FCN网络结构讲解与Pytorch逐行讲解实现
FCN-8s 网络结构与数据流动详解
整个网络可以看作两个部分:编码器(Encoder)负责下采样和特征提取,解码器(Decoder)负责上采样和特征融合。
第一部分:编码器(下采样路径)- 提取层次化特征
数据首先从这里开始流动。编码器就是标准VGG16的前13个卷积层加上5个池化层。
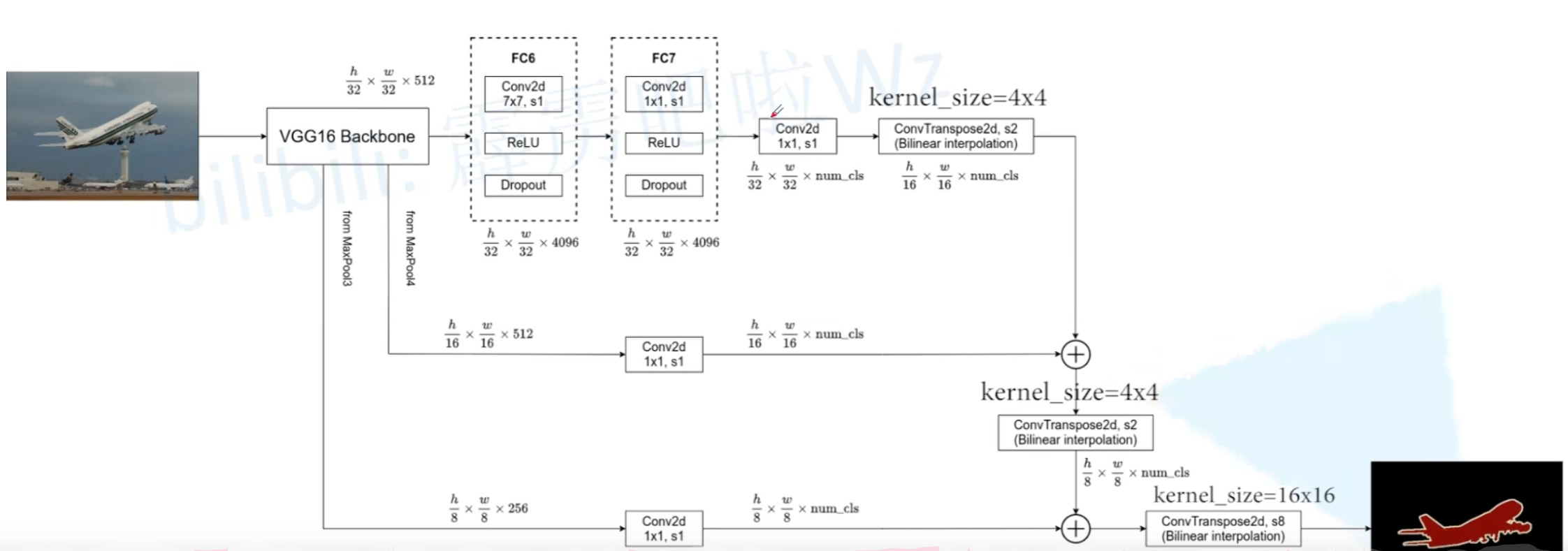
1.输入:一张任意尺寸的图像,例如 (H, W, 3)。
2.数据流动:图像依次通过VGG的卷积块(Convolutional Blocks)和池化层(Pooling Layers)。
[输入图像] (H x W x 3)|V
[VGG16 Encoder (卷积块 + 池化)]||-- (下采样2x) -> [pool1] (H/2 x W/2 x ...)| || |------- (后续层忽略...)||-- (下采样4x) -> [pool2] (H/4 x W/4 x ...)||-- (下采样8x) -> [pool3] (H/8 x W/8 x 256) -->(1)----------------> [conv 1x1 (x N)] -> [score_pool3] (H/8 x W/8 x N)||-- (下采样16x) -> [pool4] (H/16 x W/16 x 512) -->(2)-------------> [conv 1x1 (x N)] -> [score_pool4] (H/16 x W/16 x N)||-- (下采样32x) -> [pool5] (H/32 x W/32 x 512)|V[conv 1x1 (x N)] -> [score_pool5] (H/32 x W/32 x N) # |V[deconv (Transposed Conv) stride=2, kernel=4] -> 上采样2倍|V[upscore_pool5] (H/16 x W/16 x N) # 尺寸恢复到1/16| ( + ) <-------------------- (2) [score_pool4] (H/16 x W/16 x N)|V[fused_score4] (H/16 x W/16 x N) # 融合高层语义 (pool5) 和中级特征 (pool4)|V[deconv stride=2, kernel=4] -> 上采样2倍|V[upscore_fused4] (H/8 x W/8 x N) # 尺寸恢复到1/8| ( + ) <-------------------- (1) [score_pool3] (H/8 x W/8 x N)|V[fused_score3] (H/8 x W/8 x N) # 再融合浅层细节特征 (pool3)|V[deconv stride=8, kernel=16] OR [deconv stride=2 (x3)] # 上采样8倍|V
[最终Score Map] (H x W x N) # N通道得分图,每个像素位置(N维向量)|V
[Pixel-wise argmax] OR [Sigmoid/Softmax + Threshold]|V
[输出分割掩码] (H x W) # 每个像素值为预测类别ID Conv Block 1 & 2 -> pool2后,特征图尺寸变为 (H/4, W/4),步长(stride)为4
Conv Block 3 -> pool3后,特征图尺寸变为 (H/8, W/8),步长为8。【记忆点1:这是第一个要被融合的特征,记为 feat_pool3】
Conv Block 4 -> pool4后,特征图尺寸变为 (H/16, W/16),步长为16。【记忆点2:这是第二个要被融合的特征,记为 feat_pool4】
Conv Block 5 -> pool5后,特征图尺寸变为 (H/32, W/32),步长为32。【记忆点3:这是语义信息最强的特征,记为 feat_pool5】
至此,编码器部分完成。我们得到了三份宝贵的原材料:feat_pool3, feat_pool4, feat_pool5,它们将被用于后续的细节恢复。
第二部分:全卷积化改造与解码器(上采样路径)
步骤 1:生成最粗糙的语义预测图 (FCN-32s的基础)
1.改造全连接层:VGG16原本的 pool5 之后是三个全连接层(fc6, fc7, fc8)。FCN将它们全部替换为卷积层。特别是最后一个 fc8(用于1000分类),被替换为一个 1x1 的卷积层,其输出通道数等于我们要分割的类别总数(比如PASCAL VOC数据集就是21类)。
2.数据流动:feat_pool5 -> 卷积化改造层 -> 输出一个尺寸为 (H/32, W/32, num_classes) 的特征图。我们称之为 score_pool5。这张图就是最原始、最粗糙的语义热力图。
步骤 2:第一次融合,得到16s预测图 (FCN-16s)
上采样:将 score_pool5 (步长32) 输入一个步长为2的转置卷积层 (Transposed Convolution),将其尺寸放大2倍,得到一个步长为16的特征图,记为 upsampled_score5。
准备融合材料:取出编码器阶段保存的 feat_pool4 (步长16)。对其应用一个 1x1 卷积层,目的只有一个:将其通道数也变成 num_classes,从而可以和 upsampled_score5 进行数学运算。我们将这个结果称为 score_pool4。
融合:将 upsampled_score5 和 score_pool4 进行逐元素相加 (Element-wise Addition)。得到的 (H/16, W/16, num_classes) 特征图就是FCN-16s的预测结果,我们称之为 fuse_16s。
步骤 3:第二次融合,得到8s预测图 (FCN-8s)
上采样:将上一步得到的 fuse_16s (步长16) 再次输入一个步长为2的转置卷积层,将其尺寸放大2倍,得到一个步长为8的特征图,记为 upsampled_score16。
准备融合材料:取出编码器阶段保存的 feat_pool3 (步长8)。同样,对其应用一个 1x1 卷积层,将通道数变为 num_classes,得到 score_pool3。
融合:将 upsampled_score16 和 score_pool3 进行逐元素相加。得到的 (H/8, W/8, num_classes) 特征图就是FCN-8s的核心预测结果,我们称之为 fuse_8s。
步骤 4:最后一步,恢复原始尺寸
将 fuse_8s (步长8) 输入一个步长为8的转置卷积层,将其尺寸放大8倍,直接恢复到和原始输入图像完全相同的尺寸 (H, W, num_classes)。
这就是FCN-8s最终输出的、每个像素点都包含类别分数的预测图。在推理时,对每个像素位置的 num_classes 个分数取 argmax,即可得到该像素的最终类别,从而生成最终的彩色分割图。
+------------------+| Image |+------------------+|[VGG16 Encoder (Downsampling)]|
+-----------------------------------------------+-----------------------------------------------+
| | |
[feat_pool3 (s=8)] [feat_pool4 (s=16)] [feat_pool5 (s=32)]
| | |
| (1x1 Conv) | (1x1 Conv) | (Conv Layers)
| -> [score_pool3] | -> [score_pool4] | -> [score_pool5]
| | |
| | +----------------------------------------+
| | | (Element-wise Add)
| +------+-----> [fuse_16s (s=16)] <------+
| | |
+------------------------------------------------------+ (Upsample x2) | (Upsample x2)
| (Element-wise Add) | |
+-----> [fuse_8s (s=8)] <-------------------------------+--------------------------------+|(Upsample x8)|
+---------------------------+
| Final Segmentation Map |
| (Original Size) |
+---------------------------+Pytorch实例实现讲解
这是一个简化的、用于教学的实现,重点在于展示网络结构。
核心架构定义
import torch
import torch.nn as nnclass FCN8s(nn.Module):def __init__(self, num_classes=1):super(FCN8s, self).__init__()# 编码器 (基于VGG16) - 定义为独立的模块self.block1 = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(2, stride=2))self.block2 = nn.Sequential(nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(128, 128, 3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(2, stride=2))self.block3 = nn.Sequential(nn.Conv2d(128, 256, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(2, stride=2))self.block4 = nn.Sequential(nn.Conv2d(256, 512, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, 3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(2, stride=2))self.block5 = nn.Sequential(nn.Conv2d(512, 512, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, 3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(2, stride=2))# FCN分类器self.classifier = nn.Sequential(nn.Conv2d(512, 4096, 7, padding=3), nn.ReLU(inplace=True),nn.Dropout2d(0.5),nn.Conv2d(4096, 4096, 1), nn.ReLU(inplace=True),nn.Dropout2d(0.5),nn.Conv2d(4096, num_classes, 1))这部分代码定义了 FCN-8s 模型的核心骨架,特别是它的编码器(Encoder)部分。
它有什么用? (What it does?)
简单来说,这段代码的核心作用是“看懂”并“压缩”输入的图像。它构建了一个深度卷积神经网络,用来从原始的像素图像中提取有意义的、层次化的特征。
具体来看,它完成了两件事:
1.特征提取 (Feature Extraction): 代码中的 self.block1 到 self.block5 模仿了经典的 VGG16 网络的结构。输入图像经过这些卷积层和激活函数(ReLU)后,会一步步被转换成“特征图”(Feature Map)。越往后的 block,提取出的特征越高级、越抽象。
block1 可能识别边缘、颜色块。
block3 可能识别纹理、物体的部件。
block5 可能识别出更复杂的概念,比如“这是一只猫的轮廓”。
2.空间降维 (Downsampling): 每个 block 结尾的 nn.MaxPool2d 层执行了下采样操作。它会将特征图的尺寸缩小一半(比如从 256x256 变成 128x128)。这不仅减少了计算量,还增大了后续卷积层的“感受野”,让网络能看到更广阔的图像区域。
3.初步分类 (Initial Classification): self.classifier 部分是 FCN 的精髓之一。它用卷积层替换了传统 VGG16 最后的全连接层,对 block5 输出的最抽象的特征图进行像素级别的分类预测,生成一个粗糙的、低分辨率的分割热力图(Score Map)。
它为什么有用? (Why it's useful?)
这套设计的巧妙之处在于它为图像分割任务打下了坚实的基础。
1.利用迁移学习 (Leveraging Transfer Learning): FCN 的作者巧妙地沿用了 VGG16 的结构。这意味着我们可以直接加载在大型图像分类数据集(如 ImageNet)上预训练好的 VGG16 权重。这就像让一个已经认识世界上成千上万种物体的“专家”来帮我们做特征提取,极大地提升了模型的学习效率和分割精度,尤其是在我们的训练数据不够多的时候。
2.层次化特征是理解图像的关键: 图像中的信息是分层的。从边缘到纹理,再到物体部件,最后到整个物体。这种逐层深入的特征提取方式完全模拟了我们人类视觉系统的认知过程,让模型能够真正“理解”图像内容,而不是死记硬背像素。
3.全卷积化是实现像素级预测的前提: 传统分类网络最后的全连接层会丢掉所有的空间信息,只能输出一个类别标签(比如“猫”)。而 self.classifier 使用 1x1 和 7x7 的卷积层,保留了空间维度,使得输出结果是一个与输入特征图大小一致的热力图。图上每个“像素”的值都代表了原始图像对应区域属于某个类别的可能性。这是从“图像分类”迈向“像素级分割”的革命性一步。
它该如何使用? (How to use it?)
self.block1 = ...: 我们在 FCN8s 类的实例上创建了一个名为 block1 的属性。这个属性本身就是一个神经网络模块。
nn.Sequential(...): 这是一个容器模块。你可以把它看作一个“流水线”,它接收一系列其他的网络层作为参数。当数据流经 nn.Sequential 时,会严格按照你定义的顺序,依次通过里面的每一个层。这让代码非常整洁。
nn.Conv2d(in_channels, out_channels, kernel_size, ...): 定义一个二维卷积层
第一个参数 3: 输入通道数(in_channels)。对于RGB图像,就是3。对于 block1 中的第二个卷积层,输入是前一个卷积层输出的 64。
第二个参数 64: 输出通道数(out_channels)。这代表卷积层使用了64个不同的卷积核(filter)。
第三个参数 3: 卷积核的大小(kernel_size),这里是 3x3。
padding=1: 在输入特征图的四周填充1个像素的边界。对于 3x3 的卷积核,padding=1 可以确保输出的特征图和输入的尺寸保持不变。
nn.Conv2d(..., 1): 这是一个 1x1 卷积。当卷积核大小为1时,它不会改变特征图的宽高,但可以有效地改变通道数。在这里,nn.Conv2d(4096, num_classes, 1) 的作用是将 4096 个特征通道“压缩”成 num_classes 个通道,每个通道对应一个类别的预测分数。
解码器(Decoder)和跳跃连接(Skip Connection)部分
# 跳级连接self.score_pool4 = nn.Conv2d(512, num_classes, 1)self.score_pool3 = nn.Conv2d(256, num_classes, 1)# 上采样层 self.upscore2_1 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)self.upscore2_2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)self.upscore8 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=8, padding=4)# 确保所有模块都初始化self._init_weights()它有什么用? (What it does?)
这段代码的核心作用是“融合特征”与“恢复尺寸”。它负责将编码器输出的、高度浓缩的语义信息(“图片里有什么”)与编码器早期阶段的、包含丰富空间细节的特征(“物体边缘在哪里”)结合起来,并逐步将图像放大回原始尺寸。
具体来看,它定义了两类“零件”:
1.跳跃连接适配器 (self.score_pool4, self.score_pool3):
它们是两个独立的 1x1 卷积层。
作用是处理来自编码器中间层(block4 和 block3)的特征图,将它们的通道数统一调整为 num_classes。你可以把它们想象成“转换插头”,让不同阶段的特征图能够在语义层面进行对齐和相加。
2.上采样器 (self.upscore...):
它们是三个转置卷积(Transposed Convolution)层
作用与最大池化(MaxPool)正好相反,它们的功能是放大特征图的尺寸。upscore2_1 和 upscore2_2 负责放大2倍,upscore8 负责放大8倍。
_init_weights() 是一个自定义的函数调用,用于对这些新定义的层进行权重初始化,这是一个保证模型稳定训练的好习惯。
它为什么有用? (Why it's useful?)
这套设计的 brilliance 在于它解决了深度学习在图像分割中的一个核心矛盾:语义信息和空间信息的冲突。
1.深度的网络(如 block5)能提供丰富的语义信息(知道这里是“人”),但由于反复下采样,其空间信息严重丢失(不知道“人”的精确轮廓)。
2.浅层的网络(如 block3, block4)保留了更精确的空间信息(清晰的物体边缘),但语义信息不足(只知道是边缘,但不知道是“人”的边缘还是“背景”的边缘)。
FCN-8s 的解决方案就是“跳跃连接”:
1.弥补细节: 直接将深层、粗糙的预测结果(来自 classifier)进行上采样,会得到模糊的边界。通过 self.score_pool4 和 self.score_pool3 将浅层特征图“翻译”成同维度的分数图,然后与上采样后的深层分数图逐像素相加,相当于用浅层的细节信息去修正深层的预测结果。
2.逐级精细化: FCN-8s 不是一步到位地融合,而是分两步进行:
首先,将 block5 的预测结果上采样2倍,与 block4 的特征融合。
然后,将融合后的结果再上采样2倍,与 block3 的特征融合。
最后,将第二次融合的结果上采样8倍,得到最终的分割图。 这种 2x + 2x + 8x 的上采样结构,就是 "FCN-8s" 名称的由来。它比 FCN-32s(直接上采样32倍)和 FCN-16s(只融合一次)的效果要好得多,因为它融合了更多不同尺度的信息。
3.可学习的上采样: 使用 ConvTranspose2d 而不是简单的插值算法(如双线性插值)来进行上采样是有优势的。因为转置卷积的“放大”方式(即卷积核的权重)是可以通过训练学习的。这使得模型可以自己学会最优的细节恢复策略,而不是使用一种固定的、人工设计的算法。
它该如何使用?
1.self.score_pool4 = nn.Conv2d(512, num_classes, 1)
nn.Conv2d: 定义一个标准的二维卷积层。512: 输入通道数。这个数字对应了 VGG16 中block4输出特征图的通道数。num_classes: 输出通道数。将特征维度调整为类别数,使其成为一个“分数图”。1: 卷积核大小为1x1。它的作用是在不改变特征图宽高的情况下,对每个像素点的512个通道值进行一次线性组合,最终融合成num_classes个新的通道值。
2.self.upscore2_1 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1)
nn.ConvTranspose2d: 定义一个二维转置卷积层,用于上采样。num_classes, num_classes: 输入和输出通道数都是类别数,因为它处理的是分数图。kernel_size=4,stride=2,padding=1: 这是一组“黄金参数组合”。对于一个给定的输入尺寸H x W,使用这组参数的转置卷积,输出尺寸恰好是2H x 2W,即精确地放大2倍。这是一个常用的、需要记住的技巧。self.upscore8中的kernel_size=16, stride=8, padding=4也是同理,这组参数可以精确地将输入尺寸放大8倍。
3.self._init_weights()
这是一个在类内部定义的普通方法调用(方法名前的下划线
_是一种约定,表示它是一个内部使用的方法)。它的作用通常是遍历模型中的各个层(
self.modules()),并根据层的类型(是卷积层还是全连接层等)应用特定的权重初始化方案,例如高斯分布初始化、Xavier 初始化等。
def _init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)它执行了两个具体操作:
初始化权重 (Initialize Weights): 对所有卷积层和转置卷积层的权重(
m.weight),使用一种名为 “Kaiming Normal” 的特定随机化方法进行初始化。初始化偏置 (Initialize Biases): 如果这些层有偏置(
m.bias),则将它们全部设置为 0。
# 定义一个名为 _init_weights 的方法。
# 前导下划线 '_' 是 Python 的一种惯例,表示这是一个“内部”方法,主要供类自身使用。
def _init_weights(self):# self.modules() 会递归地遍历模型中定义的所有模块(或层)。# 'm' 在每次循环中会代表一个具体的层,例如 nn.Conv2d, nn.ReLU, nn.Sequential 等。for m in self.modules():# isinstance(m, class) 是 Python 内置函数,用于检查变量 'm' 是否是某个类的实例。# 这行代码的逻辑是:“如果当前这个模块 m 是一个卷积层或者是一个转置卷积层,那么就执行下面的初始化代码。”if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):# nn.init 是 PyTorch 的初始化工具箱。# kaiming_normal_ 是其中的 Kaiming 正态分布初始化函数。# 函数名末尾的下划线 '_' 表示这是一个“in-place”操作,即直接修改输入的张量,不返回新的张量。nn.init.kaiming_normal_(m.weight, # 第一个参数:要初始化的权重张量。mode='fan_out', # 'fan_out' 模式在计算方差时考虑输出通道数,有助于保持反向传播时梯度的大小。nonlinearity='relu' # 明确告知函数,这个权重所在的层后面跟着一个 ReLU 激活函数,函数会据此调整方差。)# 检查这个层是否有偏置项 (有些层可以设置为 bias=False)。if m.bias is not None:# 如果偏置项存在,则使用 constant_ 函数将其所有元素设置为 0。nn.init.constant_(m.bias, 0)forward 方法
def forward(self, x):# 1. 提取各层特征x1 = self.block1(x) # /2x2 = self.block2(x1) # /4x3 = self.block3(x2) # /8 (256通道) - pool3x4 = self.block4(x3) # /16 (512通道) - pool4x5 = self.block5(x4) # /32 (512通道) - pool5# 2. 处理最深层特征score5 = self.classifier(x5) # (N, num_classes, H/32, W/32)# 3. 第一次上采样和融合score5_up = self.upscore2_1(score5) # /16 (2倍上采样)score4 = self.score_pool4(x4) # 调整pool4特征通道数score4_fused = score5_up + score4 # 融合# 4. 第二次上采样和融合score4_up = self.upscore2_2(score4_fused) # /8 (2倍上采样)score3 = self.score_pool3(x3) # 调整pool3特征通道数score3_fused = score4_up + score3 # 融合# 5. 最终上采样到原始尺寸output = self.upscore8(score3_fused) # 原始尺寸 (8倍上采样)return output它有什么用? (What it does?)
这个 forward 方法的作用是定义模型的前向传播路径。它精确地描述了当一个输入图像张量 x 进入模型后,应该按照怎样的顺序、经过哪些层、进行何种计算,最终生成像素级的分割预测图 output。
整个流程可以清晰地分为五个步骤,正如代码注释所示:
1.编码/下采样: 图像 x 依次穿过 block1 到 block5,特征图尺寸被不断缩小(/2, /4, /8, /16, /32),同时特征的抽象和语义层次越来越高。
2.初始预测: 在最小的特征图 x5 上进行像素级分类,得到一个非常粗糙的分割结果 score5。
3.第一次融合: 将粗糙结果 score5 放大2倍,与来自 block4 的、更精细的特征进行融合,得到修正后的结果 score4_fused。
4.第二次融合: 将第一次修正后的结果 score4_fused 再放大2倍,与来自 block3 的、最精细的特征进行融合,得到进一步修正的结果 score3_fused。
5.最终输出: 将第二次修正后的结果 score3_fused 一次性放大8倍,恢复到原始图像尺寸,得到最终的分割图 output。
它为什么有用? (Why it's useful?)
融合是关键: 如果没有步骤3和4的融合操作,直接将 score5 上采样32倍(这就是 FCN-32s 的做法),得到的分割图边界会非常模糊。因为在反复下采样的过程中,精确的位置信息早已丢失。
score5_up + score4 这一步,是用 score4 中包含的、来自 block4 的空间细节去修正 score5_up 的语义预测。
score4_up + score3 这一步,是在上一步的基础上,用 score3 中更丰富的细节再次进行修正。
这种由粗到精、层层递进的修正方式,使得最终的分割结果能够同时拥有深层网络的语义理解能力和浅层网络的细节描绘能力。
它该如何使用?
# 'def forward(self, x):'
# 定义了模型的前向传播函数。'self' 指向模型实例,'x' 是输入的张量(例如一个批次的图片)。
# 'x' 的形状通常是 [N, C, H, W],即 [批次大小, 通道数, 高, 宽]。
def forward(self, x):# 1. 提取各层特征# 这是一个标准的函数式调用。self.block1 是一个 nn.Module 对象,# 通过 'self.block1(x)' 的方式将张量 x 输入该模块,并接收其输出。# 输出 x1 作为下一个模块的输入,形成一个链式调用。x1 = self.block1(x)x2 = self.block2(x1)x3 = self.block3(x2)x4 = self.block4(x3)x5 = self.block5(x4)# 2. 处理最深层特征# 将编码器最深层的输出 x5 输入分类器模块。score5 = self.classifier(x5)# 3. 第一次上采样和融合score5_up = self.upscore2_1(score5) # 将 score5 输入上采样层score4 = self.score_pool4(x4) # 将 x4 输入跳跃连接的适配层# 这里的 '+' 是 PyTorch 中张量的逐元素加法操作。# 这个操作要求两个张量 score5_up 和 score4 的形状必须完全相同。# 这也正是我们在 __init__ 中精心设计 self.upscore2_1 和 self.score_pool4 的原因。score4_fused = score5_up + score4# 4. 第二次上采样和融合score4_up = self.upscore2_2(score4_fused)score3 = self.score_pool3(x3)# 同样是逐元素相加,融合信息。score3_fused = score4_up + score3# 5. 最终上采样到原始尺寸output = self.upscore8(score3_fused)# 'return' 关键字返回最终的计算结果。# output 的形状是 [N, num_classes, H, W],其中 H 和 W 与输入图像 x 的 H 和 W 相同。# 这个输出张量是模型的原始预测(logits),通常还需要经过一个 Softmax 或 Argmax 操作来得到最终的分割图。return output训练与测试
# 测试代码
if __name__ == "__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"使用设备: {device}")# 初始化模型 (二分类)model = FCN8s(num_classes=1).to(device)print(f"模型参数量: {sum(p.numel() for p in model.parameters())/1e6:.2f}M")# 模拟256x256图像输入dummy_input = torch.randn(2, 3, 256, 256).to(device)print(f"输入尺寸: {dummy_input.shape}")# 测试前向传播model.eval()with torch.no_grad():output = model(dummy_input)print(f"输出尺寸: {output.shape} (应与输入同空间尺寸)")# 模拟训练dummy_target = torch.randint(0, 2, (2, 256, 256)).float().to(device)model.train()criterion = nn.BCEWithLogitsLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)optimizer.zero_grad()output = model(dummy_input)loss = criterion(output.squeeze(1), dummy_target)loss.backward()optimizer.step()print(f"训练损失: {loss.item():.4f}")它有什么用? (What it does?)
它的核心作用是验证我们前面定义的 FCN8s 类能否正常工作,并演示一个完整的训练流程。
它执行了以下一系列操作:
1.环境准备: 自动检测电脑上是否有可用的 CUDA GPU,并选择相应的设备(GPU 或 CPU)。
2.模型实例化: 创建一个 FCN8s 模型的实例,用于一个二分类(num_classes=1)任务,并计算和打印模型的总参数量。
3.推理测试 (Inference Test):
创建一个假的、随机的输入图像 (dummy_input)。
将模型切换到“评估模式” (model.eval())。
在不计算梯度的模式下(torch.no_grad()),执行一次前向传播,检查模型的输出尺寸是否符合预期(空间尺寸应与输入一致)。
4.训练测试 (Training Test):
创建一个假的、随机的目标标签 (dummy_target)。
将模型切换回“训练模式” (model.train())。
定义损失函数 (BCEWithLogitsLoss) 和优化器 (Adam)。
模拟一个完整的训练迭代: 前向传播 -> 计算损失 -> 反向传播(计算梯度)-> 更新权重。
打印出计算得到的损失值。
它如何使用
# 这是一个 Python 的标准写法。只有当这个 .py 文件被直接运行时,
# 'if' 后面的代码块才会被执行。如果这个文件作为模块被其他文件导入,
# 这部分代码则不会运行。这是将可执行的测试代码与可导入的类定义分开的最佳实践。
if __name__ == "__main__":# torch.device() 创建一个设备对象。# torch.cuda.is_available() 检查 GPU 是否可用。这是一个三元表达式。device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 实例化模型,并通过 .to(device) 将模型的所有参数和缓冲区移动到指定的设备(GPU或CPU)。model = FCN8s(num_classes=1).to(device)# model.parameters() 返回一个包含模型所有可学习参数(权重、偏置)的迭代器。# p.numel() 返回一个张量 p 中元素的总数。# sum(...) / 1e6 将总参数量转换为以“百万”(M)为单位。print(f"模型参数量: {sum(p.numel() for p in model.parameters())/1e6:.2f}M")# torch.randn(2, 3, 256, 256) 创建一个形状为 [2, 3, 256, 256] 的张量,# 其中的元素服从标准正态分布。这模拟了一个批次为2的RGB图像。dummy_input = torch.randn(2, 3, 256, 256).to(device)# 将模型设置为评估模式。这会关闭 Dropout 和 BatchNorm 等在训练和测试时行为不同的层。model.eval()# 'with torch.no_grad():' 是一个上下文管理器,# 在这个代码块内,所有 PyTorch 的计算都不会追踪梯度,可以节省显存并加速计算。# 这在模型推理时是必须的。with torch.no_grad():output = model(dummy_input)# torch.randint(low, high, size) 创建一个在 [low, high) 区间内的随机整数张量。# 这里模拟了二分类的标签图,像素值为 0 或 1。dummy_target = torch.randint(0, 2, (2, 256, 256)).float().to(device)# 将模型设置回训练模式。model.train()# nn.BCEWithLogitsLoss() 是一个专门用于二分类任务的损失函数。# 它内部集成了 Sigmoid 激活函数和二元交叉熵损失,比手动分开使用更数值稳定。criterion = nn.BCEWithLogitsLoss()# torch.optim.Adam 是一个常用的优化器算法。# 它接收模型的参数和学习率 (lr) 作为输入。optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)# --- 标准的 PyTorch 训练五步曲 ---# 1. 清空旧梯度。如果不清零,梯度会累加。optimizer.zero_grad()# 2. 前向传播,得到模型输出。output = model(dummy_input)# 3. 计算损失。# output.squeeze(1) 将形状从 [2, 1, 256, 256] 压缩到 [2, 256, 256],# 以匹配 dummy_target 的形状和 BCEWithLogitsLoss 的输入要求。loss = criterion(output.squeeze(1), dummy_target)# 4. 反向传播,根据损失计算所有参数的梯度。loss.backward()# 5. 优化器根据计算出的梯度,更新模型的所有参数。optimizer.step()# loss 是一个包含单个值的张量。 .item() 方法可以将其中的 Python 数值提取出来。print(f"训练损失: {loss.item():.4f}")推理演示
# 推理示例with torch.no_grad():probs = torch.sigmoid(output)pred_mask = (probs > 0.5).float()print(f"预测掩码尺寸: {pred_mask.shape}")print("预测值示例:", pred_mask[0, 0, :5, :5].cpu().numpy())它有什么用? (What it does?)
这段代码的核心作用是“后处理”(Post-processing)。它负责接收模型前向传播产生的原始输出(称为 logits),并将其转换成一个最终的、可视化的二值分割掩码(Mask)。
具体来说,它执行了以下两步关键转换:
Logits -> 概率 (Probabilities): 使用 torch.sigmoid 函数,将模型输出的、范围可以是任意实数的 logits,压缩到 0 到 1 之间,使其可以被解释为“每个像素属于目标类别的概率”。
概率 -> 最终掩码 (Final Mask): 设置一个阈值(这里是 0.5),将上一步得到的概率图转换为一个只包含 0 和 1 的二值图像。如果一个像素的概率大于 0.5,我们就判定它为目标(赋值为1),否则判定为背景(赋值为0)。
它为什么有用? (Why it's useful?)
1.赋予输出实际意义: 模型的原始输出 output 是一堆浮点数(logits),它们的大小能反映模型对分类的“信心”,但并没有明确的物理意义。通过 sigmoid 函数,我们将其转换为概率,这是一个非常直观的概念(例如,“这个像素有80%的可能性是病灶”)。这使得模型的结果变得可解释。
2.做出最终决策: 概率图仍然是连续的,而不是一个确定的分割结果。在实际应用中,我们通常需要一个非黑即白的结论(“是”或“不是”)。阈值化 (> 0.5) 就是这个“决策”过程,它根据概率大小,为每个像素分配一个最终的类别标签(0或1),生成可用于计算面积、叠加在原图上进行可视化等下游任务的分割掩码。
3.连接 PyTorch 与其他生态: pred_mask.cpu().numpy() 这一步至关重要。PyTorch 的计算(尤其是在GPU上时)是在其自己的生态系统中完成的。而我们经常需要使用其他库(如 OpenCV 进行图像处理,Matplotlib 进行绘图,Scikit-image 进行形态学分析)来处理最终结果。这些库几乎都基于 NumPy 数组。所以,.cpu().numpy() 的作用就是将结果从 PyTorch 的张量格式(可能在GPU上)安全地转换成通用的 NumPy 数组格式(在CPU上),以便进行后续的分析和可视化。
它该如何使用?
# 再次强调,在 with torch.no_grad(): 代码块中进行所有推理相关的操作,
# 这样可以节省计算资源,因为我们不需要为这些操作计算梯度。
with torch.no_grad():# torch.sigmoid() 是一个逐元素计算的函数。# 它将输入张量 'output' 中的每一个 logit 值 x,通过 sigmoid(x) = 1 / (1 + e^(-x)) 公式,# 映射到 (0, 1) 区间,得到概率张量 'probs'。probs = torch.sigmoid(output)# '(probs > 0.5)' 是一个逐元素的比较操作。# 它会返回一个与 'probs' 形状相同的布尔 (boolean) 张量。# 其中,'probs' 中值大于 0.5 的位置为 True,否则为 False。# 接着,.float() 方法将这个布尔张量转换为浮点数张量。# 在这个转换中,True 会变成 1.0,False 会变成 0.0。# 这样我们就得到了一个由0和1组成的二值分割掩码。pred_mask = (probs > 0.5).float()print(f"预测掩码尺寸: {pred_mask.shape}")# 这是一个组合操作,用于查看结果的一小部分。# pred_mask[0, 0, :5, :5]:这是张量切片。# '0' - 取批次中的第1张图。# '0' - 取通道中的第1个通道 (对于二分类,只有一个通道)。# ':5' - 取高度的前5行 (从0到4)。# ':5' - 取宽度的前5列 (从0到4)。# .cpu():如果张量在 GPU (cuda) 上,这个方法会将其复制到 CPU 内存中。# 如果张量已经在 CPU 上,则此操作无效。这是调用 .numpy() 之前的安全步骤。# .numpy():将 PyTorch CPU 张量转换为 NumPy 数组,以便在 Python 的其他库中使用。print("预测值示例:", pred_mask[0, 0, :5, :5].cpu().numpy())