Ubuntu24.04配置yolov5
一、前言
记录一下在 Ubuntu24.04 系统上配置 yolov5 算法的过程。系统、anaconda3 都前期都已配置好,下载链接也已替换为镜像源。
1. 参考链接:
基于Ubuntu下Yolov5的目标识别】保姆级教程 | 虚拟机安装 - Ubuntu安装 - 环境配置(Anaconda/Pytorch/Vscode/Yolov5) |全过程图文by.Akaxi
2. 项目链接
yolov5 官网
二、安装vscode
1. 安装vscode
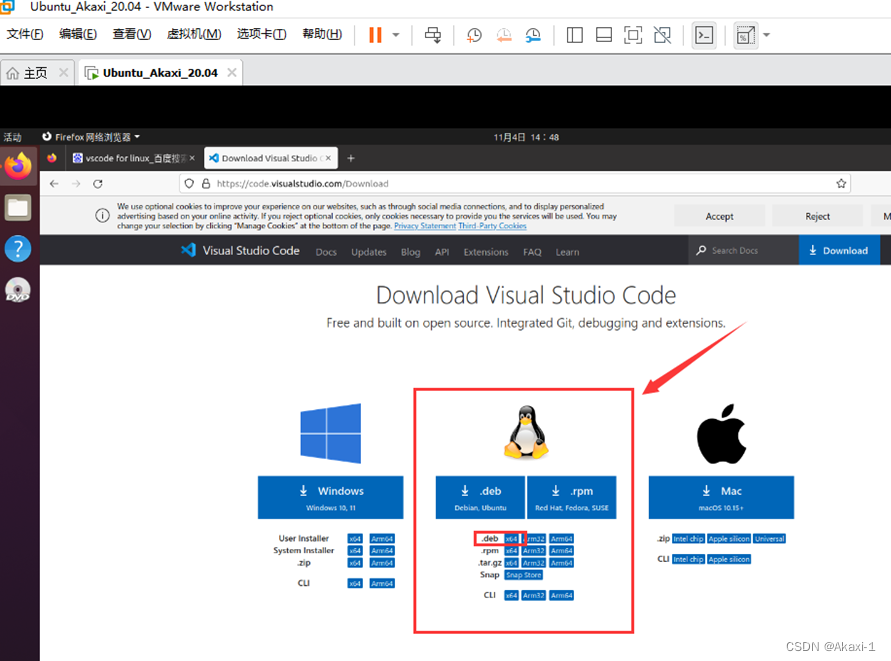
【Vscode官网】https://code.visualstudio.com/Download
选择linux版本的.deb_x64版本,点击下载
下载完成后,在文件的下载中找到安装包,右键用应用中心打开,安装。
2. 配置 vscode
打开 vscode,点击拓展,下载拓展中文包
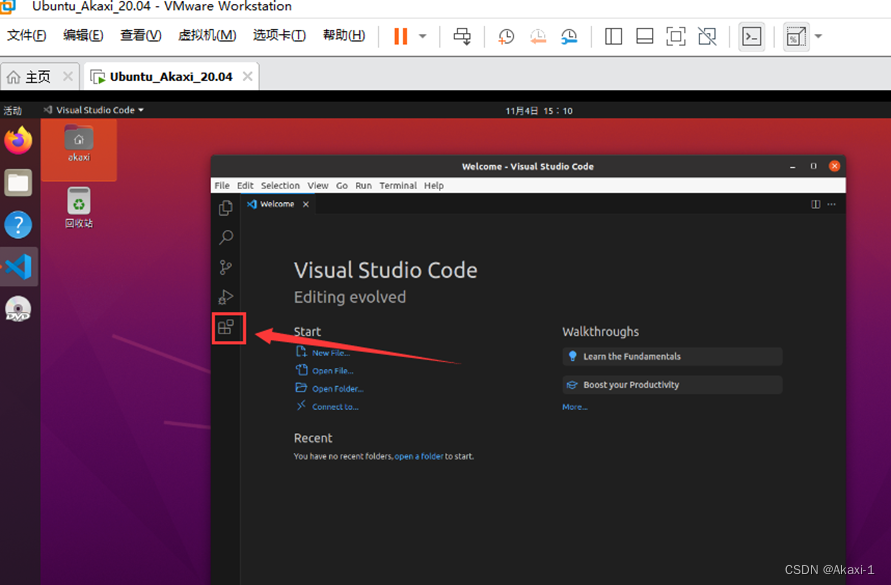
输入 chinese 找到中文包,点击 install 下载
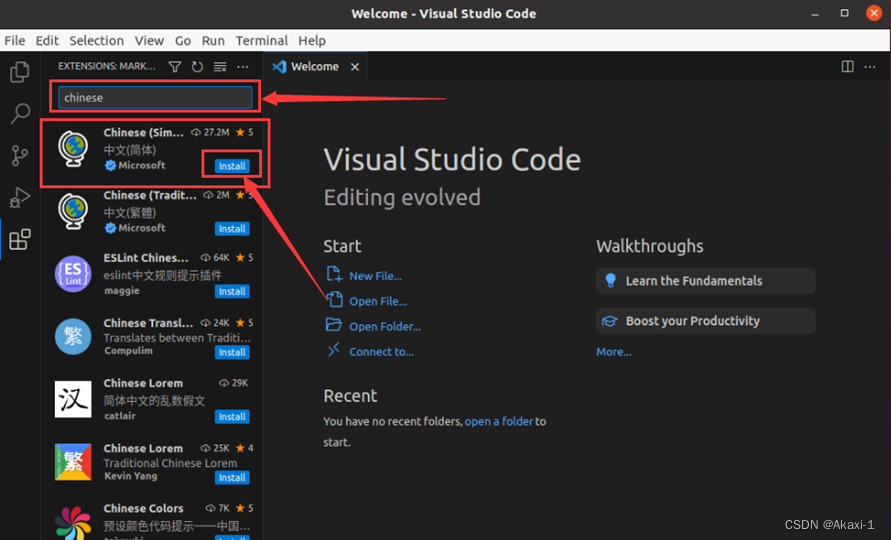
下载完成后,右下角更改系统语言并且重启 vscode。
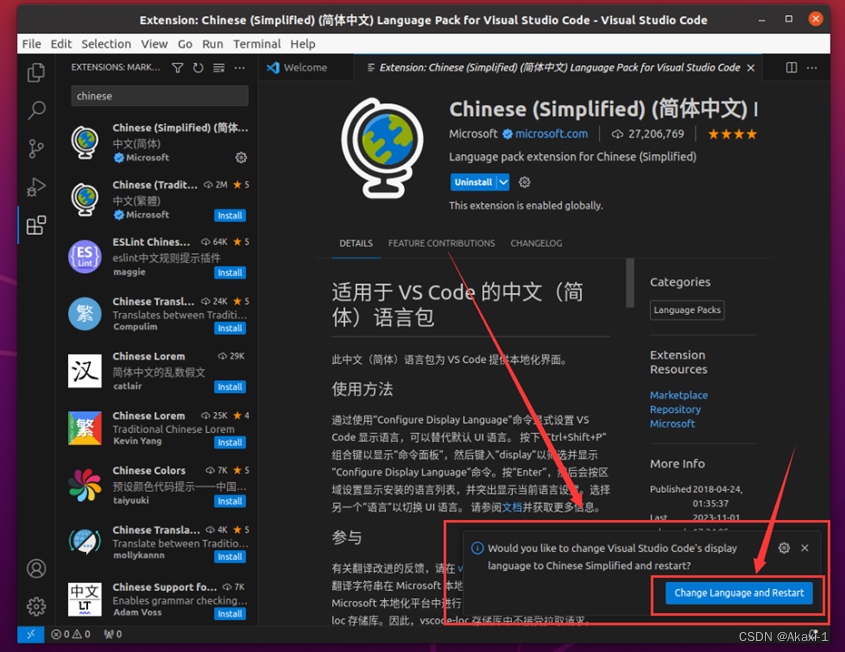
接下来配置 Python 拓展,同样在 vscode 拓展里输入 python 下载拓展并安装:
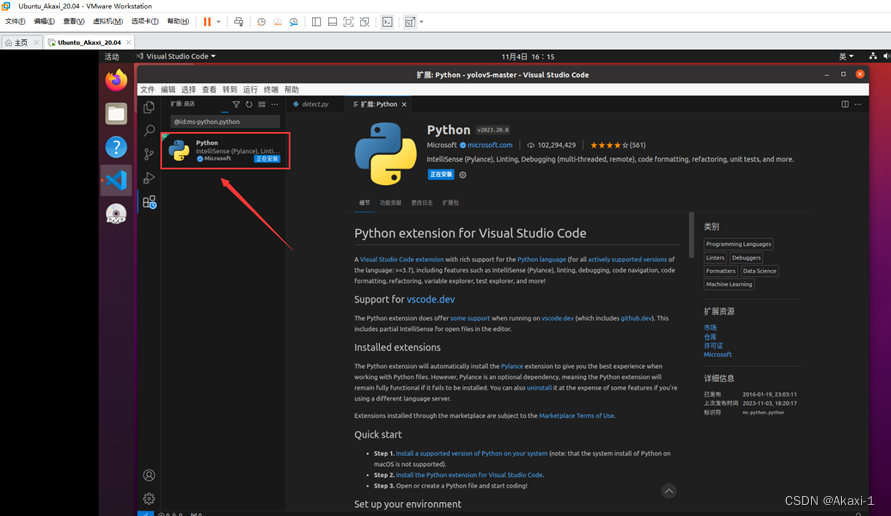
三、配置 yolov5
1. 新建虚拟环境
在终端输入:
conda create -n yolov5 python=3.8
yolov5 是我新建的虚拟环境的名称
激活虚拟环境:
conda activate yolov5
2. 安装 CUDA+cudnn+pytorch
这一部分我安装的版本不正确,后面测试的时候才发现,匹配我显卡的版本应为 CUDA11.8,具体见第五节第2部分,但安装过程没有问题
全程参考链接
1)查看 CUDA 与 cudnn 版本
在终端输入nvcc -V查看显卡信息,这里我能安装的 CUDA 的最高版本为 12.4。
在 pytorch 官网查看对应版本信息:
yolo5 要求安装的 torch 版本需要 >= 1.7,这里我选择安装 1.8 版本,对应的 CUDA 版本我选择 10.2:

2)安装 CUDA+cudnn
下载地址: https://developer.nvidia.com/cuda-toolkit
历史版本下载地址: https://developer.nvidia.com/cuda-toolkit-archive
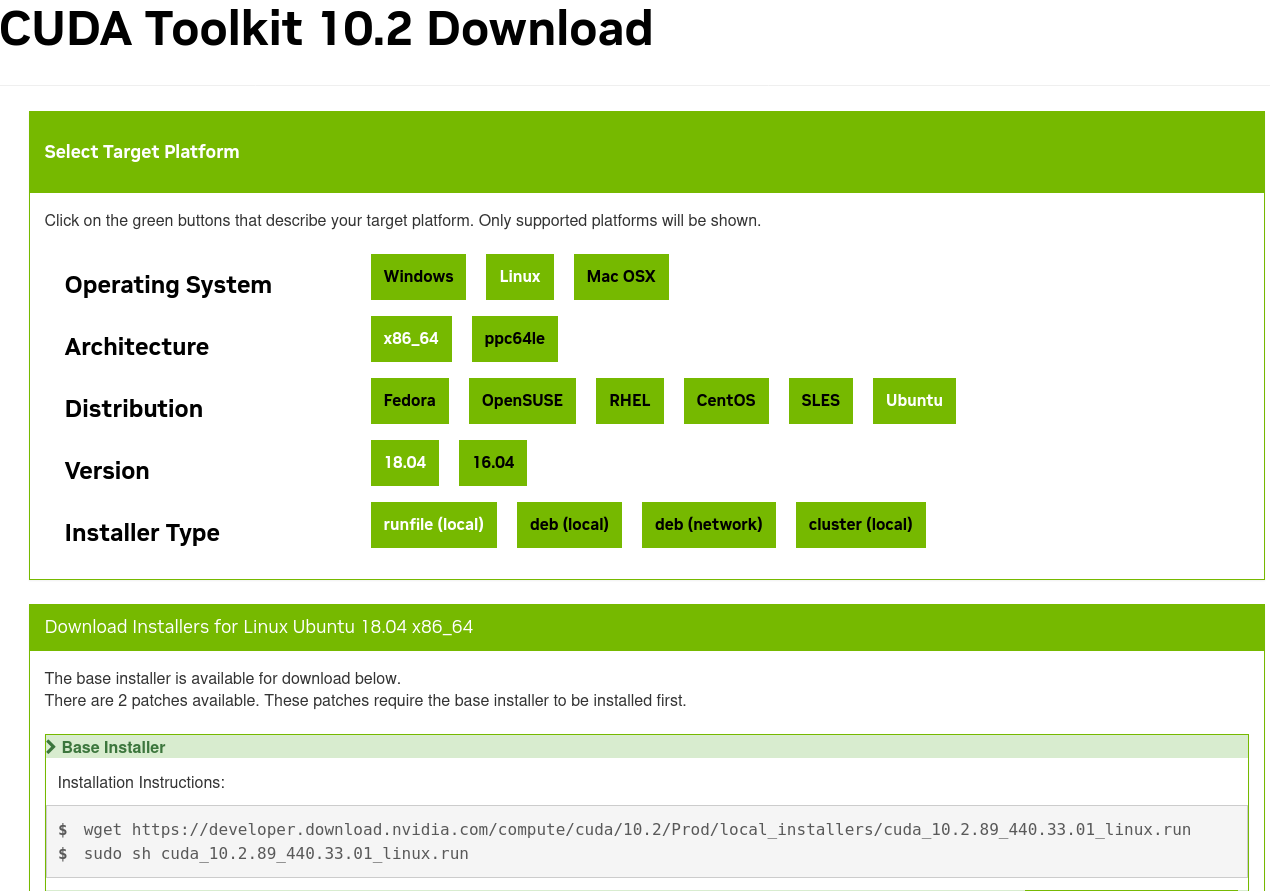 依次执行上面的两条命令:
依次执行上面的两条命令:
wget https://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
sudo sh cuda_10.2.89_440.33.01_linux.run
然后出现:
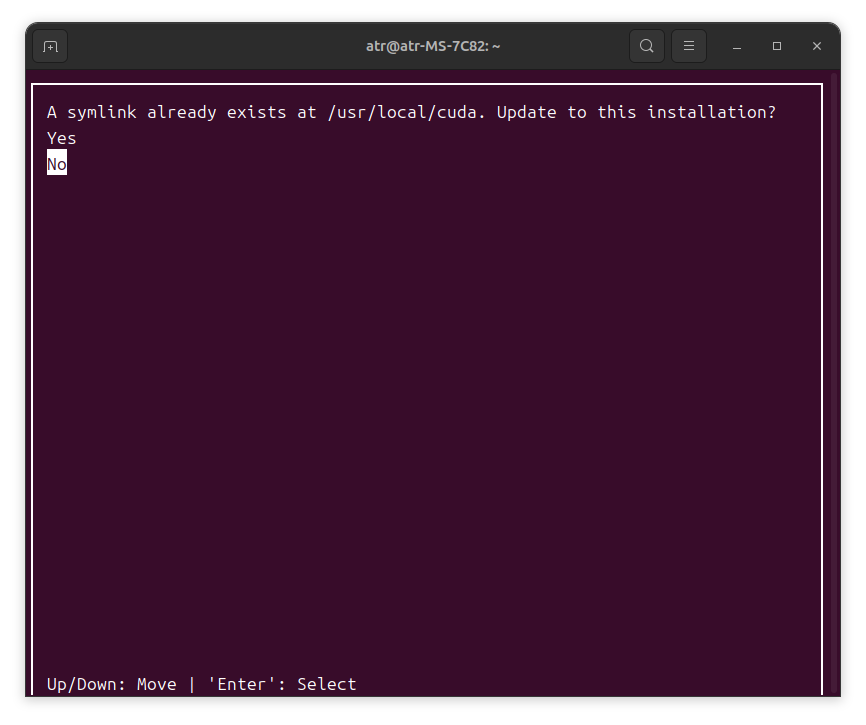
A symlink already exists at /usr/local/cuda. Update to this installation?
因为我之前安装过一个 12.1 的版本,所以问我是否要覆盖之前的软链接。这里我选择 No。
创建新的软链接:
cd /usr/local
sudo rm -r cuda
sudo ln -s cuda-10.2 cuda # 更改为cuda10.2
输入nvcc -V查看是否安装成功:

成功。
3) 安装 CUDNN
在官网选择合适的版本安装。

这里我选择8.7.0。解压后进入文件夹,并在文件夹中打开终端,执行以下命令:
sudo cp include/cudnn.h /usr/local/cuda/include
sudo cp lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
测试是否安装成功:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
4)安装 torch
- 打开官网
- 选择合适的版本
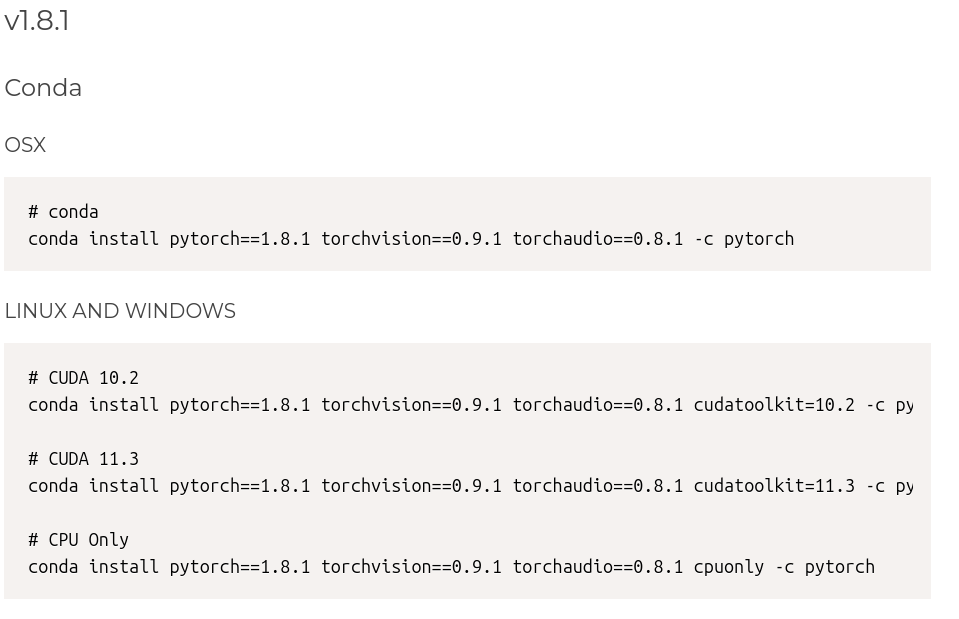
输入指令:
conda install pytorch==1.8.1 torchvision==0.9.1 torchaudio==0.8.1 cudatoolkit=10.2 -c pytorch
检测是否安装成功:
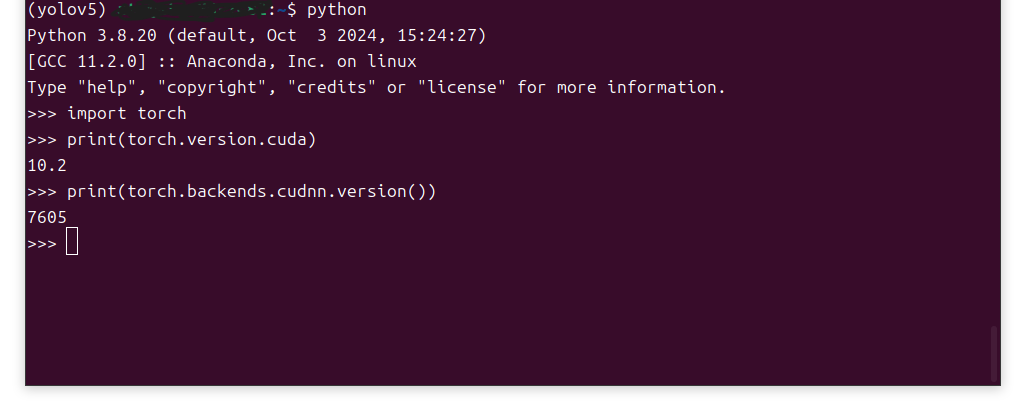
pythonimport torch
print(torch.version.cuda)
print(torch.backends.cudnn.version())
3. 安装其它包
- 在 yolov5 主文件夹中打开终端,激活虚拟环境
- 在终端输入指令:
pip install -U -r requirements.txt
四、测试 yolov5
-
打开 vscode,点击打开文件夹,点击 yolov5 文件夹
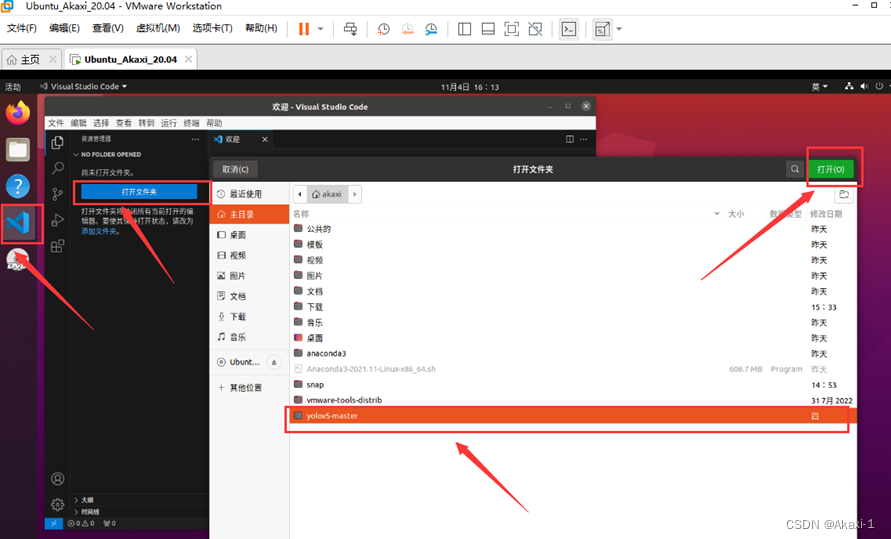
-
打开后,信任文件夹
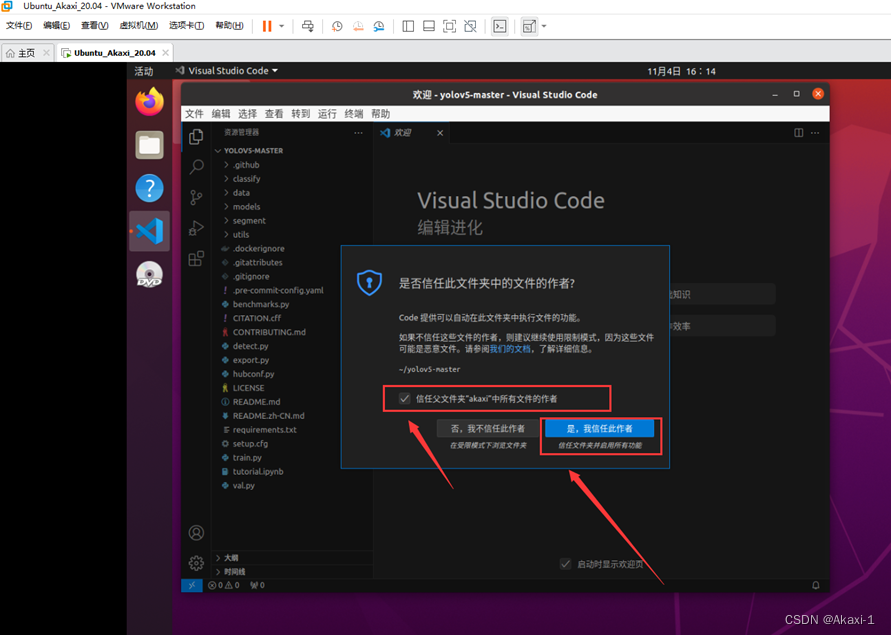
-
点击 detect.py 文件,点击右下角的环境解释器,在上面选框中找到 yolov5 解释器。
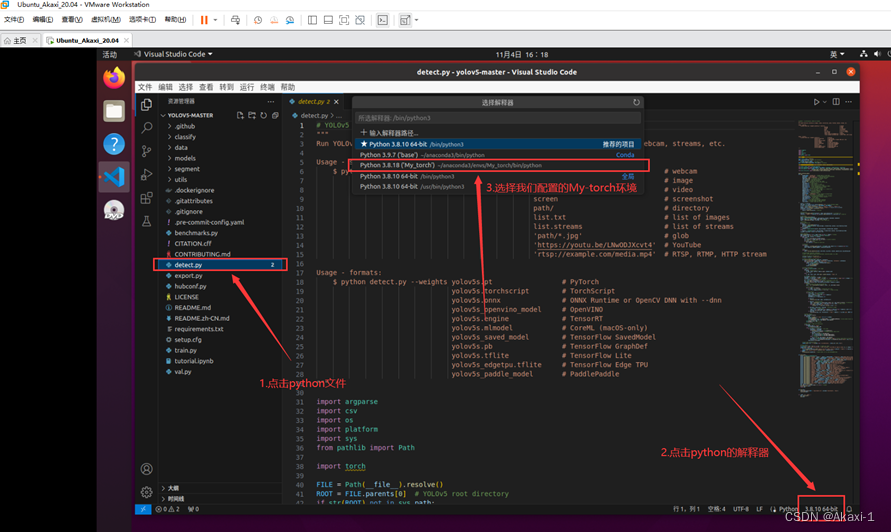
-
点击右上角的三角运行。
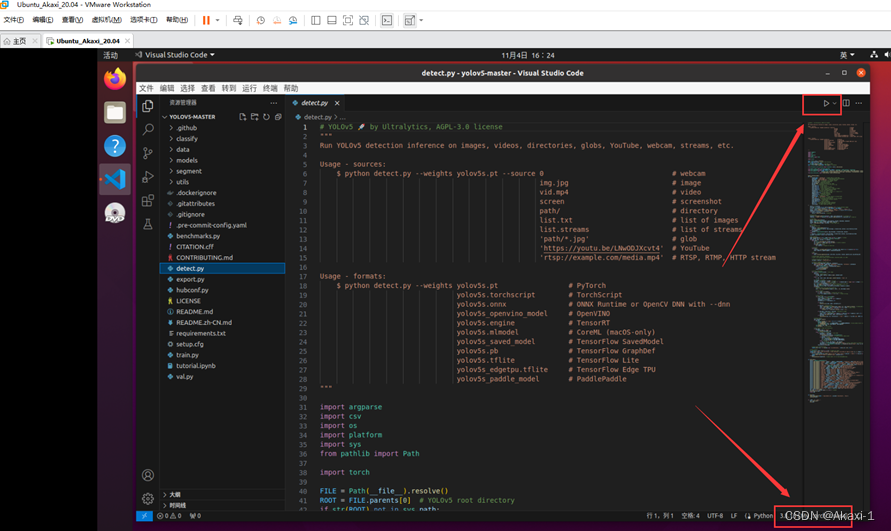
这里出现了一些问题,具体在第五节进行了详细描述。问题解决后测试结果如下:


五、出现问题
1. 没有 SPPF 模块
- 问题描述:
AttributeError: Can't get attribute 'SPPF' on <module 'models.common' from '/.../yolov5-5.0/models/common.py'>
问题原因就是在 models 文件夹下的 common.py 文件中没有找到 SPPF 模块。因为这里我下载的是 yolov5-v5.0 版本,而训练好的模型则下载的 7.0 版本,运行环境与模型版本不一致。
-
参考链接:
link1
link2
link3 -
解决方案
这里有两种解决方案,一种是将新版本 common.py 中的 SPPF 类复制过来,二是重新下载合适版本的训练模型。这里我选择第二种方法。
更改utils/google_utils文件的内容:
response = requests.get(f'https://api.github.com/repos/{repo}/releases/latest').json() # github api
我这里是在第 25 行,可以看到现在下载的就是最新的模型。将他改为如下形式:
response = requests.get(f'https://api.github.com/repos/{repo}/releases/tags/v5.0').json() # github api
我更改了以后还是无法成功下载,最终我是手动下载的,下载地址。
2. 显卡算力与 CUDA 不匹配
- 问题描述
UserWarning:
NVIDIA GeForce RTX 4090 with CUDA capability sm_89 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37.
If you want to use the NVIDIA GeForce RTX 4090 GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
也就是说我当前显卡的算力为 89,但是我安装的 pytorch 不支持这个算力,所以需要安装对应的版本。
-
参考链接
link1 -
解决方案
(1)查看显卡算力CUDA GPUs - Compute Capability | NVIDIA Developer
4090对应8.9。
(2)查看算力对应的cuda版本
NVIDIA Datacenter Drivers :: NVIDIA Data Center GPU Driver Documentation
对应 8.9 的是 cuda11.8,只能高不能低。
(3)卸载 CUDA10.2
参考链接
这里我采用的是第一种方法,直接进入
/usr/local/cuda-10.2/bin文件夹,打开终端,输入命令:
sudo ./cuda-uninstaller
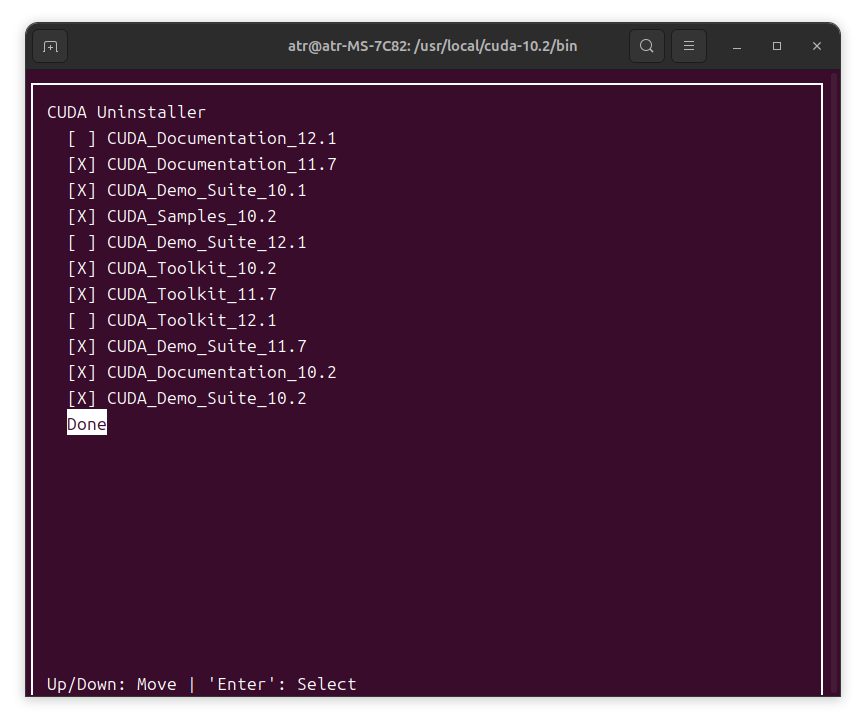
这里我是把除了 12.1 版本以外的都选中删除了。
(4)卸载 pytorch
参考链接
在终端输入以下命令:
conda remove pytorch torchvision torchaudio
(5)重装 CUDA+cudnn+pytorch
1)首先安装 CUDA11.8
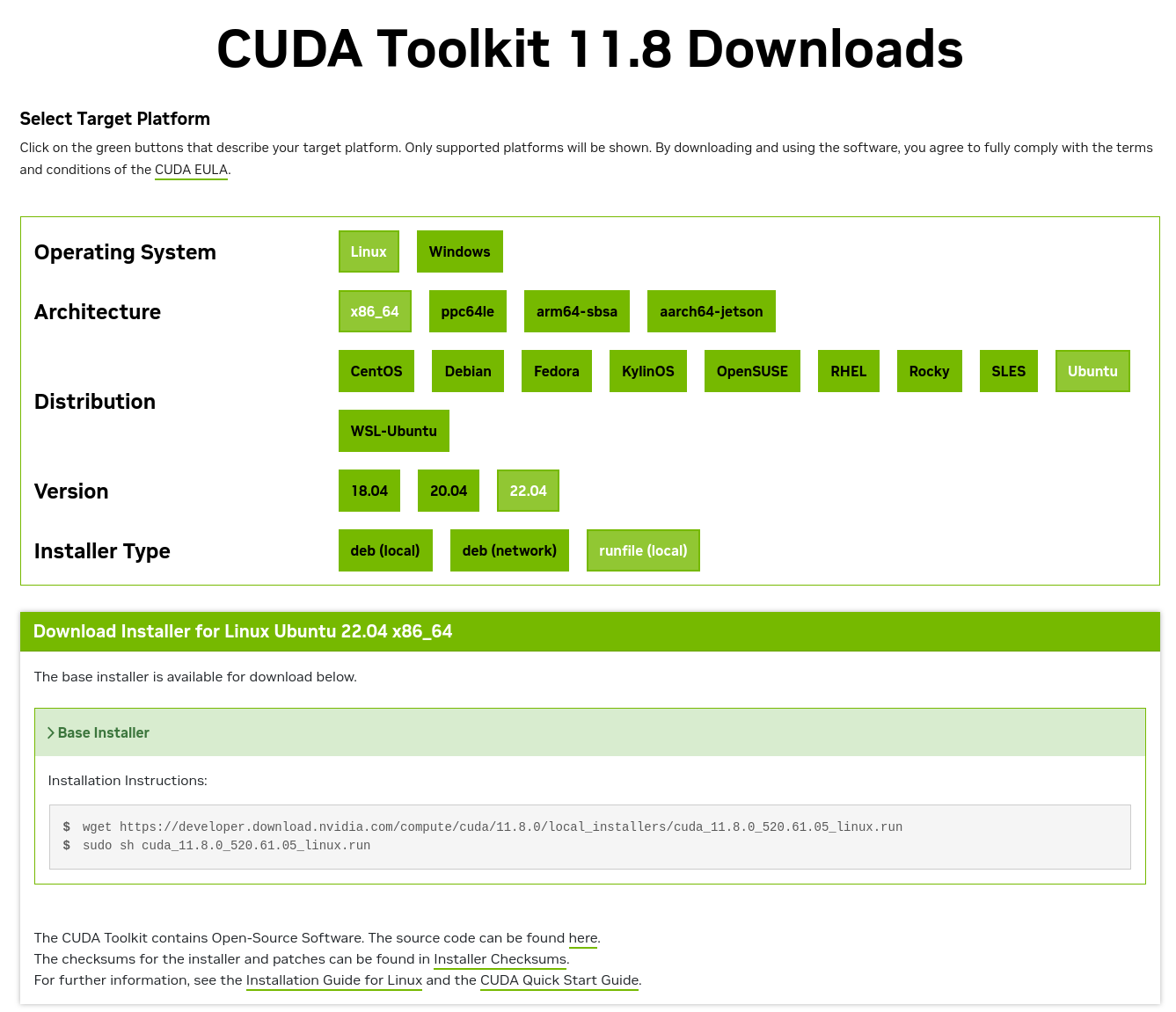
输入第一行指令时出现如下问题:
无法写入 ‘cuda_11.8.0_520.61.05_linux.run’ (成功)。
我重启了一下电脑好了。
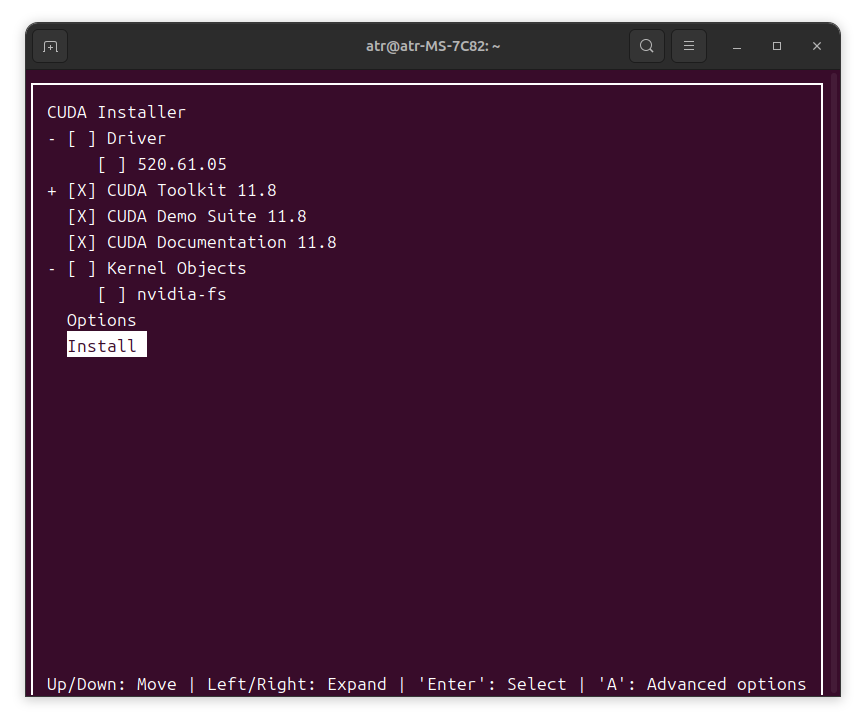
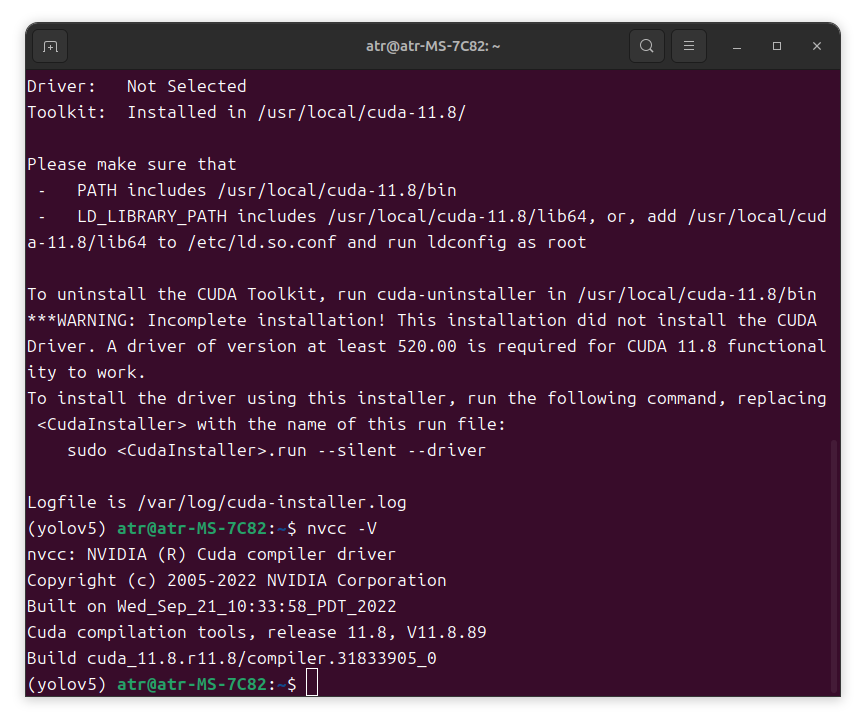
创建新的软链接
cd /usr/local
sudo rm -r cuda
sudo ln -s cuda-11.8 cuda
输入nvcc -V查看是否安装成功:
2)安装 cudnn
这里我选择8.9.7。解压后进入文件夹,并在文件夹中打开终端,执行以下命令:
sudo cp include/cudnn.h /usr/local/cuda/include
sudo cp lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
测试是否安装成功:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
3)安装 torch
- 打开官网
- 选择合适的版本
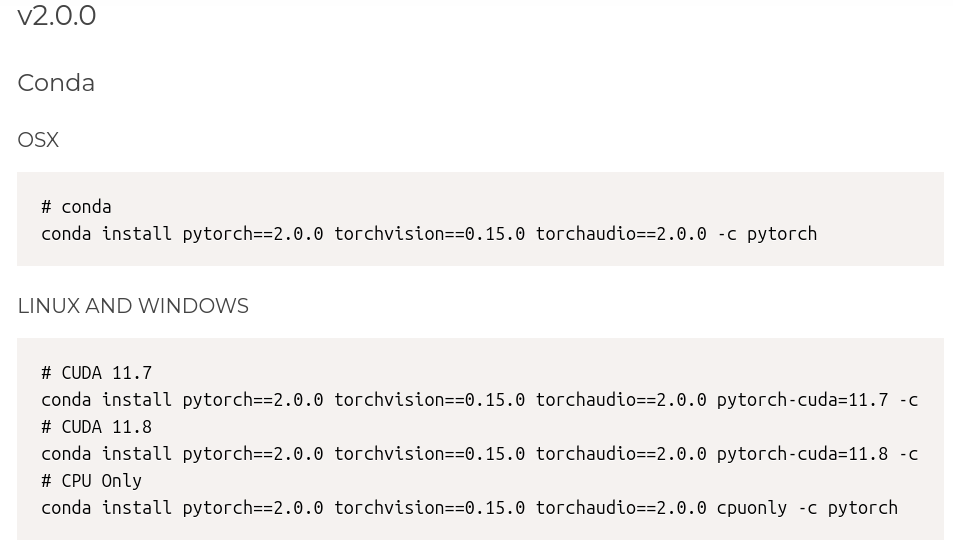
pytorch 与 python 对应版本关系
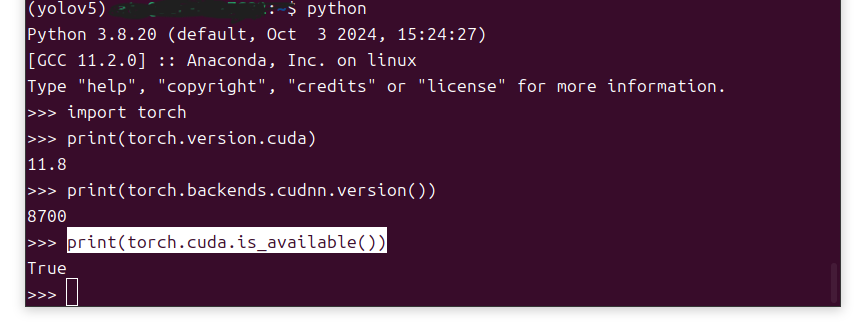
验证是否安装成功:
pythonimport torch
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.is_available())
3. charset-normalizer 库不匹配
- 问题描述:
AttributeError: partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)
- 参考链接
link1
link2 - 解决方案
我的 charset-normalizer 已经是 3.3.10 版本,应该不是版本过低导致的。这里我还是选择安装 3.1.0 版本。在终端输入以下内容:
pip install --force-reinstall charset-normalizer==3.1.0
问题解决。
4. undefined symbol: nvrtcGetCUBIN
- 问题描述
Could not load library libcudnn_cnn_infer.so.8. Error: /.../yolov5/lib/python3.8/site-packages/torch/lib/../../../../libnvrtc.so: undefined symbol: nvrtcGetCUBIN
已中止 (核心已转储)
- 参考链接
link1
link2
link3 - 解决方案
我在搜索解决方案的过程中发现,大家的错误后面几乎都是无法加载或找不到 libnvrtc.so,而我显示的却是有未定义的符号 nvrtcGetCUBIN。我这里确实也没有 libnvrtc.so 文件,因此我按照 link2 的方法创建了一个软链接,然而运行后问题依然存在。然后我猜想可能是 CUDA 与 cudnn 版本不匹配造成的?结果发现我的 cudnn 似乎根本没有安装成功。
在命令行输入conda list,输出:
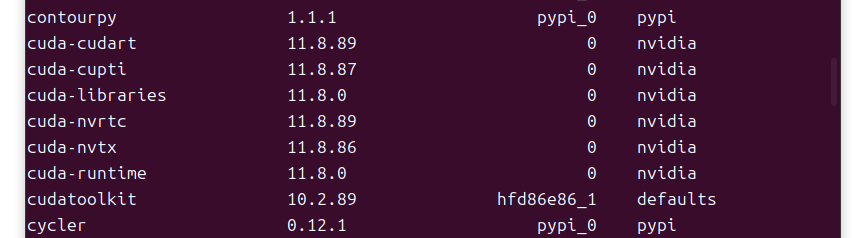
没有 cudnn,而且 cudatoolkit 版本也不对,还是 10.2 的版本。所以首先需要安装正确版本的 cudatoolkit。这里我运行命令conda uninstall cudatoolkit失败了,没有成功卸载 cudatoolkit。于是我先卸载了 CUDA,再执行conda uninstall cudatoolkit,卸载成功。之后又重新安装了 CUDA11.8。
接下来是继续安装 cudnn。在命令行中输入dpkg -l | grep cudnn:

然后发现我只有一个 9.3.0 版本的 cudnn。在网上搜索了一下,感觉 cudnn 的安装过程应该是没问题的,可能是有些地方没有配置成功。然后我看到了 link3。在 link3 中博主输入了一个命令sudo ldconfig用来更新库链接,这一步我没执行过,所以我也执行了一下,然后就报了错:

然后我按照博主的方法创建了符号链接,并对 cudnn 进行了验证:
# 检查目标库是否存在
ls /usr/local/cuda-11.8/lib64/libcudnn_cnn_infer.so.8*# 查看cuDNN版本
cat /usr/local/cuda-11.8/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
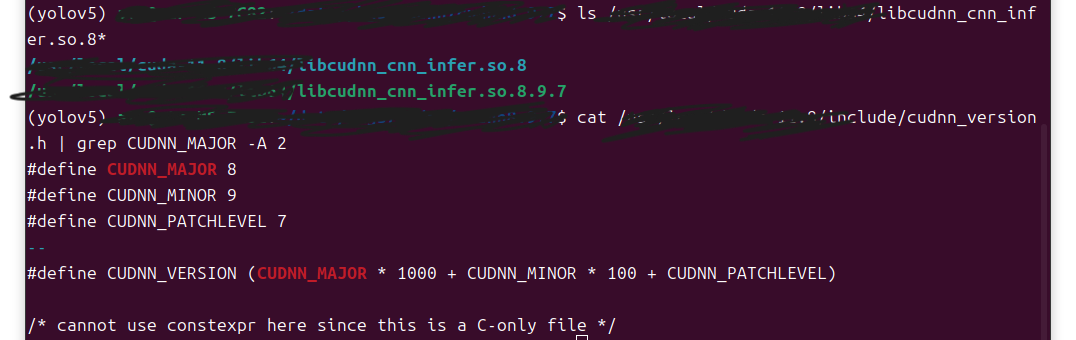
成功。
5. 未找到 recompute_scale_factor 属性
- 问题描述
AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
- 参考链接
link1
link2 - 解决方案
找到 upsampling.py 文件的 forward 函数,如下:
def forward(self, input: Tensor) -> Tensor:return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners,recompute_scale_factor=self.recompute_scale_factor)
注释掉,改为如下形式:
def forward(self, input: Tensor) -> Tensor:return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)