Java-面试八股文-Java高级篇
Java高级篇
1、HashMap底层源码 难度系数:⭐⭐⭐

-
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
-
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(或者红黑树的边界值,默认为 8)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
-
补充:将链表转换成红黑树前会判断,即使阈值大于8,但是数组长度小于64,此时并不会将链表变为红黑树。而是选择进行数组扩容。
-
这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。具体可以参考 treeifyBin方法。
-
当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于8并且数组长度大于64时,链表转换为红黑树时,效率也变的更高效。
2、JVM内存分哪几个区,每个区的作用是什么 难度系数:⭐⭐
📌 JVM 内存区域划分(运行时数据区)
1. 程序计数器 (Program Counter Register)
-
作用:记录当前线程执行的字节码行号(相当于行号指示器)。
-
特点:
- 线程私有,每个线程都有自己的 PC 寄存器。
- 执行 Java 方法时,记录正在执行的字节码指令地址;
- 执行 Native 方法时,PC 值为空。
2. Java 虚拟机栈 (Java Virtual Machine Stack)
-
作用:描述 Java 方法执行的内存模型。
-
内容:
-
每个方法调用时都会创建一个 栈帧 (Stack Frame),栈帧中包含:
- 局部变量表(方法参数、局部变量)
- 操作数栈(执行过程中用来计算的中间结果)
- 动态链接(指向运行时常量池的方法引用)
- 方法出口信息
-
-
特点:
-
线程私有,生命周期与线程相同。
-
可能抛出异常:
StackOverflowError(栈深度超出限制)OutOfMemoryError(无法申请足够内存)
-
3. 本地方法栈 (Native Method Stack)
-
作用:为 JVM 调用 本地方法(C/C++实现) 提供支持。
-
特点:
- 和 Java 虚拟机栈类似,但服务的是 Native 方法。
- 可能抛出
StackOverflowError或OutOfMemoryError。
4. 堆 (Heap)
-
作用:存放对象实例和数组,是垃圾回收器(GC)的主要管理区域。
-
特点:
- 所有线程共享。
- JVM 启动时创建,大小可通过
-Xms和-Xmx参数调整。 - 可能抛出
OutOfMemoryError。
-
进一步划分:
- 新生代(Young Generation):Eden 区 + Survivor 区(S0/S1),用于存放新创建的对象。
- 老年代(Old Generation):存放生命周期较长的对象。
5. 方法区 (Method Area)
-
作用:存放 类的结构信息(类元数据),包括:
- 已加载的类信息(类名、父类名、修饰符等)
- 常量池(运行时常量池)
- 静态变量
- 即时编译器(JIT)编译后的代码
-
特点:
- 所有线程共享。
- JDK 7 及以前:方法区由 永久代 (PermGen) 实现;
- JDK 8 之后:方法区由 元空间 (Metaspace) 实现,存放在本地内存(不是 JVM 堆内)。
- 可能抛出
OutOfMemoryError: Metaspace。
📌 总结表格
| 区域 | 线程共享 | 作用 |
|---|---|---|
| 程序计数器 | ❌ 私有 | 记录字节码执行行号 |
| JVM 栈 | ❌ 私有 | 方法调用、局部变量、操作数栈 |
| 本地方法栈 | ❌ 私有 | 本地方法调用支持 |
| 堆 (Heap) | ✅ 共享 | 存放对象和数组,GC 管理的主要区域 |
| 方法区 (Metaspace) | ✅ 共享 | 存放类元数据、常量池、静态变量 |
3、Java中垃圾收集的方法有哪些 难度系数:⭐
1. 引用计数法 (Reference Counting)
- 原理:每个对象有一个引用计数器,当有地方引用它时 +1,引用消失时 -1,计数为 0 就可以回收。
- 优点:实现简单,回收及时。
- 缺点:无法解决循环引用问题(A 引用 B,B 引用 A,两者计数都不为 0)。
- 现状:Java 没有单独使用,但在一些其他语言或框架里会见到。
2. 标记-清除算法 (Mark-Sweep)
-
原理:
- 从 GC Roots 出发,标记所有可达对象;
- 清除未被标记的对象。
-
优点:实现简单。
-
缺点:会产生 内存碎片,影响分配效率。
3. 复制算法 (Copying)
- 原理:将内存分为两块,每次只使用其中一块。垃圾回收时,把存活的对象复制到另一块,清空当前块。
- 优点:实现简单,没有内存碎片。
- 缺点:需要 额外空间,内存利用率低。
- 应用:JVM 新生代(Eden + Survivor 区) 采用复制算法。
4. 标记-整理算法 (Mark-Compact)
-
原理:
- 标记存活对象;
- 将存活对象移动到一端,清理掉边界以外的内存。
-
优点:解决了内存碎片问题。
-
缺点:整理(对象移动)需要消耗性能。
-
应用:常用于 老年代(Old Generation)。
5. 分代收集算法 (Generational Collection)
-
原理:综合使用上面几种方法,根据对象的生命周期特点,将堆分为 新生代 和 老年代:
- 新生代:大量对象朝生夕死 → 采用 复制算法;
- 老年代:对象存活时间长 → 采用 标记-清除 或 标记-整理。
-
应用:JVM 垃圾收集的核心思想,大部分 GC 都基于分代收集。
📌 总结表格
| 方法/算法 | 特点 | 优缺点 | 应用场景 |
|---|---|---|---|
| 引用计数法 | 计数为 0 即回收 | 无法解决循环引用 | Java 不用 |
| 标记-清除 | 标记存活再清除 | 内存碎片 | 老年代(早期) |
| 复制算法 | 存活对象复制到另一块 | 空间浪费 | 新生代 |
| 标记-整理 | 存活对象移动到一端 | 性能开销大 | 老年代 |
| 分代收集 | 新生代用复制,老年代用标记-清除/整理 | 综合最优 | JVM 主流 |
4、如何判断一个对象是否存活(或者GC对象的判定方法) 难度系数:⭐
📌 判断对象是否存活的方法
1. 引用计数法 (Reference Counting)
- 原理:对象有一个引用计数器,每当有一个地方引用它时,计数 +1;引用失效时,计数 -1;当计数为 0,说明对象不可再被使用,可以回收。
- 优点:实现简单,回收及时。
- 缺点:无法解决 循环引用 问题(两个对象相互引用,即使没有外部引用,计数也不为 0)。
- 现状:Java 没采用,但在一些其他语言里会用到(比如 Python、Objective-C)。
2. 可达性分析算法 (Reachability Analysis)
-
原理:以 GC Roots 作为起点,向下搜索,能被 GC Roots 直接或间接引用到的对象是 存活对象,否则就是 可回收对象。
-
GC Roots 包括:
- 虚拟机栈中引用的对象(局部变量表)
- 方法区中类的静态变量
- 方法区中常量引用的对象
- 本地方法栈中 JNI(Native 方法)引用的对象
-
现状:Java、C# 等语言都采用 可达性分析 来判定对象是否存活。
✅ 面试简答版
Java 中对象是否存活主要通过 可达性分析算法 判断:从 GC Roots 出发,能被引用链直接或间接访问到的对象为存活对象,否则为可回收对象。早期的引用计数法因无法解决循环引用问题,Java 没采用。
5、什么情况下会产生StackOverflowError(栈溢出)和OutOfMemoryError(堆溢出)怎么排查 难度系数:⭐⭐
📌 1. StackOverflowError(栈溢出)
📖 产生原因
-
Java 虚拟机栈空间不足时抛出,常见于:
- 递归调用过深(方法无限递归,没有终止条件);
- 方法调用层级过深(普通调用层级太多);
- JVM 栈内存设置过小(
-Xss)。
🔧 排查思路
- 查看异常堆栈,定位是否有 无限递归 / 死循环调用。
- 使用
jstack <pid>查看线程调用栈,确认递归点。 - 调整 JVM 栈大小参数:
-Xss512k(默认 1M 左右)。
📌 2. OutOfMemoryError(堆溢出)
📖 产生原因
-
Java 堆内存不足,无法分配新对象时抛出。常见场景:
- 对象数量过多,长期存活,老年代内存不足;
- 内存泄漏(对象有引用,但已无用,GC 无法回收);
- JVM 堆内存设置过小(
-Xmx限制)。
🔎 举例
import java.util.ArrayList;
import java.util.List;public class HeapOOM {public static void main(String[] args) {List<byte[]> list = new ArrayList<>();while (true) {list.add(new byte[1024 * 1024]); // 不断申请1MB}}
}
执行后会报 java.lang.OutOfMemoryError: Java heap space。
🔧 排查思路
-
确认 OOM 类型:堆溢出、元空间溢出、直接内存溢出等(看异常信息)。
-
打开 堆转储文件(Heap Dump):
-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=./dump.hprof
-
使用 MAT / VisualVM / JProfiler 分析内存快照,查找:
- 哪些对象占用内存最多;
- 是否有集合类(List/Map)不断增长(可能是内存泄漏)。
-
调整 JVM 堆大小参数:
-Xms512m -Xmx1024m。
📌 总结表格
| 错误 | 内存区域 | 触发条件 | 常见场景 | 排查方式 |
|---|---|---|---|---|
| StackOverflowError | JVM 栈 | 栈帧过多,栈空间不足 | 无限递归、调用层级过深 | 查看异常堆栈、jstack、调大 -Xss |
| OutOfMemoryError | 堆 | 堆空间不足 | 内存泄漏、大对象分配、堆太小 | 堆转储分析(MAT/VisualVM)、调大 -Xmx |
✅ 面试答法建议:
StackOverflowError 出现在虚拟机栈,通常由无限递归或方法调用过深导致;OutOfMemoryError 出现在堆内存,通常由对象过多或内存泄漏导致。排查时可以通过线程栈 (
jstack) 或堆转储文件 (Heap Dump) 来定位问题,并结合 JVM 参数调整内存大小。
栈溢出、堆溢出案例演示
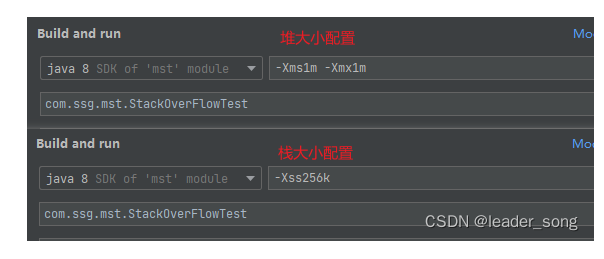
6、什么是线程池,线程池有哪些(创建) 难度系数:⭐
📌 1. 什么是线程池
线程池(ThreadPool)是一种 线程复用机制:
- 事先创建一定数量的线程放入池中;
- 当任务到来时,从池中取出空闲线程执行任务;
- 执行完任务后,线程不会销毁,而是返回池中继续使用。
✅ 好处
- 降低资源消耗:避免频繁创建和销毁线程。
- 提高响应速度:任务来了直接用已有线程。
- 统一管理:可控制并发线程数,避免系统过载。
📌 2. Java 中的线程池创建方式
Java 提供了 Executors 工具类 来快速创建几种常见线程池:
① FixedThreadPool(固定大小线程池)
ExecutorService pool = Executors.newFixedThreadPool(5);
- 特点:固定数量的线程,超出的任务会进入 无界队列。
- 适合:任务量已知、比较稳定的场景。
② CachedThreadPool(缓存线程池)
ExecutorService pool = Executors.newCachedThreadPool();
- 特点:线程数不固定,有任务就创建线程,空闲线程会被回收(默认 60 秒)。
- 适合:大量短期异步任务,并且负载较轻。
③ SingleThreadExecutor(单线程线程池)
ExecutorService pool = Executors.newSingleThreadExecutor();
- 特点:始终只有一个线程,保证任务按顺序执行。
- 适合:需要顺序执行的任务。
④ ScheduledThreadPool(定时/周期线程池)
ScheduledExecutorService pool = Executors.newScheduledThreadPool(3);
- 特点:支持定时任务和周期任务(类似 Timer,但更强大)。
- 适合:周期性执行任务,比如日志采集、心跳检测。
⚠️ 面试加分点
- 阿里巴巴开发手册推荐:不要直接用 Executors 创建线程池,因为它可能带来风险(如 FixedThreadPool 和 SingleThreadExecutor 使用无界队列,可能 OOM)。
- 推荐用:
ThreadPoolExecutor pool = new ThreadPoolExecutor(corePoolSize, // 核心线程数maximumPoolSize,// 最大线程数keepAliveTime, // 空闲线程存活时间unit, // 时间单位workQueue, // 任务队列handler // 拒绝策略
);
这样能明确控制线程池参数。
📌 总结表格
| 线程池类型 | 创建方式 | 特点 | 适用场景 |
|---|---|---|---|
| FixedThreadPool | Executors.newFixedThreadPool(n) | 固定线程数,任务排队 | 稳定任务量 |
| CachedThreadPool | Executors.newCachedThreadPool() | 线程数不固定,空闲回收 | 短期大量异步任务 |
| SingleThreadExecutor | Executors.newSingleThreadExecutor() | 单线程,顺序执行 | 顺序任务 |
| ScheduledThreadPool | Executors.newScheduledThreadPool(n) | 支持定时/周期任务 | 定时任务 |
✅ 面试简答:
线程池是用于线程复用的机制,避免频繁创建和销毁线程。Java 常见线程池有 FixedThreadPool、CachedThreadPool、SingleThreadExecutor 和 ScheduledThreadPool,实际开发中推荐使用 ThreadPoolExecutor 自定义参数。
7、为什么要使用线程池 难度系数:⭐
📌 为什么要使用线程池
-
降低资源消耗
- 线程的创建和销毁成本很高(涉及内核调度、内存分配),频繁创建/销毁会浪费性能。
- 线程池可以 复用已有线程,减少开销。
-
提高响应速度
- 任务来了不用重新创建线程,直接用池中线程执行,响应更快。
-
控制并发数量,防止系统过载
- 可以通过参数设置最大线程数、队列长度。
- 防止同时创建过多线程导致 CPU、内存被耗尽。
-
提供更强的管理功能
- 线程池提供了任务调度、定时执行、拒绝策略等机制。
- 可以方便地监控线程的运行情况。
-
解耦任务提交与执行
- 提交任务只管交给线程池,不需要关心线程的具体管理。
- 提高程序的可维护性。
✅ 面试简答版
使用线程池是为了 线程复用,减少频繁创建和销毁的开销;同时可以 提高响应速度,控制并发数量防止系统过载,并且提供了 统一的线程管理和监控,让任务调度更加灵活。
8、线程池底层工作原理 难度系数:⭐
📌 线程池底层工作原理(ThreadPoolExecutor)
-
提交任务
- 使用
execute()或submit()方法提交任务。
- 使用
-
判断线程池状态
- 如果线程池未关闭,进入下一步。
-
处理任务的执行顺序
- ① 核心线程数未满 → 创建新的核心线程执行任务。
- ② 核心线程已满,队列未满 → 将任务加入等待队列。
- ③ 队列已满,线程数 < 最大线程数 → 创建新的非核心线程执行任务。
- ④ 超过最大线程数,且队列也满了 → 执行 拒绝策略(抛异常、丢弃、调用者执行等)。
-
任务执行
- 线程从队列中取任务执行,执行完成后线程不会销毁,而是回到池中继续等待新任务(实现复用)。
-
线程回收
- 当线程空闲超过
keepAliveTime且线程数 > corePoolSize 时,多余线程会被销毁; - 核心线程默认不会销毁(除非
allowCoreThreadTimeOut(true))。
- 当线程空闲超过
📌 简化流程图
提交任务│┌─────────┼─────────┐│核心线程未满 │核心线程已满▼ ▼新建核心线程 → 任务队列是否满?│┌─────────────┼─────────────┐▼ ▼队列未满 队列已满→ 入队列 │▼线程数 < 最大线程数?│┌──────────┼──────────┐▼ ▼新建非核心线程执行 执行拒绝策略
✅ 面试简答版
线程池底层原理基于
ThreadPoolExecutor:任务提交后,先用核心线程执行;核心线程满了就进入任务队列;队列满了再创建非核心线程;如果线程数达到最大值且队列也满了,就触发拒绝策略。线程执行完任务不会销毁,而是复用以提升性能。
注意
在 Java 的 ThreadPoolExecutor 里:
✅ 线程池中的线程 共用一个任务队列
所有核心线程和非核心线程 都从同一个 BlockingQueue workQueue 中取任务。
队列相当于是任务缓冲区,线程池里空闲的线程会从队列里抢任务。
举例
-
提交任务流程:
- 前 2 个任务 → 直接由核心线程执行。
- 第 3~12 个任务 → 放入 同一个队列 里,等待核心线程执行。
- 第 13~15 个任务 → 因为队列满了,线程池会再开非核心线程来处理。
- 超过 15 个任务 → 启动拒绝策略。
ThreadPoolExecutor 的主要构造参数?
ThreadPoolExecutor 的核心构造方法:
public ThreadPoolExecutor(int corePoolSize, // 核心线程数int maximumPoolSize, // 最大线程数long keepAliveTime, // 空闲线程存活时间TimeUnit unit, // 存活时间的单位BlockingQueue<Runnable> workQueue, // 任务队列ThreadFactory threadFactory, // 线程工厂(可自定义线程名字)RejectedExecutionHandler handler // 拒绝策略
)
1. corePoolSize(核心线程数)
- 始终保留的线程数量,即使空闲也不会销毁(除非允许超时)。
- 提交任务时,优先使用核心线程。
2. maximumPoolSize(最大线程数)
- 线程池允许的最大线程数(= 核心线程 + 非核心线程)。
- 当队列满了,线程池才会创建非核心线程,最多扩展到
maximumPoolSize。
3. keepAliveTime
- 非核心线程的最大空闲存活时间,超过时间就会销毁。
- 默认核心线程不会超时,可通过
allowCoreThreadTimeOut(true)让核心线程也按这个规则回收。
4. unit
keepAliveTime的时间单位,比如TimeUnit.SECONDS。
5. workQueue
-
用来缓存等待执行任务的阻塞队列,常见几种:
ArrayBlockingQueue(有界数组队列)LinkedBlockingQueue(链表队列,默认无界,常用)SynchronousQueue(直接提交任务,不存储)
6. threadFactory
-
线程工厂,用来创建线程,可以自定义线程名方便排查问题。
-
例如:
Executors.defaultThreadFactory()
7. handler(拒绝策略)
- 当任务太多,超出最大线程数 + 队列容量时,就会触发拒绝策略:
📌 JDK 提供的 4 种拒绝策略
-
AbortPolicy(默认)
- 直接抛出
RejectedExecutionException,不执行任务。
- 直接抛出
-
CallerRunsPolicy
- 调用者线程自己执行这个任务,不抛异常。
-
DiscardPolicy
- 直接丢弃任务,不抛异常。
-
DiscardOldestPolicy
- 丢弃队列里最早的一个任务,然后再尝试提交新任务。
📌 怎么设定核心线程数和最大线程数
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, // corePoolSize 核心线程数5, // maximumPoolSize 最大线程数60, // keepAliveTime 空闲线程存活时间TimeUnit.SECONDS, // 时间单位new LinkedBlockingQueue<>(100), // 任务队列Executors.defaultThreadFactory(), // 线程工厂new ThreadPoolExecutor.AbortPolicy() // 拒绝策略
);
✅ 总结一句话:
- 核心线程数 = 常驻线程数
- 最大线程数 = 系统能承受的最大并发数
- 拒绝策略 = 队列和线程都满了后的兜底方案
10、常见线程安全的并发容器有哪些(⭐⭐)
CopyOnWriteArrayList、CopyOnWriteArraySet、ConcurrentHashMap
- CopyOnWriteArrayList、CopyOnWriteArraySet采用写时复制实现线程安全,写操作时复制一份新数组,写完再替换原数组,适合 读多写少 的场景。
- ConcurrentHashMap采用分段锁(JDK1.7)和CAS + synchronized(链表 + 红黑树)(JDK1.8)的方式实现线程安全。
11、synchronized底层实现是什么 lock底层是什么 有什么区别 难度系数:⭐⭐⭐
一、synchronized 的底层实现
synchronized 是 Java 中最基础的同步关键字,其底层依赖于 JVM 内置的监视器锁(Monitor Lock),也叫 内置锁(Intrinsic Lock) 或 对象监视器(Monitor)。
1. Monitor(监视器)机制
- 每个 Java 对象都可以关联一个 Monitor 对象(C++ 实现,在 HotSpot 虚拟机中为
ObjectMonitor)。 - 当线程进入
synchronized代码块时,会尝试获取该对象的 Monitor。 - Monitor 内部通过
_owner、_EntryList、_WaitSet等字段管理线程的进入、等待和唤醒。
2. 锁的升级机制(JDK 1.6 优化)
synchronized 并不是一开始就是重量级锁,而是根据竞争情况动态升级:
| 锁状态 | 说明 |
|---|---|
| 无锁状态 | 对象刚创建,未被任何线程锁定。 |
| 偏向锁(Biased Locking) | 第一个线程进入时,直接“偏向”该线程,避免重复加锁开销。适用于无竞争场景。 |
| 轻量级锁(Lightweight Locking) | 多个线程存在竞争但不激烈时,通过 CAS 操作尝试获取锁,避免阻塞。 |
| 重量级锁(Heavyweight Locking) | 当竞争激烈时,依赖操作系统互斥量(Mutex)实现,线程阻塞/唤醒开销大。 |
✅ 底层依赖:操作系统 Mutex(仅在重量级锁阶段)
✅ 实现位置:JVM 层(C++ 的ObjectMonitor)
二、Lock 接口的底层实现(以 ReentrantLock 为例)
Lock 是 java.util.concurrent.locks.Lock 接口,最常用实现是 ReentrantLock。
1. 核心组件:AbstractQueuedSynchronizer(AQS)
- AQS 是
Reentrant7Lock的核心,是一个同步器框架,基于FIFO 等待队列(CLH 队列变种)管理线程。 - 通过一个
volatile int state表示同步状态(如 0 表示无锁,1 表示已锁,可重入则 +1)。 - 使用
Unsafe类的 CAS 操作(如compareAndSwapInt)来原子更新state。
2. 加锁过程(以 lock() 为例):
- 尝试 CAS 修改
state,成功则获取锁。 - 失败则进入 AQS 队列,线程被
LockSupport.park()阻塞。 - 释放锁时,
state减 1,唤醒队列中下一个线程。
3. 公平锁 vs 非公平锁
- 可通过构造函数选择是否公平(公平锁按顺序获取,非公平锁允许“插队”)。
✅ 底层依赖:AQS + CAS +
volatile+LockSupport.park/unpark
✅ 实现位置:Java 层(部分依赖Unsafe,但逻辑在 Java 代码中)
三、synchronized 与 Lock 的主要区别
| 对比维度 | synchronized | Lock(如 ReentrantLock) |
|---|---|---|
| 实现层级 | JVM 层(C++) | Java 层(AQS) |
| 锁获取方式 | 自动获取/释放(进入/退出代码块) | 手动调用 lock() / unlock() |
| 可中断 | ❌ 不可中断(等待锁时无法响应中断) | ✅ 可中断(lockInterruptibly()) |
| 超时获取 | ❌ 不支持 | ✅ 支持(tryLock(timeout)) |
| 公平性控制 | ❌ 不支持(JDK 1.6+ 默认非公平) | ✅ 可选择公平或非公平锁 |
| 条件变量 | wait()/notify()/notifyAll() | Condition(支持多个等待队列) |
| 锁释放 | 自动(异常也会释放) | 必须手动释放(建议 try-finally) |
| 性能 | JDK 1.6 后优化,性能接近 Lock | 早期性能更好,现在差距不大 |
| 灵活性 | 低 | 高(可定制、可监控) |
四、总结
| 项目 | synchronized | Lock |
|---|---|---|
| 底层实现 | Monitor(C++ ObjectMonitor),锁升级机制 | AQS(Java 层队列 + CAS) |
| 优点 | 简单、安全、自动释放、JVM 优化好 | 灵活、支持中断、超时、公平锁 |
| 缺点 | 功能有限、无法中断、不支持超时 | 需手动释放,易出错(忘记 unlock) |
✅ 推荐使用建议:
- 优先使用
synchronized(简单、安全、JVM 优化充分)。- 在需要超时、中断、公平性、条件队列等高级功能时,使用
ReentrantLock。
附加:为什么 synchronized 在 JDK 1.6 后性能大幅提升?
因为引入了 锁升级机制(偏向锁 → 轻量级锁 → 重量级锁),避免了无竞争时的 Mutex 开销,使得在大多数场景下性能接近甚至优于 ReentrantLock。
12、了解ConcurrentHashMap吗 为什么性能比HashTable高,说下原理 难度系数:⭐⭐
ConcurrentHashMap vs HashTable 的性能差异及原理
1. HashTable 的性能瓶颈
- 全局锁机制:
HashTable的所有操作(如get、put)都依赖于一个全局锁(synchronized关键字),即使不同线程访问不同的键,也会互相阻塞。 - 低并发性:在多线程环境下,全局锁导致线程频繁竞争锁资源,严重影响性能。
- 读写冲突:即使读操作不需要修改数据,
get方法也需要加锁,限制了并发读的效率。
2. ConcurrentHashMap 的性能优化原理
ConcurrentHashMap 在 Java 1.7 和 1.8 的实现中有所不同,但核心目标是通过 细粒度锁 和 无锁化操作 提升并发性能。
Java 1.7 的分段锁机制
-
分段锁(Segment Locking):
- 将整个哈希表划分为多个 Segment(默认 16 个),每个 Segment 管理一部分桶(Bucket)。
- 每个 Segment 是一个独立的锁,线程只能竞争自己访问的 Segment 锁,不同 Segment 的操作可以并行执行。
- 锁粒度更小:锁的范围缩小到 Segment 级别,减少了锁竞争,提高了并发性。
-
无锁读操作:
get方法不加锁,直接通过volatile变量保证可见性(键值对的更新操作通过synchronized保证原子性)。- 读写分离:读操作无需等待写操作完成,显著提升了并发性能。
-
分段扩容:
- 扩容时,多个线程可以协作迁移不同 Segment 的数据,减少单线程扩容的阻塞时间。
Java 1.8 的进一步优化
-
移除分段锁,改用 CAS + synchronized:
- 使用 CAS(Compare and Swap) 原子操作和 synchronized 关键字,对单个桶(Bucket)加锁。
- 锁粒度更细:锁的范围缩小到桶级别,甚至仅对链表/红黑树的头节点加锁(例如
put操作时)。 - 无锁化操作:大部分读操作无需加锁,直接通过
volatile变量保证线程安全。
-
红黑树优化:
- 当链表长度超过阈值(默认 8)时,转换为红黑树,降低查找时间复杂度(从 O(n) 到 O(log n))。
- 适应高冲突场景:在哈希冲突较多时,红黑树能保持较高的查询效率。
-
弱一致性迭代器:
- 迭代器不阻塞其他线程的修改操作,且不会抛出
ConcurrentModificationException,避免了锁的开销。
- 迭代器不阻塞其他线程的修改操作,且不会抛出
3. 性能对比总结
| 特性 | HashTable | ConcurrentHashMap |
|---|---|---|
| 锁机制 | 全局锁(所有操作互斥) | 分段锁(Java 1.7)或桶级锁(Java 1.8) |
| 并发性 | 低(线程频繁竞争锁) | 高(锁粒度小,减少竞争) |
| 读操作 | 需要加锁 | 无锁(通过 volatile 保证可见性) |
| 写操作 | 需要全局锁 | 仅锁定相关 Segment 或桶(Java 1.7) 或通过 CAS/synchronized 实现(Java 1.8) |
| 扩容机制 | 单线程扩容 | 多线程协作扩容(Java 1.8) |
| 内存开销 | 较低(无分段) | 较高(Java 1.7 的分段设计) Java 1.8 更高效 |
| 适用场景 | 低并发环境 | 高并发环境 |
4. 核心优势
- 减少锁竞争:通过分段锁或桶级锁,仅锁定部分数据,而非整个哈希表。
- 无锁化读操作:读写分离,读操作无需等待写操作。
- CAS 优化:利用原子操作减少锁的开销。
- 红黑树优化:提升高冲突场景下的查询效率。
- 弱一致性迭代器:避免迭代时阻塞其他线程。
5. 为什么 ConcurrentHashMap 更高效?
- 锁粒度更小:
HashTable的全局锁限制了并发性,而ConcurrentHashMap的锁范围更小(Segment 或桶),降低了线程阻塞概率。 - 无锁化读操作:
get方法无需加锁,直接通过volatile变量保证线程安全。 - CAS 与同步结合:通过原子操作减少锁的使用,提高吞吐量。
- 适应高并发场景:分段扩容和红黑树结构使其在高并发、高冲突场景下性能更优。
13、ConcurrentHashMap 的底层原理及 JDK 1.7 与 1.8 的对比
一、ConcurrentHashMap 的核心设计目标
- 线程安全:通过细粒度锁机制和 CAS 操作保证并发写入的安全性。
- 高并发性能:减少锁竞争,允许多线程同时操作不同数据部分。
- 高效扩容:支持多线程协作扩容,避免单线程阻塞。
二、JDK 1.7 的实现原理
1. 数据结构
- 分段锁(Segment):
ConcurrentHashMap内部维护一个Segment[]数组,每个Segment是一个独立的哈希表(类似HashMap),并继承自ReentrantLock,用于加锁。- 默认
Segment数量为 16(可通过concurrencyLevel自定义)。
- HashEntry 链表:
- 每个
Segment包含一个HashEntry[]数组,数组中的每个元素是一个链表节点(HashEntry),存储键值对。 HashEntry的value和next字段用volatile修饰,确保内存可见性。
- 每个
2. 锁机制
- 分段锁(Segment Locking):
- 每个
Segment独立加锁,线程操作时仅锁定对应的Segment,不同Segment之间互不干扰。 - 锁粒度:
Segment级别(约减少 16 倍锁竞争)。
- 每个
- 读操作无锁:
get方法无需加锁,直接读取volatile字段保证可见性。
3. 扩容机制
- Segment 内部扩容:
- 每个
Segment独立扩容,不影响其他Segment。 - 扩容时,
Segment的HashEntry[]数组会被重新分配,迁移数据。
- 每个
- 局限性:
Segment数组大小固定(初始化后不可扩容),导致并发度受限。
4. 性能特点
- 优点:
- 分段锁减少锁竞争,适合高并发场景。
- 读操作无锁,提升读性能。
- 缺点:
Segment数组不可扩容,限制了并发度上限。- 扩容时单线程迁移数据,效率较低。
三、JDK 1.8 的实现原理
1. 数据结构
- Node 数组 + 链表/红黑树:
- 底层结构为
Node<K,V>[] table,每个Node存储键值对(hash、key、val、next)。 - 当链表长度超过阈值(默认 8)时,链表转换为红黑树,提升查询效率。
TreeNode继承自Node,支持红黑树操作。
- 底层结构为
2. 锁机制
- CAS + synchronized:
- 无冲突场景:使用 CAS(Compare-And-Swap) 原子操作插入空桶(无需加锁)。
- 冲突场景:对链表头节点或红黑树根节点加
synchronized锁(锁粒度降至单个节点)。 - 锁粒度:节点级别(比 1.7 的
Segment更细)。
- 读操作无锁:
get方法直接读取volatile字段,无需加锁。
3. 扩容机制
- 多线程协作扩容:
- 扩容时,多个线程可以协作迁移数据,通过
ForwardingNode标记迁移中的桶。 - 扩容过程由
transfer()方法实现,支持多线程并行迁移。
- 扩容时,多个线程可以协作迁移数据,通过
- 动态扩容:
table数组大小可动态调整,支持更高并发度。
4. 性能特点
- 优点:
- 锁粒度更细:节点级别锁减少竞争,提升并发性能。
- 无锁化操作:CAS 和
volatile减少锁的使用,提高吞吐量。 - 红黑树优化:高冲突场景下查询效率更高。
- 多线程扩容:迁移数据效率显著提升。
- 缺点:
- 实现复杂度较高,依赖
Unsafe类和 CAS 操作。
- 实现复杂度较高,依赖
四、JDK 1.7 与 1.8 的对比总结
| 特性 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | Segment[] + HashEntry[](链表) | Node[](链表/红黑树) |
| 锁机制 | 分段锁(Segment 级别) | CAS + synchronized(节点级别) |
| 锁粒度 | Segment(约 16 倍锁竞争减少) | 节点级别(更细) |
| 读操作 | 无锁(volatile 保证可见性) | 无锁(volatile 保证可见性) |
| 扩容机制 | 单线程扩容,Segment 内部扩容 | 多线程协作扩容,table 动态扩容 |
| 红黑树优化 | ❌ 无 | ✅ 有(链表长度 > 8 时转换) |
| 并发度 | 固定(由 concurrencyLevel 决定) | 动态(table 大小可扩展) |
| 性能 | 高并发场景表现良好 | 性能更优(实测比 1.7 快 30%+) |
| 适用场景 | 低到中等并发 | 高并发、高冲突场景 |
五、核心原理总结
-
JDK 1.7 的分段锁机制:
- 通过
Segment划分数据范围,减少锁竞争。 - 适合并发度较低的场景(默认 16 个
Segment)。
- 通过
-
JDK 1.8 的 CAS + synchronized 机制:
- 无冲突场景:使用 CAS 插入空桶(无锁)。
- 冲突场景:对链表/红黑树头节点加
synchronized锁(锁粒度更细)。 - 红黑树优化:高冲突场景下提升查询效率。
- 多线程扩容:支持多线程协作迁移数据,效率更高。
-
性能优化方向:
- 减少锁竞争:从
Segment级别到节点级别。 - 无锁化操作:CAS 和
volatile替代部分锁。 - 动态扩容:适应高并发场景的数据增长需求。
- 减少锁竞争:从
六、实际应用建议
- JDK 1.7:适用于并发度较低且数据量较小的场景(如缓存系统)。
- JDK 1.8:推荐用于高并发、高冲突的场景(如分布式缓存、高频交易系统)。
- 通用原则:
- 尽量避免
put操作时发生哈希冲突(合理设置负载因子和初始容量)。 - 使用
computeIfAbsent、merge等原子方法替代手动加锁逻辑。
- 尽量避免
14、了解volatile关键字不 难度系数:⭐
- volatile是Java提供的轻量级的同步机制,保证了共享变量的可见性,被volatile关键字修饰的变量,如果值发生了变化,其他线程立刻可见,避免出现脏读现象。
- volatile禁止了指令重排,可以保证程序执行的有序性,但是由于禁止了指令重排,所以JVM相关的优化没了,效率会偏弱。
15、synchronized和volatile有什么区别 难度系数:⭐⭐
- volatile本质是告诉JVM当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
- volatile仅能用在变量级别,而synchronized可以使用在变量、方法、类级别。
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
- volatile不会造成线程阻塞,synchronized可能会造成线程阻塞。
- volatile标记的变量不会被编译器优化,synchronized标记的变量可以被编译器优化。
** 核心区别总结**
| 特性 | synchronized | volatile |
|---|---|---|
| 可见性 | ✅ 保证(通过锁的释放/获取) | ✅ 保证(直接读写主内存) |
| 原子性 | ✅ 保证(互斥锁机制) | ❌ 不保证(仅适用于单次读写操作) |
| 有序性 | ✅ 保证(通过锁的 acquire/release) | ✅ 保证(通过内存屏障禁止指令重排序) |
| 锁机制 | ✅ 基于对象锁(Monitor) | ❌ 无锁机制(轻量级同步) |
| 性能开销 | ⭐⭐⭐(涉及锁竞争和上下文切换) | ⭐(无锁竞争,仅内存屏障) |
| 适用场景 | 复杂同步(如多线程共享资源的互斥访问) | 简单同步(如状态标志、单次读写操作) |
17、Java类加载过程 难度系数:⭐
Java 类加载过程
当一个类第一次被使用时,Java 虚拟机(JVM)会通过 类加载机制 把它加载到内存中,主要分为以下几个阶段:
-
加载(Loading)
- 通过 类加载器(ClassLoader) 将字节码文件(.class)读入内存。
- 生成该类的
Class对象。 - 负责找到并加载类的二进制数据。
-
链接(Linking)
分为三个小阶段:-
验证(Verification):检查字节码是否符合 JVM 规范,保证安全性(例如栈帧结构、类型检查等)。
-
准备(Preparation):为类变量(static 变量)分配内存,并设置默认初始值。
注意:这里不会执行静态代码块,也不会赋初始值,只是分配内存并给默认值。
-
解析(Resolution):把常量池中的符号引用替换为直接引用(比如类、方法、字段的实际内存地址)。
-
-
初始化(Initialization)
-
执行类构造器
<clinit>()方法:- 静态变量赋值
- 静态代码块执行
-
这一步保证了类的主动使用时才会真正触发(懒加载特性)。
-
总结口诀
加载 → 验证 → 准备 → 解析 → 初始化
(一般面试时说 加载、链接、初始化 三大步即可,链接再细分三步)。
18、什么是类加载器,类加载器有哪些 难度系数:⭐
什么是类加载器
- 类加载器(ClassLoader) 是 Java 虚拟机(JVM)的一部分,负责 把类的字节码文件(.class)加载到内存 并生成
Class对象。 - 由于 Java 可以从不同来源(文件系统、网络、JAR 包等)加载类,所以类加载器的存在让 JVM 的类加载机制更加灵活。
类加载器的分类
Java 中主要有以下几类加载器(从上到下是父子层级关系):
-
启动类加载器(Bootstrap ClassLoader)
- 由 C/C++ 实现,属于 JVM 的一部分(不是 Java 写的)。
- 负责加载 JDK 核心类库,如
rt.jar中的类(java.lang.*、java.util.*等)。 - 不能被 Java 程序直接获取。
-
扩展类加载器(Extension ClassLoader / Platform ClassLoader)
- 加载
jre/lib/ext/或由系统变量java.ext.dirs指定路径中的类。 - 例如 Java 扩展功能包。
- 加载
-
应用类加载器(Application ClassLoader / System ClassLoader)
- 负责加载 classpath 路径下的类(开发者写的代码、第三方库)。
- 最常见,也就是我们平时用的加载器。
-
自定义类加载器(Custom ClassLoader)
-
通过继承
ClassLoader实现,通常用于:- 加密/解密字节码
- 从网络动态加载类
- 实现热部署
-
类加载器的工作机制
-
双亲委派模型(Parent Delegation Model):
当一个类加载器要加载某个类时,- 先把请求委托给父类加载器;
- 如果父类加载器找不到,再由自己去加载。
-
作用:
- 避免重复加载
- 保证核心类(如
java.lang.String)不会被篡改
面试简答版
类加载器就是负责把类加载到内存的组件,常见的有 启动类加载器、扩展类加载器、应用类加载器,还可以通过继承 ClassLoader 来实现自定义类加载器,它们遵循 双亲委派模型。
19、简述java内存分配与回收策略以及Minor GC和Major GC(full GC) 难度系数:⭐⭐
Java 内存分配与回收策略
Java 内存由 堆(Heap) 为主,主要区域划分为:
-
新生代(Young Generation)
- 包括 Eden 区 和 两个 Survivor 区(S0、S1)。
- 大多数对象在这里创建。
- 特点:对象生命周期短,容易被回收。
-
老年代(Old Generation)
- 存放生命周期较长的对象(如单例、缓存对象)。
- 从新生代晋升过来的对象也会放在这里。
-
永久代(PermGen,Java 8 之前)/ 元空间(Metaspace,Java 8 之后)
- 存放类的元数据(方法、字段、常量池等)。
- JDK8 之后移到本地内存(Metaspace)。
内存分配策略
- 新对象优先分配在新生代的 Eden 区。
- 大对象直接进入老年代(如大数组)。
- 长期存活的对象进入老年代(经历多次 GC 后晋升)。
- 动态年龄判定:如果 Survivor 区中同年龄对象大小总和 > 一半空间,则 >= 该年龄的对象进入老年代。
GC 分类
-
Minor GC(Young GC)
-
发生在新生代。
-
触发条件:Eden 区满时触发。
-
特点:
- 回收速度快
- 频繁发生
- 会引起短暂停顿(STW, Stop The World)。
-
-
Major GC(Old GC)
-
发生在老年代。
-
触发条件:老年代空间不足。
-
特点:
- 回收速度比 Minor GC 慢
- 停顿时间长
- 不一定伴随 Minor GC。
-
-
Full GC
-
回收范围:新生代 + 老年代 + 元空间。
-
触发条件:
- System.gc() 显式调用
- 老年代空间不足
- 元空间不足
- Minor GC 之后晋升失败
-
特点:耗时最长,影响性能最大。
-
面试总结版(简答)
- Java 内存主要分为 新生代、老年代、元空间。
- 内存分配策略:新对象在新生代,长期存活或大对象进入老年代。
- Minor GC:新生代回收,频繁,速度快。
- Major GC:老年代回收,速度慢,停顿长。
- Full GC:整个堆和方法区回收,最消耗性能。
20、如何查看java死锁 难度系数:⭐
如何查看 Java 死锁
在 Java 中,当两个或多个线程相互等待对方持有的资源时,就可能出现 死锁。
常见的排查方式有:
使用 jps + jstack(最常用)
-
先用
jps -l查看运行中的 Java 进程 ID:jps -l -
使用
jstack <pid>打印线程堆栈信息:jstack 12345 -
在输出中查找 “Found one Java-level deadlock” 关键字,如果存在,表示发现死锁,并会展示涉及的线程和资源。
总结(面试简答版)
Java 死锁最常用的排查方式是:
- 用
jps找到进程号, - 再用
jstack打印线程栈, - 查找是否有 Found one Java-level deadlock 提示。
也可以用图形化工具 JConsole、VisualVM,或者通过ThreadMXBean代码检测。
21、Java 死锁如何避免
死锁产生的四个必要条件(操作系统理论):
- 互斥条件:资源一次只能被一个线程占用。
- 请求与保持条件:线程已经持有资源,还要申请新的资源。
- 不可剥夺条件:已获得的资源不能被强制剥夺。
- 循环等待条件:线程之间形成环路等待资源。
只要破坏其中一个条件,就能避免死锁。
常见避免策略
-
按顺序申请资源
- 保证多个线程获取锁的顺序一致,避免循环等待。
synchronized (lock1) {synchronized (lock2) {// 安全操作} }要求所有线程都按照 lock1 → lock2 的顺序获取锁。
-
尽量缩小锁的范围(减少锁粒度)
- 减少持有锁的时间,降低死锁概率。
-
避免嵌套锁
- 能不用多重
synchronized嵌套就不要用。
- 能不用多重
-
使用
tryLock设置超时时间(推荐,适合 ReentrantLock)- 如果拿不到锁,等待一段时间后放弃,避免永久等待。
ReentrantLock lock1 = new ReentrantLock(); ReentrantLock lock2 = new ReentrantLock();if (lock1.tryLock(1, TimeUnit.SECONDS)) {try {if (lock2.tryLock(1, TimeUnit.SECONDS)) {try {// 业务逻辑} finally {lock2.unlock();}}} finally {lock1.unlock();} } -
使用更高级的并发工具
- 如
java.util.concurrent提供的 线程池、并发集合、信号量 (Semaphore),减少手写锁的场景。
- 如
面试简答版
避免死锁的方法有:
- 保证获取锁的顺序一致;
- 减小锁粒度,避免嵌套锁;
- 使用
tryLock设置超时机制; - 使用 JUC 提供的并发工具代替低级锁。