AI论文速读 | 多模态能否助力时间序列预测?时序预测中融合文本的边界与条件
论文标题:Does Multimodality Lead to Better Time Series Forecasting?
作者: Xiyuan Zhang, Boran Han, Haoyang Fang, Abdul Fatir Ansari, Shuai Zhang, Danielle C. Maddix, Cuixiong Hu, Andrew Gordon Wilson, Michael W. Mahoney, Hao Wang, Yan Liu, Huzefa Rangwala, George Karypis, Bernie Wang
机构:亚马逊AWS(Amazon Web Services)
论文链接:https://arxiv.org/abs/2506.21611
Cool Paper:https://papers.cool/arxiv/2506.21611
代码:https://github.com/AdityaLab/MM-TSFlib
TL;DR:针对“文本能否及何时提升时间序列预测”这一悬而未决的问题,作者设计涵盖14个数据集、对齐与提示两大范式的系统基准,发现多模态并非万能:仅当文本提供独有信号、时间序列模型较弱、文本/对齐策略匹配且数据充足时才显著优于单模态,并给出可操作的建模与数据指导。
关键词:多模态时间序列预测,文本融合,模型容量,对齐策略,数据特性

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
最近,将文本信息融入基础模型以进行时间序列预测的研究日益受到关注。然而,目前尚不清楚这种多模态融合是否以及在何种条件下能够持续带来收益。本文在涵盖健康、环境和经济等7个领域的14个预测任务的多样化基准测试中,系统地研究了这些问题。本文评估了两种流行的多模态预测范式:基于对齐的方法,即对齐时间序列和文本表示;以及基于提示的方法,即直接向大语言模型发出预测提示。尽管先前的研究报告了多模态输入带来的收益,但本文发现这些效果并非在所有数据集和模型中都普遍存在,多模态方法有时并不优于最强的单模态基线。为了了解文本信息何时发挥作用,本文对模型架构属性和数据特征的影响进行了拆解。本文的研究结果表明,在建模方面,当满足以下条件时,融入文本信息最为有效:(1)高容量文本模型;(2)相对较弱的时间序列模型;(3)合适的对齐策略。在数据方面,当满足以下条件时,更有可能实现性能提升:(4)有足够的训练数据;(5)文本提供了仅从时间序列中无法获得的补充预测信号。本文的实证研究结果为预测任务何时可以期望多模态方法提供帮助,以及何时不能提供帮助,提供了实用的指导方针。

Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是:在时间序列预测中,将文本信息与时间序列数据相结合(即多模态时间序列预测,Multimodal Time Series Forecasting, MMTS)是否真的能够提高预测性能,以及在什么条件下这种多模态方法能够发挥作用。
具体来说,论文主要关注以下几个方面:
- 多模态方法的有效性:系统地研究多模态方法是否在各种情况下都能提升预测性能,还是仅在特定条件下有效。
- 模型架构的影响:探讨文本编码器和时间序列模型的容量如何影响多模态预测的性能。
- 数据特性的影响:分析数据集的大小、文本和时间序列的对齐质量等因素对多模态方法性能的影响。
通过这些研究,论文旨在为未来在时间序列预测中是否以及如何使用多模态方法提供实际指导。
Q: 有哪些相关研究?
A: 论文中提到了多个与多模态时间序列预测(Multimodal Time Series Forecasting, MMTS)相关的研究,这些研究主要集中在两个主要的建模范式:基于对齐的方法(aligning-based methods)和基于提示的方法(prompting-based methods)。以下是一些关键的相关研究:
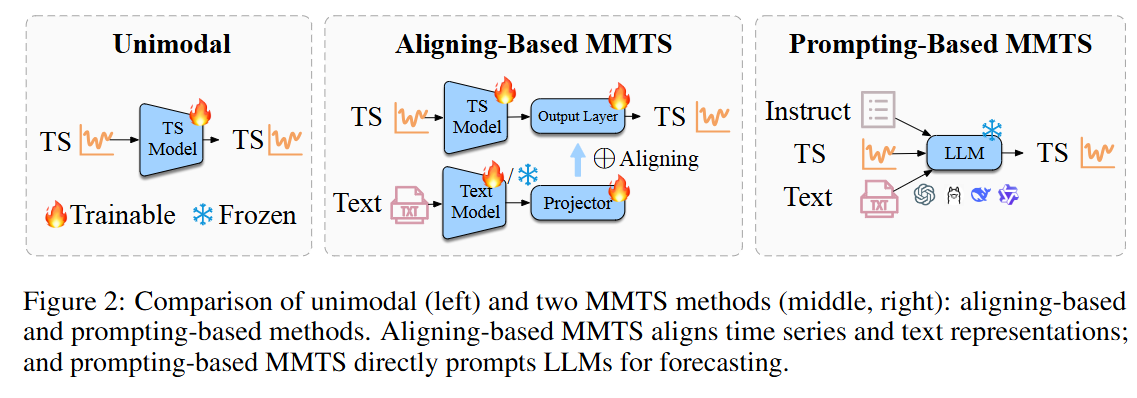
基于对齐的方法(Aligning-Based Methods)
- GPT4MTS [9]:将BERT文本嵌入作为可训练的软提示,与时间序列输入序列融合。
- Time-LLM [11]:通过重新编程大型语言模型(LLMs),将时间序列嵌入与文本表示对齐。
- AutoTimes [16]:将时间序列映射到语言标记的嵌入空间,并自回归地生成未来值。
- TEST [26]:基于实例、特征和文本原型对齐的对比目标,将时间序列表示空间与冻结的LLM对齐。
- UniTime [14]:学习将不同的时间序列输入投影到与语言模型共享的统一潜在空间中,以实现跨域泛化。
- S2IP-LLM [20]:从预训练的标记嵌入中推导出语义锚点,并通过余弦相似性将它们与时间序列表示对齐。
- MM-TSFlib [13]:探索不同文本和时间序列编码器的组合,以统一的基准进行评估。
- Hybrid-MMF [12]:使用共享的嵌入空间联合预测未来的时间序列和文本。
基于提示的方法(Prompting-Based Methods)
- PromptCast [30]:展示LLMs可以用于时间序列预测,通过精心设计的提示产生数值输出。
- LLMTime [8]:展示像GPT-3和LLaMA-2这样的模型可以在零样本设置中外推时间序列,达到与特定任务模型相当或更好的性能。
- LLM Processes [24]:从LLMs中引出数值预测分布,超越了一维时间序列预测,扩展到多维回归和密度估计。
- Context is Key [29]:展示直接提示LLM在包含预测信号的多样化文本上下文中表现更好。
这些研究为多模态时间序列预测提供了不同的方法和视角,但论文指出,尽管这些研究报告了从辅助文本中获得的收益,但这些效果并非在所有数据集和模型上都是普遍存在的。论文通过广泛的基准测试,挑战了多模态信息固有地提高预测准确性的传统观点。
Q: 论文如何解决这个问题?
A: 论文通过以下方法系统地研究了多模态时间序列预测(MMTS)的有效性,并探讨了在何种条件下多模态方法能够提升预测性能:
1. 基准测试
- 数据集选择:论文选择了14个真实世界的数据集,覆盖了7个不同的领域(如健康、环境、能源和经济等)。这些数据集包括动态文本设置(每时间步都有文本输入)和静态文本设置(整个时间序列关联一个文本描述)。
- 评估指标:使用均方误差(MSE)和平均绝对误差(MAE)评估点预测性能;对于能够进行概率预测的模型,还报告了加权分位数损失(WQL)和连续排序概率分数(CRPS)。
2. 建模范式
- 对齐方法(Aligning-Based Methods):将时间序列和文本表示对齐,通过联合编码时间序列和文本信息来预测未来值。论文评估了多种时间序列模型(如PatchTST、DLinear、FEDformer、Informer、iTransformer、Chronos)与不同文本模型(如BERT、GPT-2、T5、Qwen-1.5B、LLaMA-7B)的组合。
- 提示方法(Prompting-Based Methods):直接利用预训练的大型语言模型(LLMs),通过自然语言提示格式化时间序列和文本输入,依赖LLMs的推理能力生成预测。论文评估了多种LLMs(如LLaMA、Qwen、Mistral、GPT-4o-mini、Claude 1)。
Q: 论文做了哪些实验?
A: 论文进行了广泛的实验,以系统地评估多模态时间序列预测(MMTS)方法的有效性。以下是实验的主要内容和设计:
1. 基准测试
- 数据集选择:选择了14个真实世界的数据集,覆盖7个不同的领域,包括健康、环境、能源、经济等。这些数据集包括动态文本设置(每时间步都有文本输入)和静态文本设置(整个时间序列关联一个文本描述)。
- 评估指标:使用均方误差(MSE)和平均绝对误差(MAE)评估点预测性能;对于能够进行概率预测的模型,还报告了加权分位数损失(WQL)和连续排序概率分数(CRPS)。
2. 建模范式
- 对齐方法(Aligning-Based Methods):评估了多种时间序列模型(如PatchTST、DLinear、FEDformer、Informer、iTransformer、Chronos)与不同文本模型(如BERT、GPT-2、T5、Qwen-1.5B、LLaMA-7B)的组合。
- 提示方法(Prompting-Based Methods):评估了多种LLMs(如LLaMA、Qwen、Mistral、GPT-4o-mini、Claude 1)。
3. 实验设计
- 模型性能对比:将多模态模型(对齐方法和提示方法)与单模态模型(仅使用时间序列数据)进行对比,评估多模态方法是否一致优于单模态方法。
- 关键因素分析:
- 文本模型容量:研究不同容量的文本模型对多模态预测性能的影响。
- 时间序列模型容量:研究不同容量的时间序列模型对多模态预测性能的影响。
- 对齐策略:研究不同的对齐策略(如加法、拼接、投影等)对多模态预测性能的影响。
- 数据集大小:研究训练数据量对多模态预测性能的影响。
- 文本和时间序列的对齐质量:通过合成数据集和真实数据集,研究文本信息与时间序列的对齐质量对多模态预测性能的影响。
4. 具体实验
- 多模态方法的有效性(RQ1):
- 实验结果:在14个数据集中,单模态模型在6个数据集上根据MSE表现最佳,在7个数据集上根据MAE表现最佳。这表明多模态方法并不总是优于单模态方法。

- 文本模型容量的影响(RQ2):
- 实验结果:对于提示方法,较大的LLMs(如LLaMA-405B、Qwen-32B)在某些数据集上表现更好,但与最强的单模态模型相比仍有差距。对于对齐方法,文本模型的容量对预测性能的影响较小。
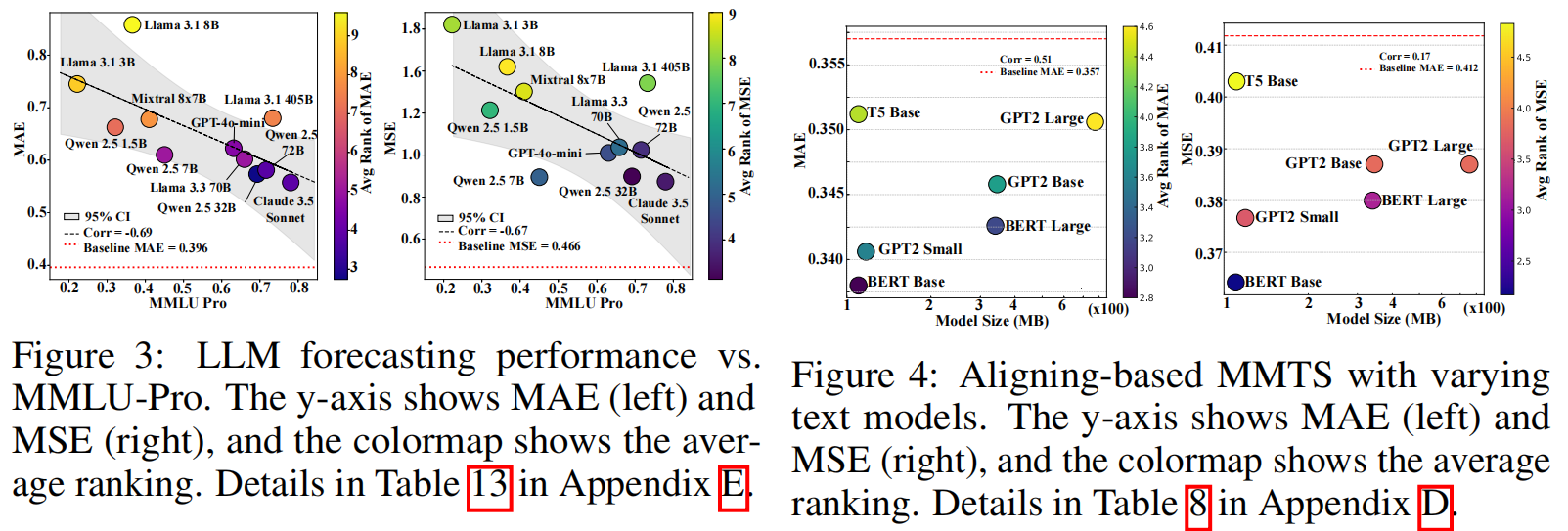
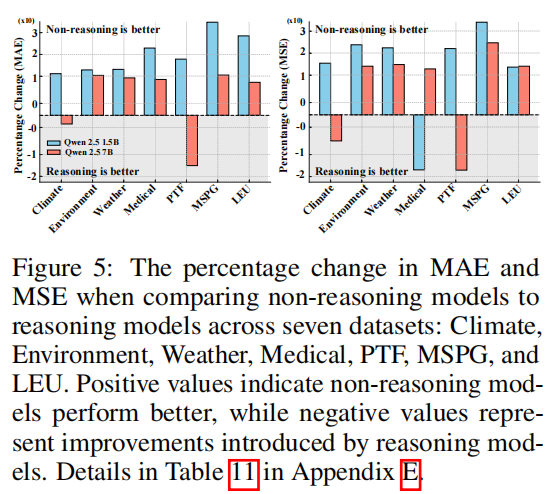
- 时间序列模型容量的影响(RQ3):
- 实验结果:较弱的时间序列模型从文本信息中受益更多,而较强的单模态时间序列模型(如Chronos)在多模态设置中提升有限。
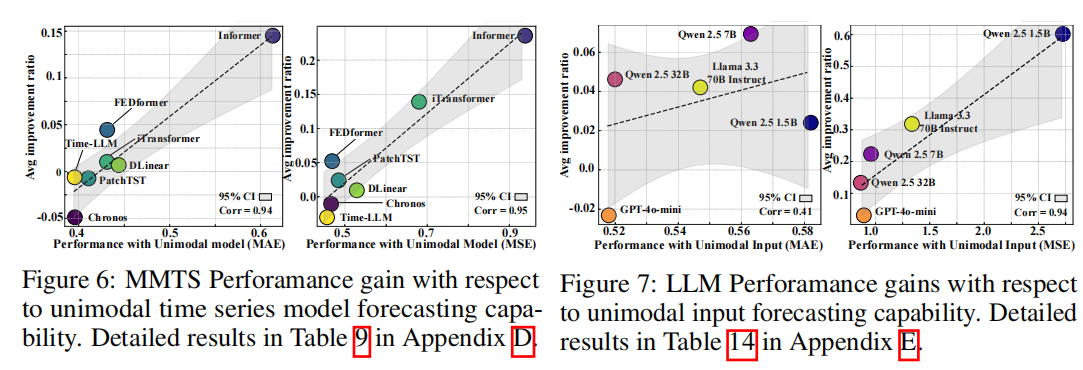
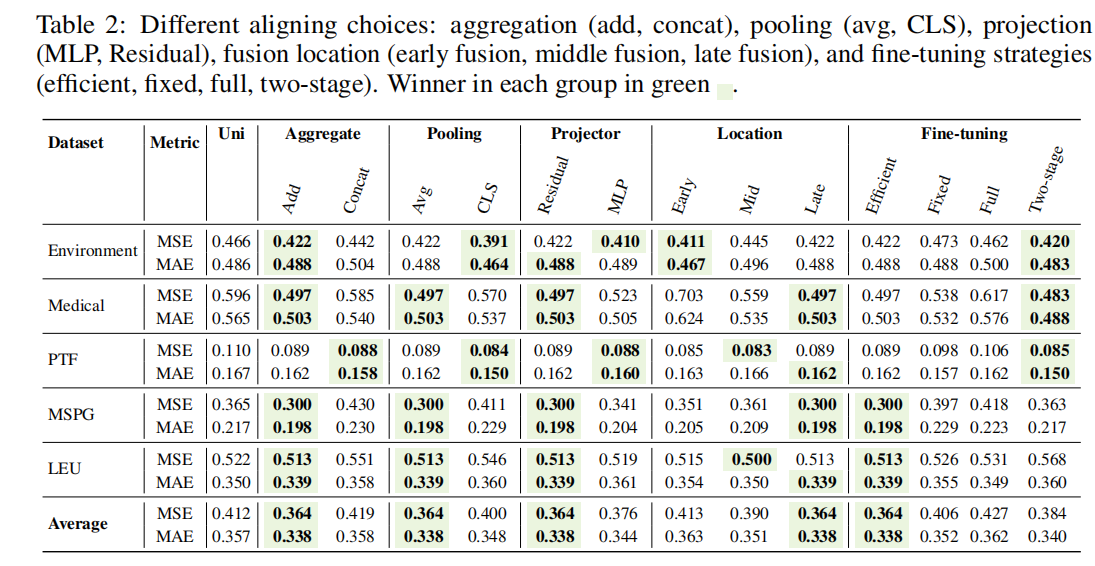
- 对齐策略的重要性(RQ4):
- 实验结果:不同的对齐策略对性能有显著影响,最佳配置因数据集而异。例如,加法聚合、平均池化、残差投影、晚期融合和高效微调等策略在平均性能上表现较好。
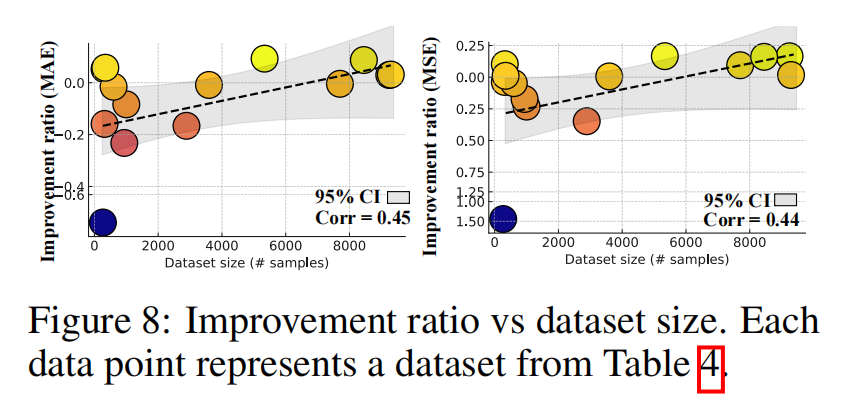
- 数据集大小的影响(RQ5):
- 实验结果:较大的训练数据集有助于多模态模型的学习,因为更多的数据可以支持跨模态表示的学习。

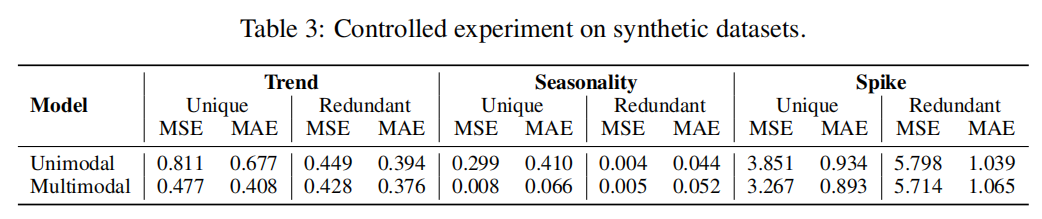
- 文本和时间序列的对齐质量(RQ6):
- 合成数据集实验:通过控制文本和时间序列之间的关系,研究文本信息是否提供独特的预测信号。结果表明,只有当文本信息提供与时间序列不重叠的预测信号时,多模态方法才显著优于单模态方法。
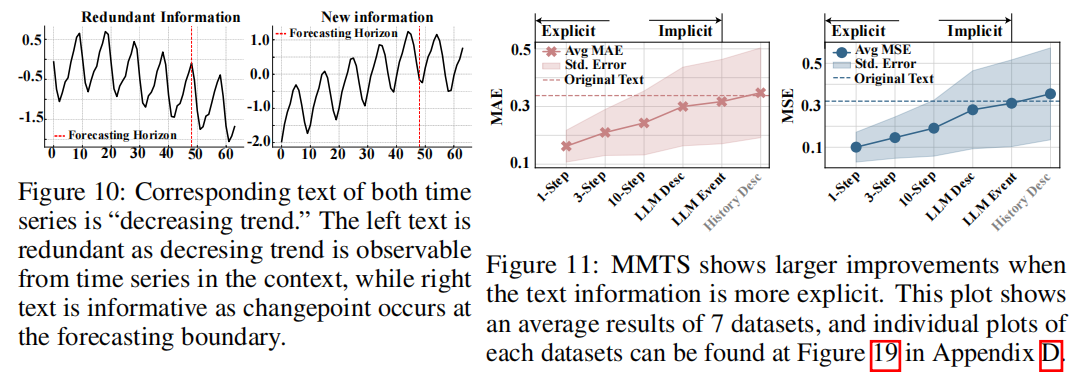
- 真实数据集实验:通过生成不同类型的文本变体(如未来变化的精确描述、未来变化的平均值、LLM生成的描述等),研究文本信息的明确性对多模态预测性能的影响。结果表明,文本信息越明确,多模态方法的性能提升越显著。
5. 实验结果
- 多模态方法的有效性:多模态方法并不总是优于单模态方法,其效果高度依赖于模型架构、对齐策略和数据特性。
- 文本模型容量:较大的LLMs在提示方法中表现更好,但在对齐方法中影响较小。
- 时间序列模型容量:较弱的时间序列模型从文本信息中受益更多。
- 对齐策略:不同的对齐策略对性能有显著影响,最佳配置因数据集而异。
- 数据集大小:较大的训练数据集有助于多模态模型的学习。
- 文本和时间序列的对齐质量:只有当文本信息提供与时间序列不重叠的预测信号时,多模态方法才显著优于单模态方法。
通过这些实验,论文提供了关于多模态时间序列预测方法在不同条件下的性能表现的全面分析,为未来的研究和实际应用提供了宝贵的指导。
附录中有更加详细的实验结果和分析,阅读原文获取详细的信息。
时间序列的对齐质量**:只有当文本信息提供与时间序列不重叠的预测信号时,多模态方法才显著优于单模态方法。
通过这些实验,论文提供了关于多模态时间序列预测方法在不同条件下的性能表现的全面分析,为未来的研究和实际应用提供了宝贵的指导。
附录中有更加详细的实验结果和分析,阅读原文获取详细的信息。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅