(CVPR-2025)通过频率分解实现身份保持的文本到视频生成
通过频率分解实现身份保持的文本到视频生成
paper是PKU发表在CVPR 2025的工作
paper title:Identity-Preserving Text-to-Video Generation by Frequency Decomposition
Code:链接
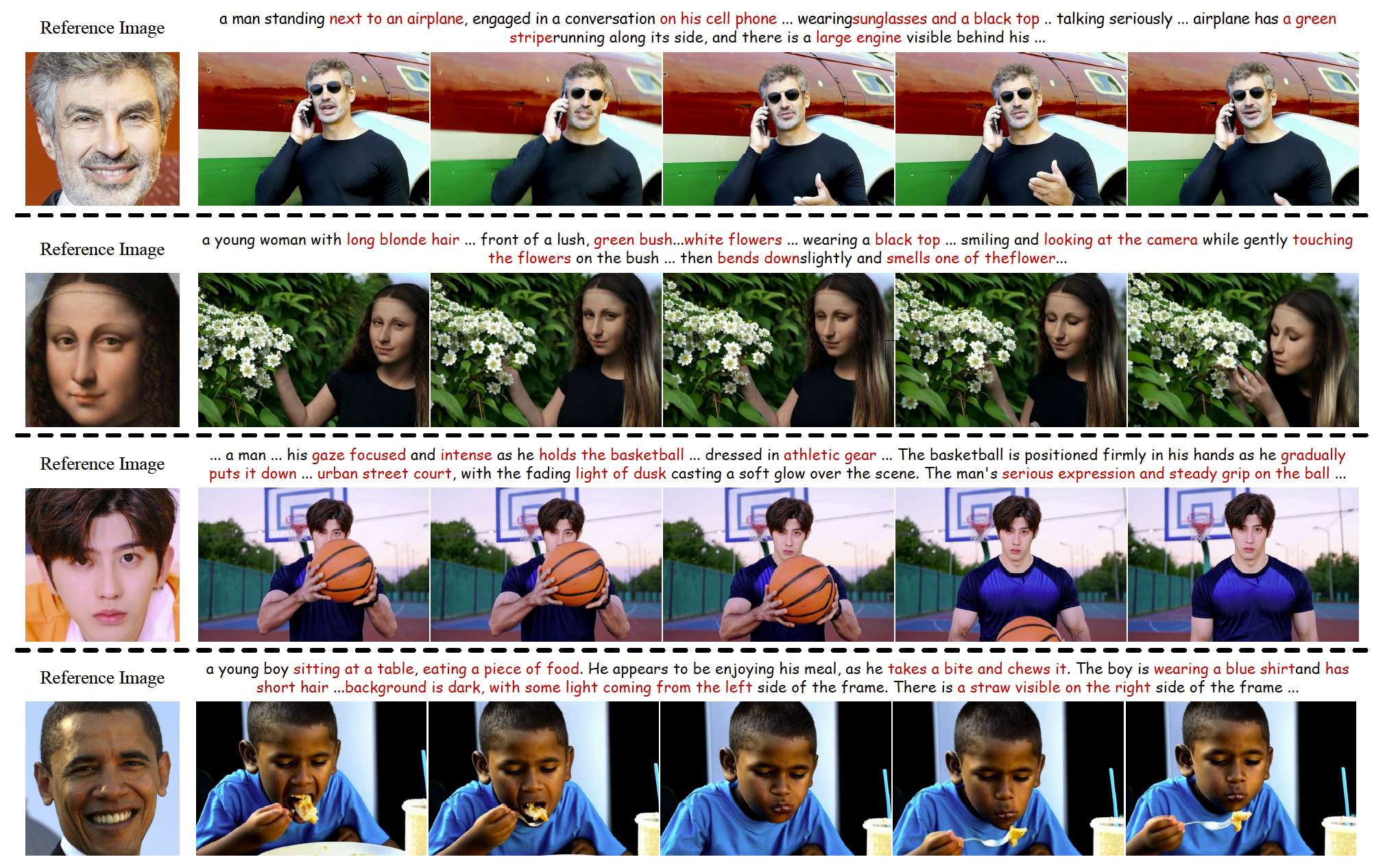
图1. 我们的 ConsisID 方法在身份保持视频生成 (IPT2V) 中的示例。给定一张参考图像,我们的方法能够生成逼真且个性化的人物中心视频,同时保持身份一致性。红色表示长指令中的属性。
Abstract
身份保持文本生成视频 (IPT2V) 的目标是生成具有一致人类身份的高保真视频。这是视频生成中的一项重要任务,但对生成模型来说仍是一个未解决的问题。本文在两个文献中尚未解决的方向上推动了 IPT2V 的技术前沿:(1) 一个无需繁琐逐案微调的无调优流程,(2) 一个基于频率感知启发式的身份保持 Diffusion Transformer (DiT) 控制方案。为实现这些目标,我们提出 ConsisID,一个无需调优的基于 DiT 的可控 IPT2V 模型,用于保持生成视频中的人类身份一致性。受视觉/扩散 Transformer 频率分析的相关研究启发,该方法基于频域采用身份控制信号,因为面部特征可以分解为低频的全局特征(例如轮廓、比例)和高频的内在特征(例如不受姿态变化影响的身份标记)。大量实验表明,我们的频率感知启发式方案为基于 DiT 的模型提供了一种最优控制解决方案,推动了更高效 IPT2V 的实现。
1. Introduction
大规模预训练视频扩散模型 [37, 83, 96, 97] 推动了多种下游应用 [60, 65, 86, 87, 89, 91],特别是在身份保持文本生成视频 (IPT2V) [10, 46, 70, 72, 73] 方面。然而,现有方法面临重大挑战,尤其是需要逐案微调所带来的高开销,这削弱了其实用性。在开源社区中,只有 ID-Animator [19] 可以实现无调优的 IPT2V,但它仅能生成类似说话人头像 [69] 的视频,并且身份保持效果较差。
此外,上述方法大多基于 U-Net,无法适配新兴的基于 DiT 的视频模型 [37, 76, 83, 96, 97]。这一挑战可能源于 DiT 相比 U-Net 的固有局限性,包括训练收敛难度更大以及在感知面部细节方面的不足。从已有的视觉/扩散 Transformer 频率分析研究 [3–5, 53, 61, 66, 88] 中可以得出以下结论:
- 发现1:浅层(例如低级、低频)特征对扩散模型中的像素级预测任务至关重要,因为它们有助于模型训练。U-Net 通过长跳跃连接将浅层特征聚合到解码器,从而促进了模型收敛,而 DiT 并未采用这一机制;
- 发现2:Transformer 在感知高频信息方面有限,而高频信息对保持面部特征至关重要。U-Net 的编码器-解码器结构天然具备多尺度特征(例如高频信息的丰富性),而 DiT 缺乏类似结构。
因此,要开发基于 DiT 的控制模型,必须首先解决这些问题。详见附录。
对于身份保持视频生成,挑战在于每一帧都必须结合来自参考图像的高频信息(例如与年龄和妆容无关的身份标记)和低频信息(例如面部形状),这恰好可以用来弥补上述 DiT 的缺陷。因此,我们提出 ConsisID,通过频率分解在视频生成中保持身份一致性,基于前述 DiT 的频率分析发现。得益于大规模预训练 DiT,我们能够利用其强大能力实现无调优效果。
ConsisID 将身份特征解耦为高频和低频信号,并注入 DiT 内的特定位置,从而促进高效的 IPT2V 生成。具体而言,遵循发现1,我们首先将参考图像和面部关键点转换为低频信号,然后将其与输入噪声潜变量拼接,以缓解训练难度。遵循发现2,我们利用双塔特征提取器捕获高频面部信息,并将其与 Transformer 块中的视觉 token 融合,从而增强 DiT 的高频感知能力。最后,为了将预训练模型转化为 IPT2V 模型并提升其泛化能力,我们进一步引入分层训练策略。
我们的贡献总结如下:
- 我们提出 ConsisID,一个无需调优的基于 DiT 的身份保持 IPT2V 模型,它通过频率分解得到的控制信号来保持视频主体的身份一致性。
- 我们提出了一种分层训练策略,包括由粗到细的训练、动态掩码损失和动态跨人脸损失,这些方法协同作用以促进训练并有效提升泛化能力。
- 大量实验表明,我们的 ConsisID 可以生成高质量、可编辑且身份一致性良好的视频,这得益于我们的频率感知身份保持 T2V DiT 控制方案。
2. Related Work
基于调优的身份保持 T2V 模型。扩散模型因其强大的生成能力 [23, 42–45, 52, 89, 90] 而广受认可,极大推动了身份保持生成模型的发展 [11, 47, 71, 91]。最初,研究人员使用基于调优的方法来生成与输入 ID 匹配的内容。这一过程需要在推理阶段为每个新的人进行预训练模型的微调。例如,DreamBooth [57] 引入了一种新的损失函数,对整个网络进行微调,在嵌入身份信息的同时保持原有的生成能力。LoRA [25] 与 DreamBooth [57] 类似,只需训练一小部分网络参数。相比之下,Textual Inversion [15] 冻结了预训练网络,并将身份信息嵌入到一个可训练的词嵌入中。后续基于调优的方法,包括基于 U-Net 或 DiT 架构的图像和视频模型 [10, 33, 58, 70, 72, 73, 75, 82, 95],一般遵循三种主要途径。尽管这些模型展现出了显著的有效性,但由于需要针对每个新身份进行微调,限制了其实用性。
无调优的身份保持 T2V 模型。为了解决高资源消耗的问题,近年来在图像生成领域出现了多种无调优扩散模型 [17, 18, 36, 68, 84]。这些模型在推理阶段无需针对新引入的 ID 微调参数。例如,IP-Adapter [84] 通过跨注意力机制利用身份图像的 CLIP [51] 特征来引导预训练模型生成身份保持图像。InstantID [68] 在此基础上,用 Arcface [13] 特征替换 CLIP [51] 特征,并结合姿态网络来调整面部比例。与这些通过视觉 token 引入控制信号的初始方法不同,PhotoMaker [36] 和 Imagine Yourself [20] 利用文本 token。具体而言,PhotoMaker [36] 将从 CLIP 编码器 [51] 获取的身份特征与文本嵌入拼接,而 Imagine Yourself [20] 则采用逐元素相加的方式进行特征融合。在视频生成领域,目前仅有 MovieGen [50] 和 ID-Animator [19] 支持身份保持文本生成视频 (IPT2V)。MovieGen 是闭源的,而 ID-Animator 是开源的,但采用了与图像模型类似的方法,导致生成视频的身份保持质量较差。我们选择新兴的 DiT 架构 [37, 41, 83, 96] 并针对 IPT2V 进行优化,借鉴了先前频率分析的结论 [3–5, 53, 61, 66]。这使得高质量、可编辑且身份一致的 IPT2V 生成成为可能。
3. Methodology
3.1. Preliminaries
扩散模型。文本到视频生成模型通常采用扩散范式,该范式逐步将噪声ϵ\epsilonϵ转化为视频x0x_{0}x0。最初,去噪直接在像素空间中进行 [24, 62, 63];然而,由于显著的计算开销,近期方法主要采用潜在空间 [16, 32, 56, 89]。优化过程定义为:
La=Ex0,t,y,ϵ[∥ϵ−ϵθ(x0,t,τθ(y))∥22],(1)\mathcal{L}_{a} = \mathbb{E}_{x_{0},t,y,\epsilon} \left[ \| \epsilon - \epsilon_{\theta}(x_{0}, t, \tau_{\theta}(y)) \|_{2}^{2} \right], \tag{1} La=Ex0,t,y,ϵ[∥ϵ−ϵθ(x0,t,τθ(y))∥22],(1)
其中yyy是文本条件,ϵ\epsilonϵ从标准正态分布中采样(例如,ϵ∼N(0,1)\epsilon \sim \mathcal{N}(0,1)ϵ∼N(0,1)),τθ(⋅)\tau_{\theta}(\cdot)τθ(⋅)是文本编码器。通过将x0x_{0}x0替换为E(x0)\mathcal{E}(x_{0})E(x0),即可得到潜在扩散,该方法被ConsisID使用。
扩散Transformer。基于DiT的视频生成模型在模拟物理世界方面显示出显著潜力 [8, 83, 97]。尽管它是一种新颖的架构,但关于可控生成的研究仍然有限,当前的方法 [12, 17, 50, 94] 在很大程度上类似于基于U-Net的方法 [15, 47, 91]。然而,目前尚无研究探讨为什么这种方法在DiT中有效。借鉴先前从频率域角度对扩散模型和Transformer的分析 [3–5, 53, 61, 66],我们得出结论:(1) 低频(例如浅层)特征对于扩散模型中的像素级预测任务至关重要,有助于促进模型训练;(2) Transformer对高频信息的感知有限,而高频信息对于可控生成非常重要。基于此,我们将身份特征解耦为高频和低频部分,并将它们注入到特定位置,从而实现了有效的身份保持型文本到视频生成。
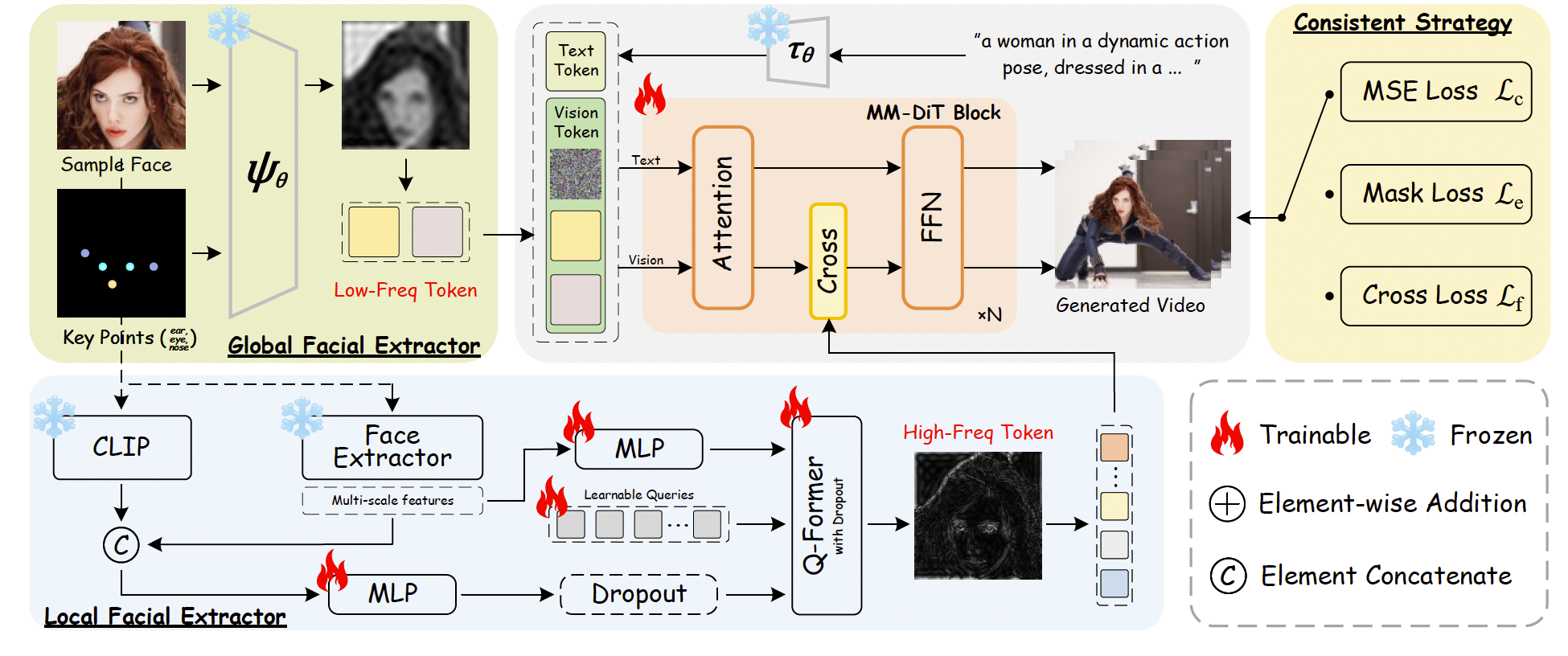
图2. 所提出的 ConsisID 的整体框架。基于 DiT 的研究结果,低频人脸信息被嵌入到浅层,而高频信息则被融合到注意力模块中的视觉 token 中。采用身份保持的训练方案(ID-preserving Recipe)以简化训练并提升泛化能力。交叉人脸、DropToken 和 Dropout 按概率执行。
3.2. ConsisID: Keep Your Identity Consistent
整体流程如图2所示。给定一张参考图像,全局人脸特征提取器和局部人脸特征提取器将高频和低频的人脸信息注入模型,随后在一致性训练策略的辅助下生成身份保持的视频。
3.2.1. Low-frequency View: Global Facial Extractor
根据 Finding 1,加强低层(例如,浅层、低频)特征能够加速模型收敛。为了让一个预训练模型更容易适配 IPT2V 任务,最直接的方法是将参考人脸与噪声输入的潜变量拼接在一起 [7]。然而,参考人脸同时包含高频细节(例如,眼睛和嘴唇纹理)以及低频信息(例如,面部比例和轮廓)。根据 Finding 2,将高频信息过早地注入 Transformer 是低效的,并且可能会妨碍模型对低频信息的处理,因为 Transformer 主要依赖低频特征。此外,将参考人脸直接输入模型可能会引入无关噪声,例如光照和阴影。为缓解这一问题,我们提取人脸关键点,将其转换为 RGB 图像,然后与参考图像拼接,如图2所示。这一策略使模型的注意力集中在面部的低频信号上,同时尽量减少无关特征的影响。我们发现,当这一组件被舍弃时,模型难以收敛。目标函数被修改为:
Lb=Ex0,t,y,f,ϵ[∥ϵ−ϵθ(x0,t,τθ(y),ψθ(f))∥22],\mathcal{L}_b = \mathbb{E}_{x_0, t, y, f, \epsilon} \left[ \lVert \epsilon - \epsilon_\theta (x_0, t, \tau_\theta (y), \psi_\theta(f)) \rVert^2_2 \right], Lb=Ex0,t,y,f,ϵ[∥ϵ−ϵθ(x0,t,τθ(y),ψθ(f))∥22],
其中 ψθ(⋅)\psi_\theta(\cdot)ψθ(⋅) 是变分自编码器,fff 表示参考图像,在此处我们为简洁起见忽略关键点。
3.2.2. High-frequency View: Local Facial Extractor
根据 Finding 2,我们认识到 Transformer 对高频信息的敏感性有限。可以得出结论,仅依赖全局人脸特征提取器不足以完成 IPT2V 生成,因为全局人脸特征缺乏高频信息。因此,我们使用一个人脸识别骨干网络 [13] 来提取高频特征,因为这些特征对非身份属性(例如表情、姿态和脸型)不敏感。我们将这些特征称为内在身份特征(即高频特征),因为年龄和妆容不会改变个体的核心身份。按照 [18],我们使用骨干网络的倒数第二层,而不是其输出层,因为这一层保留了更多与身份相关的空间信息。然而,我们的实验表明,虽然人脸识别骨干网络能够提升身份一致性,但它缺乏执行编辑所需的语义特征。本任务不仅要求保持身份一致性,还要求具备编辑能力,例如生成相同身份但具有不同年龄和妆容的视频。以往研究 [19, 20] 仅依赖 CLIP 编码器 [51] 来实现编辑能力。然而,由于 CLIP 并未在面部数据集上专门训练,其提取的特征中包含无关的非面部信息,从而可能破坏身份保真度 [36, 68, 84]。
为了解决这些问题,我们首先使用人脸识别骨干网络提取强表征内在身份的特征,同时使用 CLIP 图像编码器捕获语义丰富的特征。然后,我们采用 Q-Former [34, 35, 77] 融合这些特征,从而得到包含高频语义信息的内在身份表征。为了减轻 CLIP 带来的无关特征影响,我们在处理后施加 dropout [2, 26]。此外,我们遵循 [18],将经过插值后的浅层多尺度人脸识别特征与 CLIP 特征拼接。这样确保模型能够捕获关键的内在身份特征,同时过滤掉与身份无关的噪声。最后,我们通过交叉注意力机制,使该特征集与预训练模型的每个注意力块生成的视觉 token 进行交互,从而增强 DiT 中的高频信息:
Zi′=Zi+Attention(Qiv,Kif,Vif),Z'_i = Z_i + Attention(Q^v_i, K^f_i, V^f_i), Zi′=Zi+Attention(Qiv,Kif,Vif),
其中,iii 表示注意力块的层数,Qv=ZiWiqQ^v = Z_i W^q_iQv=ZiWiq,Kf=FWikK^f = F W^k_iKf=FWik,Vf=FWivV^f = F W^v_iVf=FWiv。这里,ZiZ_iZi 是视觉 token,FFF 表示内在身份特征,WqW_qWq、WkW_kWk 和 WvW_vWv 是可训练参数。目标函数被修改为:
Lc=Ex0,t,y,f,ϵ[∥ϵ−ϵθ(x0,t,τθ(y),ψθ(f),φθ(f))∥22],\mathcal{L}_c = \mathbb{E}_{x_0,t,y,f,\epsilon} \Big[ \| \epsilon - \epsilon_\theta(x_0, t, \tau_\theta(y), \psi_\theta(f), \varphi_\theta(f)) \|_2^2 \Big], Lc=Ex0,t,y,f,ϵ[∥ϵ−ϵθ(x0,t,τθ(y),ψθ(f),φθ(f))∥22],
其中,φθ(⋅)\varphi_\theta(\cdot)φθ(⋅) 是局部人脸特征提取器。
3.2.3. Consistency Training Strategy
在训练过程中,我们从训练帧中随机选择一帧,并应用 Crop&Align [13] 提取人脸区域作为参考图像,随后用作身份控制信号,与文本控制一起使用。
粗到细训练(Coarse-to-Fine Training) 相较于保持身份一致性的图像生成,视频生成需要在空间和时间维度上保持一致性,确保高低频人脸信息与参考图像一致。为减轻训练的复杂性,我们提出一种分层策略,即模型先全局学习信息,再进行局部精细化。在粗粒度阶段(例如,对应 Finding 1),我们使用全局人脸特征提取器,使模型优先学习低频特征,如面部轮廓和比例,从而确保快速获取参考图像中的身份信息,并保证视频序列的一致性。在细粒度阶段(例如,对应 Finding 2),局部人脸特征提取器将模型的注意力转移到高频细节,如眼睛和嘴唇的纹理细节(即内在身份特征),提升面部表情的真实感和生成面孔的整体相似度。
动态掩码损失(Dynamic Mask Loss) 我们的任务目标是确保生成视频中的人物身份与输入参考图像保持一致。然而,公式(1)考虑了整个场景,既包含高、低频的身份信息,也包含冗余的背景内容,这会引入噪声,干扰模型训练。为了解决这个问题,我们提出将模型的注意力集中在人脸区域。具体而言,我们首先从视频中提取人脸掩码,应用三线性插值将其映射到潜在空间,最后使用该掩码来约束Lc\mathcal{L}_cLc的计算:
Ld=M⊙Lc,\mathcal{L}_d = M \odot \mathcal{L}_c, Ld=M⊙Lc,
其中,MMM 表示与ϵ\epsilonϵ 形状相同的掩码。然而,如果将公式(5)用作所有训练数据的监督信号,模型在推理时可能无法生成自然的背景。为缓解这一问题,我们以概率ppp 应用公式(5),概率为α\alphaα,结果为:
Le={Ld,if p>αLc,if p≤α\mathcal{L}_e = \begin{cases} \mathcal{L}_d, & \text{if } p > \alpha \\ \mathcal{L}_c, & \text{if } p \leq \alpha \end{cases} Le={Ld,Lc,if p>αif p≤α
动态跨人脸损失(Dynamic Cross-Face Loss) 在用公式(6)训练后,我们观察到模型在推理时对于训练域中不存在的人物难以生成令人满意的结果。这个问题的出现是因为模型只在训练帧中的人脸上训练,容易过拟合,通过采用“复制-粘贴”的捷径——实质上是不加改动地复制参考图像。为了提升模型的泛化能力,我们在参考图像中引入轻微的高斯噪声ζ\zetaζ,并使用跨人脸输入(例如,参考图像来自训练帧之外的视频帧),其概率为β\betaβ:
Lf={Lewhere x0⋅ζ,if p>βLewhere xc⋅ζ,if p≤β\mathcal{L}_f = \begin{cases} \mathcal{L}_e \quad \text{where } x_0 \cdot \zeta, & \text{if } p > \beta \\ \mathcal{L}_e \quad \text{where } x_c \cdot \zeta, & \text{if } p \leq \beta \end{cases} Lf={Lewhere x0⋅ζ,Lewhere xc⋅ζ,if p>βif p≤β
其中,x0x_0x0 是从训练帧中提取的参考图像,xcx_cxc 是从训练帧外提取的。
4. Experiments
4.1. Setup
实现细节。ConsisID 选择基于 DiT 的生成架构 CogVideoX-5B [83] 作为验证的基线模型。我们使用一个内部的人体中心数据集进行训练,该数据集不同于之前仅关注人脸的数据集 [48, 69, 85]。在训练阶段,我们将分辨率设置为480×720,并从每个视频中以步长3提取连续的49帧作为训练数据。批量大小设为80,学习率设为3×10−63 \times 10^{-6}3×10−6,训练总步数为1.8k。随机丢弃文本的比例设为0.1,优化器采用AdamW,学习率调度器采用cosine_with_restarts。训练策略与第3.2.3节相同。我们将动态交叉人脸损失(Le\mathcal{L}_eLe)和动态掩码损失(Lf\mathcal{L}_fLf)中的α\alphaα和β\betaβ均设置为0.5。在推理阶段,我们使用DPM [62],采样步数为50,分类器自由引导系数为6.0。更多细节和结果请参考附录。
基准测试。由于缺乏评估数据集,我们选择了30个未包含在训练数据中的人物,并为每个ID从互联网获取了5张高质量图像。然后我们设计了90个不同的提示,涵盖多种表情、动作和背景,用于评估。在之前工作的基础上 [19, 50],我们从四个维度进行评估:(1) 身份保持:我们使用FaceSim-Arc [13]并引入FaceSim-Cur,通过测量生成视频中的人脸区域与真实人脸图像在人脸特征空间(ArcFace [13]和CurricularFace [27])中的特征差异来评估身份保持。(2) 视觉质量:我们利用FID [22],通过计算生成帧与真实人脸图像在人脸区域内的特征差异(InceptionV3 [64]特征空间)来衡量。(3) 文本相关性:我们使用CLIPScore [21]来测量生成视频与输入提示之间的相似度。(4) 动作幅度:由于缺乏可靠的度量标准 [29, 90],我们通过用户研究进行评估。