微调系列:LoRA原理
论文链接:https://arxiv.org/pdf/2106.09685
视频推荐:
大模型微调第5节-LoRA微调的原理及从零实现_哔哩哔哩_bilibili
动机
1. 预训练大模型本质上具有低秩特性
2. 全参微调模型非常昂贵
有研究表明:即使将模型参数通过随机投影映射到更小的子空间,模型依然能够高效地学习。
Measuring the Intrinsic Dimension of Objective Landscapes
这篇论文提出并实验证明了“模型训练的本征维度远小于模型参数总数”。他们通过随机投影等技术测量了神经网络loss lanscape的本征维数,发现即使大模型,真正有效参与优化的空间也很小。
什么是本征维度?
用来描述高维数据或参数空间中,实际有效变化或有意义信息所处的“内在”维度。什么是LandScape?
“损失景观”,损失函数随着模型参数变化而形成的高维空间中的“地形”或“曲面”。
把参数空间的每一个点(即一组参数值)都对应到一个损失函数值:整个参数空间中的每个点都有一个“高度”,这个高度就是损失函数值。
- 损失景观中的“低谷”是损失较低(模型表现好的参数组合),最优点就是“最低点”。
- “鞍点”或“高原”是一些局部平坦或特殊结构区域。
怎么理解通过随机投影测量loss lanscape的本征维数找寻有效优化空间?
随机投影:在高维参数空间里,随机选出一个低维子空间(“划一片区域”),模型参数只允许在这片区域内调整。
维数:子空间的“大小”,即用多少个方向描述这片区域。
本征维数:一开始子空间很小,可选择的方向很少,所以不能找到landscape中所有的低谷(最优解),逐渐增加,可选择的方向增加,直到在某个空间包含的方向能够找到最优解(模型和全空间训练效果一样),这个最小的充分空间就称为本征维数。
整体理解为通过随机投影的手段,在loss landscape上,找出覆盖所有最优解方向所需的最小空间(最少的独立方向即维度)。
注意,这里的空间指的是方向的几何,而不是具体的空间部分。随机投影不是简单地选一个“地形片段”,而是确定了一组“方向”,每个方向是一条直线。

Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
这篇论文系统研究了大型语言模型微调的本征维数。他们发现下游任务微调时,参数空间的有效维度(本征维度)非常低,这意味着只需要对极少量参数进行调整就可以获得很好的迁移效果。
其他微调方法存在的问题
当前的高效适配主要有两种策略:Adapter适配器 和 优化输入层的某种激活形式。
Adapter
1. 推理延迟增加
Adapter层通常插入在Transformer Block内部。虽然参数量很少,但需要按顺序处理,导致推理速度下降(尤其是batchsize很小,比如在线服务)。
2. 部署和维护复杂度提升
每个任务都有独立的Adapter参数;在分布式或多实例部署时,adapter参数可能需要冗余存储于多台设备,消耗更多内存。
3. 计算资源消耗
Parameter-Efficient Transfer Learning for NLP的方法:每个 Transformer 块有两个适配器层
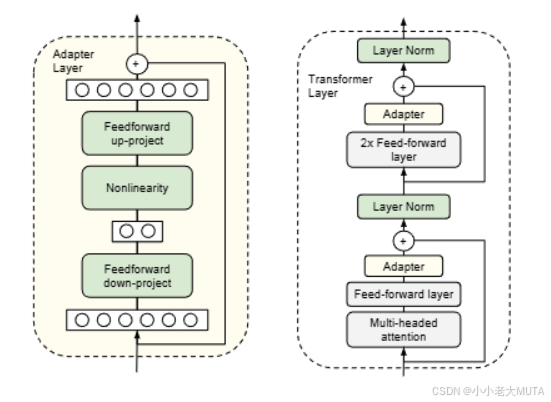
Exploring Versatile Generative Language Model Via Parameter-Efficient Transfer Learning的方法:每个块只有一个适配器层,但多了一个 LayerNorm
直接优化prompt
该类方法有prompt tuning、soft prompt、prefix tuning,通过优化可学习的“伪 token”向量,作为上下文插入到输入中,从而调整大模型的行为。
1. 可调空间有限
- 因为参数量少,通常只优化几十到几百个虚拟token的嵌入参数,远小于Adapter和LoRA。
- 并且prompt层本质只能重排列和强调预训练模型预警学会的知识,难以引入全新知识。
2. 任务适用性低
对于复杂任务(逻辑推理,复杂理解,跨域迁移),单靠prompt编排输入不足以让模型学会新技能。
3. 训练不稳定
soft prompt训练初期很容易陷入局部最优或者梯度消失/爆炸,优化难度大。
4. 数据依赖性高
需要较多数据才能学习到效果较好的soft prompt,数据少时容易过拟合。
下图为prefix-tuning的方法:
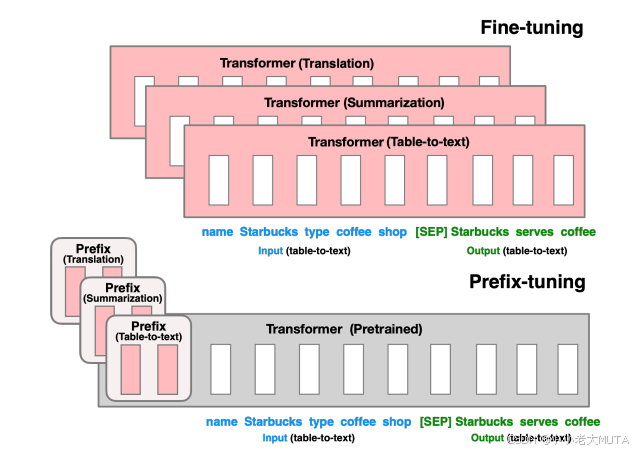
方法
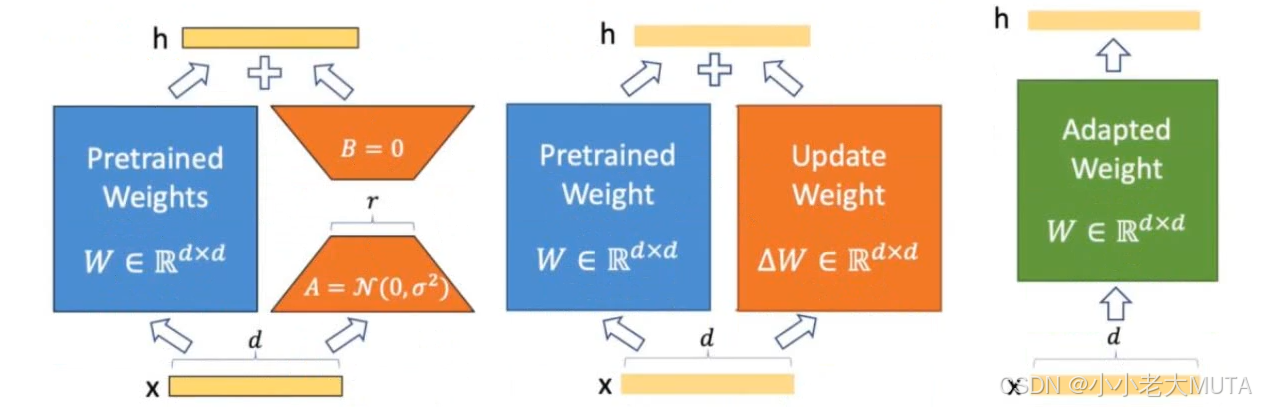
对于一个预训练的权重矩阵:
其中,,
,且秩
训练时,被冻结,不接收梯度更新,A 和B 包含可训练参数。注意,
和
都会与相同的输入相乘,并将各自的输出向量按坐标加和。
对输入 x,有:
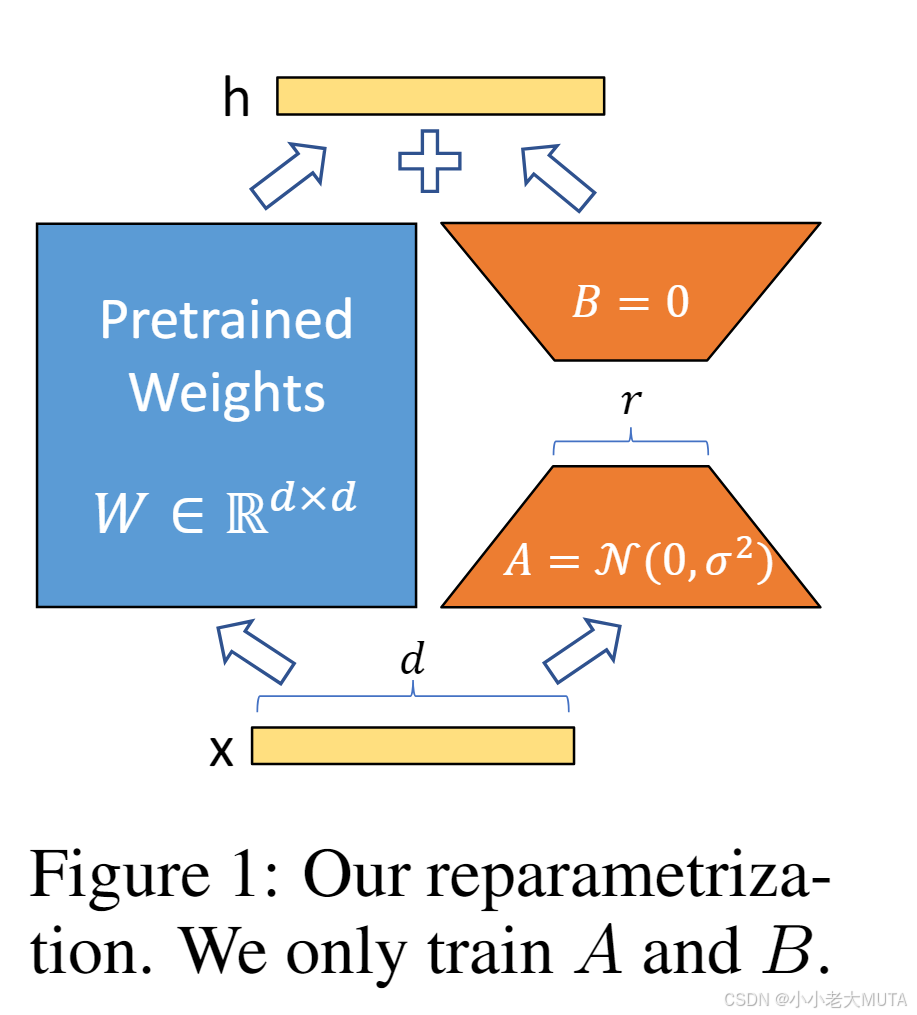
用高斯分布随机初始化A,用零初始化B,因此在训练开始时。
然后用 来缩放
,其中 α 是一个与 r 有关的常数。
用Adam优化时,如果初始化合适,调节α 大致相当于调整学习率。
实际上,直接将α设为我们尝试的第一个rr值,并不专门调参。这种缩放有助于在调整r时减少超参数调优的需求。
如果将LORA的秩r 设置为预训练权重矩阵的秩,就能恢复全量微调的表达能力。
优点
无额外推理延迟
在实际部署中,我们可以显式计算并存储
,像常规模型一样进行推理。注意,
和
形状都是d×k。
当需切换到其他下游任务时,只需将
即可,这个操作非常快,几乎不增加内存。
重要的是,这确保了与全量微调模型相比,推理时不会引入任何额外延迟。
LoRA可以调节可训练参数数量,使得训练效果大致能收敛到近似训练原始模型的水平;
而Adapter方法则收敛到一个MLP;
Prefix-based方法则无法处理长输入序列。