阿里云 AI 搜索 DeepSearch 技术实践
在大模型(LLM)技术迅猛发展的背景下,如何高效、精准地将海量知识与模型能力结合,成为企业智能化升级的关键挑战。
阿里云 OpenSearch 自 2023 年推出面向大模型的 LLM 版以来,持续深耕检索增强生成(RAG, Retrieval-Augmented Generation)领域,历经两年的迭代探索,现已完成从 RAG 1.0 到 RAG 2.0 的重大升级。这一演进的核心成果,便是我们今天重点介绍的技术 —— DeepSearch(深度搜索)。
一、从 RAG 1.0 到 RAG 2.0
首先需要简单介绍下 OpenSearch LLM 版(下面简称 LLM 版)的主要功能。
LLM 版的核心链路如下:
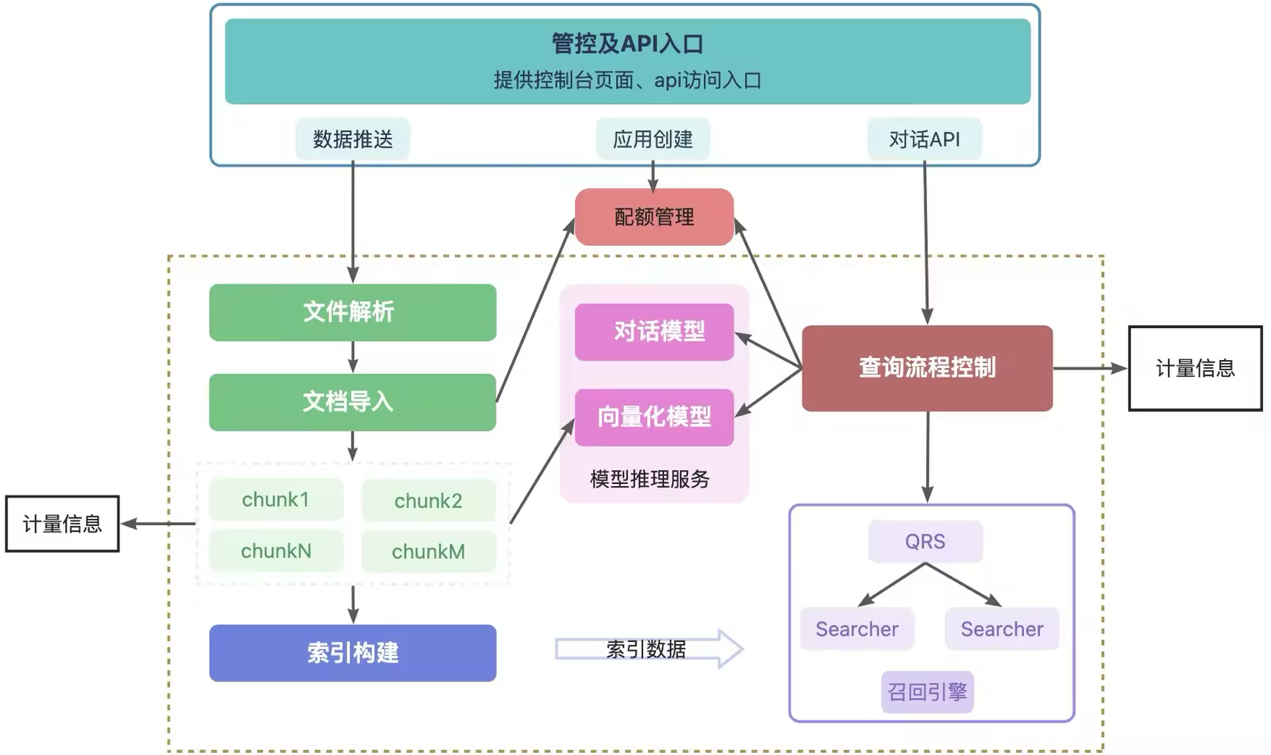
OpenSearch LLM 版的核心链路由两大模块构成:
- 离线数据处理:包括文件解析、文档切片、向量化与索引构建;
- 在线问答流程:涵盖 query 前处理、数据召回、后处理、Prompt 组装与大模型生成。
本次聚焦于在线问答阶段的技术演进,这是决定最终回答质量的关键环节。在此过程中,LLM 版经历了三次关键迭代:
第一次迭代: RAG 1.0:标准单次检索模式
最基础的 RAG 架构,通过一次检索 + 一次阅读 + 一次推理完成问答。
- 优点:响应速度快,适用于简单事实类问题;
- 缺点:面对需要多步推理或跨文档关联的复杂问题时,信息召回不全,难以形成完整答案。
第二次迭代:RAG 1.5:基于 ReAct 的单智能体模式(过渡方案)
引入 ReAct(Reasoning + Acting)框架,实现自适应检索,支持多轮交互。
- 优点:可动态调整检索策略,提升复杂问题解答率;
- 缺点:
- 推理与生成耦合,难以灵活定制 Prompt;
- Agent 调优难度高,泛化能力受限。
- 随着推理链加深,上下文迅速膨胀,影响生成效率与稳定性;
第三次迭代:RAG 2.0:基于 Plan 的多智能体系统 —— DeepSearch
这是当前 OpenSearch LLM 版的核心架构,也是我们定义的 RAG 2.0。其核心思想是:通过多个专业化 Agent 协同工作,实现“规划—搜索—阅读—反思”的闭环迭代,持续逼近最优解。
- 优势:
- 显著提升对多跳问题、对比分析类问题的解决能力;
- 架构可扩展性强,便于未来接入更多工具与模态。
- 支持更复杂的逻辑推理与知识整合;
- 挑战:
- 系统复杂度上升;
- 回答延迟相对增加,需在效果与性能间做权衡。
二、DeepSearch 架构详解
DeepSearch 的整体架构如下图所示,采用 Multi-Agent + 分层控制 的设计理念,LLM 版 DeepSearch 的主要思路是通过迭代式【搜索 + 阅读 + 推理】循环,持续探索直至找到最优解的过程。
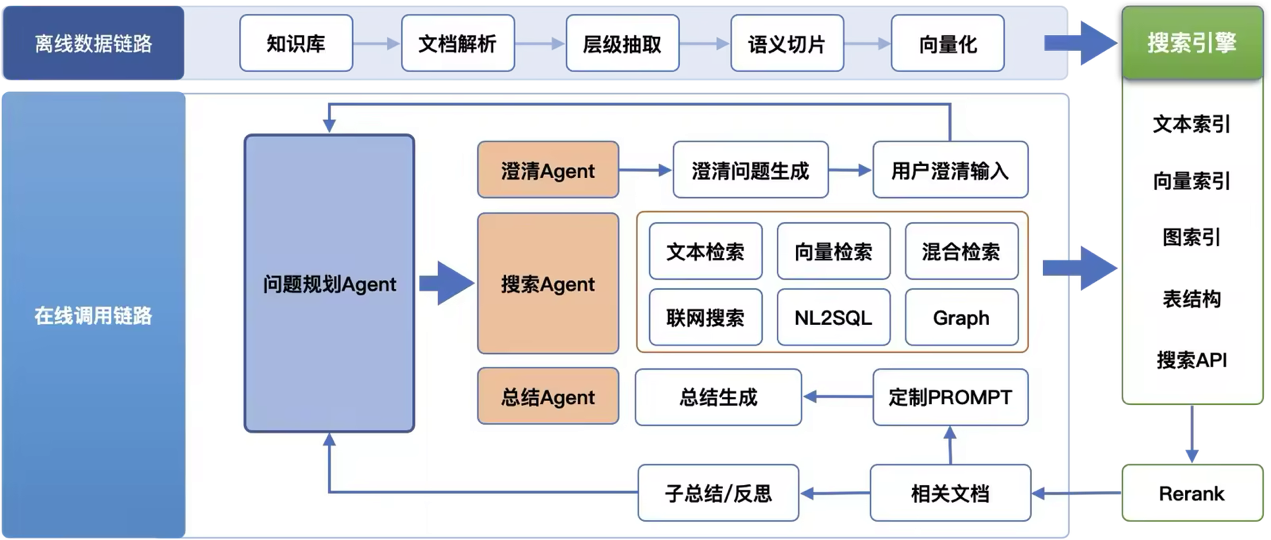
如上图所示,DeepSearch 主要由以下几个子 Agent 组成:
1. 问题规划 Agent ——系统分析的“大脑”
作为 DeepSearch 的主循环,主要负责迭代式推理与行动,不断地进行问题规划拆解->信息搜索->信息总结阅读->逻辑推理,直到满足预设的答案标准或达到资源预算上限。
其核心设计包括:
- 全局计划生成:针对用户问题生成高层次、可执行的推理路径(Plan),指导后续动作。
- 显式终止机制:通过预设 (final_answer)工具明确结束条件,避免模型“隐式判断”带来的不确定性。
- 全局 memory 更新:每轮迭代后汇总已有信息,进行反思并更新计划,确保推理路径的合理性。
- 深度激发机制:防止模型“偷懒”(如两轮无果即放弃),通过提示明确告知“问题必有解”,激励深层探索。
- 操作约束机制:限制重复使用相同工具或参数,防止陷入无效循环。
- 反思重试机制:当回答失败时,自动分析错误原因并修正上下文,避免重复犯错。
- 结构化输出规范:强制模型输出结构化指令,提升系统稳定性和可解析性。
这些机制共同保障了 DeepSearch 在复杂任务中的稳定性与准确性。
2. 澄清 Agent —— 用户意图的“翻译官”
面对模糊或歧义性问题,直接迭代搜索会导致回答冗长且与问题关联性较差。为此,澄清 Agent 主要负责针对客户问题进行意图澄清,确保搜索信息更加精确,提升客户产品体验。
例如,用户提问:“帮我看看那个项目的情况。”
→ 澄清 Agent 会追问:“您指的是哪个项目?是否指上周评审的‘智能客服升级’项目?”
由于 LLM 版本身涉及到用户领域知识库,因此该 Agent 强依赖于客户领域知识库,能够结合上下文精准识别语义,并显著提升后续搜索的准确率与用户体验。
3. 搜索 Agent —— 信息获取的“侦察兵”
搜索 Agent 是 DeepSearch 中有效信息采集的核心组件,分为两大功能模块:信息检索与信息筛选。
(1)信息检索
支持三种数据源混合检索:
- LLM 版知识库:经过完整离线处理(解析、切片、向量化),召回精度最高;
- 用户外挂 ES 知识库:客户已有数据,无需经过 LLM 版的离线流程,可快速接入;
- 联网数据:结合公开互联网资源,补充私有知识盲区。
(2)信息筛选
对召回结果进行去噪与有效信息精简:
- 过滤无关片段;
- 使用 LLM 提取关键信息;
- 返回精简、结构化的上下文给 Planner Agent,降低推理负担。
得益于 OpenSearch 在搜索领域的长期积累,保证了信息来源的广度和精度,搜索 Agent 集成了以下能力:
- 文本检索、向量检索、混合检索(基于自研向量化模型):依托 OpenSearch 自研的向量化模型,OpenSearch 向量引擎和丰富的后处理,确保每一轮的检索能达到更好的效果;
- 外接知识库:为了支持客户更快速的接入,我们允许客户使用已有的知识库进行问答,目前支持接入用户已有的ES。
- NL2SQL:提升结构化数据库的问答能力;
- Graph 查询:辅助关系推理;
- 联网搜索的前后处理优化:提升内容可信度与相关性。
4. 总结 Agent —— 最终答案的“编辑者”
当问题规划触发 inal_answer 工具或者达到迭代 max_steps,触发总结 Agent 生成最终回答。
其能力特点包括:
- 支持多种大模型:内置微调后的 Qwen、开源 Qwen、DeepSeek 系列,同时支持用户接入百炼平台或其他第三方模型;
- 多格式优化:针对总结 Agent 的 prompt 进行了专门的优化,提升更丰富的总结能力,包括图片、表格、图表等。
- 语言输出优化:同时根据中文和英文场景进行了专门的优化,提升了表达自然度;
- 自定义 Prompt 支持:满足企业个性化表达需求。
此外,系统还会识别闲聊类请求,避免不必要的资源消耗,提升整体服务效率。
三、工程实现:构建稳定高效的多智能体系统
为支撑 DeepSearch 的复杂架构,通过对比和调研多个内部和外部的多智能体开源框架,并结合 LLM 版在RAG领域的实践经验,最终实现了适合LLM版现状的多智能体系统。整体架构如下图所示:
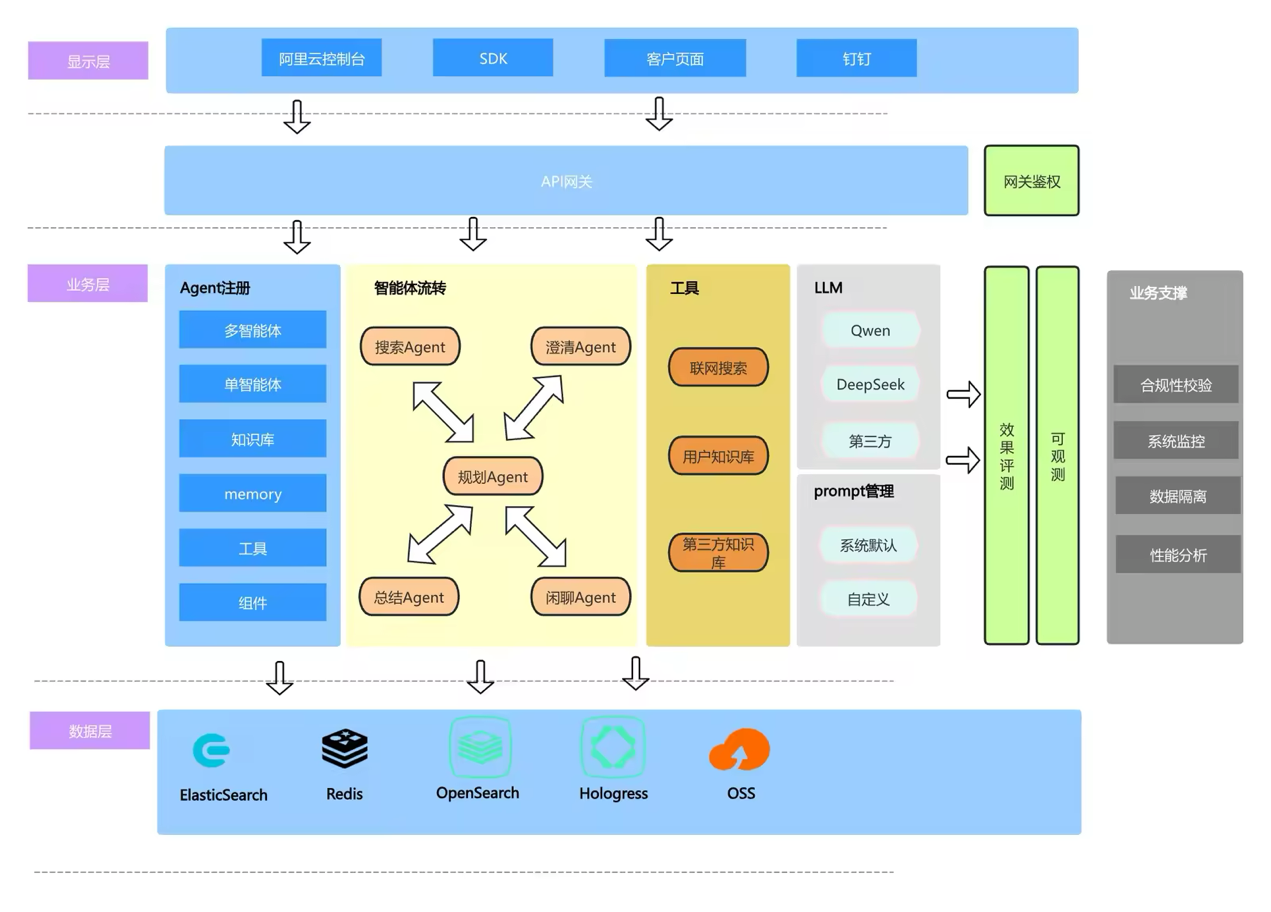
系统架构概览
1. Agent 注册机制
统一注册多智能体、单智能体、知识库、工具等模块,明确功能边界,提升复用性和可维护性。
2. 智能体协作流程
- 由问题规划 Agent 主导,负责发起任务和调度;
- 其他子 Agent(如搜索、澄清、总结)负责执行具体动作,并与各模块交互。
3. 独立工具服务层
- 工具(如搜索、联网、NL2SQL)被抽象为独立服务,接口通用、易于扩展,支持多种场景复用。
4. 多模型支持与优化
- 内置微调 Qwen、原生 Qwen、DeepSeek 等多种大模型;
- 微调模型经过推理加速,响应更快;
- 严格控制不同模型的上下文长度,保障稳定性。
5. Prompt 与输出优化
- 针对 DeepSearch 场景优化 Prompt,支持中英文;
- 输出支持文本、表格、图表、图片等多种格式;
- 支持用户自定义 Prompt,满足个性化需求。
6. 多源知识融合
- 支持混合使用:LLM 自建知识库、用户已有 ES 知识库、联网数据;
- LLM 自建库因完整处理流程效果更优,ES 外接库缺少后处理,效果略弱。
7. 自动化评测能力
- 提供评测服务,用户可在实际场景中对比不同方法效果,选择最优配置。
我们结合 OpenSearch 的实际场景做了深度定制,打造出更适合企业级应用的多智能体运行环境。
四、效果验证:DeepSearch 的真实表现
1. 效果测试:应用场景示例
1.1. 场景一:基于内部知识库的多跳推理
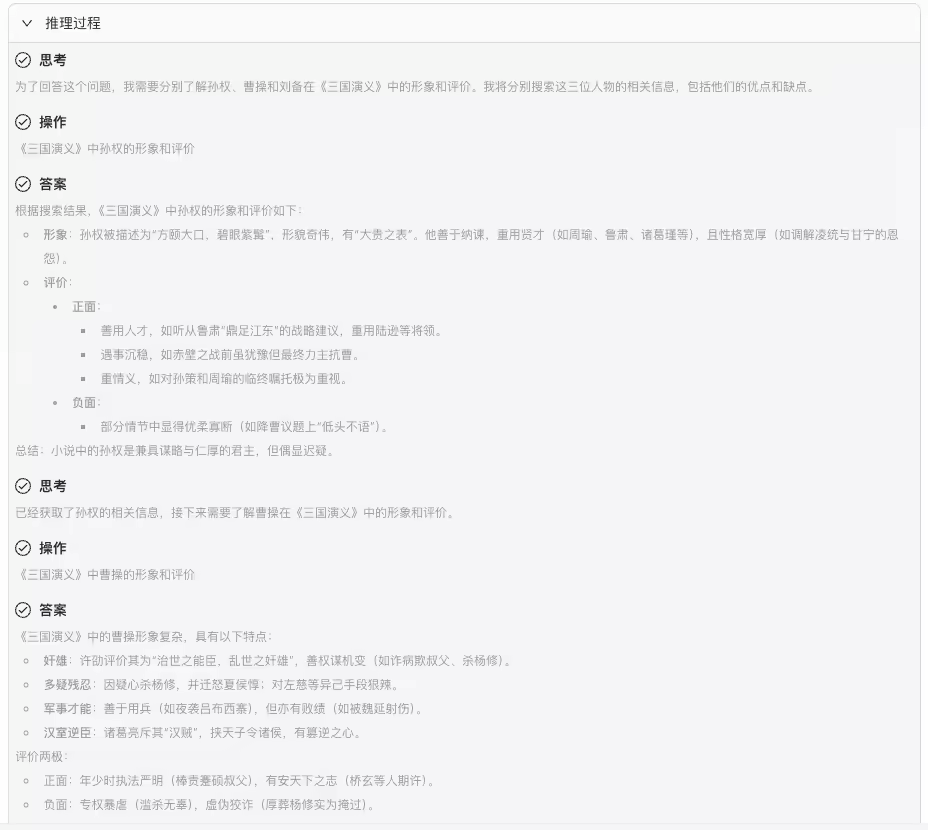
问题:
“根据《三国演义》,如何评价孙权、曹操和刘备?他们的优缺点分别是什么?”
推理过程:
结果:

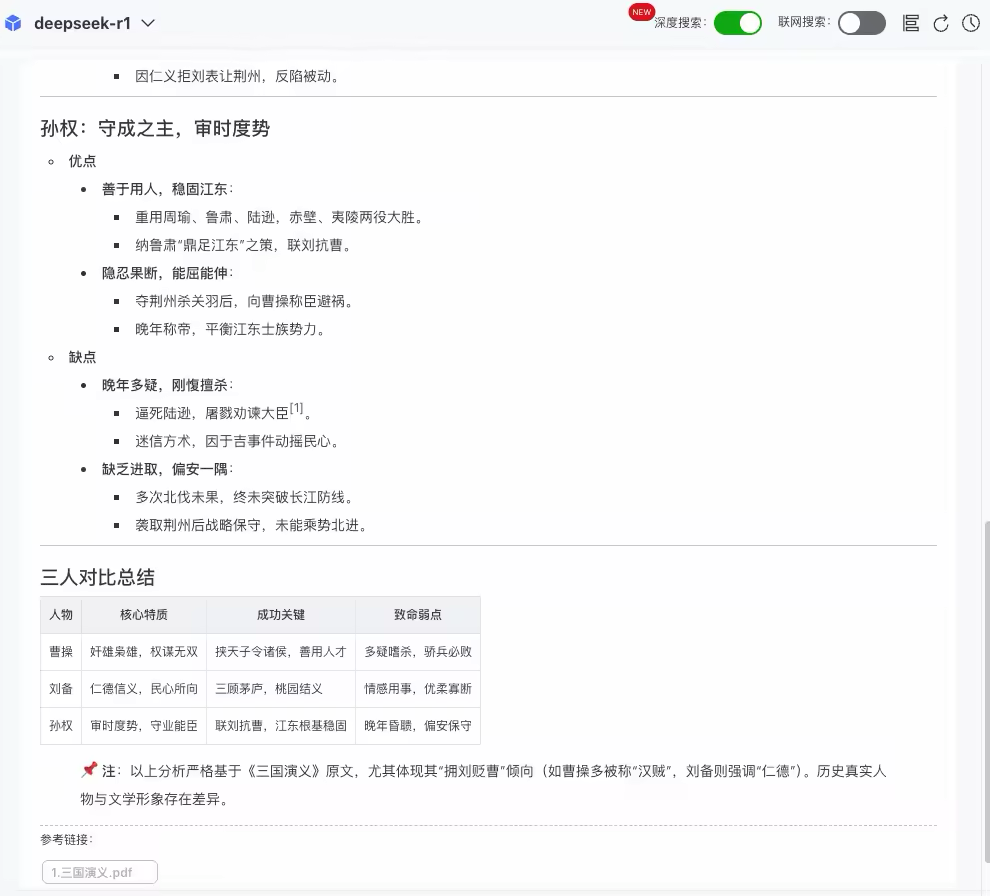
1.2. 场景二:联网场景下的效果
问题:
“opensearch 有哪些版本?哪个版本适合大数据场景?哪个版本适合搭建问答机器人?哪个版本适合在电商场景使用?分别描述下具体原因。”
推理过程:
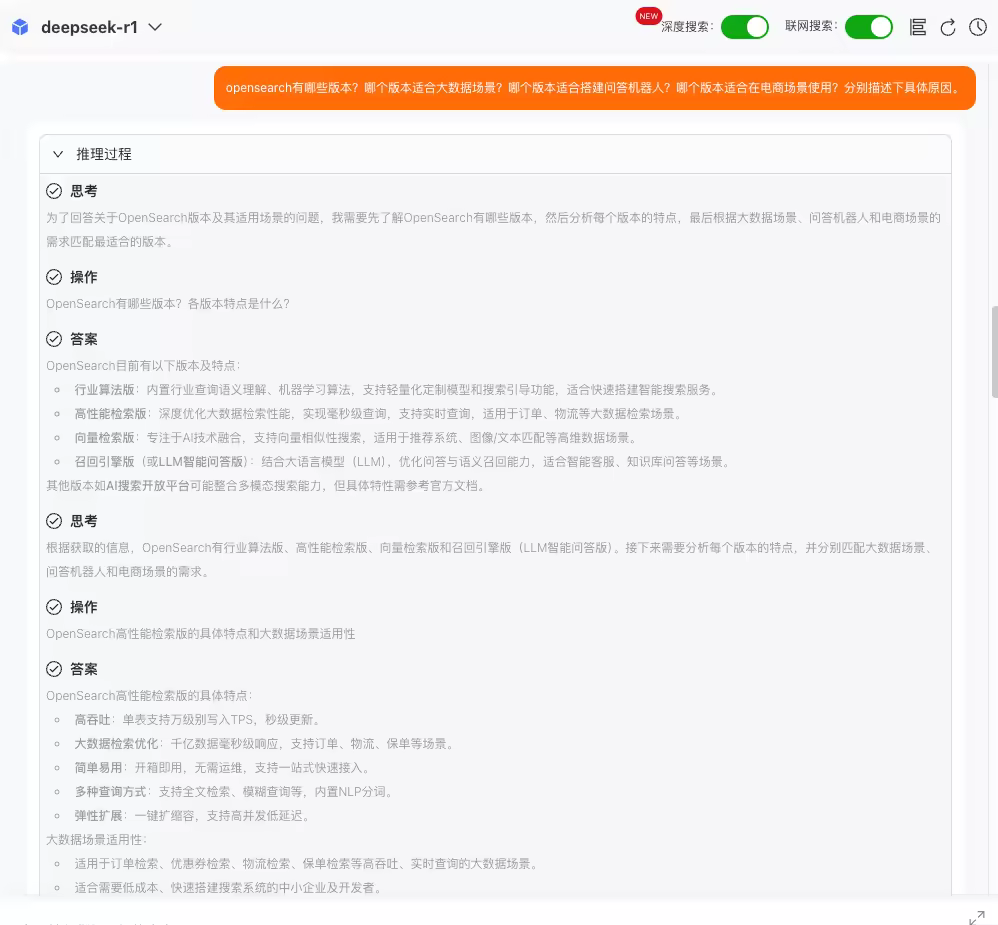
结果:


可以看到,不管是内部知识库场景,还是混合联网搜索的场景,LLM版的DeepSearch可以解决多跳问题、复杂对比类问题。
2. 效果评估:
在多个公开数据集上进行了端到端测试,以 检索召回率(full hit) 为指标,评估不同架构的表现:
| 数据集 | 方法 | 平均搜索深度 | 召回率 |
| hotpotQA_2hop (100条) | 单次召回 | 1 | 42% |
| 单智能体 ReAct | 3.02 | 71% | |
| 多智能体 DeepSearch | 4.77 | 86% | |
| musique_2hop | 单次召回 | 1 | 16% |
| ReAct | 3.46 | 66% | |
| DeepSearch | 6.35 | 83% | |
| musique_3hop | 单次召回 | 1 | 2% |
| ReAct | 4.23 | 37% | |
| DeepSearch | 9.14 | 59% | |
| musique_4hop | 单次召回 | 1 | 0% |
| ReAct | 4.44 | 8% | |
| DeepSearch | 8.91 | 20% | |
| crud_2&3hop(中文86条) | 单次召回 | 1 | 65% |
| ReAct | 2.45 | 73% | |
| DeepSearch | 4.29 | 86% |
结论:随着问题复杂度上升,DeepSearch 的优势愈发明显,尤其在 3 跳以上问题中,远超传统方法。
3. 3. 在 xBench-DeepSearch 榜单上的表现
使用 DeepSearch 框架仅调用 search 工具测试 xBench-DeepSearch 数据集,最优效果达到了 63% (5轮均值),后续加上visit工具应该能达到更优效果。
榜单地址:xbench-DeepSearch-Leaderboard
七、总结
阿里云 OpenSearch LLM 版历经两年打磨,完成了从 RAG 1.0 到 RAG 2.0 的关键跨越。以 DeepSearch 为代表的多智能体深度搜索架构,不仅解决了传统 RAG 在复杂问题上的局限,更在企业知识管理、智能客服、技术文档问答等场景中展现出强大潜力。
这不仅是技术的升级,更是思维方式的转变——从“检索即回答”到“思考再回答”。未来,我们将继续深耕 RAG 与 Agent 技术,推动 AI 搜索向更智能、更可靠、更通用的方向发展,助力企业真正实现“知识自由”。
AI 搜索不止于搜索,而在于理解与创造。
了解更多:OpenSearch LLM智能问答版_对话式搜索_大模型_阿里云