YOLOv7:重新定义实时目标检测的技术突破

前言:在智能视觉时代,目标检测已成为深度学习领域最具实用价值的核心技术之一。而 YOLO以其端到端的高效结构与卓越的实时性能,成为工程落地与学术研究中的明星算法。
本专栏 《YOLO目标检测最强通关秘籍》 从算法原理、模型设计到实验复现与工程部署,系统梳理 YOLO 系列的技术演进与关键创新,让复杂的模型调优和实战部署变得更系统。
一、YOLOv7的革命性突破
在计算机视觉的演进历程中,YOLOv7的出现标志着实时目标检测领域的一个重要转折点。这不仅仅是一次简单的版本迭代,而是对整个目标检测范式的重新思考和定义。YOLOv7以其卓越的性能表现,在速度与精度之间找到了前所未有的平衡点,成为了业界瞩目的焦点。
与传统的目标检测器相比,YOLOv7的优势不仅体现在数值上的提升,更重要的是其设计理念的根本性转变。传统方法往往专注于网络架构的优化,试图通过更复杂的结构来提升性能,而YOLOv7则将目光转向了训练过程本身的优化,这种思路上的转变为整个领域带来了新的启发。
1. 性能基准的全面超越
实时目标检测随着 YOLOv7 的发布而取得进步,这是 YOLO 模型生命周期中的最新迭代。与之前版本(如 YOLOv5)相比,YOLOv7 推理速度更快、精度更高,将目标检测领域的最新技术推向了新的高度。
YOLOv7在多个关键指标上实现了显著突破。在GPU V100上,它达到了56.8%的AP值,这一成绩在所有能够维持30 FPS以上的实时检测器中位居榜首。更为令人印象深刻的是,它能够在5-160 FPS的宽泛范围内保持稳定的高精度表现,这种灵活性为不同应用场景提供了更多选择空间。
# YOLOv7推理性能对比示例
class YOLOv7Performance:def __init__(self):self.fps_range = (5, 160)self.ap_score = 56.8 # 在V100上的表现self.inference_speed = 30 # FPS阈值def compare_with_predecessors(self):# 与前代模型的性能对比improvements = {'speed': 127, # 相比YOLOv5的FPS提升'accuracy': 10.7, # AP提升百分比'parameters_reduction': 41 # 参数减少百分比}return improvements
这段代码虽然简单,但清晰地展示了YOLOv7在关键性能指标上的量化优势。这些数字背后,是大量技术创新的结果。
2. 架构创新的深层逻辑
YOLOv7的设计哲学体现了一种全新的平衡艺术。它不再单纯追求模型的复杂度,而是通过巧妙的结构设计和训练策略优化,在保持轻量化的同时显著提升了检测能力。这种设计思路的转变,为后续的模型发展指明了方向。
二、核心技术架构解析
YOLOv7的技术架构可以说是现代深度学习技术的集大成者,它巧妙地融合了多项前沿技术,形成了一个有机的整体。理解这些技术的内在联系和协同作用,对于掌握YOLOv7的精髓至关重要。
1. 可训练的bag-of-freebies概念
"可训练的bag-of-freebies"是YOLOv7提出的一个核心概念,它指的是那些只在训练阶段增加计算开销,而在推理阶段不会影响速度的优化技术。这种设计理念的巧妙之处在于,它允许模型在训练时使用更复杂的结构和策略来学习更好的表征,而在实际部署时仍能保持高效的推理速度。
这一概念的实现依赖于多个技术组件的协同工作。例如,在训练阶段使用复杂的数据增强策略、多尺度训练、知识蒸馏等技术,而在推理阶段这些额外的计算开销完全消除。这种训练与推理的分离设计,为模型性能的提升开辟了新的路径。
class TrainableBagOfFreebies:def __init__(self):self.training_augmentations = ['mosaic', 'mixup', 'cutmix', 'multi_scale_training']self.inference_optimizations = ['re_parameterization','dynamic_label_assignment']def apply_training_strategies(self, batch_data):# 训练阶段的增强策略for aug in self.training_augmentations:batch_data = self.apply_augmentation(aug, batch_data)return batch_datadef optimize_for_inference(self, model):# 推理阶段的优化,移除训练时的额外开销optimized_model = self.remove_training_overhead(model)return optimized_model
2. 计划性重参数化策略
重参数化技术是YOLOv7架构中的另一个重要创新。这种技术允许模型在训练和推理阶段使用不同的网络结构,从而在不牺牲推理效率的前提下,充分利用训练阶段的计算资源。
计划性重参数化的核心思想是在训练时使用多分支结构来增强模型的表达能力,而在推理时将这些分支融合成单一路径,既保留了训练阶段学到的丰富特征表示,又确保了推理阶段的高效性。这种设计在卷积层和归一化层中都有广泛应用。
def planned_re_parameterization(training_block, inference_mode=False):"""计划性重参数化实现"""if not inference_mode:# 训练阶段:多分支结构conv_3x3 = training_block.conv_3x3(x)conv_1x1 = training_block.conv_1x1(x) identity = training_block.identity(x)output = conv_3x3 + conv_1x1 + identityelse:# 推理阶段:融合为单一卷积fused_conv = fuse_conv_branches(training_block.conv_3x3,training_block.conv_1x1, training_block.identity)output = fused_conv(x)return output
这段代码展示了重参数化的基本原理:训练时使用多个并行分支来增强学习能力,推理时将所有分支等价融合为单个高效的卷积操作。
3. 梯度路径优化机制
YOLOv7在网络设计中特别注重梯度传播路径的优化。通过精心设计的残差连接和特征融合机制,确保梯度能够有效地传播到网络的各个层次,从而提高训练的稳定性和收敛速度。
这种优化不仅提高了训练效率,还增强了模型对不同尺度目标的检测能力。通过建立有效的梯度通道,网络能够更好地学习从浅层细节特征到深层语义特征的映射关系。
三、动态标签分配创新
在多输出层的目标检测模型中,如何为不同的预测分支分配合适的训练目标一直是一个挑战性问题。YOLOv7提出的动态标签分配机制,为这个问题提供了优雅的解决方案。
1. 从粗到细的引导策略
传统的标签分配方法通常采用静态规则,例如基于IoU阈值的硬性分配。这种方法的问题在于,它无法很好地适应不同目标的特点和不同预测层的特性。YOLOv7的动态标签分配采用了从粗到细的渐进式策略,能够根据训练过程中的实际情况动态调整标签分配。
这种策略的核心思想是利用粗粒度的预测来指导细粒度的标签分配。在训练初期,使用相对宽松的分配策略来确保网络能够学到基本的目标位置信息;随着训练的深入,逐渐收紧分配策略,使网络能够学习到更精确的边界框回归和分类信息。
class DynamicLabelAssignment:def __init__(self, num_classes, anchor_scales):self.num_classes = num_classesself.anchor_scales = anchor_scalesself.assignment_strategy = 'coarse_to_fine'def assign_labels(self, predictions, targets, epoch):"""动态标签分配实现"""coarse_assignments = self.coarse_assignment(predictions, targets)fine_assignments = self.fine_assignment(coarse_assignments, predictions, targets, epoch)# 根据训练进度调整分配权重alpha = min(epoch / 100, 1.0) # 渐进式权重调整final_assignments = self.blend_assignments(coarse_assignments, fine_assignments, alpha)return final_assignments
YOLO 网络头部负责网络的最终预测,但由于它位于网络的末端,因此添加一个位于中间层的主干头是有利的。在训练过程中,你不仅监督这个检测头,还监督实际进行预测的头部。
辅助头部的训练效率不如最终头部,因为它与预测之间的网络层数较少——因此 YOLOv7 的作者对这种头部的不同监督级别进行了实验,最终确定采用从粗到细的定义,即在不同粒度级别上从主导头部传递监督。
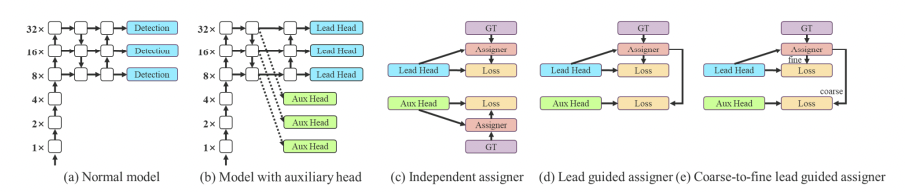
2. 多尺度感知的分配机制
YOLOv7的标签分配还考虑了多尺度检测的特殊需求。不同大小的目标适合在不同的特征层进行检测,因此标签分配策略需要能够智能地判断哪些预测头更适合检测特定的目标。
这种多尺度感知机制通过分析目标的尺度特征和各个检测头的感受野大小,动态决定标签的分配权重。小目标更多地分配给具有高分辨率特征图的检测头,而大目标则主要分配给具有大感受野的深层检测头。
四、复合缩放与效率优化
模型缩放是深度学习中的一个重要问题,特别是在需要部署到不同硬件平台的实际应用中。YOLOv7提出的复合缩放方法,为这个问题提供了系统性的解决方案。
1. 参数效率的极致优化
传统的模型缩放方法通常只考虑单一维度的调整,比如增加网络深度或宽度。YOLOv7的复合缩放则同时考虑了深度、宽度、分辨率等多个维度,并建立了它们之间的协调关系。这种方法能够在保证性能的前提下,最大化地利用可用的计算资源。
通过精心设计的缩放策略,YOLOv7能够相比同类模型减少约40%的参数量和50%的计算量,这种效率的提升对于实际部署具有重要意义。特别是在边缘设备和移动平台上,这种优化带来的好处更加明显。
class CompoundScaling:def __init__(self, base_model):self.base_model = base_modelself.scaling_factors = {'depth': 1.0,'width': 1.0, 'resolution': 1.0}def scale_model(self, efficiency_target):"""基于效率目标的复合缩放"""# 根据效率约束计算最优缩放因子optimal_factors = self.optimize_scaling_factors(efficiency_target)scaled_model = self.apply_scaling(self.base_model, optimal_factors)return scaled_model, self.compute_efficiency_metrics(scaled_model)def optimize_scaling_factors(self, efficiency_target):# 多目标优化:平衡准确率和效率constraints = {'max_parameters': efficiency_target['max_params'],'max_flops': efficiency_target['max_flops'],'min_accuracy': efficiency_target['min_ap']}return self.pareto_optimization(constraints)
2. 计算图优化策略
除了模型结构的优化,YOLOv7还在计算图层面进行了大量优化工作。这包括算子融合、内存访问模式优化、并行计算策略等多个方面。这些优化虽然在算法层面不太明显,但对实际的推理速度有显著影响。
计算图优化的一个重要方面是减少内存访问的开销。通过重新组织计算顺序和数据布局,YOLOv7能够更好地利用现代GPU的内存层次结构,从而提高实际的推理吞吐量。
五、实验验证与性能分析
YOLOv7的性能验证建立在严格的实验设计基础上,涵盖了多个数据集和不同的评估指标。这种全面的评估为其优越性能提供了可靠的证据支撑。
1. COCO数据集上的综合表现
在MS COCO数据集上的实验结果清晰地展示了YOLOv7的优势。从性能对比表中可以看出,YOLOv7在各个模型尺度上都实现了最佳的速度-精度权衡。特别值得注意的是,YOLOv7-tiny在保持轻量化的同时,达到了38.7%的AP值和286 FPS的推理速度,这种性能组合在移动端应用中具有重要价值。
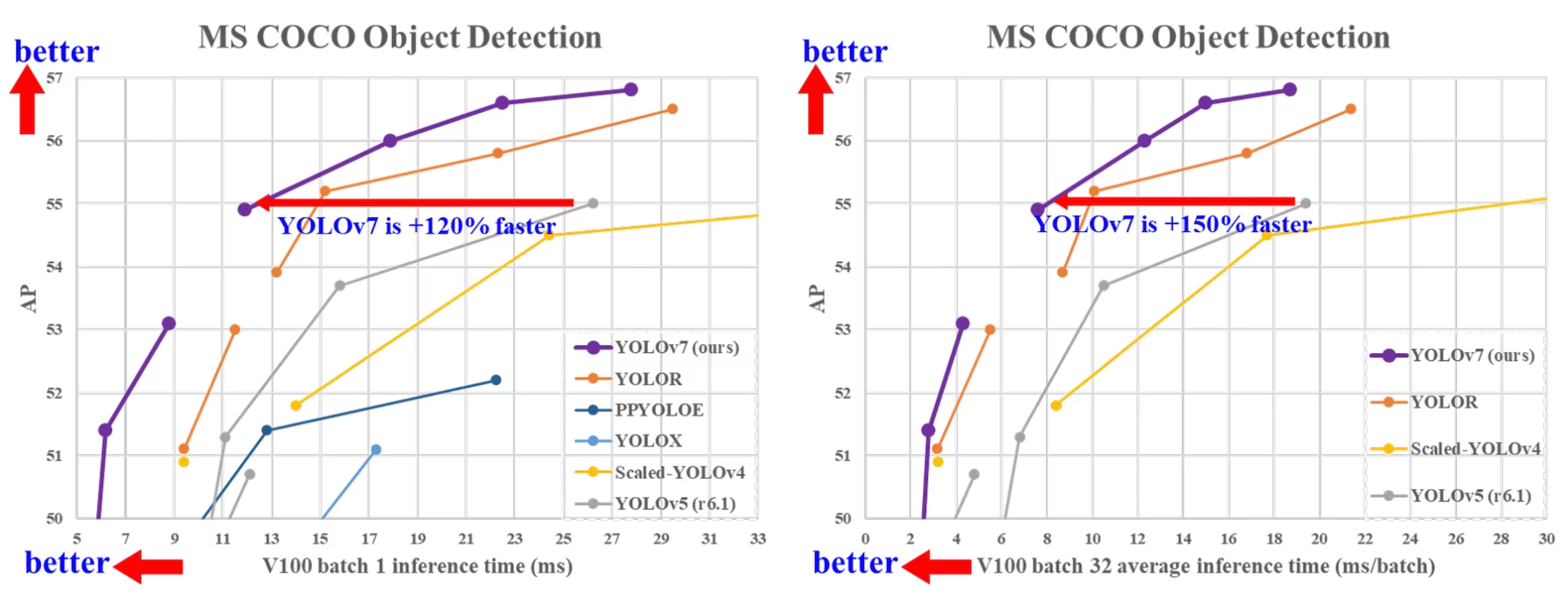
更大规模的YOLOv7-X模型则在高精度应用场景中展现了突出优势,53.1%的AP值配合114 FPS的推理速度,为需要高精度检测的应用提供了理想的解决方案。这种分层的性能设计,使得YOLOv7能够适应不同的应用需求。
2. 跨平台部署验证
YOLOv7的另一个重要特性是其优秀的跨平台兼容性。从边缘设备到云端GPU,YOLOv7都能保持稳定的性能表现。这种兼容性得益于其精心设计的架构和优化策略,使得模型能够充分利用不同硬件平台的特性。
在移动端的部署测试中,YOLOv7展现了相比前代模型显著的效率提升。这不仅体现在推理速度上,还包括内存占用、功耗控制等多个维度。这些改进对于实际的移动应用部署具有重要意义。
YOLOv7代表了实时目标检测技术的一个重要里程碑。它不仅在性能指标上实现了显著突破,更重要的是提出了一系列具有启发性的技术创新。这些创新不仅解决了当前的技术挑战,也为未来的发展奠定了坚实基础。
从技术角度来看,YOLOv7的成功在于其系统性的设计理念和精细化的工程实现。它证明了通过深入理解问题本质和巧妙的技术设计,能够在看似矛盾的性能要求之间找到完美的平衡点。对于研究者而言,YOLOv7提供了丰富的技术思路和实现细节,为后续研究提供了宝贵的参考。对于工程师而言,YOLOv7的优秀性能和良好的工程特性,使其成为实际项目中的理想选择。
文末送书
参与方式
免费包邮送三本! Dream送书活动——第七十期:《Python大模型优化策略:理论与实践》、《人工智能大模型:动手训练大模型基础》
参与方式:
1.点赞收藏文章
2.在评论区留言:人生苦短,我用Python!(多可评论三条)
3.随机抽取3位免费送出!
4.截止时间: 2025-09-02
上期中奖名单:苦学AI的小猪、一寸星河、丶重明(请中奖者私信我)
本期推荐1:《Python大模型优化策略:理论与实践》

京东:https://item.jd.com/15108782.html
Python大模型优化策略指南:从Transformer架构到遗传算法、蚁群算法调优,涵盖模型压缩、量化部署与DeepSeek集成等,赠送可运行的项目代码+教学PPT,助你攻克算力围墙!
关键点
1.零基础友好:从基础概念到实战代码,全程图解+案例拆解,哪怕没学过Python也能轻松掌握大模型优化技巧。
2.硬核干货:一本书搞定深度学习全链路优化,覆盖模型训练、压缩、部署全流程,详解梯度下降、遗传算法、神经网络优化等核心技术,附赠可运行代码库。
3.实战派秘籍:真实项目经验直接搬进书里,书中包含自动驾驶、医疗诊断等落地场景优化方案,带你解决实际业务痛点。
4前沿技术解码:独家解析分布式训练、混合专家系统等核心技术细节,手把手教你用API调通大模型。
5.算力焦虑终结者:小设备也能玩转大模型,量化训练、剪枝、蒸馏等黑科技全公开,教你用有限资源榨干模型性能。
6.产学研闭环:内容紧密结合校企合作案例,基于实际业务需求,确保知识点的实用性。
内容简介
本书是一本全面介绍Python大模型优化策略的专业书籍,旨在帮助读者掌握如何高效训练、优化、部署和调用大规模深度学习模型。掌握这些优化技巧将是推动大模型应用和提升AI行业竞争力的关键。
本书以深度学习和大模型技术为引,系统讲解了各种优化算法,并深入探讨了两者的融合与应用。本书涵盖了机器学习与深度学习概述、Transformer模型与大模型概述、模型训练与优化技巧、模型调用与优化基础、大模型优化概述、常用的优化算法概述、遗传算法、多目标优化与遗传算法进阶、蚁群算法、鲸鱼优化算法、萤火虫优化算法、神经网络优化算法、大模型与优化应用实践、DeepSeek的介绍与使用等内容,每章通过实践练习介绍了大模型优化的实际应用。
本书面向具备机器学习和深度学习基础的读者,适合作为高等院校计算机相关专业的本科及专科教材。对于AI从业者、科研人员和工程师而言,本书能够助力他们在大模型训练与优化领域深入理解并积累实践经验。
本期推荐2:《人工智能大模型:动手训练大模型基础》

京东:https://item.jd.com/14463355.html
大模型手把手训练指南:从Transformer原理到PyTorch实战,从GPU加速到模型量化;从Python环境搭建到多模态应用,从DeepSeek优化到金融医疗落地。系统掌握分布式训练与产业级开发,成为大模型实战高手!
关键点
(1)理论×实践双驱动:从Transformer架构解析到PyTorch实战,系统掌握大模型开发全流程。
(2)硬核技术全景图:涵盖GPU加速、分布式训练、模型量化、DeepSeek等核心技术,深入解析大模型训练优化的技术细节。
(3)行业应用指南:覆盖NLP、CV、多模态三大前沿领域,通过金融、医疗等真实案例掌握产业级解决方案。
(4)开发者成长体系:Python环境搭建→模型微调→架构创新,构建从入门到精通的完整学习路径。
内容简介
在人工智能蓬勃发展的当下,大模型技术正引领着新一轮的技术变革。本书以Python语言为主要工具,采用理论与实践相结合的方式,全面、深入地阐述了人工智能大模型的构建与应用,旨在帮助读者系统理解大模型的技术原理,掌握其核心训练方法,从而在人工智能领域建立系统的技术认知体系。
全书分为五个部分,第一部分从大模型的技术演进历程讲起,重点剖析Python语言在大模型开发中的核心作用;第二部分围绕模型架构设计、训练优化算法及分布式训练策略展开;第三部分深度解读Transformer等主流架构及其变体的实现原理;第四部分涵盖超参数调优、正则化技术、模型评估指标与优化策略;第五部分提供了大模型在自然语言处理、计算机视觉、语音识别等领域的高级应用案例。
本书兼具通俗性与专业性,案例丰富且实操性强,既可作为人工智能初学者的系统入门指南,也可满足进阶学习者的技术提升需求。对研究人员与工程师而言,本书更是一部极具参考价值的技术手册。此外,本书还适合作为高校或培训机构的人工智能