机器学习经典算法总结:K-Means聚类与集成学习(Bagging, Boosting, Stacking)
一、引言
机器学习中的无监督学习和集成学习是两大重要方向。我将对K-Means聚类算法和集成学习方法(Bagging, Boosting, Stacking) 进行系统总结,涵盖算法原理、优缺点、应用场景及实现方式。
二、K-Means聚类算法
1. 聚类算法简介:
聚类是一种无监督学习方法,目标是将相似的数据点划分为同一组,不相似的数据点划分到不同组。
难点在于:如何评估聚类效果、如何选择合适的聚类数目K、如何定义“相似性”。
2. 距离度量:
常用的距离度量包括:
欧式距离:多维空间中的直线距离。
曼哈顿距离:各坐标轴上的绝对距离之和。
3. K-Means算法流程:
随机选择K个中心点;
将每个点分配到最近的中心点所属簇;
重新计算每个簇的中心点;
重复步骤2-3直到中心点不再变化。
4. 评估指标:CH指标:
衡量类内紧密度与类间分离度;
CH值越大,聚类效果越好。
5. 优缺点:
优点:简单、高效、适用于常规数据集;
缺点:K值难以确定、对异常值敏感、难以处理非球形簇。
三、集成学习(Ensemble Learning)
1. 集成学习简介:
集成学习通过结合多个弱学习器构建一个强学习器,提升模型的泛化能力和鲁棒性。
2. 结合策略:
简单平均法 加权平均法 投票法(少数服从多数)
3. 集成学习分类:
Bagging(Bootstrap Aggregating):
代表算法:随机森林(Random Forest)
特点:并行训练多个基学习器,通过投票或平均得到最终结果。
优点:可处理高维数据;能输出特征重要性;支持并行化,训练速度快。
Boosting:
代表算法:AdaBoost
特点:串行训练,根据上一轮结果调整样本权重。
流程:
初始化样本权重;训练弱分类器,调整错分样本权重;组合所有弱分类器,加权得到最终结果。
Stacking:
特点:堆叠多种不同类型的分类器(如KNN、SVM、RF等);
流程:第一阶段各分类器输出结果,第二阶段用这些结果训练一个元分类器。
四、课堂练习:
1.用make_blobs()创建一个你喜欢的数据集,然后对它进行k均值聚类。

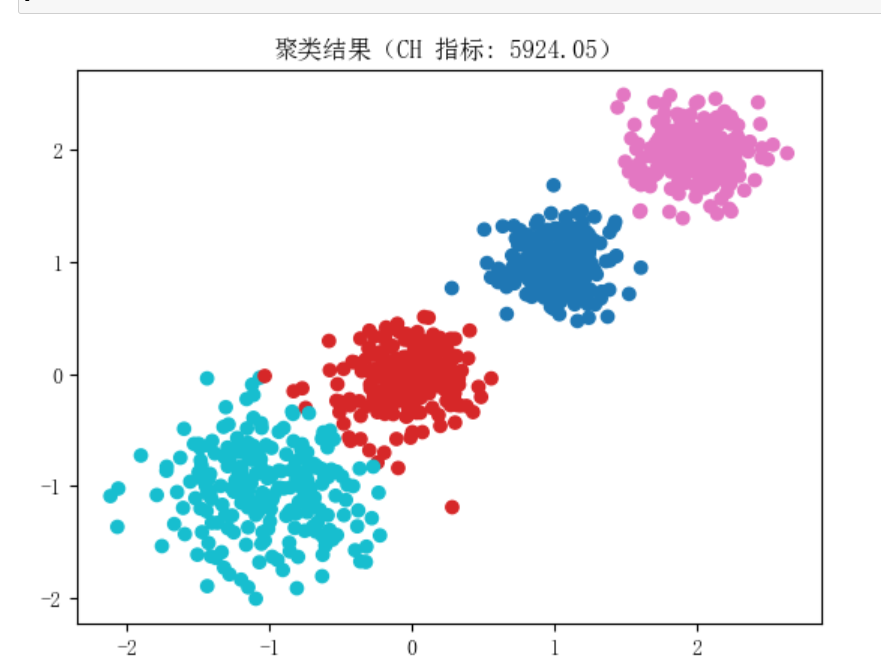
2.用随机森林实现葡萄酒分类。

五、总结
| 算法类型 | 代表算法 | 特点 | 适用场景 |
|---|---|---|---|
| 聚类 | K-Means | 无监督,简单高效 | 数据分群、图像分割 |
| 集成学习-Bagging | 随机森林 | 并行、抗过拟合、可解释性强 | 分类、回归、特征选择 |
| 集成学习-Boosting | AdaBoost | 串行、调整权重、强分类器 | 二分类、异常检测 |
| 集成学习-Stacking | 多模型堆叠 | 暴力组合、灵活性强 | 复杂任务、竞赛常用 |
K-Means和集成学习算法是机器学习中非常基础且实用的方法。理解其原理、掌握其实现方式,对于构建更复杂模型和解决实际问题具有重要意义。