RLHF的定义
RLHF的定义首先由《Deep Reinforcement Learning from Human Preferences》提出,解决了强化学习中奖励函数怎么设计的问题。
传统RL的问题:依赖于人类设计的奖励函数,这在实际应用中往往非常困难且不够灵活,因为面临涉及复杂、定义不明确或难以指定的目标的任务时,很难定义奖励函数。而不正确或者有偏的奖励函数会导致reward hacking问题,导致训练出的模型不符合预期。而让人类实时的对模型当前行为进行反馈的成本又过高。
RLHF提出从人类给出的反馈中学习奖励函数,该奖励函数满足以下需求:
能够解决人类只能识别所需行为,但不一定能提供演示的任务
允许非专家用户进行示教
能扩展到大规模问题
用户给出反馈的成本不高
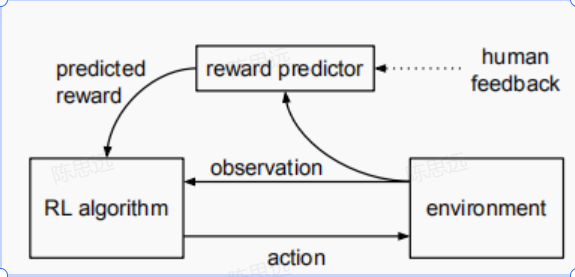
如下图所示,利用人类偏好来拟合奖励函数,同时利用RL算法优化当前预测的奖励函数。人类比较两个agent的行为轨迹片段哪个更好,而不是提供绝对数值分数。在某些领域中,人类更擅长比较agent的性能而不是给出绝对的评分,这种比较也能学习到人类偏好。比较agent轨迹片段与比较单个状态几乎一样快,比较轨迹片段明显更有帮助。在线地收集反馈可以提高系统的性能,并防止agent利用学到的奖励函数的弱点刷分。