GraphRAG
一个思考:有价值的技术都是是为了解决需求而存在的,然而在解决问题的同时,往往会伴随新的问题出现
背景介绍:
随着大模型的不断发展,凭借着优秀的泛化能力,在通用领域的智能问答、特征提取等方面表现出不俗的潜力
然而预训练+微调的模式使得LLM本身高度依赖训练时候的数据,导致使用过程中出现知识陈旧与“幻觉”等问题的出现。同时如果想运用到企业哪边更加困难,企业数据及其重要训练过程很难有私域数据。基于以上问题目前主流解决方案:检索增强(RAG),当然有实力可以自主微调适用的“SLM”垂直领域的小模型也是很多人探索的方向。今天咱们得主题就是基于RAG基础之上的GraphRAG。
前置:RAG-检索增强
查询流程
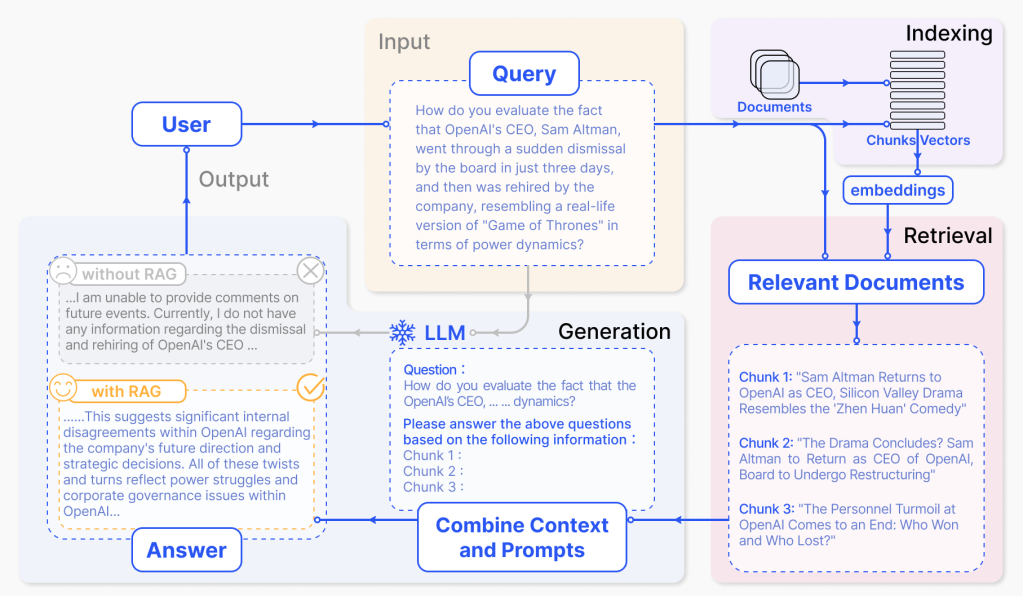
核心流程
Step1:数据准备:构建可检索的知识库
先切片,现在各大平台如阿里云百炼大模型,再构建知识库的时候偏可以使用PDF文档,然后切片示例如下:

Step2:查询理解:明确用户需求的语义
这一步和通用的问答系统or聊天机器人是相似的,在当前阶段需将用户的自然语言查询转化为可以使用的向量格式,同时优化查询精度,避免因 “查询表述模糊” 导致检索偏差。通常也分为两步:
1、查询预处理(各种数据清洗、降噪、纠错等)
2、查询嵌入(格式转换,最终都是基于同维度向量匹配的)
Step3:检索:获取相关知识片段(核心)
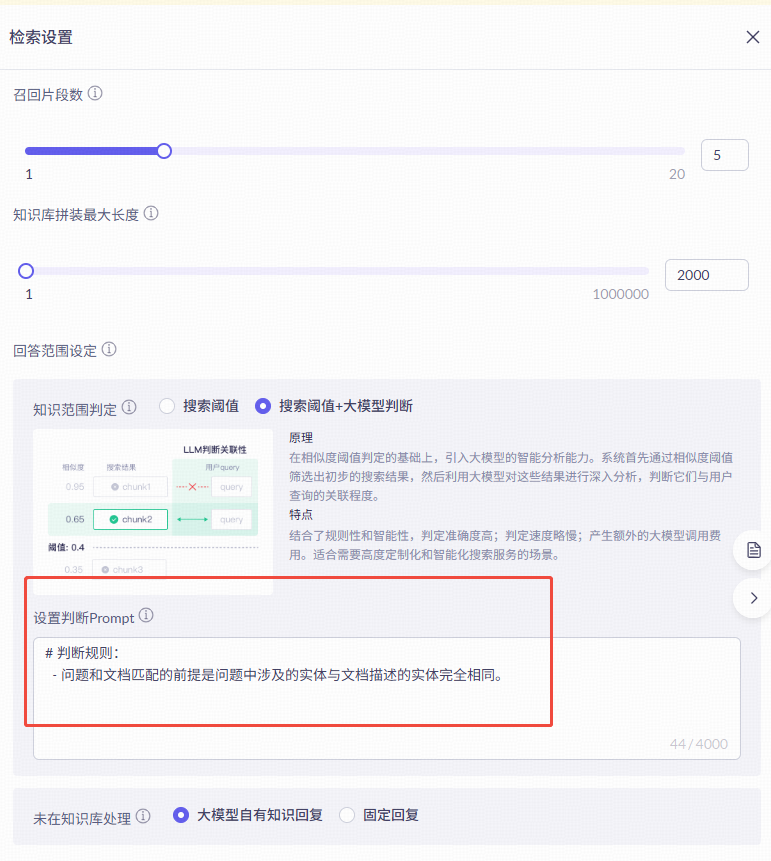
毫无疑问,RAG名字就是检索增强,所以检索阶段就是RAG的核心步骤。简单点理解就是在我们理解客户的输入查询后,从我们构建的知识库中找到与客户最相关的切片,为后续回复提供内容支持。该阶段需要解决核心问题便是寻找“最相关”,通常使用:向量检索(相似性搜索)。
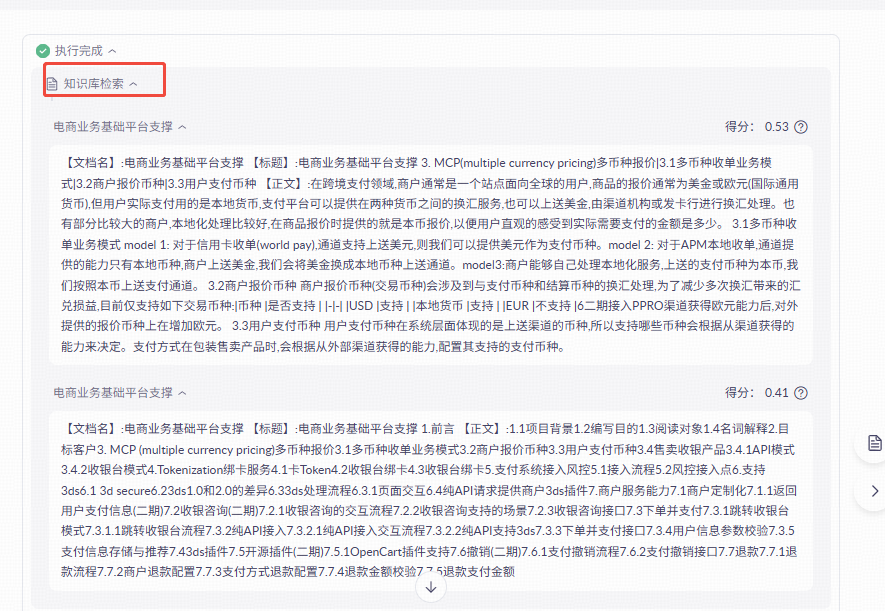
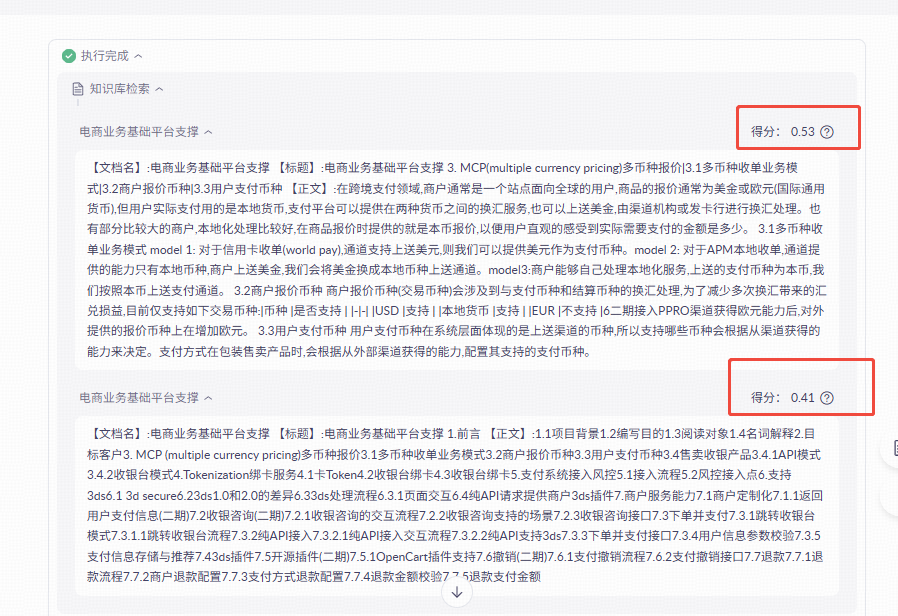
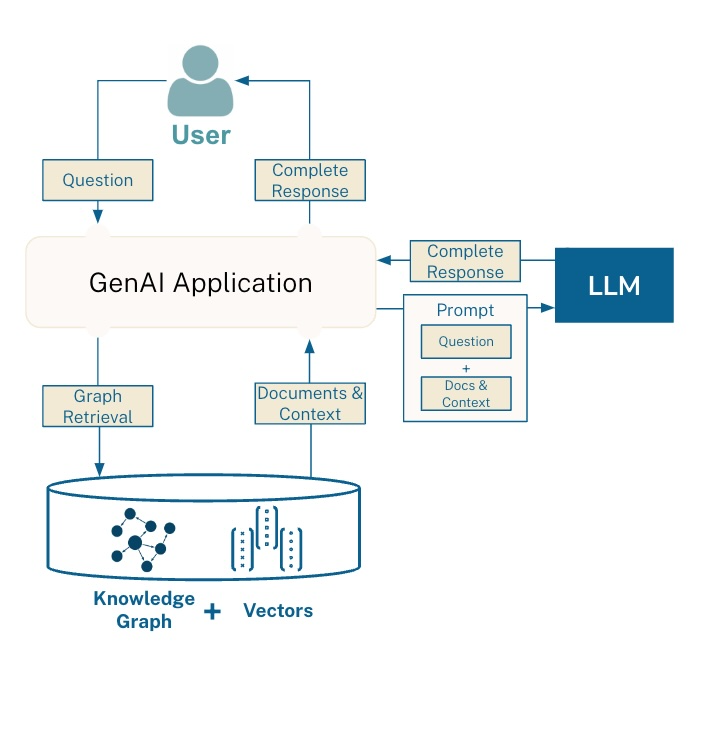
Step4:上下文构建:整合检索结果
该阶段就是整合上一步骤中获取到的切片,然后基于切片内容转换成大模型能够理解的上下文。如下图:
Step5:生成:大模型基于知识生成答案
经过上述步骤,我们已经拿到用户的查询和整合后的上下问数据,此时需要给用户响应。此时我们可以通过设置System-Prompt模板来让LLM给出准确无幻觉的回答。
小结
上述我们通过简单的流程介绍,了解了传统RAG是怎么做的,思考下有什么问题?
1、分片如何选择呢?通过上文可以看到我的一个文档给我切割成了1000多个切片,那么检索的时候我到底要召回这里面的那些切片呢?不同切片的得分又该怎么计算呢?
2、全局问题该怎么办,例如:请根据案例介绍下商收款的数据流、信息流?
GraphRAG
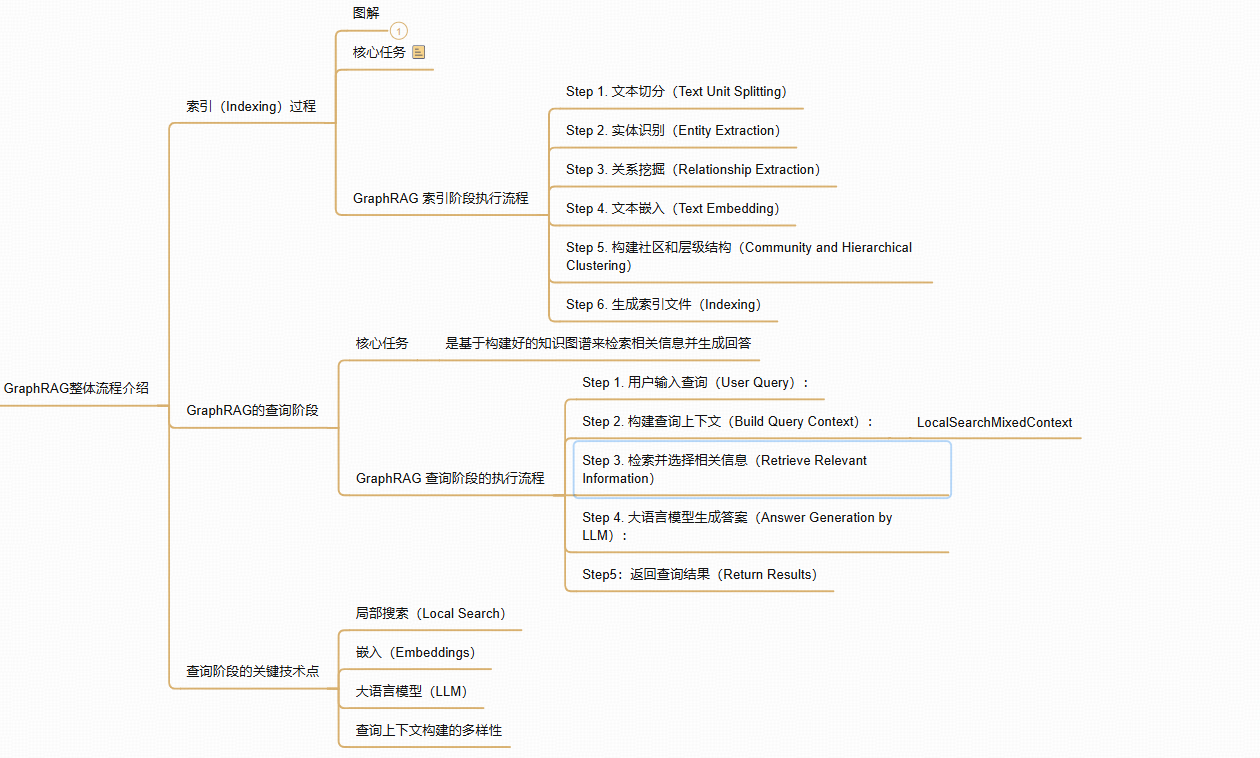
索引(Indexing)过程
Step 1. 文本切分(Text Unit Splitting)
将下图修改为Index分片示例:

| id | human_readable_id | text | n_tokens | document_ids |
| t1 | text_unit_1(切片00) | 篇:跨境支付基础知识...61.1跨境支付基础概念总览...61.1.1 33张图、66个跨境支付基础知识点,看完就入门!...61.1.2跨境支付三 查看详情 | 50(segment_length) | doc_1 |
| t2 | text_unit_2(切片01) | 深度解析“外卡收单”体系...1342.1.2跨境支付中的外卡收单体系浅析...1562.2境外聚合收单...1662.2.1境外本地聚合支付一览...1662.3电商 B2C收款...1702.3.1跨境电商收 | 50(segment_length) | doc_1 |
Step 2. 实体识别(Entity Extraction)
实体识别通常指的是文本中具有独立存在、能够被明确识别并且具有特定意义的对象。实体通常是指一些特定的名词,它们代表现实世界中的对象或概念,可以是人、地点、组织、事件、日期、物品、概念等。
例如:电商、知识等
- 知识图谱中的实体
在知识图谱中,每个实体都有其独特的标识符和属性(例如,姓名、类型、描述等)。这些属性和关系帮助我们理解实体在特定领域中的作用和上下文。实体识别是图谱构建的重要步骤之一。
实体识别(Entity Recognition)是指从文本中自动识别出这些重要的实体
实体分类:在识别实体之后,还需要根据其属性对实体进行分类,阿里百搭可以打标签,手动执行
Step 3. 关系挖掘(Relationship Extraction)
关系挖掘(Relationship Extraction)是构建知识图谱过程中的一个关键环节,它旨在识别文本中不同实体之间的关系。关系挖掘通常是实体识别之后的第二步,目的是将各个实体连接起来,形成一个有意义的图谱结构。在GraphRAG中,关系挖掘的过程涉及多种技术手段,包括自然语言处理(NLP)、机器学习、深度学习等方法。
核心概念一:度数 (Degree)
核心概念二:等级 (Level)
Step 4. 文本嵌入(Text Embedding)
将上述步骤构建的信息,转换成LLM可以理解的向量数据,为后续计算提供准备条件。
Step 5. 构建社区和层级结构(Community and Hierarchical Clustering)
根据社区算法的结果,我们可以将实体划分到两个社区,并基于每个社区的特点生成社区报告。每个社区报告将描述该社区的核心内容、关联的实体、关系以及社区的重要性等信息。
Step 6. 生成索引文件(Indexing)
生成索引文件,落入磁盘持久化上述构构建的信息,可以简单理解为数据刷入磁盘的操作。只是这些文件已经构建好相关信息。
GraphRAG的查询阶段
Step 1. 用户输入查询(User Query)
这个就是用户在对话框中输入的信息如:什么是MCP
Step 2. 构建查询上下文(Build Query Context)
GraphRAG会根据用户输入查询的内容,从已经构建好的知识图谱中提取相关的信息并构建查询上下文。根据预设的参数(如文本单元占比、实体数量等)来选择最相关的文本片段、实体、关系等,以便提供一个完整的上下文。
Step 3. 检索并选择相关信息(Retrieve Relevant Information)
检索并选择相关信息(Retrieve Relevant Information):
通过构建好的查询上下文,GraphRAG会检索并从中选择最相关的文本单元、实体和关系。这个过程的目的是通过“局部搜索”算法找到与用户查询最相关的信息,并确定哪些是能够提供解答的关键内容。
Step 4. 大语言模型生成答案(Answer Generation by LLM)
结合检索到的上下文信息,GraphRAG使用一个大型语言模型来生成最终的回答。模型会根据检索到的上下文生成自然语言的回应,并根据查询的需要决定回答的格式和内容
Step5:返回查询结果(Return Results)
最终,GraphRAG将生成的答案返回给用户。如果设置了“返回候选上下文”(return_candidate_context=True),则还会返回所有相关候选的实体、关系和文本单元,供用户参考。
查询阶段的关键技术点
- 局部搜索(Local Search):通过局部搜索算法,GraphRAG从已有的知识图谱中选择与查询最相关的信息,形成查询上下文。
- 嵌入(Embeddings):对于文本单元、实体和关系,GraphRAG使用嵌入模型将它们转化为向量表示,从而计算相似度,选取最相关的内容。
- 大语言模型(LLM):基于查询上下文,使用大语言模型生成自然语言回答。
- 查询上下文构建的多样性:在不同的查询中,GraphRAG会根据具体的需求调整上下文的构建方式,例如调整文本单元和社区报告的比例,或者增加对历史对话的考虑。
TinyGraphRAG
写在前面
tinyGraphRAG是github项目datawhalechina中根据GraphRAG思想从0实现一个类似demo项目。
原文地址:https://github.com/datawhalechina/tiny-universe/tree/main/content/TinyGraphRAG
根据上文整个对GraphGAG流程的理解,如果让我们实现的一个GraphGAG的话其实核心需要解决两个问题:1、知识库文档索引如何构建 2、如何根据输入查询最佳文档。
技术选型
- LLM:智普;
- 向量数据库:智普
- 图数据库: Neo4J
模型使用
使用大模型厂商提供的API或者向量数据库其实核心就三点:1:base_url 2:api_key 3: other_params,后面就根据API文档调用需要的接口即可。
Neo4J
在上述流程中,我们介绍了如何创建文档索引文件,项目这里选择使用 Neo4j 作为图数据库,Neo4j 是一个基于图的数据库,可以方便的进行图的存储与查询,同时,Neo4j 也提供了丰富的图操作算法,可以方便的进行图的分析。
GraphRAG核心代码解读
索引构建
图提取
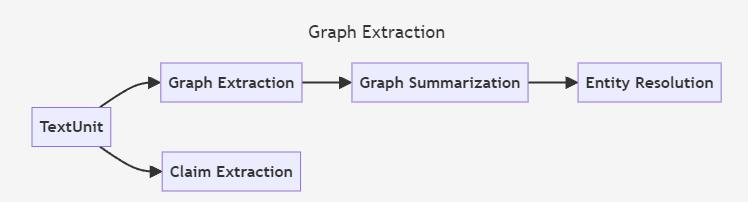
构建社区

社区总结

文档处理

查询
LocalSearch
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.query.structured_search.local_search.mixed_context import LocalSearchMixedContextclass LocalSearch:def __init__(self, llm, context_builder, token_encoder, llm_params, context_builder_params, response_type, system_prompt=None):self.llm = llm # 用于生成响应的 LLMself.context_builder = context_builder # 上下文构建器,结合知识图谱和文本块self.token_encoder = token_encoder # 用于 token 计数的编码器self.llm_params = llm_params # LLM 参数(如 temperature, max_tokens)self.context_builder_params = context_builder_params # 上下文构建参数self.response_type = response_type # 响应格式self.system_prompt = system_prompt # 可选的自定义系统提示async def search(self, query, conversation_history=None, **kwargs):# 构建上下文context_result = self.context_builder.build_context(query=query, conversation_history=conversation_history, **self.context_builder_params)# 生成提示search_prompt = self._create_prompt(context_result, query)# 调用 LLM 生成响应response = await self.llm(search_prompt, **self.llm_params)return response上下文构建器(LocalSearchMixedContext)
```
LocalSearchMixedContext 是 LocalSearch 的核心组件,
负责整合知识图谱中的实体、关系、社区报告和原始文本块。```class LocalSearchMixedContext:def __init__(self, community_reports, text_units, entities, relationships, covariates, entity_text_embeddings, embedding_vectorstore_key, text_embedder, token_encoder):self.community_reports = community_reports # 社区报告self.text_units = text_units # 文本块self.entities = entities # 实体列表self.relationships = relationships # 关系列表self.covariates = covariates # 可选的协变量self.entity_text_embeddings = entity_text_embeddings # 实体描述嵌入self.embedding_vectorstore_key = embedding_vectorstore_key # 嵌入存储键self.text_embedder = text_embedder # 嵌入模型self.token_encoder = token_encoder # token 编码器def build_context(self, query, conversation_history, **params):# 将查询映射到相关实体selected_entities = map_query_to_entities(query=query, text_embedding_vectorstore=self.entity_text_embeddings,text_embedder=self.text_embedder, all_entities_dict=self.entities,k=params.get("top_k_mapped_entities", 10))# 提取相关关系、文本块和社区报告context_data = self._collect_context(selected_entities, params)return context_data示例
api_key = os.environ["GRAPHRAG_API_KEY"]
llm = ChatOpenAI(api_key=api_key, model="gpt-4-turbo")
text_embedder = OpenAIEmbedding(api_key=api_key, model="text-embedding-ada-002")
token_encoder = tiktoken.get_encoding("cl100k_base")context_builder = LocalSearchMixedContext(community_reports=reports, text_units=text_units, entities=entities,relationships=relationships, entity_text_embeddings=description_embedding_store,text_embedder=text_embedder, token_encoder=token_encoder
)search_engine = LocalSearch(llm=llm, context_builder=context_builder, token_encoder=token_encoder,llm_params={"max_tokens": 2000, "temperature": 0.0},context_builder_params={"text_unit_prop": 0.5, "community_prop": 0.1, "top_k_mapped_entities": 10},response_type="multiple paragraphs"
)result = await search_engine.search("Tell me about Agent Mercer")
print(result.response)global_search
GlobalSearch
from graphrag.query.structured_search.global_search.search import GlobalSearchclass GlobalSearch:def __init__(self, llm, context_builder, map_system_prompt, reduce_system_prompt, response_type, allow_general_knowledge=False):self.llm = llm # 用于生成响应的 LLMself.context_builder = context_builder # 上下文构建器,用于从社区报告准备数据self.map_system_prompt = map_system_prompt # Map 阶段的提示模板self.reduce_system_prompt = reduce_system_prompt # Reduce 阶段的提示模板self.response_type = response_type # 响应格式(例如多段文本)self.allow_general_knowledge = allow_general_knowledge # 是否允许引入外部知识async def search(self, query, conversation_history=None, **kwargs):# 构建上下文context_result = self.context_builder.build_context(query=query, conversation_history=conversation_history, **kwargs)# Map 阶段:对每个社区摘要生成部分响应map_responses = await self._map_community_summaries(context_result, query)# Reduce 阶段:汇总所有部分响应生成最终答案final_response = await self._reduce_responses(map_responses, query)return final_response代码示例
search_engine = GlobalSearch(llm=ChatOpenAI(api_key=api_key, model="gpt-4-turbo"),context_builder=GlobalSearchContextBuilder(community_reports=reports),map_system_prompt="Given the community summary: {summary}, answer the query: {query}",reduce_system_prompt="Summarize the following responses: {responses} into a coherent answer",response_type="multiple paragraphs"
)
result = await search_engine.search("用户输入的查询?")
print(result)GlobalSearch 与 LocalSearch 的对比
| 特性 | GlobalSearch | LocalSearch |
| 查询类型 | 全局性问题(例如数据集主题) | 局部性问题(例如特定实体细节) |
| 数据来源 | 社区摘要(Community Summaries) | 知识图谱实体、关系、文本块 |
| 处理方式 | Map-Reduce 范式,汇总社区响应 | 基于实体映射的上下文构建 |
| 适用场景 | 需要综合整个数据集的洞察 | 需要深入挖掘特定实体的信息 |
| 性能 | 70-80% 胜率优于传统 RAG(综述性、多样性) | 适合高精度、特定上下文的查询 |
| 计算成本 | 较低(使用预生成摘要) | 较高(动态检索实体和文本块) |
GraphRAG问题
- GraphRAG 的知识图谱是静态生成的,难以支持实时数据更新
- LocalSearch 依赖查询到实体的语义映射,若查询与图谱中的实体无强关联,检索结果可能为空。
- GlobalSearch 依赖社区摘要,难以回答需要细粒度事实的查询。
- LLM 可能在上下文不足时,基于其预训练知识生成答案,导致与数据集不符。
- GlobalSearch 的 Reduce 阶段可能过度概括,引入偏差。
基于上述问题又有哪些解决方案呢?咱们下次在讨论
参考文献:
https://github.com/datawhalechina/tiny-universe/blob/main/content/TinyGraphRAG/readme.md
https://github.com/microsoft/graphrag
https://zhuanlan.zhihu.com/p/13801755777
https://zhuanlan.zhihu.com/p/716999421
https://gitee.com/open-llm/llm-graph-rag.git