自然语言处理——06 迁移学习(中)
1 迁移学习及相关概念
-
迁移学习(Transfer Learning)
- 利用在一个任务上学到的知识来改善在另一个相关任务上的性能,让模型在新任务里少走弯路、表现更好;
- 释义:就是把已经学习到的知识迁移到另外一个地方,形象比喻成迁移学习
-
迁移学习的形式很多:
-
特征迁移:将在一个任务上训练的模型的一部分(如词嵌入或者更高层的特征)应用于另一个任务;
-
模型迁移:直接搬整个模型,再微调适配新任务;
-
知识迁移:将从源任务中学到的知识(例如,词嵌入、模型参数等)应用于目标任务。
-
-
相关术语
-
预训练模型(Pretrained Model):
- 一般情况下是大而全的基础模型,靠海量数据练出来,自带通用知识;
- 特点:网络复杂,参数多,需要大量的数据进行训练;
- 在NLP领域,预训练模型往往是语言模型,语言模型又是许多典型NLP任务的基础,如机器翻译、文本生成、阅读理解等;
- 常见预训练模型 BERT、GPT、roBERTa、transformer-XL
-
微调(Fine - tuning):
- 微调的对象:预训练模型;
- 微调的方式:1、微调预训练模型的参数;2、增加1层或2层输出结构再用小批量标准数据进行重新训练;
- 微调的目标:让模型更加适应特性任务;
-
-
迁移学习的两种迁移方式
-
开箱即用型:直接用预训练模型做同类任务,不用改结构或参数,这种情况一般只适用于普适任务。比如fasttext里的词向量模型,拿来直接做文本相似度计算,因为模型开发者已经做好通用适配;
为什么可以开箱即用?
是因为模型提前做了支持。模型开发者为了达到开箱即用的效果,将模型结构分各个部分保存为不同的预训练模型,提供对应的加载方法来完成特定目标;
比如 BERT 模型里面就分为:文本特征抽取、文本分类、命名实体识别、阅读理解等;
-
微调改造型:继承预训练模型,再微调参数或加结构、用小数据重训。适合任务有差异的场景,比如拿通用语言模型,微调后做电商行业的客服对话生成,用少量行业数据让模型“更懂行”。
-
2 NLP 常见预训练模型
2.1 NLP 常见预训练模型分类
- 自回归语言模型(Auto Regressive Language Model AR)
- 主要做文本语言生成。比如:已知abcdef,来生成g;
- 是根据上文内容预测下一个可能的单词,就是常说的自左向右的语言模型任务;
- 优点:从左向右的生成内容,能匹配很多自然语言任务。比如生成类的NLP任务:文本摘要,机器翻译等;
- 缺点:只能利用上文或者下文的信息,不能同时利用上文和下文的信息;
- 例子:GPT、GPT2、Transformer-XL、XLNET……
- 自编码语言模型(Auto Encoder Language Model AE)
- 主要适合做语言理解。比如:阅读理解、完型填空、提取句子特征做分类等;
- 自编码语言模型是对输入的句子随机Mask其中的单词,根据上下文单词来预测这些被Mask掉的单词;
- 优点:它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文;
- 缺点:训练时使用Mask标记,推理时不使用Mask规则,规则不一致对模型有影响;
- 例子:BERT、ALBERT、RoBERTa、ELECTRA……
- Seq2Seq编码和解码混合类型的语言模型
- 既可以做文本理解任务,也可以做文本生成任务;
- 工作方式:编码和解码相互结合的方式。比如:文本摘要任务,一般是要先编码,然后再解码生成摘要;
- 优点:能拥有编码模型和解码模型的两种功能;
- 缺点:模型会变得比较大
- 例子:BART、Pegasus、T5……
2.2 NLP 常见预训练模型
-
BERT及其变体
- bert-base-uncased:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在小写的英文文本上进行训练而得到;
- bert-large-uncased:编码器具有24个隐层,输出1024维张量,16个自注意力头,共340M参数量,在小写的英文文本上进行训练而得到;
- bert-base-cased:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在不区分大小写的英文文本上进行训练而得到;
- bert-large-cased:编码器具有24个隐层,输出1024维张量,16个自注意力头,共340M参数量,在不区分大小写的英文文本上进行训练而得到;
- bert-base-multilingual-uncased:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在小写的102种语言文本上进行训练而得到;
- bert-large-multilingual-uncased:编码器具有24个隐层,输出1024维张量,16个自注意力头,共340M参数量,在小写的102种语言文本上进行训练而得到;
- bert-base-chinese:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在简体和繁体中文文本上进行训练而得到;
-
GPT
- penai-gpt:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,由OpenAI在英文语料上进行训练而得到;
-
GPT-2及其变体
- gpt2:编码器具有12个隐层,输出768维张量,12个自注意力头,共117M参数量,在OpenAI GPT-2英文语料上进行训练而得到;
- gpt2-xl:编码器具有48个隐层,输出1600维张量,25个自注意力头,共1558M参数量,在大型的OpenAI GPT-2英文语料上进行训练而得到;
-
Transformer-XL
- transformer-xl-wt103:编码器具有18个隐层,输出1024维张量,16个自注意力头,共257M参数量,在wikitext-103英文语料进行训练而得到;
-
XLNet及其变体
- xlnet-base-cased:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在英文语料上进行训练而得到;
- xlnet-large-cased:编码器具有24个隐层,输出1024维张量,16个自注意力头,共240参数量,在英文语料上进行训练而得到;
-
XLM
- xlm-mlm-en-2048:编码器具有12个隐层,输出2048维张量,16个自注意力头,在英文文本上进行训练而得到;
-
RoBERTa及其变体
- roberta-base:编码器具有12个隐层,输出768维张量,12个自注意力头,共125M参数量,在英文文本上进行训练而得到;
- roberta-large:编码器具有24个隐层,输出1024维张量,16个自注意力头,共355M参数量,在英文文本上进行训练而得到;
-
DistilBERT及其变体 (知识蒸馏的BERT模型)
- distilbert-base-uncased:基于bert-base-uncased的蒸馏(压缩)模型,编码器具有6个隐层,输出768维张量,12个自注意力头,共66M参数量;
- distilbert-base-multilingual-cased:基于bert-base-multilingual-uncased的蒸馏(压缩)模型,编码器具有6个隐层,输出768维张量,12个自注意力头,共66M参数量;
-
ALBERT (小的bert模型,参数每一层公用)
- albert-base-v1:编码器具有12个隐层,输出768维张量,12个自注意力头,共125M参数量,在英文文本上进行训练而得到;
- albert-base-v2:编码器具有12个隐层,输出768维张量,12个自注意力头,共125M参数量,在英文文本上进行训练而得到,相比v1使用了更多的数据量,花费更长的训练时间;
-
T5模型
- t5-small:编码器具有6个隐层,输出512维张量,8个自注意力头,共60M参数量,在C4语料上进行训练而得到;
- t5-base:编码器具有12个隐层,输出768维张量,12个自注意力头,共220M参数量,在C4语料上进行训练而得到;
- t5-large:编码器具有24个隐层,输出1024维张量,16个自注意力头,共770M参数量,在C4语料上进行训练而得到;
-
XLM-RoBERTa及其变体
- xlm-roberta-base:编码器具有12个隐层,输出768维张量,8个自注意力头,共125M参数量,在2.5TB的100种语言文本上进行训练而得到
- xlm-roberta-large:编码器具有24个隐层,输出1027维张量,16个自注意力头,共355M参数量,在2.5TB的100种语言文本上进行训练而得到
2.3 说明
- 所有上述预训练模型及其变体都是以Transformer为基础,只是在模型结构如神经元连接方式、编码器隐层数、多头注意力的头数等发生改变;
- 要根据不同的任务类型,不同的数据集选择不同的模型;
- 因此,对于工程落地而言,不需要从理论上深度探究这些预训练模型的结构设计的优劣,只需要在自己处理的目标数据上,尽量遍历所有可用的模型对比得到最优效果即可。
3 Hugging Face Transformers库的使用
3.1 简介
-
Hugging Face Transformers库是基于 Transformer 架构的开源工具库,专门聚焦 NLP 领域;
- Transformers 提供了NLP领域大量目前最优的(SOTA,State-Of-The-Art)的预训练语言模型和调用框架;
- 它支持 Pytorch和Tensorflow2.0,并且支持两个框架的相互转换;
-
Hugging Face 总部位于纽约,是一家专注于自然语言处理、人工智能和分布式系统的创业公司
- 他们所提供的聊天机器人技术一直颇受欢迎,但更出名的是他们在NLP开源社区上的贡献;
- Hugging Face 一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上 SOTA 的NLP技术,而非困窘于训练资源的匮乏;
-
Hugging Face 社区地址:Hugging Face – The AI community building the future.;
- 点击 Models 链接可查看、下载预训练模型;
- 点击 Datasets 链接可查看、下载数据集;
- 点击 Docs 链接可以阅读预训练模型的编程文档;
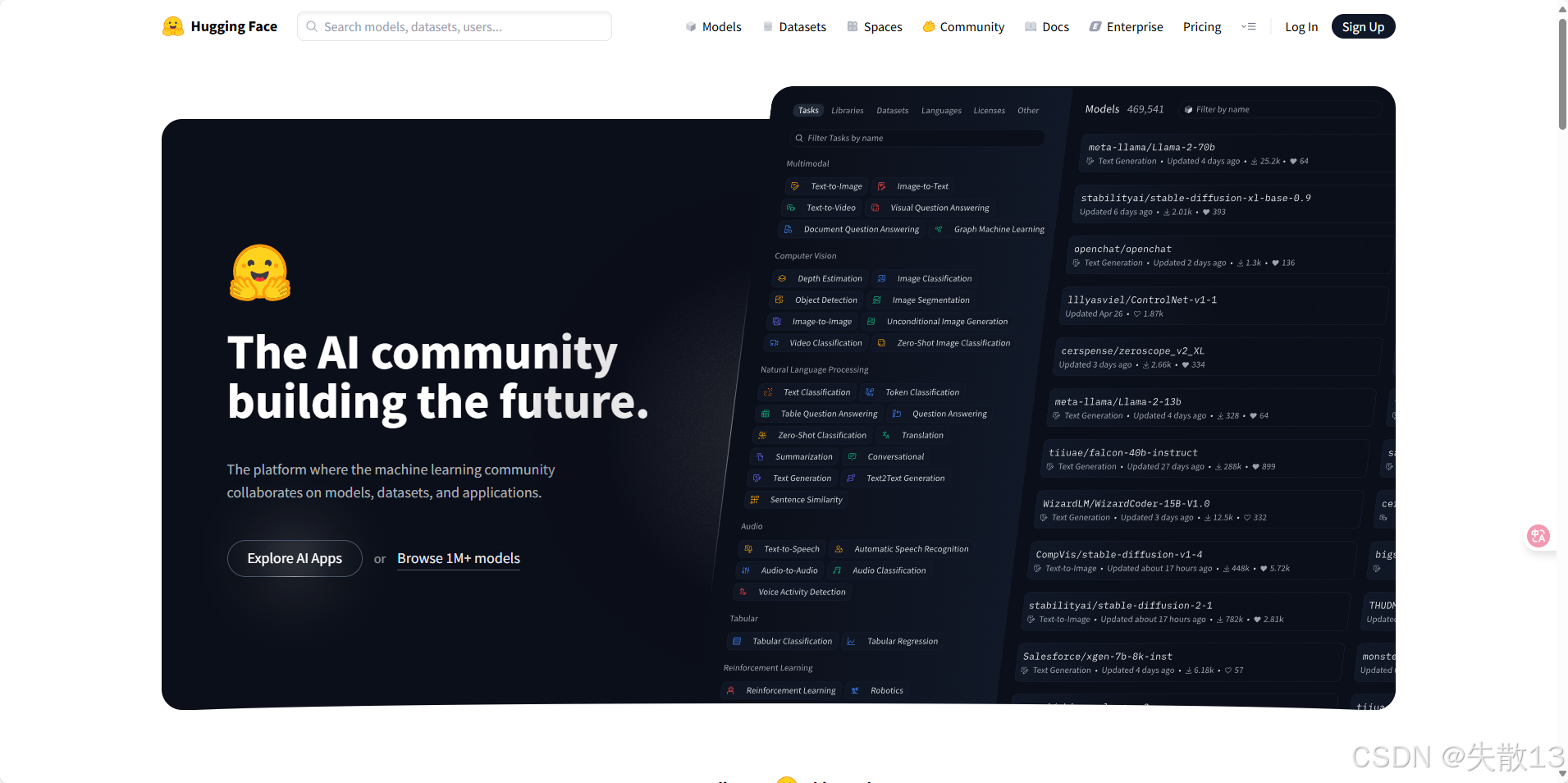
3.2 Transformers库的三层应用结构
-
Transformers库把 NLP 任务的模型调用,分成简单→进阶→专业三层,让初学者能快速上手,专业人士也能精细调参,覆盖从跑通流程到深度定制的需求;
-
管道(Pipeline):最傻瓜式,一行代码解决问题
- 特点:高度集成的极简使用方式,只需要几行代码即可实现一个NLP任务;
- 适合人群:纯新手、想快速验证想法的人,不用懂模型细节,会调用 API 就行;
- 例子:比如做情感分析,直接用
pipeline("sentiment - analysis"),传文本进去,直接出结果,底层模型、数据处理全帮你做好了;
-
自动模型(AutoModel):选好模板,适配任务
- 特点:需指定任务类型(分类、摘要等),模型会按任务规则,自动适配输入输出格式,比 Pipeline 灵活点,能选具体模型家族(BERTology 系列);
- 适合人群:有基础的开发者,想选特定模型系列,又不想纠结太细的参数;
- 例子:做文本分类,选
AutoModelForSequenceClassification,指定用 BERT 模型,它会自动调好结构,接你的数据训练 / 推理;
-
具体模型(SpecificModel):精细操控,深度定制
- 特点:需明确指定具体模型(BERT、GPT - 2 等),还要调模型内部参数(词嵌入、层结构),灵活度拉满,但得懂模型细节;
- 适合人群:专业算法工程师、做前沿研究的人,要对模型深度改造,适配特殊任务;
- 例子:直接用
BertForPreTraining,改它的预训练参数、调整网络层,给模型 “动手术”,让它精准适配业务(比如行业专属文本处理);
-
-
文档:transformers/i18n/README_zh-hans.md at main · huggingface/transformers · GitHub;
-
安装:
conda install conda-forge::transformers
3.3 管道
3.3.1 文本分类任务Text Classification
-
文本分类是指模型可以根据文本中的内容来进行分类。例如:根据内容对情绪进行分类、根据内容对商品分类等;
-
文本分类模型一般是通过有监督训练得到的。对文本内容的具体分类,依赖于训练时所使用的样本标签;
-
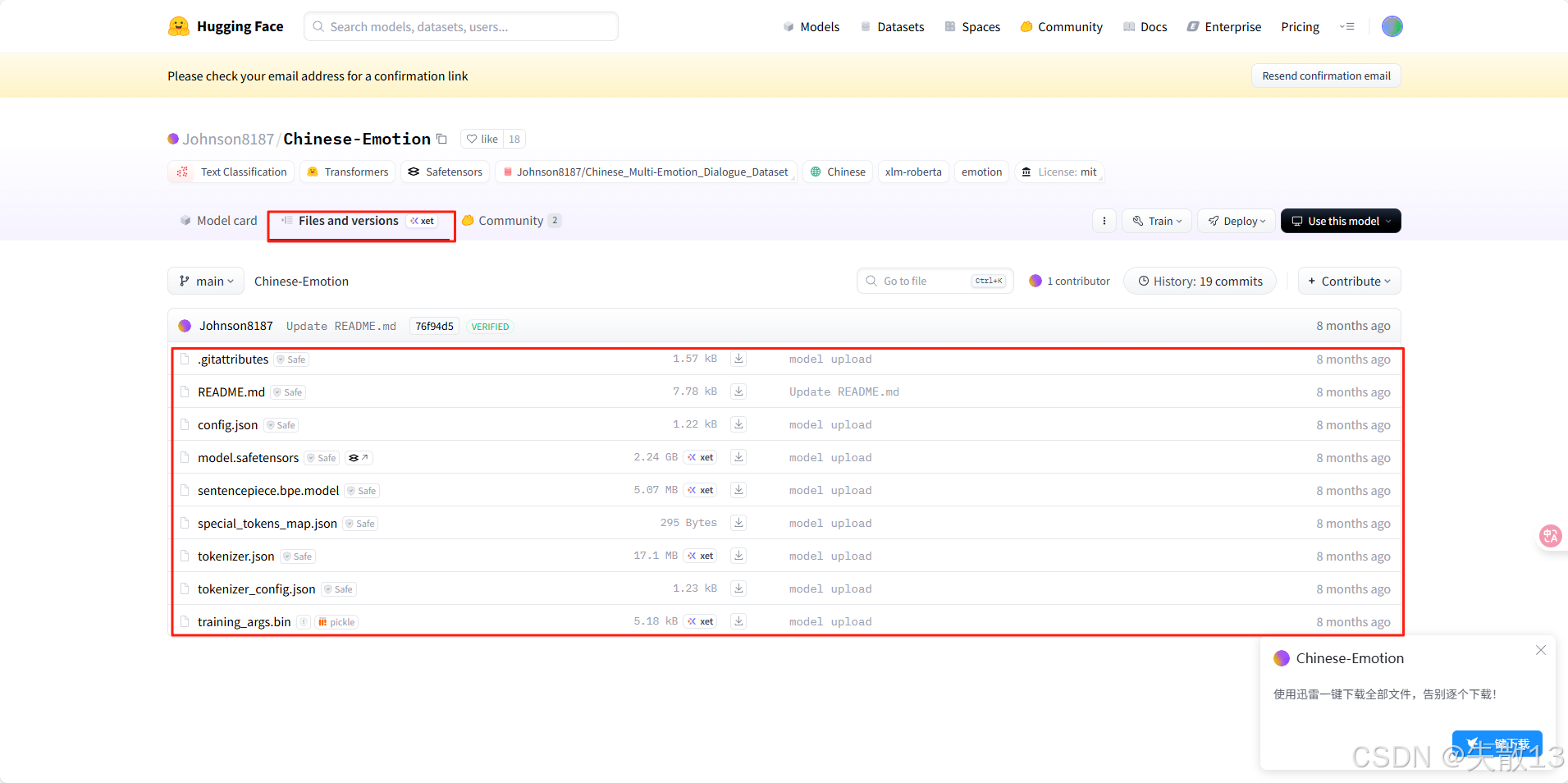
查找需要的模型:
-
在 Hugging Face 网页上可以试用:
-
将模型下载下来:
-
使用:
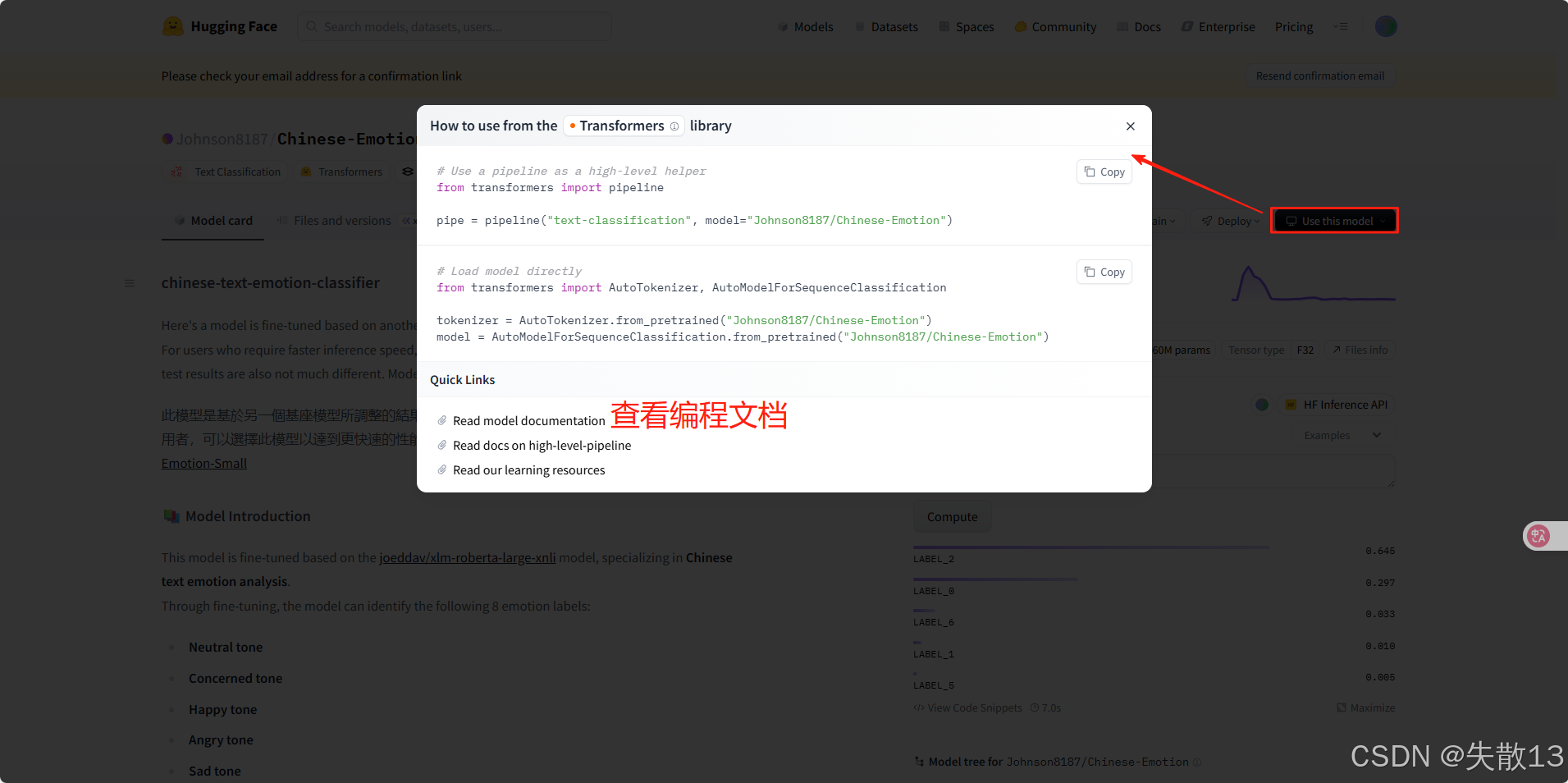
-
代码实现:
from transformers import pipeline import numpy as np# 文本分类任务Text Classification # 可能因为版本兼容性问题需要安装:pip install tf-keras model = pipeline("text-classification", model="huggingface_model/Chinese-Emotion") model('我爱北京天安门,天安门上太阳升。')
3.3.2 特征提取任务Feature Extraction
-
用预训练模型,把文本转成数值特征,这些特征是模型理解文本的中间结果,能给后续任务(分类、聚类等)当原材料,本身不直接出任务结果;
-
代码实现:
# 特征提取任务Feature Extraction model = pipeline("feature-extraction", model="huggingface_model/bert-base-chinese") output = model('人生该如何起头') print(type(output), np.array(output).shape)
- 特征格式:1 条数据,9 个 token,每个 token 对应 768 维特征;
- 1:代表输入是 1 条文本(批量处理时,数量会变多);
- 9:
- 文本处理后变成 9 个 token(不是原文本的 7 个字);
- 原因是模型在处理文本时,会自动加特殊标记:
[CLS](开头,代表整句特征) + 原文本 token(“人”“生”…“头” ) +[SEP](结尾,分隔标记),所以 7 字 → 9 个 token([CLS] 人 生 该 如 何 起 头 [SEP]);
- 768:BERT-base 模型的特征维度,每个 token 会被转成 768 维的数值向量,代表模型对这个 token 的理解;
-
延伸知识:
- 不带任务头 VS 带任务头:
- 特征提取是不带任务头,只输出通用特征;
- 像文本分类、完形填空,属于带任务头,模型会在特征基础上,加专门的输出层(分类头、填空头),直接出任务结果(比如情感标签、填空答案)。
- 不带任务头 VS 带任务头:
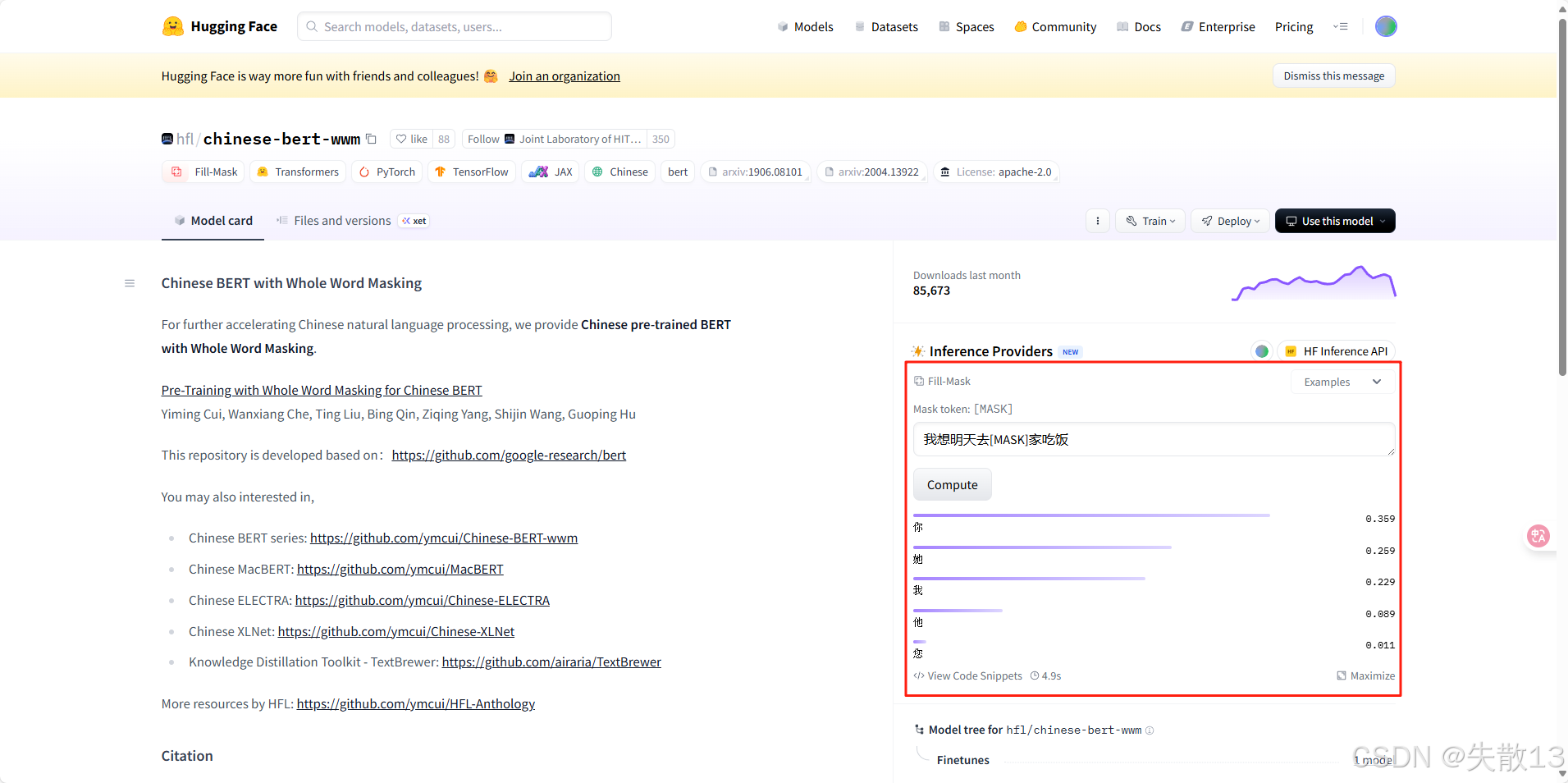
3.3.3 完型填空任务Fill-Mask
-
代码实现:
# 完型填空任务Fill-Mask model = pipeline("fill-mask", model="huggingface_model/chinese-bert-wwm") model('我想明天去[MASK]家吃饭')[{'score': 0.3592354953289032,'token': 872,'token_str': '你','sequence': '我 想 明 天 去 你 家 吃 饭'},{'score': 0.25940409302711487,'token': 1961,'token_str': '她','sequence': '我 想 明 天 去 她 家 吃 饭'},{'score': 0.22949208319187164,'token': 2769,'token_str': '我','sequence': '我 想 明 天 去 我 家 吃 饭'},{'score': 0.08896282315254211,'token': 800,'token_str': '他','sequence': '我 想 明 天 去 他 家 吃 饭'},{'score': 0.010735985822975636,'token': 2644,'token_str': '您','sequence': '我 想 明 天 去 您 家 吃 饭'}]
3.3.4 阅读理解任务Question Answering
-
阅读理解任务又称为“抽取式问答任务”,即输入一段文本和一个问题,让模型输出结果;
-
代码实现:
# 阅读理解任务Question Answering # 问答语句 context = '我叫张三,我是一个程序员,我的喜好是打篮球。' questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?'] model = pipeline('question-answering', model='huggingface_model/chinese_pretrain_mrc_roberta_wwm_ext_large') print(model(context=context, question=questions))[{'score': 1.2072212804067894e-12, 'start': 2, 'end': 4, 'answer': '张三'},{'score': 2.6090071969520068e-06, 'start': 9, 'end': 12, 'answer': '程序员'},{'score': 4.168756007061347e-08, 'start': 18, 'end': 21, 'answer': '打篮球'} ]score:模型对该答案的置信度分数(数值越大置信度越高)start和end:答案在原文中的起始和结束位置(字符级别)answer:提取的答案文本
3.3.5 文本摘要任务Summarization
-
输入是一段文字,输出是一段概况、简单的文字;
-
代码实现:
# 文本摘要任务Summarization model = pipeline('summarization', model='huggingface_model/distilbart-cnn-12-6') text = "BERT is a transformers model pretrained on a large corpus of English data " \ "in a self-supervised fashion. This means it was pretrained on the raw texts " \ "only, with no humans labelling them in any way (which is why it can use lots " \ "of publicly available data) with an automatic process to generate inputs and " \ "labels from those texts. More precisely, it was pretrained with two objectives:Masked " \ "language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \ "words in the input then run the entire masked sentence through the model and has " \ "to predict the masked words. This is different from traditional recurrent neural " \ "networks (RNNs) that usually see the words one after the other, or from autoregressive " \ "models like GPT which internally mask the future tokens. It allows the model to learn " \ "a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \ " concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \ "sentences that were next to each other in the original text, sometimes not. The model then " \ "has to predict if the two sentences were following each other or not." model(text)
3.3.6 NER 任务Token Classification
-
实体词识别(NER)任务是NLP中的基础任务。它用于识别文本中的人名(PER)、地名(LOC)、组织(ORG)以及其他实体(MISC)等;
-
例如:王(B-PER)、小(I-PER)、明(I-PER)、在(O)、办(B-LOC)、公(I-LOC)、室(I-LOC);
- 其中O表示一个非实体,B表示一个实体的开始,I表示一个实体块的内部。
-
实体词识别本质上是一个分类任务(又叫序列标注任务),实体词识别是句法分析的基础,而句法分析优势NLP任务的核心;
-
代码实现:
# NER 任务Token Classification model = pipeline('ner', model='huggingface_model/roberta-base-finetuned-cluener2020-chinese') model('我爱北京天安门,天安门上太阳升。')[{'entity': 'B-address','score': np.float32(0.86893946),'index': 3,'word': '北','start': 2,'end': 3},{'entity': 'I-address','score': np.float32(0.81952566),'index': 4,'word': '京','start': 3,'end': 4},{'entity': 'I-address','score': np.float32(0.47017276),'index': 5,'word': '天','start': 4,'end': 5},{'entity': 'I-address','score': np.float32(0.7396459),'index': 6,'word': '安','start': 5,'end': 6},{'entity': 'I-address','score': np.float32(0.68122023),'index': 7,'word': '门','start': 6,'end': 7},{'entity': 'B-address','score': np.float32(0.55431896),'index': 9,'word': '天','start': 8,'end': 9},{'entity': 'I-address','score': np.float32(0.46039915),'index': 10,'word': '安','start': 9,'end': 10},{'entity': 'I-address','score': np.float32(0.43023294),'index': 11,'word': '门','start': 10,'end': 11}]
3.4 自动模型
3.4.1 “Auto”工具
- Hugging Face 搞了一套**“Auto” 工具**(
AutoConfig、AutoTokenizer、AutoModel等),核心是 “自动适配模型” :不管你用 BERT、GPT 还是其他预训练模型,用 Auto 系列能自动识别、加载对应的分词器、模型结构,不用手动区分模型类型,大大简化开发; - 基础工具:
AutoConfig:加载模型的配置(参数、架构信息),比如你想改模型的隐藏层数量,就用它调;AutoTokenizer:自动加载模型对应的分词器(把文本拆成模型能懂的 token),不同模型分词规则不同(BERT 用 WordPiece,GPT 用 Byte-Pair Encoding),AutoTokenizer 会自动匹配;encode()处理文本:return_tensors='pt':输出 PyTorch 的张量(torch.Tensor),方便丢给模型训练;不加这个参数,默认输出列表(list);padding='max_length':文本长度不够时,自动补全到最大长度(打 padding ),让 batch 里的文本长度统一,模型好处理;
AutoModel:加载基础预训练模型(只输出特征,不带具体任务);
- 任务专用模型:
AutoModelForSequenceClassification:带**“文本分类”任务头**的模型(比如情感分析、垃圾邮件分类),直接输出分类结果;AutoModelForMaskedLM:带**“掩码语言建模”任务头**的模型(比如 BERT 填空任务,预测被遮住的词);AutoModelForQuestionAnswering:带**“问答任务头”**的模型(从文本里找问题答案);AutoModelForSeq2SeqLM:带**“序列到序列”任务头**的模型(比如翻译、文本摘要,输入一个序列,输出另一个序列);AutoModelForTokenClassification:带**“token 分类”任务头**的模型(比如命名实体识别,给每个词标标签:人名、地名)。
3.4.2 文本分类任务Text Classification
-
导包:
import torch from transformers import AutoConfig, AutoModel, AutoTokenizer from transformers import AutoModelForSequenceClassification, AutoModelForMaskedLM, AutoModelForQuestionAnswering from transformers import AutoModelForSeq2SeqLM, AutoModelForTokenClassification -
代码实现:
# 1 加载分词器 tokenizer = AutoTokenizer.from_pretrained("huggingface_model/Chinese-Emotion") # 2 加载带“分类头”的模型 model = AutoModelForSequenceClassification.from_pretrained("huggingface_model/Chinese-Emotion") # 3 要转换成张量的文本 message = '人生该如何起头' # 3-1 return_tensors='pt',返回是二维tensor msg_tensor1 = tokenizer.encode(text=message, return_tensors='pt', # 输出 PyTorch 张量(二维)padding=True, # 补全到同长度truncation=True, # 超长截断max_length=20 # 最大长度 ) print('msg_tensor1--->', msg_tensor1) # 3-2 不用return_tensors='pt',是一维列表 msg_list2 = tokenizer.encode(text=message, padding=True, truncation=True, max_length=20) print('msg_list2--->', msg_list2) # 再转 PyTorch 张量(手动包成二维,模型要求输入是 batch 形式) msg_tensor2 = torch.tensor([msg_list2]) print('msg_tensor2--->', msg_tensor2) # 4 将数据送给模型。切换到推理模式(关闭 dropout 等训练用的层) model.eval() # 方式 1:默认返回字典(含 logits、loss 等,方便看结果) output1 = model(msg_tensor2) print('情感分类模型头输出outpout1--->', output1) output2 = model(msg_tensor2, return_dict=False) # 方式 2:返回元组(适合需要原始输出的场景) print('情感分类模型头输出outpout2--->', output2)在 Python 中,
**是字典解包运算符,在output = model(** input)中的作用是:将input字典中的键值对,以关键字参数的形式传递给model函数;msg_tensor1---> tensor([[ 0, 6, 13599, 4941, 5733, 2797, 3878, 2]]) msg_list2---> [0, 6, 13599, 4941, 5733, 2797, 3878, 2] msg_tensor2---> tensor([[ 0, 6, 13599, 4941, 5733, 2797, 3878, 2]]) 情感分类模型头输出outpout1---> SequenceClassifierOutput(loss=None, logits=tensor([[ 0.6293, 1.7759, -0.6120, -1.6538, 0.2759, 2.7990, 0.8231, -2.5783]],grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None) 情感分类模型头输出outpout2---> (tensor([[ 0.6293, 1.7759, -0.6120, -1.6538, 0.2759, 2.7990, 0.8231, -2.5783]],grad_fn=<AddmmBackward0>),)0是[CLS](句子开头标记 ),2是[SEP](句子结尾标记 ),中间是分词后的 token ID,模型靠这些 ID 理解文本;logits是模型输出的原始分数(还没转成概率),每个数值对应一个情感类别(比如第 0 类、第 1 类…),分数越高,模型认为文本属于该类的可能性越大;- 第二种输出是只返回
logits张量,更简洁,适合自己后续处理(比如手动转概率、选最大分数的类别)。
3.4.3 特征提取任务Feature Extraction
# 特征提取任务Feature Extraction
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path='huggingface_model/bert-base-chinese')
model = AutoModel.from_pretrained(pretrained_model_name_or_path='huggingface_model/bert-base-chinese')
message = ['你是谁', '人生该如何起头']
msgs_tensor = tokenizer.encode_plus(text=message, return_tensors='pt', truncation=True, padding="max_length",max_length=30)
print('msgs_tensor--->\n', msgs_tensor)
model.eval()
output = model(**msgs_tensor)
print('不带模型头输出output--->\n', output)
print('outputs.last_hidden_state.shape--->\n', output.last_hidden_state.shape) # torch.Size([1, 30, 768])
print('outputs.pooler_output.shape--->\n', output.pooler_output.shape) # torch.Size([1, 768])
msgs_tensor--->{'input_ids': tensor([[ 101, 872, 3221, 6443, 102, 782, 4495, 6421, 1963, 862, 6629, 1928,102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0]])}
不带模型头输出output--->BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.7001, 0.4651, 0.2427, ..., 0.5753, -0.4330, 0.1878],[ 0.4017, 0.1123, 0.4482, ..., -0.2614, -0.2649, -0.1497],[ 1.2000, -0.4859, 1.1970, ..., 0.7543, -0.2405, -0.2627],...,[ 0.2074, 0.4022, -0.0448, ..., -0.0849, -0.0766, -0.2134],[ 0.0879, 0.2482, -0.2356, ..., 0.2967, -0.2357, -0.5138],[ 0.4944, 0.1340, -0.2387, ..., 0.2375, -0.1011, -0.3314]]],grad_fn=<NativeLayerNormBackward0>), pooler_output=tensor([[ 0.9996, 1.0000, 0.9995, 0.9412, 0.8629, 0.9592, -0.8144, -0.9654,0.9892, -0.9997, 1.0000, 0.9998, -0.1187, -0.9373, 0.9999, -1.0000,...,-0.9967, 1.0000, 0.8626, -0.9993, -0.9704, -0.9993, -0.9971, 0.8522]],grad_fn=<TanhBackward0>), hidden_states=None, past_key_values=None, attentions=None, cross_attentions=None)
outputs.last_hidden_state.shape--->torch.Size([1, 30, 768])
outputs.pooler_output.shape--->torch.Size([1, 768])
-
msgs_tensor:文本处理后的张量。包含模型能理解的编码后的数据,比如:input_ids:包括[CLS](开头标记 )、[SEP](结尾标记 )和文本分词后转成的 token ID;token_type_ids:区分不同句子(比如两条文本,第一条标0,第二条标1),BERT 用它理解句子边界。后面的0表示按照编码要求padding="max_length"和max_length=30补充;attention_mask:标记哪些是真实文本(1)、哪些是补的 padding(0),模型注意力机制靠它忽略无效 padding;
-
output:模型输出的特征。BERT 处理文本后,输出两种关键特征:-
last_hidden_state(token 级特征)-
形状:
torch.Size([2, 30, 768])→ 2 条文本,每条补全到 30 个 token,每个 token 用 768 维向量表示; -
含义:每个 token 的特征,能体现每个字 / 词在句子中的语义(比如“你”“是”“谁”各自的向量),适合 token 级任务(命名实体识别、分词);
-
-
pooler_output(句子级特征)-
形状:
torch.Size([2, 768])→ 2 条文本,每条用 768 维向量概括整个句子的语义; -
含义:句子整体的特征,是
[CLS]位置的向量经过池化(pooler )后的结果,适合句子级任务(文本分类、相似度)。
-
-
3.4.4 完型填空任务Fill-Mask
# 完型填空任务Fill-Mask
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path='huggingface_model/chinese-bert-wwm')
model = AutoModelForMaskedLM.from_pretrained(pretrained_model_name_or_path='huggingface_model/chinese-bert-wwm')
input = tokenizer.encode_plus('我想明天去[MASK]家吃饭.', return_tensors='pt')
print('input--->\n', input)
model.eval()
output = model(**input)
print('output--->\n', output)
print('output.logits--->\n', output.logits.shape) # [1,12,21128]
mask_pred_idx = torch.argmax(output.logits[0][6]).item()
print('打印概率最高的字:', tokenizer.convert_ids_to_tokens([mask_pred_idx]))
input--->{'input_ids': tensor([[ 101, 2769, 2682, 3209, 1921, 1343, 103, 2157, 1391, 7649, 119, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
output--->MaskedLMOutput(loss=None, logits=tensor([[[ -9.9017, -9.6006, -9.8032, ..., -7.9744, -7.7402, -8.2912],[-14.3878, -15.0353, -14.7893, ..., -10.0437, -10.5279, -9.7544],[-14.2215, -14.1145, -14.5770, ..., -6.3246, -4.1784, -4.6072],...,[-14.6938, -16.8133, -15.1296, ..., -9.2327, -8.1931, -15.2430],[-10.8649, -11.4887, -11.5731, ..., -6.5378, -0.8715, -5.3870],[-11.8495, -11.8358, -12.0314, ..., -8.4242, -6.2741, -8.2787]]],grad_fn=<ViewBackward0>), hidden_states=None, attentions=None)
output.logits--->torch.Size([1, 12, 21128])
打印概率最高的字: ['她']
output相关:模型预测的 “分数”logits:形状torch.Size([1, 12, 21128])→ 1 条文本、12 个 token、21128 个候选字(模型词表大小)。logits是模型对每个候选字的 “原始分数”,分数越高,认为该字越适合填[MASK];MaskedLMOutput:模型输出的封装结果,包含logits、loss(此处loss=None,因为没计算损失)等。
3.4.5 阅读理解任务Question Answering
# 阅读理解任务Question Answering
tokenizer = AutoTokenizer.from_pretrained('huggingface_model/chinese_pretrain_mrc_roberta_wwm_ext_large')
model = AutoModelForQuestionAnswering.from_pretrained('huggingface_model/chinese_pretrain_mrc_roberta_wwm_ext_large')
# 文字中的标点符号如果是中文的话,会影响到预测结果,所以可以去掉标点符号
context = '我叫张三 我是一个程序员 我的喜好是打篮球'
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?']
model.eval()
for question in questions:input = tokenizer.encode_plus(question, context, return_tensors='pt')print('input--->\n', input)output = model(**input)print('output--->\n', output)start, end = torch.argmax(output.start_logits), torch.argmax(output.end_logits) +1answer = tokenizer.convert_ids_to_tokens(input['input_ids'][0][start:end] )print('question:', question, 'answer:', answer)
input--->{'input_ids': tensor([[ 101, 2769, 3221, 6443, 8043, 102, 2769, 1373, 2476, 676, 2769, 3221,671, 702, 4923, 2415, 1447, 2769, 4638, 1599, 1962, 3221, 2802, 5074,4413, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1]])}
output--->QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[ -1.9978, -11.4788, -12.6324, -11.8324, -12.4148, -11.9371, -2.7246,-6.6402, 3.9131, -2.9533, -7.0866, -9.5696, -4.2775, -8.9042,0.5753, -6.9468, -7.0469, -8.5334, -11.3796, -9.3905, -11.0242,-11.1047, -5.7124, -2.7293, -7.5896, -12.6013]],grad_fn=<CloneBackward0>), end_logits=tensor([[ -1.3483, -12.0141, -11.6312, -11.6629, -11.9607, -12.0039, -4.6118,-7.4034, -2.3499, 4.7159, -7.2880, -9.5317, -6.6742, -6.0915,-7.0023, -4.9691, 1.4515, -7.8329, -9.0895, -10.3742, -8.7482,-9.8567, -7.2930, -5.8163, -1.7323, -12.2525]],grad_fn=<CloneBackward0>), hidden_states=None, attentions=None)
question: 我是谁? answer: ['张', '三']
input--->{'input_ids': tensor([[ 101, 2769, 3221, 976, 784, 720, 4638, 8043, 102, 2769, 1373, 2476,676, 2769, 3221, 671, 702, 4923, 2415, 1447, 2769, 4638, 1599, 1962,3221, 2802, 5074, 4413, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1]])}
output--->QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[ -2.2018, -12.1859, -12.2946, -12.1527, -11.8349, -12.2244, -12.5048,-12.3524, -11.7760, -5.8289, -9.2119, -2.6119, -5.2339, -8.9569,-9.6797, -3.3958, -8.2407, 4.9941, -4.8070, -4.2607, -10.8480,-12.1394, -10.7349, -12.1574, -12.8387, -7.0354, -3.5467, -7.8111,-13.3356]], grad_fn=<CloneBackward0>), end_logits=tensor([[ -1.6445, -12.8343, -12.8161, -12.5158, -12.6665, -12.5056, -12.3809,-12.7396, -12.8024, -7.9332, -8.8340, -6.6529, -1.3183, -8.8469,-10.3757, -7.1896, -6.2773, -4.6138, 1.4756, 5.7726, -9.4083,-10.5839, -10.6289, -9.3858, -10.9594, -8.2169, -5.4891, -2.3510,-11.5964]], grad_fn=<CloneBackward0>), hidden_states=None, attentions=None)
question: 我是做什么的? answer: ['程', '序', '员']
input--->{'input_ids': tensor([[ 101, 2769, 4638, 4263, 1962, 3221, 784, 720, 8043, 102, 2769, 1373,2476, 676, 2769, 3221, 671, 702, 4923, 2415, 1447, 2769, 4638, 1599,1962, 3221, 2802, 5074, 4413, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1]])}
output--->QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[ -2.3626, -11.8109, -12.0014, -11.8726, -12.1884, -11.8566, -9.7494,-11.1390, -11.7340, -11.1959, -7.9703, -10.8244, -6.8488, -7.3804,-10.2713, -11.6897, -9.4933, -10.8606, -5.7595, -9.2127, -10.6542,-9.7533, -10.6992, -7.8148, -10.3834, -9.6321, 3.5385, 1.6568,-5.6116, -13.1424]], grad_fn=<CloneBackward0>), end_logits=tensor([[ -1.6990, -11.7872, -11.4344, -11.7961, -10.9140, -11.3832, -10.8778,-10.4030, -11.2210, -10.8597, -9.3072, -8.4403, -9.3098, -4.2836,-10.4882, -10.9745, -9.0912, -8.4680, -8.4498, -7.5450, -6.3684,-10.0657, -9.6512, -9.8094, -7.6295, -10.5727, -2.3553, -2.5650,4.3905, -10.5694]], grad_fn=<CloneBackward0>), hidden_states=None, attentions=None)
question: 我的爱好是什么? answer: ['打', '篮', '球']
output部分:模型找答案的线索start_logits/end_logits:- 模型预测答案在文本中的起始 / 结束位置概率(分数越高,越可能是答案边界);
- 例:
start_logits最大值的位置 = 答案开始的 token,end_logits最大值位置 = 答案结束的 token;
QuestionAnsweringModelOutput:封装结果,包含start_logits、end_logits等,是模型跑完问答任务的输出。
3.4.6 文本摘要任务Summarization
# 文本摘要任务Summarization
text = "BERT is a transformers model pretrained on a large corpus of English data " \
"in a self-supervised fashion. This means it was pretrained on the raw texts " \
"only, with no humans labelling them in any way (which is why it can use lots " \
"of publicly available data) with an automatic process to generate inputs and " \
"labels from those texts. More precisely, it was pretrained with two objectives:Masked " \
"language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \
"words in the input then run the entire masked sentence through the model and has " \
"to predict the masked words. This is different from traditional recurrent neural " \
"networks (RNNs) that usually see the words one after the other, or from autoregressive " \
"models like GPT which internally mask the future tokens. It allows the model to learn " \
"a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \
" concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \
"sentences that were next to each other in the original text, sometimes not. The model then " \
"has to predict if the two sentences were following each other or not."tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path="huggingface_model/distilbart-cnn-12-6")
model = AutoModelForSeq2SeqLM.from_pretrained(pretrained_model_name_or_path='huggingface_model/distilbart-cnn-12-6')
input = tokenizer([text], return_tensors='pt')
model.eval()
output = model.generate(input.input_ids)
print('output--->\n', output)
print([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in output])
print(tokenizer.convert_ids_to_tokens(output[0]))
output--->tensor([[ 2, 0, 11126, 565, 16, 10, 7891, 268, 1421, 11857,26492, 15, 10, 739, 42168, 9, 2370, 414, 11, 10,1403, 12, 16101, 25376, 2734, 479, 85, 21, 11857, 26492,19, 80, 10366, 35, 31755, 196, 2777, 19039, 36, 10537,448, 43, 8, 220, 3645, 16782, 36, 487, 4186, 43,20, 3092, 10146, 26511, 1626, 80, 24397, 11305, 25, 16584,148, 11857, 32155, 479, 7411, 51, 20719, 7, 11305, 14,58, 220, 7, 349, 97, 11, 5, 1461, 2788, 6,2128, 45, 479, 2]])
['BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion . It was pretrained with two objectives: Masked language modeling (MLM) and next sentence prediction (NSP) The models concatenates two masked sentences as inputs during pretraining . Sometimes they correspond to sentences that were next to each other in the original text, sometimes not .']
['</s>', '<s>', 'BER', 'T', 'Ġis', 'Ġa', 'Ġtransform', 'ers', 'Ġmodel', 'Ġpret', 'rained', 'Ġon', 'Ġa', 'Ġlarge', 'Ġcorpus', 'Ġof', 'ĠEnglish', 'Ġdata', 'Ġin', 'Ġa', 'Ġself', '-', 'super', 'vised', 'Ġfashion', 'Ġ.', 'ĠIt', 'Ġwas', 'Ġpret', 'rained', 'Ġwith', 'Ġtwo', 'Ġobjectives', ':', 'ĠMask', 'ed', 'Ġlanguage', 'Ġmodeling', 'Ġ(', 'ML', 'M', ')', 'Ġand', 'Ġnext', 'Ġsentence', 'Ġprediction', 'Ġ(', 'N', 'SP', ')', 'ĠThe', 'Ġmodels', 'Ġconc', 'aten', 'ates', 'Ġtwo', 'Ġmasked', 'Ġsentences', 'Ġas', 'Ġinputs', 'Ġduring', 'Ġpret', 'raining', 'Ġ.', 'ĠSometimes', 'Ġthey', 'Ġcorrespond', 'Ġto', 'Ġsentences', 'Ġthat', 'Ġwere', 'Ġnext', 'Ġto', 'Ġeach', 'Ġother', 'Ġin', 'Ġthe', 'Ġoriginal', 'Ġtext', ',', 'Ġsometimes', 'Ġnot', 'Ġ.', '</s>']
print([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in output])- 把模型生成的
token ID(output里的内容)解码成人类能读的字符串(摘要文本); - 参数拆解:
g:遍历output里的每个生成结果(这里output只有一个结果,所以g=output[0]);skip_special_tokens=True:忽略特殊 token(如[CLS]、[SEP]),只保留摘要文本;clean_up_tokenization_spaces=False:不自动清理分词后的空格,保持模型输出的原始空格格式(避免过度处理导致文本变形);
- 把模型生成的
print(tokenizer.convert_ids_to_tokens(output[0]))- 把模型生成的
token ID(output[0])转换为模型词表中的token(包含特殊 token,如</s>、<s>等); - 特点:
- 不会过滤特殊 token,能看到模型生成的原始
token(包括开头 / 结尾的标记); - 适合调试(看模型到底生成了哪些
token,是否包含特殊标记 ),但不适合直接当摘要结果(因为有冗余符号)。
- 不会过滤特殊 token,能看到模型生成的原始
- 把模型生成的
3.4.7 NER 任务Token Classification
# NER 任务Token Classification
# 加载中文命名实体识别(NER)专用的分词器,基于roberta-base在cluener2020数据集上微调得到
# cluener2020是中文通用实体识别数据集,包含人名、地名、组织名等常见实体类型
tokenizer = AutoTokenizer.from_pretrained('huggingface_model/roberta-base-finetuned-cluener2020-chinese')
# 加载对应的带实体分类头的模型,专门用于token级别的实体识别任务
model = AutoModelForTokenClassification.from_pretrained('huggingface_model/roberta-base-finetuned-cluener2020-chinese')
# 加载模型配置,包含标签映射(id到实体类型的对应关系,如0→'O'表示非实体)
config = AutoConfig.from_pretrained('huggingface_model/roberta-base-finetuned-cluener2020-chinese')
inputs = tokenizer.encode_plus('我爱北京天安门,天安门上太阳升', return_tensors='pt')
print('inputs--->\n', inputs.input_ids.shape, inputs.input_ids)
model.eval()
# 将输入的token ID传入模型,获取logits(每个token对应各实体类型的原始分数)
logits = model(inputs.input_ids).logits
print('logits--->', logits.shape)
# 将token ID转换为对应的token(分词后的字/子词),便于后续和实体标签对应
input_tokens = tokenizer.convert_ids_to_tokens(inputs.input_ids[0])
print('input_tokens--->\n', input_tokens)
outputs = []
print('outputs--->')
# 遍历每个token和对应的logits,进行实体标签预测
for token, value in zip(input_tokens, logits[0]):# 跳过特殊标记(如[CLS]、[SEP]),这些位置不参与实体识别if token in tokenizer.all_special_tokens:continue# 对当前token的logits取最大值,得到最可能的实体标签IDidx = torch.argmax(value).item()# 将token和对应的实体标签(通过配置的id2label映射得到)存入结果列表outputs.append((token, config.id2label[idx]))# 打印实时结果,格式为[(token1, 标签1), (token2, 标签2), ...]# 例如"北"可能对应"B-LOC"(地点开头),"京"对应"I-LOC"(地点中间),表示"北京"是地点print(outputs)
inputs--->torch.Size([1, 17]) tensor([[ 101, 2769, 4263, 1266, 776, 1921, 2128, 7305, 8024, 1921, 2128, 7305,677, 1922, 7345, 1285, 102]])
logits---> torch.Size([1, 17, 32])
input_tokens--->['[CLS]', '我', '爱', '北', '京', '天', '安', '门', ',', '天', '安', '门', '上', '太', '阳', '升', '[SEP]']
outputs--->
[('我', 'O')]
[('我', 'O'), ('爱', 'O')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address'), ('安', 'I-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address'), ('安', 'I-address'), ('门', 'I-address')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address'), ('安', 'I-address'), ('门', 'I-address'), ('上', 'O')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address'), ('安', 'I-address'), ('门', 'I-address'), ('上', 'O'), ('太', 'O')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address'), ('安', 'I-address'), ('门', 'I-address'), ('上', 'O'), ('太', 'O'), ('阳', 'O')]
[('我', 'O'), ('爱', 'O'), ('北', 'B-address'), ('京', 'I-address'), ('天', 'I-address'), ('安', 'I-address'), ('门', 'I-address'), (',', 'O'), ('天', 'B-address'), ('安', 'I-address'), ('门', 'I-address'), ('上', 'O'), ('太', 'O'), ('阳', 'O'), ('升', 'O')]
3.5 具体模型
import torch
from transformers import BertTokenizer, BertForMaskedLM, BertModel
BertTokenizer:中文 BERT 的分词器,负责把文本转成模型能懂的token ID;BertForMaskedLM:带掩码语言模型头的 BERT 模型,专门用于预测[MASK]位置的字词,输出每个位置的候选字概率;
modename = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(modename)
model = BertForMaskedLM.from_pretrained(modename)
input = tokenizer.encode_plus('我想明天去[MASK]家吃饭.', return_tensors='pt')
print('input--->\n', input)
model.eval()
output = model(**input)
print('output--->\n', output)
print('output.logits--->\n', output.logits.shape) # [1,12,21128]
mask_pred_idx = torch.argmax(output.logits[0][6]).item()
print('打印概率最高的字:', tokenizer.convert_ids_to_tokens([mask_pred_idx]))
3.6 自动模型 VS 具体模型
- 两者都能实现 NLP 任务:不管用自动模型方式还是具体模型模型方式,最终目标都是完成 NLP 任务(分类、问答等 ),只是实现路径不同;
AutoModel是框架提供的“智能管家”,会根据任务类型(如完形填空、文本分类),自动适配不同厂商的预训练模型,统一输入输出格式;- 如果不用
AutoModel,开发者得手动选具体模型(如直接用BertForMaskedLM),还要自己处理输入输出(不同模型可能格式不同),灵活但复杂。