自然语言处理——06 迁移学习(下)
1 迁移学习中文分类
1.1 任务介绍
- 完成中文语料评论分类。评论是一个二分类,正面评价(1)、负面评价(0);
- 实现分析:
- 使用迁移学习方式完成;
- 使用预训练模型 BERT 模型提取文本特征,后面添加全连接层和softmax进行二分类。
1.2 数据介绍
-
数据文件有三个,即
train.csv、test.csv、validation.csv,数据样式都是一样的;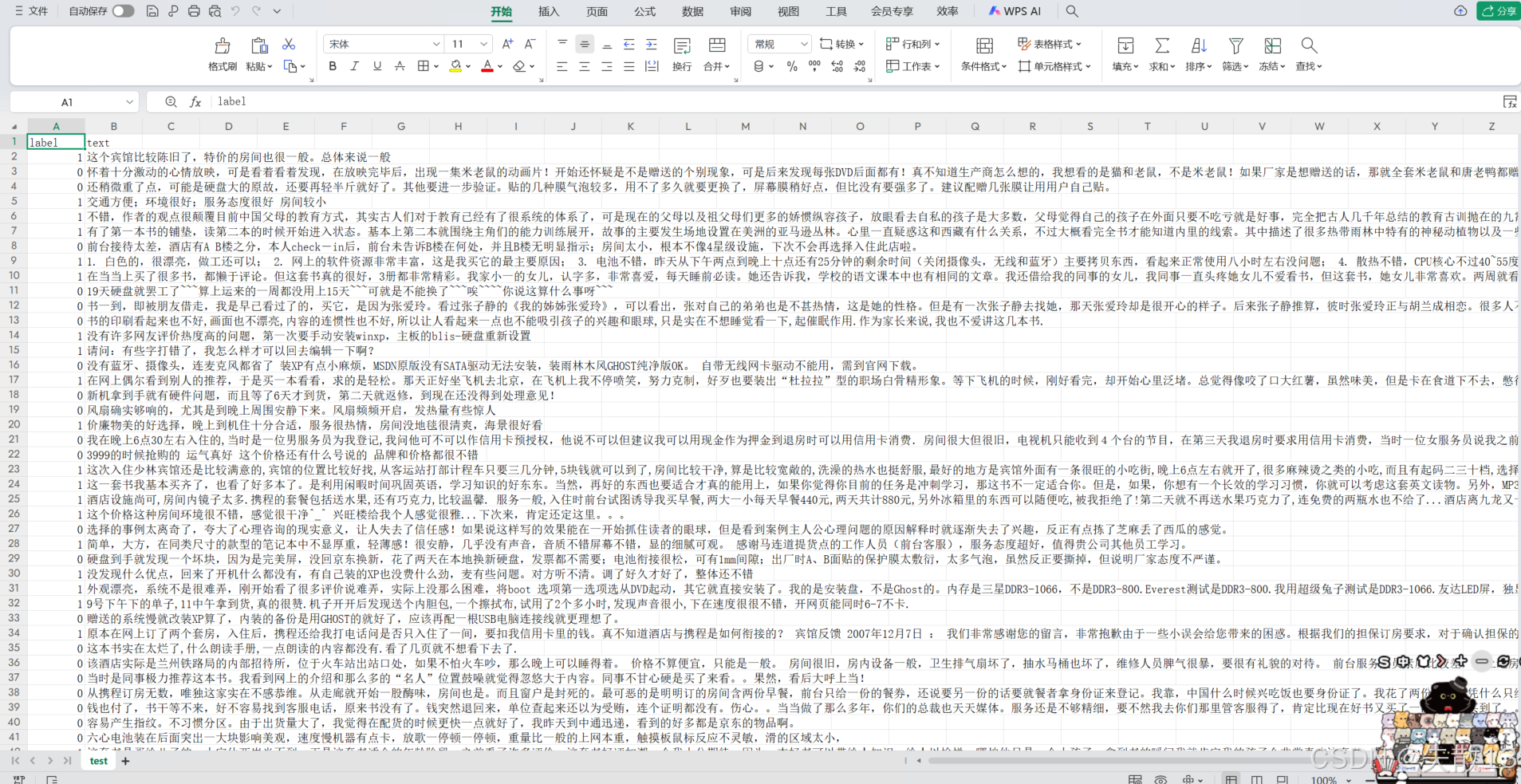
-
导包:
import torch from datasets import load_dataset from transformers import BertTokenizer, BertModel import time from torch.optim import AdamW -
使用 HuggingFace 的 datasets 库的 load_dataset 函数加载数据:
def dm_file2dataset():# 实例化数据源对象my_dataset_trainprint('加载训练集')my_dataset_train = load_dataset('csv', data_files='data/train.csv', split='train')print('dataset_train--->', my_dataset_train)print(my_dataset_train[0:3])# 实例化数据源对象my_dataset_testprint('\n加载测试集')my_dataset_test = load_dataset('csv', data_files='data/test.csv', split='train')print('my_dataset_test--->', my_dataset_test)print(my_dataset_test[0:3])# 实例化数据源对象my_dataset_trainprint('\n加载验证集')my_dataset_validation = load_dataset('csv', data_files='data/validation.csv', split="train")print('my_dataset_validation--->', my_dataset_validation)print(my_dataset_validation[0:3]) dm_file2dataset()加载训练集 dataset_train---> Dataset({features: ['label', 'text'],num_rows: 9600 }) {'label': [1, 1, 0], 'text': ['选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', '房间太小。其他的都一般。。。。。。。。。']}加载测试集 my_dataset_test---> Dataset({features: ['label', 'text'],num_rows: 1200 }) {'label': [1, 0, 0], 'text': ['这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般', '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片!开始还怀疑是不是赠送的个别现象,可是后来发现每张DVD后面都有!真不知道生产商怎么想的,我想看的是猫和老鼠,不是米老鼠!如果厂家是想赠送的话,那就全套米老鼠和唐老鸭都赠送,只在每张DVD后面添加一集算什么??简直是画蛇添足!!', '还稍微重了点,可能是硬盘大的原故,还要再轻半斤就好了。其他要进一步验证。贴的几种膜气泡较多,用不了多久就要更换了,屏幕膜稍好点,但比没有要强多了。建议配赠几张膜让用用户自己贴。']}加载验证集 my_dataset_validation---> Dataset({features: ['label', 'text'],num_rows: 1200 }) {'label': [1, 1, 0], 'text': ['這間酒店環境和服務態度亦算不錯,但房間空間太小~~不宣容納太大件行李~~且房間格調還可以~~ 中餐廳的廣東點心不太好吃~~要改善之~~~~但算價錢平宜~~可接受~~ 西餐廳格調都很好~~但吃的味道一般且令人等得太耐了~~要改善之~~', '<荐书> 推荐所有喜欢<红楼>的红迷们一定要收藏这本书,要知道当年我听说这本书的时候花很长时间去图书馆找和借都没能如愿,所以这次一看到当当有,马上买了,红迷们也要记得备货哦!', '商品的不足暂时还没发现,京东的订单处理速度实在.......周二就打包完成,周五才发货...']}
1.3 数据预处理
-
加载模型和工具:
# 加载字典和分词工具,实例化分词工具 my_tokenizer = BertTokenizer.from_pretrained('huggingface_model/bert-base-chinese') # 加载预训练模型,实例化预训练模型 my_model_pretrained = BertModel.from_pretrained('huggingface_model/bert-base-chinese') -
数据预处理函数:
# 数据预处理 def collate_fn1(data):# data 是一个列表,每个元素是字典,代表一条样本,格式如: [{'text':'文本内容','label':标签}, ...]# 从 data 的每个字典元素中,取出 'text' 字段,组成句子列表 sentssents = [i['text'] for i in data]# 从 data 的每个字典元素中,取出 'label' 字段,组成标签列表 labelslabels = [i['label'] for i in data]# 使用分词器对文本进行编码data = my_tokenizer.batch_encode_plus( # batch_encode_plus 是分词器的批量编码方法,用于处理多个文本batch_text_or_text_pairs=sents,truncation=True, # 开启截断,超过 max_length 的部分会被截断padding='max_length', # 用 padding 填充到 max_length 长度,保证每个文本编码后长度一致max_length=500, # 设置文本编码后的最大长度return_tensors='pt', # 返回 PyTorch 的张量(tensor)return_length=True) # 返回每个文本编码前的原始长度# input_ids:文本编码后的数字标识,每个数字对应分词器词汇表中的一个词/子词input_ids = data['input_ids']# attention_mask:补零位置标记为 0,原始文本内容位置标记为 1,用于模型区分有效文本和 paddingattention_mask = data['attention_mask']# token_type_ids:用于区分句子对(如 BERT 的句对任务),单句任务中通常全为 0token_type_ids = data['token_type_ids']# 将标签列表转换为 PyTorch 的 LongTensor 类型,因为模型训练时标签需要是这种张量类型labels = torch.LongTensor(labels)# 返回编码后的文本张量(供模型输入)和标签张量(供计算损失)# 这些返回值会作为模型 forward 函数的输入,或用于计算损失return input_ids, attention_mask, token_type_ids, labels -
测试:
def dm01_test_dataset():dataset_train = load_dataset('csv', data_files='data/train.csv', split="train")print('dataset_train--->\n', dataset_train)# 创建数据加载器# 使用 PyTorch 的 DataLoader 将数据集转换为可迭代的批次数据mydataloader = torch.utils.data.DataLoader(dataset_train, # 要加载的数据集batch_size=8, # 每个批次包含 8 个样本collate_fn=collate_fn1, # 使用自定义的 collate_fn1 函数处理批次数据(如文本编码、长度对齐等)shuffle=True, # 加载数据时打乱样本顺序drop_last=True # 如果最后一个批次样本数量不足 batch_size,就丢弃该批次)# 打印数据加载器的批次数量(总样本数 // batch_size)print('mydataloader--->\n', len(mydataloader))# 遍历数据加载器,检查批次数据格式# enumerate 用于同时获取批次索引 i 和批次数据# 批次数据通过 collate_fn1 处理后,返回 (input_ids, attention_mask, token_type_ids, labels) 四个张量for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(mydataloader):# 再次打印总批次数量(验证与之前一致)print('mydataloader--->\n', len(mydataloader))# 打印每个张量的形状,确认维度是否符合预期print('每个张量的形状--->\n', input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)# 打印编码后的文本张量(每个数字对应词汇表中的 token)print('input_ids--->\n', input_ids)# 打印注意力掩码张量(0 表示填充位置,1 表示有效文本位置)print('attention_mask--->\n', attention_mask)# 打印句子分段张量(用于区分句对,单句任务中通常全为 0)print('token_type_ids--->\n', token_type_ids)# 打印标签张量(每个样本对应的类别标签)print('labels--->\n', labels)# 只循环一次就退出,用于测试数据格式是否正确,避免打印过多信息break # 调用函数执行测试 dm01_test_dataset()dataset_train--->Dataset({features: ['label', 'text'],num_rows: 9600 }) mydataloader--->1200 mydataloader--->1200 每个张量的形状--->torch.Size([8, 500]) torch.Size([8, 500]) torch.Size([8, 500]) tensor([1, 1, 1, 1, 0, 0, 1, 1]) input_ids--->tensor([[ 101, 7553, 4638, ..., 0, 0, 0],[ 101, 6983, 2421, ..., 0, 0, 0],[ 101, 809, 1184, ..., 0, 0, 0],...,[ 101, 5314, 3301, ..., 0, 0, 0],[ 101, 671, 2458, ..., 0, 0, 0],[ 101, 1348, 743, ..., 0, 0, 0]]) attention_mask--->tensor([[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],...,[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0]]) token_type_ids--->tensor([[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]]) labels--->tensor([1, 1, 1, 1, 0, 0, 1, 1])
1.4 自定义下游任务网络模型
-
自定义下游任务网络模型
# 定义下游任务模型,继承自 PyTorch 的 nn.Module,是构建自定义神经网络模型的基类 class MyModel(torch.nn.Module):# 初始化方法,创建模型实例时会调用def __init__(self):# 调用父类(nn.Module)的初始化方法,这是必须的,确保模块正确初始化super().__init__()# 定义一个全连接层(线性层),输入维度是 768(通常是预训练模型输出的特征维度,比如 BERT 输出的隐藏状态维度),输出维度是 2(对应二分类任务的两个类别 )self.fc = torch.nn.Linear(768, 2)# 前向传播方法,定义模型接收输入并得到输出的计算流程,模型调用时会执行def forward(self, input_ids, attention_mask, token_type_ids):# 使用 torch.no_grad() 上下文管理器,在这个代码块内,计算不会被跟踪,不计算梯度,因为预训练模型这里只用来特征抽取,不需要更新其参数with torch.no_grad():# 调用预训练模型,传入输入参数,得到预训练模型的输出out = my_model_pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 从预训练模型输出中获取 [CLS] 位置的隐藏状态(last_hidden_state 是包含所有位置隐藏状态的张量,[:, 0] 取第一个位置,即 [CLS] 对应的特征),# 然后通过前面定义的全连接层 self.fc 进行维度变换,将 768 维特征映射到 2 维(对应两个分类)out = self.fc(out.last_hidden_state[:, 0])# 对全连接层输出的结果,在维度 1(dim=1,即每个样本的分类维度 )上进行 softmax 归一化,得到每个样本属于两个类别的概率值out = out.softmax(dim=1)# 返回最终的分类概率输出,用于后续计算损失、评估等return out# 1. out.last_hidden_state[:, 0] # - out 是预训练模型(如BERT)的输出对象,包含模型各层的计算结果 # - last_hidden_state 是预训练模型最后一层的隐藏状态张量,形状通常为 [batch_size, sequence_length, hidden_size] # 例如:[8, 500, 768] 表示8个样本,每个样本500个token,每个token对应768维特征 # - [:, 0] 是张量切片操作: # - 第一个冒号 ":" 表示取所有样本(保留batch_size维度) # - 第二个数字 "0" 表示取每个样本序列中的第0个token(即[CLS]标记) # 结果得到形状为 [batch_size, hidden_size] 的张量,例如 [8, 768]# 2. self.fc(...) # - self.fc 是前面定义的全连接层(Linear(768, 2)) # - 将 [CLS] 标记的768维特征输入全连接层,进行线性变换 # - 输出形状为 [batch_size, 2] 的张量,例如 [8, 2],对应二分类任务的两个类别分数out = self.fc(out.last_hidden_state[:, 0]) -
模型测试:
# 定义模型测试函数,用于验证自定义下游任务模型的基本功能和输出格式 def dm02_test_mymodel():# 加载训练数据集dataset_train = load_dataset('csv', data_files='data/train.csv', split="train")# 创建数据加载器# 用 PyTorch 的 DataLoader 将数据集转换为批量迭代的数据mydataloader = torch.utils.data.DataLoader(dataset_train, # 要加载的数据集batch_size=8, # 每个批次包含 8 个样本collate_fn=collate_fn1, # 使用自定义的 collate_fn1 函数处理批次数据shuffle=False, # 不打乱数据顺序(测试时固定顺序便于观察结果)drop_last=True # 如果最后一个批次样本数不足 8 ,则丢弃该批次)# 打印数据加载器的总批次数量(总样本数 // batch_size),验证数据加载是否符合预期print('mydataloader--->\n', len(mydataloader))# 实例化自定义的下游任务模型(MyModel 类的对象)mymodel = MyModel()# 打印模型结构,查看模型的层组成(这里主要是全连接层)print('mymodel--->\n', mymodel)# 遍历数据加载器,获取批次数据并输入模型测试# enumerate 同时返回批次索引 i 和批次数据(input_ids, attention_mask, token_type_ids, labels)for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(mydataloader):# 打印总批次数量(再次确认)print(len(mydataloader))# 打印每个输入张量的形状,验证维度是否符合模型输入要求print('每个张量的形状--->\n', input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)# 将批次数据输入模型,得到模型的输出结果 y_outy_out = mymodel(input_ids, attention_mask, token_type_ids)# 打印模型输出的形状和具体值:# 形状应为 [8, 2](8个样本,每个样本对应2个类别的概率)# 输出值是经过 softmax 归一化的概率分布print('y_out---->\n', y_out.shape, y_out)# 只运行一次循环就退出(测试用,避免打印过多数据)breakmydataloader--->1200 mymodel--->MyModel((fc): Linear(in_features=768, out_features=2, bias=True) ) 1200 每个张量的形状--->torch.Size([8, 500]) torch.Size([8, 500]) torch.Size([8, 500]) tensor([1, 1, 0, 0, 1, 0, 0, 0]) y_out---->torch.Size([8, 2]) tensor([[0.6511, 0.3489],[0.5566, 0.4434],[0.7369, 0.2631],[0.6649, 0.3351],[0.6146, 0.3854],[0.6626, 0.3374],[0.5863, 0.4137],[0.5712, 0.4288]], grad_fn=<SoftmaxBackward0>)
1.5 模型训练
# 定义模型训练函数,实现下游任务模型的训练过程
def dm03_train_model():# 实例化自定义的下游任务模型(MyModel类)my_model = MyModel()# 实例化优化器(AdamW是常用的优化器,适合Transformer类模型)# 优化器负责更新模型参数,这里只优化my_model的参数(预训练模型参数不更新)# lr=5e-4表示学习率为0.0005,控制参数更新的步长my_optimizer = AdamW(my_model.parameters(), lr=5e-4)# 实例化损失函数(CrossEntropyLoss适用于分类任务)# 用于计算模型预测值与真实标签之间的差距my_criterion = torch.nn.CrossEntropyLoss()# 加载训练数据集my_dataset_train = load_dataset('csv', data_files='data/train.csv', split="train")# 固定预训练模型参数(不参与训练)# 遍历预训练模型(my_model_pretrained)的所有参数,设置requires_grad=False# 表示不需要计算这些参数的梯度,也不会被优化器更新,只作为特征提取器for param in my_model_pretrained.parameters():param.requires_grad_(False)# 设置训练轮数(整个数据集将被训练3次)epochs = 3# 将模型设置为训练模式(部分层如Dropout在训练和测试模式下行为不同)my_model.train()# 测试用# 用于记录总迭代次数total_iterations = 0# 目标迭代次数target_iterations = 100# 外层循环:控制训练轮次for eporch_idx in range(epochs):# 记录本轮训练开始时间(用于计算耗时)starttime = (int)(time.time())# 创建数据加载器(每个轮次重新创建,确保shuffle生效)my_dataloader = torch.utils.data.DataLoader(my_dataset_train,batch_size=8, # 每批8个样本collate_fn=collate_fn1, # 用自定义函数处理批次数据shuffle=True, # 打乱数据顺序,增强训练效果drop_last=True # 丢弃最后一个不完整的批次)# 内层循环:按批次迭代训练数据# enumerate的start=1表示迭代计数从1开始for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(my_dataloader, start=1):# 测试用# 累加总迭代次数total_iterations += 1# 当达到目标迭代次数时,终止训练if total_iterations > target_iterations:# 保存当前模型torch.save(my_model.state_dict(), './my_model_final.bin')print(f"已完成{target_iterations}次迭代,终止训练")return # 退出整个函数# 将批次数据输入模型,得到预测输出(形状为[8, 2],每个样本的2个类别概率)my_out = my_model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 计算损失值(预测输出与真实标签的差距)my_loss = my_criterion(my_out, labels)# 梯度清零(防止上一轮的梯度累积影响当前轮次)my_optimizer.zero_grad()# 反向传播(计算各参数的梯度,从损失值反向推导)my_loss.backward()# 梯度更新(根据计算出的梯度,通过优化器更新模型参数)my_optimizer.step()# 每迭代5次,计算并打印一次准确率(监控训练效果)if i % 5 == 0:# 从预测概率中取最大值的索引作为预测类别([8,2]→[8,])out = my_out.argmax(dim=1)# 计算准确率:预测正确的样本数 ÷ 总样本数accuracy = (out == labels).sum().item() / len(labels)# 打印训练信息:轮次、迭代数、损失值、准确率、耗时print('轮次:%d 迭代数:%d 损失:%.6f 准确率%.3f 时间%d' \%(eporch_idx, i, my_loss.item(), accuracy, (int)(time.time())-starttime))# 每个轮次结束后,保存当前模型的参数(状态字典)# 保存路径为:./my_model_1.bin、./my_model_2.bin等torch.save(my_model.state_dict(), './my_model_%d.bin' % (eporch_idx + 1))# 调用训练函数,开始模型训练
dm03_train_model()
轮次:0 迭代数:5 损失:0.729210 准确率0.500 时间6
轮次:0 迭代数:10 损失:0.608048 准确率0.875 时间13
轮次:0 迭代数:15 损失:0.643231 准确率0.625 时间19
轮次:0 迭代数:20 损失:0.607039 准确率0.625 时间26
轮次:0 迭代数:25 损失:0.685258 准确率0.500 时间32
轮次:0 迭代数:30 损失:0.583586 准确率0.750 时间39
轮次:0 迭代数:35 损失:0.535041 准确率1.000 时间45
轮次:0 迭代数:40 损失:0.571271 准确率0.875 时间52
轮次:0 迭代数:45 损失:0.516152 准确率1.000 时间58
轮次:0 迭代数:50 损失:0.540038 准确率0.875 时间65
轮次:0 迭代数:55 损失:0.576123 准确率0.750 时间71
轮次:0 迭代数:60 损失:0.595128 准确率0.875 时间78
轮次:0 迭代数:65 损失:0.602563 准确率0.625 时间84
轮次:0 迭代数:70 损失:0.562873 准确率0.875 时间92
轮次:0 迭代数:75 损失:0.478363 准确率0.875 时间98
轮次:0 迭代数:80 损失:0.566524 准确率0.750 时间105
轮次:0 迭代数:85 损失:0.572177 准确率0.750 时间112
轮次:0 迭代数:90 损失:0.565277 准确率0.625 时间118
轮次:0 迭代数:95 损失:0.450267 准确率1.000 时间125
轮次:0 迭代数:100 损失:0.502919 准确率0.875 时间132
已完成100次迭代,终止训练
- 注意:由于此处加了测试代码,即
torch.save(my_model.state_dict(), './my_model_final.bin'),所以只会保存最后一次迭代的模型为my_model_final.bin。
1.6 模型评估
# 定义模型评估函数,用于测试训练好的模型在测试集上的表现
def dm04_evaluate_model():# split='train'这里表示加载测试集数据在文件中的存储格式与训练集一致my_dataset_test = load_dataset('csv', data_files='data/test.csv', split='train')# 准备加载训练好的模型参数# 模型参数文件路径,这里加载的是第3轮训练保存的模型path = './my_model_final.bin'# 实例化下游任务模型my_model = MyModel()# 加载预保存的模型参数(状态字典)到模型中my_model.load_state_dict(torch.load(path))# 打印模型结构,确认模型加载成功print('my_model-->\n', my_model)# 将模型设置为评估模式# 评估模式下,模型中的 dropout 等层会关闭,确保预测结果稳定my_model.eval()# 初始化评估指标变量correct = 0 # 用于记录预测正确的样本数total = 0 # 用于记录总样本数# 测试用eval_count = 0 # 新增:记录已执行的评估迭代次数max_evals = 25 # 新增:设置最大评估迭代次数为25# 创建测试集的数据加载器my_loader_test = torch.utils.data.DataLoader(my_dataset_test,batch_size=8, # 每批处理8个样本collate_fn=collate_fn1, # 使用与训练时相同的批处理函数shuffle=True, # 测试时打乱数据顺序drop_last=True # 丢弃最后一个不完整的批次)# 遍历测试集数据加载器,进行模型评估for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(my_loader_test):# 测试用# 每次迭代计数+1eval_count += 1# 当达到5次迭代时,终止评估if eval_count > max_evals:print(f"\n已完成{max_evals}次评估迭代,终止评估")break # 跳出循环,停止评估# 使用 torch.no_grad() 上下文管理器,关闭梯度计算# 评估时不需要计算梯度,节省内存并加快计算速度with torch.no_grad():# 将测试数据输入模型,得到预测输出my_out = my_model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 从模型输出的概率分布中,取概率最大的类别作为预测结果# argmax(dim=1) 表示在第二个维度(类别维度)上取最大值的索引out = my_out.argmax(dim=1)# 计算预测正确的样本数并累加到correctcorrect += (out == labels).sum().item()# 累加总样本数total += len(labels)# 每迭代5次,打印一次当前的准确率和部分样本的预测情况if i % 5 == 0:# 打印当前累积的准确率(正确数/总数)print(correct / total, end=" ")# 将第一个样本的编码(input_ids)解码回原始文本(跳过特殊符号如[CLS]、[PAD]等)print(my_tokenizer.decode(input_ids[0], skip_special_tokens=True), end=" ")# 打印第一个样本的预测值和真实标签,直观查看预测效果print('预测值:真实值:', out[0].item(), ':', labels[0].item())# 调用评估函数,开始模型测试
dm04_evaluate_model()
my_model-->MyModel((fc): Linear(in_features=768, out_features=2, bias=True)
)
0.75 性 价 比 高 intel - 硬 盘 卖 掉 换 普 通 硬 盘 一 台 上 网 本 才 2000 不 到 外 观 漂 亮 全 铝 机 身 预测值:真实值: 1 : 1
0.7916666666666666 屏 幕 大 , 配 置 强 悍 , 外 观 还 可 以 , 散 热 没 问 题 , 华 硕 质 量 信 得 过 , 作 为 家 用 机 非 常 不 错 预测值:真实值: 1 : 1
0.8068181818181818 总 体 很 满 意 , 但 有 一 点 需 改 进 , 我 在 9 楼 入 住 , 走 时 到 1 楼 前 台 结 帐 时 由 9 楼 层 服 务 员 检 查 房 间 , 发 现 我 有 零 星 物 品 遗 失 在 房 间 , 我 当 时 请 他 们 送 下 来 , 结 果 答 复 是 到 4 楼 客 房 服 务 部 去 取 , 我 到 了 4 楼 , 又 说 服 员 员 没 时 间 , 又 要 到 9 楼 去 取 。 当 然 这 没 什 么 , 但 是 如 果 他 们 给 东 西 送 下 来 , 哪 怕 是 到 4 楼 就 取 到 了 东 西 , 我 会 对 酒 店 有 更 好 的 印 象 。 预测值:真实值: 1 : 1
0.8359375 对 于 这 本 鲤, 我 是 针 对 于 它 每 期 的 主 题 而 买 的 , 第 一 次 买 鲤 & # 183 ; 孤 独 很 自 然 的 认 为 是 张 悦 然 写 的 , 买 了 之 后 才 发 现 原 来 是 她 主 编 , 所 以 有 一 点 失 望 , 随 便 的 看 了 几 篇 , 觉 得 也 就 这 样 , 没 什 么 大 的 感 觉 , 但 是 却 一 直 很 喜 欢 她 出 书 的 主 题 , 所 以 这 次 就 买 了 鲤 & # 183 ; 谎 言 。 看 完 之 后 发 生 真 的 很 喜 欢 很 喜 欢 她 对 于 书 的 主 题 , 里 面 的 内 容 也 相 当 的 好 , 虽 然 没 有 一 篇 篇 的 看 下 来 , 但 让 我 产 生 一 种 不 一 样 的 感 受 。 很 好 看 ! 预测值:真实值: 1 : 1
0.8511904761904762 超 难 装 , 送 货 速 度 简 直 慢 的 没 法 说 了 , 打 了 无 数 次 客 服 电 话 都 说 马 上 处 理 马 上 处 理 , 处 理 了 几 天 才 给 我 送 过 来 预测值:真实值: 0 : 0已完成25次评估迭代,终止评估
2 迁移学习中文填空
2.1 任务介绍
- 完成中文语料完型填空;
- 实现分析:
- 使用迁移学习方式完成;
- 使用预训练模型 BERT 模型提取文本特征,后面添加全连接层和softmax进行单标签多分类。
2.2 数据介绍
- 同
1.2 数据介绍。
2.3 数据预处理函数
-
导包:
import torch from torch.utils.data import DataLoader from datasets import load_dataset from transformers import BertTokenizer, BertModel import time from torch.optim import AdamW -
加载模型和工具:
# 加载字典和分词工具,实例化分词工具 my_tokenizer = BertTokenizer.from_pretrained('huggingface_model/bert-base-chinese') # 加载预训练模型,实例化预训练模型 my_model_pretrained = BertModel.from_pretrained('huggingface_model/bert-base-chinese') -
数据预处理:
# 数据预处理 def collate_fn2(data):# 从输入数据中提取所有文本内容,组成句子列表# data是包含多个字典的列表,每个字典有'text'键对应文本sents = [i['text'] for i in data]# 对文本进行批量编码(数值化处理)# 使用分词器my_tokenizer的batch_encode_plus方法处理多个文本data = my_tokenizer.batch_encode_plus(batch_text_or_text_pairs=sents,truncation=True,padding='max_length',max_length=32,return_tensors='pt',return_length=True)# 从编码结果中提取关键张量input_ids = data['input_ids'] # 文本编码后的数字序列,形状为[batch_size, 32]attention_mask = data['attention_mask'] # 注意力掩码,0表示填充位置,1表示有效文本token_type_ids = data['token_type_ids'] # 句子分段标识(单句任务中通常全为0)# 构建标签:将每个样本中第16个位置的token作为标签# input_ids[:, 16]:取所有样本(第0维全部)的第16个token(第1维索引16)# reshape(-1):将形状调整为一维张量([batch_size,])# clone():复制张量,避免后续修改input_ids时影响标签labels = input_ids[:, 16].reshape(-1).clone()# 将输入序列中第16个位置的token替换为掩码符号([MASK])# my_tokenizer.get_vocab()[my_tokenizer.mask_token]:获取[MASK]对应的编码值input_ids[:, 16] = my_tokenizer.get_vocab()[my_tokenizer.mask_token]# 确保标签为长整数类型张量(符合PyTorch计算要求)labels = torch.LongTensor(labels)# 返回处理后的输入张量和标签,用于模型训练/评估return input_ids, attention_mask, token_type_ids, labels -
测试:
def dm01_test_dataset():dataset_train_tmp = load_dataset('csv', data_files='data/train.csv', split="train")# 对原始数据集进行过滤,只保留文本长度大于32的样本# lambda x: len(x['text']) > 32 是过滤条件:取'text'字段长度超过32的样本# 目的是确保文本长度足够,能在第16个位置有有效token(避免因文本过短导致掩码位置为填充符)my_dataset_train = dataset_train_tmp.filter(lambda x: len(x['text']) > 32)# 创建数据加载器,用于批量处理过滤后的数据集mydataloader = DataLoader(my_dataset_train, batch_size=8, collate_fn=collate_fn2, shuffle=True, drop_last=True)print('mydataloader--->', mydataloader)# 固定预训练模型的参数for param in my_model_pretrained.parameters():param.requires_grad_(False)# 遍历数据加载器,查看处理后的批次数据格式# 用enumerate获取迭代索引i和批次数据(input_ids, attention_mask, token_type_ids, labels)for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(mydataloader):# 打印各张量的形状,验证维度是否符合预期# 例如:input_ids应为[8, 32](8个样本,每个长度32),labels应为[8]print(input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)# 打印第1个样本的掩码前后信息print('\n第1句mask的信息')# 将编码后的input_ids解码为文本,查看第16个位置是否被替换为[MASK]print(my_tokenizer.decode(input_ids[0]))# 解码labels[0],查看被掩码的原始token是什么print(my_tokenizer.decode(labels[0]))# 打印第2个样本的掩码前后信息print('\n第2句mask的信息')print(my_tokenizer.decode(input_ids[1])) # 带[MASK]的句子print(my_tokenizer.decode(labels[1])) # 被掩码的原始token# 只循环一次就退出,避免打印过多信息(仅作测试用)break dm01_test_dataset()mydataloader---> <torch.utils.data.dataloader.DataLoader object at 0x000002388D469A90> torch.Size([8, 32]) torch.Size([8, 32]) torch.Size([8, 32]) tensor([1377, 741, 2990, 4638, 1921, 6981, 2207, 8024])第1句mask的信息 [CLS] 酒 店 的 大 堂 环 境 比 以 前 有 所 提 高, [MASK] 能 是 因 为 鲜 花 摆 放 的 原 因. 房 间 [SEP] 可第2句mask的信息 [CLS] 我 于 2008 年 1 月 29 日 下 单 订 购 了 三 本 [MASK] , 其 中 之 一 是 《 杜 拉 拉 升 职 记 》 [SEP] 书
2.4 自定义下游任务网络模型
# 自定义下游任务网络模型
class MyModel(torch.nn.Module):def __init__(self):super().__init__()# 定义一个全连接层(解码器层),用于将预训练模型的特征映射到词汇表空间# 输入维度为768(预训练模型输出的隐藏状态维度)# 输出维度为分词器的词汇表大小(my_tokenizer.vocab_size),即可能的token数量# bias=False:暂时不启用偏置项(后续会手动设置)self.decoder = torch.nn.Linear(768, my_tokenizer.vocab_size, bias=False)# 手动为全连接层设置偏置项,形状为词汇表大小,初始值全为0# 这一步是为了单独初始化偏置,确保训练时能正确更新self.decoder.bias = torch.nn.Parameter(torch.zeros(my_tokenizer.vocab_size))# 前向传播方法,定义数据流向和计算过程def forward(self, input_ids, attention_mask, token_type_ids):# 使用torch.no_grad()关闭梯度计算,固定预训练模型参数(不参与训练)# 仅用预训练模型进行特征提取with torch.no_grad():# 调用预训练模型(my_model_pretrained),传入输入参数# 得到模型输出(包含各位置的隐藏状态等信息)out = my_model_pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 从预训练模型的输出中,提取第16个位置(被掩码的位置)的隐藏状态# out.last_hidden_state是形状为[batch_size, sequence_length, 768]的张量# [:, 16]表示取所有样本(第0维)的第16个位置(第1维索引16),得到形状为[batch_size, 768]的张量# 再通过全连接层self.decoder映射到词汇表空间,输出形状为[batch_size, vocab_size]# 例如:输入[8, 768] → 输出[8, 21128](假设词汇表大小为21128)out = self.decoder(out.last_hidden_state[:, 16])# 返回映射后的结果,用于后续计算预测损失(预测被掩码的token)return out
def dm02_test_mymodel():dataset_train_tmp = load_dataset('csv', data_files='data/train.csv', split="train")my_dataset_train = dataset_train_tmp.filter(lambda x: len(x['text']) > 32)# 创建数据加载器,批量处理过滤后的数据集mydataloader = DataLoader(my_dataset_train,batch_size=8,collate_fn=collate_fn2,shuffle=True,drop_last=True)print('mydataloader--->', mydataloader)# 固定预训练模型的参数(不计算梯度)for param in my_model_pretrained.parameters():param.requires_grad_(False)mymodel = MyModel()# 遍历数据加载器,获取批次数据并输入模型测试for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(mydataloader):# 打印各张量的形状,验证维度是否符合预期print(input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)# 打印第1个样本的掩码前后信息print('\n第1句mask的信息')# 解码输入序列,查看第16个位置是否被替换为[MASK]print(my_tokenizer.decode(input_ids[0]))# 解码标签,查看被掩码的原始tokenprint(my_tokenizer.decode(labels[0]))# 打印第2个样本的掩码前后信息print('\n第2句mask的信息')print(my_tokenizer.decode(input_ids[1])) # 带[MASK]的输入序列print(my_tokenizer.decode(labels[1])) # 被掩码的原始token# 将批次数据输入模型,得到预测输出# 模型输入为编码后的文本信息,输出为每个样本在词汇表上的预测分数# 形状变化:[8, 32](输入)→ [8, 768](预训练模型特征)→ [8, vocab_size](如21128,词汇表大小)myout = mymodel(input_ids, attention_mask, token_type_ids)# 打印模型输出的形状和内容,验证输出是否符合预期# 输出形状应为[8, vocab_size],每个元素表示对应token的预测分数print('myout--->', myout.shape, myout)break
dm02_test_mymodel()
mydataloader---> <torch.utils.data.dataloader.DataLoader object at 0x000002388D501090>
torch.Size([8, 32]) torch.Size([8, 32]) torch.Size([8, 32]) tensor([4638, 2157, 7313, 4692, 1912, 4692, 511, 800])第1句mask的信息
[CLS] 左 右 键 不 太 好 用 , 比 较 僵 硬 ; 自 带 [MASK] [UNK] 系 统 太 差 了 , 很 多 东 西 都 不 兼 [SEP]
的第2句mask的信息
[CLS] 用 它 我 也 没 多 记 住 什 么 单 词 啊 ! 大 [MASK] 要 是 想 学 单 词 , 有 很 多 方 式 , 没 [SEP]
家
myout---> torch.Size([8, 21128]) tensor([[ 0.4759, -0.1286, -0.4247, ..., -0.0141, -0.4226, 0.2576],[ 0.4839, 0.6495, -0.7174, ..., 0.1296, -0.2981, -0.2595],[ 0.3090, -0.0845, 0.1643, ..., 0.3128, -0.2409, -0.0955],...,[ 0.4489, -0.2583, -0.3419, ..., 0.3697, -0.0071, 0.2483],[-0.0030, 0.3164, -0.4169, ..., 0.1122, -0.2581, -0.5706],[ 0.4340, 0.3078, -0.4170, ..., 0.4005, -0.4167, -0.2265]],grad_fn=<AddmmBackward0>)
2.5 模型训练
# 模型训练
def dm03_train_model():dataset_train_tmp = load_dataset('csv', data_files='data/train.csv', split="train")my_dataset_train = dataset_train_tmp.filter(lambda x: len(x['text']) > 32)print('my_dataset_train--->', my_dataset_train)my_model = MyModel()my_optimizer = AdamW(my_model.parameters(), lr=5e-4)my_criterion = torch.nn.CrossEntropyLoss()for param in my_model_pretrained.parameters():param.requires_grad_(False)epochs = 3 my_model.train()for eporch_idx in range(epochs):my_dataloader = torch.utils.data.DataLoader(my_dataset_train,batch_size=8,collate_fn=collate_fn2,shuffle=True,drop_last=True)starttime = (int)(time.time())for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(my_dataloader, start=1):my_out = my_model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 计算损失my_loss = my_criterion(my_out, labels)# 梯度清零my_optimizer.zero_grad()# 反向传播my_loss.backward()# 梯度更新my_optimizer.step()# 每5次迭代 算一下准确率if i % 20 == 0:out = my_out.argmax(dim=1) # [8,21128] --> (8,)accuracy = (out == labels).sum().item() / len(labels)print('轮次:%d 迭代数:%d 损失:%.6f 准确率%.3f 时间%d' \%(eporch_idx, i, my_loss.item(), accuracy, (int)(time.time())-starttime))# 每个轮次保存模型torch.save(my_model.state_dict(), './my_model_mask_%d.bin' % (eporch_idx + 1))
dm03_train_model()
2.6 模型评估
# 模型评估
def dm04_evaluate_model():print('\n加载测试集')my_dataset_tmp = load_dataset('csv', data_files='data/test.csv', split='train')my_dataset_test = my_dataset_tmp.filter(lambda x: len(x['text']) > 32)print('my_dataset_test--->', my_dataset_test)path = './my_model_mask_3.bin'my_model = MyModel()my_model.load_state_dict(torch.load(path))print('my_model-->', my_model)my_model.eval()# 设置评估参数correct = 0total = 0# 实例化化dataloadermy_loader_test = torch.utils.data.DataLoader(my_dataset_test,batch_size=8,collate_fn=collate_fn2,shuffle=True,drop_last=True)# 给模型送数据 测试预测结果for i, (input_ids, attention_mask, token_type_ids,labels) in enumerate(my_loader_test):with torch.no_grad():my_out = my_model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)out = my_out.argmax(dim=1)correct += (out == labels).sum().item()total += len(labels)if i % 25 == 0:print(i+1, my_tokenizer.decode(input_ids[0]))print('预测值:', my_tokenizer.decode(out[0]), '\t真实值:', my_tokenizer.decode(labels[0]))print(correct / total)
dm04_evaluate_model()
3 迁移学习中文句子关系
3.1 任务介绍
- 下一句话任务NSP(Next Sentence Prediction),中文句子关系任务;
- 输入2句话,判断第二句是否为第一句的下半句,这是一个二分类问题;
- 实现分析:
- 使用迁移学习方式完成;
- 数据处理环节:构建第1句话,第2句话形成正负样本;
- 使用预训练模型 BERT 模型提取文本特征,后面添加全连接层和softmax进行二分类分类。
3.2 代码实现
import torch
from torch.utils.data import DataLoader
from datasets import load_dataset
from transformers import BertTokenizer, BertModel
from torch.optim import AdamW
import time
from random import randommy_tokenizer = BertTokenizer.from_pretrained('huggingface_model/bert-base-chinese')
my_model_pretrained = BertModel.from_pretrained('huggingface_model/bert-base-chinese')
# 定义数据源类
class MyDataSet:def __init__(self, data_csv_files):# 生成数据源 dataset 对象my_dataset_temp = load_dataset('csv', data_files=data_csv_files, split="train")# 按照条件过滤数据源对象(文本长度 > 44)self.my_dataset = my_dataset_temp.filter(lambda x: len(x['text']) > 44)def __len__(self):self.len = len(self.my_dataset)return self.len # 返回数据集样本数量def __getitem__(self, index):# 1 表示下一句话关系,0 表示不是下一句话关系label = 1 text = self.my_dataset[index]['text']# 从文本中切分两个句子片段sentence1 = text[0:22] sentence2 = text[22:44] # 产生负样本:随机概率选中 0 时,替换为无关句子片段if random.randint(0, 1) == 0: j = random.randint(0, self.len - 1)sentence2 = self.my_dataset[j]['text'][22:44] label = 0 # 标记为负样本# 返回两个句子片段和它们之间的关系标签return sentence1, sentence2, label
# 数据集处理自定义函数
def collate_fn3(data):# 提取前两个元素作为句子对(sents),第三个元素作为标签(labels)sents = [i[:2] for i in data]labels = [i[2] for i in data]# 文本数值化,使用分词器对句子对进行编码data = my_tokenizer.batch_encode_plus(batch_text_or_text_pairs=sents,truncation=True,padding='max_length',max_length=50, # 44 + cls + sep + sep 等,计算得最大长度设为50return_tensors='pt',return_length=True)# 从编码结果中提取关键张量input_ids = data['input_ids'] # 编码之后的数字序列attention_mask = data['attention_mask'] # 补零位置为0,其他为1的掩码token_type_ids = data['token_type_ids'] # 区分句子对的标识# 注意labels不要忘记需要转成tensor 1维数组labels = torch.LongTensor(labels)return input_ids, attention_mask, token_type_ids, labels
# 定义下游任务模型NSP(Next Sentence Prediction)
class MyModel(torch.nn.Module):def __init__(self):super().__init__()# 调用父类初始化,确保Module的参数初始化逻辑生效super().__init__() # 定义全连接层:将预训练模型的768维特征映射到2分类(句子关系任务常用二分类)self.fc = torch.nn.Linear(768, 2) def forward(self, input_ids, attention_mask, token_type_ids):# 1. 预训练模型特征提取(固定参数,不训练)# with torch.no_grad() 关闭梯度计算,避免更新预训练模型参数with torch.no_grad(): # 调用预训练模型(my_model_pretrained需提前定义,如BERT等)out = my_model_pretrained( input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 2. 下游任务适配:取预训练模型输出的 [CLS] 位置特征(last_hidden_state[:, 0])# last_hidden_state 形状: [batch_size, sequence_length, 768]# 取第0个位置([:, 0])得到 [batch_size, 768] 的特征cls_feature = out.last_hidden_state[:, 0] # 3. 全连接层映射到分类空间# 将768维特征映射到2维(二分类)out = self.fc(cls_feature) # 4. softmax归一化,得到分类概率(dim=1 表示在类别维度计算概率)out = out.softmax(dim=1) return out
def dm02_test_mymodel():# 定义数据集文件路径data_files = 'data/train.csv'# 实例化自定义数据集mydataset = MyDataSet(data_files)print('mydataset--->', mydataset, len(mydataset))# 通过dataloader进行迭代,设置批次大小、数据处理函数等mydataloader = DataLoader(mydataset, batch_size=8, collate_fn=collate_fn3, shuffle=True, drop_last=True)print('mydataloader--->', mydataloader)# 实例化下游任务模型mymodel = MyModel()# 遍历数据加载器,测试模型输入输出for (input_ids, attention_mask, token_type_ids, labels) in mydataloader:# 打印解码后的第一条样本文本,查看编码前的内容print(my_tokenizer.decode(input_ids[0]))# 打印各张量形状,确认输入维度print(input_ids.shape, attention_mask.shape, token_type_ids.shape, labels)# 给模型喂数据,执行前向传播,NSP任务是二分类,输入特征维度到输出二分类结果myout = mymodel(input_ids, attention_mask, token_type_ids)print('myout--->', myout.shape, myout)# 只测试一轮批次就退出循环break
# 模型训练NSP
def dm03_train_model():# 1. 加载数据集data_files = './mydatal/train.csv'mydataset = MyDataSet(data_files)# 2. 实例化下游任务模型、优化器、损失函数my_model = MyModel()my_optimizer = torch.optim.AdamW(my_model.parameters(), lr=5e-4)my_criterion = torch.nn.CrossEntropyLoss()# 3. 固定预训练模型参数(不训练预训练模型)for param in my_model_pretrained.parameters():param.requires_grad_(False)# 4. 设置训练参数epochs = 3# 设置模型为训练模式my_model.train()# 5. 外层循环:控制训练轮数for epoch_idx in range(epochs):# 实例化数据迭代器对象(每个 epoch 重新创建 DataLoader 实现打乱等)my_dataloader = DataLoader(mydataset,batch_size=8,collate_fn=collate_fn3,shuffle=True,drop_last=True)start_time = int(time.time())# 6. 内层循环:控制迭代次数(遍历一个 epoch 的数据)for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(my_dataloader):# 给模型喂数据,执行前向传播my_out = my_model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 计算损失my_loss = my_criterion(my_out, labels)# 梯度清零my_optimizer.zero_grad()# 反向传播my_loss.backward()# 梯度更新my_optimizer.step()# 每20次迭代 计算并打印一次准确率等信息(原截图是% 20 == 0,这里保持一致)if i % 20 == 0:# 获取预测类别(取概率最大的类别)out = my_out.argmax(dim=1) # 计算准确率accuracy = (out == labels).sum().item() / len(labels) print('轮次:%d 迭代数:%d 损失:%.6f 准确率:%.3f 时间:%d' % (epoch_idx, i, my_loss.item(), accuracy, int(time.time()) - start_time))# 每个轮次保存模型(模型参数、优化器状态等,按轮次命名)torch.save(my_model.state_dict(), './my_model_nsp_%d.bin' % (epoch_idx + 1))
# 模型评估函数
def dm04_evaluate_model():# 1. 实例化测试数据集对象data_files = './mydatal/train.csv' # 数据集路径mydataset = MyDataSet(data_files) # 自定义数据集类实例化# 2. 实例化下游任务模型并加载预训练好的参数path = './my_model_nsp_3.bin' # 模型参数文件路径my_model = MyModel() # 自定义模型类实例化my_model.load_state_dict(torch.load(path)) # 加载模型参数print('my_model-->', my_model) # 打印模型结构,查看加载情况# 3. 设置模型为评估模式(影响 dropout、batch_norm 等层行为)my_model.eval()# 4. 初始化评估指标correct = 0 # 正确预测的样本数量total = 0 # 参与评估的总样本数量# 5. 实例化测试集数据加载器my_loader_test = DataLoader(mydataset,batch_size=8, # 批次大小collate_fn=collate_fn3, # 数据拼接与处理函数shuffle=True, # 测试时是否打乱数据(可根据需求调整)drop_last=True # 丢弃最后不完整的批次)# 6. 遍历测试集,进行模型评估for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(my_loader_test):# 关闭梯度计算(评估阶段无需计算梯度,节省内存)with torch.no_grad():# 模型前向传播,得到预测输出my_out = my_model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)# 从预测输出中获取类别(取概率最大的类别)out = my_out.argmax(dim=1)# 更新正确预测数和总样本数correct += (out == labels).sum().item()total += len(labels)# 每 20 个批次打印一次当前准确率(可根据需求调整打印频率)if i % 20 == 0 and total != 0: # 避免 total 为 0 时除以 0 错误print(f"当前准确率: {correct / total:.4f}") # 打印准确率