【文献阅读】Lossless data compression by large models
1. 中华人工智能研究中心,郑州。 2. 鹏程实验室,深圳。 3. 上海数学与交叉学科研究所,上海。 4. 中国科学院计算技术研究所,北京。 5. 宁波人工智能产业研究所,宁波。 6. 滑铁卢大学计算机科学学院,加拿大安大略省渥太华。 7. 大连理工大学数学科学学院,大连。
nature machine intelligence
Lossless data compression by large models | Nature Machine Intelligence

数据压缩是一项基础性技术,能够实现信息的高效存储与传输。然而,经过 80 年的研究与发展,传统压缩方法正逐渐接近其理论极限。与此同时,大型人工智能模型应运而生,这些模型通过在海量数据上训练,能够 “理解” 各种语义信息。直观来看,语义能够简洁地传递数据的含义,因此大型模型有望为压缩技术带来革命性变革。
本文提出了一种名为 LMCompress 的新方法,该方法利用大型模型进行数据压缩。LMCompress 在文本、图像、视频和音频这四种媒体类型上打破了所有以往的无损压缩记录。它将图像压缩领域 JPEG-XL、音频压缩领域 FLAC 以及视频压缩领域 H.264 的压缩率降低了一半,并且在文本压缩方面达到了 zpaq 压缩率的近三分之一。我们的研究结果表明,模型对数据的理解越好,其压缩效果就越显著,这揭示了理解与压缩之间存在着深刻的联系1。
无损数据压缩是一项关键技术,它能确保压缩后的数据可以被完美重构。在可执行程序、文本文档、基因组学、密码学以及多媒体存档或制作等领域,无损数据压缩都不可或缺2。
目前已开发出多种无损压缩方法,例如 7z(参考文献 1)、FLAC、PNG 以及无损 H.264(参考文献 4)/H.265(参考文献 5)。这些方法在很大程度上局限于香农 80 多年前建立的信息论框架。它们依靠各种可计算特征,如复杂的规则和变换,来识别并消除数据中的冗余。经过 80 年的研究,这类方法已达到其性能极限3。
随着大型模型的出现,一场深刻的变革拉开了序幕。大型模型的原理可追溯至 20 世纪 60 年代提出的著名的所罗门诺夫归纳法 7。与定义可计算特征不同,大型模型通过大量数据来逼近不可计算的所罗门诺夫归纳法 8。通过这种方式,大型模型实现了对数据的理解,就像我们在日常生活中所做的那样,从而能够实现高效压缩4。
基于上述观察,我们提出了一种新的压缩方法,即利用大型模型理解各类数据并进而对其进行压缩(总体概述见图 1)。
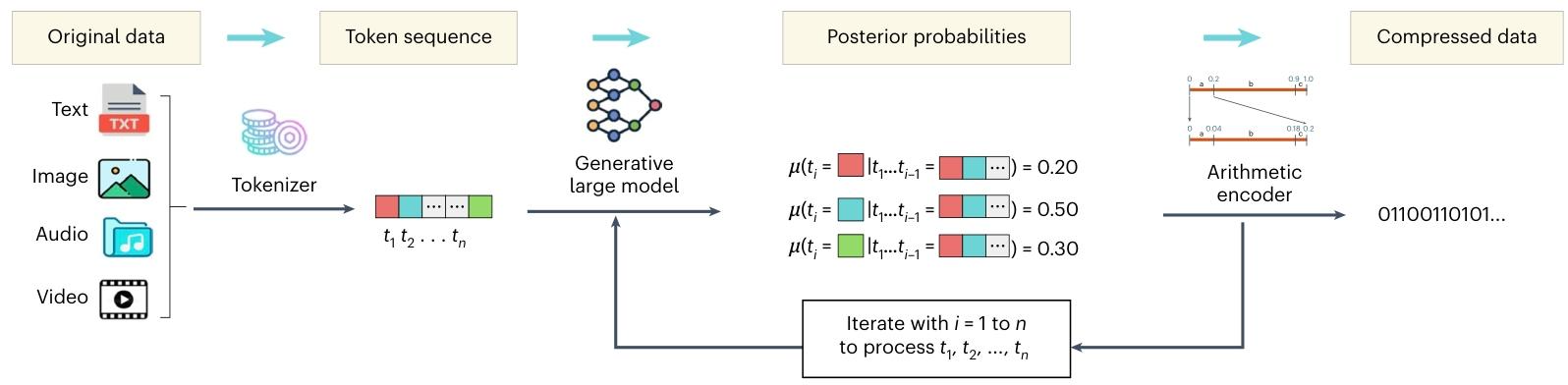
图1 LMCompress 转换为一系列令牌。然后,该令牌序列被输入至图1 | 我们的LMCompress架构。首先,原始数据是生成式大型模型,该模型会输出每个令牌的预测分布。 最后,算术编码基于预测分布对原始数据进行无损压缩。令牌化工具和生成式大型模型可能会根据数据类型的不同而有所差异。
这是 LMCompress(基于大模型的无损压缩方法)的工作流程图 ,清晰展示了如何用生成式大模型对文本、图像、音频、视频等数据进行无损压缩,拆解步骤如下:
1. 原始数据(Original data)
涵盖文本(Text)、图像(Image)、音频(Audio)、视频(Video)等不同类型的数据,是压缩的输入源头。
2. 令牌化(Tokenizer → Token sequence)
通过 “令牌化工具(Tokenizer)”,把原始数据转换成令牌序列(Token sequence,即 t₁, t₂ … tₙ ) 。
-
简单理解:类似把文本拆成单词、图像 / 音频拆成特征片段,让大模型能 “读懂” 数据,是统一处理不同数据类型的基础。
3. 生成式大模型(Generative large model)
接收令牌序列,输出后验概率(Posterior probabilities) ,即基于前面令牌(t₁…tᵢ₋₁ ),预测下一个令牌 tᵢ 出现的概率(比如红、蓝、绿块的概率分别是 0.20、0.50、0.30 )。
-
核心逻辑:大模型通过学习海量数据,“理解” 数据规律,用概率量化这种理解,为压缩做准备。
4. 算术编码(Arithmetic encoder → Compressed data)
依据大模型输出的概率,用算术编码器(Arithmetic encoder) 对原始数据无损压缩,最终输出二进制压缩结果(如 01100110101… )。
-
关键作用:概率越精准(大模型 “理解” 越好 ),压缩效率越高,实现用更少二进制位存储原始数据。
整个流程的核心是 “用大模型理解数据规律(概率预测),再用算术编码实现高效压缩” ,体现了 “理解驱动压缩” 的思路
我们之前已独立发表过相关前期研究 9,DeepMind 团队也发表过类似工作 10,此外文献 11 也表达了相似的观点。从本质上来说,是将数据输入自回归生成模型,该模型会生成一系列下一个令牌的概率分布。这些概率分布进而通过算术编码将原始数据等效转换为二进制字符串。参考文献 9 和参考文献 10 中的研究表明,这种新方法在性能上远超 7z 等常用的顶级压缩工具数倍。不过,这些研究主要聚焦于文本压缩领域5。
本文旨在全面验证 “更好的理解意味着更好的压缩” 这一观点。为了增强对不同类型数据的理解,对于图像和视频,我们使用图像生成预训练 Transformer(GPT)12 而非普通的大型语言模型(LLM);
对于音频,我们使用在原始音频字节上预训练的大型模型 bGPT-audio13;而对于特定领域的文本,我们则采用经过专门微调的大型语言模型。在对数据有了一定理解的基础上,我们接下来应用算术编码(详见补充材料第 4 节)对数据进行压缩。
无损压缩实验表明,通过使用大型语言模型理解数据,我们在包括文本、图像、视频和音频在内的所有类型数据的压缩率上都有了显著提升。我们的方法比传统算法性能高出数倍,并且与使用普通大型语言模型的变体相比,优势也十分明显67。
基于此,我们有理由认为理解意味着压缩。而我们在参考文献 14 中,在合理的定义下证明了反向关系,即压缩意味着理解。综上所述,我们得出了 “理解即压缩” 这一见解,如图 2 所示8。

图2 | 本文的核心见解。该见解指出理解等同于压缩,搭建起了认知概念与技术概念之间的桥梁 。
结果
我们将压缩率作为衡量压缩性能的主要指标,压缩率指的是压缩后的数据大小与原始数据大小的比值。在压缩率这一指标下,数值越低越好。其他指标,如时间成本,将在补充材料第 3 节中讨论9。
大多数基线方法,如 H.264 视频压缩标准,既可以工作在有损模式下,也可以工作在无损模式下。为了进行公平比较,在我们的实验中,所有基线方法都被设置为无损模式10。
此外,由于一种算法的压缩率会因数据集的不同而有所变化,为了减轻潜在的数据偏差带来的影响,每种压缩算法都在至少两个不同的数据集上进行评估11。
图像压缩
模型:我们使用图像 GPT(iGPT)模型作为图像压缩的生成式大型模型12。
数据集:我们在两个基准图像数据集上评估了 LMCompress 的图像压缩性能,这两个数据集分别是:(1)ILSVRC2017(参考文献 15),这是一个大规模数据集,包含来自 ImageNet 语料库的数百万张分属数千个类别的带标签图像;(2)CLIC2019 professional16,该数据集是专门为评估图像压缩算法而设计的。CLIC2019 包含高质量图像,这些图像具有多种不同特征,包括自然场景、纹理、图案和结构等13。
最终,算术编码根据预测分布对原始数据进行无损压缩。针对不同类型的数据,所使用的令牌化工具和生成式大型模型可能会有所不同14。
由于数据集规模过大,我们从其中抽取了 197 张图像。这些图像的总大小为 128 兆字节。为了适配 iGPT 的上下文窗口,上下文长度被设置为 102415。
图 3 展示了基线方法和 LMCompress 在两个数据集上的压缩率。结果表明,我们的 LMCompress 在两个数据集上都显著优于所有基线方法,将压缩率降低了一半以上。值得注意的是,DeepMind 的方法也使用了大型模型,即 Chinchilla 系列。但其压缩率远高于 LMCompress,这可能是因为 Chinchilla 仅在语言语料库上训练,而 iGPT 在图像语料库上训练,能够更好地理解图像16。
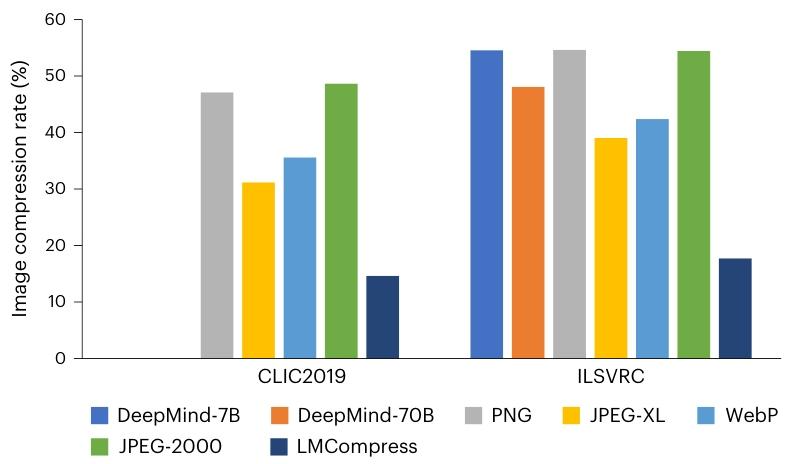
图 3 | 图像压缩率。数据集为 CLIC2019 和 ILSVRC。ILSVRC 上 DeepMind 方法的结果来自参考文献 10,而 CLIC2019 上的结果为空白,因为既没有公开此类结果,也没有公开 Chinchilla 模型25。
视频压缩
模型:我们同样使用 iGPT 作为视频压缩的生成式大型模型17。
数据集:我们使用了来自Xiph.org(参考文献 17)的测试数据,该数据集包含超过 1000 个未压缩的 YUV4MPEG 格式视频片段。由于数据集规模庞大,我们选取了一个子集进行测试。该子集包括一个高分辨率视频片段(4096×2160)、五个静态场景视频片段和五个动态场景视频片段,静态和动态场景视频片段均为低分辨率(352×288)。如果一个视频片段的连续帧变化较小,例如课堂录制视频,则称其为静态场景视频;否则,如动作电影,则称为动态场景视频。这三类视频片段的总大小分别为 759 兆字节、162 兆字节和 237 兆字节18。
如图 4 所示,LMCompress 在两种视频类型上都优于所有基线方法。在高分辨率数据上,与基线方法相比,LMCompress 的压缩率提升了 20% 以上。在低分辨率静态场景数据上,LMCompress 的压缩率提升超过 30%。在低分辨率动态场景数据上,LMCompress 依然保持优势,压缩率至少提升 30%。我们还观察到,动态场景比静态场景更难压缩。一个可能的原因是,在动态场景视频片段中,演员的姿势往往是瞬时变化的,难以理解和预测19。
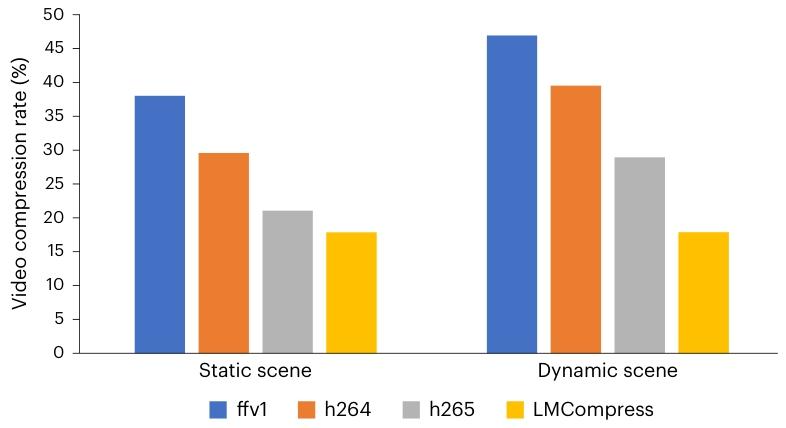
图 4 | 视频压缩率。数据集来自Xiph.org,包括高分辨率和低分辨率视频片段。低分辨率视频片段进一步分为 “静态场景” 和 “动态场景”32。
音频压缩
模型:我们使用 bGPT-audio 作为音频压缩的生成式大型模型20。
数据集:由于 bGPT-audio 是在 LibriSpeech 数据集 18 上预训练的,因此我们在另外三个数据集上评估其压缩性能:LJSpeech19、Mozilla Common Voice 11(参考文献 20)和 VoxPopuli21。LibriSpeech 和 LJSpeech 都源自 LibriVox 项目,包含近 1000 小时的 16 千赫兹英语有声书录音。Mozilla Common Voice 11 是一个多语言语音数据集,由 Common Voice 项目整理而成,在该项目中,用户通过朗读提供的文本贡献语音录音。VoxPopuli 是另一个多语言语音数据集,由 2009 年至 2020 年期间欧洲议会活动的录音组成2122。
对于每个数据集,我们首先将音频文件标准化为 16 千赫兹采样率、单声道和 8 位深度。随后,从每个数据集随机抽取一段约 100 兆字节的连续音频用于压缩。对于 Mozilla Common Voice 11 和 VoxPopuli,采样仅限于英语录音。在由 bGPT-audio 处理之前,每个采样片段都被转换为原始字节,并分割成最大长度为 8160 字节的块。这种分割方式与该模型 8192 字节的上下文窗口相适配,以满足包含 16 字节序列开始令牌和 16 字节序列结束令牌的格式要求23。
结果如图 5 所示。我们得出两个观察结论:(1)LMCompress 在所有数据集上的性能都优于 DeepMind 的方法,这可能是因为 LLaMA 模型系列仅在语言语料库上训练,而 bGPT-audio 在音频数据上训练;(2)LMCompress 相较于最高效的传统方法 OptimFROG 具有显著优势,甚至超过了基于大型模型的 DeepMind 方法。具体而言,与 OptimFROG 相比,LMCompress 在 LJSpeech、Mozilla Common Voice 11 和 VoxPopuli 数据集上的压缩率分别降低了 28%、35% 和 23%24。
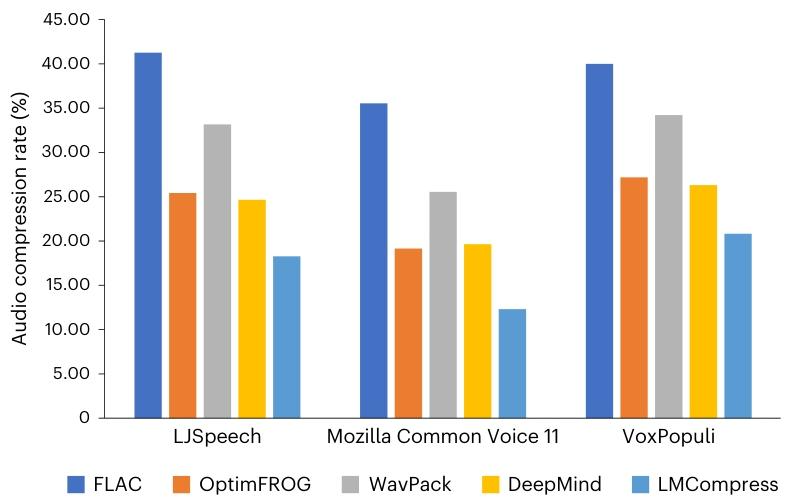
图 5 | 音频压缩率。数据集为 LJSpeech、Mozilla Common Voice 11 和 VoxPopuli。为了与我们的 LMCompress 进行公平比较,DeepMind 方法是在参考文献 10 的基础上通过将 LLaMA2 替换为 LLaMA3-8B 进行调整得到的42。
文本压缩
模型:在 LMCompress 的文本压缩中,我们选择通过低秩适应进行领域特定微调的 LLaMA3-8B 作为生成式大型模型26。
数据集:我们用于文本压缩的基准数据集是 MeDAL22 和 Pile of Law23。MeDAL 是一个医学领域的数据集,由 2019 年年度基线中发布的 PubMed 摘要创建而成,主要用作理解医学缩写的语料库。另一方面,Pile of Law 是一个法律领域的数据集,它包含从 35 个来源汇编的法律和行政文本27。
在实验中,我们从 MeDAL 和 Pile of Law 语料库的 eurlex 分集中提取了前约 180 兆字节的数据。为了适配 LLaMA3-8B 的上下文窗口,上下文长度被设置为 102428。
对于每个领域的数据集,我们使用前 64 兆字节的数据对 LLaMA3-8B 进行微调,接下来的 16 兆字节用于验证,其余数据用于测试29。
如图 6 所示,LMCompress 优于所有基线模型,在每个数据集上的压缩率都不到最佳传统基线 zpaq 的三分之一。与 LMCompress * 相比,它也展现出更低的压缩率,这凸显了领域特定微调在增强文本压缩效果方面的有效性3031。
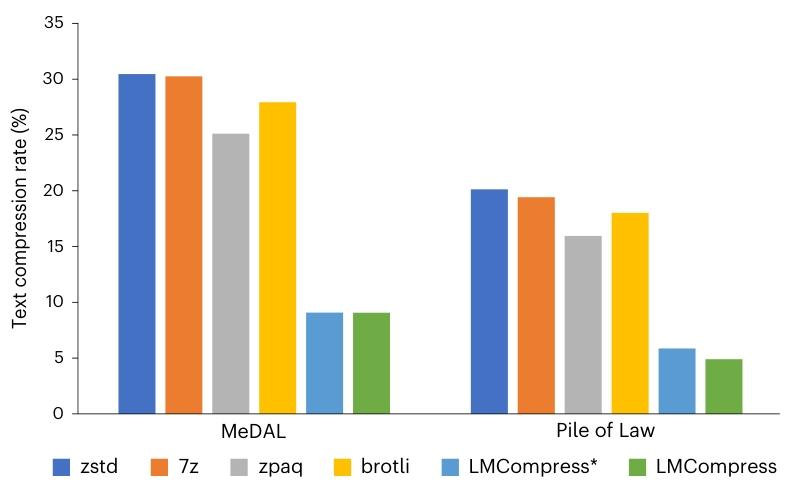
图 6 | 文本压缩率。数据集为 MeDAL 和 Pile of Law。LMCompress * 方法是在参考文献 9、10 的基础上通过将 LLaMA2-7B 替换为 LLaMA3-8B 进行调整得到的,用于公平比较。它与 LMCompress 类似,但使用未经微调的原始 LLaMA3-8B 模型43。
总之,在各种类型的数据上,LMCompress 的压缩率都高于所有传统基线方法和原始基于大型语言模型的算法。这一证据支持了我们的观点,即更好的理解能带来更好的压缩效果33。
讨论
过去的通信通常受香农范式支配,编码效率以香农熵为上限。尽管探索其他可计算特征能够进一步改善压缩效果,但大型模型或许可以被视为对不可计算的所罗门诺夫归纳法的逼近,从而开启压缩领域新的柯尔莫哥洛夫范式。正如我们所展示的,这种新的无损压缩方法在各类数据上都取得了显著的改进。只要大型语言模型在某种数据类型或领域上经过训练能够实现良好的预测,它就可以用于以更高的效率对该数据进行压缩。这种范式使我们能够系统地理解我们所传输的数据,将我们从香农熵的限制中解放出来34。
LMCompress 的一个潜在应用场景是 6G 通信,特别是在卫星带宽有限的情况下 24。通过在通信两端利用大型模型进行编码和解码,借助对数据的理解,通信性能将得到显著提升。随着大型模型作为智能体被专门化,在检索增强生成技术的辅助下,人工智能将能更好地理解待传输的数据。当数据需要加密时,我们的压缩操作需要在加密之前完成。甚至可以想象,拥有更优模型的一方公开广播压缩消息,只有拥有同等模型的一方才能对其进行解密,这可作为第一级加密,且无需额外成本35。
我们已经测试了 LMCompress 的编码时间成本,结果如补充材料第 2 节所示。LMCompress 的编码时间成本甚至低于一些传统方法,这意味着编码时间并非 LMCompress 在音频压缩应用中的障碍。然而,考虑到非音频数据的时间成本较高,更不用说大型模型高昂的资源和能源消耗,LMCompress 距离实际部署还有一定距离。但这并非长期需要担忧的问题,原因如下36。
首先,大型模型领域的研究者们正积极致力于推理加速和模型规模缩减的研究。我们有理由预期,在不久的将来会出现快速且强大的大型模型,这将使 LMCompress 能够在压缩效率和成本之间取得令人满意的平衡37。
其次,LMCompress 的编码过程相对容易加速,因为不同令牌的预测概率分布计算可以并行进行。这种经过编码加速的 LMCompress 特别适用于静态存储场景,在这类场景中,数据需要长期存储但很少被访问。静态存储的需求正在不断增长,例如监控数据存档、医疗记录和在线交易日志等3839。
方法
无论是有损还是无损的传统压缩方法,都依赖可计算函数来表征数据。在此,我们提出 LMCompress,这是一种基于不可计算的所罗门诺夫归纳法的柯尔莫哥洛夫范式压缩方法 25。大型模型通过不断输入数据来逼近所罗门诺夫归纳法。随着对所罗门诺夫归纳法的逼近程度越高以及对数据的理解越好,压缩率也会相应提高40。
LMCompress 的流程如图 1 所示。首先,我们将原始数据分解为一系列令牌。然后,我们将这个令牌序列输入大型生成模型,该模型会输出每个令牌的预测分布。最后,我们基于这些预测分布使用算术编码对原始数据进行无损压缩。为了增强对各类数据的理解,我们针对不同数据类型使用不同的令牌化工具和生成式大型模型,下文将对其进行更详细的描述41。
图像压缩
我们使用 iGPT 作为图像的生成式大型模型。选择 iGPT 主要基于两个关键因素44。
首先,iGPT 是一种大规模视觉模型,它在海量图像语料库上进行过训练,具备对视觉数据的深入理解能力。这使得 iGPT 非常适合用于图像的分析和处理45。
其次,iGPT 是一种自回归模型。当输入一序列像素时,它能够为序列中的每个像素生成预测概率分布。而概率分布的可获得性是算术编码的前提条件46。
由于GPT 的令牌是灰度值,我们将一张图像视为三个灰度图像,分别对应 RGB 三个通道,并对每个通道独立进行压缩。具体来说,对于每个通道,我们将灰度图像的各行连接成一个灰度像素序列,将该序列输入 iGPT,然后将 iGPT 生成的概率分布输入算术编码器,完成该通道的压缩。在解压缩过程中,每个通道被独立解压缩,之后三个通道被合并以重构原始图像。
然而,由于 iGPT 的上下文窗口有限,一个通道的整个像素序列通常无法一次性输入 iGPT。因此,我们将该序列划分为不重叠的片段(其长度称为上下文长度),每个片段都能适配 iGPT 的上下文窗口。这些片段随后被输入 iGPT 并独立进行压缩。
视频压缩
我们尚未发现公开可用的、能自回归生成像素级概率分布的大型视频模型。这一限制可通过利用视频的固有结构来克服。由于视频由一系列帧组成,我们将每个帧视为一幅图像,如 “图像压缩” 部分所述,使用 iGPT 逐帧对视频进行压缩。具体而言,各帧被独立压缩并按原始顺序存储。在解压缩过程中,各帧被独立解码,然后按顺序排列,以重构原始视频。
在现阶段,我们选择不利用帧间信息进行压缩,主要基于以下两方面考虑。
首先,不考虑帧间信息可使视频编解码器具有可扩展性,能有效避免错误随时间传播,适用于网络环境和点对点场景,且支持随机帧访问。事实上,一些已确立的视频标准并不依赖帧间信息,例如 FFV1(参考文献 26)和 Motion JPEG 2000(参考文献 27)。
其次,LMCompress 难以有效利用帧间信息。一方面,我们观察到帧间信息对 LMCompress 的帮助小于帧内信息。另一方面,由于 iGPT 的上下文窗口固定,纳入帧间信息会减少帧内信息的使用,从而导致性能下降。
音频压缩
音频本质上是一种时序媒体。一段音频由一系列时域帧组成,每个帧使用固定数量的字节对特定时间点的振幅信息进行编码。因此,利用大型自回归模型对音频进行压缩是很自然的选择。
我们使用 bGPT 模型对音频进行压缩,该模型直接在原始音频字节上进行预训练。它接收音频字节序列作为输入,并为序列中的每个字节生成预测概率分布。这些分布随后被输入算术编码器进行压缩。
由于 bGPT 的上下文窗口有限,长音频字节序列将如 “音频压缩” 部分所述进行分段压缩。
文本压缩
大型语言模型在普通文本压缩方面已展现出令人印象深刻的能力 9,10。有趣的是,如果待压缩文本局限于特定领域,大型语言模型有望实现更高效的压缩。关键在于使大型语言模型更好地理解目标领域。这通过在特定领域的文本语料库上对大型语言模型进行微调来实现,使模型适应该领域的特征。然后,为了压缩该领域的文本,我们将其输入经过微调的大型语言模型。该大型语言模型会估计文本中令牌的预测概率,这些概率可被算术编码用于压缩。同样,当大型语言模型的上下文窗口有限时,文本将如 “音频压缩” 部分所述进行分段压缩。
数据可用性
ILSVRC 可通过ImageNet获取。
CLIC 可通过https://clic.compression.cc/2019/获取。
LibriSpeech 可通过www.openslr.org/12获取。
LJSpeech 可通过The LJ Speech Dataset获取。
Mozilla Common Voice 11 可通过https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0获取。
VoxPopuli 可通过https://huggingface.co/datasets/facebook/voxpopuli获取。
MeDAL 可通过https://github.com/McGill-NLP/medal获取。
Eurlex 可通过https://huggingface.co/datasets/pile-of-law/pile-of-law获取。
CIPR SIF 可通过Xiph.org :: Derf's Test Media Collection获取。
代码可用性
我们的代码可通过 Code Ocean 获取,链接为https://doi.org/10.24433/CO.9735997.v1(参考文献 28)。