RoboTwin--CVPR2025--港大--2025.4.17--开源
0. 前言

Robotwin 2.0 是很好的工作,在社区中的反响非常好,所以来看看可能是RoboTwin2.0的前身的这篇文章。
项目页:RoboTwin2.0
论文页
github
@article{mu2024robotwin,title={RoboTwin: Dual-Arm Robot Benchmark with Generative Digital Twins (early version)},author={Mu, Yao and Chen, Tianxing and Peng, Shijia and Chen, Zanxin and Gao, Zeyu and Zou, Yude and Lin, Lunkai and Xie, Zhiqiang and Luo, Ping},journal={arXiv preprint arXiv:2409.02920},year={2024}
}
1. 背景与相关技术
1.1 提出问题
在飞速发展的机器人领域,双臂协调与复杂物体操控是构建先进自主系统的关键能力。具备复杂双臂协同与精细灵巧性的机器人系统,对于实现复杂物体操控并在医疗、制造、物流与家务等领域解锁高级能力是必不可少的。
然而,缺乏多样且高质量的示范数据以及与现实对齐的评估基准,严重制约了这些能力的发展。
数据少 + 基准不吻合 → 学到的 policy 在真实世界泛化差。
传统的数据收集方法,尤其是人类远程操控(teleoperation),能获得高质量示范,但存在显著的实际限制。虽然这些方法能提供可靠的训练数据,但通常代价昂贵、耗时,并且难以覆盖机器人在真实部署中会遇到的多样场景。为了应对这些限制,研究者转向在仿真中使用算法化轨迹生成器。
然而,这些替代方法往往需要针对具体任务的设计,从而限制了它们的泛化能力与可扩展性。最近的进展(如 MimicGen 与 RoboCaca)已经展示了从有限人类示范生成大规模仿真专家数据的显著成果。
然而,这些方法通常在固定场景设置下运行,难以处理超出预定义配置的任务变体,从而限制了它们对新场景的泛化能力。现有基准的另一个局限是,它们主要集中于单臂任务或两个独立臂的双手任务,而未能体现一体化双臂系统所固有的复杂性与协调需求。
虽然 HumanoidBench 与 BiGym 探索了类人双手操作的基准,但它们的可扩展性受限于固定环境或对 VR 远程操控示范收集的依赖。因此,这些差距凸显出急需一个可扩展、标准化的双臂协作基准,并配以高效的数据采集流水线。
1.2 解决问题
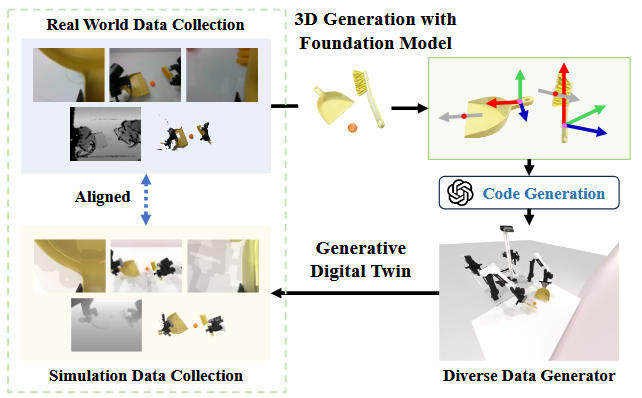
为了解决这些问题(fig1),作者提出了 RoboTwin——一个生成式的 digital twin 框架,利用 3D 生成型 foundation models 与大型语言模型(LLMs)来生成多样化的专家数据集,并为双臂机器人任务提供与现实对齐的评估平台。
具体来说,RoboTwin 能从单张 2D 图像利用生成型 foundation models生成多样化的对象 ,从而构建逼真且可交互的场景。每个对象类别都附带空间标注,定义了功能轴(function axes)、接近轴(approach axes)、横向轴(lateral axes)与接触点(contact points),并通过特征点匹配技术在同类别的不同实例之间通用。
在这些具有空间感知的 digital twin 基础上,RoboTwin 利用 LLM 来解释并将复杂任务分解为可管理的子任务。对于每个子任务,我们推断其终端状态的约束条件。
例如在敲击任务中,锤头的功能点需要与目标物体的表面对齐。RoboTwin 接着生成可执行代码,根据这些空间约束与对象属性计算关键位姿,并与底层规划模块接口以生成完整且可行的执行轨迹。
他们的框架提供了一个包含仿真与真实数据的综合基准,从而实现标准化评估并改善仿真训练与真实表现之间的对齐。在开源的 COBOT Magic Robot 平台上验证了该方法。
在 RoboTwin 生成的数据上预训练并用有限真实样本微调的策略(policy)表明,在 300 个 RoboTwin 生成样本上预训练并用 20 个真实样本微调的策略,与仅用 20 个真实样本训练的策略相比,在单臂操控任务(例如敲击)上的成功率提升了 70%,在双臂协调任务(例如ball sweep)上的提升超过 40%。
总结的主要贡献包括:
- 建立了一个便捷的 real-to-sim 流水线,仅需一张来自真实世界的 RGB 图像即可借助 3D 生成型 foundation model 生成多样化的目标对象 3D 模型;
- 创建了一个空间感知的代码生成框架,利用大型语言模型与目标对象的空间注释自动生成专家级示范数据。
- 开发了一个包含真实远程操控数据与为相应场景生成的高保真合成数据的双臂操作标准基准。
需要一张草莓图生成多样化的3D模型,利用LLM与草莓空间注释生成专家及示范数据。
这些进展为生成多样且高质量的训练数据以及双臂操作任务的策略评估提供了一个稳健的框架,对构建更强大、更通用的机器人系统具有重要贡献。
1.3 相关技术
机器人领域的数据集和基准
为收集用于机器人任务的有效示范,遥操是最常见的方法,人类通过手动引导机器人执行各种任务。近来有进展是通过组织多人团队、长期采集来构建大规模真实世界数据集。另一种方法是在仿真器中使用算法化轨迹生成器来产生示范数据。
然而,这类方法通常需要为每个任务进行手工、任务特定的设计。最近的一些工作(如 MimicGen 与 RoboCaca)通过将动作适配到新的物体位姿来生成仿真专家数据,但仍局限于固定场景和预定义任务配置。此外,它们对固定三维物体的依赖限制了交互对象与形状的多样性。
另外,ManiSkill 提供了多样的仿真场景,但缺乏自动化的数据收集机制。
相比之下,RoboTwin 利用 3D 生成型 foundation models 与 LLMs 来自主生成任务变体与相应的专家示范。RoboTwin 从 3D 资产出发,通过空间推理生成任务场景与可执行代码,从而最小化人工干预并支持多样化的物体外观。
双臂操作
尽管单臂操控取得了显著进展,协同多臂操控仍然在很大程度上未被充分探索。
Peract2 为双手任务(两臂相对独立的设置)提供了基准,但其设置没有涵盖一体化双臂系统所具有的复杂性。HumanoidBench 在固定的强化学习基准中评估类人机器人精巧的全身操控,而 BiGym 提供了双手基准,但受制于依赖 VR 远程操控,从而限制了数据采集与评估的可扩展性。
作为双臂任务的基准,RoboTwin 支持自动化且大规模的协同操作数据生成,并能进行全面的策略评估。
机器人操作学习方法
在机器人操控学习中,采用人类示范来教授机器人操作技能是普遍的方法。在这些技术中,Behavioral Cloning(行为克隆)以离线从示范学习策略著称:它复制来自精选数据集的观测动作。
相对而言,Offline Reinforcement Learning 通过基于预定义奖励函数对动作进行优化,并利用大规模数据集来增强策略学习。
Action Chunking with Transformers(ACT)技术将基于 Transformer 的视觉-运动策略与条件变分自编码器结合,用于构建动作序列的学习结构。
由于扩散模型(diffusion models)出色的生成能力,它们已被引入机器人模仿学习并逐步成为主流方法。
最近,Diffusion Policy 方法越来越受到关注:它采用条件去噪扩散过程来表示视觉-运动策略,有效减少了 Transformer 型视觉-运动策略中常见的轨迹生成累积误差。
3D Diffusion Policy 使用点云作为环境观测,增强了空间信息的利用,并能在仿真与真实环境中以少量示范处理多种机器人任务。
LLM for机器人代码生成
大型语言模型(LLMs)以其卓越的自然语言理解与代码生成能力,已经革新了人工智能的多个领域。在机器人领域,这些模型在把自然语言命令与可执行机器人动作之间搭桥方面表现出色。
Code as Policies 与 RoboCodeX 等工作证明 LLM 能把高层任务描述有效地转译成可运行的机器人控制程序。
虽然 Rekep 在关键点间的空间推理上有所进展,但在处理功能轴约束方面存在局限,并且在生成代码时未考虑物体功能轴与桌面表面之间的空间关系。
此外,现有的代码生成方法主要聚焦于单臂机器人,忽视了双臂协作与主动避碰策略等关键问题。
2. 将物理世界与数字世界连接起来以生成多样化的机器人行为
2.1 多样数据资产的生成
作者的方法利用 Deemos 的 Rodin 平台,从简单的 2D RGB 图像创建 3D 模型。该方法显著降低了对昂贵传感器的依赖,同时能实现逼真的视觉效果并支持物理仿真。
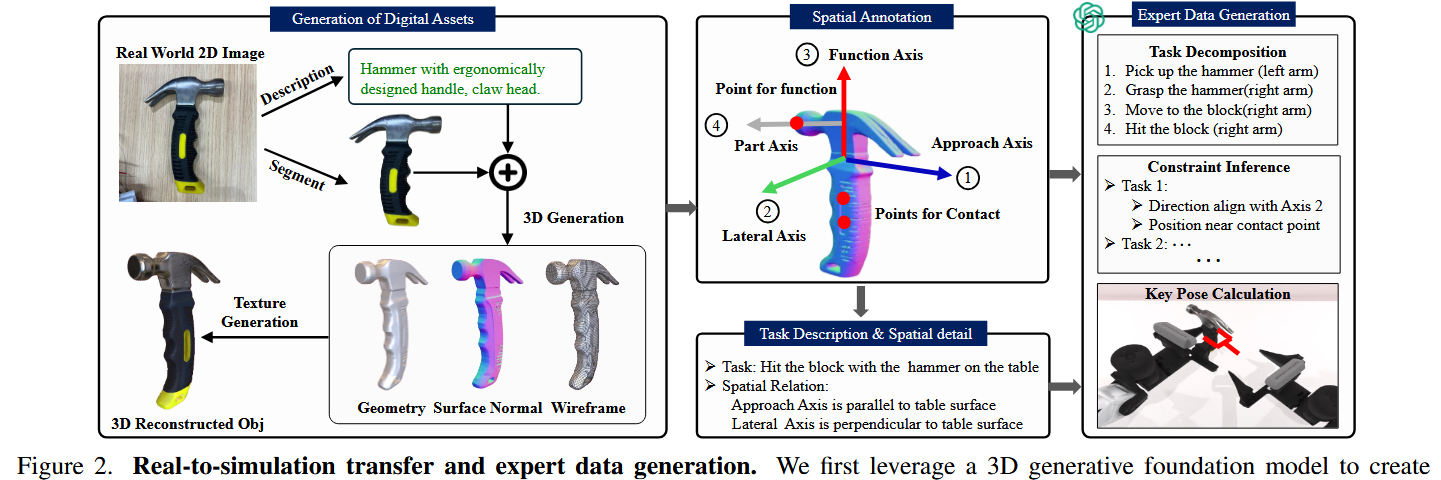
流程从拍摄真实物体的照片开始。如图 2 所示,使用 GPT-4V 解析这些图像以生成对应描述,然后通过语言模型对这些描述进行自动修改,生成相似但在视觉上有差异的对象描述。
用这些描述配合 SDXL-Turbo (高质量文本到图像模型)来生成一组多样化的 2D 图像,表示同一类对象的不同外观。
随后,一个以图像为条件的 3D 生成模型处理这组图像,为单一对象类型生成大量不同的 3D 模型。最终输出将 2D 图像转化成一个完整的 3D 模型,包含精细几何、表面法线、线框与纹理。
用两种互补方法验证资产质量:通过 UCLIP-I 相似性度量做定量评估,以及通过 GPT-4V 做定性视觉验证。低于质量阈值的资产会被自动标记以便重新生成。
这种双重验证方法确保了视觉与几何的一致性,从而有助于有效的仿真到现实(sim-to-real)迁移。为确保物理逼真性,作者利用 GPT-4V 对物体材质进行分类,并为物理参数分配合适的取值,同时加入 ±5% 的随机扰动以增强鲁棒性。
2.2 三维资产的空间标注框架
为了增强生成资产的结构完整性与通用适用性,作者实现了一种系统化的方法来对工具上的关键点和轴进行标注。该方法旨在使数据对 LLMs 在生成复杂任务代码时更易理解与可用。
如图 3 所示,标注过程关注两个主要要素:关键点(key points)与轴(axes)。

关键点:关键点代表工具上与其功能操作或用户交互点直接相关的特定位置。
- 功能点(Point for Function):该关键点标识工具的主要功能部位,例如锤子的敲击面。它定义了工具的功能起点或作用点,与工具在特定任务中的主要用途直接相关。
- 接触点(Point for Contact):该关键点指示工具与其使用者或其他物体交互的区域,代表握持点或接触面,作为重要的人机接口点。对该点的标注有助于理解工具的操作姿态。
轴(Axes):轴用于描述工具在执行任务时的空间方向性,包含功能执行方向以及工具接近目标物体的方向。三条主要轴:
- 功能轴(Function Axis):表示工具执行其主要功能的方向,通常与工具的主要操作向量对齐,用来指导工具在任务中预期的使用与运动。
- 接近轴(Approach Axis):接近轴描述工具接近或施加到目标物体的方向。该轴对于理解工具与操作对象之间的空间关系至关重要。
- 横向轴(Lateral Axis):该轴与功能轴和接近轴均垂直,完成工具的三维坐标系。横向轴有助于定义工具的朝向以及在使用过程中的旋转动作。
通过系统地标注这些关键点与轴,作者为每种工具创建了一个全面的空间框架。该框架使得对工具功能的理解更精确且具有上下文意识,从而促进 LLM 在任务规划与执行方面的改进。
不需要对同一类别的不同 3D 模型反复进行标注。相反,为了简化对同类不同 3D 模型的标注流程,采用了一种利用 Stable Diffusion 编码器的特征点匹配方法。该方法使关键点能够在同一对象类别的不同 3D 模型之间迁移。
作者方法利用特征点匹配来确定目标点。具体来说,在桌面视角下,给定源图像 Is、目标图像 It 以及源点 ps,我们的目标是在目标图像中定位对应点 pt。按照文献 [35, 68] 描述的方法,我们从 Is 与 It 中提取 diffusion 特征。
由于这些 diffusion 特征与目标图像中的各像素一一对应,可以通过分析提取的特征来识别与 ps 最相似的 It 中像素。该技术支持在相似对象的不同 3D 模型间高效地迁移关键点,从而消除了重复标注的需求并提高了 3D 建模流程的整体效率。
2.3 专家数据生成
在已有的空间注释框架与专家数据生成流水线基础上,作者提出了一种系统化方法,用于生成既满足空间约束又能保证无碰撞执行的机器人行为。作者框架的核心是一个功能完善的双臂操控系统,具备三大关键能力。
- 第一,通过螺旋运动插值(screw motion interpolation)与协同夹爪动作,该系统实现了双臂同步移动,保证了物体的稳定操作。
- 第二,它支持在需不对称运动的场景下进行独立臂操作。
- 第三,通过持续调整臂间的安全中间位置,实现动态避碰。
运动生成采用三阶段方法:
① 空间约束推断:分析对象注释以建立几何关系;
② 基于 LLM 的代码生成:将约束翻译为可执行代码(使用 MPlib 轨迹优化库);
③ 执行验证:确保任务完成。
还加入了自我纠正机制:把执行错误反馈给语言模型,并在复杂情况由最少量的人类监督介入。借助这些集成功能,使用带预定义 API 的大型语言模型来系统化地产生各种机器人任务的专家示范。这个过程包括以下详细步骤:
- 场景初始化:配置任务环境并设置相关对象的初始位姿。例如,敲击任务需要把锤子和目标物体放置到起始位置。
- 任务分解:基于人类给出的任务描述,用 LLM 将其拆分为子任务。例如,“锤钉”任务可分解为:a) 抓握锤子,b) 将锤子定位在钉子上方,c) 敲击钉子,d) 将锤子放回原位。
- 约束推断:针对每个子任务,通过分层约束分析流程使用 LLM 系统地推断空间与时间约束。该分析从识别对象关键点与轴之间的功能关系开始。对于抓取子任务,推导末端执行器位姿与对象注释的接触点及接近轴之间的约束,以确保抓取稳定有效。对于操作子任务,在工具的功能点与目标物体之间建立几何约束,这些约束既包括位置对齐也包括方向性要求。
- 机器人行为生成:基于推导出的空间约束,LLM通过调用相关 API(示例见附录 D) 生成每个子任务对应的行为代码**。在执行过程中,系统根据这些空间约束精确计算末端执行器位姿。流程首先在世界坐标系中识别物体上的功能点,作为所有后续位姿计算的参考基准。
在此基础上,实现了两种方法来确定最优目标位姿。
第一种方法利用对象上预标注的接触点来生成抓取位姿,此方法同时考虑对象的几何特性与机器人的运动学限制。
对于更复杂的操作任务:
第二种方法会被采用:通过将对象的功能点与指定目标点对齐并遵守特定方向约束来计算目标位姿。举例来说,在敲击任务中,系统会把锤头与钉子对齐并计算出有效敲击的合适朝向。
minθ(t)J(θ(t))min_{θ(t)} J(θ(t))minθ(t)J(θ(t))
Tee=fFK(θ(t))Tee = f_FK(θ(t))Tee=fFK(θ(t)) (Kinematic constraint)
Pee=Po−d⋅a⃗oPee = Po − d · \vec{a}_oPee=Po−d⋅ao (Position alignment)
n⃗ee=a⃗o\vec{n}_{ee} = \vec{a}_onee=ao (Orientation alignment)
θ(t)∈C,∀t∈[t0,tf]θ(t) ∈ C, ∀ t ∈ [t_0, t_f]θ(t)∈C,∀t∈[t0,tf] (Collision avoidance)
每个子任务的行为生成核心是一个优化问题,目标是寻找最优关节轨迹 θ(t)。系统使用螺旋运动规划器,在满足所有任务特定约束的同时最小化代价函数 J(θ(t))。该优化表述为(如上)。
其中,J(θ(t)) 表示一个代价函数,可能包含能耗、执行时间与运动平滑性等因素。约束确保机器人末端姿态 Tee 与通过正运动学 fFK(θ(t))f_FK(θ(t))fFK(θ(t)) 计算出的目标位姿一致,并与对象的接触点 PoP_oPo 及接近轴 a⃗o\vec{a}_oao 对齐(位置与朝向对齐)。
最后,轨迹 θ(t) 必须在时间区间 [t0, tf] 内始终位于无碰撞配置空间 C 中,以确保避免碰撞。这个全面的优化框架使得能够生成高效、满足空间约束并保证安全无碰撞执行的机器人行为(例如敲击)。
- 成功评估:实现了评估任务成功完成的判定标准。对于敲击任务,可能包括验证钉子是否被敲入到正确深度。
- 迭代精化:系统从多个来源收集错误数据:运行时错误消息、轨迹规划失败步骤以及最终物体状态与目标配置之间的偏差。为生成改进后的代码,系统会综合使用收集到的错误信息、原始任务描述、对象注释和上一版代码作为输入。新生成的代码随后被测试,若问题仍存在,则循环继续直到达到期望性能。
3. 基准
基于第 2 节介绍的方法,作者设计了一个名为 RoboTwin 的综合基准来评估双臂机器人,总共包含 15 个任务。基础物理引擎采用 ManiSkill3。ManiSkill,这是一个基于 SAPIEN [72] 的开源仿真平台,支持 GPU 加速的数据采集。
使用如图 4 所示的开源 Cobot Magic 平台,该平台配备了四只机械臂和四台 Intel RealSense D-435 RGBD 相机,并构建在 Tracer 底盘上。
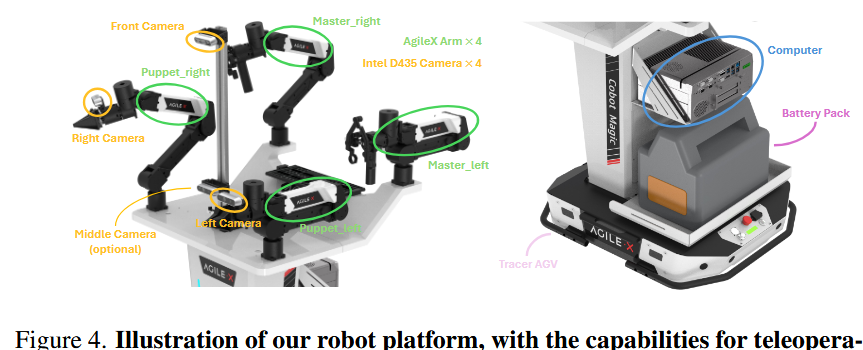
相机的布置具策略性:一台安装在支架高处以获取宽阔视野,两个装在机械臂的腕部,另一个安装在支架低位(可选使用)。前、左、右三台相机以 30Hz 的频率同步采集数据。
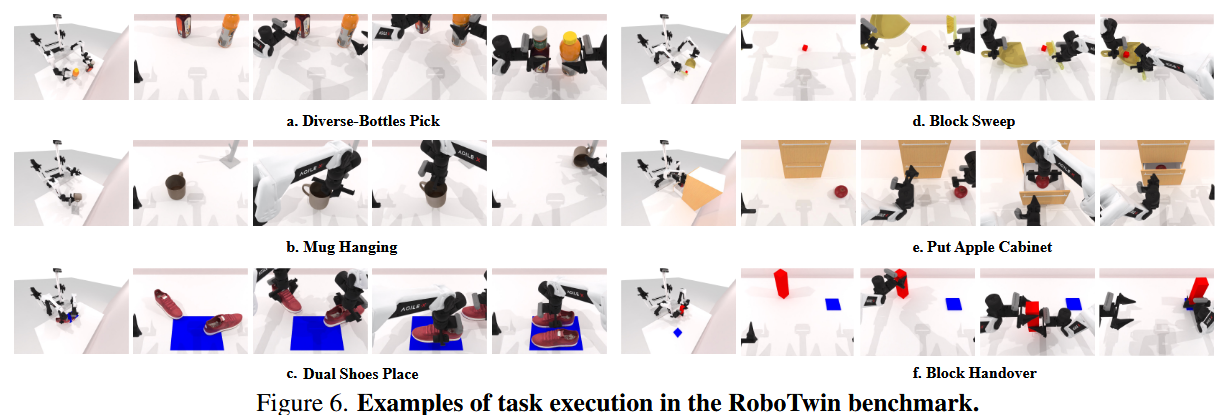
RoboTwin 中每个任务的具体细节可见附录 A。在 RoboTwin 基准中,agent 需根据目标物体与左臂、右臂的距离选择合适的协作方式以成功完成任务。任务包含双臂交接场景(如交接任务、将杯子放到杯垫上)以及避免臂间互相干扰的场景(如放鞋任务,要求两臂在鞋盒的有限空间内协调放置一双鞋)。
所有任务中目标物体的初始位置与姿态均为随机化。在场景加载前,会检查随机初始化场景的机械动力学可达性,以确保其可行。
任务还包含形状与外观各异的对象。“双瓶抓取”任务包含可乐瓶、雪碧瓶、矿泉水瓶等不同模型,所有这些模型均由 2D 真实照片生成。环境中物体的尺寸也会在一定阈值范围内随机化。
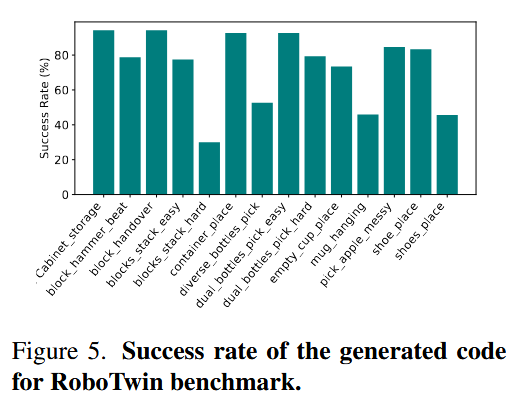
对于每个任务,提供了精心设计的脚本文件,用以在多样化场景中生成专家数据,涵盖不同物体摆放和环境条件。还在第 2.3 节所述的方法下,在图 5 中报告了所生成代码的成功率。
对于基准中的每个任务,预先收集了 100 组仿真数据和 20 组真实世界数据。
真实世界实验的硬件配置严格与仿真环境一致。在仿真与真实数据集中,每帧包含三台相机的图像,每台相机提供一对 RGB 与深度图像。同时提供由深度图生成的点云数据,以及由 RGB 与深度图联合生成的彩色点云,以支持不同类型算法的评估。
此外,数据还包含机械臂在主/从配置下的关节与末端执行器位姿信息,覆盖左右臂。
4. 在RoboTwin基准上的实验
4.1 基线和实验设置
Diffusion Policy 是一种用于机器人模仿学习的生成模型,它对潜在动作的分布建模,从而生成多样且复杂的动作序列。该方法根据输入维度演化出两种主要变体:
- 2D Diffusion Policy 处理二维视觉信息(图像和视频帧)来预测机器人操控动作。虽然对许多应用有效,但在需要深度感知与空间推理的任务上,此方法可能存在局限。
- 3D Diffusion Policy(DP3)通过点云引入三维视觉表征来解决这些限制。通过使用高效的点编码器构建紧凑的 3D 表示,DP3 提高了空间感知能力,并在需要复杂空间理解的任务中表现更好。
在 14 个基准任务上评估了 3D(DP3,带色彩与不带色彩)和 2D(DP)输入的模仿学习方法(见图 6),并针对各模型特点使用 20、50、100 个专家示范作为评估样本量。
成功率的判定依据是:执行完成后满足目标位姿约束,并且在整个任务过程中轨迹保持无碰撞。
4.2 实验结果
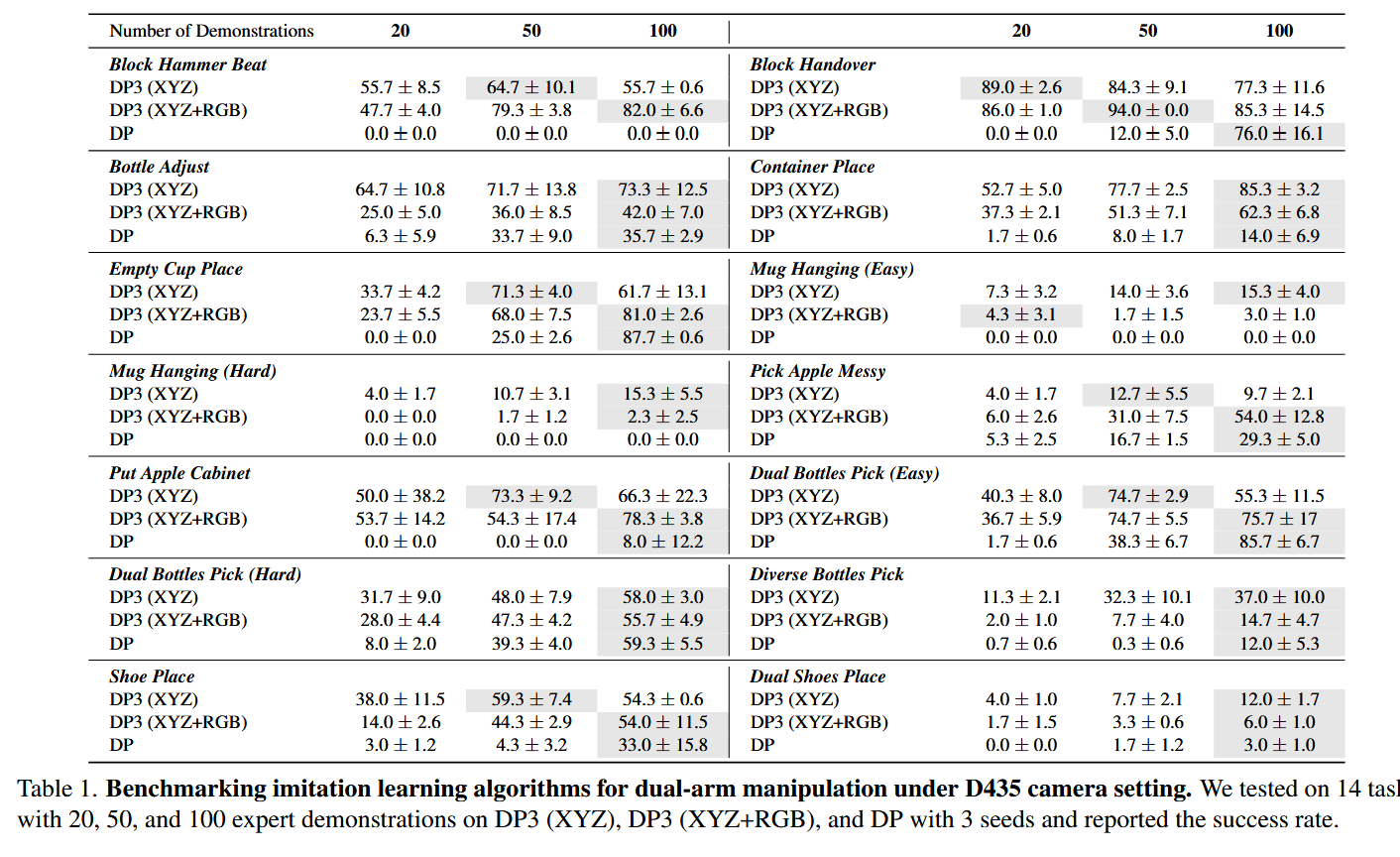
如表 1 所示,实验结果显示不同模仿学习方法在性能上呈现出明显不同的模式。DP3 在少样本学习方面表现出色,仅用 20 个示范就能达到显著性能。然而,随着训练数据扩展到 100 个样本,其性能扩展性有限,改进甚少甚至出现下降。
相反,DP(二维扩散)在样本有限时初始表现较差,可能是因为缺乏几何先验,但随着训练样本增加其可扩展性显著。
在 100 个示范下,DP 在若干任务上超过了 DP3;例如在 Dual Bottles Pick(Easy)任务中,性能从 1.7% 飙升到 85.7%。这表明在更大数据集上,DP 的学习能力优越。
将 RGB 数据与点云表征融合所带来的收益并不稳定,这凸显了当前双手操控方法在多模态融合方面的根本性限制。
虽然 DP3(XYZ+RGB) 在拥挤/混乱场景(例如 Pick Apple Messy)中显著提升,但在某些任务(如 Container Place)上却出现性能下降。这表明需要开发更好的融合表示来结合 RGB 语义信息与点云三维信息(详见附录表 4)。
实验结果表明,性能显著依赖于协调复杂度。
简单操作(如 Dual Bottles Pick)取得了高成功率(DP 在 100 个示范下达到 85.7%),而要求复杂双臂协作的任务(如 Dual Shoes Place)表现很差(所有方法成功率均低于 15%)。
值得注意的是,要求复杂双臂协作的任务明显逊于那些两臂可相对独立操作(且臂的选择主要基于与目标物的近邻关系)的任务。这凸显了当前模仿学习算法在双臂协调方面的局限性。
4.3 真实世界实验
为验证 RoboTwin 生成的训练数据在真实世界策略部署中的有效性,在单臂与双臂操作任务上进行了全面实验(见图 8)。

做了对比实验:一组策略仅用 20 组真实数据训练;另一组先在 300 组仿真数据上预训练,再用 20 组真实数据微调(具体细节与结果见附录 B)。之所以选择 300 组仿真数据作为超参数,是基于图 7 中的经验性证据。
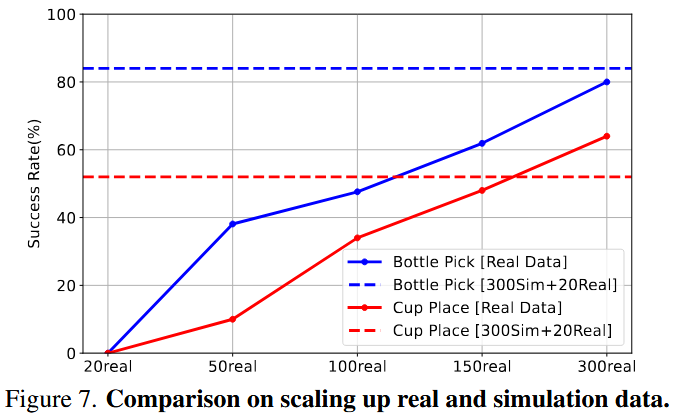
通过逐步扩展真实数据量,可以发现:将 300 组仿真数据与 20 组真实数据结合后,在单臂瓶子抓取和双臂杯子放置任务上,其性能可与仅使用 300 组真实数据的结果相当。
为了研究基线算法在单臂与双臂任务间性能差异,对两类任务都进行了 sim-to-real 转移实验。每个任务都进行了 50 次测试试验,初始配置随机化(包括物体位置/朝向和机器人臂位于预定边界内的摆放)。
如表 2 与表 3 所示,实验结果显示:在组合数据集上训练的策略在真实测试场景中取得了明显更好的性能。
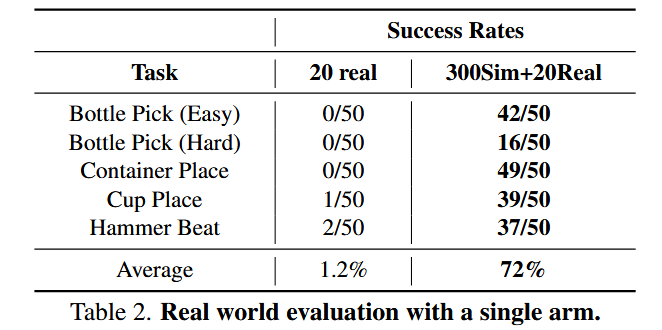
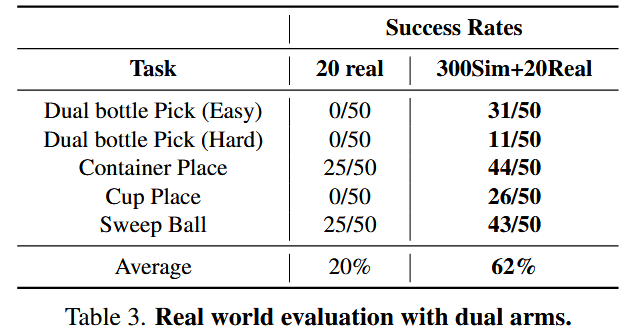
具体而言:与仅用真实数据训练的策略相比,融合仿真数据使单臂任务的成功率提高了 72%。对于更复杂的双臂任务,观察到成功率提升超过 40%。
这些发现验证了他们的基准与数据生成方法在缩小 sim-to-real 差距方面的有效性,并表明这是一条有望开发更稳健、泛化性更强的双臂操控策略的方向。
观察到单臂与双臂场景之间存在显著差异。在瓶子重新摆放任务中,双臂操作面临更大挑战,主要原因是目标瓶子的初始状态多样(直立或横躺)。虽然加入仿真数据使策略取得了非零成功率,但总体性能仍不理想。这凸显了迫切需要为双臂协调任务专门开发更有效的模仿学习算法。
5. 结论
本文提出了 RoboTwin——一个将真实与合成数据整合用于双臂机器人操控的综合基准。
基于 COBOT Magic Robot 平台并利用 3D 生成模型构建 generative digital twins,这种框架能从单张 RGB 图像高效生成多样化训练数据。
此外,空间感知代码生成框架通过将对象注释与 LLM 结合,自动生成专家示范,用以分解复杂任务并生成精确动作。
实验表明:使用 RoboTwin 生成的仿真数据训练的策略,在更少真实数据的情况下,成功率高于仅用真实数据训练的策略。
这些结果证实了作者方法能有效缩小 sim-to-real 差距,同时也指出了双臂协调任务的局限性。未来工作将致力于开发用于双臂协调的高级算法,并扩展该框架以处理更复杂的操控任务。