DataStream实现WordCount
目录
- 读取文本数据
- 读取端口数据
事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批统一之后的DataStream API更加强大,可以直接处理批处理和流处理的所有场景。
读取文本数据
需要处理数据如下:
hello flink
hello java
hello world
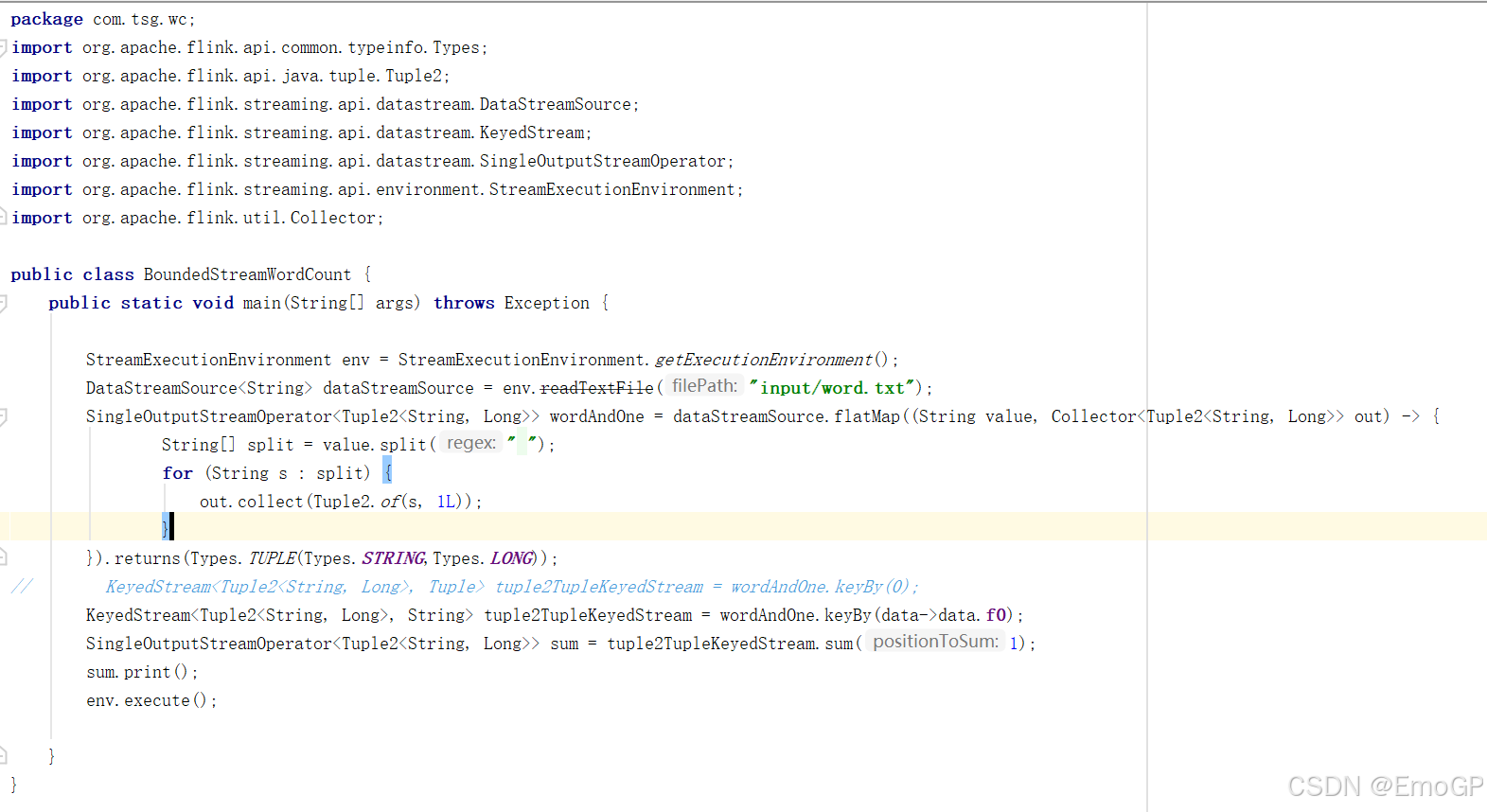
package com.tsg.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class BoundedStreamWordCount {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> dataStreamSource = env.readTextFile("input/word.txt");SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = dataStreamSource.flatMap((String value, Collector<Tuple2<String, Long>> out) -> {String[] split = value.split(" ");for (String s : split) {out.collect(Tuple2.of(s, 1L));}}).returns(Types.TUPLE(Types.STRING,Types.LONG));
// KeyedStream<Tuple2<String, Long>, Tuple> tuple2TupleKeyedStream = wordAndOne.keyBy(0);KeyedStream<Tuple2<String, Long>, String> tuple2TupleKeyedStream = wordAndOne.keyBy(data->data.f0);SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2TupleKeyedStream.sum(1);sum.print();env.execute();}
}

读取端口数据

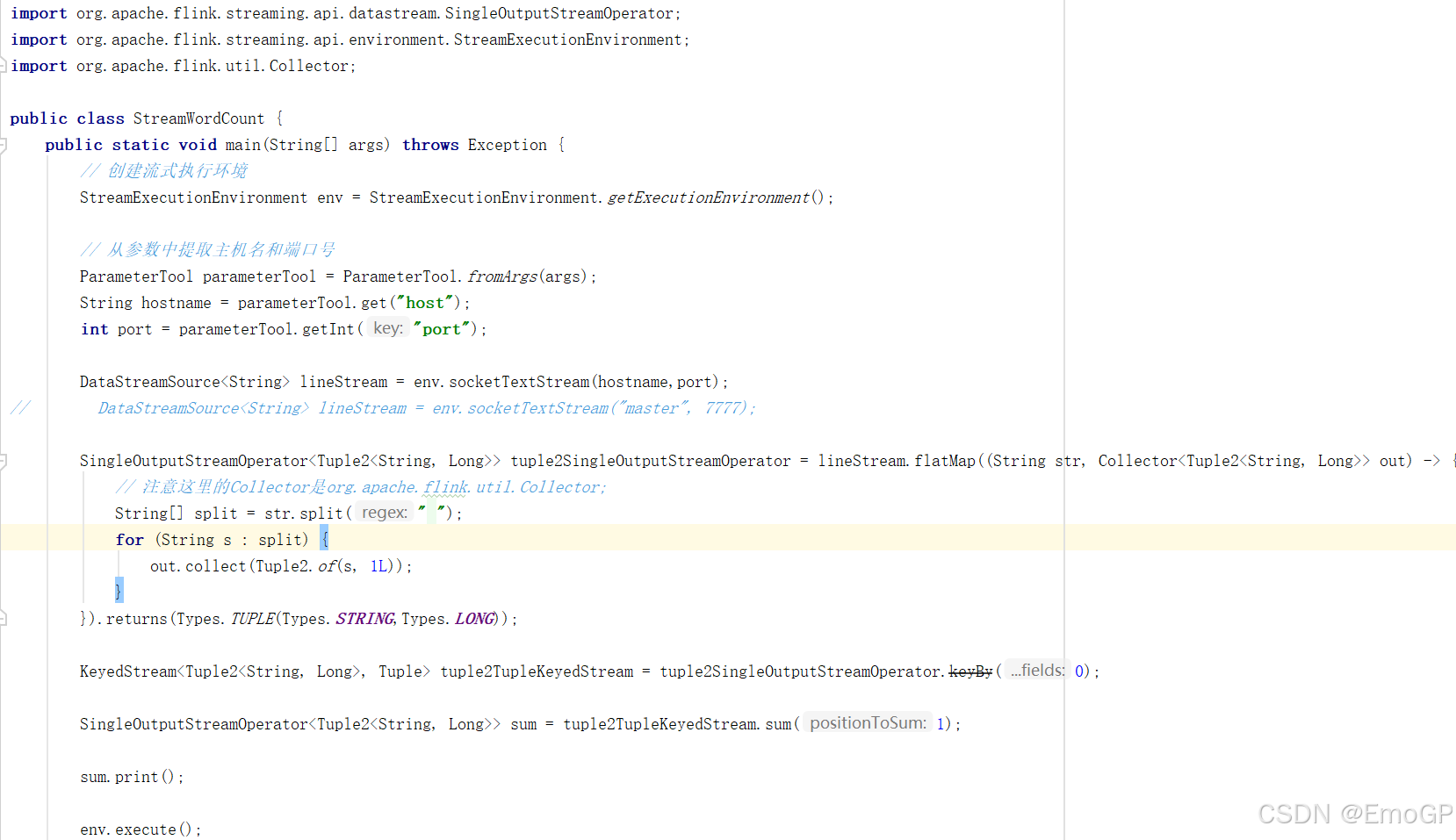
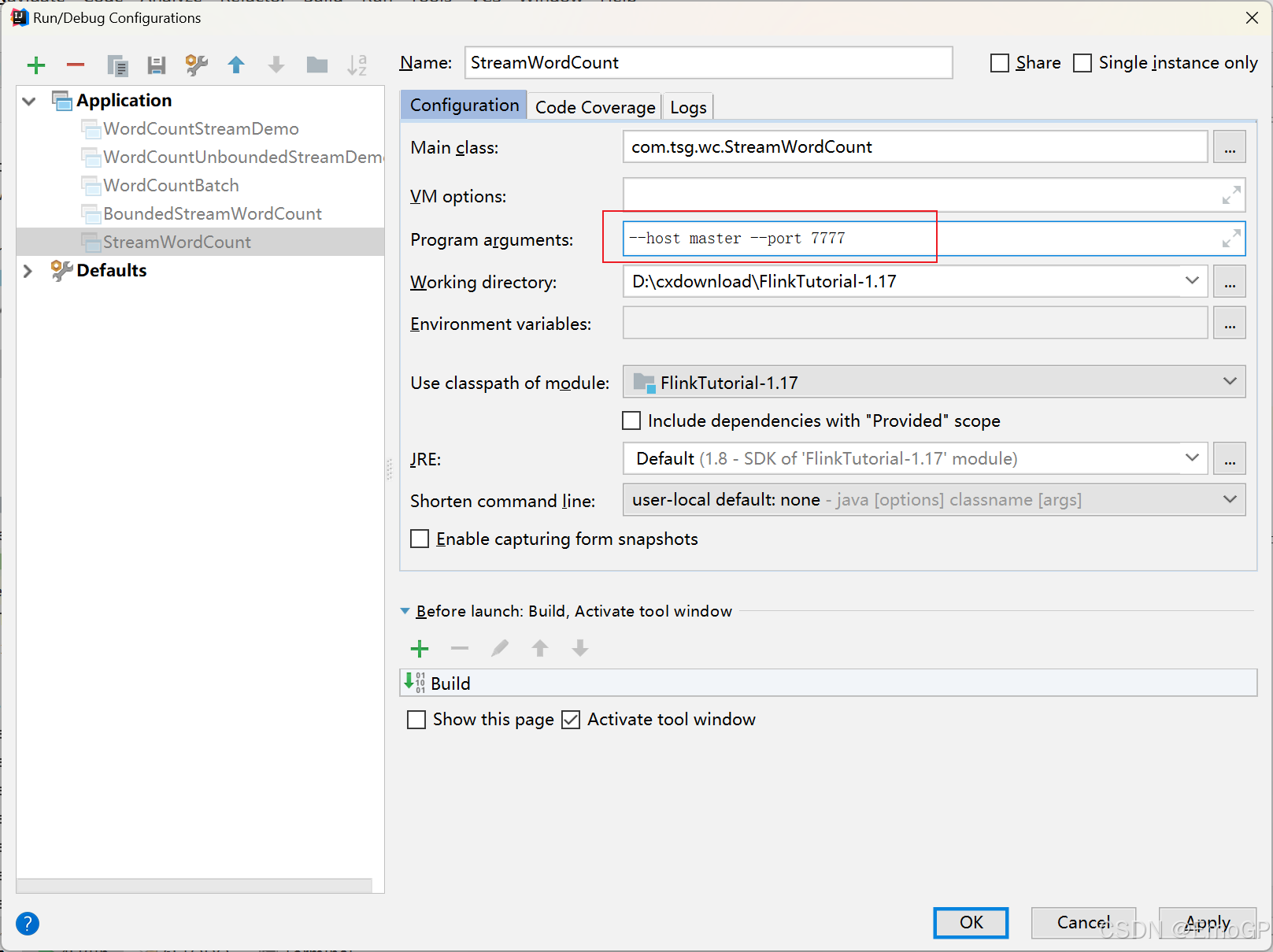
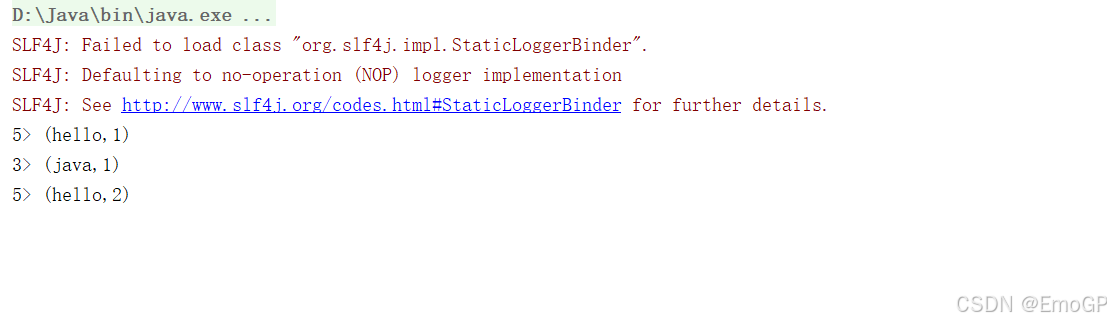
package com.tsg.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class StreamWordCount {public static void main(String[] args) throws Exception {// 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 从参数中提取主机名和端口号ParameterTool parameterTool = ParameterTool.fromArgs(args);String hostname = parameterTool.get("host");int port = parameterTool.getInt("port");DataStreamSource<String> lineStream = env.socketTextStream(hostname,port);
// DataStreamSource<String> lineStream = env.socketTextStream("master", 7777);SingleOutputStreamOperator<Tuple2<String, Long>> tuple2SingleOutputStreamOperator = lineStream.flatMap((String str, Collector<Tuple2<String, Long>> out) -> {// 注意这里的Collector是org.apache.flink.util.Collector;String[] split = str.split(" ");for (String s : split) {out.collect(Tuple2.of(s, 1L));}}).returns(Types.TUPLE(Types.STRING,Types.LONG));KeyedStream<Tuple2<String, Long>, Tuple> tuple2TupleKeyedStream = tuple2SingleOutputStreamOperator.keyBy(0);SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2TupleKeyedStream.sum(1);sum.print();env.execute();}
}