Kafka 在 6 大典型用例的落地实践架构、参数与避坑清单
一、选型速查表
| 场景 | 关键目标 | 推荐清单(示例) |
|---|---|---|
| 消息(Messaging) | 解耦、低延迟、可靠投递 | acks=all、enable.idempotence=true、retries>0、min.insync.replicas=2、合理分区键、DLT |
| 网站活动追踪 | 吞吐极高、可回放 | 主题按类型拆分(page_view, search…),compression.type=zstd,长保留或分层存储,Schema Registry |
| 指标(Metrics) | 运维聚合、准实时 | 窗口聚合(Streams/Flink),短保留(1–7 天),多分区避免热点,消费者组扩展 |
| 日志聚合 | 统一采集、低时延 | Log agent(Fluent Bit/Vector)→ Kafka,cleanup.policy=delete,分来源建主题,DLT+重试 |
| 流处理 | 多阶段管道、图式数据流 | Kafka Streams/Flink,主题“每阶段一写”,幂等写出,回放友好 |
| 事件溯源 / 提交日志 | 可追溯、状态重建 | cleanup.policy=compact(或 compact+delete),键=实体ID,Materialized View |
二、用日志做消息
目标:生产者与消费者解耦、低端到端延迟、强持久性。
与传统 MQ 的区别:Kafka 的消息默认保留(不会因消费而删除),天然支持回放与多订阅者,并通过分区获得线性扩展。
最小配置建议
-
生产者:
acks=all、enable.idempotence=true(开启幂等,避免重复写)max.in.flight.requests.per.connection=1~5(Exactly-Once 时设 ≤5)retries& 退避(exponential backoff)
-
Broker/主题:
replication.factor=3、min.insync.replicas=2(容错 + 一致性)- 分区键选择:满足局部有序(如
orderId)、避免热点
-
消费侧:
- 合理的消费者组并行度
- 死信主题(DLT) + 重试队列,隔离“毒消息”
常见坑
- 只配
acks=1→ 故障丢消息 - 错分分区键 → 热点/顺序失控
- 忽略 DLT → 处理链路被一条异常消息“卡死”
三、网站活动追踪(Website Activity Tracking):超高吞吐的“点击流”
模式:每种活动类型一条中心主题(page_view, search, click…),多下游并行消费:实时监控、风控、离线数仓、画像计算。
落地要点
-
数据模型:强烈建议Schema Registry(Avro/Protobuf),版本演进友好
-
分区策略:
userId/sessionId做 key,保障会话内顺序 -
吞吐与成本:
compression.type=zstd或lz4,批量发送(linger/batch.size) -
保留策略:
- 实时主题:7–30 天
- 历史归档:
tiered storage/对象存储 + 索引(按需)
参考主题
activity.page_view、activity.search、activity.clickactivity.enriched.*(清洗/富化后)
四、指标(Metrics):把分布式指标“汇江成海”
场景:应用/服务把运行指标聚合到中心流,做SLA 监控、容量规划、异常检测。
设计建议
- 生产端聚合后再上报(降噪/降频),或在 Streams/Flink 中做窗口聚合(如 10s/1m)
- 消费侧多用途:存时序库(M3DB/ClickHouse/Influx/TSDB)、在线告警
- 保留:1–7 天足矣(更久走冷存储)
参数要点
- 主题分区数 ≥ 生产端节点数/区域数,避免单分区热点
retention.ms以窗口与排查周期为准
五、日志聚合(Log Aggregation):比“拉文件”更干净的抽象
对比:与 Scribe/Flume 相比,Kafka 提供复制与更低端到端延迟,把“文件”抽象成事件流,天然支持多源多消费者。
推荐链路
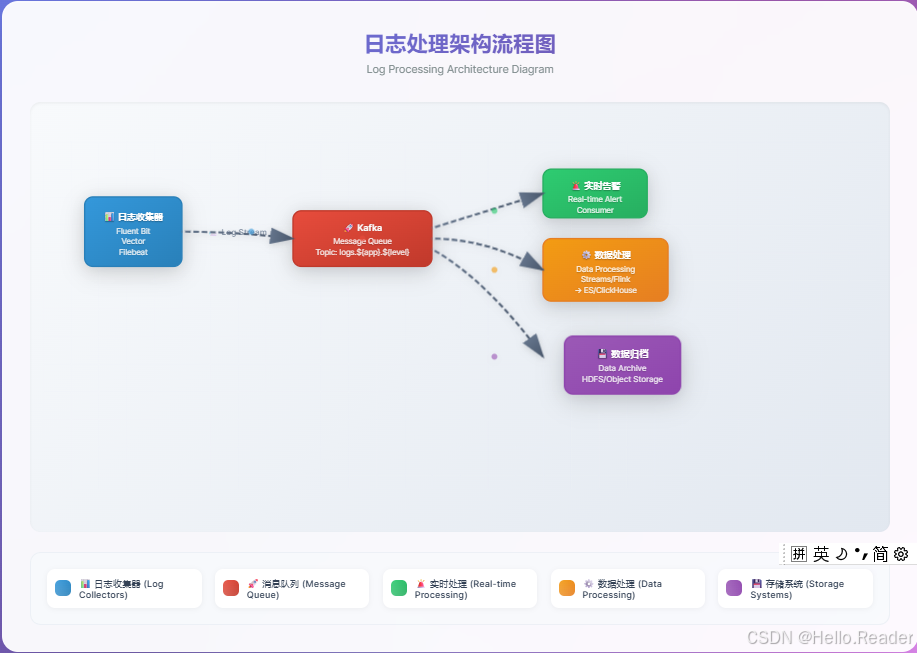
配置要点
cleanup.policy=delete(日志通常无需去重)- 分来源/级别建主题:
logs.app1.info、logs.app1.error… - DLT + 重试:解析失败/超大行单独处理
- 大行处理:生产端分片/截断策略,避免单消息过大
六、流处理(Stream Processing):多阶段实时数据管道
模式:原始 → 清洗/富化 → 主题 A → 统计/聚合 → 主题 B → 推荐/画像…
每一阶段写回 Kafka,形成有向图,具备回放能力与可观察性。
工具选择
- Kafka Streams(轻量、内嵌、与 Kafka 紧耦合,运维简单)
- 或 Flink/Spark Streaming/Samza(复杂拓扑/跨源融合/批流一体)
工程要点
- Exactly-Once:Streams/Flink 均可配置 EOS 事务与一致性写(双写避免)
- 窗口:滚动/滑动/会话窗口,按事件时间处理 + 水位线
- 回放:定位时间点 → 重置消费者位点 → 重新计算
七、事件溯源(Event Sourcing)与提交日志(Commit Log)
事件溯源:把状态变更记录为按时间排序的不可变事件;当前状态 = 事件重放后的结果。
提交日志:为分布式系统提供外部复制与重放的“真相来源”(Source of Truth)。
Kafka 配置要点
- 主题:
cleanup.policy=compact(或compact,delete组合) - key 设计:实体ID(
accountId/orderId),保证“最后一次事件”长留 - 读侧:Materialized View(Streams/Flink 的 KTable/State),对外提供查询
- 故障恢复:新副本/新服务节点通过回放日志快速重建状态
何时选 compact?
- 需要任意时刻的最新值(KV 视图)且保留“最后一次变更”
- 结合 delete:既要最新值,又要保留一段历史
八、参考参数模板(可直接套用)
通用(Broker/主题)
# 可用性与一致性
replication.factor=3
min.insync.replicas=2# 吞吐与成本
compression.type=zstd
message.max.bytes=10485760 # 10MB,视业务调整
消息/交易类主题
cleanup.policy=delete
retention.ms=604800000 # 7 天
活动追踪/点击流
cleanup.policy=delete
retention.ms=2592000000 # 30 天或更长
指标主题
cleanup.policy=delete
retention.ms=604800000 # 1–7 天
事件溯源/提交日志(KV 视图)
cleanup.policy=compact
min.cleanable.dirty.ratio=0.1
segment.ms=604800000
生产者(Exactly-Once/高可靠)
acks=all
enable.idempotence=true
retries=2147483647
max.in.flight.requests.per.connection=5
delivery.timeout.ms=120000
linger.ms=5
batch.size=131072
九、监控与可观测性(必做)
- 延迟:生产端/消费端/端到端
- Lag:消费者组积压
- 吞吐与错误率:生产失败、重试、DLT 数量
- 存储水位:磁盘占用、Log Cleaner(压缩)进度
- 再均衡:频率与耗时(过于频繁需排查分区分配/会话超时)
十、常见设计误区与修正
- 把 Kafka 当“队列”:忽视保留与回放 → 设计 DLT、位点重置、历史重算
- 分区数拍脑袋:过多导致内存/FD/控制面成本陡增;过少限制并行度
- schema 无约束:序列化随意 → 引入 Schema Registry,版本演进有序
- 忽视跨数据中心/多活:需评估 MirrorMaker 2 / Flink CDC / 云托管多区域复制方案
十一、结语
把 Kafka 用对地方,你会得到一条既能顶住流量、又能回溯历史,还能驱动实时决策的“数据中枢神经”。
从消息解耦到点击流,从运维指标到日志聚合,再到流式计算与事件溯源,Kafka 提供了统一的抽象与工业级的可靠性。