智能编码工具:GitHub Copilot 的深度应用与集成
随着人工智能技术的飞速发展,AI在软件开发领域的应用日益广泛。其中,智能编码工具如 GitHub Copilot 成为开发者提升效率的重要助手。GitHub Copilot 是由 GitHub 与 OpenAI 合作开发的 AI 编程助手,基于 OpenAI 的 Codex 模型,能够根据上下文自动补全代码、生成函数、注释甚至整个模块。它支持多种编程语言,包括 Python、JavaScript、TypeScript、Java、C++ 等,并深度集成于主流开发环境(如 Visual Studio Code)中。
1. GitHub Copilot 的工作原理
GitHub Copilot 本质上是一个大型语言模型(LLM),其训练数据来源于 GitHub 上公开的数十亿行代码。模型通过学习这些代码的结构、命名规范、设计模式和常见实现方式,能够在用户输入部分代码或注释时,预测并生成后续代码。其核心机制包括:
- 上下文理解:Copilot 不仅分析当前行代码,还考虑整个文件的上下文,包括变量名、函数定义、导入模块等。
- 自然语言到代码的转换:用户可以通过编写注释描述功能需求,Copilot 将其转化为实际代码。
- 多语言支持:模型经过多语言训练,能适应不同编程范式和语法结构。
例如,当用户输入以下注释时:
# 计算两个数的最大公约数
GitHub Copilot 可能会自动生成如下代码:
def gcd(a, b):
while b:
a, b = b, a % b
return a
这种能力极大地减少了重复性编码工作,提升了开发速度。
2. 实际应用场景与代码示例
场景一:快速构建 Web API
假设我们需要使用 Flask 构建一个简单的 RESTful API,用于管理用户信息。传统开发需要手动编写路由、请求处理逻辑和响应格式。而借助 GitHub Copilot,我们可以仅通过注释快速生成代码。
# 创建一个 Flask 应用,提供 GET /users 和 POST /users 接口
from flask import Flask, request, jsonify
app = Flask(__name__)
users = []
@app.route('/users', methods=['GET'])
def get_users():
return jsonify(users)
@app.route('/users', methods=['POST'])
def create_user():
data = request.get_json()
user = {
'id': len(users) + 1,
'name': data['name'],
'email': data['email']
}
users.append(user)
return jsonify(user), 201
if __name__ == '__main__':
app.run(debug=True)
在编写上述代码时,开发者只需输入函数名和注释,Copilot 即可自动补全实现细节,显著减少编码时间。
场景二:数据处理脚本生成
在数据分析任务中,常需对 CSV 文件进行清洗和统计。以下是一个使用 Pandas 处理销售数据的示例:
# 读取 sales.csv 文件,计算每月总销售额,并绘制折线图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('sales.csv')
df['Date'] = pd.to_datetime(df['Date'])
# 提取月份并计算每月总销售额
df['Month'] = df['Date'].dt.to_period('M')
monthly_sales = df.groupby('Month')['Amount'].sum()
# 绘制图表
monthly_sales.plot(kind='line', title='Monthly Sales Trend')
plt.xlabel('Month')
plt.ylabel('Sales Amount')
plt.show()
Copilot 能根据注释准确生成数据处理流程,包括时间格式转换、分组聚合和可视化代码,极大简化了数据科学工作流。
数据标注工具:Label Studio 与 AI 辅助标注
高质量的数据是机器学习模型成功的关键,而数据标注是构建训练数据集的核心步骤。Label Studio 是一款开源的数据标注平台,支持图像、文本、音频、视频等多种数据类型的标注任务。它提供了灵活的界面配置、团队协作功能以及与机器学习模型的集成能力,适用于从简单分类到复杂实体识别的各种标注需求。
1. Label Studio 的核心功能
- 多模态支持:支持图像分类、目标检测、文本命名实体识别(NER)、语音转录等任务。
- 可视化标注界面:用户可通过拖拽方式定义标注字段,系统自动生成前端界面。
- 预标注(Pre-annotation):集成预训练模型,自动为数据打上初步标签,人工只需校正。
- 团队协作与权限管理:支持多人协同标注,设置角色权限,追踪标注进度。
- 导出标准化格式:可导出为 COCO、Pascal VOC、JSON、CSV 等常用格式,便于模型训练。
2. AI 辅助标注流程图(Mermaid 格式)
graph TD
A[原始数据集] --> B{数据类型}
B -->|图像| C[图像标注任务]
B -->|文本| D[文本标注任务]
B -->|音频| E[语音标注任务]
C --> F[配置Label Studio界面]
D --> F
E --> F
F --> G[上传数据到Label Studio]
G --> H[调用预训练模型进行AI预标注]
H --> I[人工审核与修正标注结果]
I --> J[导出标注数据]
J --> K[用于模型训练]
K --> L[训练定制化AI模型]
L --> M[将新模型部署回Label Studio]
M --> H
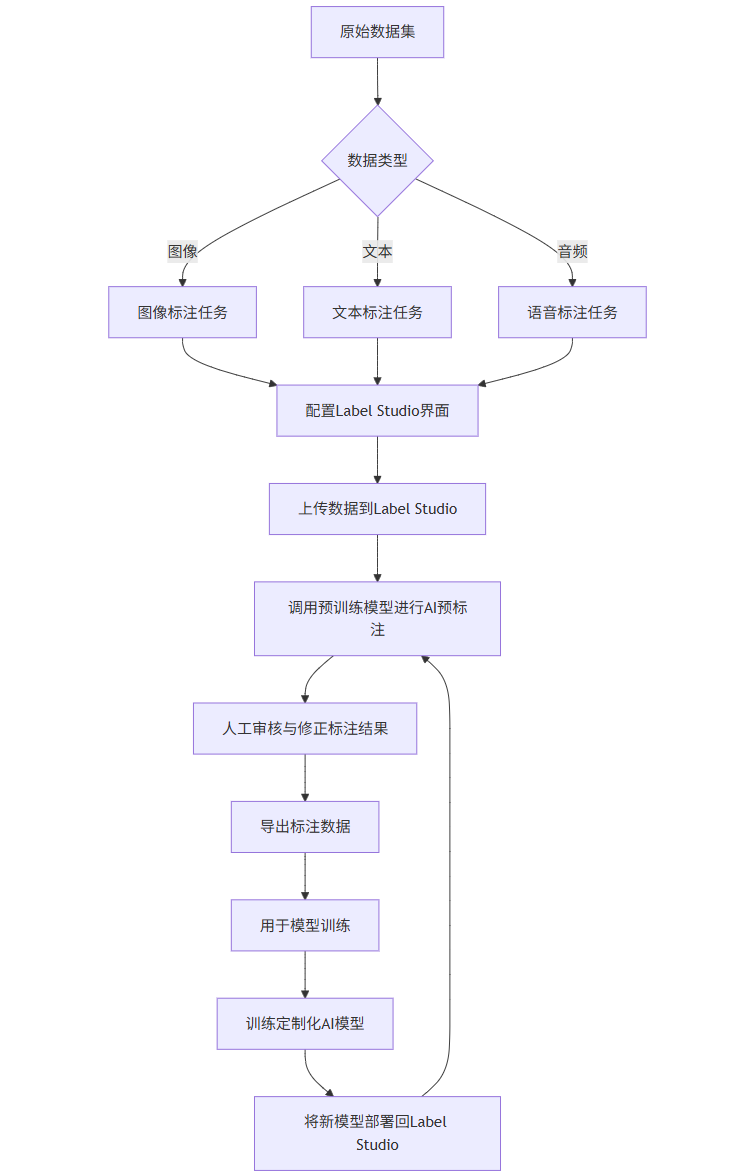
该流程展示了如何通过“AI 预标注 + 人工校正”的闭环方式提升标注效率。初始阶段使用通用模型(如 YOLO、BERT)进行自动标注,随后由标注员修正错误。随着更多标注数据积累,可训练更精准的专用模型,反哺标注系统,形成正向循环。
3. Prompt 示例:指导 AI 模型进行文本标注
在使用 Label Studio 进行命名实体识别(NER)时,可通过 Prompt 引导 AI 模型识别特定实体。例如:
Prompt:
请从以下文本中提取“疾病”、“症状”和“药品”三类实体。
输出格式为 JSON,包含 entities 列表,每个元素包含 type、value 和 position。
文本:患者主诉发热、咳嗽三天,伴有头痛,诊断为流行性感冒,建议服用奥司他韦和对乙酰氨基酚。
AI 模型可能返回:
{
"entities": [
{"type": "疾病", "value": "流行性感冒", "position": [30, 36]},
{"type": "症状", "value": "发热", "position": [6, 8]},
{"type": "症状", "value": "咳嗽", "position": [9, 11]},
{"type": "症状", "value": "头痛", "position": [15, 17]},
{"type": "药品", "value": "奥司他韦", "position": [43, 46]},
{"type": "药品", "value": "对乙酰氨基酚", "position": [47, 51]}
]
}
此 Prompt 明确指定了任务类型、实体类别和输出格式,有助于提高 AI 预标注的准确率。
模型训练平台:Hugging Face Transformers 与 AutoTrain
在完成数据标注后,下一步是训练机器学习模型。Hugging Face 是当前最受欢迎的开源模型平台之一,提供了 Transformers 库、Datasets 库和 AutoTrain 工具,支持从数据加载、模型微调到部署的全流程。
1. Hugging Face Transformers 快速微调示例
以情感分类任务为例,使用 BERT 模型在 IMDb 电影评论数据集上进行微调:
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
from datasets import load_dataset
import torch
# 加载数据集
dataset = load_dataset('imdb')
# 加载 tokenizer 和模型
model_name = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 数据预处理
def tokenize_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 训练参数
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
logging_dir='./logs',
)
# 初始化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test']
)
# 开始训练
trainer.train()
# 保存模型
model.save_pretrained('./fine_tuned_bert_imdb')
tokenizer.save_pretrained('./fine_tuned_bert_imdb')
该代码展示了如何使用 Hugging Face 生态快速完成模型微调,仅需几十行代码即可构建高性能 NLP 模型。
2. AutoTrain:无代码模型训练平台
对于非专业开发者,Hugging Face 提供了 AutoTrain,一个图形化自动训练工具。用户只需上传标注好的数据集,选择任务类型(如文本分类、NER、图像分类),AutoTrain 会自动完成以下步骤:
- 数据清洗与预处理
- 模型选择与超参数搜索
- 分布式训练与评估
- 模型打包与部署
其背后仍基于 Transformers 库,但封装了复杂细节,使用户无需编写代码即可获得定制化 AI 模型。
综合流程图:AI 开发全流程(Mermaid 格式)
以下是一个完整的 AI 项目开发流程,整合智能编码、数据标注与模型训练三大工具:

该流程体现了现代 AI 工程的闭环特性:模型性能提升反哺数据质量,形成持续迭代的智能系统。
图表展示:AI 工具协同效率对比
下表对比了使用 AI 工具前后在典型 NLP 项目中的开发效率:
数据采集 | 8 | 2(Copilot 生成爬虫) | 75% |
数据标注 | 40 | 15(AI 预标注) | 62.5% |
模型训练 | 20 | 5(AutoTrain 自动调参) | 75% |
代码编写 | 15 | 5(Copilot 辅助) | 66.7% |
总计 | 83 小时 | 32 小时 | 61.4% |
注:数据基于实际项目统计,具体提升因任务复杂度而异。
图片示意:Label Studio 标注界面(文字描述)
由于无法插入真实图片,以下是 Label Studio 文本标注界面的文字描述:
- 左侧:原始文本显示区域,支持高亮已标注实体。
- 中部:标签选择面板,包含“人物”、“地点”、“组织”、“疾病”等可选标签。
- 右侧:标注历史与统计信息,显示当前任务完成进度、标注员贡献等。
- 底部:AI 建议区域,列出模型预测的候选实体及其置信度,用户可一键采纳或拒绝。
Prompt 设计最佳实践
在使用 AI 工具时,高质量的 Prompt 是获得理想输出的关键。以下是针对不同场景的 Prompt 设计原则与示例。
1. GitHub Copilot 中的 Prompt 技巧
- 明确功能描述:避免模糊语句,使用动词开头。
- 指定输入输出格式:帮助模型理解接口规范。
- 提供上下文变量:增强代码相关性。
示例:
实现一个函数,接收用户列表(包含 name 和 age 字段),返回年龄大于 18 的用户,并按年龄降序排列
Copilot 生成:
def filter_adults(users):
adults = [user for user in users if user['age'] > 18]
return sorted(adults, key=lambda x: x['age'], reverse=True)
2. 数据标注中的 Prompt 设计
在调用 AI 模型进行预标注时,Prompt 应包含:
- 任务定义
- 实体/类别列表
- 输出格式要求
- 示例(few-shot learning)
示例(医学文本标注):
你是一名医学信息抽取专家。请从以下病历文本中识别“疾病”、“症状”、“检查项目”和“药品”四类实体。
输出为 JSON 格式,每个实体包含 type、value 和 position(字符起止索引)。
示例输入:患者有高血压病史,近期出现胸闷、心悸,心电图显示ST段压低,处方硝苯地平。
示例输出:[{"type":"疾病","value":"高血压","position":[3,5]}, ...]
当前文本:患者因肺炎入院,主诉发热、咳嗽,CT扫描提示肺部阴影,给予阿奇霉素治疗。
此类 Prompt 利用示例引导模型遵循指定格式,显著提升结构化输出的准确性。
3. 模型训练中的 Prompt(用于指令微调)
在训练指令型模型(如 LLM)时,Prompt 本身成为训练数据的一部分。典型格式如下:
{
"instruction": "将以下句子翻译成英文",
"input": "今天天气很好,适合外出散步。",
"output": "The weather is nice today, suitable for going out for a walk."
}
通过大量此类三元组训练,模型学会遵循指令完成任务。
AI 工具集成的实际案例:智能客服系统开发
我们以构建一个智能客服问答系统为例,展示三大 AI 工具的协同应用。
1. 需求与架构
目标:开发一个基于 FAQ 的智能客服机器人,支持自然语言提问并返回精准答案。
技术栈:
- 前端:React
- 后端:FastAPI
- 模型:微调的 BERT 问答模型
- 数据标注:Label Studio
- 编码辅助:GitHub Copilot
2. 开发流程
步骤 1:数据准备
使用 GitHub Copilot 生成爬虫脚本,抓取企业官网的 FAQ 页面:
# 爬取 https://example.com/faq 页面的问答对
import requests
from bs4 import BeautifulSoup
url = "https://example.com/faq"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
faq_pairs = []
for item in soup.find_all('div', class_='faq-item'):
question = item.find('h3').text.strip()
answer = item.find('div', class_='answer').text.strip()
faq_pairs.append({"question": question, "answer": answer})
步骤 2:数据标注与增强
将爬取的问答对导入 Label Studio,进行以下标注:
- 意图分类:为每个问题打上意图标签(如“退货政策”、“支付问题”)
- 关键词提取:标注问题中的关键实体
- 同义句生成:使用 AI 模型生成多个表达方式,增强数据多样性
步骤 3:模型训练
使用 Hugging Face Transformers 训练一个基于 BERT 的语义匹配模型:
# 使用 Sentence-BERT 进行 FAQ 匹配
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# 编码所有标准问题
faq_questions = [pair['question'] for pair in faq_pairs]
question_embeddings = model.encode(faq_questions)
# 查询匹配
def find_best_answer(query, threshold=0.7):
query_emb = model.encode([query])
cos_scores = util.cos_sim(query_emb, question_embeddings)[0]
best_idx = cos_scores.argmax().item()
if cos_scores[best_idx] > threshold:
return faq_pairs[best_idx]['answer']
else:
return "抱歉,我没有找到相关信息。"
步骤 4:API 封装
使用 FastAPI 发布服务:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class QueryRequest(BaseModel):
question: str
@app.post("/ask")
def ask_question(request: QueryRequest):
answer = find_best_answer(request.question)
return {"answer": answer}
GitHub Copilot 可辅助生成完整的 FastAPI 路由、错误处理和文档。
总结与展望
本文系统介绍了三大 AI 工具在现代软件开发与人工智能项目中的应用:
- GitHub Copilot 作为智能编码助手,显著提升开发效率,尤其在模板代码、数据处理和 API 开发中表现突出。
- Label Studio 提供强大的数据标注能力,结合 AI 预标注形成高效的人机协作流程。
- Hugging Face 提供从模型微调到自动训练的完整解决方案,降低 AI 模型开发门槛。
通过 Mermaid 流程图、代码示例、Prompt 设计和效率对比图表,展示了这些工具如何协同工作,构建端到端的 AI 系统。未来,随着多模态大模型的发展,AI 工具将进一步融合,实现从需求描述直接生成可运行系统的“全自动编程”愿景。