DeepSeek-V3.1发布,预示下一代国产芯片即将发布,更新一小版本,跨出一大步
2025 年 8 月 21 日,DeepSeek官方升级了最新版本DeepSeek-V3.1。
一、核心升级亮点
| 维度 | 说明 |
|---|---|
| 混合推理架构 | 同一模型支持 思考模式 与 非思考模式,通过 深度思考按钮 一键切换。 |
| 更高思考效率 | DeepSeek-V3.1-Think 在保持与 DeepSeek-R1-0528 同等表现的同时,响应时间更短(输出 token 数减少 20–50%)。 |
| 更强 Agent 能力 | Post-Training 优化后,工具调用与智能体任务表现显著提升。 |
二、产品体验更新
-
官方 App / 网页端
已全面升级为 DeepSeek-V3.1。
新增「深度思考」按钮,可在思考 ⇄ 非思考模式间自由切换。 -
DeepSeek API
deepseek-chat→ 非思考模式deepseek-reasoner→ 思考模式- 上下文长度统一扩展至 128K
- Beta 接口支持 strict 模式 Function Calling,输出严格符合 schema。
- 文档:Function Calling
-
Anthropic API 兼容
通过简单配置即可把 DeepSeek-V3.1 接入 Claude Code 框架。
文档:
三、工具调用 / 智能体能力评测
1. 编程智能体
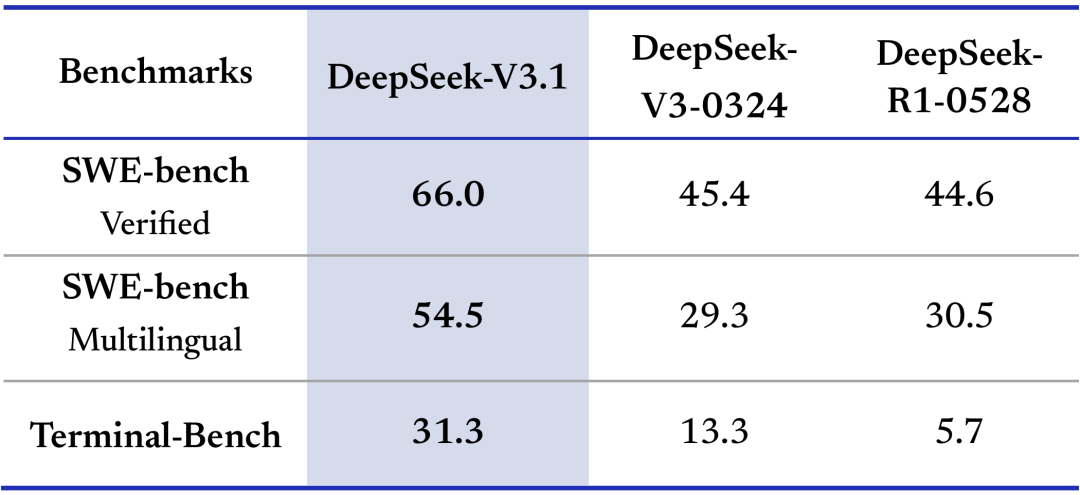
在代码修复测评 SWE 与命令行终端环境下的复杂任务(Terminal-Bench)测试中,DeepSeek-V3.1 相比之前的 DeepSeek 系列模型有明显提高。
2. 搜索智能体
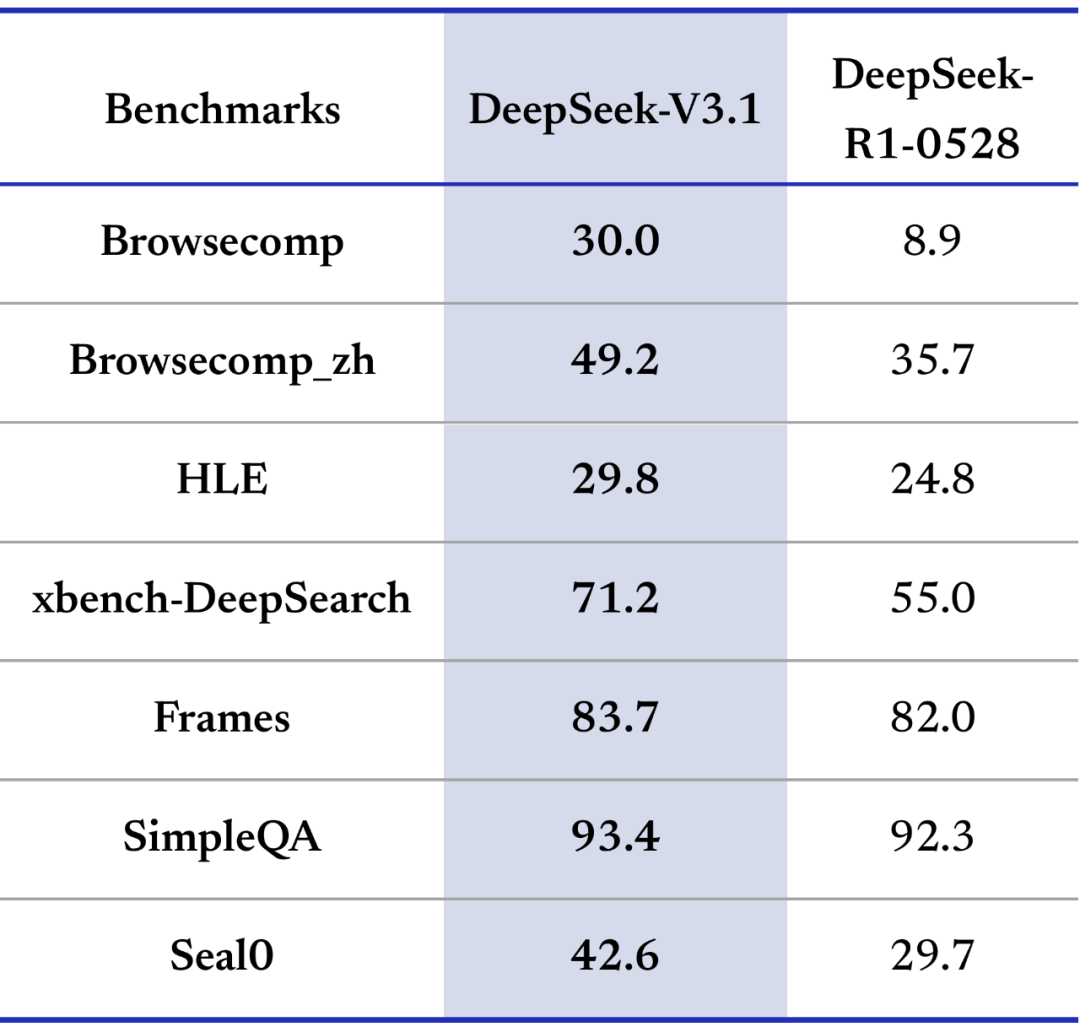
DeepSeek-V3.1 在多项搜索评测指标上取得了较大提升。在需要多步推理的复杂搜索测试(browsecomp)与多学科专家级难题测试(HLE)上,DeepSeek-V3.1 性能已大幅领先 R1-0528。
四、思考效率实测
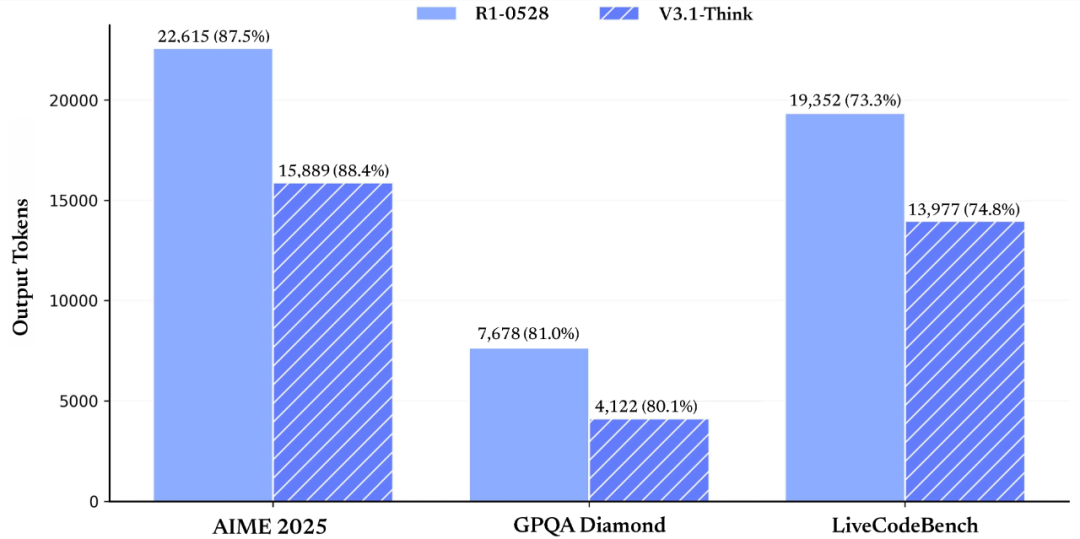
在得分基本持平的前提下,V3.1-Think 的 token 消耗量下降 20–50%;非思考模式亦显著压缩输出长度。
五、模型开源与部署
| 模型 | Hugging Face | 魔搭 |
|---|---|---|
| DeepSeek-V3.1-Base | 🔗 链接 | 🔗 链接 |
| DeepSeek-V3.1(后训练) | 🔗 链接 | 🔗 链接 |
注意事项
- 采用 UE8M0 FP8 Scale 参数精度
- tokenizer & chat template 与 DeepSeek-V3 有差异,部署前请务必阅读新版说明文档。
六、UE8M0 FP8 Scale
意味着 DeepSeek-V3.1 并不是简单地把模型“改个精度”,而是提前为即将面世的下一代国产 AI 芯片打好了“地基”,把“模型-框架-芯片”三个层面做成了一套互相咬合的体系。具体来讲,UE8M0 FP8 的引入带来了三层含义:
-
技术层面:用 8 位浮点(FP8)替代传统的 FP16/FP32,显存占用和能耗直接砍掉 50–75%,但靠“UE8M0”这套定制编码(无符号指数+动态尾数+可缩放因子)把精度损失控制在可接受范围,让国产芯片在有限算力、有限制程下跑出接近国际旗舰 GPU 的效果。
-
生态层面:DeepSeek 在模型设计阶段就把国产芯片的指令集、访存带宽、能效比全部考虑进去,形成“软硬协同设计”——模型一出世就天然适配国产硬件,开发者无需再做二次优化,大幅降低了国产芯片落地门槛。
-
产业层面:这标志着中国 AI 产业第一次从“能用国产芯片”升级到“专为国产芯片定制标准”。以往国产 GPU/NPU 只能去兼容 CUDA、ROCm 等国外生态,现在反过来,模型和框架先为国产芯片量身打造,未来国产 AI 芯片-国产开源模型-下游应用形成闭环,减少对外部技术的依赖。
一句话总结:UE8M0 FP8 不仅是技术参数,更是下一代国产 AI 芯片的“入场券”。DeepSeek-V3.1 率先支持它,意味着未来你拿到新的国产 AI 卡,直接跑 V3.1 就能“开箱即用”,性能、成本、功耗全面优于传统方案,国产算力生态真正开始闭环。
8 月 22 日(周五)一开盘,DeepSeek-V3.1 的“官宣效应”迅速在盘面兑现,国产 AI 算力链成为资金主攻方向:
DeepSeek-V3.1 直接把市场从“概念炒作”带入“业绩+国产替代”共振阶段,芯片、算力、大模型应用三大赛道集体爆发,短线资金与长线配置盘同步抢筹。