【知识杂记】卡尔曼滤波相关知识高频问答
先贴一张KF的流程图
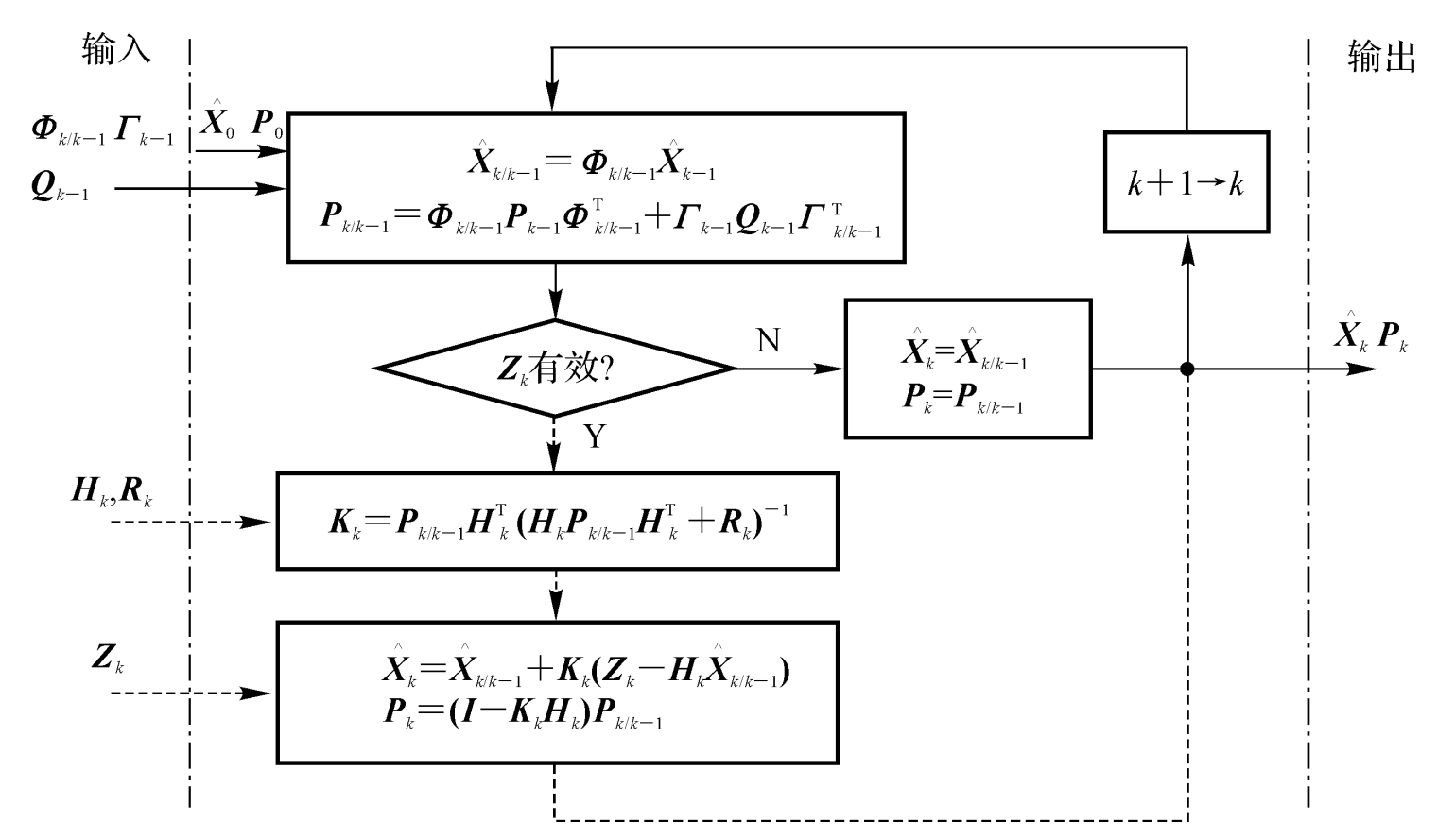
下面进入正题
一、卡尔曼滤波核心概念与原理
1. 卡尔曼滤波是什么?
核心回答:
卡尔曼滤波是一种高效的递归滤波器,用于从一系列不完整、含有噪声的测量中,估计动态系统的状态。它能在不确定性环境下,对系统的未来状态进行预测,并结合新的测量进行更新,从而得到一个比单独使用预测或测量都更精确的估计。
适当延伸:
你可以将卡尔曼滤波想象成一个聪明的侦探。这个侦探在追踪一个移动目标(比如一辆车)。它会根据目标之前的速度和方向(系统模型)来预测目标下一步的位置,但它知道这个预测可能不完全准确(预测不确定性)。同时,它也会通过望远镜(传感器)得到目标的新位置,但这个位置也可能存在一些测量误差。卡尔曼滤波就是这个侦探,它会综合考虑自己的预测和望远镜的观测,并根据它们各自的“可信度”(协方差)来权衡,最终得出一个比单独依赖任何一方都更准确的目标位置。
2. 卡尔曼滤波的核心思想是什么?为什么说它是“预测-更新”循环?
核心回答:
卡尔曼滤波的核心思想是融合,即利用当前时刻的系统模型和传感器测量,通过最小均方误差的准则,得到对系统状态的最优估计。
“预测-更新”循环是其算法流程的直观体现。预测(Predict) 阶段,根据上一时刻的状态估计,利用系统模型来预测当前时刻的状态及其不确定性(协方差)。更新(Update) 阶段,将预测值与当前时刻的传感器测量值进行融合,并根据两者的不确定性(协方差)来分配权重,从而得到一个更精确的估计值。这个过程周而复始,不断迭代。
适当延伸:
这个循环是卡尔曼滤波能够实时工作的关键。预测步骤基于物理模型,描述了系统随时间的变化;更新步骤则引入了新的观测信息,对预测进行修正。两者的有机结合使得滤波器能够实时地处理数据流,不断地改善其对系统状态的估计。
3. 为什么说卡尔曼滤波是“最优线性滤波器”?
核心回答:
在满足四个基本假设(线性系统、高斯白噪声、已知系统模型和噪声协方差)的前提下,卡尔曼滤波能够提供最小均方误差(Minimum Mean Square Error, MMSE) 意义下的最优估计。这里的“最优”指的是,在所有可能的线性估计方法中,卡尔曼滤波得到的估计值的均方误差是最小的。
适当延伸:
需要强调的是,“最优”是有前提的。如果系统模型是非线性的,或者噪声不满足高斯分布,那么卡尔曼滤波就不是最优的了。这也是后来发展出扩展卡尔曼滤波(EKF) 和无迹卡尔曼滤波(UKF) 的原因。
4. 卡尔曼增益的物理意义和作用是什么?
核心回答:
卡尔曼增益(Kalman Gain, KkK_kKk)是卡尔曼滤波中一个非常关键的参数,它的物理意义是预测误差与测量误差之间的权重分配系数。
其作用是,在更新步骤中,决定我们应该在多大程度上信任新的测量值。
适当延伸:
卡尔曼增益的计算公式为:
Kk=Pk−HkT(HkPk−HkT+Rk)−1K_k = P_k^- H_k^T (H_k P_k^- H_k^T + R_k)^{-1}Kk=Pk−HkT(HkPk−HkT+Rk)−1
从公式可以看出,卡尔曼增益的大小取决于预测协方差 Pk−P_k^-Pk− 和测量协方差 RkR_kRk 的相对大小。
- 如果预测协方差 Pk−P_k^-Pk− 很大(说明对预测值很不自信),而测量协方差 RkR_kRk 很小(说明测量很可靠),那么卡尔曼增益 KkK_kKk 就会很大,新的状态估计就会更倾向于新的测量值。
- 反之,如果预测协方差 Pk−P_k^-Pk− 很小(对预测值很自信),而测量协方差 RkR_kRk 很大(测量噪声大,不可靠),那么卡尔曼增益 KkK_kKk 就会很小,新的状态估计就会更倾向于之前的预测值。
简而言之,卡尔曼增益在预测值和测量值之间做了一个动态的、自适应的平衡。
5. 在卡尔曼滤波中,P、Q、R这三个关键矩阵的物理意义是什么?
核心回答:
这三个矩阵是卡尔曼滤波的“灵魂”,它们描述了系统中的不确定性。
- PPP (状态协方差矩阵): 描述状态估计的不确定性。它是一个对称矩阵,对角线上的元素是每个状态变量的方差,非对角线元素是不同状态变量之间的协方差。PPP 越大,表示我们对当前的状态估计越不确定。
- QQQ (过程噪声协方差矩阵): 描述系统模型的不确定性。它代表了系统在运动过程中,由于未建模的随机扰动(如风、未知的加速度变化等)引入的不确定性。QQQ 越大,表示我们认为系统模型越不可靠,预测的不确定性会增加得越快。
- RRR (测量噪声协方差矩阵): 描述传感器测量的不确定性。它代表了传感器自身的随机误差。RRR 越大,表示我们认为传感器的测量越不可靠。
适当延伸:
这三个矩阵的合理设定是卡尔曼滤波能否正常工作的关键。Q 和 R 矩阵通常需要根据实际经验或实验数据来确定,它们决定了预测和测量在融合时的相对权重。P 矩阵则会随着滤波器的运行而动态更新。
6. 卡尔曼滤波的预测和更新两个步骤的数学公式是什么?
核心回答:
卡尔曼滤波的数学公式分为两步,对应预测和更新。
预测(Prediction)阶段:
- 状态预测方程: x^k−=Fkx^k−1+Bkuk\hat{x}_k^- = F_k \hat{x}_{k-1} + B_k u_kx^k−=Fkx^k−1+Bkuk
- 协方差预测方程: Pk−=FkPk−1FkT+QkP_k^- = F_k P_{k-1} F_k^T + Q_kPk−=FkPk−1FkT+Qk
更新(Update)阶段:
3. 卡尔曼增益方程: Kk=Pk−HkT(HkPk−HkT+Rk)−1K_k = P_k^- H_k^T (H_k P_k^- H_k^T + R_k)^{-1}Kk=Pk−HkT(HkPk−HkT+Rk)−1
4. 状态更新方程: x^k=x^k−+Kk(zk−Hkx^k−)\hat{x}_k = \hat{x}_k^- + K_k(z_k - H_k \hat{x}_k^-)x^k=x^k−+Kk(zk−Hkx^k−)
5. 协方差更新方程: Pk=(I−KkHk)Pk−P_k = (I - K_k H_k)P_k^-Pk=(I−KkHk)Pk−
适当延伸:
这些公式共同构成了一个完整的递归过程。xkx_kxk 代表状态向量,FkF_kFk 是状态转移矩阵,uku_kuk 是控制输入,BkB_kBk 是控制输入矩阵,PkP_kPk 是协方差矩阵,QkQ_kQk 是过程噪声,zkz_kzk 是测量向量,HkH_kHk 是测量矩阵,RkR_kRk 是测量噪声。带负号的上标表示预测值,不带负号的表示更新后的估计值。
7. 在卡尔曼滤波中,为什么需要计算协方差矩阵的逆?
核心回答:
在卡尔曼增益的计算公式中,Kk=Pk−HkT(HkPk−HkT+Rk)−1K_k = P_k^- H_k^T (H_k P_k^- H_k^T + R_k)^{-1}Kk=Pk−HkT(HkPk−HkT+Rk)−1,需要对 (HkPk−HkT+Rk)(H_k P_k^- H_k^T + R_k)(HkPk−HkT+Rk) 这个矩阵求逆。这个矩阵代表了预测与测量融合后的不确定性,求逆是为了将其转换为卡尔曼增益,从而实现对预测误差和测量误差的相对加权。
适当延伸:
在实际应用中,如果该矩阵的维度很高,求逆操作的计算量会很大,且存在数值稳定性问题。当矩阵不可逆或接近奇异时,会造成滤波器发散。为此,实际编程中通常会使用矩阵分解(如Cholesky分解)或者伪逆等更鲁棒的数值方法来避免直接求逆。
8. 在预测步骤中,预测噪声协方差是变大还是变小?为什么?
核心回答:
在预测步骤中,预测噪声协方差总是变大。
根据公式 P_k^- = F_k P_{k-1} F_k^T + Q_k,预测协方差 Pk−P_k^-Pk− 是由上一时刻的协方差 Pk−1P_{k-1}Pk−1 经过状态转移 FkF_kFk 传递,并加上过程噪声 QkQ_kQk 得到的。
适当延伸:
这符合我们的直观理解:随着时间的推移,我们对系统状态的预测会变得越来越不确定。FkPk−1FkTF_k P_{k-1} F_k^TFkPk−1FkT 表示了上一时刻的不确定性如何传递到当前时刻,而 QkQ_kQk 则代表了系统演化本身带来的新的、不可预测的不确定性。两者相加,使得总的不确定性总是增加。
9. 在更新步骤中,估计噪声是变大还是变小?为什么?
核心回答:
在更新步骤中,估计噪声(协方差)总是变小。
根据公式Pk=(I−KkHk)Pk−P_k = (I - K_k H_k)P_k^-Pk=(I−KkHk)Pk−,新的协方差 PkP_kPk 是由预测协方差 Pk−P_k^-Pk− 减去一个正定矩阵得到的。
适当延伸:
这同样符合直观:通过引入新的、有价值的测量信息,我们对系统状态的了解增加了,因此不确定性理应减小。卡尔曼增益 KkK_kKk 的设计正是为了以最优的方式减少不确定性。当测量值被整合进来后,不确定性会从预测时的 Pk−P_k^-Pk− 减小到更新后的 PkP_kPk。
10. 卡尔曼滤波的算法基本假设有哪些?
核心回答:
卡尔曼滤波是建立在以下四个核心假设之上的:
- 线性系统: 系统的状态转移方程和测量方程都是线性的。
- 高斯白噪声: 系统过程噪声和测量噪声都是零均值的高斯白噪声。
- 已知系统模型: 状态转移矩阵 FFF 和测量矩阵 HHH 是已知的。
- 已知噪声协方差: 过程噪声协方差矩阵 QQQ 和测量噪声协方差矩阵 RRR 是已知的。
适当延伸:
这些假设是卡尔曼滤波能实现“最优”的理论基础。然而,在实际应用中,这些假设往往难以完全满足,这也是为什么会出现扩展卡尔曼滤波(EKF) 和无迹卡尔曼滤波(UKF) 等变体来处理非线性系统和非高斯噪声。
二、卡尔曼滤波实际应用与调参
11. 在实际应用中,如何调整Q和R这两个参数?它们对滤波结果有什么具体影响?
核心回答:
Q和R的调整是一个权衡(Trade-off) 的过程,需要根据实际应用和经验进行。一般原则是:
- 增大Q: 意味着更相信系统模型会偏离预测,更不相信之前的预测。这会让滤波器对新的测量值反应更快,响应更灵敏,但也会使得估计值更加震荡,更容易受到测量噪声的影响。
- 增大R: 意味着更不相信传感器测量,更相信系统预测。这会让滤波器对新的测量值反应更慢,估计值会更加平滑,但也会导致估计结果出现滞后,对真实状态变化不敏感。
适当延伸:
调整Q和R通常没有固定的公式,是一个**“试错”** 的过程,但有一些经验法则:
- 动态系统: 如果系统变化很快,比如无人机姿态控制,需要更大的Q来快速响应变化。
- 平稳系统: 如果系统变化很慢,比如室内定位,可以减小Q来获得更平滑的估计。
- 高精度传感器: 如果传感器本身精度高,R可以设小一些。
- 低精度传感器: 如果传感器精度低,R可以设大一些。
在实际中,可以根据残差($z_k - H_k \hat{x}_k^-) 的表现来调整参数。如果残差总是过大,可能需要增大Q或减小R。
12. 卡尔曼滤波对初始状态量和初始协方差矩阵P₀有什么要求?
核心回答:
- 初始状态量 x^0\hat{x}_0x^0: 最好设置为对系统初始状态的合理猜测值。如果猜测值与真实值相差很大,滤波器可能需要一段时间才能收敛,甚至可能发散。
- 初始协方差矩阵 P0P_0P0: 必须是半正定对称矩阵。对角线元素可以设置为一个较大的值,表示对初始状态的不确定性很大。随着滤波的进行,PPP 矩阵会逐渐收敛。如果 P0P_0P0 过小,表示对初始状态过于自信,可能导致滤波器发散。
适当延伸:
P0P_0P0 的设置可以看作是“谦虚”的程度。P0P_0P0 越大,表示滤波器认为初始状态估计越不可信,它会更积极地利用后续的测量来修正自身。在实际中,通常将 P0P_0P0 设置为一个较大的对角阵,比如对角线元素为100或1000。
13. 如何判断一个卡尔曼滤波器是否工作正常?
核心回答:
判断滤波器工作正常主要通过残差(创新)序列和协方差矩阵来观察:
- 残差序列($z_k - H_k \hat{x}_k^-): 如果滤波器工作正常,残差序列应该零均值且白化(无相关性),并且其协方差与 (HkPk−HkT+Rk)(H_k P_k^- H_k^T + R_k)(HkPk−HkT+Rk) 匹配。
- 状态协方差矩阵 P: P 矩阵的元素应该随着滤波的进行而收敛到一个较小的值。如果 P 矩阵的对角线元素持续增大,说明滤波器可能发散了。
适当延伸:
在调试时,可以绘制残差随时间变化的曲线。如果残差始终围绕零点上下随机波动,说明滤波器工作正常。如果残差出现明显的趋势,比如持续偏离零点,可能说明系统模型有误或参数设置不当。
14. 卡尔曼滤波的复杂度是多少?
核心回答:
卡尔曼滤波的主要计算量集中在矩阵乘法和矩阵求逆。假设状态向量维度为 nnn,测量向量维度为 mmm,则其计算复杂度为 O(n3)O(n^3)O(n3)。
适当延伸:
具体来说:
- 状态协方差预测: FkPk−1FkTF_k P_{k-1} F_k^TFkPk−1FkT,复杂度为 O(n3)O(n^3)O(n3)。
- 卡尔曼增益计算: (HkPk−HkT+Rk)−1(H_k P_k^- H_k^T + R_k)^{-1}(HkPk−HkT+Rk)−1,其中 (HkPk−HkT+Rk)(H_k P_k^- H_k^T + R_k)(HkPk−HkT+Rk) 是一个 m×mm \times mm×m 的矩阵,求逆的复杂度为 O(m3)O(m^3)O(m3)。如果 m>nm > nm>n,复杂度由求逆主导。
在实际应用中,如果状态维度 nnn 和测量维度 mmm 都很大,计算效率会成为一个重要问题,需要考虑使用更高效的数值方法。
15. 如果卡尔曼滤波器发散了,可能是什么原因造成的?
核心回答:
滤波器发散通常是由于理论假设与实际系统不符造成的,常见原因包括:
- 错误的系统模型: FFF 或 HHH 矩阵有误,无法准确描述系统运动或测量关系。
- 不准确的噪声协方差: QQQ 或 RRR 参数设置不当,特别是 P0P_0P0 设置过小。
- 非线性问题: 如果系统是非线性的,而使用了标准的卡尔曼滤波,会因为线性化误差而发散。
- 数值稳定性问题: 矩阵求逆过程中可能出现奇异矩阵,或者浮点运算误差积累。
适当延伸:
在面试中,可以具体举例说明:比如在IMU-GPS组合导航中,如果IMU的陀螺仪或加速度计存在偏差(Bias),而状态向量中没有建模,就会导致系统模型不准确,从而引起滤波发散。
16. 如何处理卡尔曼滤波中的发散问题?
核心回答:
解决发散问题需要从根源入手,常见方法包括:
- 检查模型: 重新检查状态转移方程 FFF 和测量方程 HHH,确保它们能准确描述系统。
- 调整参数:
- 增大P0P_0P0:给予滤波器更多的“不确定性”,让它更积极地利用测量。
- 增大QQQ:提高滤波器的响应速度,使其能更快地适应系统变化。
- 减小RRR:表示更信任测量值。
- 处理非线性: 如果系统非线性,考虑使用EKF或UKF。
- 提高数值稳定性: 避免直接求逆,使用更鲁棒的算法,例如U-D分解或平方根滤波。
- 增加状态量: 将系统中的未知偏差或扰动(如IMU偏差)作为状态量进行估计。
适当延伸:
在实际调试中,通常是先增大P0P_0P0和QQQ,观察滤波器的收敛情况,如果仍然发散,则需要深入检查模型本身。
17. 当某一传感器的数据暂时丢失时,卡尔曼滤波应如何操作?
核心回答:
当传感器数据丢失时,应跳过卡尔曼滤波的更新步骤,只执行预测步骤。
适当延伸:
这意味着在传感器数据缺失的这段时间内,滤波器将完全依赖于系统模型进行状态估计。状态估计的不确定性(P矩阵) 会持续增大,直到新的传感器数据到来,重新执行更新步骤,不确定性才会减小。这种处理方式被称为“预测-跳过更新-预测…”,是卡尔曼滤波在处理间歇性数据时的标准做法。
18. 滤波结果出现振荡可能是什么原因?如何调试?
核心回答:
滤波结果出现振荡通常是由于滤波器过于信任测量值,对测量噪声过于敏感。
可能原因:
- Q设置过大: 滤波器对系统模型不信任,导致对任何小的测量变化都做出过大反应。
- R设置过小: 滤波器对测量噪声过于乐观,将测量噪声当作了真实信号。
如何调试: - 减小Q,增加对系统模型的信任。
- 增大R,表示测量噪声更大,使得滤波器更加平滑。
适当延伸:
振荡现象在GNSS和IMU数据融合中很常见,如果R设置过小,滤波器会试图精确跟踪每一个GNSS测量噪声点,导致估计结果出现“毛刺”。
19. 状态估计值存在滞后应如何优化?
核心回答:
状态估计值滞后通常是由于滤波器过于保守,对系统变化响应慢。
可能原因:
- Q设置过小: 滤波器对系统模型过于信任,认为系统变化不大,导致对真实变化响应迟缓。
- R设置过大: 滤波器对测量值不信任,导致新信息被严重抑制。
如何优化: - 增大Q:使滤波器更快地响应系统状态的变化。
- 减小R:使滤波器更积极地利用新的测量信息。
- 增加状态量:例如将加速度作为状态量,让滤波器能更早地预测出速度和位置的变化。
适当延伸:
在惯性导航中,如果只估计位置和速度,当车辆急加速时,卡尔曼滤波通常会滞后,因为加速度信息并未直接参与到预测中。将加速度作为状态量或使用加速度传感器信息,能有效减少滞后。
20. 如何根据系统特性在KF、EKF和UKF之间进行选择?
核心回答:
- KF(卡尔曼滤波): 适用于线性系统和高斯白噪声,计算效率最高。
- EKF(扩展卡尔曼滤波): 适用于弱非线性系统。它通过雅可比矩阵将非线性系统进行一阶泰勒展开近似为线性系统。优点是实现相对简单,但缺点是当非线性很强时,线性化误差可能导致精度下降甚至发散。
- UKF(无迹卡尔曼滤波): 适用于强非线性系统。它通过无迹变换(Unscented Transform) 来逼近非线性函数的均值和协方差,避免了雅可比矩阵的计算。通常比EKF精度更高,且在非线性很强时更鲁棒,但计算量通常也更大。
适当延伸:
- 无人机姿态估计: 通常使用EKF,因为姿态动力学是非线性的,但通常可以近似为线性。
- 高动态运动目标跟踪: UKF可能更合适,因为目标运动的非线性更强。
- VIO/VINS: EKF或ESKF(误差状态卡尔曼滤波)是主流,因为其非线性相对可控,且EKF计算效率更高。
三、扩展卡尔曼滤波(EKF)与非线性问题
21. 扩展卡尔曼滤波(EKF)与卡尔曼滤波(KF)的主要区别是什么?它们各自的适用场景是什么?
核心回答:
- 主要区别: EKF与KF的主要区别在于它们处理非线性的方式。KF只能处理线性系统,而EKF通过线性化来处理非线性系统。
- 适用场景:
- KF: 适用于状态转移和测量方程都是线性的系统,例如简单的匀速运动模型。
- EKF: 适用于弱非线性系统,是处理非线性问题的首选,因为它在大多数情况下表现良好且计算量适中。
适当延伸:
在EKF中,状态转移矩阵 FkF_kFk 和测量矩阵 HkH_kHk 不再是常数矩阵,而是需要根据当前状态估计值,计算雅可比矩阵来得到。
22. EKF是如何处理非线性系统的?它的核心思想是什么?
核心回答:
EKF处理非线性系统的核心思想是局部线性化(Local Linearization)。它利用一阶泰勒展开,将非线性的状态转移方程和测量方程在当前的状态估计值附近进行近似,从而得到一个线性的系统模型。然后,在这个近似的线性模型上,执行标准的卡尔曼滤波。
适当延伸:
具体的线性化过程如下:
- 状态转移: f(xk−1,uk)≈f(x^k−1,uk)+Fk(xk−1−x^k−1)f(x_{k-1}, u_k) \approx f(\hat{x}_{k-1}, u_k) + F_k (x_{k-1} - \hat{x}_{k-1})f(xk−1,uk)≈f(x^k−1,uk)+Fk(xk−1−x^k−1),其中 Fk=∂f∂x∣x=x^k−1F_k = \frac{\partial f}{\partial x}|_{x = \hat{x}_{k-1}}Fk=∂x∂f∣x=x^k−1。
- 测量方程: h(xk)≈h(x^k−)+Hk(xk−x^k−)h(x_k) \approx h(\hat{x}_k^-) + H_k (x_k - \hat{x}_k^-)h(xk)≈h(x^k−)+Hk(xk−x^k−),其中 Hk=∂h∂x∣x=x^k−H_k = \frac{\partial h}{\partial x}|_{x = \hat{x}_k^-}Hk=∂x∂h∣x=x^k−。
23. EKF相比于KF有什么潜在的缺点?
核心回答:
EKF的潜在缺点主要来自于线性化误差和计算复杂度:
- 线性化误差: 当系统非线性较强时,一阶泰勒展开的近似误差会很大,可能导致滤波器精度下降,甚至发散。
- 雅可比矩阵计算: 需要手动推导和计算雅可比矩阵,这在状态向量维度很高时会变得非常复杂且容易出错。
- 非最优性: EKF不再是理论上的最优滤波器,因为它破坏了高斯噪声假设在非线性系统中的传递。
适当延伸:
EKF的这些缺点促使了后续 UKF 等更高级的非线性滤波算法的发展。
24. EKF的线性化误差主要来源于什么?如何减小其影响?
核心回答:
EKF的线性化误差主要来源于一阶泰勒展开对非线性函数的近似。当非线性程度很高时,这种近似就会不准确。
减小影响的方法:
- 使用高频采样: 缩短采样周期,使得系统在每次更新之间的变化量更小,从而减弱非线性效应。
- 迭代扩展卡尔曼滤波(IEKF): 在更新步骤中进行多次迭代,以减小线性化误差。
- 使用UKF等更高级算法: 避免线性化,直接处理非线性。
适当延伸:
例如,在无人机姿态估计中,如果采样频率过低,IMU的角速度积分会引入较大误差,导致EKF的线性化效果变差。
25. 雅可比矩阵在EKF中的作用是什么?如何计算?
核心回答:
- 作用: 雅可比矩阵在EKF中扮演着线性化算子的角色,它表示了非线性函数在某个点处的局部变化率。
- 计算: 雅可比矩阵是一个偏导数矩阵,其元素为:
- 状态转移矩阵 FkF_kFk: Fij=∂fi∂xj∣x=x^k−1F_{ij} = \frac{\partial f_i}{\partial x_j}|_{x = \hat{x}_{k-1}}Fij=∂xj∂fi∣x=x^k−1
- 测量矩阵 HkH_kHk: Hij=∂hi∂xj∣x=x^k−H_{ij} = \frac{\partial h_i}{\partial x_j}|_{x = \hat{x}_k^-}Hij=∂xj∂hi∣x=x^k−
适当延伸:
在实际编程中,如果解析求导过于复杂,也可以使用数值求导来近似计算雅可比矩阵,但这会引入额外的数值误差。
26. 什么是迭代扩展卡尔曼滤波(IEKF)?它比EKF有什么优势?
核心回答:
IEKF(Iterated Extended Kalman Filter) 是一种改进的EKF算法。它在EKF的更新步骤中,不再仅仅使用预测状态来线性化测量方程,而是迭代地使用更新后的状态估计值来重新线性化,直到状态估计收敛。
优势:
- 更高的精度: IEKF能减小线性化误差,在强非线性问题上比EKF表现更好。
- 更强的鲁棒性: 迭代过程可以纠正因初始线性化点选择不当而导致的偏差。
适当延伸:
IEKF的代价是计算量更大,因为它在每次更新步骤中都需要多次迭代,但它在一些对精度要求很高的应用中(如SLAM)非常有用。
27. 什么是无迹卡尔曼滤波(UKF)?它与EKF相比有什么优势?
核心回答:
UKF(Unscented Kalman Filter) 是一种基于无迹变换(Unscented Transform, UT) 的非线性滤波算法,它不依赖于雅可比矩阵的计算。
优势:
- 避免线性化误差: UKF通过一组精心选择的Sigma点来近似状态的均值和协方差,这些Sigma点经过非线性函数变换后,能更准确地捕捉到其均值和协方差的变化。这避免了EKF的线性化误差。
- 更高的精度: 在大多数情况下,UKF的精度优于EKF,尤其是在强非线性系统中。
- 更强的鲁棒性: UKF对系统非线性更不敏感,不易发散。
- 无需计算雅可比矩阵: 避免了复杂的偏导数推导。
适当延伸:
UKF的核心思想是“传递高斯分布的均值和协方差,而不是传递随机变量本身”。它用少量Sigma点来代表整个高斯分布,通过非线性函数对这些点进行变换,然后重新计算新的均值和协方差。
四、卡尔曼滤波与其他算法的联系与应用
28. 卡尔曼滤波与最小二乘法有何区别与联系?
核心回答:
- 联系: 卡尔曼滤波在本质上可以看作是递归的加权最小二乘法。它的更新步骤正是通过最小化加权后的残差平方和来寻找最优估计。
- 区别:
- 动态 vs. 静态: 卡尔曼滤波是动态的,用于实时估计随时间变化的系统状态。最小二乘法通常是静态的,用于对已有的所有数据进行一次性批处理,寻找最优解。
- 递归 vs. 批量: 卡尔曼滤波是递归的,不需要存储所有历史数据,只依赖上一时刻的估计。最小二乘法通常需要批量处理所有数据。
适当延伸:
在导航领域,最小二乘法常用于GNSS的单点定位,而卡尔曼滤波则用于实时的组合导航。
29. 卡尔曼滤波可以处理非高斯噪声吗?如果不能,该怎么办?
核心回答:
标准的卡尔曼滤波不可以直接处理非高斯噪声,因为它的“最优”性是建立在高斯噪声假设之上的。
解决方法:
- 高斯化近似: 在噪声接近高斯分布时,可以尝试使用EKF或UKF,它们在一定程度上能处理非高斯噪声。
- 粒子滤波(Particle Filter): 粒子滤波是一种非参数化的滤波方法,它不依赖于任何噪声分布假设,可以处理非高斯、非线性问题,但计算量通常很大。
- 鲁棒卡尔曼滤波: 引入鲁棒估计(如M估计)的思想,在更新步骤中对异常值(outlier)进行加权或抑制,从而减弱非高斯噪声的影响。
适当延伸:
在自动驾驶中,一些突发的大噪声(比如GNSS的跳变)就是非高斯噪声,需要用鲁棒滤波或异常值检测方法来处理。
30. 粒子滤波与卡尔曼滤波系列算法的根本区别是什么?
核心回答:
- 卡尔曼滤波系列(KF/EKF/UKF): 属于参数化滤波。它假设状态服从高斯分布,并用均值和协方差这两个参数来描述整个分布。
- 粒子滤波(Particle Filter): 属于非参数化滤波。它不依赖于任何分布假设,而是通过大量随机粒子(样本) 来近似系统的后验概率分布。
适当延伸:
- 优点: 粒子滤波可以处理任何非线性、非高斯问题,因为它不进行任何近似。
- 缺点: 粒子滤波的计算量非常大,且需要大量的粒子才能获得好的估计效果,因此在实时性要求高的应用中较少使用。
31. 在多传感器数据融合中,如何使用卡尔曼滤波?
核心回答:
卡尔曼滤波是多传感器数据融合的核心算法之一。通常有三种融合策略:
- 集中式融合(Centralized Fusion): 将所有传感器的测量值作为一个大的测量向量,统一输入到单个卡尔曼滤波器中。
- 分布式融合(Decentralized Fusion): 每个传感器都有自己的滤波器,先独立估计,然后将各自的估计结果融合到主滤波器中。
- 联邦卡尔曼滤波(Federated Kalman Filter): 一种特殊的分布式融合,主滤波器和子滤波器之间会进行信息共享和协方差重置,以保证全局最优性。
适当延伸:
在组合导航中,通常采用集中式融合,将IMU的预测和GNSS的测量作为输入,在一个滤波器中进行融合。
32. 如何利用卡尔曼滤波进行故障检测?
核心回答:
利用卡尔曼滤波进行故障检测的主要思想是监控残差序列。
- 正常工作: 如果系统工作正常,传感器的测量值与预测值之间的残差($z_k - H_k \hat{x}_k^-)应该符合零均值的高斯白噪声,其方差由 HkPk−HkT+RkH_k P_k^- H_k^T + R_kHkPk−HkT+Rk 决定。
- 故障发生: 当某个传感器发生故障时,其测量值会突然偏离正常范围,导致残差序列的均值或方差发生异常变化。
故障检测方法:
可以设置一个阈值,如果残差的平方大于某个预设的阈值,就认为传感器可能发生了故障。
适当延伸:
这种方法在卫星导航中非常常见,用于检测卫星的伪距或多普勒观测值是否异常。
33. 卡尔曼滤波在自动驾驶中是如何应用的?请举一个例子。
核心回答:
在自动驾驶中,卡尔曼滤波用于实现高精度定位和目标跟踪。
例子: 惯导(IMU)与GNSS的组合导航。
- 状态向量: 包括车辆的位置、速度、姿态以及IMU的偏差(Bias)。
- 预测步骤: 使用高频的IMU(惯性测量单元)数据(加速度计和陀螺仪)对车辆的位置、速度和姿态进行高频预测。IMU的预测是连续且平滑的,但在长时间内会累积误差。
- 更新步骤: 使用低频的GNSS(全球导航卫星系统)数据对IMU的预测进行校正。GNSS提供绝对位置,虽然有噪声,但没有累积误差。
通过卡尔曼滤波,可以将IMU的高频、短时精准特性和GNSS的低频、长时无漂移特性结合起来,得到一个高精度、高频率、实时的车辆定位结果。
34. 为什么在组合导航中常采用卡尔曼滤波作为融合算法?
核心回答:
在组合导航中采用卡尔曼滤波作为融合算法的原因主要有:
- 最优性: 在高斯噪声假设下,卡尔曼滤波是最小均方误差意义下的最优估计。
- 递归性: 它是一个递归算法,无需存储大量历史数据,非常适合实时应用。
- 动态性: 它可以处理随时间变化的动态系统,将IMU的预测和GNSS的测量无缝融合。
- 不确定性建模: 它能显式地建模和更新系统和测量的不确定性,并根据不确定性的相对大小来分配权重,从而实现智能融合。
适当延伸:
相比于其他融合方法,卡尔曼滤波能够动态地、自适应地利用来自不同传感器的信息,这是其不可替代的优势。
35. 什么是误差状态卡尔曼滤波(ESKF)?它与EKF有何异同?
核心回答:
- ESKF(Error State Kalman Filter): 是一种特殊的EKF,它不是直接估计系统全状态,而是估计系统状态的微小误差。
- 异同:
- 相同点: ESKF本质上也是EKF,其核心思想也是线性化,并利用卡尔曼滤波的预测-更新框架。
- 不同点:
- 状态量: EKF估计的是真实状态(如位置、速度、姿态),而ESKF估计的是误差状态(如位置误差、速度误差、姿态误差)。
- 线性化点: EKF在真实状态附近进行线性化,而ESKF在零误差附近进行线性化。
适当延伸:
ESKF的优势在于,误差状态通常是零均值的,其动力学方程通常也比真实状态方程更线性。这使得ESKF的线性化误差更小,精度更高,且在导航领域(尤其是姿态表示)能避免欧拉角或四元数的奇异性问题。
36. 什么是预积分?为什么在VIO/VINS等算法中IMU观测需要先进行预积分?
核心回答:
- 预积分(Pre-integration): 是指在两个视觉关键帧(或GNSS测量)之间,将高频的IMU测量数据进行累积或积分,得到它们之间的相对运动量(如相对位置、速度和姿态)。
- 原因: 在VIO(视觉-惯性里程计)或VINS(视觉-惯性导航系统)中,视觉传感器通常以较低的频率(如10-30Hz)工作,而IMU以较高的频率(如100-200Hz)工作。如果每次IMU测量都进行一次卡尔曼滤波更新,计算量会非常大。
预积分的优势:
- 降低计算量: 将高频的IMU测量打包成一个相对运动量,卡尔曼滤波的更新频率可以降低到与视觉测量同步,大大减少计算量。
- 处理IMU Bias: 在预积分过程中,可以对IMU的偏差(Bias) 进行建模和估计,这能有效提高系统的精度。
- 解耦IMU和视觉: 预积分将IMU的运动信息从具体的时间点中解耦出来,使得后端优化(如非线性优化)变得更高效。
适当延伸:
预积分是现代VIO/VINS算法的核心技术之一,它在保持高精度的同时,极大地提升了算法的实时性和效率。