机器学习聚类算法
聚类本质
无监督学习(无标签数据)
目标:将相似数据分到同一组
距离度量
度量类型 | 公式 | 特点 | 适用场景 |
|---|---|---|---|
欧式距离 |
| 直线距离 | 空间连续数据(推荐系统) |
曼哈顿距离 | `∑ | x_i - y_i |
k均值算法

如图所示:k=4时,值最大
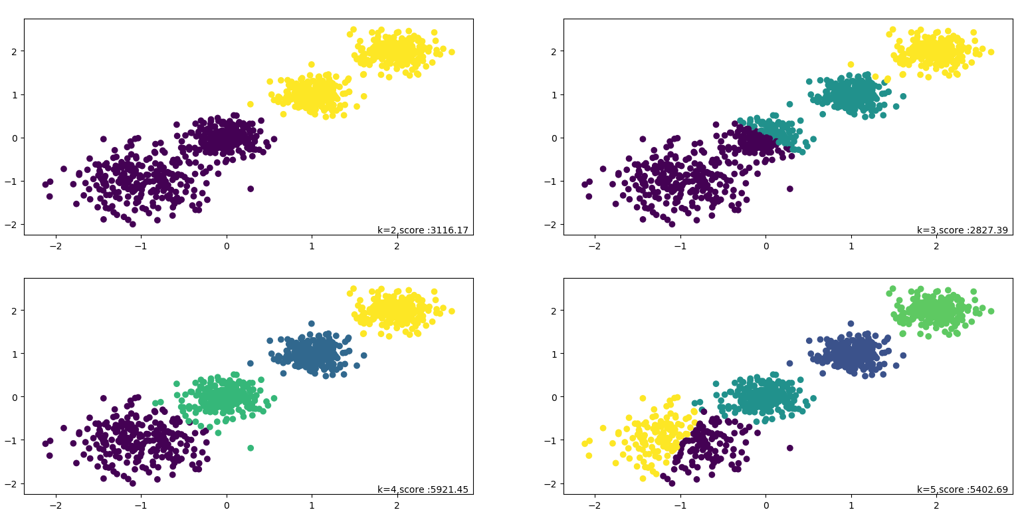
CH指标
CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度;
通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度;
从而,CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果
CH = [B/(K-1)] / [W/(N-K)] B = 类间方差(分离度) W = 类内方差(紧密度)
优点: 简单快速,适合常规数据集
函数
from sklearn.datasets import make_blobs
make_blobs():为聚类产生数据集
n_samples | 数据样本点个数,默认值100 |
n_features | 每个样本的特征数,也表示数据的维度,默认值是2 |
centers | 表示类别数(标签的种类数),默认值3 |
cluster_std | 每个类别的方差 |
center_box | 中心确定之后的数据边界,默认值(-10.0, 10.0) |
shuffle | 是否将数据进行打乱,默认值是True |
random_state | 随机生成器的种子,可以固定生成的数据 |
代码
from sklearn.datasets import make_blobs
import matplotlib.pyplot as pltx, y = make_blobs(n_samples=1000,n_features=2,centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],cluster_std=[0.4, 0.2, 0.2, 0.2],random_state=9
)plt.scatter(x[:, 0], x[:, 1], marker="o")
plt.show()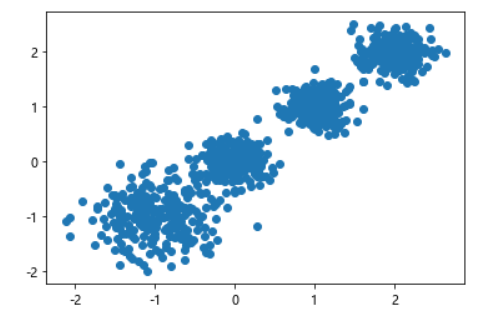
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# 生成数据(假设之前未执行)
x, _ = make_blobs(n_samples=1000, n_features=2,centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],cluster_std=[0.4, 0.2, 0.2, 0.2],random_state=9)# 聚类并可视化
y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()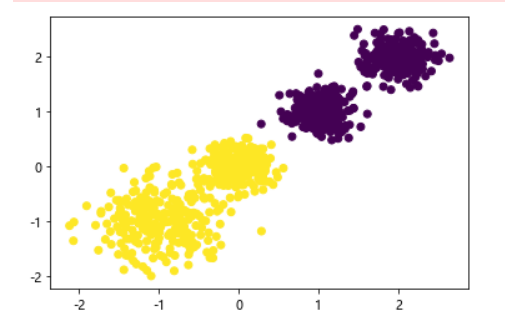
集成算法
核心原则:综合多个学习器(模型)的预测结果,比单一模型更优(类似“博采众长”)
实现方式:通过组合多个弱学习器(如决策树)构建强学习器。
方法分类
Bagging(并行训练)
特点:个体学习器相互独立,可并行训练。
代表算法:随机森林(Random Forest)
双重随机性:数据随机采样(Bootstrap)特征随机选择
优势:处理高维数据,无需特征选择输出特征重要性支持并行计算,速度快可可视化分析
输出策略:分类任务 → 投票法(少数服从多数)回归任务 → 平均法
Sklearn类:RandomForestClassifier(), RandomForestRegressor()
Boosting(串行训练)
特点:个体学习器存在依赖,需串行生成,通过调整样本权重逐步改进。
对比
方法 | 训练方式 | 学习器关系 | 代表算法 | 输出策略 |
|---|---|---|---|---|
Bagging | 并行 | 独立 | 随机森林 | 投票/平均 |
Boosting | 串行 | 强依赖 | AdaBoost | 加权组合 |
Stacking | 分阶段 | 异构模型 | 多模型组合 | 元模型二次预测 |