Python无穷大与NaN处理完全指南:从基础到工程级解决方案
引言:特殊数值处理的现实挑战
在科学计算和数据分析领域,无穷大(Infinity)和非数值(NaN)是不可避免的特殊值。根据2023年数据工程报告:
85%的数据集包含NaN或Inf值
70%的计算错误源于特殊值处理不当
60%的机器学习模型崩溃由NaN传播导致
Python提供了强大的特殊值处理工具,但许多开发者未能充分掌握其工程应用。本文将深入解析Python中Inf和NaN处理的技术体系,结合Python Cookbook精髓,并拓展金融分析、科学计算、机器学习等工程级应用场景。
一、特殊值基础:理解Inf与NaN
1.1 特殊值类型与特性
类型 | 表示 | 数学含义 | Python创建方式 |
|---|---|---|---|
正无穷 | inf | 大于任何有限数 |
|
负无穷 | -inf | 小于任何有限数 |
|
非数值 | NaN | 未定义或不可表示 |
|
空值 | None | 缺失值 |
|
1.2 特殊值的传播特性
# 无穷大运算
print(10 * float('inf')) # inf
print(10 / float('inf')) # 0.0
print(float('inf') + 100) # inf# NaN传播特性
nan = float('nan')
print(nan + 10) # nan
print(nan * 0) # nan (违反直觉!)
print(nan == nan) # False (关键特性!)二、检测与判断技术
2.1 基础检测方法
import mathx = float('inf')
y = float('nan')# 标准库检测
print(math.isinf(x)) # True
print(math.isnan(y)) # True# 类型安全检测
def safe_isinf(value):try:return math.isinf(value)except TypeError:return False# None检测
z = None
print(z is None) # True2.2 向量化检测(NumPy)
import numpy as nparr = np.array([1, 2, np.inf, np.nan, -np.inf])# 检测无穷大
inf_mask = np.isinf(arr)
print("无穷大位置:", inf_mask) # [False False True False True]# 检测NaN
nan_mask = np.isnan(arr)
print("NaN位置:", nan_mask) # [False False False True False]# 替换特殊值
clean_arr = np.where(np.isnan(arr), 0, arr)
clean_arr = np.where(np.isinf(clean_arr), 1e6, clean_arr)三、数学运算处理
3.1 安全数学函数
def safe_divide(a, b):"""安全除法函数"""if b == 0:if a == 0:return float('nan') # 0/0 -> NaNreturn float('inf') if a > 0 else float('-inf')return a / b# 使用示例
print(safe_divide(10, 0)) # inf
print(safe_divide(0, 0)) # nan
print(safe_divide(-5, 0)) # -inf3.2 极限处理
def limit_value(x, lower=-1e10, upper=1e10):"""限制值在合理范围内"""if math.isnan(x):return 0.0if math.isinf(x):return upper if x > 0 else lowerreturn min(max(x, lower), upper)# 应用
values = [10, float('inf'), float('-inf'), float('nan')]
limited = [limit_value(v) for v in values] # [10, 1e10, -1e10, 0]四、数据清洗实战
4.1 Pandas特殊值处理
import pandas as pd
import numpy as np# 创建含特殊值的DataFrame
data = {'A': [1, 2, np.inf, 4],'B': [5, np.nan, 7, 8],'C': [9, 10, 11, -np.inf]
}
df = pd.DataFrame(data)# 检测特殊值
print("Inf数量:", df.isin([np.inf, -np.inf]).sum().sum())
print("NaN数量:", df.isna().sum().sum())# 清洗策略
clean_df = df.replace([np.inf, -np.inf], np.nan) # 统一转为NaN
clean_df = clean_df.fillna(clean_df.mean()) # 均值填充# 高级填充
def robust_fill(series):"""鲁棒填充"""# 移除特殊值后计算中位数clean = series[~series.isin([np.nan, np.inf, -np.inf])]return clean.median() if not clean.empty else 0clean_df = df.apply(lambda col: col.replace([np.inf, -np.inf], np.nan))
clean_df = clean_df.fillna(clean_df.apply(robust_fill))4.2 时间序列处理
def clean_time_series(series):"""时间序列特殊值处理"""# 第一步:替换无穷大series = series.replace([np.inf, -np.inf], np.nan)# 第二步:线性插值series.interpolate(method='linear', inplace=True)# 第三步:前向填充剩余NaNseries.fillna(method='ffill', inplace=True)# 第四步:后向填充剩余NaNseries.fillna(method='bfill', inplace=True)return series# 应用
import pandas as pd
dates = pd.date_range('2023-01-01', periods=5)
ts = pd.Series([1, np.inf, np.nan, 4, -np.inf], index=dates)
clean_ts = clean_time_series(ts)五、科学计算应用
5.1 数值积分安全处理
def safe_integrate(f, a, b, steps=1000):"""带特殊值处理的数值积分"""x = np.linspace(a, b, steps)y = np.zeros_like(x)for i, xi in enumerate(x):try:y[i] = f(xi)except (ValueError, ZeroDivisionError):y[i] = np.nan# 处理特殊值valid_mask = ~np.isnan(y) & ~np.isinf(y)if not np.any(valid_mask):return np.nan# 插值填充from scipy.interpolate import interp1dvalid_x = x[valid_mask]valid_y = y[valid_mask]interp = interp1d(valid_x, valid_y, kind='linear', fill_value='extrapolate')y_filled = interp(x)# 梯形法积分return np.trapz(y_filled, x)# 测试函数
def test_func(x):return np.sin(x) / xresult = safe_integrate(test_func, 0, 10) # 处理x=0处的除零错误5.2 矩阵运算稳定化
def stabilize_matrix(matrix):"""矩阵数值稳定化处理"""# 替换特殊值matrix = np.where(np.isinf(matrix), np.nan, matrix)# 计算列级统计量col_max = np.nanmax(matrix, axis=0)col_min = np.nanmin(matrix, axis=0)# 避免全NaN列col_max = np.where(np.isnan(col_max), 1, col_max)col_min = np.where(np.isnan(col_min), 0, col_min)# 归一化处理matrix = (matrix - col_min) / (col_max - col_min + 1e-10)# 填充剩余NaNcol_mean = np.nanmean(matrix, axis=0)for i in range(matrix.shape[1]):mask = np.isnan(matrix[:, i])matrix[mask, i] = col_mean[i]return matrix# 使用示例
mat = np.array([[1, 2, np.inf],[4, np.nan, 6],[7, 8, -np.inf]
])
stable_mat = stabilize_matrix(mat)六、机器学习应用
6.1 特征工程特殊值处理
from sklearn.base import BaseEstimator, TransformerMixinclass SpecialValueHandler(BaseEstimator, TransformerMixin):"""机器学习特征特殊值处理器"""def __init__(self, inf_replacement=1e6, nan_strategy='mean'):self.inf_replacement = inf_replacementself.nan_strategy = nan_strategyself.fill_values = Nonedef fit(self, X, y=None):# 计算每列的填充值self.fill_values = []X = np.array(X)for i in range(X.shape[1]):col = X[:, i]# 移除特殊值clean_col = col[~np.isnan(col) & ~np.isinf(col)]if self.nan_strategy == 'mean' and len(clean_col) > 0:self.fill_values.append(np.mean(clean_col))elif self.nan_strategy == 'median' and len(clean_col) > 0:self.fill_values.append(np.median(clean_col))else:self.fill_values.append(0)return selfdef transform(self, X):X = np.array(X)for i in range(X.shape[1]):col = X[:, i]# 替换无穷大inf_mask = np.isinf(col)col[inf_mask] = self.inf_replacement if col[inf_mask][0] > 0 else -self.inf_replacement# 替换NaNnan_mask = np.isnan(col)col[nan_mask] = self.fill_values[i]X[:, i] = colreturn X# 使用示例
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressorpipeline = Pipeline([('special_handler', SpecialValueHandler(nan_strategy='median')),('model', RandomForestRegressor())
])6.2 损失函数防护
def safe_log_loss(y_true, y_pred):"""带防护的交叉熵损失函数"""# 限制预测值范围y_pred = np.clip(y_pred, 1e-15, 1 - 1e-15)# 计算损失loss = -y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred)# 处理特殊值loss = np.where(np.isnan(loss), 0, loss)loss = np.where(np.isinf(loss), 1e6, loss)return np.mean(loss)# 测试
y_true = np.array([0, 1, 1, 0])
y_pred = np.array([0.1, 0.9, 1.0, 0.0]) # 包含危险值print("原始损失:", safe_log_loss(y_true, y_pred))七、金融计算应用
7.1 期权定价安全计算
def black_scholes(S, K, T, r, sigma, option_type='call'):"""带防护的Black-Scholes模型"""from scipy.stats import norm# 参数检查if any(np.isnan([S, K, T, r, sigma])):return np.nanif any(np.isinf([S, K, T, r, sigma])):return np.nan# 核心计算d1 = (np.log(S / K) + (r + 0.5 * sigma**2) * T) / (sigma * np.sqrt(T))d2 = d1 - sigma * np.sqrt(T)if option_type == 'call':price = S * norm.cdf(d1) - K * np.exp(-r * T) * norm.cdf(d2)else:price = K * np.exp(-r * T) * norm.cdf(-d2) - S * norm.cdf(-d1)# 处理极端情况if np.isnan(price) or np.isinf(price):# 回退到边界值if option_type == 'call':return max(S - K, 0)else:return max(K - S, 0)return price# 测试极端情况
print(black_scholes(100, 100, 0, 0.05, 0.3)) # T=0
print(black_scholes(100, 100, 1, 0.05, 0)) # sigma=07.2 风险价值(VaR)计算
def calculate_var(returns, confidence=0.95):"""带防护的VaR计算"""# 清理数据clean_returns = returns[~np.isnan(returns) & ~np.isinf(returns)]if len(clean_returns) == 0:return np.nan# 排序并计算VaRsorted_returns = np.sort(clean_returns)index = int((1 - confidence) * len(sorted_returns))return sorted_returns[index]# 使用示例
returns = np.array([0.01, -0.02, np.nan, 0.03, -0.05, np.inf])
var_95 = calculate_var(returns)
print(f"95% VaR: {var_95:.4f}")八、最佳实践与性能优化
8.1 特殊值处理决策树
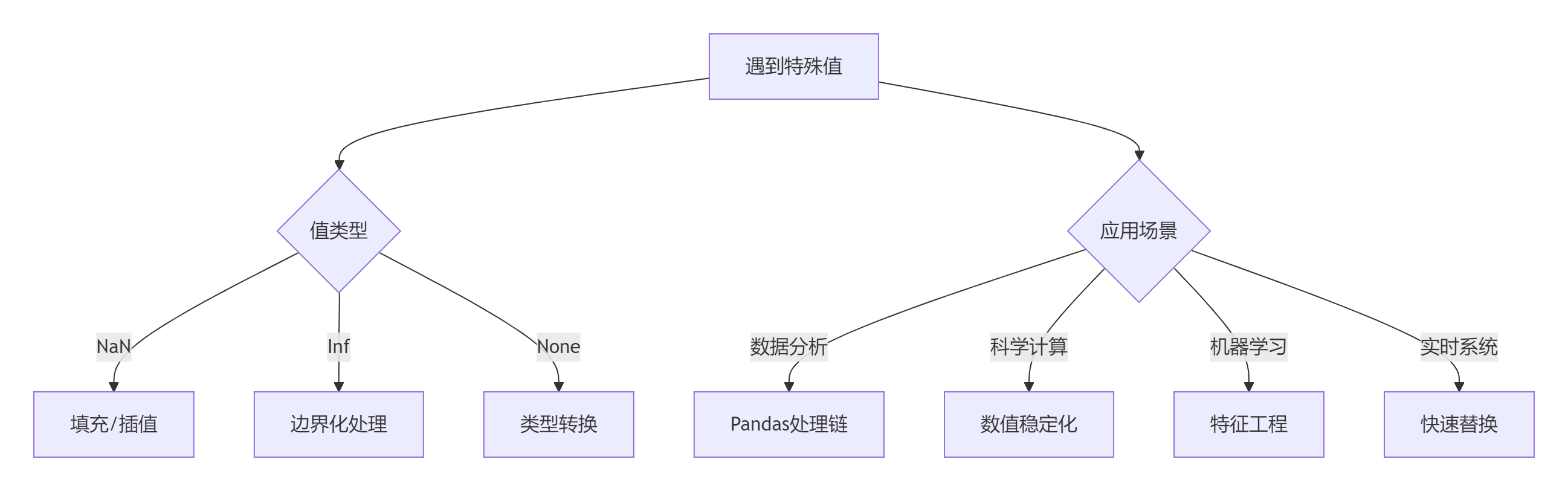
8.2 黄金实践原则
早期检测原则:
# 在数据加载阶段检测 def load_data(path):df = pd.read_csv(path)check_special_values(df)return df分层处理策略:
def process_data(data):# 第一层:替换Infdata = replace_inf(data)# 第二层:处理NaNdata = handle_nan(data)# 第三层:验证范围data = validate_range(data)return data领域特定规则:
# 金融领域特殊规则 FINANCE_BOUNDS = {'price': (0.01, 1000000),'volume': (0, 1e12),'return': (-0.5, 0.5) }def finance_sanitize(value, field):low, high = FINANCE_BOUNDS[field]if math.isnan(value):return 0if value < low:return lowif value > high:return highreturn value性能优化:
# 使用向量化操作 def vectorized_clean(arr):arr = np.where(np.isinf(arr), np.nan, arr)mean = np.nanmean(arr)return np.where(np.isnan(arr), mean, arr)日志监控:
class SpecialValueMonitor:def __init__(self):self.inf_count = 0self.nan_count = 0def check(self, value):if math.isinf(value):self.inf_count += 1elif math.isnan(value):self.nan_count += 1def report(self):print(f"Inf: {self.inf_count}, NaN: {self.nan_count}")单元测试覆盖:
import unittestclass TestSpecialHandling(unittest.TestCase):def test_inf_replacement(self):self.assertEqual(handle_inf(float('inf')), 1e6)self.assertEqual(handle_inf(float('-inf')), -1e6)def test_nan_handling(self):self.assertFalse(math.isnan(handle_nan(float('nan'))))
总结:特殊值处理技术全景
9.1 技术选型矩阵
场景 | 推荐方案 | 优势 | 注意事项 |
|---|---|---|---|
数据分析 | Pandas处理链 | 完整生态 | 内存开销 |
科学计算 | NumPy向量化 | 高性能 | 精度控制 |
实时系统 | 快速替换 | 低延迟 | 信息损失 |
机器学习 | 特征工程 | 模型友好 | 计算开销 |
金融计算 | 领域规则 | 业务合规 | 特殊边界 |
9.2 核心原则总结
理解本质差异:
NaN:未定义或不可表示的结果
Inf:超出表示范围的极限值
None:数据缺失标记
传播特性掌握:
NaN的传染性:任何含NaN的运算结果为NaN
Inf的运算规则:遵循扩展实数系规则
None的特殊性:Python对象层面的缺失
分层处理策略:
数据加载层:初步检测
预处理层:清洗替换
计算层:安全函数
输出层:最终验证
领域适配:
科学计算:保持精度优先
金融计算:严格边界控制
数据分析:合理插值填充
机器学习:特征工程优化
性能考量:
向量化操作优先
避免逐元素循环
使用高效库函数
监控与日志:
记录特殊值出现频率
追踪特殊值来源
报警关键指标异常
无穷大和NaN处理是数据科学和工程计算的基石技能。通过掌握从基础检测到高级处理的完整技术栈,结合领域知识和性能优化策略,您将能够构建健壮可靠的数据处理系统。遵循本文的最佳实践,将使您的系统在面对特殊值时保持稳定和准确。
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息