【TrOCR】模型预训练权重各个文件解读
预训练权重下载
huggingface上预训练权重trocr-base-printed
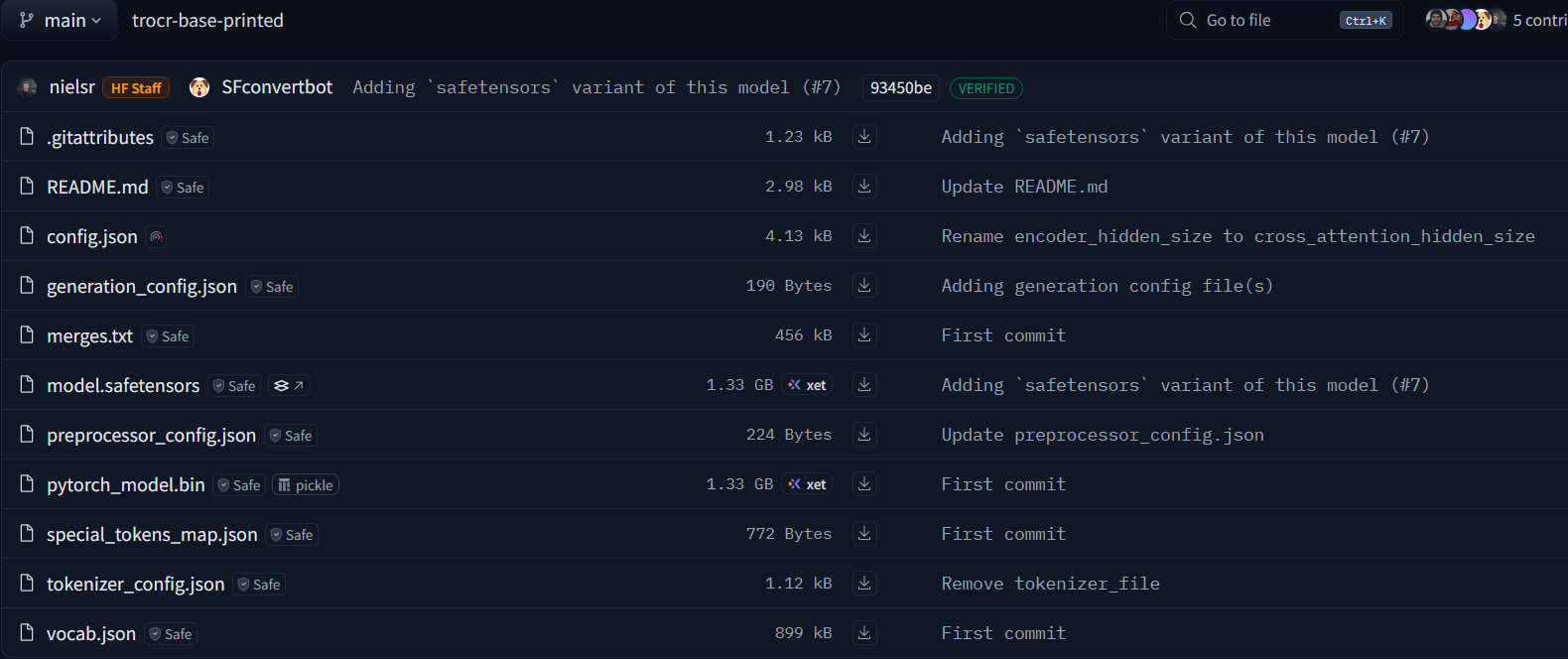
下载后的trocr-base-printed是一个文件夹,结构如下:

以下是对 trocr-base-printed 模型文件夹内各文件的简短分点解读,基于此前的详细分析提炼核心作用:
1. 模型结构与配置
config.json:定义模型整体架构(编码器-解码器结构、网络层数/维度等),是模型“蓝图”,决定网络结构与超参数。generation_config.json:文本生成专属配置(起始/结束 Token、生成策略默认值),控制model.generate()的行为。
2. 数据预处理与分词
preprocessor_config.json:图像预处理规则(归一化、缩放尺寸、插值方法),确保输入图像与预训练逻辑一致。tokenizer_config.json+vocab.json+merges.txt:定义文本分词规则(BPE 分词词表、合并规则),将文本转成模型可理解的 Token ID。special_tokens_map.json:特殊 Token(如<s>、<pad>)的映射关系,标记序列开始、结束、填充等边界。
3. 模型权重与版本管理
model.safetensors:核心权重文件(安全高效的safetensors格式),存储编码器、解码器的预训练参数,是模型“知识载体”。.gitattributes:Git LFS 规则,让大文件(如model.safetensors)被 Git LFS 管理,避免仓库膨胀。
这些文件相互配合,从 数据预处理(靠 preprocessor/tokenizer 配置)→ 模型结构定义(config.json)→ 权重加载(model.safetensors)→ 文本生成策略(generation_config.json),完整支撑了模型从“加载”到“运行”的全流程,支撑 TrOCR 完成“图像→文本”的 OCR 任务。
README.md
---
tags:
- trocr
- image-to-text
widget:
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X00016469612_1.jpgexample_title: Printed 1
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X51005255805_7.jpgexample_title: Printed 2
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X51005745214_6.jpgexample_title: Printed 3
---# TrOCR (base-sized model, fine-tuned on SROIE) TrOCR model fine-tuned on the [SROIE dataset](https://rrc.cvc.uab.es/?ch=13). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr). Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.## Model descriptionThe TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.## Intended uses & limitationsYou can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.### How to useHere is how to use this model in PyTorch:```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests# load image from the IAM database (actually this model is meant to be used on printed text)
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-printed')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-printed')
pixel_values = processor(images=image, return_tensors="pt").pixel_valuesgenerated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```### BibTeX entry and citation info```bibtex
@misc{li2021trocr,title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models}, author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},year={2021},eprint={2109.10282},archivePrefix={arXiv},primaryClass={cs.CL}
}
```
这份 README.md 是 Hugging Face Hub 上 microsoft/trocr-base-printed 模型的说明文档,详细介绍了模型的基本信息、用途、使用方法等,是快速上手该模型的核心参考。以下是逐部分解读:
一、头部元信息(模型标签与示例)
tags:
- trocr
- image-to-text
widget:
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X00016469612_1.jpgexample_title: Printed 1
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X51005255805_7.jpgexample_title: Printed 2
- src: https://layoutlm.blob.core.windows.net/trocr/dataset/SROIE2019Task2Crop/train/X51005745214_6.jpgexample_title: Printed 3
tags:模型标签,用于分类和检索。trocr表明属于 TrOCR 系列,image-to-text说明其核心功能是“图像到文本”转换(即 OCR)。widget:交互式示例,展示模型的典型输入(印刷体文本图像)。在 Hugging Face 模型页面中,用户可直接上传类似图像测试模型输出,直观了解模型效果。
二、模型基本信息
# TrOCR (base-sized model, fine-tuned on SROIE) TrOCR model fine-tuned on the [SROIE dataset](https://rrc.cvc.uab.es/?ch=13). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr). Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
- 模型名称:
trocr-base-printed是基础版(base-sized)TrOCR 模型,专门针对印刷体文本优化,并在SROIE数据集(收据识别数据集)上进行了微调。 - 来源:模型源自 2021 年论文《TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models》,由微软团队开发,首次发布于 unilm 仓库。
- 免责声明:原团队未提供官方模型卡片,此文档由 Hugging Face 团队补充,确保用户能获取关键信息。
三、模型结构说明(Model description)
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
- 核心架构:TrOCR 是“编码器-解码器”结构:
- 编码器:基于图像 Transformer(源自 BEiT 模型的预训练权重),负责将图像转换为特征序列。
- 解码器:基于文本 Transformer(源自 RoBERTa 模型的预训练权重),负责将图像特征生成为文本序列。
- 图像处理流程:
- 图像被分割为 16x16 像素的固定大小“补丁(patch)”;
- 每个补丁通过线性嵌入转换为向量,并添加绝对位置嵌入(标记补丁在图像中的位置);
- 嵌入后的序列输入 Transformer 编码器,输出图像特征;
- 解码器以自回归方式(逐词生成)基于图像特征生成文本。
四、用途与限制(Intended uses & limitations)
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
- 主要用途:适用于单行文本图像的 OCR 任务(如扫描文档中的单行文字、街景中的单行招牌等)。
- 限制:
- 对多行文本、复杂布局的图像识别效果较差(需额外的文本检测模型先分割单行);
- 主要优化印刷体,对手写体或低质量(模糊、倾斜、噪声)图像的识别可能不准确;
- 如需针对特定场景(如收据、车牌)使用,建议寻找在对应数据集上微调过的版本(可通过 Hugging Face 模型 hub 搜索)。
五、使用示例(How to use)
提供了 PyTorch 环境下的最小化使用代码,核心步骤包括:
- 加载处理器(
TrOCRProcessor)和模型(VisionEncoderDecoderModel); - 读取图像并转换为模型可接受的格式(
pixel_values); - 生成文本(
model.generate())并解码为可读字符串(processor.batch_decode())。
示例代码简洁展示了从“加载模型”到“输出结果”的完整流程,方便用户快速测试。
六、引用信息(BibTeX entry)
提供了论文的 BibTeX 引用格式,方便用户在学术研究中引用该模型时使用,确保合规性。
总结
这份 README.md 是 trocr-base-printed 模型的“使用说明书”,核心价值在于:
- 明确模型的适用场景(单行印刷体 OCR)和结构(编码器-解码器架构);
- 提供直观的使用示例,降低上手门槛;
- 提示模型的局限性和扩展方向(如寻找特定场景的微调版本)。
对于使用者而言,可通过此文档快速判断模型是否符合需求,并直接复用示例代码进行测试或集成到项目中。
vocab.json
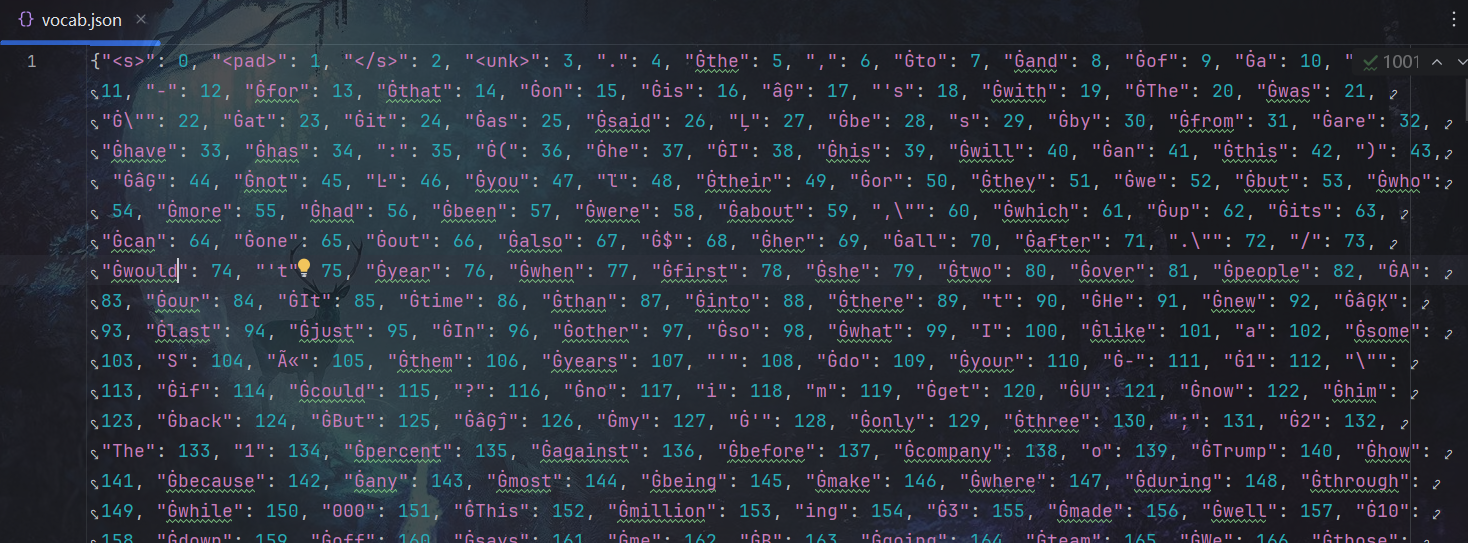
用Pycharm快捷键Ctrl+Alt+L,格式化一下:

以下为你详细解读 vocab.json 中各类 Token 的含义、作用,以及背后的分词逻辑(结合 TrOCR 这类基于 BPE 分词的模型场景),帮你理解文本是如何被“拆”成模型能懂的单元:
一、核心特殊 Token(模型运行的基础标记)
| Token | ID | 含义与作用 |
|---|---|---|
<s> | 0 | 一般是 序列开始标记(Sentence Start),文本生成任务中,常作为解码器的“起始信号”。比如用 model.generate 时,解码器会先拿到 <s>,再逐步生成后续内容。 |
<pad> | 1 | 填充标记(Padding),用来对齐一个 batch 中长度不一的文本。短文本会用 <pad> 填充到最大长度,模型会忽略这些位置的损失(或特殊处理)。 |
</s> | 2 | 序列结束标记(Sentence End),文本生成时,模型输出 </s> 就表示生成结束;也用于区分不同文本片段(比如多句子输入时)。 |
<unk> | 3 | 未知标记(Unknown),遇到分词器不认识的字符/子词时,会替换成 <unk>,避免因词表外内容报错,不过也会损失一些语义信息。 |
二、标点与常见词 Token(文本内容的基础单元)
-
标点符号:如
.:4、,:6、-:12
这些是文本中常见的标点,会被单独拆分为 Token(或和前后子词结合,取决于 BPE 规则)。作用是保留文本的语法结构,让模型理解句子停顿、断句等。 -
常见英文单词/子词:如
Ġthe:5、Ġto:7、Ġand:8- 前面的
Ġ(实际是一个特殊的空白符号,可能显示为Ġ或##类似标记),表示这个 Token 是词的开头(或独立词)。 - 比如
Ġthe就是完整的单词the,而如果有##e这样的 Token(假设存在),则表示它是某个词中间的子词(比如another可能被拆成an+##other)。 - 这类常见词的 Token,是预训练时统计高频出现的结果,让模型能高效处理日常文本。
- 前面的
三、特殊字符与缩写 Token(覆盖多样文本场景)
-
特殊字符:如
âĢ:17(可能是文本编码问题,或原始数据中的特殊符号)
预训练数据中如果包含特殊符号、小众语言字符、emoji 等,会被编码成对应的 Token 存入词表,确保模型能“看见”这些内容(虽然可能出现频率低,语义难捕捉)。 -
缩写/词缀:如
's:18(英文里的所有格缩写,如Virgil's可能拆成ĠVirgil+'s)
这类 Token 处理语言中的“紧凑表达”,让分词器不用生硬拆分'和s,保留语义完整性。
四、分词逻辑与 merges.txt 的关联(BPE 分词的关键)
vocab.json 里的 Token 是 BPE 分词的“终点”——预训练时,先统计所有可能的字符对,按频率合并成子词,直到达到预设词表大小。而 merges.txt 就记录了合并的步骤(比如先合并 e 和 s 成 es,再合并 the 和 es 成 thees 等,不过实际是更细的字符对合并)。
举个流程示例:
原始文本 → 拆成字符(t, h, e, , w, o, r, l, d…)→ 按 merges.txt 合并高频对 → 最终得到 vocab.json 里的 Ġthe、Ġworld 等 Token。
所以,vocab.json 里的每个 Token,都是 BPE 算法“合并到不能再合并(或达到词表限制)”的产物,平衡了词表大小和语义表达力。
五、对模型训练/推理的影响
- 训练阶段:模型学习的是这些 Token 之间的关联(比如看到
Ġthe后,更可能接Ġworld还是Ġof),通过预测下一个 Token 学习文本规律。 - 推理阶段:输入文本会先经分词器,按
vocab.json和merges.txt拆成对应 Token ID,再喂给模型;模型输出的 ID,也会通过vocab.json转回文本(比如 ID5对应Ġthe,最终去掉Ġ显示为the)。
简单说,vocab.json 就是模型的“字典”——所有输入输出都要通过这个“字典”转成数字 ID 才能被模型理解,而背后的 merges.txt 则是“字典是怎么造出来的”规则书。理解这套逻辑,调参(比如词表大小)、处理未登录词(Out-of-Vocabulary)时就更清晰啦
merges.txt
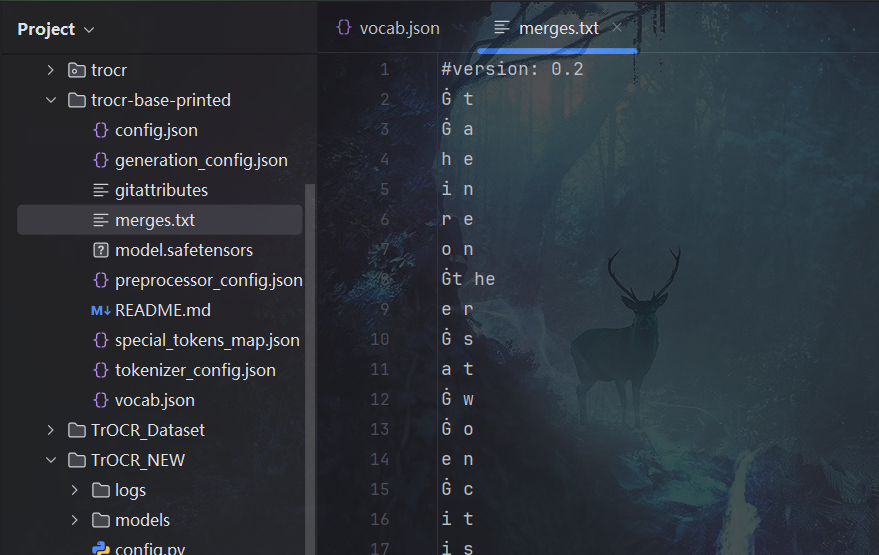
merges.txt文件在基于字节对编码(Byte - Pair Encoding,BPE)的分词算法中起着关键作用,以下是对该merges.txt文件的详细解读:
1. 文件头信息
#version: 0.2
这是一个注释行,表明当前merges.txt文件的版本信息。注释行以#开头,在BPE算法执行过程中,解析器会忽略这些注释行。它主要用于记录和区分不同版本的合并规则文件,方便管理和追溯。
2. 合并规则解析
每一行代表一次合并操作,格式为token1 token2,表示将这两个相邻的token合并成一个新的token。以下举例说明:
Ġ t:Ġ是一个特殊的前缀符号,在很多基于BPE的分词系统中,用于表示词的开头。这一行规则表示将词开头符号Ġ和字符t合并。在实际应用中,可能会出现以t开头的单词,通过这样的合并,能够在分词时将词开头和首字符作为一个整体处理。例如,对于单词the,在后续的合并步骤中,结合其他规则可以将其正确分词。
r e:- 将字符
r和e合并,这可能用于处理如re开头的词缀(如return、rebuild等)或者一些常见的双字符组合。
- 将字符
o n:- 合并字符
o和n,on是常见的介词,通过此规则将其作为一个token处理。
- 合并字符
e r:- 合并字符
e和r,这对于处理以er结尾的单词(如teacher、worker等)或者一些常见的双字符组合很有帮助。
- 合并字符
a t:- 合并字符
a和at,at是常用的介词,通过此规则将其作为一个token。
- 合并字符
3. BPE算法执行过程简述
在执行BPE算法时,初始状态下,文本会被拆分成最细粒度的单元,通常是字符或字节。然后,根据merges.txt中的合并规则,从频率最高的字符对(在训练过程中统计得出)开始,逐步进行合并操作。每次合并后,更新文本中的token表示,直到达到预设的词表大小或者没有可合并的token对为止。
4. 对分词和模型的影响
- 分词效果:通过这些合并规则,BPE分词算法能够生成更符合语言习惯和文本统计规律的词表。对于高频词,如
the、and、in等,会被完整地作为一个token,减少了分词后的token数量,提高了模型对常见语言模式的捕捉能力。同时,对于一些不常见的单词或词缀,也能通过合并规则进行合理的切分和表示。 - 模型训练:在模型训练阶段,使用基于BPE分词后的token作为输入,模型能够学习到这些token之间的语义和语法关系。由于BPE词表的构建考虑了文本的统计特性,模型可以更高效地学习到语言的规律,提高训练效率和模型性能。在推理阶段,输入文本按照相同的BPE规则进行分词,然后输入到模型中进行处理,从而得到准确的预测结果。
总之,merges.txt文件中的合并规则是BPE分词算法的核心,它决定了词表的构建和文本的分词方式,对基于该分词算法的自然语言处理模型有着重要的影响。
special_tokens_map.json
{"bos_token": {"content": "<s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true},"eos_token": {"content": "</s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true},"unk_token": {"content": "<unk>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true},"sep_token": {"content": "</s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true},"pad_token": {"content": "<pad>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true},"cls_token": {"content": "<s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true},"mask_token": {"content": "<mask>","single_word": false,"lstrip": true,"rstrip": false,"normalized": true}
}
以下是对 trocr-base-printed/special_tokens_map.json 文件内容的详细解读,帮你理解每个特殊 Token 的定义和作用:
1. 核心字段含义
每个 Token 配置包含 5 个字段,共同定义 Token 的行为:
| 字段 | 作用 |
|---|---|
content | Token 的文本内容(如 <s>、<pad>),是模型/分词器实际处理的字符串 |
single_word | 是否强制作为“单个词”处理(一般设为 false,让分词器按 BPE 规则拆分/合并) |
lstrip | 是否自动去除 Token 左侧的空白(仅对 mask_token 等特殊场景有用,控制前后空格处理) |
rstrip | 是否自动去除 Token 右侧的空白(同上,微调空格对文本的影响) |
normalized | 是否启用“标准化”(如 Unicode 归一化,确保输入文本和预训练时的处理逻辑一致) |
2. 逐个 Token 解读
(1) bos_token(Begin Of Sequence)
- 作用:序列开始标记,文本生成时强制作为解码器的第一个输入(让模型知道“从这里开始生成”)。
- 配置细节:
content: "<s>":和vocab.json中定义的<s>对应,确保前后端统一。- 其他字段(
single_word等)默认值,表明按常规分词逻辑处理(实际也不会拆分它,因为是特殊标记)。
(2) eos_token(End Of Sequence)
- 作用:序列结束标记,文本生成时遇到它就停止生成;也用于分割不同文本片段(如多句子输入)。
- 配置细节:
content: "</s>":和vocab.json中定义的</s>对应。- 注意:这里
eos_token和sep_token复用了</s>,说明模型设计中“结束序列”和“分隔片段”用同一个标记。
(3) unk_token(Unknown)
- 作用:遇到词表外的字符/子词时,用
<unk>替代,避免报错,保证模型鲁棒性。 - 配置细节:
content: "<unk>":对应vocab.json中的未知标记。- 实际场景中,若输入文本有生僻字、乱码,就会被转成
<unk>,模型会学习对这类标记的“泛化处理”。
(4) sep_token(Separator)
- 作用:文本分隔标记,分割不同语义单元(如多句文本拼接时,用
</s>分隔句子)。 - 配置细节:
- 和
eos_token复用</s>,说明模型设计中“结束”和“分隔”逻辑复用(常见于_seq2seq 任务,一个标记承担两种角色)。
- 和
(5) pad_token(Padding)
- 作用:填充标记,对齐 batch 内不等长的文本(短文本用
<pad>补全到最大长度)。 - 配置细节:
content: "<pad>":对应vocab.json中的填充标记。- 模型计算损失时,通常会忽略
<pad>位置的损失(靠attention_mask实现),避免无效计算。
(6) cls_token(Classification)
- 作用:分类标记,部分模型(如 BERT)用
<s>作为cls_token,提取整段文本的语义特征(TrOCR 中可能用于 encoder-decoder 架构的特殊位置编码)。 - 配置细节:
- 和
bos_token复用<s>,说明模型设计中“序列开始”和“分类特征提取”复用同一个标记(常见于多任务适配)。
- 和
(7) mask_token(Mask)
- 作用:掩码标记,预训练任务(如 MLM)中用
<mask>替代部分文本,让模型预测被掩盖的内容。 - 配置细节:
lstrip: true:自动去除左侧空白,避免掩码前后多余空格影响语义(比如<mask>word→<mask>word)。- TrOCR 虽以 OCR 为核心,但可能保留
mask_token适配多任务,或历史代码兼容。
3. 对 TrOCR 训练/推理的影响
-
训练阶段:
- 文本输入会自动插入
bos_token/eos_token(如[<s>, token1, token2, </s>]),保证模型学习完整的“序列开始-内容-结束”逻辑。 pad_token对齐 batch,mask_token(若用到 MLM 预训练)让模型学习文本修复能力。
- 文本输入会自动插入
-
推理阶段:
- 生成文本时,解码器从
bos_token(<s>)开始,直到输出eos_token(</s>)停止。 - 遇到未知字符自动转
unk_token,避免崩溃;pad_token不影响最终输出(会被过滤)。
- 生成文本时,解码器从
简单说,这个文件是**“特殊 Token 的使用说明书”**,定义了每个标记的文本形式、处理规则,让模型在 encoder-decoder 流程中,能统一处理“开始、结束、填充、未知、掩码”等特殊场景,保证和预训练逻辑一致 。理解这些配置,微调模型或适配新任务时,就能清晰控制输入输出的边界啦~
tokenizer_config.json
{"errors": "replace","unk_token": {"content": "<unk>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true,"__type": "AddedToken"},"bos_token": {"content": "<s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true,"__type": "AddedToken"},"eos_token": {"content": "</s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true,"__type": "AddedToken"},"add_prefix_space": false,"sep_token": {"content": "</s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true,"__type": "AddedToken"},"cls_token": {"content": "<s>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true,"__type": "AddedToken"},"pad_token": {"content": "<pad>","single_word": false,"lstrip": false,"rstrip": false,"normalized": true,"__type": "AddedToken"},"mask_token": {"content": "<mask>","single_word": false,"lstrip": true,"rstrip": false,"normalized": true,"__type": "AddedToken"},"model_max_length": 512,"special_tokens_map_file": null,"name_or_path": "roberta-large","tokenizer_class": "RobertaTokenizer"
}
tokenizer_config.json文件是分词器的配置文件,它定义了分词器在处理文本时的各种行为和属性。以下是对该文件内容的详细解读:
通用配置字段
errors:"replace"- 含义:指定在分词过程中遇到编码错误时的处理方式。当设置为
replace时,意味着在遇到无法正确编码的字符时,分词器会用一个替代字符(通常是?)来替换错误字符,而不是抛出异常。这样可以保证分词过程的连续性,避免因个别字符的编码问题导致整个文本处理失败。
- 含义:指定在分词过程中遇到编码错误时的处理方式。当设置为
add_prefix_space:false- 含义:决定是否在输入文本前添加一个空格。当设置为
false时,分词器会按照文本原本的样子进行处理,不会额外添加空格。如果设置为true,对于一些基于词的分词器,可能会影响分词结果,例如原本分词为"hello"和"world"的文本,添加空格后可能会被视为一个整体的词组进行不同方式的分词。
- 含义:决定是否在输入文本前添加一个空格。当设置为
特殊Token配置
文件中对多个特殊Token进行了详细配置,这些特殊Token在自然语言处理任务中起着关键作用,如标记文本的开始、结束,处理未知词汇等。每个特殊Token的配置都包含以下几个字段:
content: 表示特殊Token的文本内容,与vocab.json中的定义相对应。single_word:false,表示该Token不会被强制视为一个单独的单词,分词器会根据其内部规则(如BPE算法)来决定是否对其进行进一步拆分或合并。lstrip: 表示是否去除Token左侧的空白字符。例如,对于" <mask>",如果lstrip为true,则会去除左侧的空格,变为"<mask>"。rstrip: 表示是否去除Token右侧的空白字符,与lstrip类似。normalized:true,表示启用标准化操作,例如Unicode归一化,确保输入文本的格式与预训练时的格式一致,避免因字符表示差异导致的问题。__type:"AddedToken",表明这些特殊Token是在词表基础上额外添加的特殊标记。
具体的特殊Token及其作用如下:
unk_token:- 作用:当分词器遇到词表中不存在的字符或子词时,会将其替换为
<unk>(未知标记),防止因未知词汇导致分词失败,同时模型可以学习对这类未知情况的处理方式。
- 作用:当分词器遇到词表中不存在的字符或子词时,会将其替换为
bos_token:- 作用:即Begin Of Sequence,序列开始标记,用于指示文本序列的起始位置。在文本生成任务中,解码器通常会以这个标记作为生成的起点。
eos_token:- 作用:即End Of Sequence,序列结束标记,用于指示文本序列的结束。当模型在生成文本时输出这个标记,就表示生成过程结束。在多句文本处理中,也可以用来分隔不同的句子。
sep_token:- 作用:即Separator Token,分隔标记,用于分隔不同的文本片段。例如,在处理包含多个句子的文本时,可以用
</s>来分隔各个句子,帮助模型理解文本的结构。
- 作用:即Separator Token,分隔标记,用于分隔不同的文本片段。例如,在处理包含多个句子的文本时,可以用
cls_token:- 作用:即Classification Token,分类标记。在一些模型(如BERT及其衍生模型)中,会在文本序列的开头添加这个标记,模型会对这个标记对应的输出向量进行处理,用于文本分类等任务,以获取整个文本的语义表示。
pad_token:- 作用:即Padding Token,填充标记。在将多个文本组成一个批次(batch)进行处理时,由于文本长度可能不同,需要将短文本填充到与最长文本相同的长度,这时就会使用
<pad>标记进行填充。在计算损失时,通常会忽略这些填充位置,以避免对模型训练产生干扰。
- 作用:即Padding Token,填充标记。在将多个文本组成一个批次(batch)进行处理时,由于文本长度可能不同,需要将短文本填充到与最长文本相同的长度,这时就会使用
mask_token:- 作用:即Mask Token,掩码标记。在一些预训练任务(如Masked Language Model,MLM)中,会随机将文本中的一些Token替换为
<mask>,然后让模型预测被掩码的Token是什么,以此来学习文本的语义信息。
- 作用:即Mask Token,掩码标记。在一些预训练任务(如Masked Language Model,MLM)中,会随机将文本中的一些Token替换为
其他配置字段
model_max_length:512- 含义:指定模型能够处理的最大文本长度(以Token为单位)。当输入文本的Token数量超过这个值时,分词器可能会进行截断操作,以确保输入符合模型的要求。
special_tokens_map_file:null- 含义:指定特殊Token映射文件的路径。如果该文件存在,分词器会从这个文件中读取特殊Token的映射关系。当前设置为
null,可能意味着使用当前文件中定义的特殊Token配置。
- 含义:指定特殊Token映射文件的路径。如果该文件存在,分词器会从这个文件中读取特殊Token的映射关系。当前设置为
name_or_path:"roberta-large"- 含义:指定分词器对应的模型名称或路径。这里表示该分词器是基于
roberta-large模型的,这会影响分词器的一些默认行为和词表等属性。
- 含义:指定分词器对应的模型名称或路径。这里表示该分词器是基于
tokenizer_class:"RobertaTokenizer"- 含义:指定分词器的类名。这里表明使用的是
RobertaTokenizer类,它定义了分词器的具体实现逻辑,包括分词、编码、解码等操作。
- 含义:指定分词器的类名。这里表明使用的是
总的来说,tokenizer_config.json文件详细定义了分词器的各种行为和属性,确保分词器能够按照模型的需求正确地处理输入文本,在自然语言处理任务的文本预处理阶段起着至关重要的作用。
preprocessor_config.json
{"do_normalize": true,"do_resize": true,"image_processor_type": "ViTImageProcessor","image_mean": [0.5,0.5,0.5],"image_std": [0.5,0.5,0.5],"resample": 2,"size": 384
}
preprocessor_config.json 是 TrOCR 模型中图像预处理的核心配置文件,定义了输入图像如何转换为模型可接受的格式(与预训练时的处理逻辑保持一致)。以下是详细解读:
1. 核心预处理开关
-
do_normalize: true
启用图像归一化处理。
作用:将图像像素值从[0, 255]映射到[-1, 1](结合image_mean和image_std),消除不同图像间光照、对比度差异的影响,让模型更专注于内容特征学习。
计算方式:normalized_pixel = (pixel - mean) / std(每个通道单独计算)。 -
do_resize: true
启用图像缩放处理。
作用:将输入图像统一缩放到固定尺寸(由size定义),确保输入到模型的张量形状一致(TrOCR 的编码器要求固定尺寸的输入)。
2. 图像处理器类型
image_processor_type: "ViTImageProcessor"
声明使用的图像处理器类型为ViTImageProcessor(ViT 即 Vision Transformer)。
TrOCR 的编码器基于 ViT 架构,因此需要用配套的处理器处理图像,确保与预训练时的分块、编码逻辑一致(例如将图像分割为 16x16 的 patches 等)。
3. 归一化参数
-
image_mean: [0.5, 0.5, 0.5]
图像三个通道(RGB)的均值。
预训练时,模型使用的图像数据集(如 BookCorpus、COCO 等)的像素均值被统计为[0.5, 0.5, 0.5](已归一化到[0, 1]范围,对应原始像素值127.5)。 -
image_std: [0.5, 0.5, 0.5]
图像三个通道的标准差。
与均值对应,预训练数据的标准差为0.5(对应原始像素值的标准差127.5)。
结合均值和标准差,归一化后像素值范围为[-1, 1],这是 ViT 模型常用的输入范围。
4. 缩放与采样参数
-
resample: 2
图像缩放时使用的插值方法。
在 PIL 库中,resample=2对应 双线性插值(BILINEAR),这是一种平衡速度和质量的插值方式,能较好地保留图像细节(尤其适合文本图像,避免字体边缘模糊)。 -
size: 384
图像缩放后的目标尺寸(单位:像素)。
TrOCR-base 模型的编码器要求输入图像尺寸为384x384(宽 x 高),因此所有输入图像会被缩放到这个尺寸(短边缩放,长边按比例裁剪或填充,具体由处理器内部逻辑决定)。
对模型训练/推理的影响
- 训练阶段:若输入图像未按此配置处理(如均值/标准差错误、尺寸不符),会导致模型看到的“像素分布”与预训练时不一致,严重影响拟合效果(例如损失居高不下、精度极低)。
- 推理阶段:若测试图像的预处理逻辑与配置不符(如未归一化、尺寸错误),模型会因输入分布不匹配而输出错误结果(例如文本识别错乱)。
总结来说,preprocessor_config.json 是图像输入的“标准化说明书”,确保所有输入图像都按预训练时的规则(尺寸、归一化、插值方法等)处理,是 TrOCR 模型能正常工作的前提。修改这些参数(如更换 size 或 image_mean)需谨慎,通常需重新训练模型才能适配新的输入分布。
generation_config.json
{"_from_model_config": true,"bos_token_id": 0,"decoder_start_token_id": 2,"eos_token_id": 2,"pad_token_id": 1,"transformers_version": "4.27.0.dev0","use_cache": false
}
generation_config.json 是 TrOCR 模型进行文本生成(如 model.generate())时的核心配置文件,定义了生成过程中的关键参数和行为规则。以下是对该文件内容的详细解读:
1. 配置来源标记
"_from_model_config": true
表明当前生成配置是从模型主配置(config.json)中迁移而来的。
这与transformers库的版本演进有关:早期版本将生成参数放在model.config中,后期版本独立为generation_config,此标记用于兼容历史配置,说明这些参数继承自原始模型配置。
2. 特殊 Token ID 映射(生成的核心边界定义)
-
"bos_token_id": 0
对应vocab.json中<s>的 ID(序列开始标记)。
生成文本时,部分模型会在序列开头插入此 Token(但 TrOCR 等 encoder-decoder 模型更依赖decoder_start_token_id,此处可能为兼容保留)。 -
"decoder_start_token_id": 2
解码器的起始 Token ID,对应vocab.json中的</s>(序列结束标记)。
这是 TrOCR 生成的关键参数:解码器开始生成时,第一个输入 Token 就是 ID=2 的</s>,之后基于图像特征逐步生成后续文本。
(注:此处用</s>作为起始符是模型设计特性,不同模型可能用<s>或其他特殊 Token,需严格遵循预训练配置。) -
"eos_token_id": 2
序列结束 Token ID,同样对应</s>。
当解码器生成 ID=2 的 Token 时,生成过程会终止,确保文本不会无限延长。 -
"pad_token_id": 1
填充 Token ID,对应vocab.json中的<pad>。
当生成的文本长度不足max_length时,会用此 Token 填充至指定长度(不影响语义,仅用于对齐 batch 数据)。
3. 模型版本与缓存控制
-
"transformers_version": "4.27.0.dev0"
记录生成此配置时使用的transformers库版本。
不同版本的生成逻辑可能存在细节差异(如 beam search 实现),此标记用于追溯兼容性问题。 -
"use_cache": false
控制生成过程中是否缓存解码器的中间计算结果(如注意力权重)。false表示不缓存,每次生成新 Token 时重新计算所有中间结果,适合小模型或需要动态调整的场景,但速度较慢。- 若设为
true,会缓存前序步骤的计算结果,加速生成(尤其长文本),但会增加内存占用。
TrOCR 此处默认false可能是为了兼容某些生成策略,实际使用中可根据需求在model.generate()中动态覆盖(如use_cache=True加速推理)。
对生成效果的影响
这些参数直接决定了生成文本的“边界”和“效率”:
decoder_start_token_id错误会导致解码器无法正确启动(如生成乱码或提前终止);eos_token_id错误会导致生成无限延长(不会自动停止);use_cache影响生成速度和内存占用,需根据硬件调整。
总结
generation_config.json 是文本生成的“交通规则”:通过定义起始、结束、填充等 Token 的 ID,划定生成的边界;通过缓存控制等参数调节生成效率。对于 TrOCR,decoder_start_token_id=2 是最关键的参数,必须与预训练时的解码器起始逻辑一致,否则会导致生成失败。实际使用中,若需调整生成策略(如 beam search 数量、最大长度),可在 model.generate() 中动态传入参数(如 num_beams=4),无需修改此配置文件。
config.json
{"architectures": ["VisionEncoderDecoderModel"],"decoder": {"_name_or_path": "","activation_dropout": 0.0,"activation_function": "gelu","add_cross_attention": true,"architectures": null,"attention_dropout": 0.0,"bad_words_ids": null,"bos_token_id": 0,"chunk_size_feed_forward": 0,"classifier_dropout": 0.0,"d_model": 1024,"decoder_attention_heads": 16,"decoder_ffn_dim": 4096,"decoder_layerdrop": 0.0,"decoder_layers": 12,"decoder_start_token_id": 2,"diversity_penalty": 0.0,"do_sample": false,"dropout": 0.1,"early_stopping": false,"cross_attention_hidden_size": 768,"encoder_no_repeat_ngram_size": 0,"eos_token_id": 2,"finetuning_task": null,"forced_bos_token_id": null,"forced_eos_token_id": null,"id2label": {"0": "LABEL_0","1": "LABEL_1"},"init_std": 0.02,"is_decoder": true,"is_encoder_decoder": false,"label2id": {"LABEL_0": 0,"LABEL_1": 1},"length_penalty": 1.0,"max_length": 20,"max_position_embeddings": 512,"min_length": 0,"model_type": "trocr","no_repeat_ngram_size": 0,"num_beam_groups": 1,"num_beams": 1,"num_return_sequences": 1,"output_attentions": false,"output_hidden_states": false,"output_scores": false,"pad_token_id": 1,"prefix": null,"problem_type": null,"pruned_heads": {},"remove_invalid_values": false,"repetition_penalty": 1.0,"return_dict": true,"return_dict_in_generate": false,"scale_embedding": false,"sep_token_id": null,"task_specific_params": null,"temperature": 1.0,"tie_encoder_decoder": false,"tie_word_embeddings": true,"tokenizer_class": null,"top_k": 50,"top_p": 1.0,"torch_dtype": null,"torchscript": false,"transformers_version": "4.12.0.dev0","use_bfloat16": false,"use_cache": false,"vocab_size": 50265},"encoder": {"_name_or_path": "","add_cross_attention": false,"architectures": null,"attention_probs_dropout_prob": 0.0,"bad_words_ids": null,"bos_token_id": null,"chunk_size_feed_forward": 0,"decoder_start_token_id": null,"diversity_penalty": 0.0,"do_sample": false,"early_stopping": false,"cross_attention_hidden_size": null,"encoder_no_repeat_ngram_size": 0,"eos_token_id": null,"finetuning_task": null,"forced_bos_token_id": null,"forced_eos_token_id": null,"hidden_act": "gelu","hidden_dropout_prob": 0.0,"hidden_size": 768,"id2label": {"0": "LABEL_0","1": "LABEL_1"},"image_size": 384,"initializer_range": 0.02,"intermediate_size": 3072,"is_decoder": false,"is_encoder_decoder": false,"label2id": {"LABEL_0": 0,"LABEL_1": 1},"layer_norm_eps": 1e-12,"length_penalty": 1.0,"max_length": 20,"min_length": 0,"model_type": "vit","no_repeat_ngram_size": 0,"num_attention_heads": 12,"num_beam_groups": 1,"num_beams": 1,"num_channels": 3,"num_hidden_layers": 12,"num_return_sequences": 1,"output_attentions": false,"output_hidden_states": false,"output_scores": false,"pad_token_id": null,"patch_size": 16,"prefix": null,"problem_type": null,"pruned_heads": {},"qkv_bias": false,"remove_invalid_values": false,"repetition_penalty": 1.0,"return_dict": true,"return_dict_in_generate": false,"sep_token_id": null,"task_specific_params": null,"temperature": 1.0,"tie_encoder_decoder": false,"tie_word_embeddings": true,"tokenizer_class": null,"top_k": 50,"top_p": 1.0,"torch_dtype": null,"torchscript": false,"transformers_version": "4.12.0.dev0","use_bfloat16": false},"is_encoder_decoder": true,"model_type": "vision-encoder-decoder","tie_word_embeddings": false,"torch_dtype": "float32","transformers_version": null
}
config.json 是 TrOCR 模型的核心配置文件,完整定义了模型的整体架构、编码器(图像处理)、解码器(文本生成)的网络结构、超参数及行为规则,是模型从“代码结构”到“可运行实例”的桥梁。以下是详细解读:
一、整体配置(模型顶层属性)
| 参数 | 含义与作用 |
|---|---|
"architectures": ["VisionEncoderDecoderModel"] | 声明模型的核心架构为 VisionEncoderDecoderModel(视觉编码器-文本解码器架构),即 TrOCR 的核心设计:用视觉编码器处理图像,用文本解码器生成文字。 |
"is_encoder_decoder": true | 明确该模型是“编码器-解码器”结构(区别于纯编码器如 ViT 或纯解码器如 GPT),支持“图像→文本”的序列转换任务。 |
"model_type": "vision-encoder-decoder" | 模型类型标识,用于 transformers 库识别模型类别,加载对应的处理逻辑。 |
"tie_word_embeddings": false | 编码器与解码器的词嵌入(权重矩阵)是否共享。此处为 false,因为编码器处理图像(无词嵌入),解码器处理文本,无需共享。 |
"torch_dtype": "float32" | 模型参数的数据类型(32位浮点数),影响训练/推理的精度和内存占用(如 float16 可加速推理但可能损失精度)。 |
二、编码器配置(encoder,处理图像的模块)
编码器基于 Vision Transformer(ViT) 设计,负责将输入图像转换为语义特征。核心参数如下:
1. 基础属性
"model_type": "vit":编码器类型为 ViT(视觉Transformer),专门用于图像特征提取。"_name_or_path": "":预训练权重的来源路径(此处为空,说明使用默认配置)。
2. 图像输入参数
"image_size": 384:输入图像的目标尺寸(384x384 像素),与preprocessor_config.json中的size对应,确保预处理后图像尺寸与编码器要求一致。"num_channels": 3:输入图像的通道数(3 对应 RGB 彩色图像)。"patch_size": 16:ViT 将图像分割为 16x16 像素的“补丁(patch)”,每个补丁被转换为一个向量(如 384x384 图像会被分成 (384/16)x(384/16)=24x24=576 个补丁)。
3. Transformer 网络结构
"hidden_size": 768:ViT 隐藏层的维度(每个补丁向量的长度),决定特征表示的容量。"num_hidden_layers": 12:Transformer 编码器的层数(12 层),层数越多,模型拟合能力越强(但计算成本越高)。"num_attention_heads": 12:多头注意力的头数(12 头),头数越多,模型可并行捕捉的语义关系越丰富。"intermediate_size": 3072:前馈神经网络(FFN)的中间层维度(= 4×hidden_size,ViT 常见设计),用于特征的非线性转换。"hidden_act": "gelu":激活函数(GELU),引入非线性,增强模型表达能力。"attention_probs_dropout_prob": 0.0、"hidden_dropout_prob": 0.0:注意力层和隐藏层的 dropout 概率(此处为 0,可能是预训练时的设置,微调时可增加以防止过拟合)。"layer_norm_eps": 1e-12:层归一化的微小常量,避免分母为 0。
4. 其他特性
"add_cross_attention": false:编码器是否需要关注解码器的输出(此处为false,因为编码器仅负责提取图像特征,不参与文本生成的交互)。"is_decoder": false:明确编码器不是解码器(仅负责特征提取,不生成序列)。
三、解码器配置(decoder,生成文本的模块)
解码器基于 Transformer 解码器 设计,负责将编码器输出的图像特征转换为文本序列。核心参数如下:
1. 基础属性
"model_type": "trocr":解码器类型为 TrOCR 专用解码器(基于 BERT/RoBERTa 解码器改进)。"is_decoder": true:明确该模块是解码器,支持自回归生成(逐词生成文本)。"add_cross_attention": true:解码器是否关注编码器的输出(图像特征)。此处为true,是“图像→文本”生成的核心:解码器每一步生成都需要参考图像特征,确保生成的文本与图像内容一致。
2. Transformer 网络结构
"d_model": 1024:解码器隐藏层维度(与编码器的hidden_size不同,说明编码器和解码器不共享特征维度)。"decoder_layers": 12:解码器的层数(12 层),与编码器对称,平衡模型能力。"decoder_attention_heads": 16:解码器自注意力的头数(16 头),比编码器多,增强文本生成的语义捕捉能力。"decoder_ffn_dim": 4096:解码器前馈网络的维度(= 4×d_model),用于文本特征的非线性转换。"activation_function": "gelu":激活函数(与编码器一致,保持一致性)。"dropout": 0.1:解码器的 dropout 概率(0.1),略高于编码器,防止文本生成时过拟合训练数据。
3. 文本生成核心参数
"vocab_size": 50265:解码器的词表大小(与vocab.json中的词表数量对应),决定模型可生成的文本范围。"cross_attention_hidden_size": 768:跨注意力层的输入维度(与编码器的hidden_size一致),确保解码器能正确“关注”编码器输出的图像特征(维度匹配才能计算注意力)。- 特殊 Token ID:
"bos_token_id": 0(<s>的 ID)、"eos_token_id": 2(</s>的 ID)、"pad_token_id": 1(<pad>的 ID):与special_tokens_map.json完全对应,控制文本序列的开始、结束和填充。"decoder_start_token_id": 2:解码器生成的起始 Token ID(</s>),TrOCR 设计如此(不同模型可能用<s>,需严格遵循预训练配置)。
4. 生成策略默认值
"num_beams": 1:默认 beam search 的 beam 数量(1 表示贪心搜索,速度快但可能生成局部最优结果)。"max_length": 20:默认生成文本的最大长度(可在model.generate()中动态覆盖)。"use_cache": false:是否缓存前序步骤的注意力结果(默认不缓存,可在推理时设为true加速生成)。
四、关键参数的联动关系
- 图像尺寸与编码器匹配:
preprocessor_config.json中的size=384与编码器image_size=384对应,确保输入图像尺寸符合编码器要求。 - 跨注意力维度匹配:编码器
hidden_size=768与解码器cross_attention_hidden_size=768一致,保证解码器能正确“读取”图像特征。 - 特殊 Token 全局一致:
bos_token_id、eos_token_id等在config.json、special_tokens_map.json、generation_config.json中完全统一,确保文本生成的边界控制一致。
对模型的影响
- 结构层面:这些参数决定了模型的“容量”(层数、头数、隐藏维度),直接影响模型的拟合能力和计算成本(如更大的
d_model或更多层数会增加内存和时间消耗)。 - 功能层面:编码器参数确保图像能被正确转换为特征,解码器参数确保文本能基于图像特征生成,跨注意力参数是两者的“桥梁”。
- 兼容性层面:修改任何核心参数(如
image_size、vocab_size)都需要重新训练模型,否则会因输入/输出不匹配导致错误。
总结来说,config.json 是 TrOCR 模型的“蓝图”,从宏观架构到微观参数,完整定义了“图像→文本”转换的全过程。理解这些参数,能帮助你在微调、部署时更精准地控制模型行为,排查因配置不匹配导致的问题(如尺寸错误、特征维度不兼容等)。
model.safetensors
model.safetensors 是 TrOCR 模型中存储预训练权重的核心文件,采用 safetensors 格式(一种安全、高效的张量存储格式),替代了传统的 pickle 或 PyTorch .bin 格式。以下是详细解读:
1. 格式特性:为什么用 safetensors?
safetensors 是 Hugging Face 推出的新型张量存储格式,相比传统格式(如 .bin、.pth)有两大核心优势:
- 安全性:避免
pickle格式的代码执行漏洞(pickle加载时可能执行恶意代码),safetensors仅解析张量数据,不执行任何代码,大幅降低安全风险。 - 跨框架兼容性:原生支持 PyTorch、TensorFlow、JAX 等主流框架,同一文件可在不同框架中直接加载,无需格式转换。
2. 内容构成:存储什么数据?
model.safetensors 包含 TrOCR 模型所有层的权重参数,具体可分为两部分:
-
编码器(Vision Transformer)权重:
- 图像补丁嵌入层(patch embedding)的权重矩阵;
- 12 层 Transformer 编码器的参数(多头注意力权重、层归一化参数、前馈神经网络权重等);
- 位置嵌入向量(记录图像补丁的位置信息)。
-
解码器(Text Transformer)权重:
- 词嵌入层(word embedding)的权重矩阵(与
vocab.json中的词表对应); - 12 层 Transformer 解码器的参数(自注意力权重、跨注意力权重、层归一化参数等);
- 输出层(投影层)的权重(将解码器输出映射到词表空间)。
- 词嵌入层(word embedding)的权重矩阵(与
3. 数据结构:权重如何组织?
文件内部以键值对形式存储张量,键名通常对应模型层的路径,值为张量数据(多维数组)。例如:
encoder.layer.0.attention.attention.query.weight:编码器第 0 层注意力机制中“查询(query)”的权重;decoder.layer.3.crossattention.output.dense.bias:解码器第 3 层跨注意力输出层的偏置;decoder.embed_tokens.weight:解码器的词嵌入矩阵。
这些键名与 config.json 中定义的网络结构一一对应,加载模型时,transformers 库会根据键名自动将权重分配到模型的对应层。
4. 与其他文件的关联
- 依赖
config.json:权重的维度(如hidden_size=768)必须与config.json中定义的网络结构匹配,否则会出现“形状不兼容”错误。 - 配合
vocab.json:解码器的词嵌入层权重维度为[vocab_size, d_model],需与vocab.json中的词表大小(50265)一致。 - 由
.gitattributes管理:因文件体积大(通常数百 MB),通过 Git LFS 跟踪(见.gitattributes中的model.safetensors filter=lfs规则)。
5. 加载与使用
在代码中,model.safetensors 会被 VisionEncoderDecoderModel.from_pretrained() 自动加载,无需手动处理:
from transformers import VisionEncoderDecoderModel
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-printed")
# 内部流程:读取 config.json 构建模型结构 → 读取 model.safetensors 加载权重
若需手动查看权重(调试场景),可使用 safetensors 库:
from safetensors.torch import load_file
weights = load_file("model.safetensors")
print(weights.keys()) # 查看所有权重键名
print(weights["encoder.layer.0.attention.attention.query.weight"].shape) # 查看某层权重形状
6. 对模型的影响
- 模型功能的基础:没有
model.safetensors,模型仅为“空架子”(只有结构,没有预训练学到的知识),无法进行推理或微调。 - 文件完整性关键:文件损坏或不完整会导致加载失败(如
SafetensorError),需重新下载(见之前的错误解决方法)。 - 微调的载体:微调时,该文件中的权重会被更新,保存微调后的模型时,新权重也会写入
model.safetensors。
总结:model.safetensors 是 TrOCR 模型的“知识载体”,以安全高效的格式存储了所有预训练权重,是模型能够实现“图像→文本”转换的核心数据文件。理解其作用有助于排查权重加载错误(如文件损坏、版本不兼容),并明确微调时模型参数的更新对象。
gitattributes
*.7z filter=lfs diff=lfs merge=lfs -text
*.arrow filter=lfs diff=lfs merge=lfs -text
*.bin filter=lfs diff=lfs merge=lfs -text
*.bin.* filter=lfs diff=lfs merge=lfs -text
*.bz2 filter=lfs diff=lfs merge=lfs -text
*.ftz filter=lfs diff=lfs merge=lfs -text
*.gz filter=lfs diff=lfs merge=lfs -text
*.h5 filter=lfs diff=lfs merge=lfs -text
*.joblib filter=lfs diff=lfs merge=lfs -text
*.lfs.* filter=lfs diff=lfs merge=lfs -text
*.model filter=lfs diff=lfs merge=lfs -text
*.msgpack filter=lfs diff=lfs merge=lfs -text
*.onnx filter=lfs diff=lfs merge=lfs -text
*.ot filter=lfs diff=lfs merge=lfs -text
*.parquet filter=lfs diff=lfs merge=lfs -text
*.pb filter=lfs diff=lfs merge=lfs -text
*.pt filter=lfs diff=lfs merge=lfs -text
*.pth filter=lfs diff=lfs merge=lfs -text
*.rar filter=lfs diff=lfs merge=lfs -text
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.tar.* filter=lfs diff=lfs merge=lfs -text
*.tflite filter=lfs diff=lfs merge=lfs -text
*.tgz filter=lfs diff=lfs merge=lfs -text
*.xz filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zstandard filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
model.safetensors filter=lfs diff=lfs merge=lfs -text.gitattributes 文件是 Git 版本控制系统中用于指定文件属性和处理规则的配置文件,尤其在包含大文件(如模型权重、数据集)的仓库中至关重要。以下是对该文件内容的详细解读:
核心作用
该文件的主要目的是将大文件(如模型权重、压缩包)交给 Git LFS(Large File Storage)管理,避免 Git 原生机制因处理大文件导致的仓库膨胀、性能下降等问题。
语法规则
每一行的格式为:
文件匹配模式 处理规则
其中,处理规则 由多个键值对组成,常见键包括:
filter=lfs:使用 Git LFS 过滤和存储文件diff=lfs:比较文件时使用 LFS 方式(不直接比较文件内容,而是比较 LFS 指针)merge=lfs:合并文件时使用 LFS 方式(避免大文件内容冲突)-text:标记文件为二进制文件(不进行文本转换,如换行符处理)
逐行解读
文件中列出的所有规则均围绕 “让 Git LFS 管理大文件” 设计,具体如下:
| 文件模式 | 含义 |
|---|---|
*.7z | 所有 .7z 压缩文件(如数据集压缩包) |
*.arrow | Apache Arrow 格式文件(常用于大数据存储) |
*.bin、*.bin.* | 二进制文件(如原始模型权重、二进制数据) |
*.bz2、*.gz、*.xz | 各类压缩文件(如 .tar.gz 等打包文件) |
*.ftz | 可能是特定格式的压缩/二进制文件(如模型中间文件) |
*.h5 | HDF5 格式文件(常用于存储模型权重、数据集,如 Keras 模型) |
*.joblib | joblib 序列化文件(常用于存储 Python 模型或大型数据结构) |
*.lfs.* | 明确标记为 LFS 管理的文件(可能是自定义命名的大文件) |
*.model | 模型文件(如自定义格式的模型权重) |
*.msgpack | MessagePack 格式文件(高效二进制序列化格式) |
*.onnx | ONNX 格式模型文件(跨框架模型格式) |
*.ot | 可能是特定格式的二进制文件(如某些工具生成的中间文件) |
*.parquet | Parquet 格式文件(列式存储的大数据文件) |
*.pb | Protocol Buffers 格式文件(如 TensorFlow 模型、序列化数据) |
*.pt、*.pth | PyTorch 模型权重文件(核心!如 TrOCR 的 model.safetensors 类似作用) |
*.rar、*.zip | 常见压缩文件(如数据集、代码打包文件) |
saved_model/**/* | saved_model 目录下的所有文件(如 TensorFlow 保存的完整模型目录) |
*.tar.*、*.tgz | 打包压缩文件(如 .tar.bz2、.tar.xz 等) |
*.tflite | TensorFlow Lite 模型文件(移动端轻量化模型) |
*.zstandard | Zstandard 压缩格式文件(高效压缩算法) |
*tfevents* | TensorFlow 事件文件(如训练日志,通常体积较大) |
model.safetensors | 明确指定 safetensors 格式的模型权重文件(TrOCR 的核心权重文件) |
为什么需要这些规则?
-
避免 Git 仓库膨胀:
Git 原生机制适合管理文本文件(如代码),但大文件(如几百 MB 的model.safetensors)会导致仓库体积暴增,拉取/推送速度极慢。Git LFS 将大文件内容存储在单独的服务器,本地仅保留“指针文件”(记录文件位置和哈希),大幅减小仓库体积。 -
防止二进制文件处理错误:
标记-text后,Git 会将这些文件视为二进制文件,不进行文本转换(如 Windows/Linux 换行符自动转换),避免损坏二进制内容(如模型权重错乱)。 -
优化协作体验:
使用diff=lfs和merge=lfs后,多人协作时比较或合并大文件,Git 只会处理 LFS 指针,不会尝试比较GB级的文件内容,减少冲突和性能开销。
对 TrOCR 模型仓库的意义
- TrOCR 模型包含大量大文件(如
model.safetensors通常数百 MB),必须通过 Git LFS 管理才能保证仓库可维护。 - 这些规则确保所有可能的大文件类型都被 LFS 捕获,避免因遗漏导致的仓库问题(如某人误将
*.pth模型文件用 Git 原生方式提交,导致仓库体积骤增)。
总结:这份 .gitattributes 是 TrOCR 模型仓库的“大文件管理规则”,通过 Git LFS 高效处理模型权重、数据集等大文件,保证仓库的轻量性和协作效率。使用该仓库时,需先安装 Git LFS 并执行 git lfs install,否则可能无法正确拉取大文件内容。