数据挖掘5.3 PCA主成分分析降维
PCA降维
- 降维 Dimensionality Reduction
- PCA
- 投影值怎么计算
- 如何实现:朴素方法 (Naïve Implementation)
- 具体计算推导
- 1 PCA投影方差计算——max wTCww^T C wwTCw,C协方差矩阵
- 2 max wTCww^T C wwTCw——求解主成分方向 www
- 拉格朗日乘子法 (Lagrange Multipliers)
- PCA 在降维中的应用
- 方差贡献率 (Proportion of Variance, PoV)
- 如何选择 kkk
- PCA:重建与重建误差 (Reconstruction & Error)
- 1. PCA 投影
- 2. PCA 重建
- 3. 重建误差
- 4. 含义
- PCA的缺陷
- 在图像中的应用
- PCA的愚蠢
Principal Component Analysis (PCA) 主成分分析
降维 Dimensionality Reduction
矩阵 XXX 的维度为:
X∈RN×dX \in \mathbb{R}^{N \times d} X∈RN×d
NNN :样本数量 (number of samples)
ddd :特征维度 (number of features)
降维后,ddd会变小。
比如,[10,1]降维后变成[10],直接删除一个维度,是最简单直接的降维方式(当然会有很多问题)。
PCA
PCA 是投影,本质是降维。PCA是实现这一点的方法,一种数据变换的方法 (A method for transforming the data)
将数据投影到一组正交向量上,使得投影后数据的方差最大。

在方向 www 上的投影公式:
z=wTxz = w^T x z=wTx
目标是找到使投影方差最大的方向www:
maxwVar(z)\max_w Var(z) wmaxVar(z)
PCA降维,投影到一个单位向量方向,各个数据点方差最大,这是第一主成分。与第一主成分的正交(垂直)的方向单位向量,是第二主成分。

投影值怎么计算
举个栗子
a1=[23]a_1 = \begin{bmatrix} 2 \\ 3 \end{bmatrix} a1=[23]
我们想要把它投影到 xxx 轴,于是点乘 w=[10]w = \begin{bmatrix} 1 \\ 0 \end{bmatrix}w=[10],
wTa1=[10][23]=[2]w^T a_1 = \begin{bmatrix} 1 & 0 \end{bmatrix} \begin{bmatrix} 2 \\ 3 \end{bmatrix} =[ 2 ] wTa1=[10][23]=[2]
如果我们想要把它投影到 yyy 轴,于是点乘 w=[01]w = \begin{bmatrix} 0 \\ 1 \end{bmatrix}w=[01],
wTa1=[01][23]=[3]w^T a_1 = \begin{bmatrix} 0 & 1 \end{bmatrix} \begin{bmatrix} 2 \\ 3 \end{bmatrix} =[ 3 ] wTa1=[01][23]=[3]
由此可见,如果想要把一个点投影到别的轴上,点乘这个轴的单位方向向量就可以了。
如何实现:朴素方法 (Naïve Implementation)
设置 p=0p = 0p=0
对 ppp 从 000 到 π\piπ 进行迭代(分步):

-
计算投影向量 (projection vector):
wp=[cos(p)sin(p)]w_p = \begin{bmatrix} \cos(p) \\ \sin(p) \end{bmatrix} wp=[cos(p)sin(p)] -
将数据投影到该方向:
zi=wpTxiz_i = w_p^T x_i zi=wpTxi -
计算投影后数据的方差 (variance)。
-
绘制方差随 ppp 变化的曲线。

-
找到使方差最大的 ppp。
主成分分析 (PCA) 的直观实现:
通过不同角度 $p$ 的方向向量 $w_p$ 投影数据;
计算投影后的方差;
找到方差最大的方向,这个方向就是 **第一主成分**。
具体计算推导
1 PCA投影方差计算——max wTCww^T C wwTCw,C协方差矩阵
投影方差最大——> max wTCww^T C wwTCw,C是协方差矩阵,以下是推导过程,
主成分分析 (PCA):投影方差与协方差矩阵的关系
定义数据在方向 www 上的投影:
z=wTxz = w^T x z=wTx
投影的方差:
Var(z)=Var(wTx)=E[(wTx−wTμ)2]Var(z) = Var(w^T x) = E\big[(w^T x - w^T \mu)^2\big] Var(z)=Var(wTx)=E[(wTx−wTμ)2]
展开:
=E[(wT(x−μ))(wT(x−μ))]=E[wT(x−μ)(x−μ)Tw]= E\big[(w^T(x - \mu))(w^T(x - \mu))\big]\\ = E\big[w^T(x - \mu)(x - \mu)^T w\big] =E[(wT(x−μ))(wT(x−μ))]=E[wT(x−μ)(x−μ)Tw]
提取常数 www:
=wTE[(x−μ)(x−μ)T]w= w^T E\big[(x - \mu)(x - \mu)^T\big] w =wTE[(x−μ)(x−μ)T]w
协方差矩阵公式:
Cov(x)=E[(x−μ)(x−μ)T]=CCov(x) = E[(x - \mu)(x - \mu)^T] = C Cov(x)=E[(x−μ)(x−μ)T]=C
最终推出:
Var(z)=wTCwVar(z) = w^T C w Var(z)=wTCw
数据在方向 www上的投影方差 =wTCw= w^T C w=wTCw,而 PCA 就是寻找让这个这个投影方差最大的方向 www。
2 max wTCww^T C wwTCw——求解主成分方向 www
目标,希望找到一个单位向量 www,使得投影后的方差最大:
maxwVar(z1)=wTCw\max_w Var(z_1) = w^T C w wmaxVar(z1)=wTCw
约束条件是 wTw=1w^T w = 1wTw=1
其中 CCC 是协方差矩阵。
拉格朗日乘子法 (Lagrange Multipliers)
将带约束的优化问题转化为拉格朗日函数(把带约束的优化问题转成无约束问题):
L(w,α)=wTCw−α(wTw−1)L(w, \alpha) = w^T C w - \alpha (w^T w - 1) L(w,α)=wTCw−α(wTw−1)
所求为 maxwTCwmax \quad w^T C wmaxwTCw,也就是 maxL(w,α)max\quad L(w, \alpha)maxL(w,α)。
对 www 求导
∂L∂w=2Cw−2αw=0\frac{\partial L}{\partial w} = 2 C w - 2 \alpha w = 0 ∂w∂L=2Cw−2αw=0
Cw=αwC w = \alpha w Cw=αw
- www 是协方差矩阵 CCC 的 特征向量
- α\alphaα 是对应的 特征值
使方差最大的方向,就是 **最大特征值对应的特征向量**
最终,我们所要求最大化投影方差,只要求协方差矩阵的特征向量就行了。
PCA 在降维中的应用
协方差矩阵中较小的特征值对应的方向对总方差贡献很小,可以舍弃而不会丢失太多信息。
我们通常保留累计贡献率达到 90% 的前 kkk 个特征值和特征向量。
方差贡献率 (Proportion of Variance, PoV)
Proportion of Variance Explained (累计方差贡献率曲线)

横轴 (Eigenvectors):主成分个数 kkk
纵轴 (Prop of Var):累计方差贡献率(PoV)
曲线随 kkk 增大而上升,并逐渐接近 1。
在图中,当 k≈20 时,累计方差贡献率已经接近 90%,说明只需保留前 20 个主成分,就能保留大部分信息。
PoV(k)=λ1+λ2+⋯+λkλ1+λ2+⋯+λdPoV(k) = \frac{\lambda_1 + \lambda_2 + \cdots + \lambda_k}{\lambda_1 + \lambda_2 + \cdots + \lambda_d} PoV(k)=λ1+λ2+⋯+λdλ1+λ2+⋯+λk
其中:
- λi\lambda_iλi 为特征值,且按从大到小排序
- ddd 为原始数据的维度
- k<dk < dk<d 为选择保留的主成分数
如何选择 kkk
一般当 PoV>0.9PoV > 0.9PoV>0.9 时可以停止。
也可以通过 碎石图 (Scree Plot) 找“肘点 (elbow)”来确定 kkk。

Scree Graph (碎石图)
横轴 (Eigenvectors):特征向量的索引(对应主成分的序号)。
纵轴 (Eigenvalues):对应的特征值大小(代表方差贡献)。
数据投影:将 ddd 维数据 xxx (均值向量为 μ\muμ)投影到 kkk 维子空间,使用 k×dk \times dk×d 的投影矩阵 WWW
z=WT(x−μ)z = W^T (x - \mu) z=WT(x−μ)
其中:
- WWW 包含前 kkk 个特征向量
- zzz 是新的 kkk 维数据表示
PCA:重建与重建误差 (Reconstruction & Error)
1. PCA 投影
在 PCA 中,数据 xxx 被投影到低维空间:
z=WT(x−μ)z = W^T (x - \mu) z=WT(x−μ)
其中:
- xxx :原始 ddd 维数据向量
- μ\muμ :均值向量
- WWW :d×kd \times kd×k 的投影矩阵(由前 kkk 个特征向量组成)
- zzz :新的 kkk 维数据表示

2. PCA 重建
从低维表示 zzz 还原回高维近似数据:
x^=Wz+μ\hat{x} = W z + \mu x^=Wz+μ
因为 WWW 的列向量是正交的,有 WWT=IWW^T = IWWT=I。
3. 重建误差
定义为原始数据 xxx 与重建数据 x^\hat{x}x^ 的差异:
Erec=∑t=1N∥x^t−xt∥E_{rec} = \sum_{t=1}^N \| \hat{x}^t - x^t \| Erec=t=1∑N∥x^t−xt∥
其中:
- NNN :样本总数
- x^t\hat{x}^tx^t :第 ttt 个样本的重建结果
- xtx^txt :第 ttt 个原始样本
4. 含义
- 重建误差越小,说明保留的主成分越能代表原始数据。
- 当 k=dk=dk=d 时(即不降维),重建误差为 0。
- 当 k<dk<dk<d 时,误差取决于被舍弃的特征值大小。
PCA的缺陷
在图像中的应用
在不影响预测准确率的情况下,第一个主成分可能并不总是最佳主成分。
PCA的愚蠢
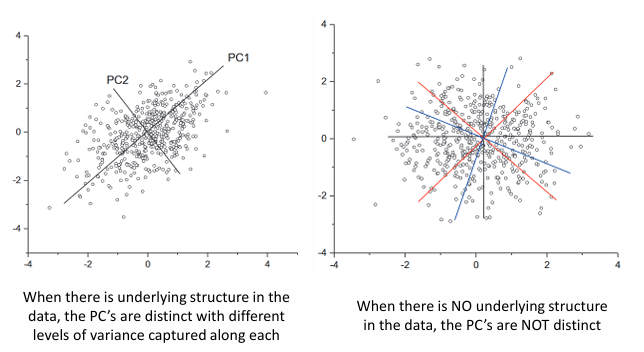
PCA是一种愚蠢的算法,它在代码中实现,你给它数据,它就会输出主成分。尽管有些数据被我们解释为最大方差的方向,但事实可能并不是,比如右图。这取决于数据集的选择。如果数据集类似左边,它可以给出一些最大方差的方向。但如果像右边这样,那就完全没有意义。