Pod 生命周期:从创建到销毁的完整旅程
Pod 的管理和优化
Pod 是 Kubernetes 中最小的部署单元,其生命周期涵盖从创建到终止的全过程。理解生命周期的各个阶段、核心机制(如初始化容器、探针)是管理 Pod 的基础,直接影响应用的稳定性和可用性。
- Pod是可以创建和管理Kubernetes计算的最小可部署单元
- 一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip
- 一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
- 多个容器间共享IPC、Network和UTC namespace

一、Pod 的核心阶段(Phase)
Pod 的生命周期可划分为 5 个关键阶段,反映其当前的运行状态,通过 kubectl get pods 可查看:
| 阶段(Phase) | 含义 | 典型场景与处理 |
|---|---|---|
| Pending | Pod 已被 Kubernetes 系统接受,但容器尚未全部启动。 | 常见原因: - 节点资源不足(CPU / 内存不满足 requests); - 镜像拉取失败(镜像地址错误、私有仓库认证失败); - 依赖的 ConfigMap/Secret 不存在; - 调度器未找到合适节点。 处理:通过 kubectl describe pod <pod-name> 查看事件日志,定位具体原因。 |
| Running | Pod 已绑定到节点,所有容器已创建,且至少一个容器处于运行状态(或正在启动 / 重启)。 | 此阶段需通过探针监控容器健康状态,避免 “假活” 或 “未就绪却接收请求”。 |
| Succeeded | 所有容器均已成功终止(退出码为 0),且不会重启。 | 常见于 Job/CronJob(一次性任务),如数据备份完成。可保留 Pod 查看日志,或通过 ttlSecondsAfterFinished 自动清理。 |
| Failed | 至少一个容器异常终止(退出码非 0)。 | 原因:应用崩溃、配置错误、资源超限(如内存 OOM)。 处理:通过 kubectl logs <pod-name> -c <container-name> 查看容器日志,定位故障。 |
| Unknown | Kubernetes 无法获取 Pod 状态(通常因节点与控制平面通信中断)。 | 原因:节点宕机、kubelet 服务异常、网络分区。 处理:检查节点状态 kubectl get nodes,修复节点通信或重启 kubelet。 |
二、pod的创建
2.1 创建自主式pod (生产不推荐)
优点:
灵活性高:
- 可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
学习和调试方便:
- 对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
适用于特殊场景:
- 在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
管理复杂:
- 如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
缺乏高级功能:
- 无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
可维护性差:
- 手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。
#查看所有pods
[root@master ~]# kubectl get pod
No resources found in default namespace.#建立一个名为testpod的pod
[root@master ~]# kubectl run testpod --image myapp:v1
pod/testpod created#再次查看
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
testpod 1/1 Running 0 2s#显示pod的较为详细的信息
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED N ODE READINESS GATES
testpod 1/1 Running 0 25s 10.244.104.31 node2 <none> <none>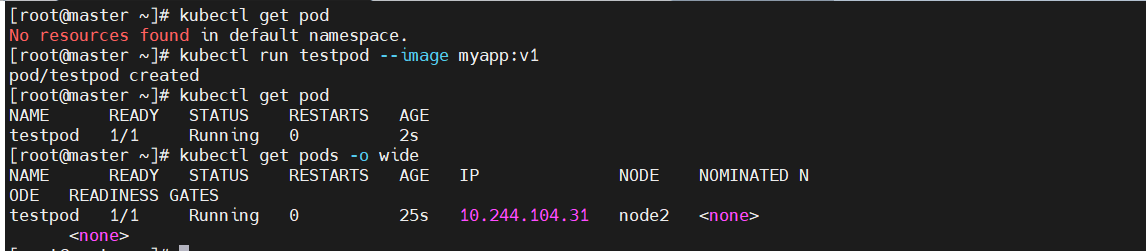
2.2 利用控制器管理pod(推荐)
高可用性和可靠性:
- 自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
- 健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
- 轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
- 水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
- 滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
- 回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
- 简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
- 期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
- 自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
- 流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
- 一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
#建立控制器testdep并自动运行pod
[root@master ~]# kubectl create deployment testdep --image myapp:v1
deployment.apps/testdep created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
testdep-689d58948d-vrvjh 1/1 Running 0 9s
[root@master ~]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
testdep 1/1 1 1 14s#为testdep扩容
[root@master ~]# kubectl scale deployment testdep --replicas 3
deployment.apps/testdep scaled
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
testdep-689d58948d-h57zt 1/1 Running 0 21s
testdep-689d58948d-mztr6 1/1 Running 0 21s
testdep-689d58948d-vrvjh 1/1 Running 0 83s#为testdep缩容
[root@master ~]# kubectl scale deployment testdep --replicas 2
deployment.apps/testdep scaled
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
testdep-689d58948d-mztr6 1/1 Running 0 42s
testdep-689d58948d-vrvjh 1/1 Running 0 104s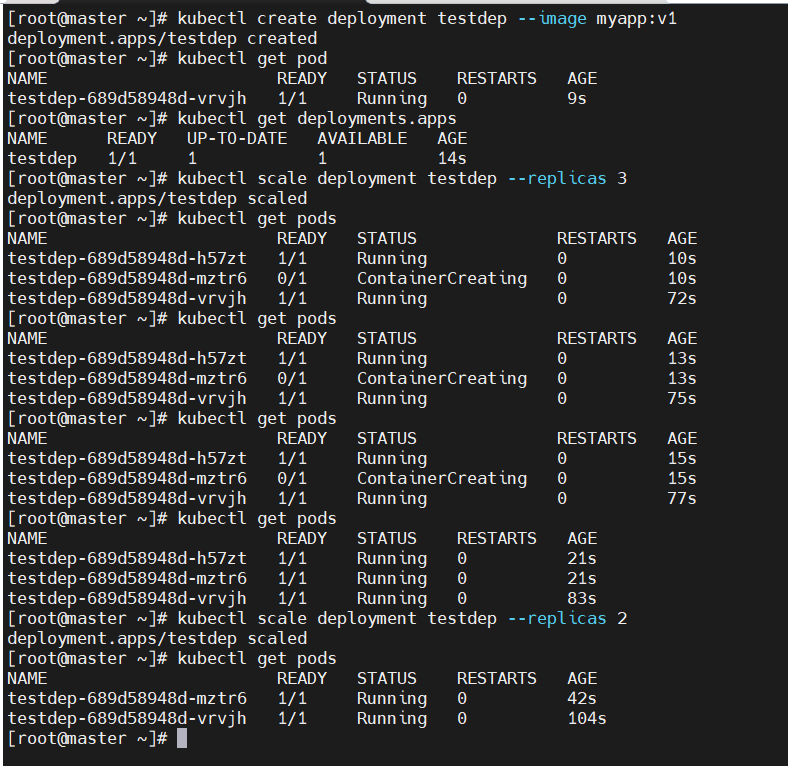
2.3 应用版本的更新
#利用控制器建立pod
[root@master ~]# kubectl create deployment test --image myapp:v1 --replicas 2
deployment.apps/test created#暴漏端口
[root@master ~]# kubectl expose deployment test --port 80 --target-port 80
service/test exposed
[root@master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h
test ClusterIP 10.110.195.120 <none> 80/TCP 8s#访问服务
[root@master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
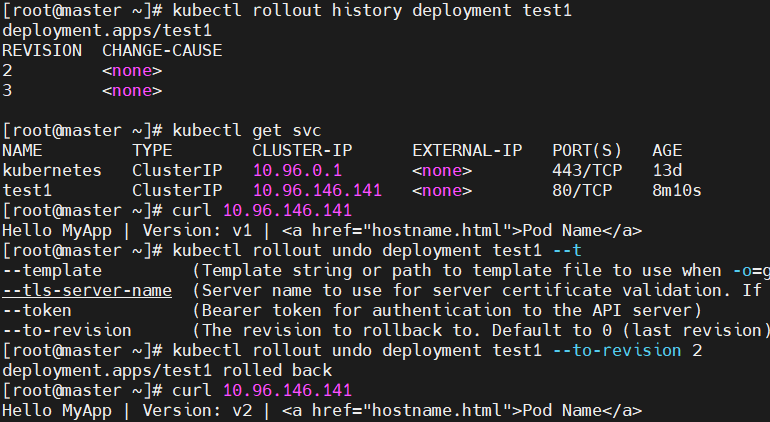
[root@master ~]# curl 10.110.195.120#产看历史版本
[root@master ~]# kubectl rollout history deployment test
deployment.apps/test
REVISION CHANGE-CAUSE
1 <none>#更新控制器镜像版本
[root@master ~]# kubectl set image deployments/test myapp=myapp:v2
deployment.apps/test image updated#查看历史版本
[root@master ~]# kubectl rollout history deployment test
deployment.apps/test
REVISION CHANGE-CAUSE
1 <none>
2 <none>#访问内容测试
[root@master ~]# curl 10.110.195.120
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
[root@master ~]# curl 10.110.195.120#版本回滚
[root@master ~]# kubectl rollout undo deployment test --to-revision 1
deployment.apps/test rolled back
[root@master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
2.4 利用yaml文件部署应用
2.4.1 用yaml文件部署应用有以下优点
声明式配置:
- 清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
- 可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
- 团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
- 丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
- 组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
- 与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
- 命令行工具支持:Kubernetes 的命令行工具
kubectl对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
2.4.2 如何获得资源帮助
kubectl explain pod.spec.containers
2.4.3 编写示例
用命令获取yaml模板
[root@master ~]# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod.yml
[root@master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timing #pod标签name: testpod #pod名称
spec:containers:- image: myapp:v1 #pod镜像name: testpod #容器名称
三、初始化容器(Init Container):启动前的准备工作
初始化容器是在业务容器启动前执行的特殊容器,用于完成前置初始化任务,特点如下:
- 执行顺序:多个 Init 容器按定义顺序依次执行,前一个成功后才启动下一个,全部完成后才启动业务容器。
- 生命周期:Init 容器执行完成后自动终止(退出码 0),不会重启(与业务容器的持续运行不同)。
- 典型用途:
- 等待依赖服务就绪(如数据库启动);
- 拉取配置文件到共享目录(供业务容器使用);
- 初始化数据库表结构、生成密钥等。
INIT 容器示例
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: initpodname: initpod
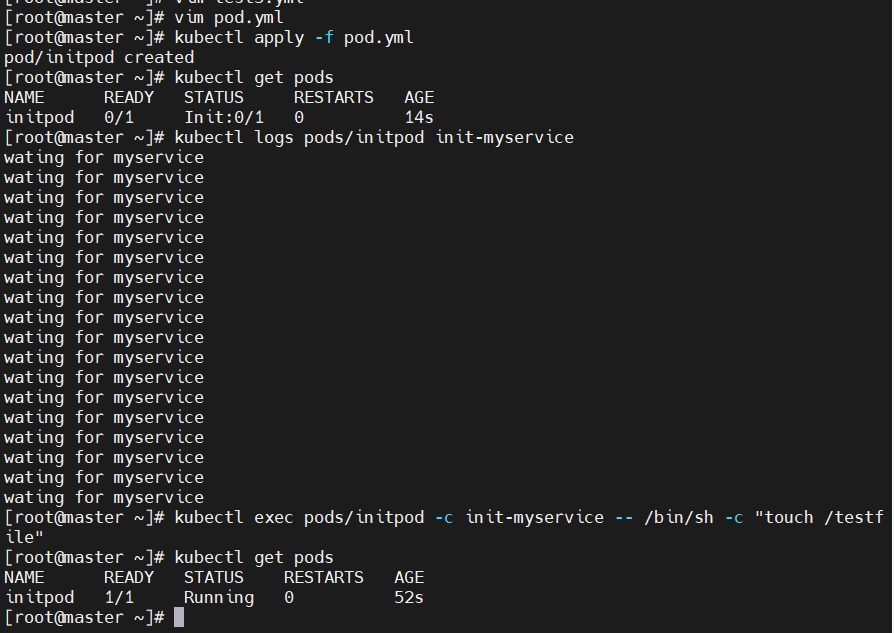
spec:containers:- image: myapp:v1name: myappinitContainers:- name: init-myserviceimage: busyboxcommand: ["sh","-c","until test -e /testfile;do echo wating for myservice; sleep 2;done"][root@k8s-master ~]# kubectl apply -f pod.yml
pod/initpod created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
initpod 0/1 Init:0/1 0 3s[root@k8s-master ~]# kubectl logs pods/initpod init-myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
[root@k8s-master ~]# kubectl exec pods/initpod -c init-myservice -- /bin/sh -c "touch /testfile"[root@k8s-master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE
initpod 1/1 Running 0 62s
探针是由 kubelet 对容器执行的定期诊断:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
- startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
ReadinessProbe 与 LivenessProbe 的区别
- ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
- LivenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
- 如果三个探针同时存在,先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod 满足 StartupProbe 探针配置的条件,其他 2 个探针启动,如果不满足按照规则重启容器。
- 另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
探针分为 3 类,配置在 spec.containers.livenessProbe/readinessProbe/startupProbe 字段:
| 探针类型 | 作用 | 失败处理 | 适用场景 |
|---|---|---|---|
| 存活探针(livenessProbe) | 检测容器是否 “存活”(如应用是否崩溃)。 | 失败则根据 restartPolicy 重启容器(默认 Always 策略下自动重启)。 | 防止容器 “假活”(进程存在但无法处理请求,如死锁)。 |
| 就绪探针(readinessProbe) | 检测容器是否 “就绪”(如是否能接收请求)。 | 失败则将 Pod 从 Service endpoints 中移除,不再接收流量。 | 处理应用启动后的初始化阶段(如加载缓存),或临时不可用(如连接数满)。 |
| 启动探针(startupProbe) | 检测容器是否 “启动完成”,仅在首次启动时生效。 | 失败则重启容器,直到成功或达到重试上限。 | 慢启动应用(如 JVM 服务、大数据组件),避免存活探针过早检测导致误判。 |
探针的配置方式
探针支持 3 种检测方式,可根据应用特性选择:
-
HTTP GET:发送 HTTP 请求到容器的指定路径和端口,返回状态码 ≥200 且 <400 视为成功。
示例(存活探针检查/health接口):livenessProbe:httpGet:path: /healthport: 8080initialDelaySeconds: 30 # 容器启动后延迟 30s 开始检测(预留启动时间)periodSeconds: 10 # 每 10s 检测一次timeoutSeconds: 5 # 超时时间 5sfailureThreshold: 3 # 连续 3 次失败视为探针失败 -
TCP Socket:尝试与容器的指定端口建立 TCP 连接,连接成功视为正常。
示例(就绪探针检查 8080 端口):readinessProbe:tcpSocket:port: 8080initialDelaySeconds: 5periodSeconds: 5 -
Exec:在容器内执行命令,命令退出码为 0 视为成功。
示例(检测配置文件是否存在):livenessProbe:exec:command: ['cat', '/app/config.conf']initialDelaySeconds: 10periodSeconds: 60
探针配置的核心参数
initialDelaySeconds:容器启动后延迟多久开始首次探测(关键!需大于应用实际启动时间,避免误判)。periodSeconds:探测间隔时间(默认 10s,太短会增加资源消耗,太长会延迟故障发现)。failureThreshold:连续失败多少次后判定为 “探针失败”(默认 3 次,避免网络波动导致的偶发失败)。
3.2.1 探针实例
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: livenessname: liveness
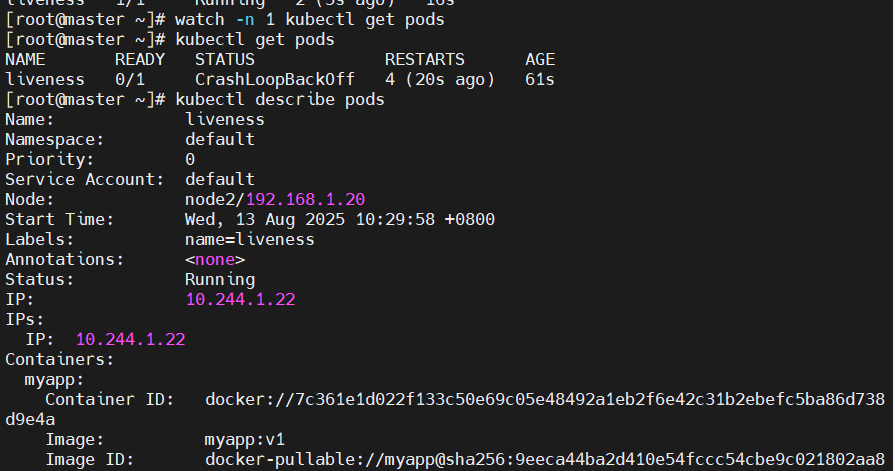
spec:containers:- image: myapp:v1name: myapplivenessProbe:tcpSocket: #检测端口存在性port: 8080initialDelaySeconds: 3 #容器启动后要等待多少秒后就探针开始工作,默认是 0periodSeconds: 1 #执行探测的时间间隔,默认为 10stimeoutSeconds: 1 #探针执行检测请求后,等待响应的超时时间,默认为 1s#测试:
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/liveness created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness 0/1 CrashLoopBackOff 2 (7s ago) 22s[root@k8s-master ~]# kubectl describe pods
Warning Unhealthy 1s (x9 over 13s) kubelet Liveness probe failed: dial tcp 10.244.2.6:8080: connect: connection refused
3.2.1.2 就绪探针示例:
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: readinessname: readiness
spec:containers:- image: myapp:v1name: myappreadinessProbe:httpGet:path: /test.htmlport: 80initialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 1#测试:
[root@k8s-master ~]# kubectl expose pod readiness --port 80 --target-port 80[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness 0/1 Running 0 5m25s[root@k8s-master ~]# kubectl describe pods readiness
Warning Unhealthy 26s (x66 over 5m43s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 404[root@k8s-master ~]# kubectl describe services readiness
Name: readiness
Namespace: default
Labels: name=readiness
Annotations: <none>
Selector: name=readiness
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.171.244
IPs: 10.100.171.244
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: #没有暴漏端口,就绪探针探测不满足暴漏条件
Session Affinity: None
Events: <none>[root@master ~]# kubectl exec pods/readiness -c myapp -- /bin/sh -c "echo test > /usr/share/nginx/html/test.html"[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readiness 1/1 Running 0 7m49s[root@k8s-master ~]# kubectl describe services readiness
Name: readiness
Namespace: default
Labels: name=readiness
Annotations: <none>
Selector: name=readiness
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.171.244
IPs: 10.100.171.244
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.8:80 #满组条件端口暴漏
Session Affinity: None
Events: <none>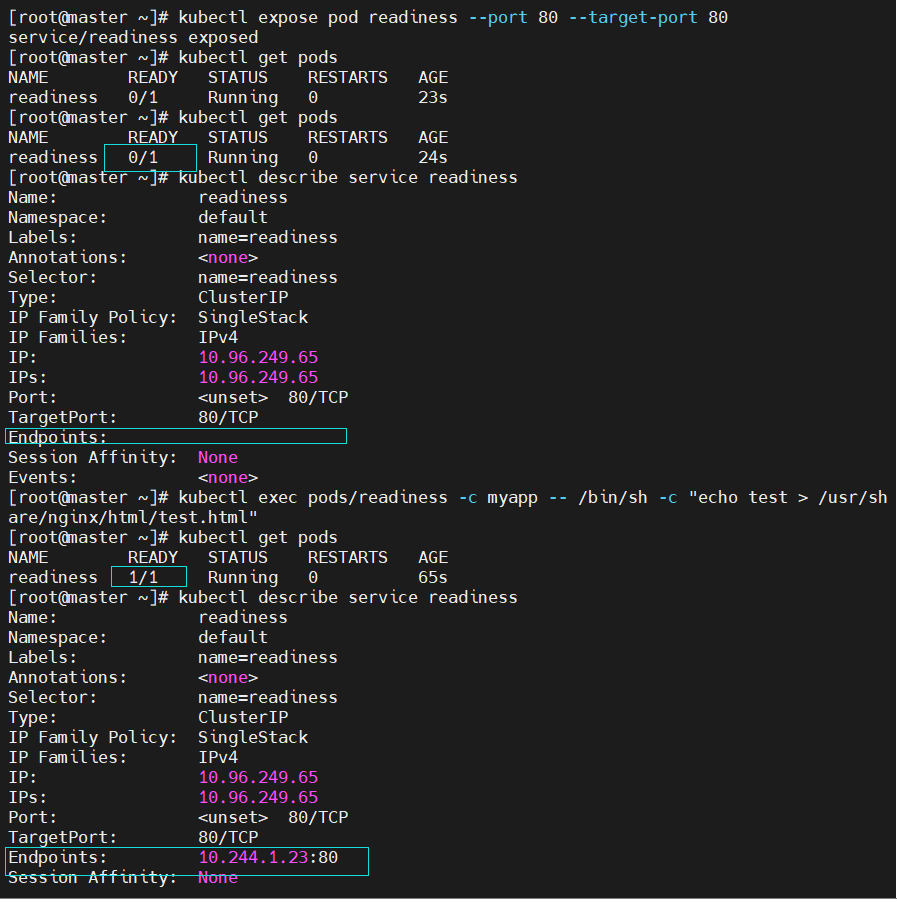
四、重启策略(restartPolicy):容器退出后的处理规则
重启策略定义了容器退出时 Kubernetes 的重启行为,仅作用于处于 Running 阶段的 Pod,配置在 spec.restartPolicy 字段,可选值:
- Always:默认值,只要容器退出(无论退出码),就自动重启(适合长期运行的服务,如 Web 应用)。
- OnFailure:仅当容器异常退出(退出码非 0)时重启(适合 Job 类任务,正常完成后不重启)。
- Never:无论容器退出原因,均不重启(适合一次性调试任务)。
注意:重启策略受控制器影响,例如 Deployment 会结合 replicas 保证副本数,即使 restartPolicy=Never,Pod 被删除后仍可能被重建。
总结
Pod 的生命周期管理是 Kubernetes 运维的核心:
- 阶段(Phase)反映 Pod 的整体状态,是排查故障的第一线索;
- 初始化容器解决了 “启动前依赖准备” 问题,确保业务容器在合适的时机启动;
- 探针(存活、就绪、启动)是保障应用健康的关键,避免 “假活”“未就绪服务接流量” 等问题;
- 重启策略则定义了故障后的恢复规则,需结合应用类型(长期服务 / 一次性任务)选择。