Linux 软件编程(十一)网络编程:TCP 机制与 HTTP 协议
五、TCP 进阶机制
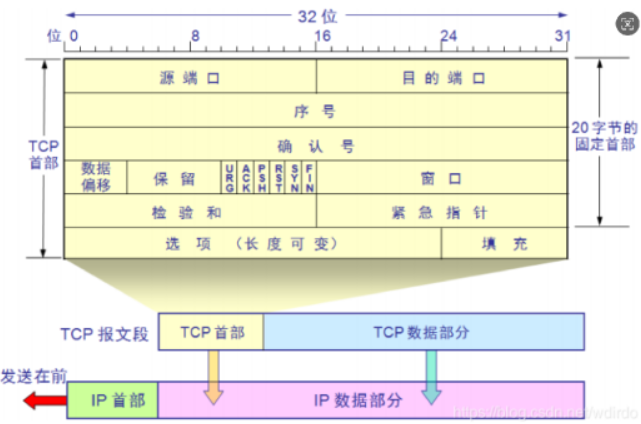
(一)TCP 头部标志位
TCP 头部的标志位是控制通信行为的 “开关”,常用标志位功能:
| 标志位 | 含义 | 典型场景 |
|---|---|---|
| SYN | 请求建立连接 | 三次握手第一步,发起连接请求 |
| ACK | 响应报文确认 | 回复对方,确认已收到数据 |
| PSH | 携带数据通知 | 告诉接收方 “立即从缓冲区取数据”,避免延迟 |
| FIN | 请求断开连接 | 四次挥手第一步,发起断开请求 |
| RST | 复位连接 | 强制重置异常连接(如网络拥塞时) |
| URG | 紧急数据标识 | 标记 “紧急数据”,需优先处理 |
(二)TCP 安全可靠传输机制
1. 三次握手 & 四次挥手
- 三次握手:通过
SYN/SYN+ACK/ACK三次交互,确认双方收发能力,为可靠通信奠基。 - 四次挥手:因服务端可能残留未发数据,需拆分
FIN/ACK/FIN/ACK四步,保证数据发完再断开。
2. 应答机制
TCP 采用 **“序列号 + 确认号”** 实现可靠应答:
- 发送方用 ** 序列号(Sequence Number)** 标记数据段的 “起始编号”;
- 接收方回复确认号(Acknowledgment Number),值为 “收到的最后一个字节编号 + 1”,告诉发送方 “已收到到这里,下一个该发啥”。
示例:发送方发 [0-999] 数据,序列号为 0;接收方回复确认号 1000,表示 “0-999 已收到,继续发 1000 开头的数据”。
3. 超时重传机制
发送方数据发出后,若超时未收到确认号,则认为数据丢失,触发重传。类似 “快递没收到,重新发货”,保障数据不丢包。
4. 滑动窗口机制
TCP 用滑动窗口管理发送与确认:
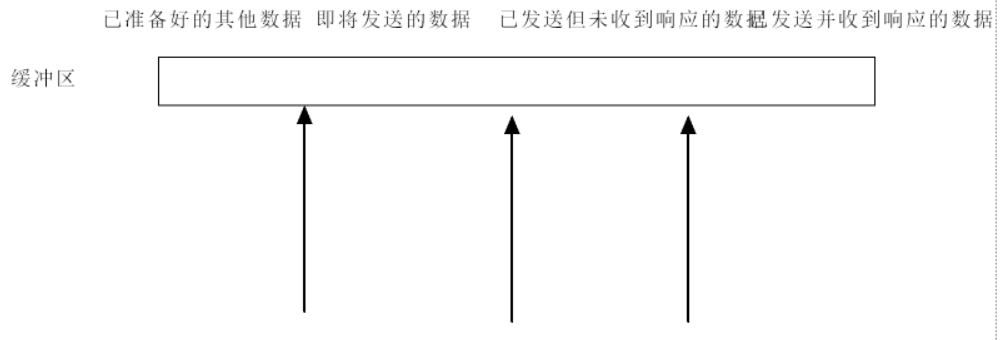
- 窗口内是 “已发送但未确认 + 待发送” 的数据;
- 收到确认号后,窗口 “滑动”,释放已确认数据的缓冲区,继续发送新数据。
( 理解:已发送并确认、已发送未确认、即将发送、准备好的数据,随窗口滑动动态变化 )
(三)TCP 效率优化机制
1. 延迟应答机制
发送数据的同时,接收方不立即回复 ACK,而是等待一段时间(攒一批数据再回复),减少 ACK 报文数量,降低网络开销。
2. 流量控制机制
通过 TCP 头部 **“窗口大小(Window Size)”(滑动窗口)** 字段实现:
- 接收方根据自身缓冲区剩余空间,动态调整 “窗口大小”;
- 发送方依据窗口大小控制发送速率,避免接收方缓冲区溢出。
3. 捎带应答机制
ACK 报文有时候不单独发送,而是 “附着” 在应用层数据里一起发(类似于变为三次挥手),减少单独发 ACK 的次数,提升效率。
六、HTTP 协议
(一)万维网通信基础
- WWW(万维网):由网页、服务器、客户端(浏览器)组成的信息系统,通过 URL 定位资源。
- URL(统一资源定位符):格式
<协议>://<主机>:<端口>/<路径>,示例:https://www.baidu.com/s?wd=关键词,精准定位网络资源。 - HTTP(超文本传输协议):应用层协议,基于 TCP 传输,默认端口
80/8080,负责客户端与服务器的请求 - 响应交互。 - HTML(超文本标记语言):浏览器解析后展示网页内容的语言,HTTP 响应报文里的 “实体主体” 常包含 HTML 代码。
(二)HTTP 通信流程
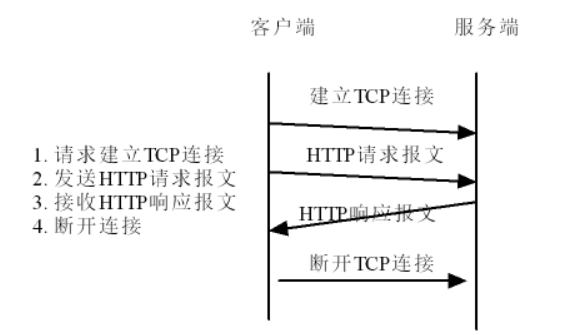
- 建立 TCP 连接:客户端与服务器通过 TCP 三次握手建立连接(如访问百度时,先建 TCP 连接 )。
- 发送 HTTP 请求报文:客户端向服务器发请求,包含 “请求方法(如 GET/POST)、URL、协议版本” 等(示例:
GET / HTTP/1.1表示用 GET 方法请求根路径资源 )。 - 接收 HTTP 响应报文:服务器处理请求后,回复包含 “状态码、响应头、实体主体(如 HTML 内容)” 的报文(示例:
HTTP/1.1 200 OK表示请求成功 )。 - 断开 TCP 连接:默认短连接(
Connection: close)直接断开;长连接(Connection: keep-alive)会保持连接一段时间,复用传输其他资源。
(三)HTTP 报文格式
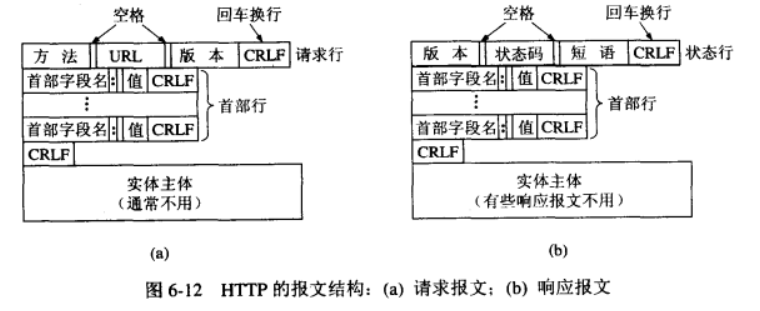
1. 请求报文结构(以 GET 为例)
请求行:方法 URL 版本 CRLF (如:GET /index.html HTTP/1.1\r\n)
首部行:字段名: 值 CRLF (如:Host: www.baidu.com\r\n)
...(更多首部行)
空行:CRLF
实体主体:(GET 通常无实体主体,POST 可带数据)
2. 响应报文结构
状态行:版本 状态码 短语 CRLF (如:HTTP/1.1 200 OK\r\n)
首部行:字段名: 值 CRLF (如:Content-Type: text/html\r\n)
...(更多首部行)
空行:CRLF
实体主体:(如 HTML 代码、文件内容等)
3. 状态码分类
| 状态码分类 | 含义 | 典型码值 | 场景 |
|---|---|---|---|
| 1xx | 通知信息 | 100 | 表示 “继续”,常为中间响应 |
| 2xx | 成功 | 200 | 请求成功,服务器正常返回数据 |
| 3xx | 重定向 | 302 | 请求的资源 “搬家了”,需重新定向 |
| 4xx | 客户端错误 | 404 | 资源不存在;400 表示请求语法错 |
| 5xx | 服务器错误 | 500 | 服务器内部故障;502 表示网关错误 |
(四)HTTP 请求方法
HTTP 定义了多种请求方法,控制对资源的操作:
| 方法 | 含义 | 典型场景 |
|---|---|---|
| OPTION | 查询选项 | 探知服务器支持的方法 |
| GET(常见) | 请求资源 | 浏览网页、获取图片等(参数放 URL 里) |
| HEAD | 请求资源头部 | 只获取响应头,不下载实体主体 |
| POST(常见) | 提交数据 | 登录、上传文件(参数放请求体) |
| PUT | 上传文档 | 在指定 URL 存储文档(需权限) |
| DELETE | 删除资源 | 删除指定 URL 对应的资源(需权限) |
| TRACE | 环回测试 | 调试用,查看请求的传输路径 |
| CONNECT | 代理连接 | 用于代理服务器,建立隧道 |
(五)爬虫
爬虫(Web Crawler) 是一种自动化程序,模拟浏览器的 HTTP 请求 - 响应流程,批量抓取网络资源:
工作逻辑:
- 构造 HTTP 请求(模仿浏览器发 GET/POST),获取网页 HTML;
- 解析 HTML 提取链接、数据;
- 递归抓取新链接,形成 “自动浏览 - 采集” 的流程。
总结
- TCP 核心:通过 “三次握手建连接、四次挥手断连接、序列号 + 确认号应答、滑动窗口控速率”,实现可靠且高效的传输。
- HTTP 核心:基于 TCP 传输,用请求 - 响应模式交互,通过 URL 定位资源,用状态码反馈结果,是万维网的 “通信语言”。
- 爬虫本质:自动化的 HTTP 请求 - 解析工具。