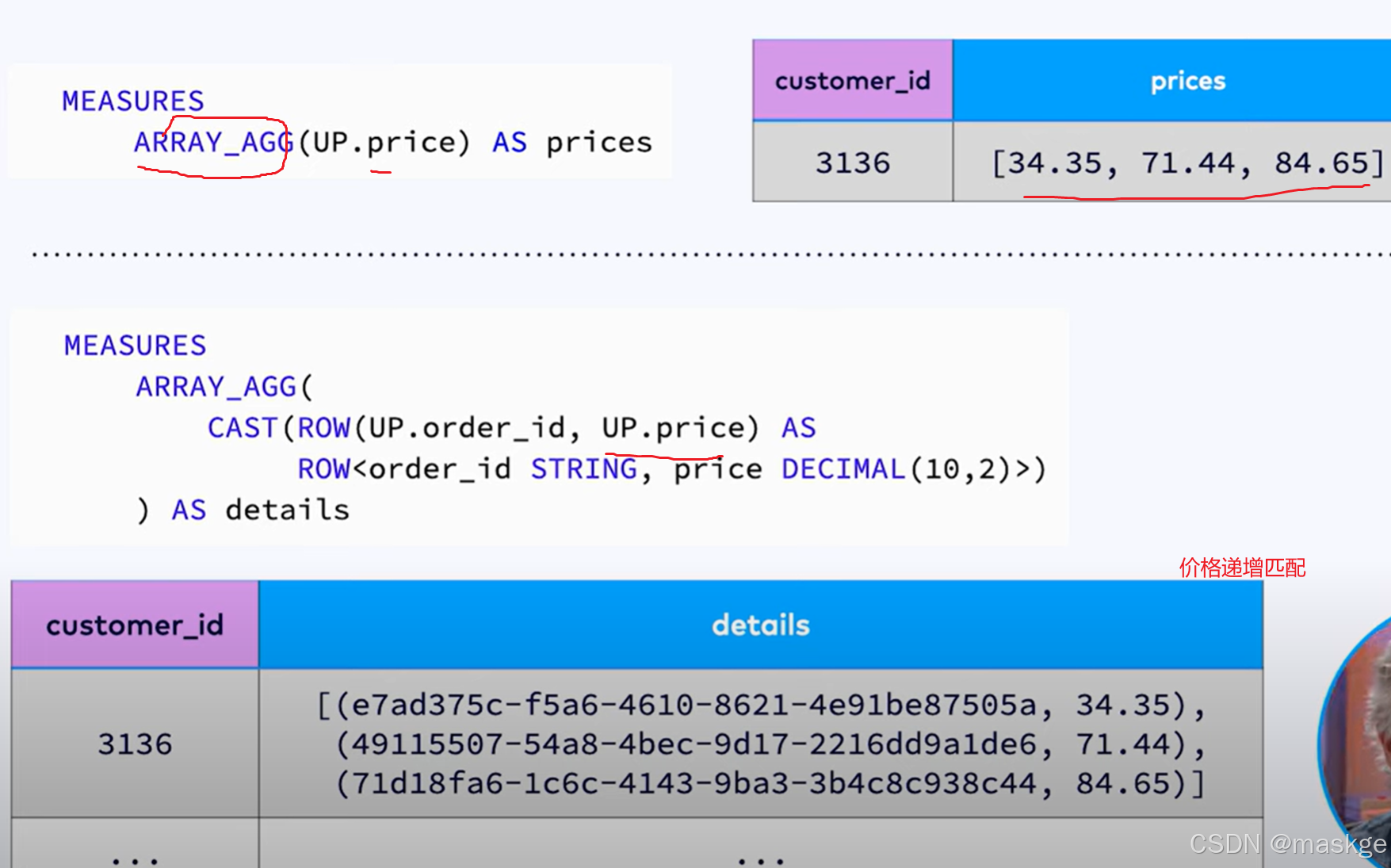
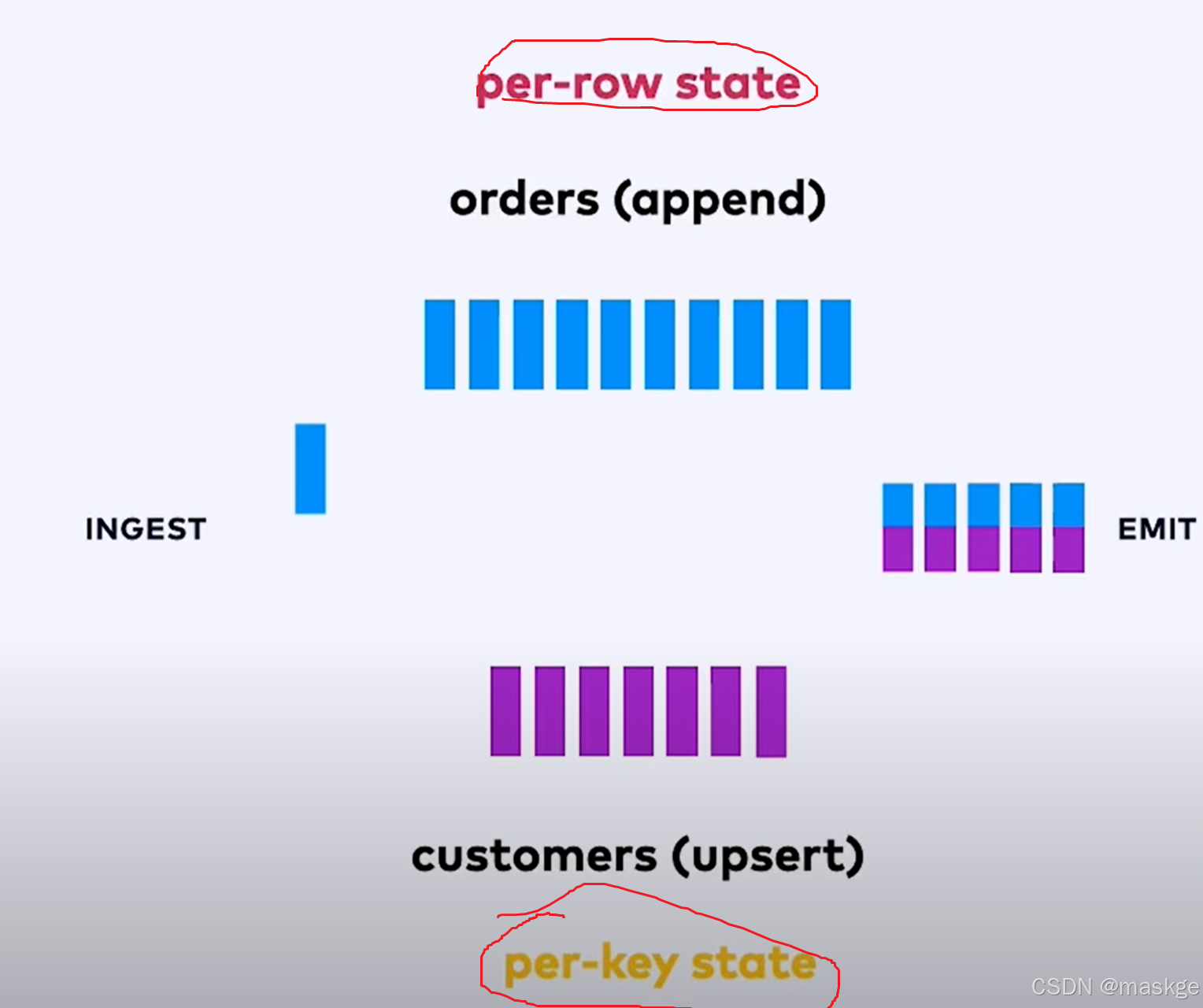
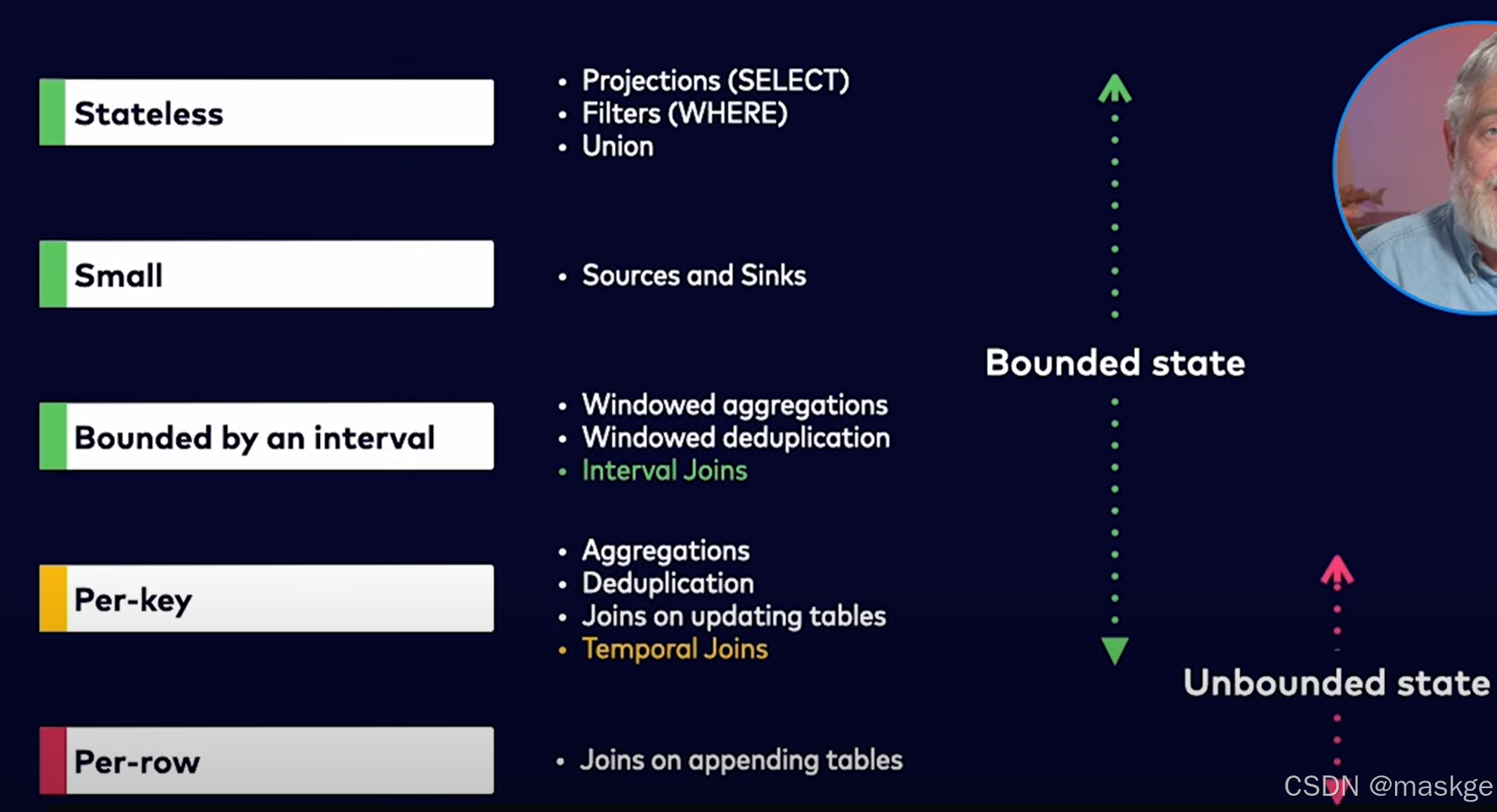
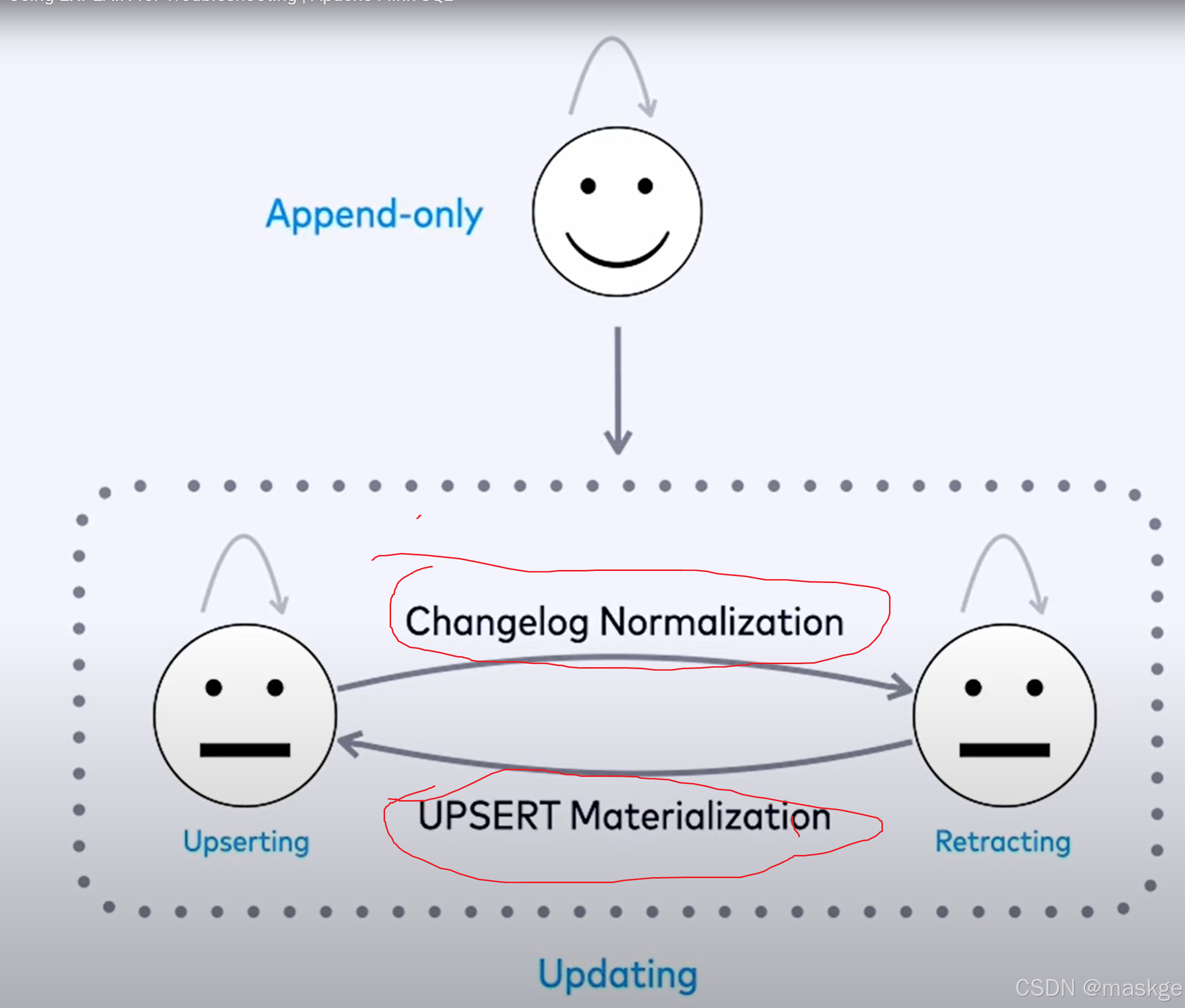
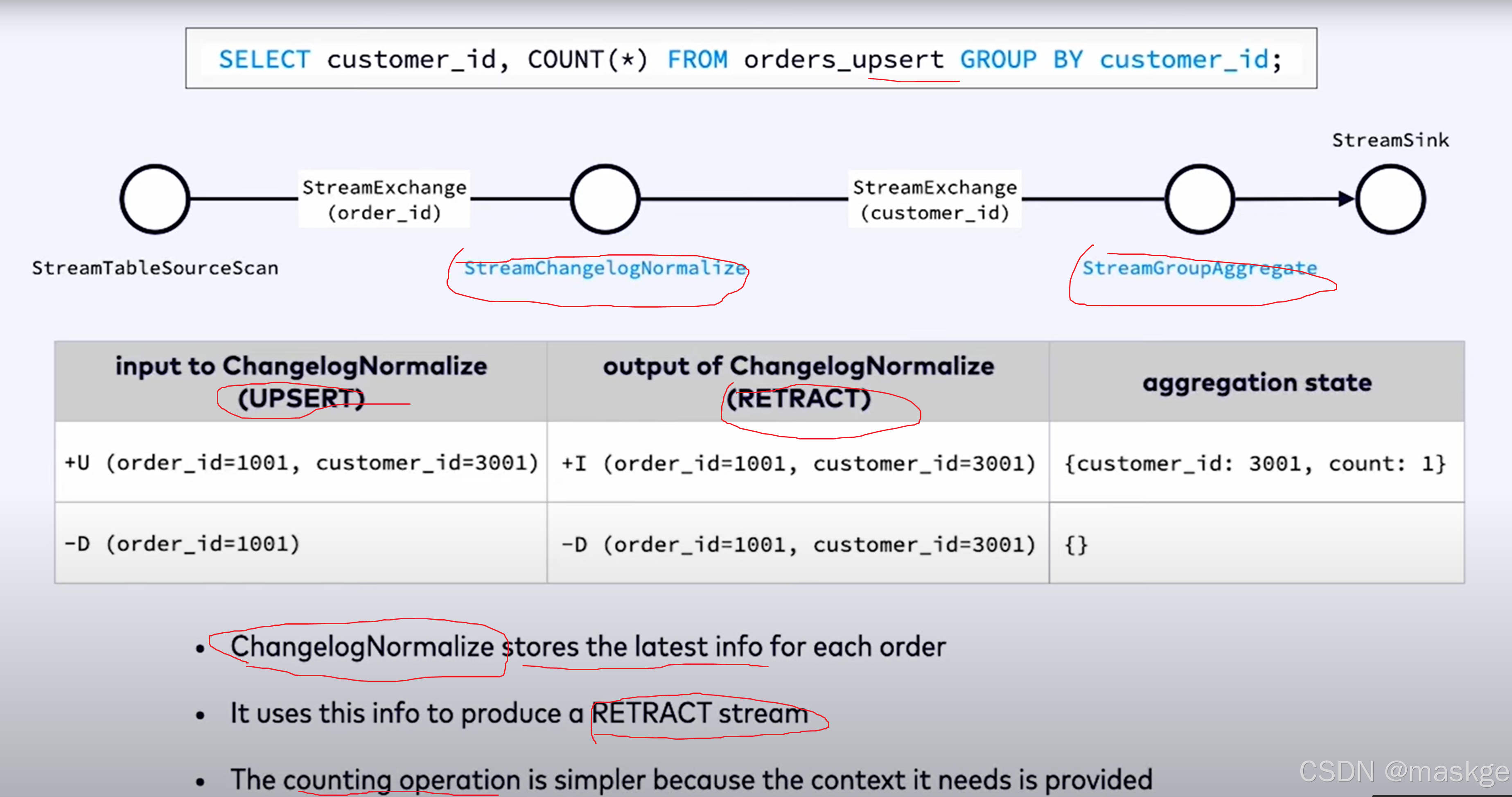
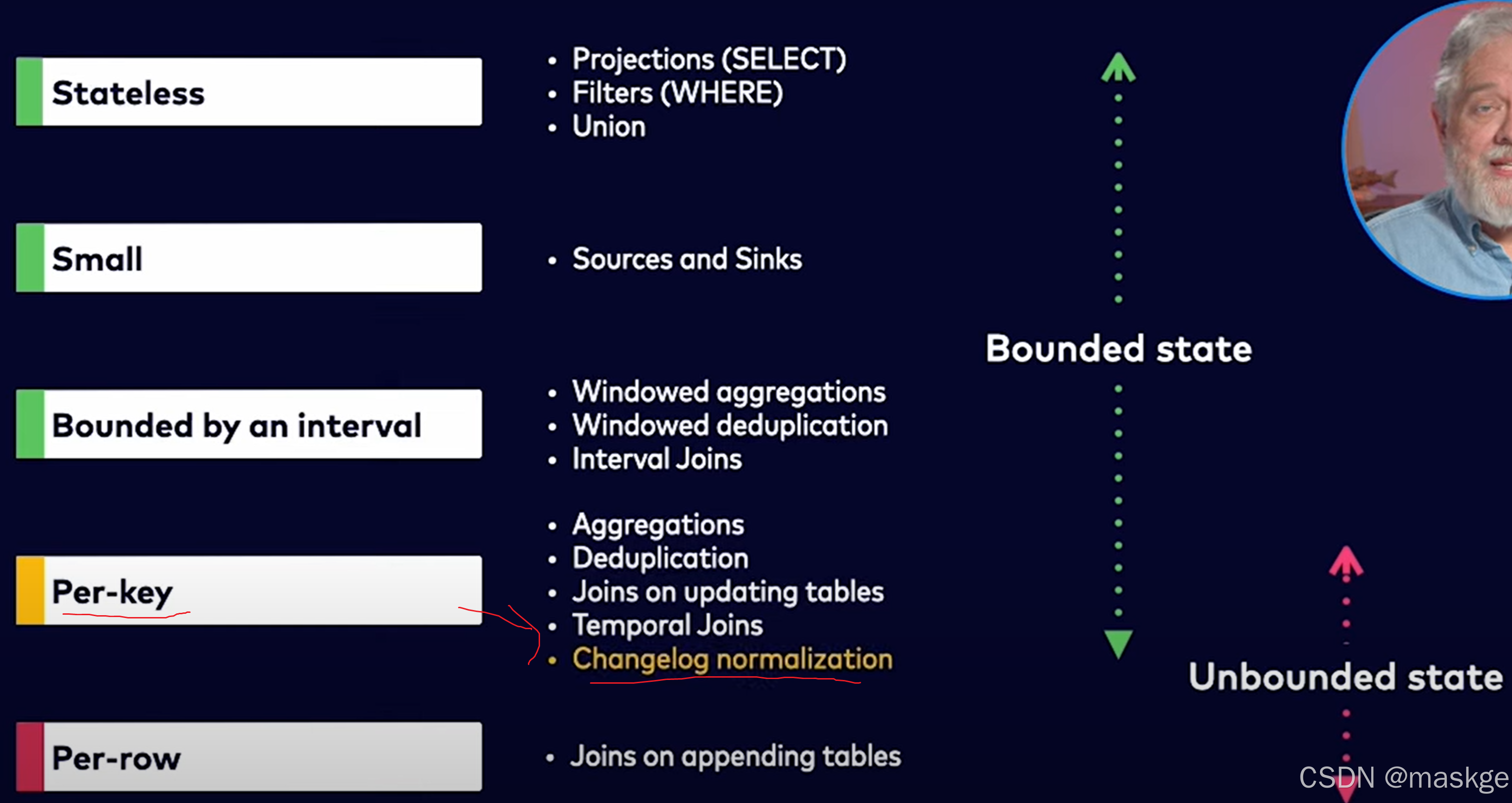
7.变更记录(changelog)处理以及变更更新错误排查


避免上面这种错误的最佳实践如下:





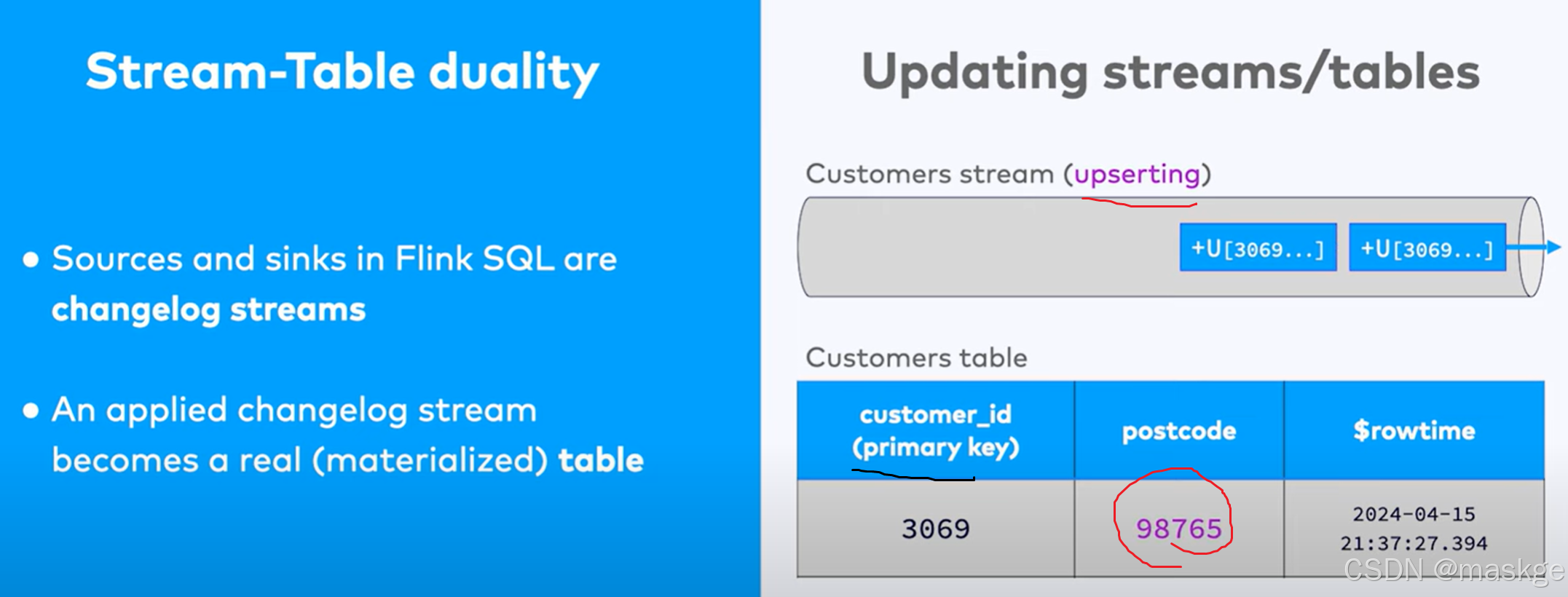
变更记录模式(Changelog modes):
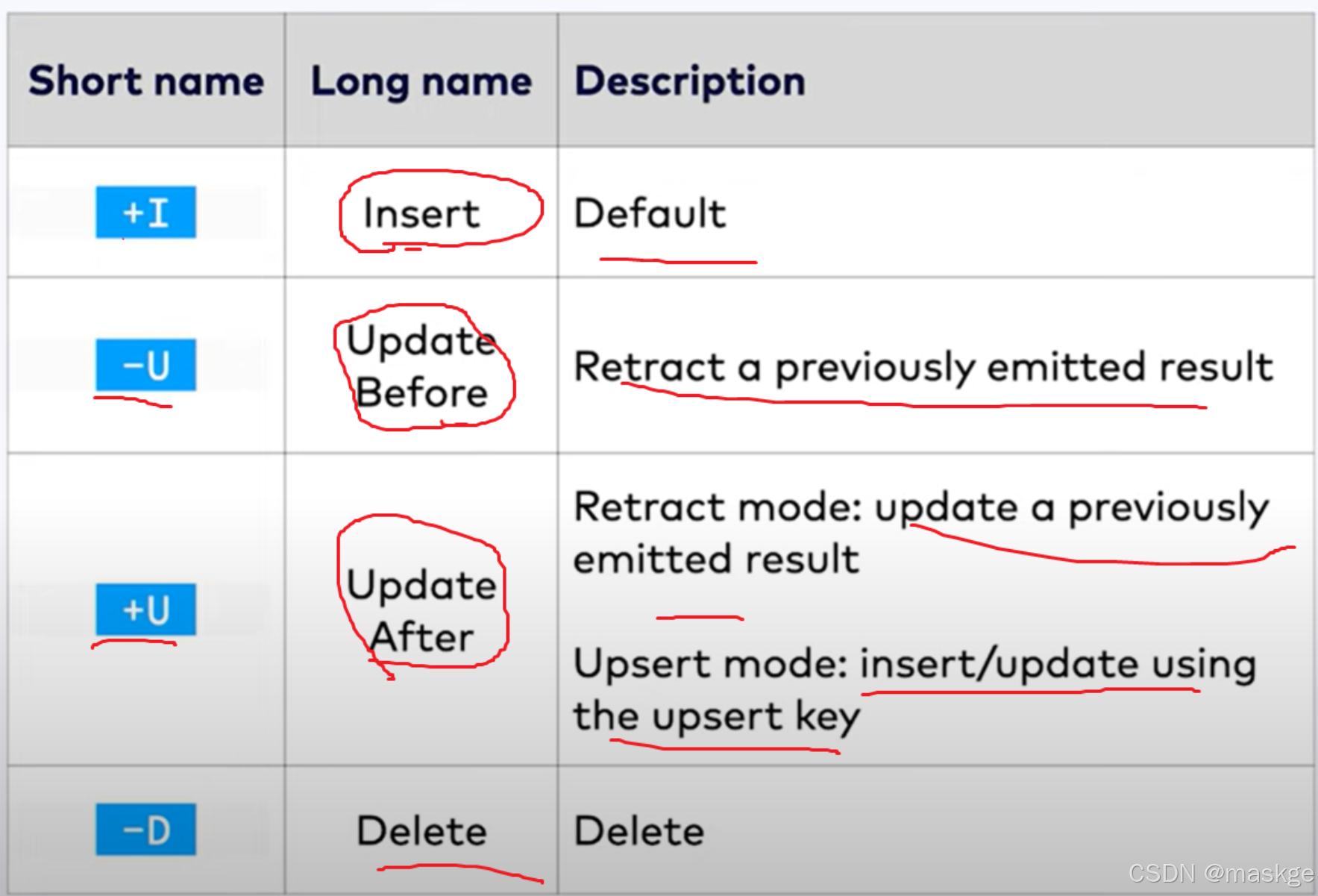
flink的2种changelog 流:
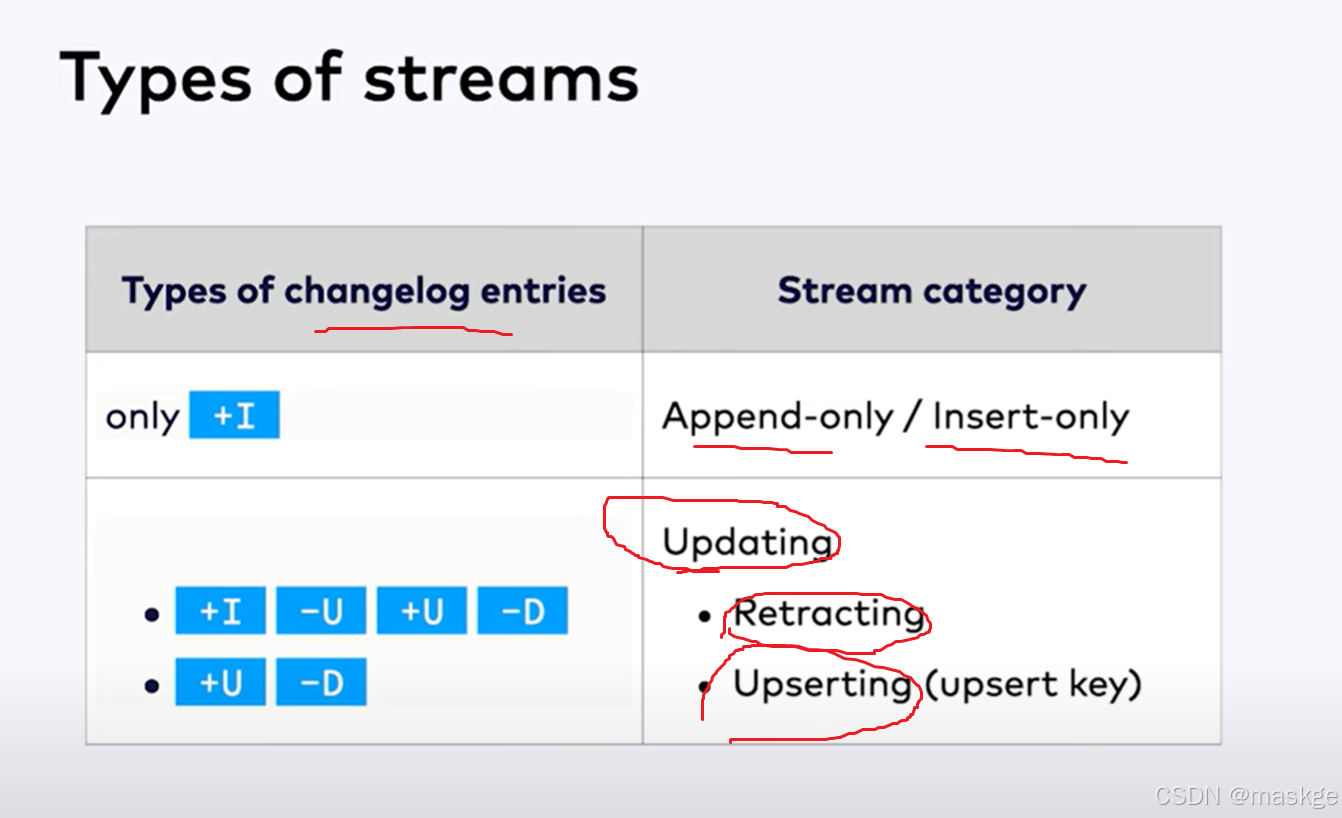
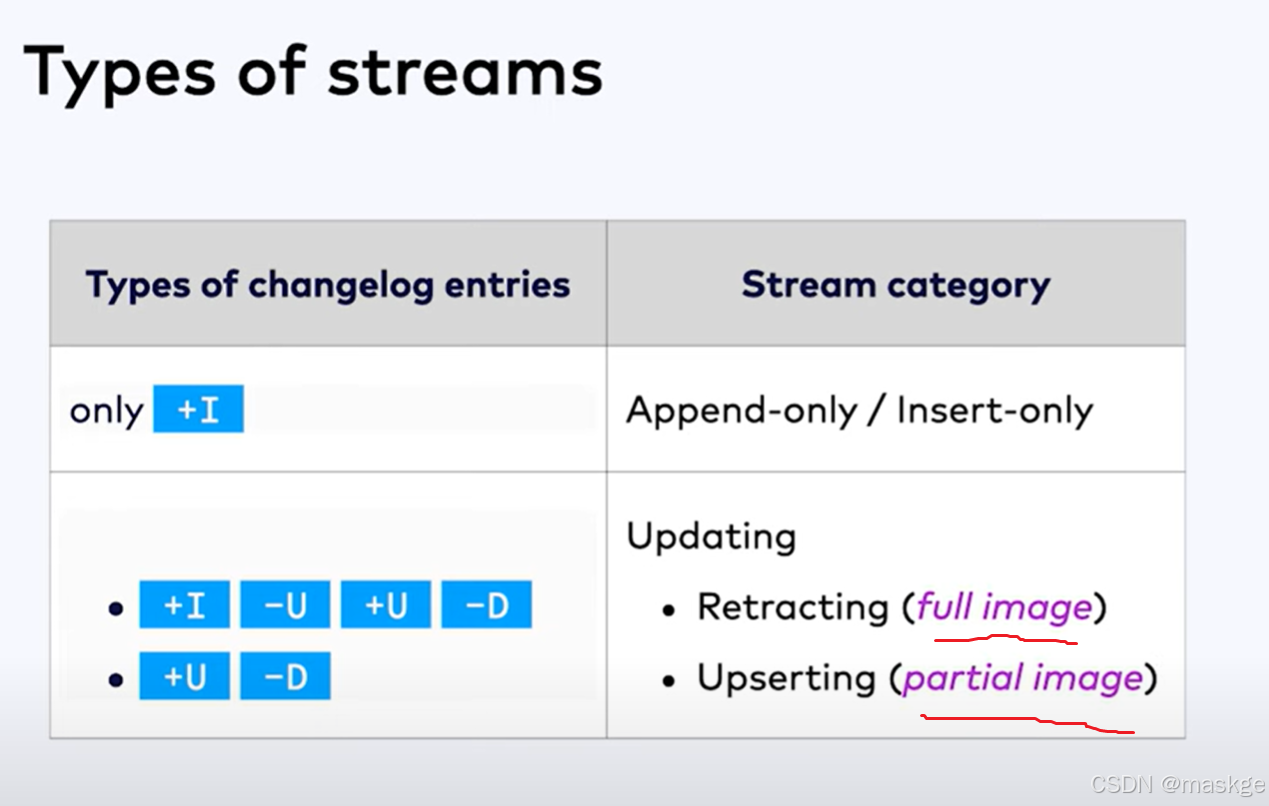





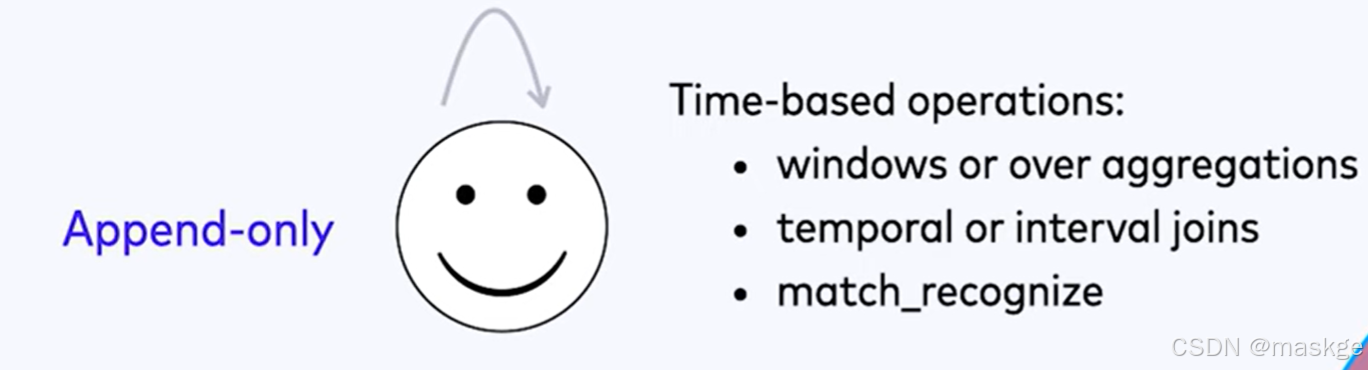
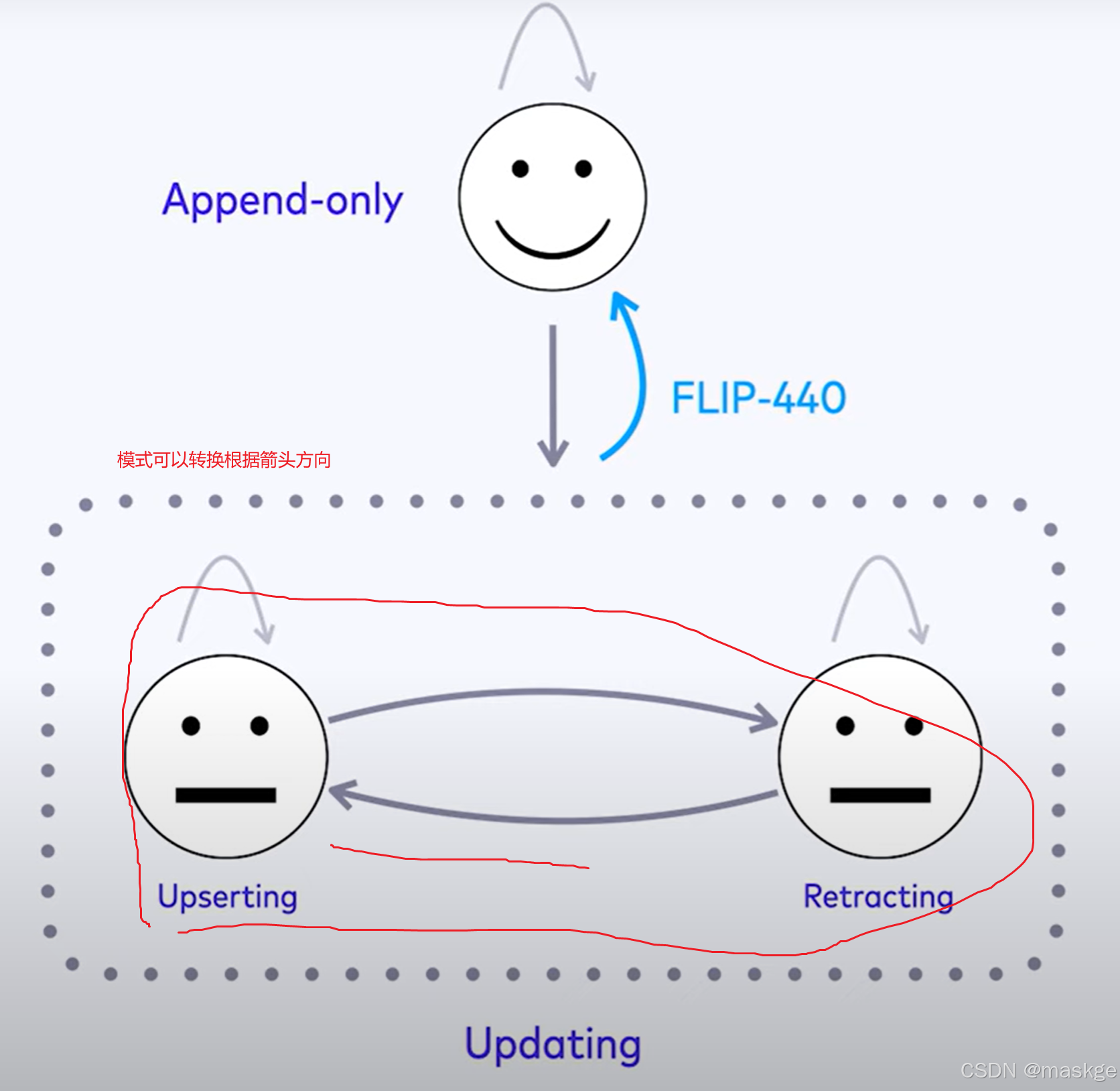
Stream change mode:
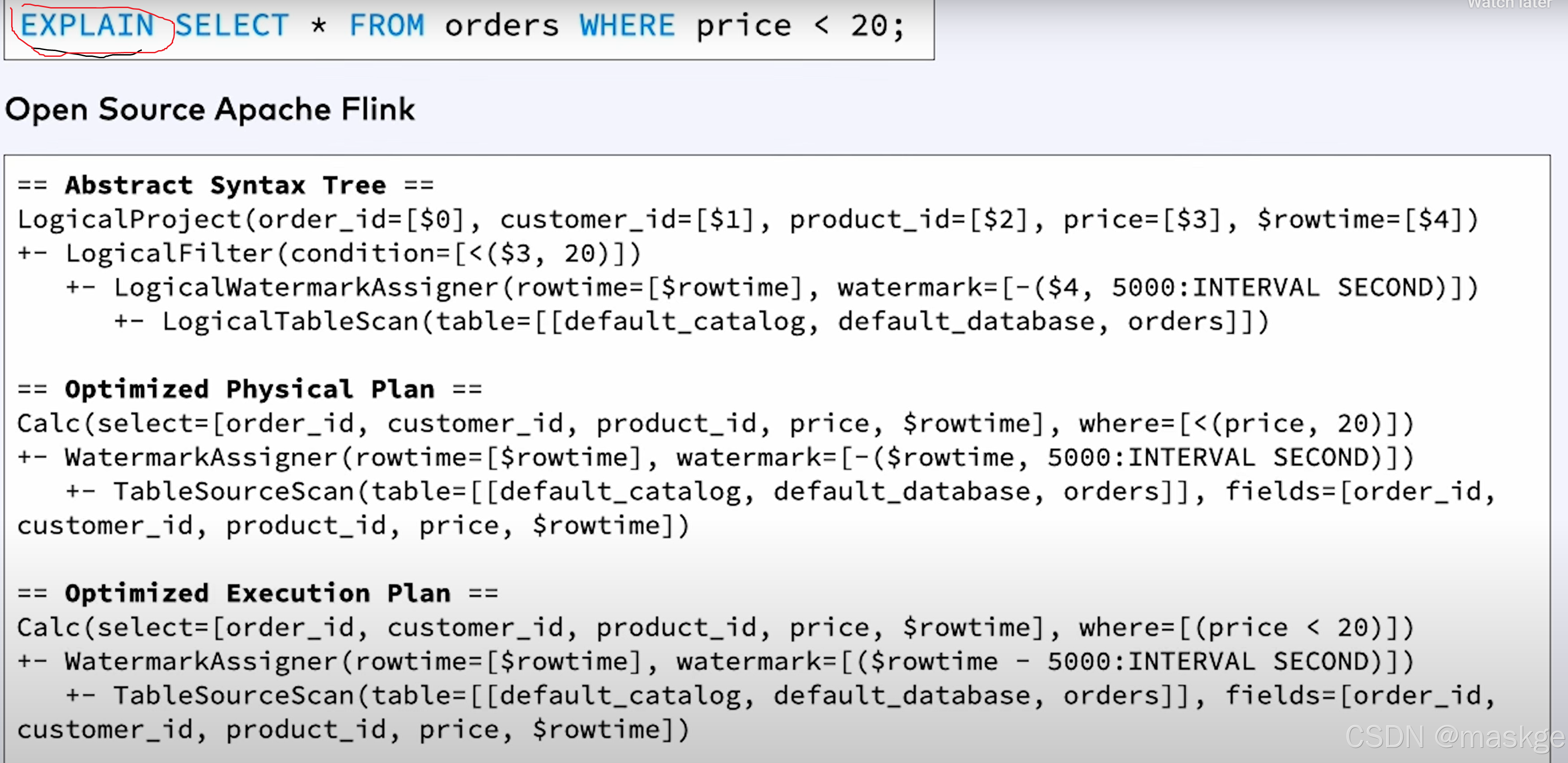
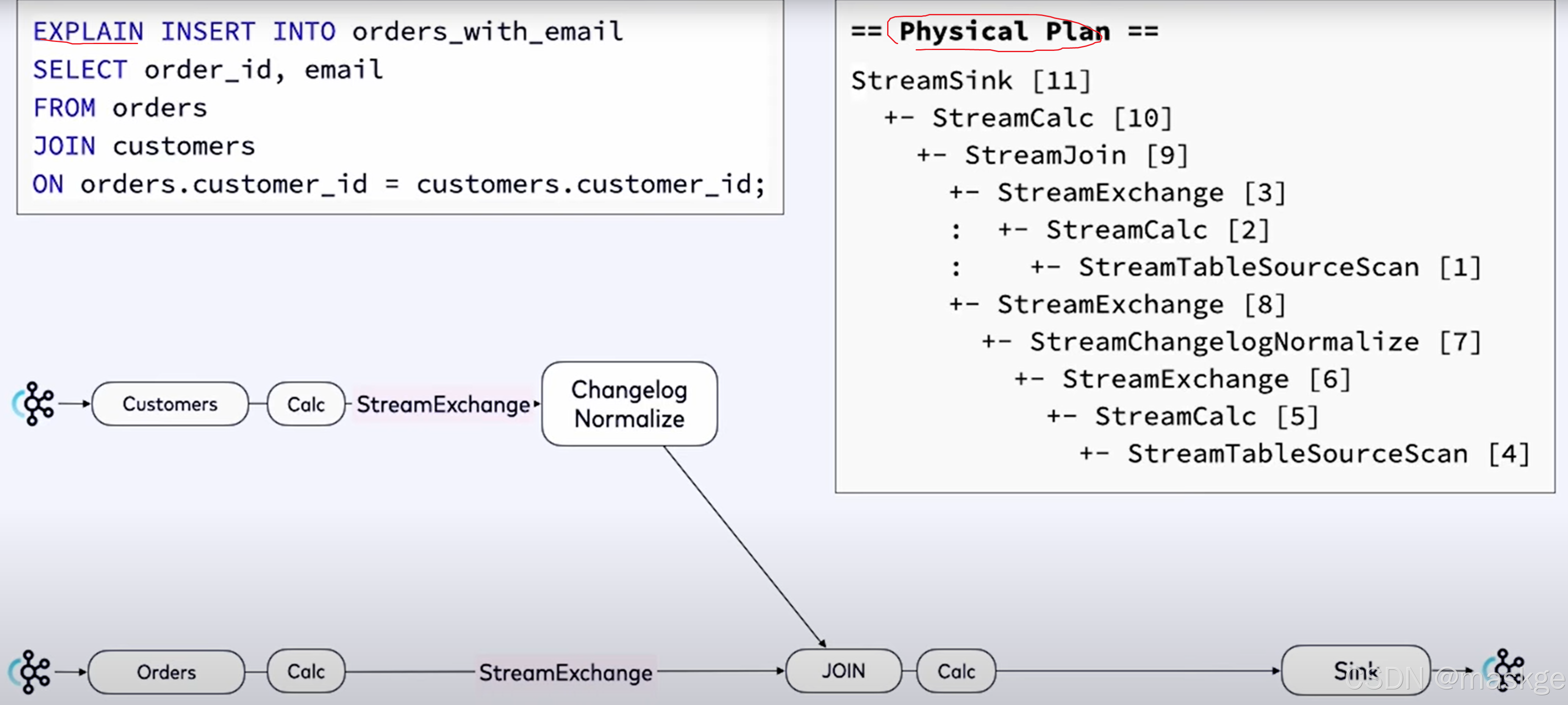
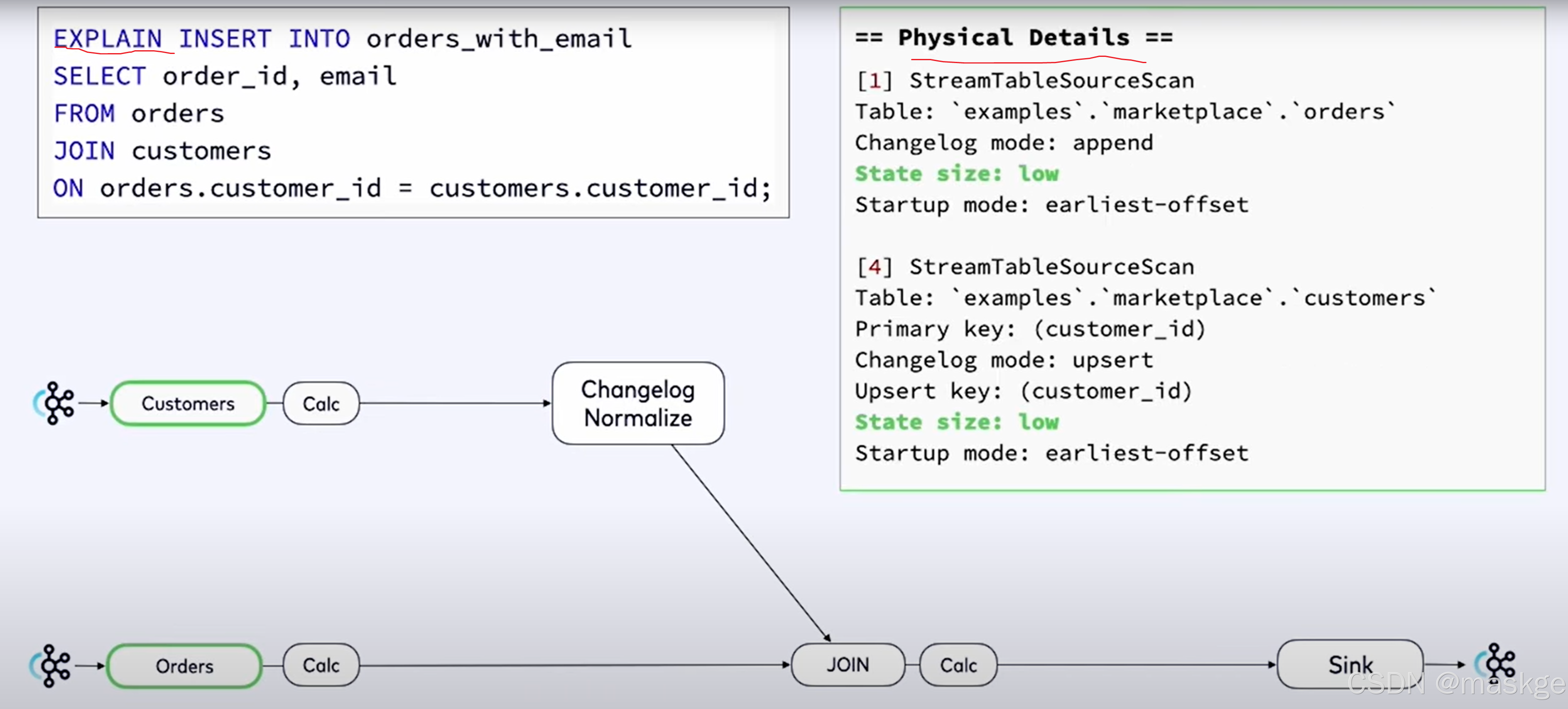
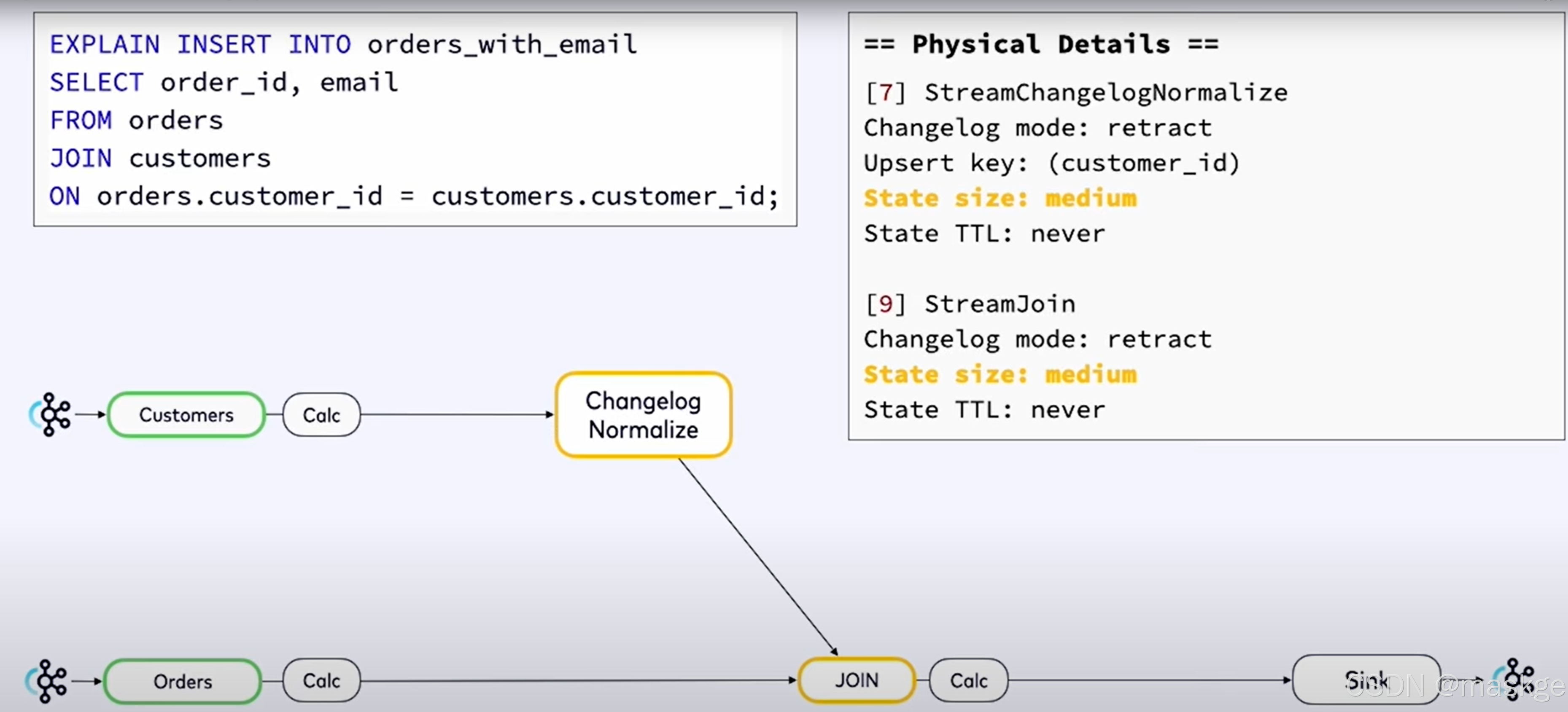
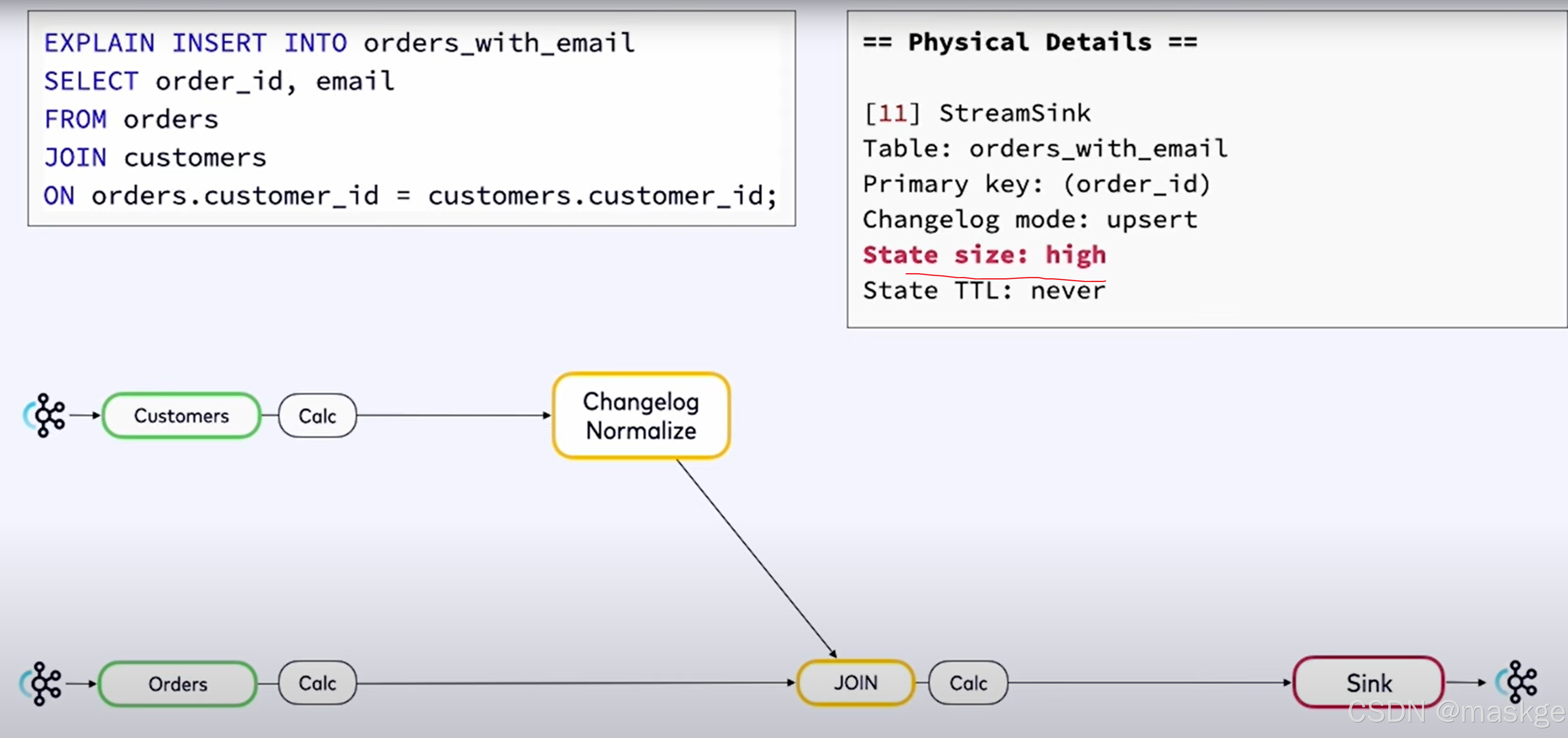
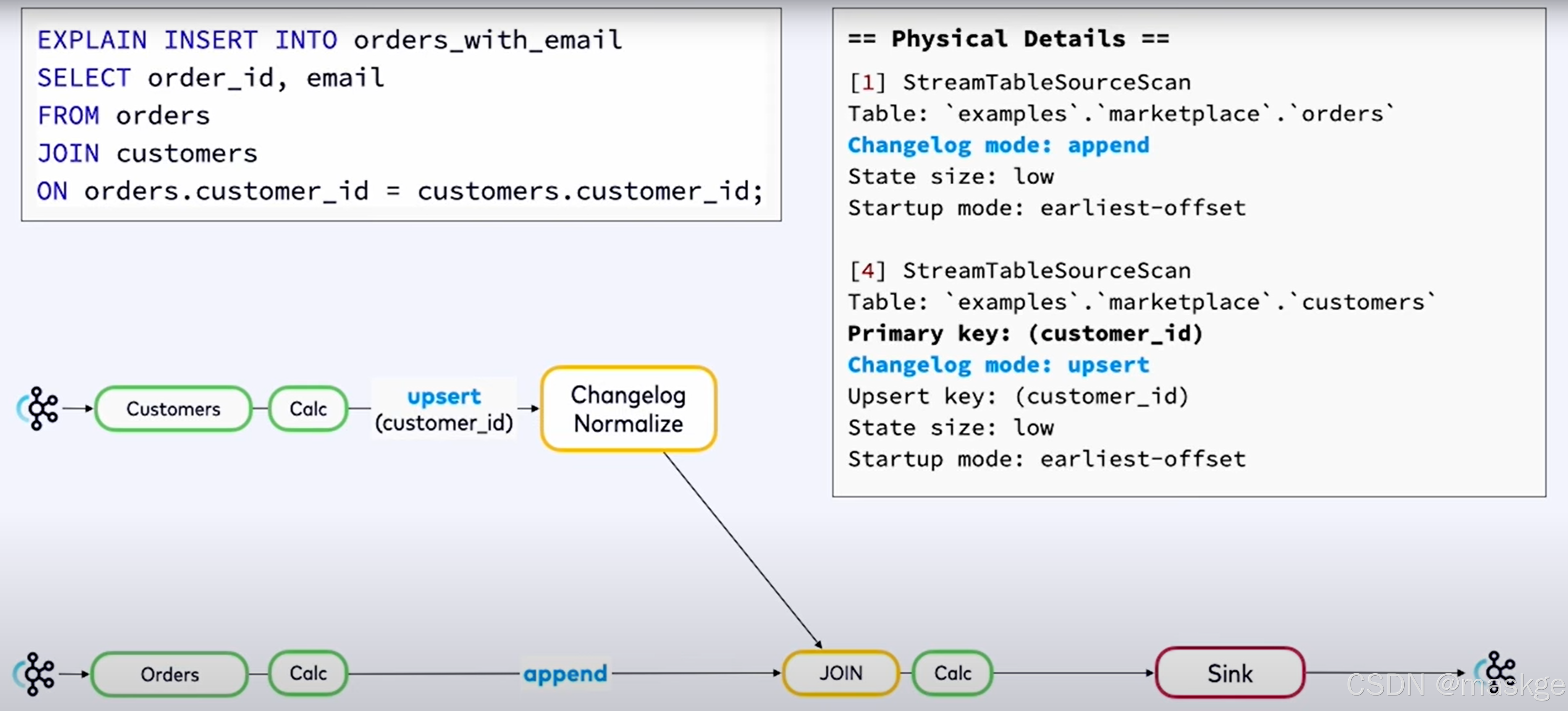
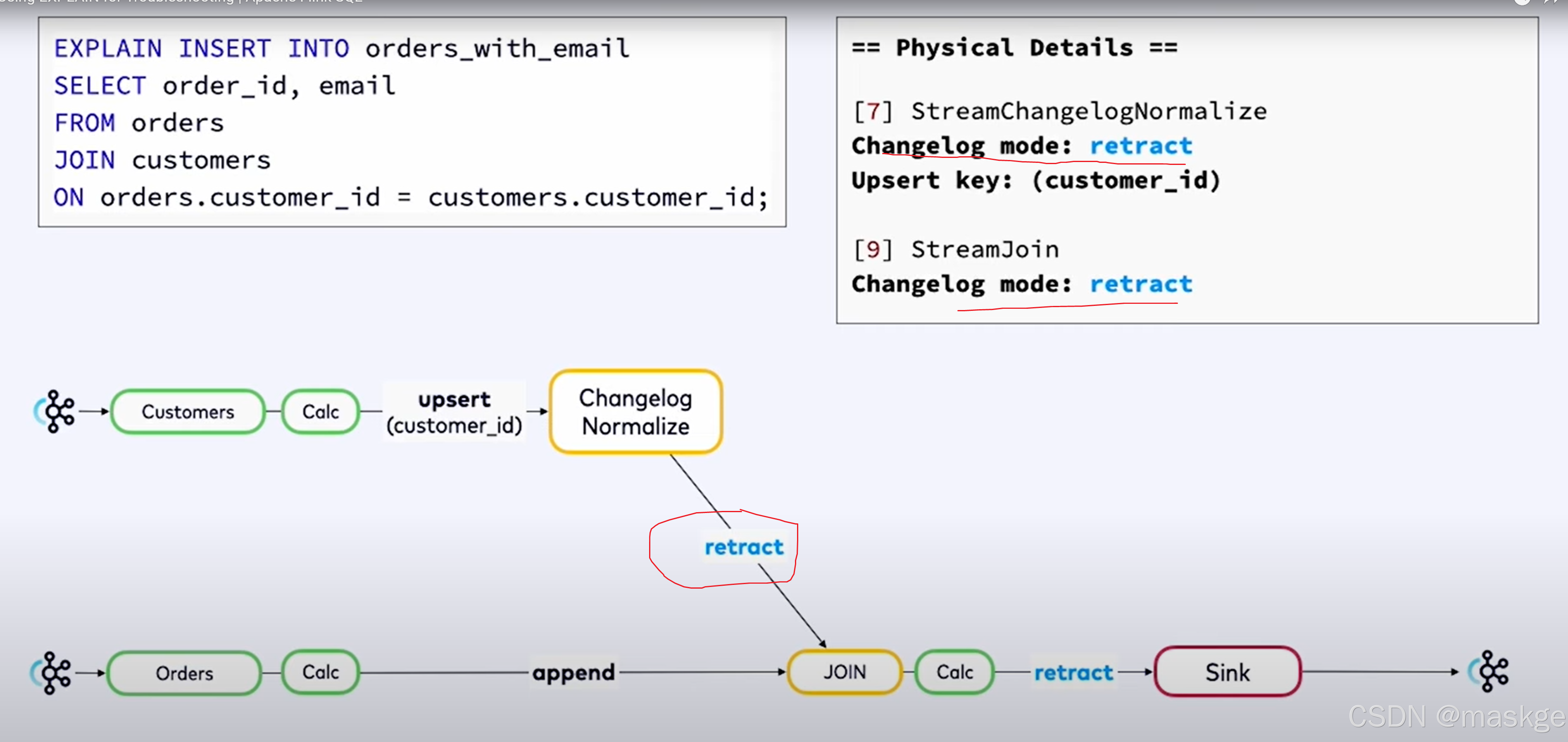
8.使用explain进行故障排除
- flink sql语句不产生结果原因是watermarks的问题
- 查询结果很慢,使用资源越来越多 原因是:state问题
flink explain诊断故障:
例子1:
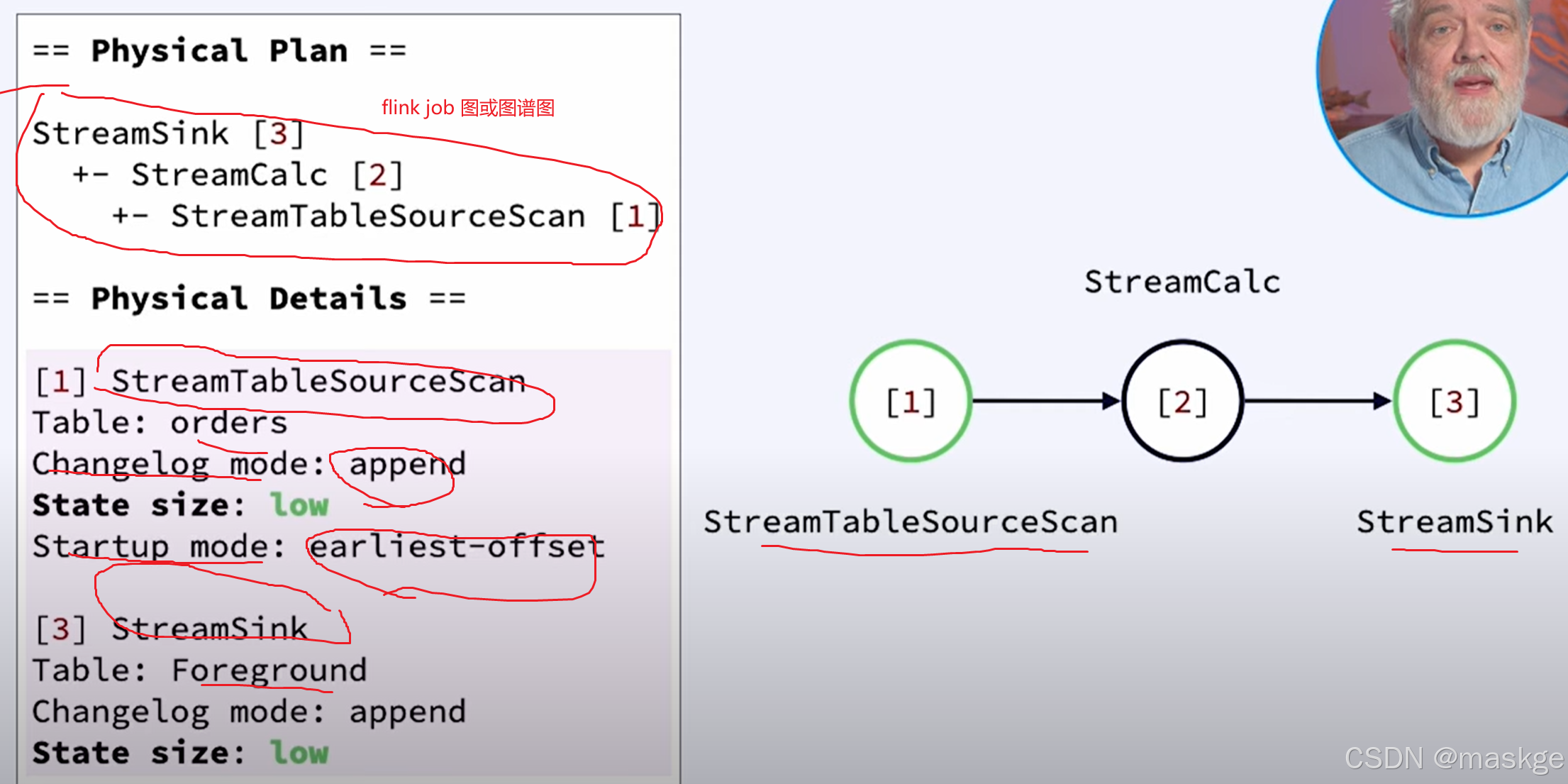
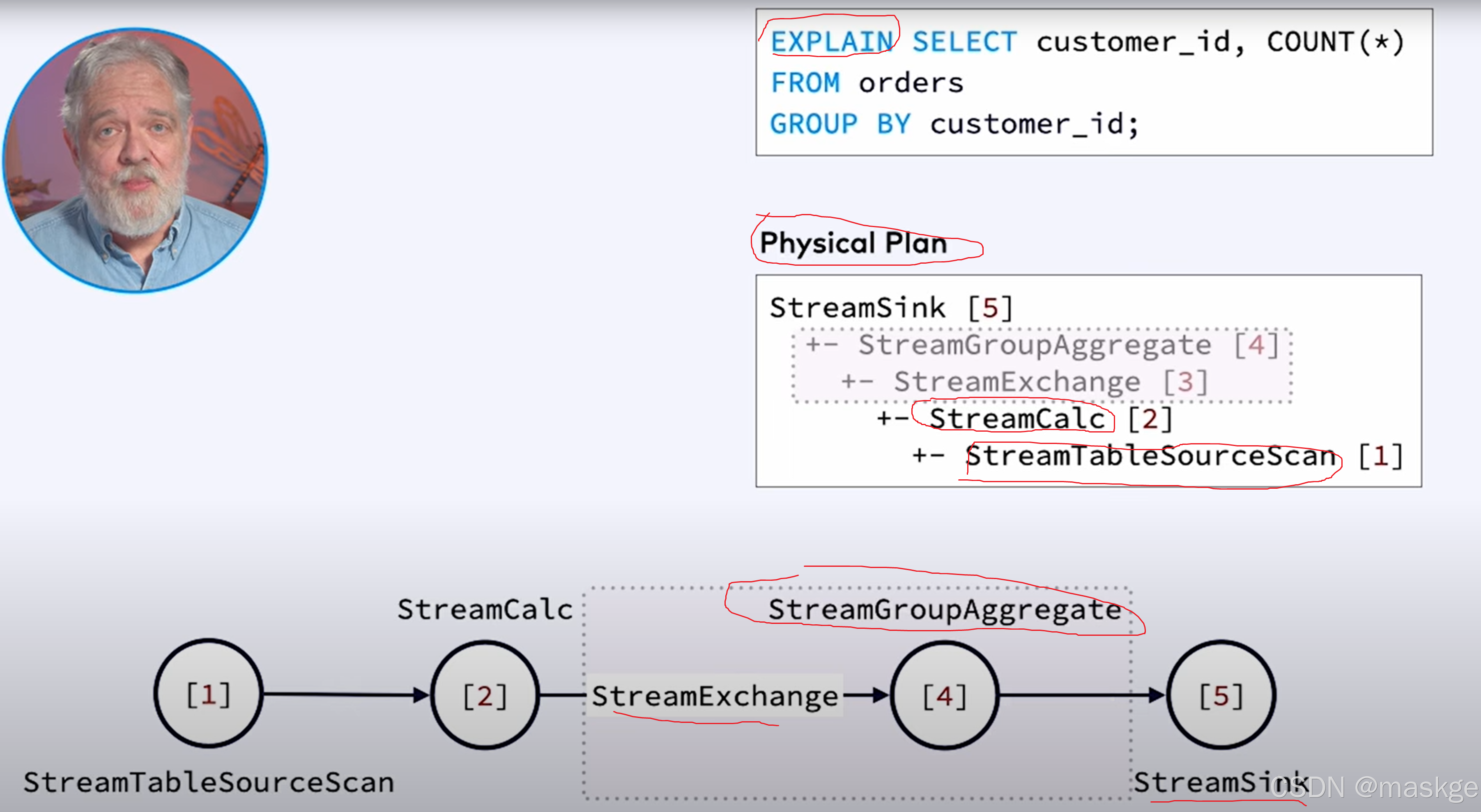
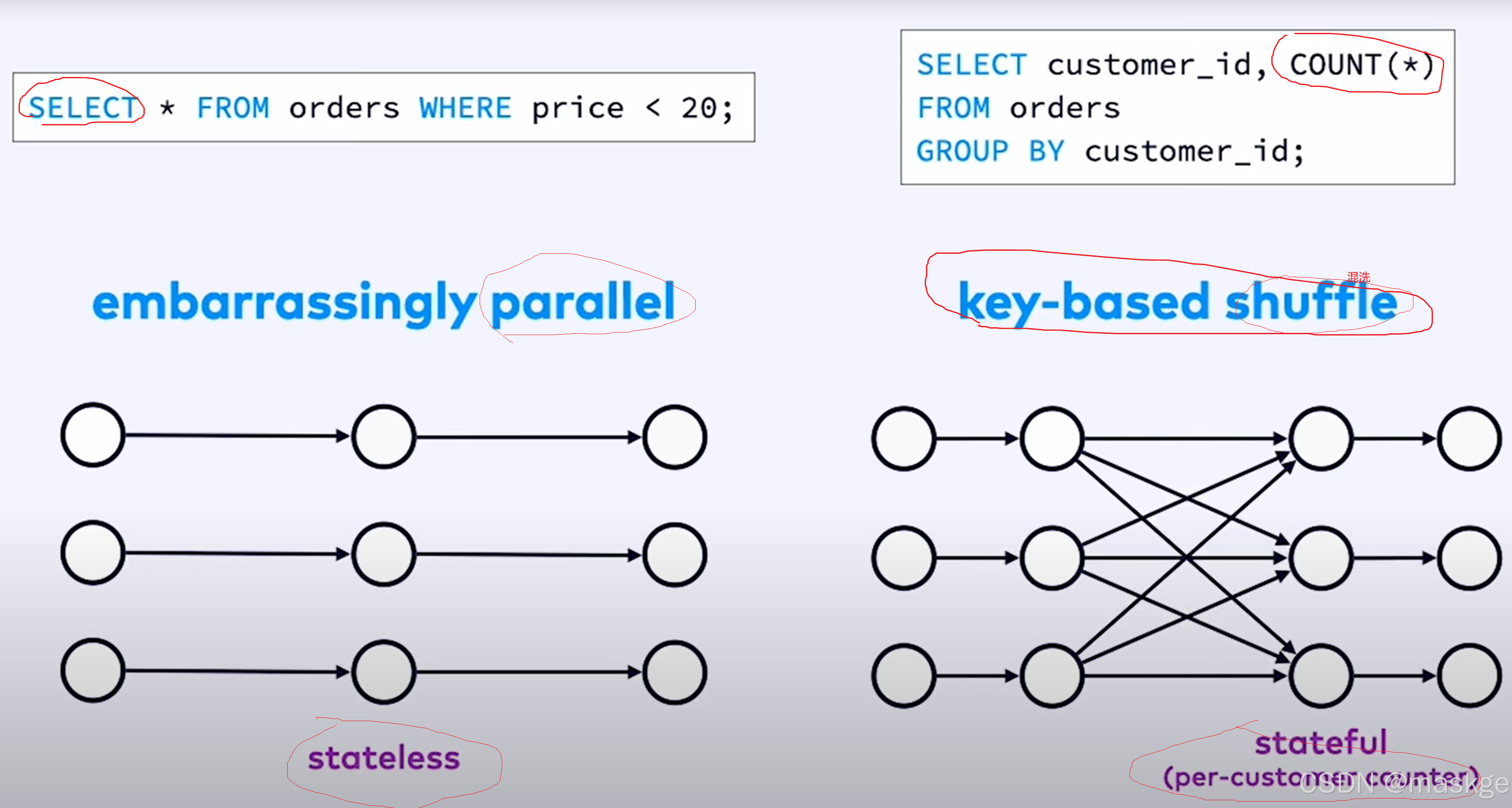
key-based shuffle:基于key抖动
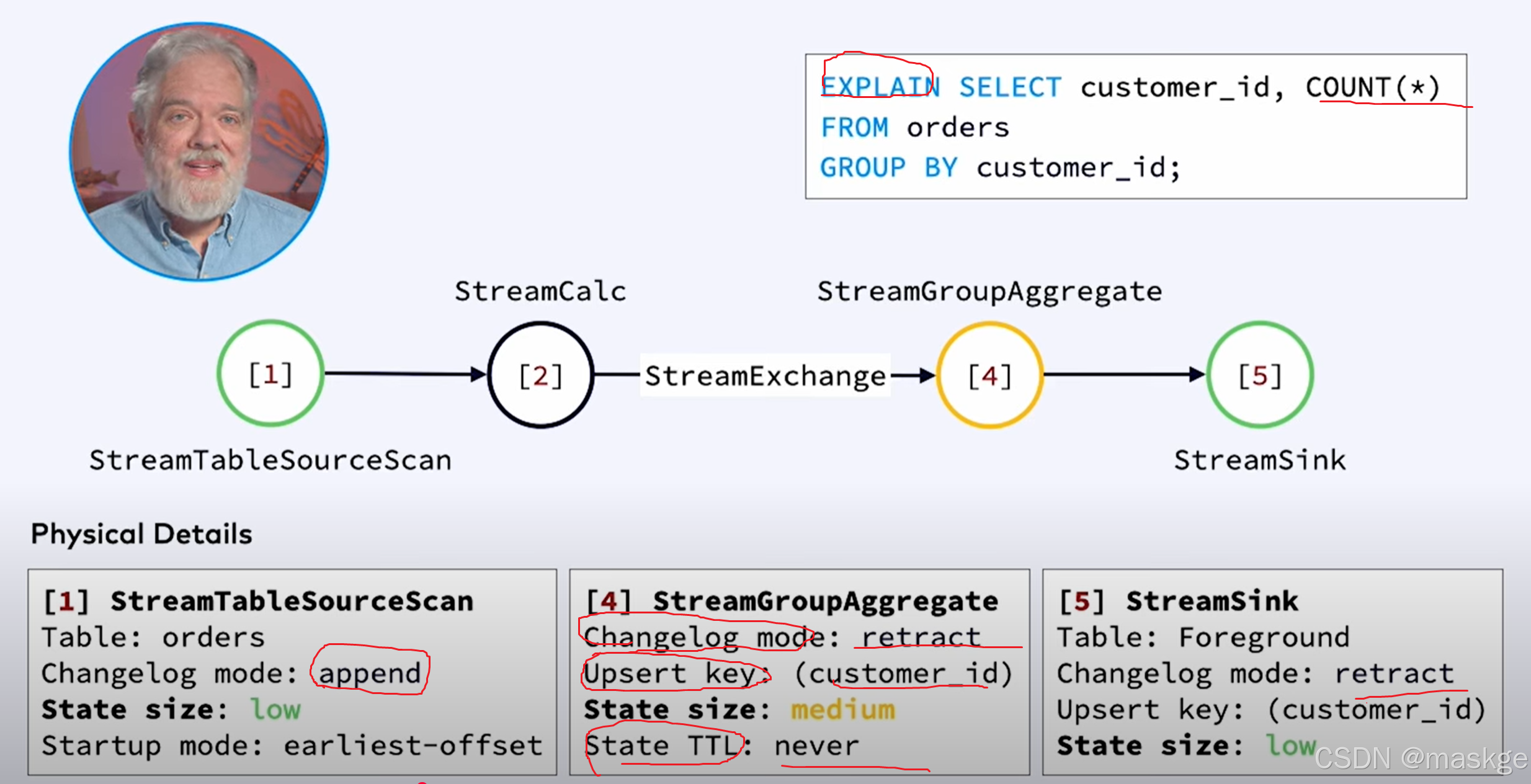
中等状态(medium state):
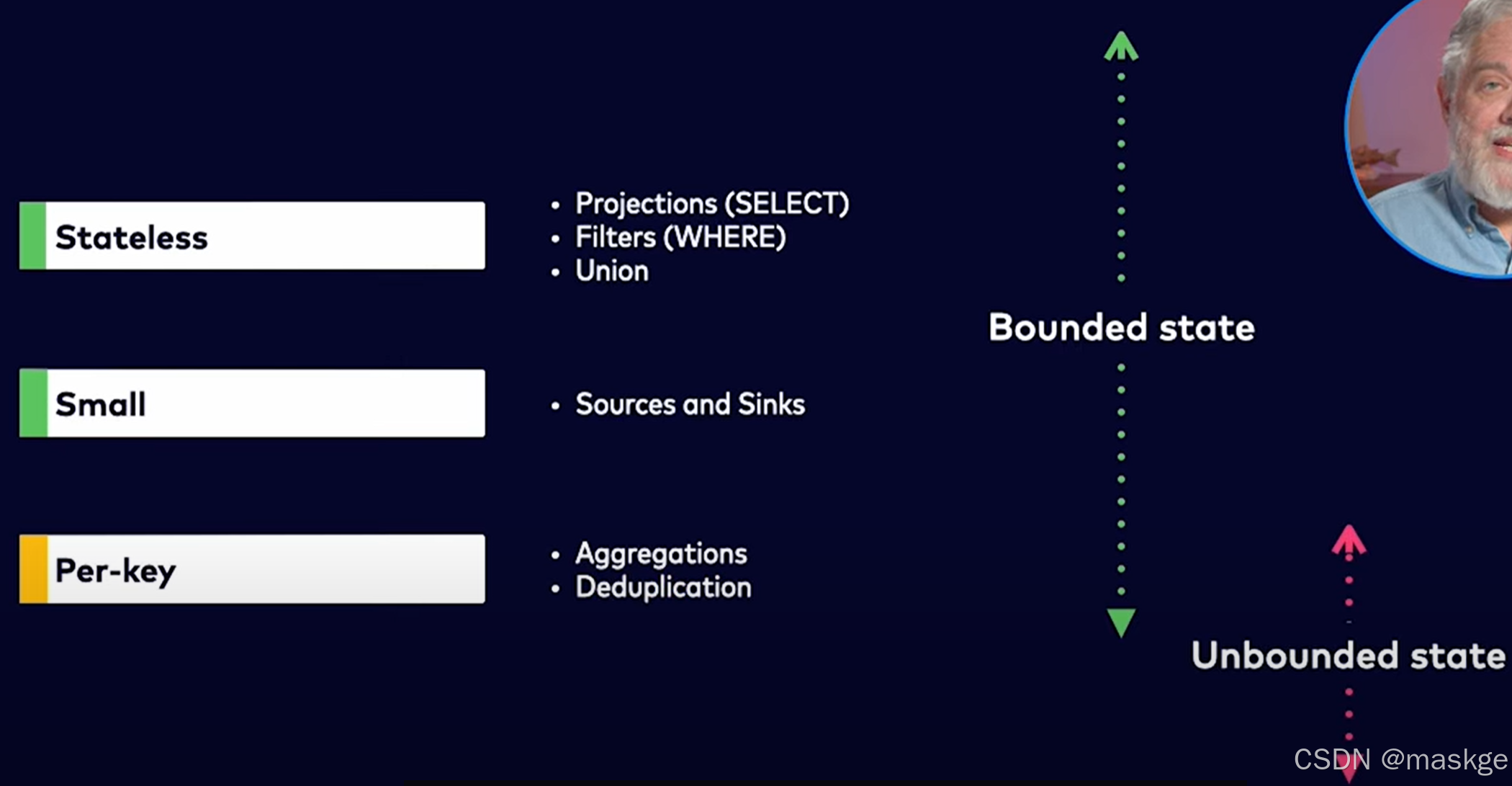
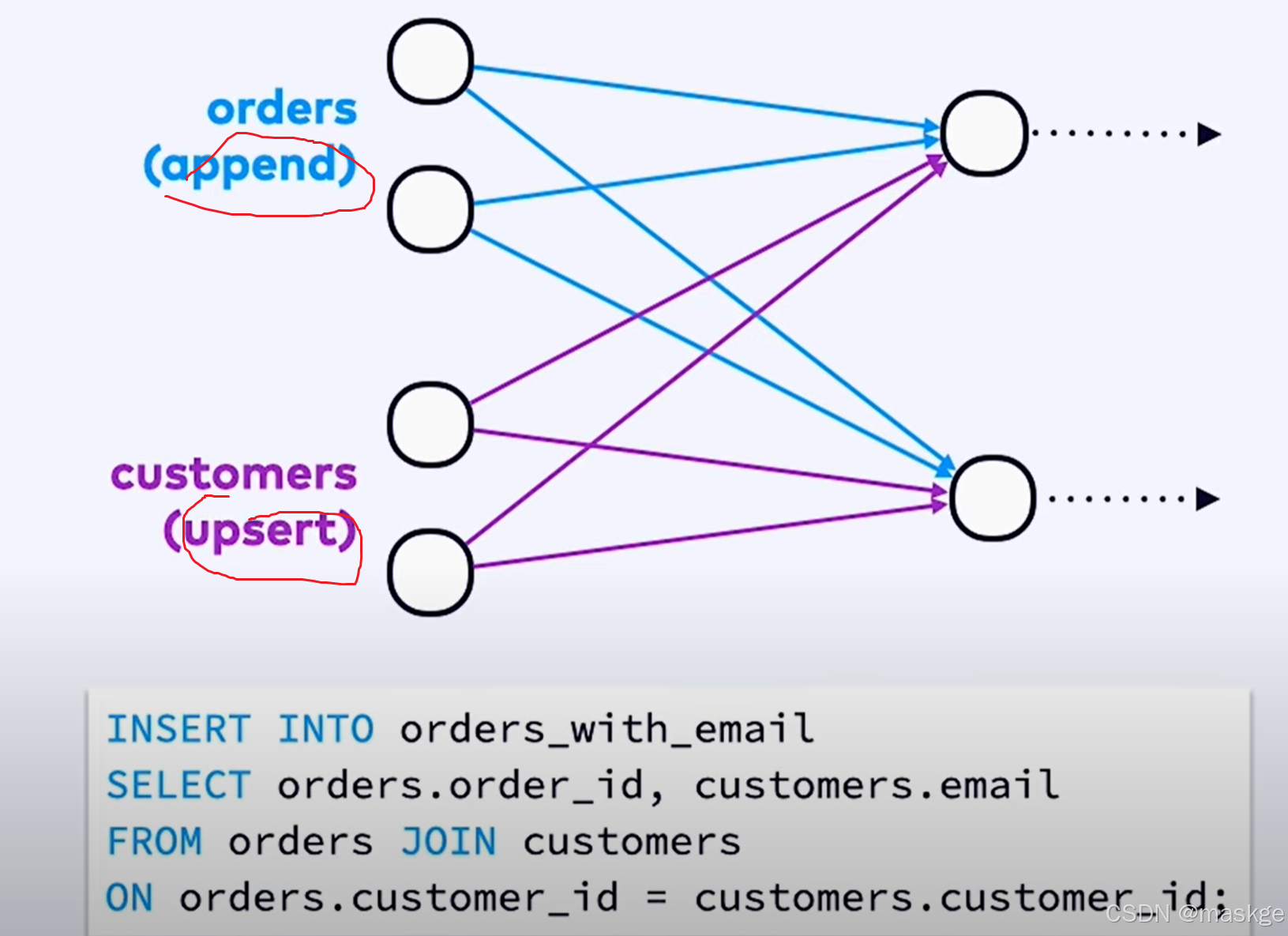
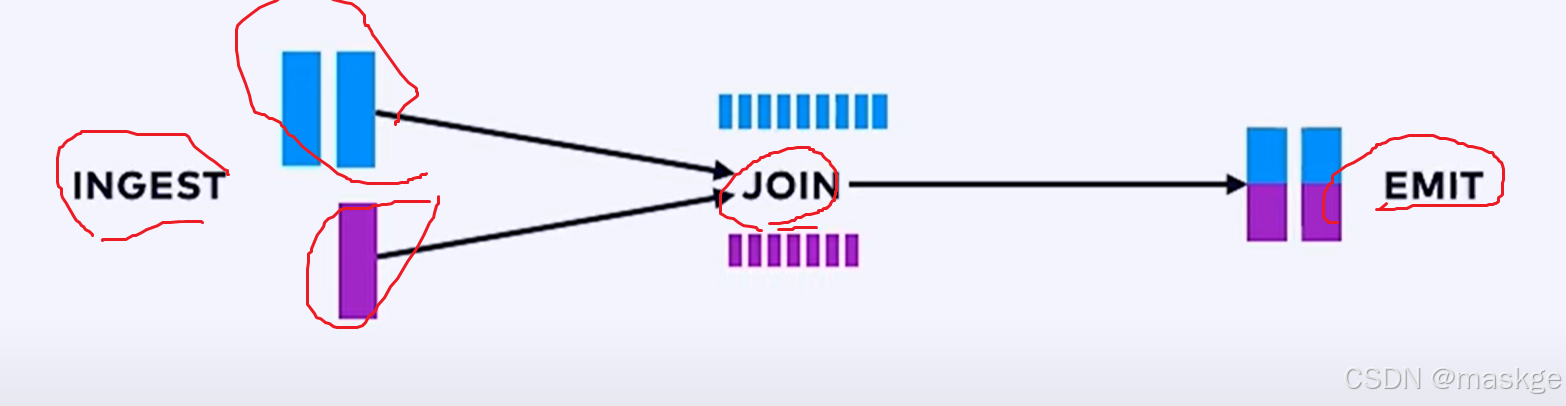
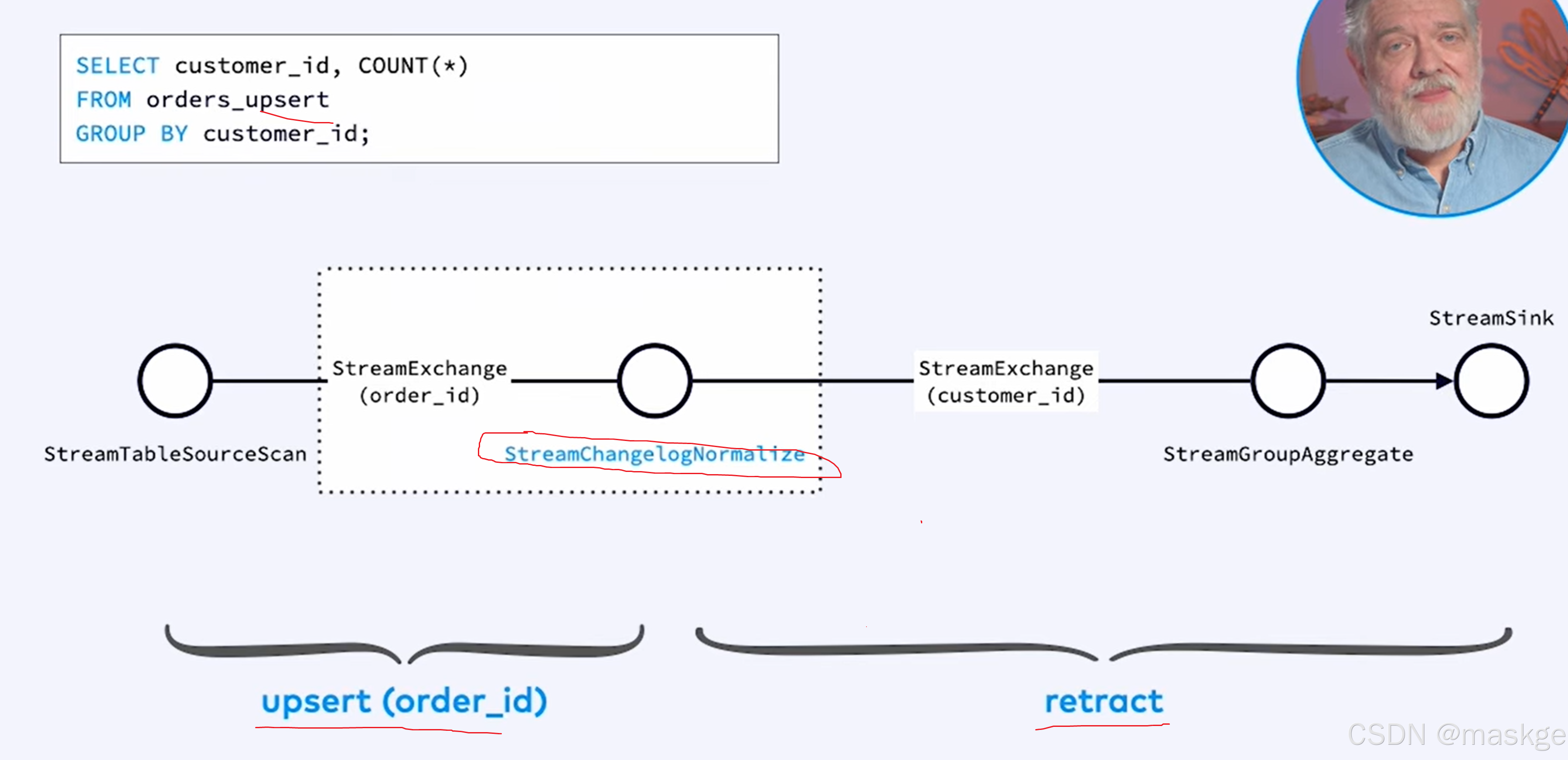
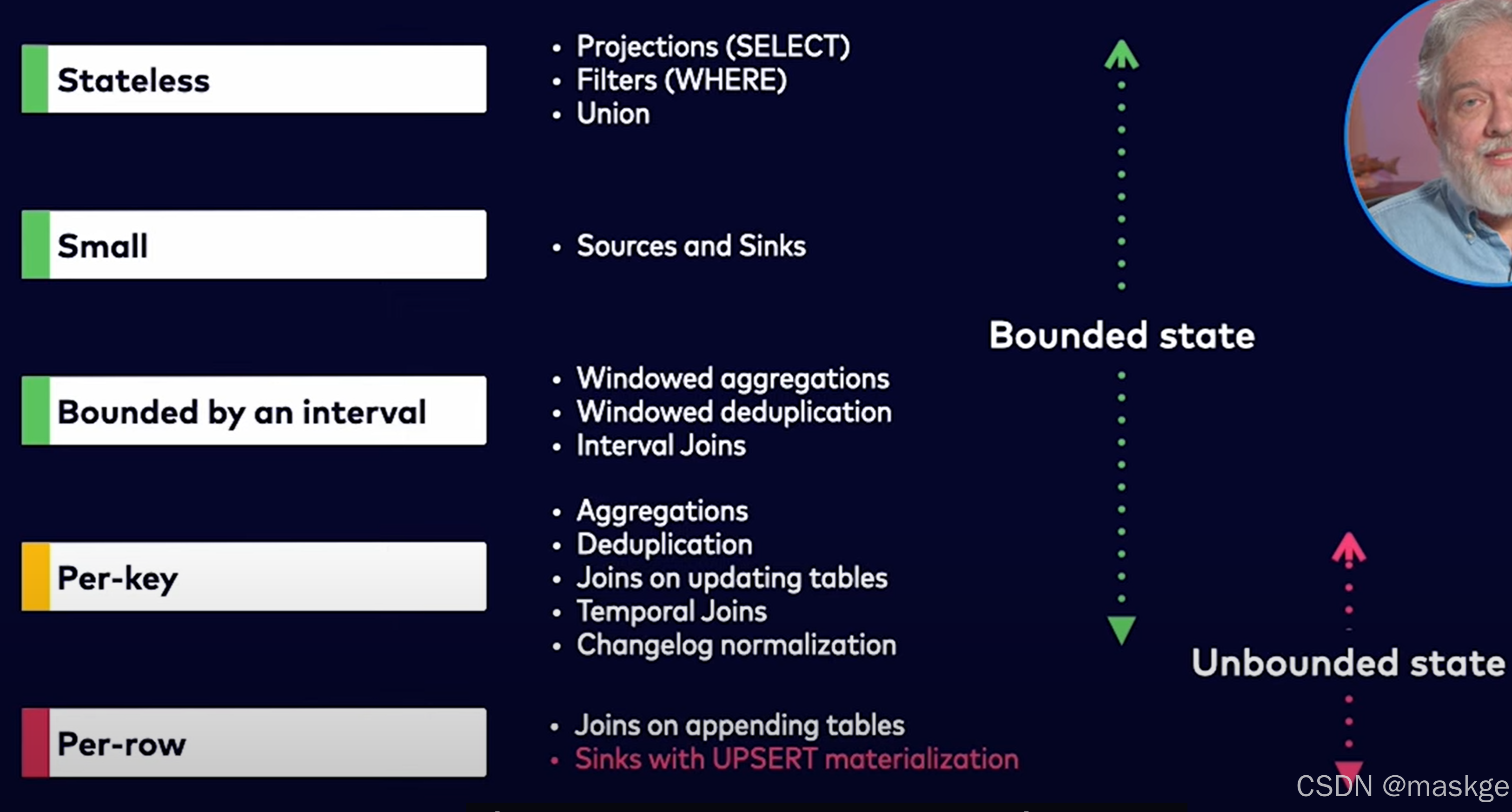
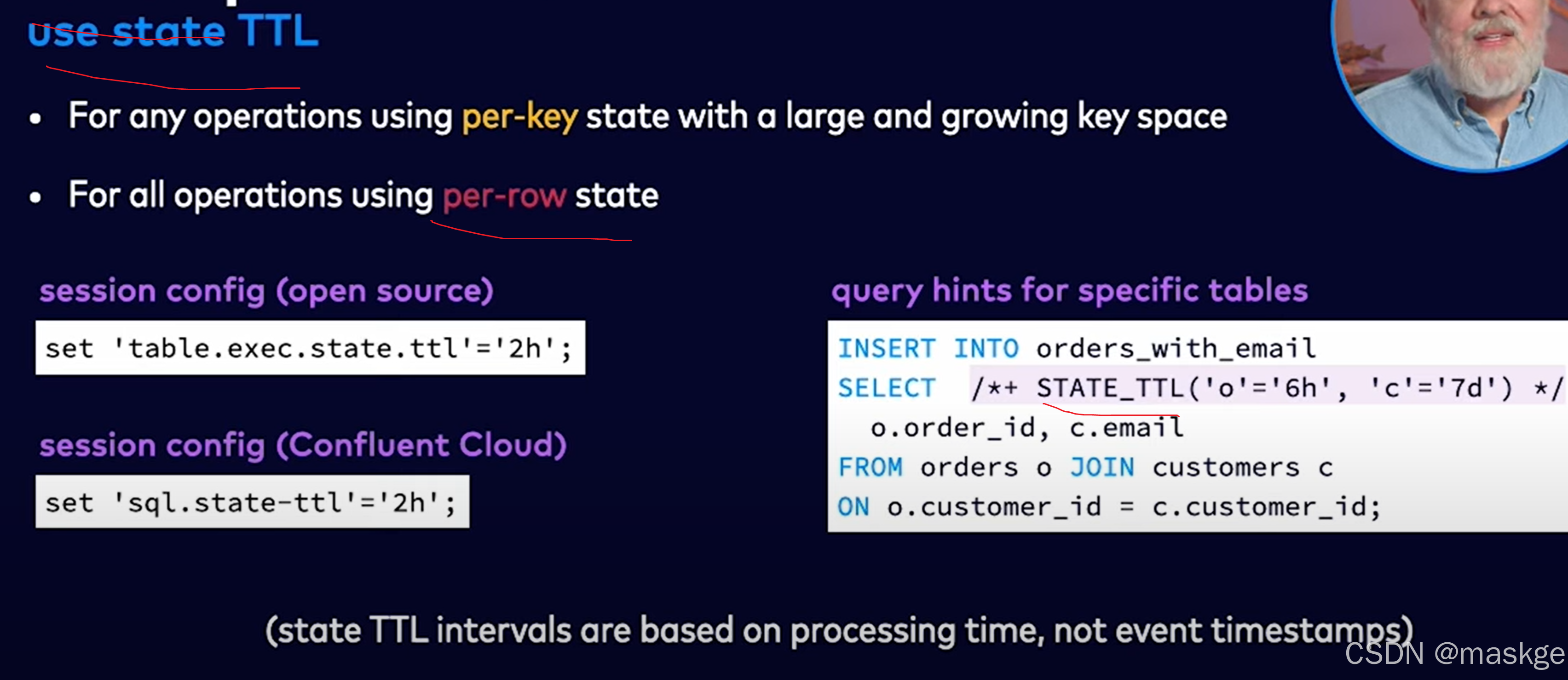
最佳实践



9.参考文档
-
flink资料:
build flink application in java
https://developer.confluent.io/courses/flink-java/overview/
flink 101
https://developer.confluent.io/courses/apache-flink/intro/
apache flink SQL
https://developer.confluent.io/courses/flink-sql/overview/flink-table-api-java
https://developer.confluent.io/courses/flink-table-api-java/overview/
flink cep 规则引擎
https://www.liaojiayi.com/deep-dive-cep/Flink CEP实战
https://www.bilibili.com/video/BV1i441127Q8/?spm_id_from=333.337.search-card.all.click&vd_source=51c993d69874e13d552c1b91dbf90aechttps://www.bilibili.com/video/BV16Z4y1v7j4/?spm_id_from=333.337.search-card.all.click&vd_source=51c993d69874e13d552c1b91dbf90aec
flink 官方文档
https://nightlies.apache.org/flink/flink-docs-master/zh/
https://nightlies.apache.org/flink/flink-docs-release-2.0/
https://www.confluent.io/resources/all/?language=english
Data Streaming Engineer:
https://developer.confluent.io/certification/flink quick start
https://developer.confluent.io/quickstart/flink-on-confluent-cloud/#3-create-flink-compute-poolflink手册 :https://developer.confluent.io/tutorials/
confluent 官方github仓库地址:https://github.com/confluentinc -
实时计算Flink版SQL实践:
https://www.bilibili.com/video/BV13V4y1L7Gz/?spm_id_from=333.337.search-card.all.click&vd_source=51c993d69874e13d552c1b91dbf90aec
-
Flink重分区算子解析 - StreamPartitioner
https://blog.csdn.net/Rango_lhl/article/details/126033155
-
流式应用flink开发框架:Apache StreamPark https://streampark.apache.org/zh-CN/
-
fink 官方B站 https://space.bilibili.com/33807709?spm_id_from=333.788.upinfo.detail.click
-
flink中文官网 https://flink-learning.org.cn
-
flink学习网:https://flink-learning.org.cn/article