2025年KBS SCI1区TOP,新颖奖励与ε-贪婪衰减Q-learning算法+局部移动机器人路径规划,深度解析+性能实测
目录
- 1.摘要
- 2.新颖奖励与ε-贪婪衰减Q-learning算法
- 3.结果展示
- 4.参考文献
- 5.代码获取
- 6.算法辅导·应用定制·读者交流

1.摘要
路径规划是移动机器人的核心任务,需要在高效导航的同时规避障碍。本文提出了一种改进Q-learning算法——定制化奖励与ε-贪婪衰减Q-learning(TRE-QL),该方法通过对重复访问状态进行惩罚,引导智能体探索新路径;并设计了基于累计奖励动态调整的ε-贪婪衰减策略,实现了从探索到利用的平滑过渡,保证学习过程的稳定性。
2.新颖奖励与ε-贪婪衰减Q-learning算法
Q-learning用于移动机器人路径规划,通过试错学习在未知环境中更新Q表,逐步形成最优策略,该方法能引导机器人以最短无障碍路径到达目标,并在迭代中收敛,实现高效导航与避障。
环境建模

在Q-learning路径规划中,环境常通过网格离散化建模,将空间划分为空闲单元与障碍单元,机器人在网格中选择动作并判断位置是否合法,从而实现路径搜索。
L(st,at)=lt,lt∈{E,lt=eO,lt=oL(s_t,a_t)=l_t,\quad l_t\in \begin{cases} E, & l_t=e \\ O, & l_t=o & \end{cases} L(st,at)=lt,lt∈{E,O,lt=elt=o
环境网格化离散化为Q-learning路径规划提供状态–动作框架,简化Q表更新并显著压缩状态空间,从而降低计算复杂度并加快收敛。该方法在室内或结构化环境中尤为适用,能高效支持实时路径规划。网格大小决定精度与效率的平衡:小网格提高路径精度但计算代价大,大网格则降低负荷但精度不足。
动作空间
在网格化环境中,机器人动作空间采用4邻域运动,每次移动一个单元格,该有限离散动作集简化了Q-learning,实现高效路径搜索与Q表更新。
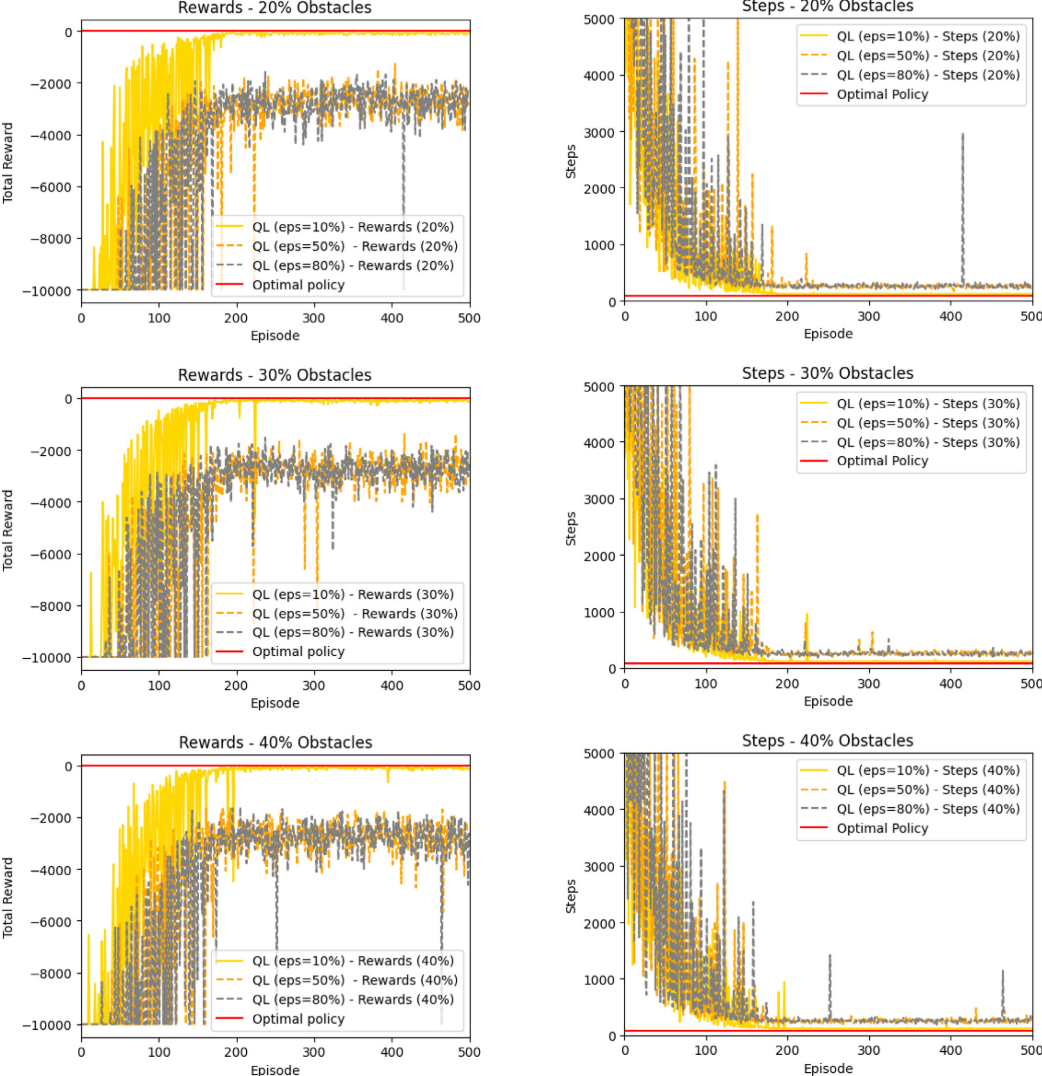
TRE-QL算法通过优化奖励函数与引入动态ε-贪婪衰减机制,有效缓解了传统Q-learning在探索—开发平衡中的局限性。实验表明,当障碍密度超过10%时,固定 ε 值往往导致收敛失败或陷入次优路径。TRE-QL 根据累计奖励自适应调整探索率,实现从探索到利用的平滑过渡,避免过早收敛并稳定智能体行为,从而在复杂环境中提升学习效率和收敛性能,显著增强了Q-learning在受限环境下的鲁棒性。
奖励函数
在强化学习中,奖励函数是智能体学习的核心反馈机制,直接决定其策略能否收敛至最优。传统Q-learning常通过奖励目标、惩罚碰撞的方式定义奖励函数:
r={−r1collisionr2gettarget−r3other statesr= \begin{cases} -r_1 & \mathrm{collision} \\ r_2 & \mathrm{get~target} \\ -r_3 & \text{other states} & \end{cases} r=⎩⎨⎧−r1r2−r3collisionget targetother states
传统Q-learning奖励函数设定为:到达目标得正奖励 +r2+r_2+r2,碰撞受惩罚 −r1-r_1−r1,其他非目标状态为−r3-r_3−r3,且满足r2>r3>r1r_2>r_3>r_1r2>r3>r1,以突出先到达目标、再避障优先级。但该设计缺乏对重复访问状态的惩罚,易导致智能体在状态间振荡、学习效率降低。为此,本文提出优化离散奖励函数:在单次回合内若状态被重复访问,则施加动态惩罚鼓励探索新路径、提升收敛速度与学习效率。
P(e)=C×KeP(e)=C\times K^e P(e)=C×Ke
在TRE-QL中,若累计奖励Tcumulative>TthresholdT_\mathrm{cumulative}>T_\mathrm{threshold}Tcumulative>Tthreshold,则引入与成功经验次数 eee 相关的动态惩罚机制,其中常数CCC与KKK控制惩罚的初始强度与衰减速率。由此,TRE-QL奖励函数在传统设计基础上引入状态重复访问惩罚与动态调节项,更好地平衡目标达成与探索效率,实现更快、更稳定的收敛。
r={−r1collisionr2gettarget−r4=−P(e)revisit same state more than once−r3other statesr= \begin{cases} -r_1 & \mathrm{collision} \\ r_2 & \mathrm{get~target} \\ -r_4=-P(e) & \text{revisit same state more than once} \\ -r_3 & \text{other states} & \end{cases} r=⎩⎨⎧−r1r2−r4=−P(e)−r3collisionget targetrevisit same state more than onceother states
动作选择策略
为避免智能体过早收敛,TRE-QL引入自适应ε-贪婪衰减机制,其核心思想是在学习初期保持足够探索,随后依据累计奖励动态调整探索率,使智能体平滑过渡到利用阶段。若ε下降过快,会导致过早利用并陷入次优;若下降过慢,则会延迟收敛。自适应衰减通过累计奖励与阈值比较来调控ε,若奖励超过阈值,则以衰减因子更新ε:
ϵt+1=ϵt×CdifRcumulative>Tthreshold\epsilon_{t+1}=\epsilon_{t}\times C_{d}\quad\mathrm{if}\quad R_{\text{cumulative}}>T_{\mathrm{threshold}} ϵt+1=ϵt×CdifRcumulative>Tthreshold

3.结果展示
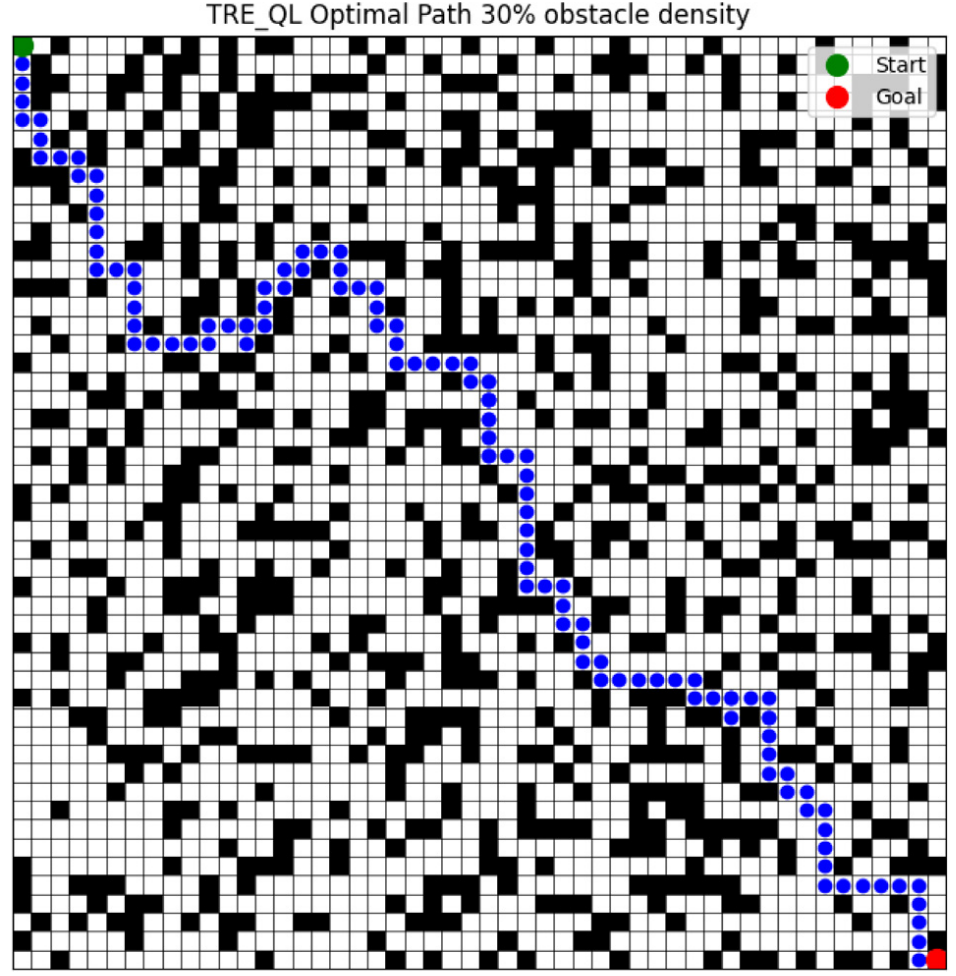
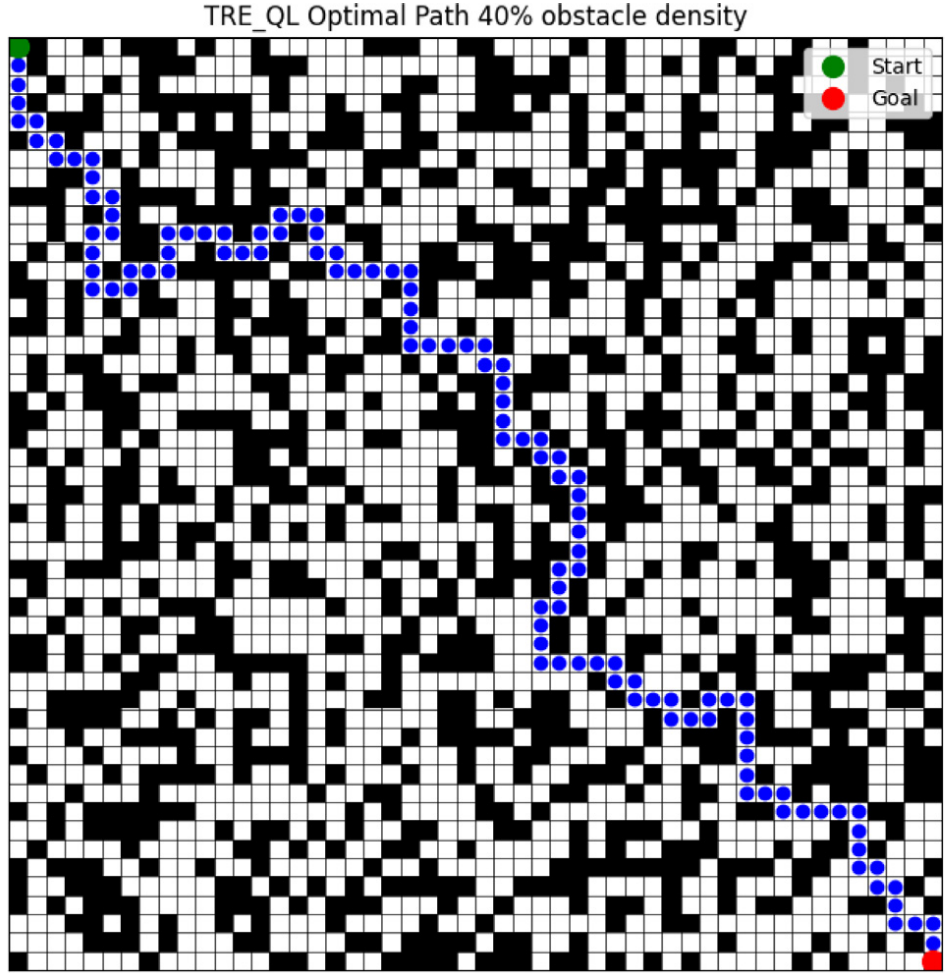
4.参考文献
[1] Ben-Akka M, Tanougast C, Diou C. Novel design of reward and epsilon-greedy decay strategy tailored for Q-learning in optimizing local mobile robot path planning[J]. Knowledge-Based Systems, 2025: 113836.
5.代码获取
xx
6.算法辅导·应用定制·读者交流
xx