数据采集怎么做?质量、效率与合规该怎么平衡?
目录
一、数据采集不是简单 “搬数据”,是为了解决问题
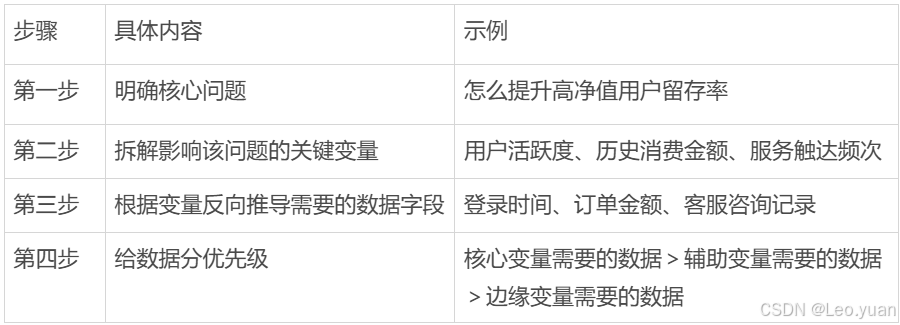
关键动作 1:用 “业务目标拆解法” 圈定该采哪些数据
关键动作 2:用 “全链路思维” 避免后面返工
二、数据质量要提前做好把控
1.判断数据质量的三个维度
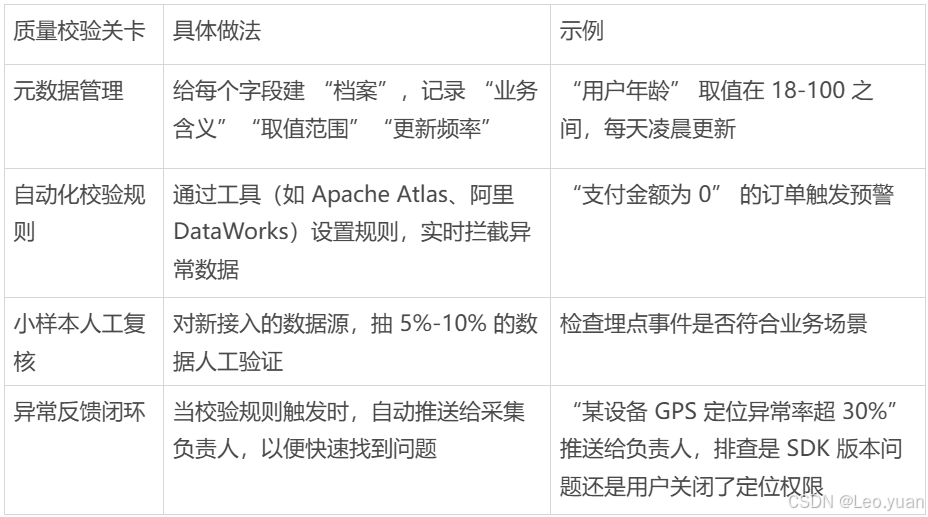
2.实操方法:把质量控制放进采集流程里
三、数据采集效率可以多层提升
1.工具层面:用自动化代替手动操作
2.架构层面:分清哪些要实时采,哪些可以离线采
3.流程层面:建立 “采集 - 验收 - 迭代” 的闭环
四、数据合规问题要提前设计规避
1.第一道防线:守住法律底线
2.第二道防线:用技术手段保障
3.第三道防线:设计合规的流程
五、根据业务阶段调整,建立动态反馈机制
1.根据业务阶段定优先级
2.建立动态反馈机制
结语
数据采集做不好?质量、效率、合规,总有一个在拖后腿!
数据采集是数据工作的起点,打不好这个基础,后面的分析、模型甚至业务决策都可能“跑偏”。
但现实中,很多人常常陷入这样的困境:
- 想抓高质量数据?流程繁琐,项目进度慢!
- 想提升效率快点儿拿到数据?又怕踩了合规的雷区,引来监管麻烦!
- 想三全其美?却发现无从下手,顾此失彼...
别担心,今天我们就来拆解这个难题!不讲虚的,从底层逻辑到实操方法,手把手教你如何在数据采集中巧妙平衡质量、效率与合规这三大难题,让数据链路的起点高质、高效又合规。
一、数据采集不是简单 “搬数据”,是为了解决问题
很多团队做数据采集时会陷入一个误区:
把「采集」等同于「搬运」—— 先把能拿到的数据全拿过来,再考虑怎么用。
但数据采集的本质是业务问题的翻译过程:
你需要先明确「解决什么问题」,再倒推「需要什么数据」,最后设计「如何采集」。
就拿连锁超市优化选品来说:
他们需要用户购买偏好数据。如果直接采集所有用户的购物小票,包含姓名、电话、商品明细等,虽然数据量大,但 90% 的信息是冗余的,比如用户手机号对选品无直接价值。
更高效的方式是:
通过会员系统关联用户 ID 与购物篮数据,重点采集高频购买时段、跨品类组合购买频次、价格敏感度等核心字段。
关键动作 1:用 “业务目标拆解法” 圈定该采哪些数据
关键动作 2:用 “全链路思维” 避免后面返工
数据采集不是孤立的环节,得考虑上下游能不能适配。
比如:
- 如果后面要做实时分析,采集的时候就得设计毫秒级的事件触发机制;
- 如果数据要放进机器学习模型里,采集时就得统一字段格式;
- 如果涉及跨系统对接(比如 ERP 和 CRM),得提前确认双方的数据字典。
二、数据质量要提前做好把控
数据质量问题年年提,但很多团队还是会踩坑:
- 空值率超标
- 字段含义模糊
- 时间戳错位
用过来人的经验告诉你,这些问题的根源,往往是 “重采集、轻校验”。
1.判断数据质量的三个维度
判断数据质量,不能只看 “有没有”,还得看 “准不准”“稳不稳”。
具体来说:
- 完整性:关键字段不能少;
- 准确性:数据得和实际业务对得上;
- 一致性:同一个指标在不同系统、不同时间的定义得统一;
- 时效性:数据得在约定时间内能用。
2.实操方法:把质量控制放进采集流程里
很多团队习惯 “先采集、再清洗”,但这样会导致:
- 无效数据占用存储资源,比如重复的用户行为日志;
- 错误数据被下游使用,比如错误的用户年龄导致精准营销没效果;
- 返工成本高,清洗数据可能需要花费大量时间。
更高效的方式是在采集环节就设置 “质量校验关卡”:
三、数据采集效率可以多层提升
数据采集效率低,常常是因为 “重复劳动多”“太依赖人工”“响应慢”。要提升效率,得从工具、架构、流程三个层面优化:
1.工具层面:用自动化代替手动操作
传统的数据采集靠 ETL 脚本,比如用 Python 写爬虫、用 SQL 写增量抽取。
但问题是:
当数据源增加到几十个(APP 埋点、CRM、第三方 API 等),维护这些脚本会花很多人力。
更重要的是:
当多个实时任务、管道任务对同一个数据库的不同表进行实时同步时,会重复解析数据库的日志,导致数据库压力过大。
特别是在实时任务场景下:
不同表会在不同实时任务中处理,就很容易导致日志被解析多次。
这时可以:
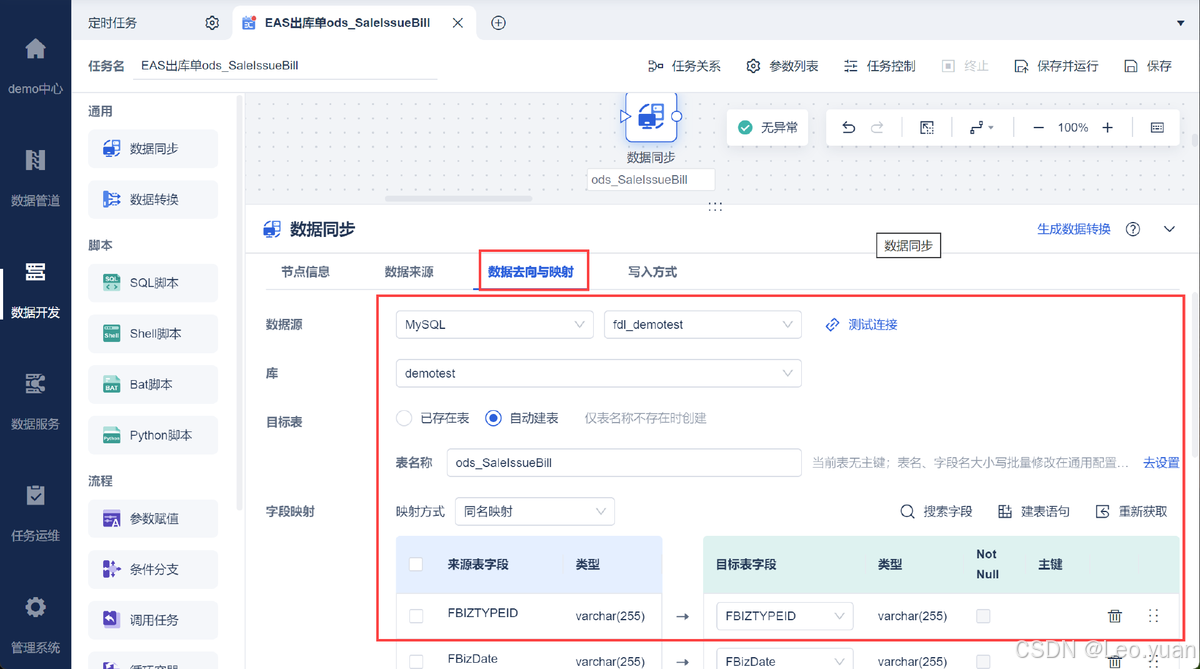
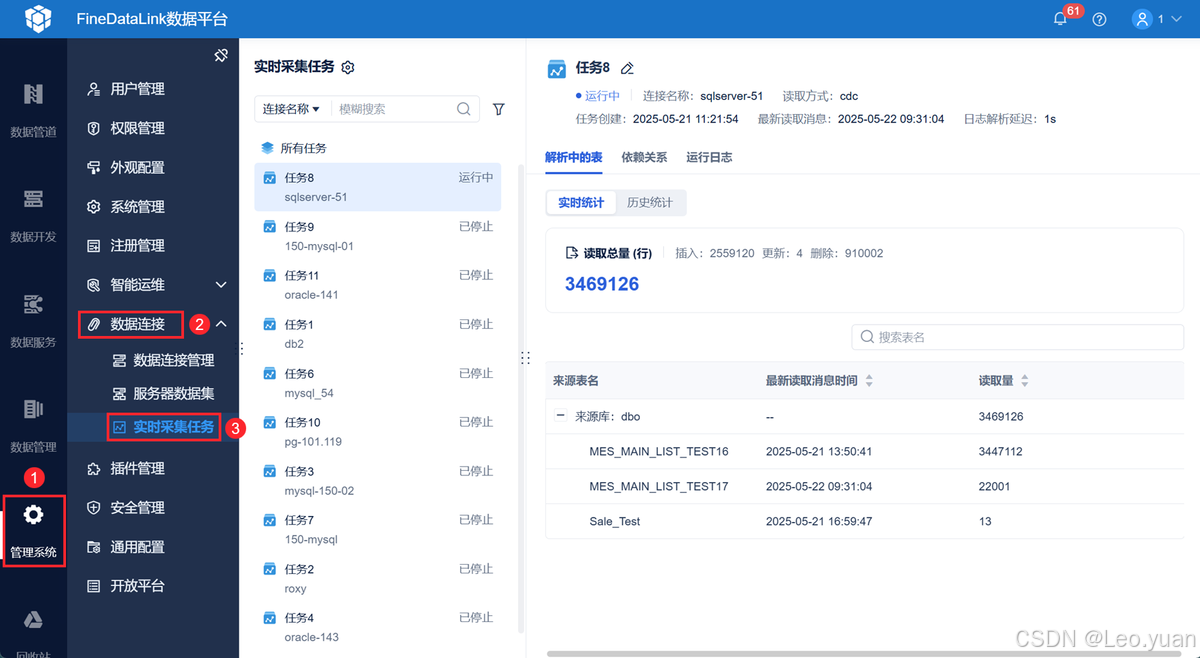
在数据集成平台FineDataLink中创建管道或者实时任务,在「管理系统>数据连接>实时采集任务」中自动新增实时采集任务,不需要手动新增,就能对数据库日志解析进行管理,存储日志解析产生的变更数据,实时任务/管道任务能够消费实时采集任务的数据。
立即体验FineDataLink:免费激活FDL(复制到浏览器打开)
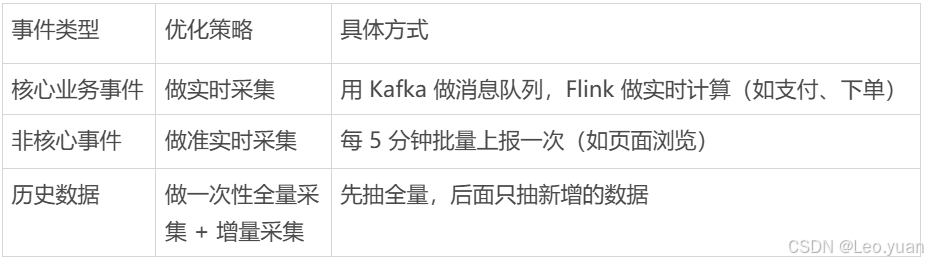
2.架构层面:分清哪些要实时采,哪些可以离线采
很多团队为了 “保险”,对所有数据都做实时采集,但实际上:
- 实时采集需要高并发处理能力,可能达到 10 万 + QPS,成本高还容易出错;
- 离线采集对时效性要求低,可以批量抽取,比如 T+1 抽取前一天数据。
优化策略是:
3.流程层面:建立 “采集 - 验收 - 迭代” 的闭环
很多团队采集完数据就不管了,丢给下游,结果问题反复出现。
正确的流程应该是:
- 需求确认:采集前和业务方说清楚 “数据用途”“字段定义”“质量标准”,比如 “用户手机号” 必须脱敏成 “1381234”;
- 试点验证:先接入 10% 的数据量,看看采集准不准,比如检查埋点事件是不是覆盖了所有用户路径;
- 正式上线:通过验收后全量采集,同时输出《数据字典》和《质量报告》;
- 迭代优化:定期收集下游反馈,调整采集规则,比如修复 SDK 的埋点漏洞。
四、数据合规问题要提前设计规避
数据合规的重要性不用多说 —— 从 GDPR 到《个人信息保护法》,从 “数据跨境传输” 到 “算法歧视”,监管越来越严。
但很多团队把合规当 “事后补丁”,直到被约谈或罚款才当回事。
下面是数据合规的三道防线:
1.第一道防线:守住法律底线
必须遵守的核心法规:
- 《个人信息保护法》:明确 “最小必要原则”(只采集和业务直接相关的数据)、“告知 - 同意原则”(采集前告诉用户用途,获得明确同意);
- 《数据安全法》:对敏感数据(比如金融账户、健康信息)做分级保护(加密存储、限制访问权限);
- 行业规范:比如金融行业的《个人金融信息保护技术规范》、医疗行业的《个人信息去标识化指南》。
2.第二道防线:用技术手段保障
- 匿名化处理:对不需要识别个人身份的数据,去掉 “可识别性”;
- 隐私计算:在需要跨机构联合建模时,用联邦学习、多方安全计算等技术,做到 “数据可用不可见”;
- 权限控制:通过 RBAC(角色权限控制)限制数据访问,比如分析师只能看脱敏后的数据,工程师不能导出原始数据。
3.第三道防线:设计合规的流程
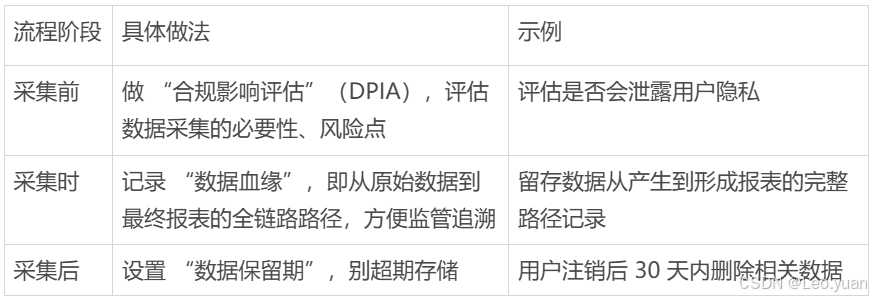
注意点:
很多人觉得 “合规会拖慢采集效率”,但实际上,合规设计能减少后期整改成本。
五、根据业务阶段调整,建立动态反馈机制
质量、效率、合规不是对立的,而是可以根据业务阶段动态调整的。关键是建立 “优先级矩阵” 和 “动态反馈机制”。
1.根据业务阶段定优先级
- 初创期:业务快速迭代,需要快速验证需求。这时候优先级:效率>质量>合规,但法律底线得守住,比如不采集敏感信息;
- 成长期:业务规模扩大,数据量增加。这时候优先级:质量>效率>合规,需要建立标准化流程,避免数据混乱;
- 成熟期:业务稳定,需要挖掘数据价值。这时候优先级:合规>质量>效率,得满足更严格的监管要求,比如跨境数据传输的安全评估。
2.建立动态反馈机制
定期(比如每月)开 “数据采集复盘会”,用这些指标评估平衡效果:
- 质量指标:数据错误率、校验通过率;
- 效率指标:采集耗时、人工干预次数;
- 合规指标:违规事件数、用户授权通过率。
根据评估结果调整策略:
比如发现 “实时采集导致质量下降”,可以降低部分非核心事件的实时性要求;发现 “合规流程太繁琐影响效率”,可以优化授权模板,比如用勾选框代替让用户读长文本。
结语
数据采集不是 “一次性工程”,而是随着业务发展不断迭代的系统工程。
它需要你:
- 先想清楚 “为什么采”,再动手 “怎么采”;
- 把质量控制放进采集的每个环节,别等出了问题再救火;
- 用技术工具和流程设计提升效率,别总靠 “人海战术”;
- 把合规当成 “底层代码”,而不是 “附加任务”。
好的数据采集,是让业务方感觉不到它的存在 —— 因为数据总是 “刚好需要,刚好正确,刚好合规”。