【Linux网络编程】Reactor反应堆模式
我们之前的代码只是为了了解接口,所以是存在很多问题的。当有文件描述符就绪时,我们就会读,我们为了保证能够将本轮读完,可以才有循环读的方式,但是这样仍然无法保证将一个或多个完整的报文读完,因为可能本轮的所有数据都无法组成一个完整的报文,所以,我们要能够将历史读到的数据进行缓存,而我们的buffer是一个临时的,所以是无法进行缓存的。
我们来写一个综合性的代码,包含了多路转接、协议定制、链接管理。
封装Epoll
namespace EpollModule
{class Epoller{public:Epoller() : _epfd(-1){}void Init(){_epfd = epoll_create(256);if (_epfd < 0){LOG(LogLevel::ERROR) << "epoll_create error";exit(EPOLL_CREATE_ERR);}LOG(LogLevel::INFO) << "epoll_create success, epfd: " << _epfd;}// 输出就绪的fd和eventsint Wait(struct epoll_event revs[], int num, int timeout){int n = epoll_wait(_epfd, revs, num, timeout);if (n < 0){LOG(LogLevel::WARNING) << "epoll_wait error";}return n;}void Ctrl(int sockfd, uint32_t events, int flag){struct epoll_event ev;ev.events = events;ev.data.fd = sockfd;int n = epoll_ctl(_epfd, flag, sockfd, &ev);if (n < 0){LOG(LogLevel::WARNING) << "epoll_ctl error";}}// 在epoll模型中增加一个文件描述符void Add(int sockfd, uint32_t events){Ctrl(sockfd, events, EPOLL_CTL_ADD);}// 在epoll模型中修改一个文件描述符所关心的事件void Update(int sockfd, uint32_t events){Ctrl(sockfd, events, EPOLL_CTL_MOD);}// 在epoll模型中删除一个文件描述符void Delete(int sockfd){int n = epoll_ctl(_epfd, EPOLL_CTL_DEL, sockfd, nullptr);if (n < 0){LOG(LogLevel::WARNING) << "epoll_ctl error";}}~Epoller(){}private:int _epfd; // epoll模型对应的文件描述符};
}协议定制
这里的协议直接使用我们之前自定义的协议。
const std::string Sep = "\r\n"; // 定义分隔符// 添加报头
// {json} -> len\r\n{json}\r\n
// 这里的message是一个序列化后的字符串
bool Encode(std::string& message)
{if(message.size() == 0) return false;// 下面的第二个分隔符是可以不要的。在这里加上是为了方便查看效果std::string package = std::to_string(message.size()) + Sep + message + Sep;message = package;return true;
}// 去除报头
// package是一个从客户端接收到的报文,我们要去除报头后,将内容放到content中
bool Decode(std::string& package, std::string& content)
{auto pos = package.find(Sep);if(pos == std::string::npos) return false;// 提取报头std::string content_length_str = package.substr(0, pos);// 将报头转换为数字int content_length = std::stoi(content_length_str);// 获取完整报文的长度int full_length = content_length_str.size() + content_length + 2 * Sep.size();// 如果package的长度小于一条完整的报文,就无法进行去除报头if(package.size() < full_length) return false;// 获取有效载荷content = package.substr(pos + Sep.size(), content_length);// 将我们拿走的这条报文从package中删除,所以package一定要是引用package.erase(0, full_length);return true;
}class Request
{
public:Request(int x = 0, int y = 0, char oper = 0):_x(x),_y(y),_oper(oper){}bool Serialize(std::string& out_string) // 序列化{Json::Value root;root["x"] = _x;root["y"] = _y;root["oper"] = _oper;Json::StreamWriterBuilder wb;std::unique_ptr<Json::StreamWriter> w(wb.newStreamWriter());std::stringstream ss;w->write(root, &ss);out_string = ss.str();return true;}bool Deserialize(std::string& in_string) // 反序列化{Json::Value root;Json::Reader reader;bool parsingSuccessful = reader.parse(in_string, root);if(!parsingSuccessful){std::cout << "Failed to parse JSON: " << reader.getFormatedErrorMessages() << std::endl;return false;}_x = root["x"].asInt();_y = root["y"].asInt();_oper = root["oper"].asInt();return true;}int X() const { return _x; }int Y() const { return _y; }char Oper() const { return _oper; }
private:int _x;int _y;char _oper;
};class Response
{
public:Response(int result = 0, int code = 0):_result(result),_code(code){}bool Serialize(std::string& out_string) // 序列化{Json::Value root;root["result"] = _result;root["code"] = _code;Json::StreamWriterBuilder wb;std::unique_ptr<Json::StreamWriter> w(wb.newStreamWriter());std::stringstream ss;w->write(root, &ss);out_string = ss.str();return true;}bool Deserialize(std::string& in_string) // 反序列化{Json::Value root;Json::Reader reader;bool parsingSuccessful = reader.parse(in_string, root);if(!parsingSuccessful){std::cout << "Failed to parse JSON: " << reader.getFormatedErrorMessages() << std::endl;return false;}_result = root["result"].asInt();_code = root["code"].asInt();return true;}int Result() const { return _result; }int Code() const { return _code; }void SetResult(int res) { _result = res; }void SetCode(int code) { _code = code; }
private:int _result; // 结果int _code; // 出错码,0表示计算成功,1,2,3,4表示相应的错误
};
class Calculator
{
public:Calculator() {}Response Execute(const Request &req) // 给计算器一个Request,返回一个Response{Response resp;switch (req.Oper()){case '+':resp.SetResult(req.X() + req.Y());break;case '-':resp.SetResult(req.X() - req.Y());break;case '*':resp.SetResult(req.X() * req.Y());break;case '/':{if (req.Y() == 0){resp.SetCode(1); // 1 就是除0}else{resp.SetResult(req.X() / req.Y());}}break;case '%':{if (req.Y() == 0){resp.SetCode(2); // 2 就是mod 0}else{resp.SetResult(req.X() % req.Y());}}break;default:resp.SetCode(3); // 3 用户发来的计算类型,无法识别break;}return resp;}~Calculator() {}
}cal;// 从用户的接收缓冲区中获取一条或多条完整的报文,将其反序列化,构建应答,再序列化
// 将一条或多条应答拼接在一起,然后返回
// 如果用户的接收缓冲区中没有一条完整的报文,返回的就是一个空字符串
std::string HandlerRequest(std::string &inbuffer)
{std::string request_str;std::string result_str;while (Decode(inbuffer, request_str)){std::string resp_str;// 一定拿到了一个完整报文// 1. 反序列化if (request_str.empty())break;Request req;if (!req.Deserialize(request_str))break;// 2. 业务处理Response resp = cal.Execute(req);// 3. 序列化resp.Serialize(resp_str);// 4. 添加长度说明 -- 协议Encode(resp_str);// 5. 添加所有的应答result_str += resp_str;}return result_str;
}链接管理
在之前的代码中,因为缓冲区是一个临时缓冲区,所以没办法对历史读到的数据进行缓存,为了能够进行缓存,我们对文件描述符进行封装,因为一个链接对应一个文件描述符,所以实际上就是对链接进行封装。
我们知道,文件描述符分为两种,一种是普通fd,一种是监听fd。普通fd既关心读事件,又关心写事件,监听fd只关心读事件。并且普通fd的读事件和监听fd的读事件的处理方式是不同的。我们想让对fd的处理方式采用同一种处理方式,所以,我们让Connection成为基类,让普通fd、监听fd均成为派生类。
// 普通的fd, Listensockfd;
// 让对fd的处理方式采用同一种方式
// 描述一个连接
class Connection
{
public:Connection() : _sockfd(-1), _events(0){// 自动获得当前系统的时间戳}// 设置客户端信息void SetPeerInfo(const InetAddr &peer_addr){_peer_addr = peer_addr;}// 设置文件描述符void SetSockfd(int sockfd){_sockfd = sockfd;}// 获取文件描述符int Sockfd() { return _sockfd; }// 设置链接关心的事件void SetEvents(uint32_t events) { _events = events; }// 获取链接关心的事件uint32_t GetEvents() { return _events; }// 设置链接所属的服务器void SetOwner(Reactor *owner){_owner = owner;}// 获取链接所属的服务器指针Reactor *GetOwner(){return _owner;}// 把收到的数据,添加到自己的接受缓冲区void Append(const std::string &in){_inbuffer += in; }// 把要发送的数据,添加到自己的发送缓冲区void AppendToOut(const std::string &out){_outbuffer += out;}// 从发送缓冲区删除n个字符void DisCardOutString(int n){_outbuffer.erase(0, n);}// 判断发送缓冲区是否满了bool IsOutBufferEmpty() { return _outbuffer.empty(); } // 获取发送缓冲区std::string &OutString(){return _outbuffer;}// 获取接收缓冲区std::string &InBuffer(){return _inbuffer;}void Close(){if(_sockfd>=0)close(_sockfd);}// 回调方法virtual void Sender() = 0;virtual void Recver() = 0;virtual void Excepter() = 0;~Connection(){}protected:int _sockfd; // 这个链接所对应的文件描述符std::string _inbuffer; // 链接的接收缓冲区std::string _outbuffer; // 链接的发送缓冲区InetAddr _peer_addr; // 链接对应的客户端// 指向这个链接所属服务器的指针Reactor *_owner;// 这个链接关心的事件uint32_t _events;
};对于监听套接字,只关心读事件,当读事件就绪,就获取新链接。
// 专门负责获取链接的模块
// 连接管理器
class Listener : public Connection
{
public:Listener(int port): _listensock(std::make_unique<TcpSocket>()),_port(port){_listensock->BuildTcpSocket(_port);SetSockfd(_listensock->Fd());// 只关心读事件,并且以ET模式工作SetEvents(EPOLLIN|EPOLLET);}virtual void Sender() override{}// 我们回调到这里,天然就有父类connectionvirtual void Recver() override{// 读就绪,而是是listensock就绪// IO处理 --- 获取新连接// 你怎么知道,一次来的,就是一个连接呢?你怎么保证你一次读完了么?while (true){InetAddr peer;int aerrno = 0;// accept 非阻塞的时候,就是IO,我们就向处理read一样,处理acceptint sockfd = _listensock->Accepter(&peer, &aerrno);if (sockfd > 0){// 获取新链接成功,需要将新链接对应的文件描述符交给Reactor服务器,让它帮我们关心这个链接的读、写事件// 注意:Reactor服务器是只认Connection的// 所以我们要将新链接对应的文件描述符交给Reactor服务器,需要先使用这个文件描述符封装一个ConnectionLOG(LogLevel::DEBUG) << "Accepter success: " << sockfd;// 2. sockfd包装成为Connection!auto conn = std::make_shared<IOService>(sockfd);// 注册回调函数conn->RegisterOnMessage(HandlerRequest); // 3. 插入到ReactorGetOwner()->InsertConnection(conn);}else{// 获取新链接失败if (aerrno == EAGAIN || aerrno == EWOULDBLOCK){// 已经将全部的链接都获取完了LOG(LogLevel::DEBUG) << "accetper all connection ... done";break;}else if (aerrno == EINTR){LOG(LogLevel::DEBUG) << "accetper intr by signal, continue";continue;}else{LOG(LogLevel::WARNING) << "accetper error ... Ignore";break;}}}}virtual void Excepter() override{}int Sockfd() { return _listensock->Fd(); }~Listener(){_listensock->Close();}private:std::unique_ptr<Socket> _listensock;int _port;
};对于普通套接字,既关心读事件,又关心写事件。
当读事件就绪时,就将内核接收缓冲区的数据读取到用户层,因为是基于ET模式的,所以一定要将内核接收缓冲区的数据全部读完,读完之后,全部的数据都放到了用户的接收缓冲区当中,此时就交给注册进来的回调函数,这个回调函数就会基于协议,对用户的接收缓冲区的数据进行处理,当然,如果用户的接收缓冲区内的数据不满足一条完整的报文,也不会处理,如果满足一条,甚至多条完整的报文,就会处理后再返回处理结果,就可以将应答放入到用户的发送缓冲区了。
当写事件就绪时,就将用户的发送缓冲区内的数据发送出去。
多路转接对于写的管理:
1. 写事件就绪:发送缓冲区是否有空间。有空间时,就是写事件就绪。对于任意一个文件描述符,发送缓冲区的空间默认就是有的。
2. 如何正确处理写入?
直接写,因为默认就是有空间的,所以直接写是不会被阻塞的。因为我们写入后,OS不一定会发送出去,所以写满了之后,写条件不具备了,才托管给epoll,让它帮我们关心。所以,读是直接托管给epoll,而写是直接写,当写入失败时,才托管给epoll。
多路转接的方案设计的时候,写事件关心,永远不能常开启。否则可能会一直通知是就绪的。对于写事件关心,永远都是按需设置。读事件通常一直关心。
因为我们现在是基于ET模式的,所以我们需要提供一个函数,将文件描述符设置为非阻塞。
// 将文件描述符设置为非阻塞
void SetNonBlock(int sockfd)
{int fl = fcntl(sockfd, F_GETFL);if(fl < 0){return;}fcntl(sockfd, F_SETFL, fl | O_NONBLOCK);
}
using func_t = std::function<std::string(std::string &)>;// 定位:只负责IO
class IOService : public Connection
{static const int size = 1024;public:IOService(int sockfd){// 1. 设置文件描述符非阻塞SetNonBlock(sockfd);SetSockfd(sockfd);SetEvents(EPOLLIN | EPOLLET);}// 将发送缓冲区的数据发送出去virtual void Sender() override{while (true){ssize_t n = send(Sockfd(), OutString().c_str(), OutString().size(), 0);if (n > 0){// 成功DisCardOutString(n); // 移除N个}else if (n == 0){// 发送缓冲区没有数据了break;}else{if (errno == EAGAIN || errno == EWOULDBLOCK){// 缓冲区写满了,下次再来break;}else if (errno == EINTR){continue;}else{// 发送异常了,进行异常处理Excepter();return;}}}// 此时会有两种原因导致结束循环// 1. 用户的发送缓冲区没有数据了,也就是这个链接的_outbuffer为空了// 处理方法:开启对读事件的关心// 2. 内核的发送缓冲区被写满了 && 用户的发送缓冲区还有数据,写条件不满足,使能sockfd在epoll中的事件// 处理方法:开启对读、写事件的关心if(!IsOutBufferEmpty()){// 修改对sockfd的事件关心!-- 开启对写事件关心// 按需设置!GetOwner()->EnableReadWrite(Sockfd(), true, true);}else{GetOwner()->EnableReadWrite(Sockfd(), true, false);}}// 我们回调到这里,天然就有父类connectionvirtual void Recver() override{// UpdateTime();// 1. 读取所有数据while (true) // ET模式{char buffer[size];ssize_t s = recv(Sockfd(), buffer, sizeof(buffer) - 1, 0); // 非阻塞if (s > 0){buffer[s] = 0;// 读取成功了Append(buffer);}if (s == 0){// 对端关闭连接Excepter();return;}else{if (errno == EAGAIN || errno == EWOULDBLOCK){break;}else if (errno == EINTR){continue;}else{// 发生错误了Excepter();return;}}}// 走到下面,我一定把本轮数据读取完毕了std::cout << "outbuffer: \n"<< InBuffer() << std::endl;// 你能确保你读到的消息,就是一个完整的报文吗??不能!!!// 我们怎么知道,读到了完整的请求呢??协议!!!std::string result;if (_on_message)result = _on_message(InBuffer()); // 将读到的消息进行序列化// 将序列化后的消息添加到用户的发送缓冲区AppendToOut(result);// 如何处理写的问题, outbuffer 发送给对方的问题!if (!IsOutBufferEmpty()){//方案一: Sender(); // 直接发送, 推荐做法//方案二: 使能Writeable即可.GetOwner()->EnableReadWrite(Sockfd(), true, true);}}virtual void Excepter() override{// IO读取的时候,所有的异常处理,全部都会转化成为这个一个函数的调用// 出现异常,我们怎么做???// 打印日志,差错处理,关闭连接,Reactor异常connection, 从内核中,移除对fd的关心LOG(LogLevel::INFO) << "客户端连接可能结束,进行异常处理: " << Sockfd();GetOwner()->DelConnection(Sockfd());}void RegisterOnMessage(func_t on_message){_on_message = on_message;}~IOService(){}private:func_t _on_message; // 回调函数,将上层的业务处理函数注册进来
};Reactor服务器
using connection_t = std::shared_ptr<Connection>;class Reactor
{const static int event_num = 64;
private:// 判断一个链接是否在这个Reactor服务器当中bool IsConnectionExists(int sockfd){return _connections.find(sockfd) != _connections.end();}
public:Reactor() : _isrunning(false), _epoller(std::make_unique<Epoller>()){_epoller->Init();}// 向这个Reactor服务器插入一个链接void InsertConnection(connection_t conn){auto iter = _connections.find(conn->Sockfd());if (iter == _connections.end()){// 1. 把连接,放到unordered_map中进行管理_connections.insert(std::make_pair(conn->Sockfd(), conn));// 2. 把新插入进来的连接,写透到内核的epoll中_epoller->Add(conn->Sockfd(), conn->GetEvents());// 3. 设置关联关系,让connection回指当前对象conn->SetOwner(this);LOG(LogLevel::DEBUG) << "add connection success: " << conn->Sockfd();}}// 修改对于一个链接的读、写事件void EnableReadWrite(int sockfd, bool readable, bool writeable){if (IsConnectionExists(sockfd)){// 修改用户层connection的事件uint32_t events = ((readable ? EPOLLIN : 0) | (writeable ? EPOLLOUT : 0) | EPOLLET);_connections[sockfd]->SetEvents(events);// 写透到内核中_epoller->Update(sockfd, _connections[sockfd]->GetEvents());}}// 从这个Reactor服务器中删除一个链接void DelConnection(int sockfd){if (IsConnectionExists(sockfd)){// 1. 从内核中异常对sockfd的关心_epoller->Delete(sockfd);// 2. 关闭特定的文件描述_connections[sockfd]->Close();// 3. 从_connections中移除对应的connection_connections.erase(sockfd);}}void Dispatcher(int n){for (int i = 0; i < n; i++){// 开始进行派发, 派发给指定的模块int sockfd = _revs[i].data.fd;uint32_t revents = _revs[i].events;if ((revents & EPOLLERR) || (revents & EPOLLHUP))revents = (EPOLLIN | EPOLLOUT); // 异常事件,转换成为读写事件if ((revents & EPOLLIN) && IsConnectionExists(sockfd)){_connections[sockfd]->Recver();}if ((revents & EPOLLOUT) && IsConnectionExists(sockfd)){_connections[sockfd]->Sender();}}}void LoopOnce(int timeout){int n = _epoller->Wait(_revs, event_num, timeout);Dispatcher(n);}void Loop(){_isrunning = true;// int timeout = -1;int timeout = 1000;while (_isrunning){LoopOnce(timeout);// 超时管理// 简单的,遍历_connections, 判断当前时间 - connection的最近访问时间>XXX// 超时了}_isrunning = false;}void Stop(){_isrunning = false;}~Reactor(){}private:std::unique_ptr<Epoller> _epoller; // 不要忘记初始化std::unordered_map<int, connection_t> _connections; // fd: Connection, 服务器内部所有的连接bool _isrunning;struct epoll_event _revs[event_num];
};
// ./select_server 8080
int main(int argc, char *argv[])
{if (argc != 2){std::cout << "Usage: " << argv[0] << " port" << std::endl;return 1;}ENABLE_CONSOLE_LOG();uint16_t local_port = std::stoi(argv[1]);Reactor reactor;auto conn = std::make_shared<Listener>(local_port);reactor.InsertConnection(conn);reactor.Loop();return 0;
}可以看到,在Reactor服务器这里,只认识一个一个的Connection。Reactor的工作原理很简单,就是通过epoll对文件描述符进行监控,当有文件描述符的事件就绪了,就判断一下这个就绪的事件是读事件,还是写事件,然后调用这个文件描述符对应的Connection的读方法或写方法,从而对事件进行处理。
这种基于事件派发,底层对一个一个的事件节点进行管理的模式称为Reactor模式,反应堆模式。我们讲一个例子帮助理解,Reactor 模式就是一种 “事件管家” 模式。有个"大管家”(Reactor)专门盯着所有的I/O操作(比如网络连接、数据收发),它不自己干活,只负责“等事儿发生”(比如有数据来了、可以发数据了),一旦有事发生,就喊对应的"专业人员”(Handler)来处理(比如读数据、发响应),全程靠“有事再处理”,不瞎忙,所以能高效应对一大堆并发连接。
Reactor 模式是一种基于事件驱动的设计模式,而多路转接(如 select/poll/epoll 等)是实现该模式的关键技术手段。
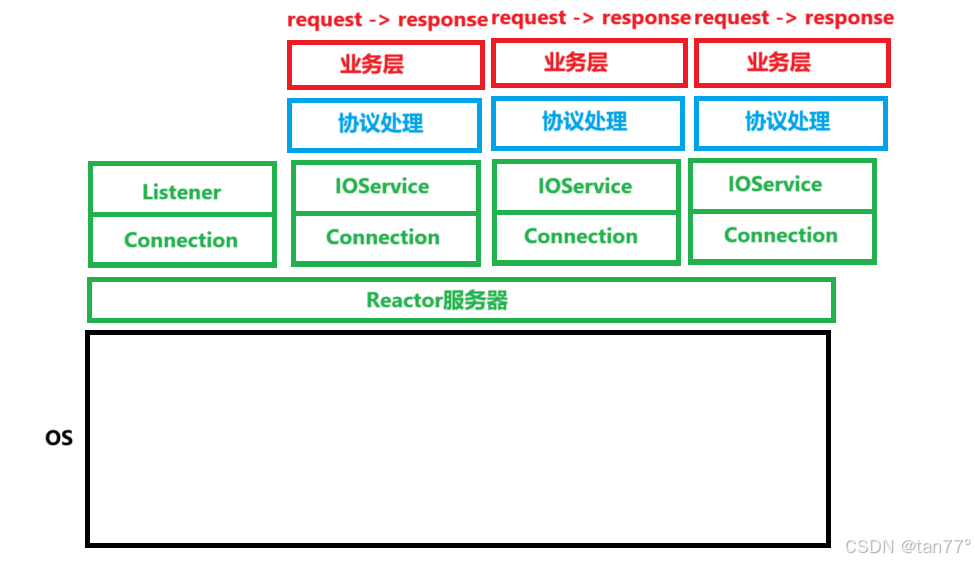
多进程/多线程
我们现在的Reactor服务器是一个单进程的Reactor服务器。
如果我们想使用线程池,可以当一个文件描述符接收到请求时,将这个请求交给线程池中的某个线程来处理,这样太麻烦了。并且当一个文件描述符接收到多个请求时,会将这些请求分别交给线程池中的线程处理,这样就没办法按照接收到请求的顺序发送应答了。
我们的主要思想是:一个fd(Connection)的全生命周期,只能由一个线程统一管理这样就不会存在任何(过多)并发问题。
多进程模式
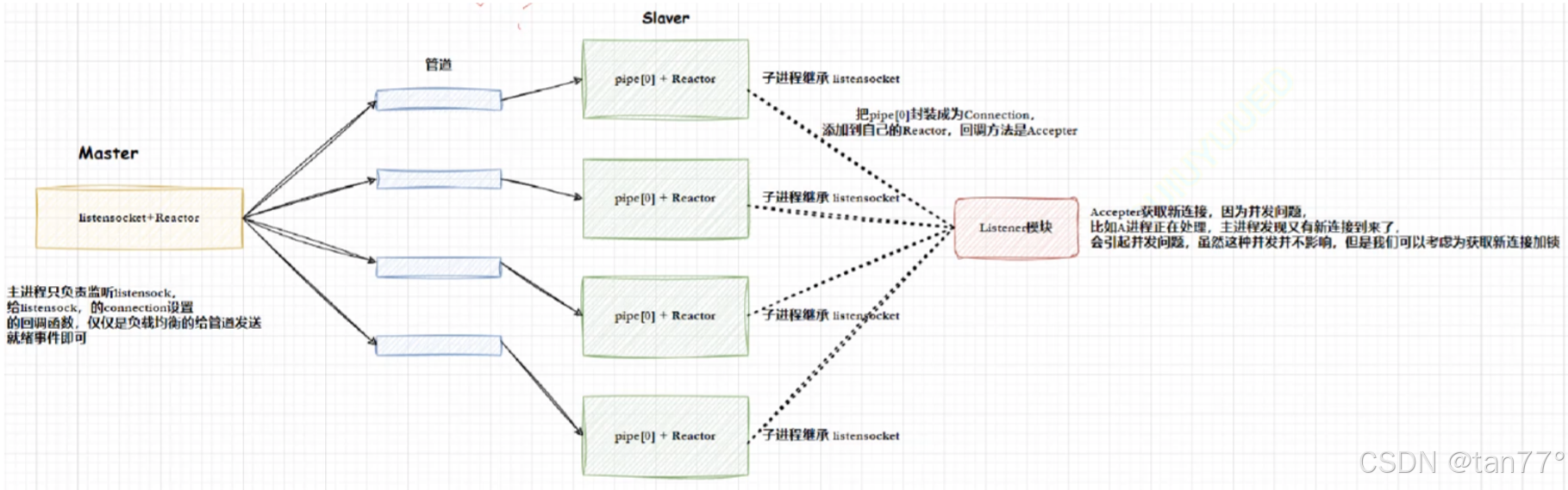
主进程创建监听套接字和自己的Reactor,这个进程称为Master进程,Master创建多个子进程,并通过管道来连接。当Master的监听套接字发现有事件就绪了,Master不会accept,它会通过管道通知某一个进程,其实就是将事件就绪的函数设置为向指定的子进程,也就是管道写入就绪。这个过程就是将链接获取进行负载均衡派发。Master是先创建监听套接字,然后再创建子进程,所以所有的子进程是可以看到监听套接字的文件描述符的。
我们只需要让子进程从一开始就关心管道的读端,就是将管道读端对应的文件描述符添加到epoll中,并设置一个回调函数,当管道读端就绪了,并且读到是数据是1(提前规定),就从listensockfd获取新链接,并添加到自己的epoll中即可。
这种模式称为One Thread One Loop'
多线程版本
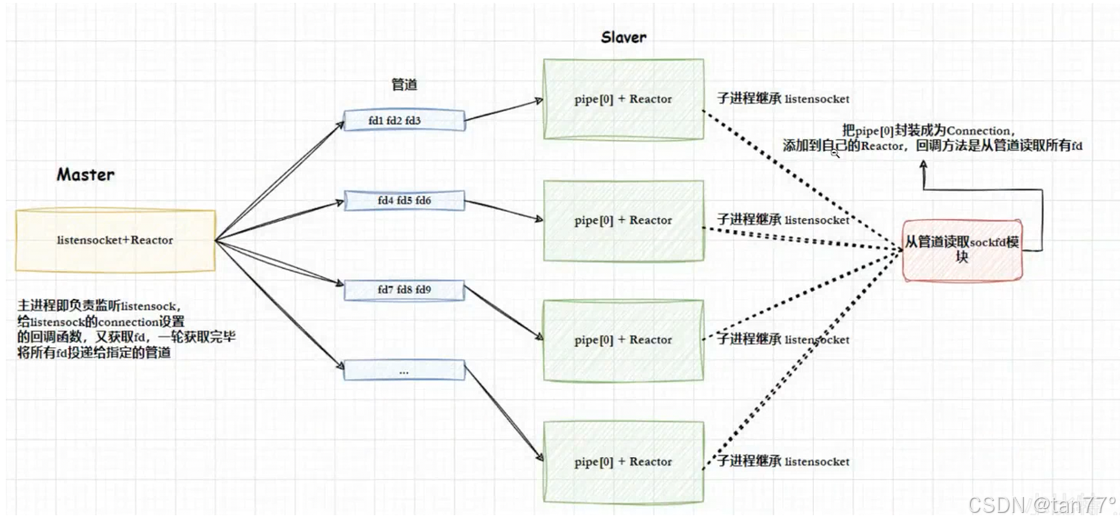
主线程和新线程之间的通信仍然使用管道,因为是两个执行流。主线程将listensockfd添加到自己的Reactor中,新线程将pipe[O]添加到自己的Reactor中。当有新链接时,主线程获取新链接,并将对应的文件描述符通过管道交给新线程。新线程再将链接的文件描述符添加到自己的Reactor中
上面使用了管道,实际上并不是很好,这里可以使用生产者消费者模型。但是使用生产者消费者模型时,当新线程没有被唤醒时,是在哪里等待呢?之前是在条件变量等,但是条件变量是不能和epol整合到一起的,因为条件变量是基于pthread库的。只能在其中一个上面等,另一个就绪了就没办法及时处理。管道是基于文件描述符的,所以可以整合到epoll当中。
若不想使用管道,就需要有线程间基于文件描述符的通知机制。
#include <sys/eventfd.h>int eventfd(unsigned int initval, int flags);evectfd会通过返回的文件描述符来进行事件通知。eventfd是一个轻量级的事件通知机制,基于文件描述符。它可以与I/O多路复用机制(如epo11)结合使用。内核维护一个64位的计数器,write会增加计数器,read会减少计数器。每写入一次,就会让底层的计数器增加,读时会清0,若读时为0,则会阻塞。
int main()
{// 传入0,表示将计数器初始化为0int efd = eventfd(0, EFD_CLOEXEC);if(efd == -1){perror("eventfd");return 1;}pid_t pid = fork();if(pid == -1){perror("fork");return 1;}if(pid == 0){// 子进程uint64_t value;read(efd, &value, sizeof(value)); // 从efd中读取事件close(efd);return 0;}else{// 父进程uint64_t value = 1;write(efd, &value, sizeof(value)); // 向efd写入事件wait(NULL);close(efd);return 0;}return 0;
}父进程向里面写入,子进程就可以从里面读取了。在线程间也是同理。
特点:
- 低开销:eventfd内部是一个64位计数器,内核维护成本低。
- 支持多路复用:可以与epol1、pol1或select等I/O多路复用机制结合使用。
- 原子性:读写操作是原子的,适合高并发场景。
- 广播通知:可以用于多对多的事件通知,而不仅仅是点对点通信。
- 高效性:相比传统管道,eventfd避免了多次数据拷贝,且内核开销更小。
注意事项:
- 仅用于事件通知:eventfd不能传递具体的消息内容,仅用于通知事件的发生。
- 非阻塞模式:建议设置EFD_NONBLOCK,避免阻塞操作。
- 信号量语义:如果需要信号量语义(每次读取计数器减1),需设置EFD_SEMAPHORE。
- 资源管理:使用完eventfd后,记得关闭文件描述符。
- 结合I/O多路复用:在高并发场景下,建议结合epoll使用。
Eventfd工作模式:
- 普通模式:不设置EFD_SEMAPHORE,读取的时候,计数器会清空
- 设置EFD_SEMAPHORE:信号量模式
普通模式:假设先写入一次1,计数器就会变成1,再写入一个2,计数器会变成3,现在循环读取3次,会一次全部读取完,第一次读到的值是3,第二次、第三次均为0。
信号量模式:假设先写入一次1,计数器就会变成1,再写入一个2,计数器会变成3,读取时,第一次读到1,第二次读到1,第三次读到1。
一般使用的都是普通模式。通过eventfd,就可以通过一个文件描述符,在两个线程之间发送信息了。
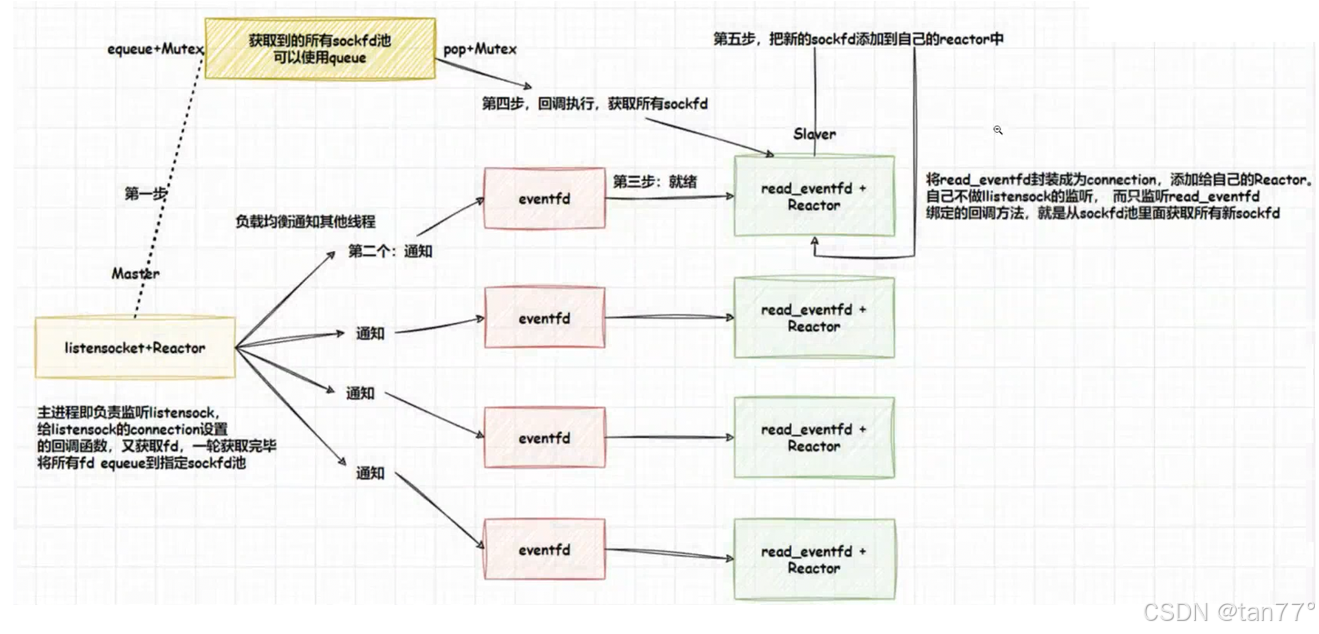
主线程当有新链接到来时,会获取新连接。每获取一个新链接,会将这个链接对应的文件描述符放入到一个队列当中。并且主线程会提前创建多个eventfd与新线程关联。当获取一个新链接时,会通过eventfd通知某一个新线程。新线程会将eventfd的读端添加到Reactor中,绑定的回调函数就是当这个文件描述符就绪了,就先加锁,并从这个队列中获取新链接的文件描述符。这样,文件描述符传递使用的就是用户空间,而通知使用的是eventfd。还可以再拓展,达到多Reactor,多线程。每一个新线程的Reactor不做lo处理,而是再创建线程来进行IO处理。