java基础(十三)消息队列
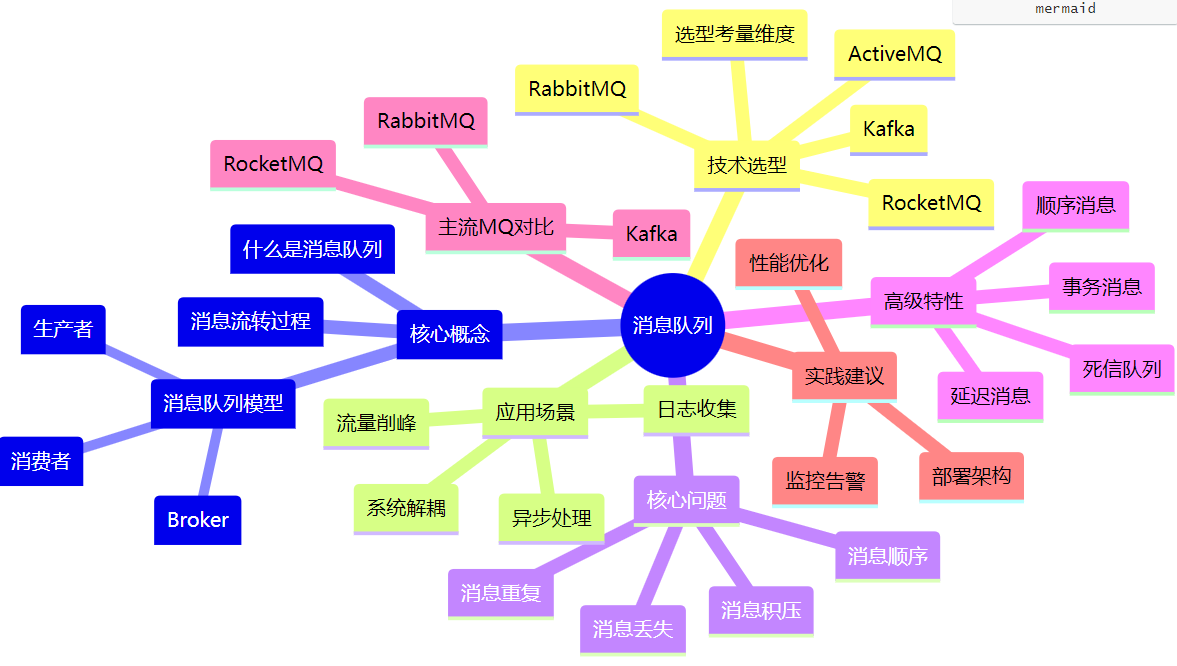
一、什么是消息队列?
消息队列(Message Queue,简称 MQ)是一种用于在不同系统、服务或组件之间传递消息的通信机制。你可以将其理解为一个中间转发器,负责接收、存储和投递消息,实现系统间的解耦、异步通信和流量削峰。
消息队列核心概念
生产者(Producer):发送消息到队列的应用或服务
消费者(Consumer):从队列中接收和处理消息的应用或服务
消息代理(Broker):接收、存储和转发消息的中间件
消息(Message):在应用间传输的数据单位
队列(Queue):存储消息的数据结构
主题(Topic):发布/订阅模式中的消息类别
消息流转过程
生产者 → 消息序列化 → 网络传输 → Broker接收 → 消息持久化 → Broker投递 → 网络传输 → 消费者接收 → 消息反序列化 → 业务处理
当前业界流行的开源消息中间件包括:RabbitMQ、RocketMQ、Kafka、ActiveMQ 等。
二、消息队列的选型指南
不同消息队列在性能、可靠性、功能支持等方面有所差异。以下是几种主流消息队列的详细对比:
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | 毫秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 消息可靠性 | 至少一次 | 至少一次 | 至少一次 | 最多一次/至少一次 |
| 消息顺序性 | 有序 | 有序 | 有序 | 分区有序 |
| 支持主题数 | 千级 | 百万级 | 千级 | 百级(多了性能下降) |
| 消息回溯 | 不支持 | 不支持 | 支持(时间) | 支持(offset) |
| 管理界面 | 普通 | 普通 | 完善 | 普通 |
| 协议支持 | OpenWire, STOMP, AMQP, MQTT | AMQP, STOMP, MQTT | 自定义协议 | 自定义协议 |
| 开发语言 | Java | Erlang | Java | Scala/Java |
详细选型建议
1. 高吞吐场景(如双十一秒杀)
优先选择 Kafka 或 RocketMQ,原因:
分布式架构支持水平扩展
高吞吐设计,单机可达10万级以上QPS
良好的分区机制支持并行处理
2. 多主题接入(如中台服务)
考虑 RabbitMQ(百万级主题)或 RocketMQ(千级),考虑因素:
RabbitMQ的Exchange机制支持灵活路由
RocketMQ的Tag系统支持精细化过滤
3. 金融等高可靠场景
选择支持分布式部署的 Kafka 或 RocketMQ,关键特性:
强一致性保证
完善的事务支持
消息持久化机制
4. IoT和边缘计算场景
RabbitMQ 更适合,因为:
支持多种协议(MQTT、AMQP等)
轻量级客户端
灵活的插件系统
5. 实时性要求极高场景
可考虑 RabbitMQ(微秒级),但注意:
实际业务中毫秒级已足够
网络延迟往往成为瓶颈
微秒级优势主要在局域网环境下明显
三、消息队列的使用场景
1. 系统解耦
问题场景:电商系统中,订单服务需要调用库存服务、积分服务、通知服务等多个下游服务。
传统方案:订单服务直接调用各个服务,耦合严重
// 紧耦合的实现方式
public class OrderService {public void createOrder(Order order) {// 创建订单orderDao.save(order);// 直接调用下游服务inventoryService.reduceStock(order);pointsService.addPoints(order);notificationService.sendSms(order);}
}消息队列方案:通过MQ解耦
// 使用MQ解耦的实现(用户:YA33)
public class OrderService {@Autowiredprivate RocketMQTemplate rocketMQTemplate;public void createOrder(Order order) {// 创建订单orderDao.save(order);// 发送消息到MQ,异步处理下游逻辑rocketMQTemplate.send("order_topic", MessageBuilder.withPayload(order).build());}
}
// 库存服务消费者
@Component
@RocketMQMessageListener(topic = "order_topic", consumerGroup = "inventory_group")
public class InventoryConsumer implements RocketMQListener<Order> {@Overridepublic void onMessage(Order order) {inventoryService.reduceStock(order);}
}优势:
系统间依赖降低
单个服务故障不影响整体系统
便于系统扩展和维护
2. 异步处理
典型场景:用户注册后需要执行多个操作
发送欢迎邮件
初始化用户权益
记录行为日志
推荐可能感兴趣的内容
同步处理的问题:
响应时间慢,用户体验差
某个操作失败影响整个流程
异步处理方案:
// 异步处理实现(用户:YA33)
public class UserService {@Autowiredprivate KafkaTemplate<String, UserEvent> kafkaTemplate;public void register(User user) {// 保存用户信息userDao.save(user);// 发送注册事件,异步处理后续逻辑UserEvent event = new UserEvent(user, "REGISTER");kafkaTemplate.send("user_events", event);// 立即返回响应return ResponseEntity.ok("注册成功");}
}
// 邮件服务消费者
@Component
public class EmailConsumer {@KafkaListener(topics = "user_events")public void handleUserEvent(UserEvent event) {if ("REGISTER".equals(event.getType())) {emailService.sendWelcomeEmail(event.getUser());}}
}3. 流量削峰
场景:电商秒杀活动,瞬时流量是平时的100倍
传统架构问题:
数据库连接池爆满
服务响应超时
系统雪崩崩溃
消息队列削峰方案:
// 流量削峰实现(用户:YA33)
public class SeckillService {@Autowiredprivate RabbitTemplate rabbitTemplate;public void handleSeckillRequest(SeckillRequest request) {// 1. 快速校验基本参数if (!validateRequest(request)) {throw new ValidationException("请求参数错误");}// 2. 立即返回"请求已接收"响应// 3. 将请求放入消息队列异步处理rabbitTemplate.convertAndSend("seckill_queue", request);return SeckillResponse.accepted();}
}
// 异步处理秒杀请求
@Component
public class SeckillProcessor {@RabbitListener(queues = "seckill_queue")public void processSeckill(SeckillRequest request) {try {// 数据库操作inventoryService.reduceStock(request);orderService.createOrder(request);// 其他业务逻辑...} catch (Exception e) {// 处理失败,进入重试或补偿流程handleFailure(request, e);}}
}4. 日志收集与处理
场景:分布式系统日志集中收集和分析
方案架构:
应用节点 → Kafka → 流处理平台 → 存储/分析系统
优势:
低侵入性
高吞吐量
实时处理能力
四、常见问题与解决方案
1. 消息重复消费问题
产生原因:
生产者重试机制导致重复发送
消费者处理成功后ACK失败
消费者重启或重平衡
解决方案:业务端实现幂等性
幂等性实现方案:
方案一:数据库唯一约束
// 基于数据库唯一索引的幂等实现(用户:YA33)
public class OrderService {public void processOrder(OrderMessage message) {try {// 插入订单记录,order_id是唯一索引orderDao.insert(message.toOrder());// 处理订单业务逻辑processOrderBusiness(message);} catch (DuplicateKeyException e) {// 订单已存在,直接返回成功log.info("订单已处理,orderId: {}", message.getOrderId());}}
}方案二:Redis原子操作
// 基于Redis的幂等控制(用户:YA33)
public class IdempotentConsumer {@Autowiredprivate RedisTemplate<String, String> redisTemplate;public void handleMessage(String messageId, String content) {// 使用setIfAbsent实现原子性检查Boolean processed = redisTemplate.opsForValue().setIfAbsent("msg:" + messageId, "processed", 5, TimeUnit.MINUTES);if (Boolean.TRUE.equals(processed)) {// 第一次处理,执行业务逻辑processMessage(content);} else {// 消息已处理,直接跳过log.info("消息 {} 已处理,跳过重复消费", messageId);}}
}方案三:版本号控制
// 基于版本号的幂等控制
public class AccountService {public void deductBalance(String accountId, BigDecimal amount, String requestId) {Account account = accountDao.findById(accountId);// 检查请求是否已处理if (account.getProcessedRequests().contains(requestId)) {return; // 已处理,直接返回}// 执行业务逻辑if (account.getBalance().compareTo(amount) >= 0) {account.setBalance(account.getBalance().subtract(amount));account.getProcessedRequests().add(requestId);accountDao.update(account);}}
}2. 消息丢失问题
需从三个环节保障消息可靠性:
生产阶段防丢失
// 生产者消息可靠性保障(用户:YA33)
public class ReliableProducer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendReliableMessage(String topic, String message) {ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, message);// 添加回调处理future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onSuccess(SendResult<String, String> result) {log.info("消息发送成功: {}", result.getRecordMetadata());}@Overridepublic void onFailure(Throwable ex) {log.error("消息发送失败,进行重试", ex);// 重试逻辑retrySendMessage(topic, message);}});}private void retrySendMessage(String topic, String message) {// 实现重试逻辑,包括指数退避等策略}
}存储阶段防丢失
Kafka:配置
acks=all和min.insync.replicas=2RocketMQ:同步刷盘 + 主从同步
RabbitMQ:持久化队列 + 镜像队列
消费阶段防丢失
// 消费者可靠性保障(用户:YA33)
@Component
public class ReliableConsumer {@KafkaListener(topics = "reliable_topic")public void consumeMessage(ConsumerRecord<String, String> record) {try {// 处理消息processMessage(record.value());// 手动提交offset,确保处理成功后才提交kafkaAcknowledgment.acknowledge();} catch (Exception e) {log.error("消息处理失败,进入死信队列", e);// 将失败消息发送到死信队列sendToDlq(record);}}
}3. 消息顺序性保障
保证消息顺序的方案:
方案一:单一分区保证顺序
// 保证相同业务ID的消息发送到同一分区(用户:YA33)
public class OrderMessageProducer {@Autowiredprivate KafkaTemplate<String, OrderEvent> kafkaTemplate;public void sendOrderEvent(OrderEvent event) {// 使用orderId作为key,确保相同订单的消息进入同一分区kafkaTemplate.send("order_events", event.getOrderId(), event);}
}
// 消费者单线程顺序处理
@Component
public class OrderEventConsumer {@KafkaListener(topics = "order_events")public void consumeOrderEvent(OrderEvent event) {// 使用分布式锁保证同一订单的顺序处理String lockKey = "order_lock:" + event.getOrderId();if (tryLock(lockKey)) {try {processOrderEvent(event);} finally {releaseLock(lockKey);}}}
}方案二:业务层面排序
// 业务层排序方案
public class MessageSequencer {private final Map<String, PriorityBlockingQueue<SequencedMessage>> queues = new ConcurrentHashMap<>();public void processInSequence(String businessId, SequencedMessage message) {queues.computeIfAbsent(businessId, id -> new PriorityBlockingQueue<>(Comparator.comparingLong(SequencedMessage::getSequenceId))).put(message);processQueue(businessId);}private void processQueue(String businessId) {// 按顺序处理队列中的消息}
}4. 消息积压处理
消息积压排查流程:
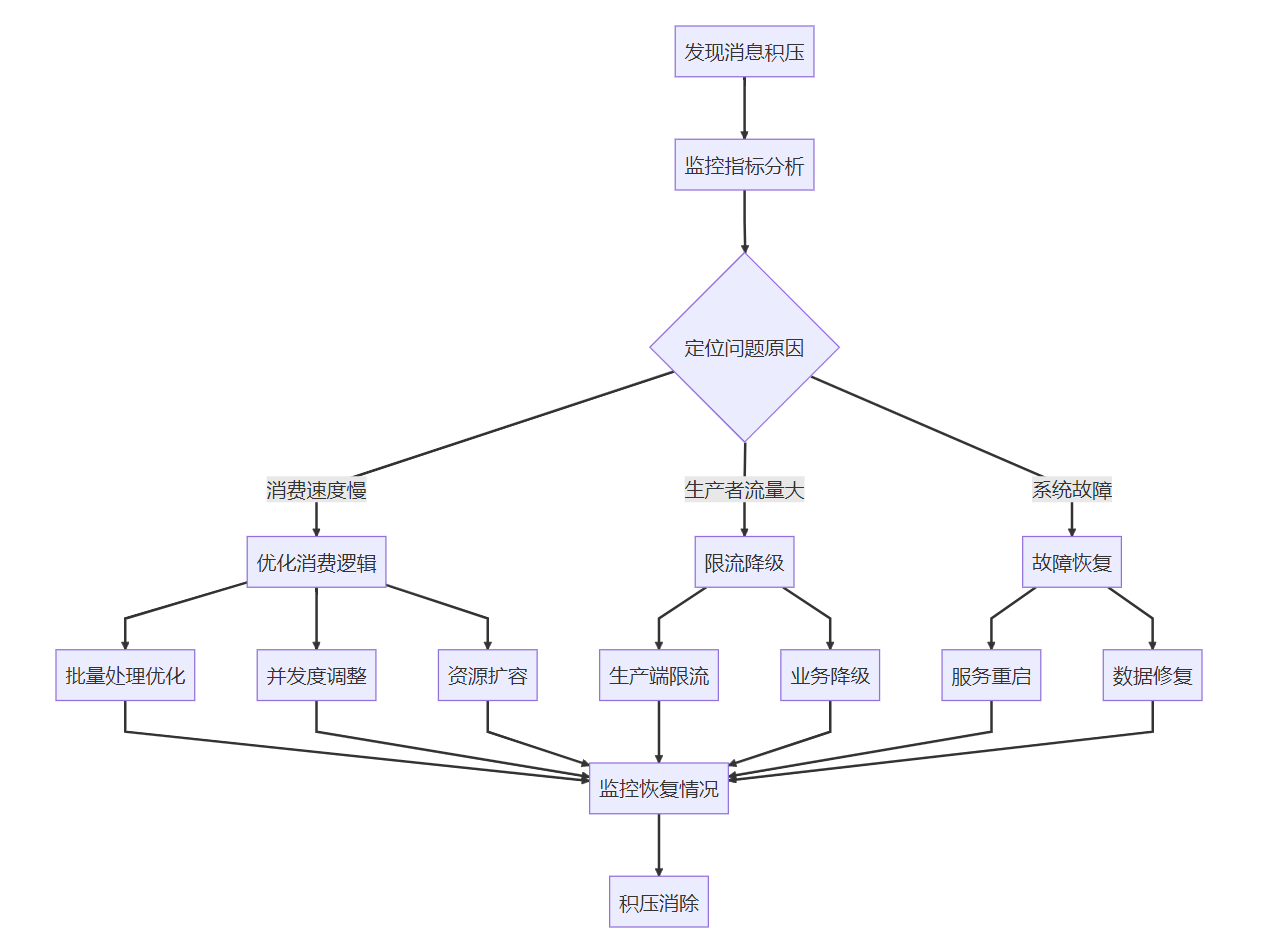
积压处理实战方案:
临时扩容方案:
评估积压量:计算需要增加的消费者数量
扩容消费者:临时增加消费者实例
分区重平衡:调整分区分配策略
监控消费速度:确保积压量持续下降
恢复原状:积压消除后缩减实例
代码示例:
// 批量消费提升处理能力(用户:YA33)
@Component
public class BatchConsumer {@KafkaListener(topics = "batch_topic", containerFactory = "batchFactory")public void consumeBatch(List<ConsumerRecord<String, String>> records) {// 批量处理消息List<Data> dataList = records.stream().map(record -> parseData(record.value())).collect(Collectors.toList());// 批量写入数据库batchInsertToDatabase(dataList);}// 批量配置@Beanpublic ConcurrentKafkaListenerContainerFactory<String, String> batchFactory() {ConcurrentKafkaListenerContainerFactory<String, String> factory =new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());factory.setBatchListener(true); // 开启批量监听factory.setConcurrency(10); // 并发消费者数量return factory;}
}五、事务消息与数据一致性
分布式事务挑战
在分布式系统中,保证数据一致性面临诸多挑战:
网络分区:节点间通信中断
节点故障:服务意外宕机
时序问题:操作执行顺序不确定
并发冲突:多个操作同时修改数据
事务消息实现方案
RocketMQ 事务消息流程:
// RocketMQ事务消息示例(用户:YA33)
public class TransactionalService {@Autowiredprivate RocketMQTemplate rocketMQTemplate;@Transactionalpublic void createOrder(Order order) {// 1. 保存订单到数据库orderDao.save(order);// 2. 发送事务消息TransactionSendResult result = rocketMQTemplate.sendMessageInTransaction("order_trans_group",MessageBuilder.withPayload(order).build(),order.getOrderId());if (!result.getLocalTransactionState().equals(LocalTransactionState.COMMIT_MESSAGE)) {throw new RuntimeException("事务消息发送失败");}}
}
// 事务监听器实现
@Component
@RocketMQTransactionListener(txProducerGroup = "order_trans_group")
public class OrderTransactionListener implements RocketMQLocalTransactionListener {@Overridepublic RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {// 执行本地事务String orderId = (String) arg;inventoryService.reduceStock(orderId);return RocketMQLocalTransactionState.COMMIT;} catch (Exception e) {return RocketMQLocalTransactionState.ROLLBACK;}}@Overridepublic RocketMQLocalTransactionState checkLocalTransaction(Message msg) {// 事务回查逻辑String orderId = (String) msg.getHeaders().get("order_id");return inventoryService.checkInventoryDeduction(orderId) ? RocketMQLocalTransactionState.COMMIT : RocketMQLocalTransactionState.ROLLBACK;}
}事务消息状态流转:
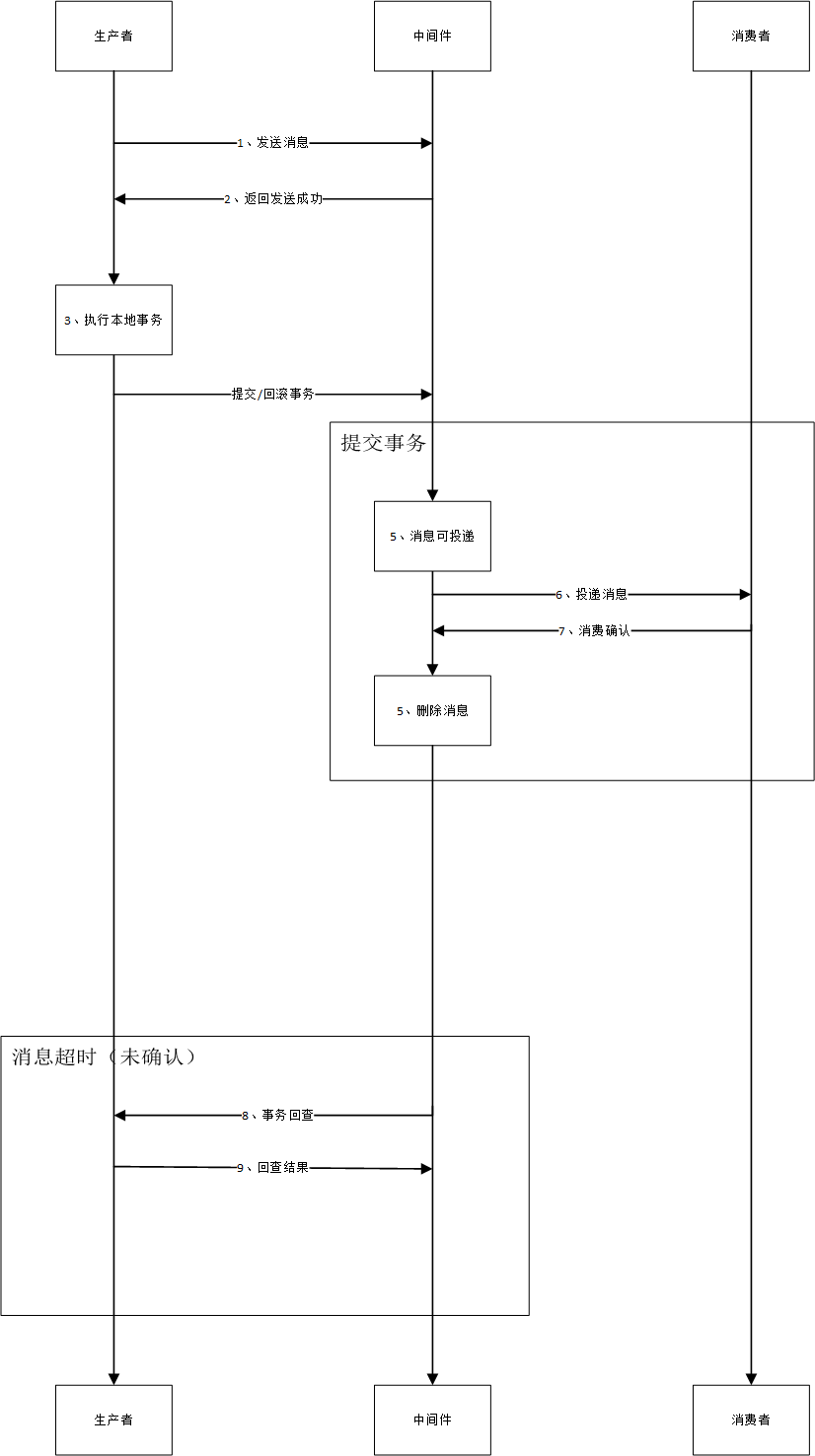
最终一致性模式
基于消息的最终一致性方案:
方案架构:
服务A(业务操作+发消息) → MQ → 服务B(消费消息+业务操作)补偿机制:
// 最终一致性补偿方案(用户:YA33)
@Component
public class ConsistencyCompensator {@Scheduled(fixedRate = 30000) // 每30秒执行一次public void compensateFailedOperations() {// 查询需要补偿的业务记录List<CompensationTask> tasks = findCompensationTasks();for (CompensationTask task : tasks) {try {// 执行补偿操作compensate(task);// 标记为已处理markAsCompensated(task);} catch (Exception e) {log.error("补偿任务执行失败: {}", task.getId(), e);// 记录失败次数,超过阈值告警recordFailure(task, e);}}}
}六、消息队列高可用架构
Kafka 高可用架构
核心机制:
分区副本机制(Replication)
领导者选举(Leader Election)
ISR(In-Sync Replicas)列表
配置示例:
# Kafka高可用配置
broker.id=1
listeners=PLAINTEXT://:9092
log.dirs=/tmp/kafka-logs
default.replication.factor=3
min.insync.replicas=2
auto.leader.rebalance.enable=true
unclean.leader.election.enable=falseRocketMQ 高可用架构
核心组件:
NameServer:无状态服务发现
Broker:消息存储和投递
Broker集群:主从架构
部署模式:
多主模式:所有Broker都是Master
多主多从模式:主从数据同步
Dledger模式:基于Raft协议的强一致性
RabbitMQ 高可用架构
集群方案:
普通集群:元数据共享,队列不复制
镜像队列:队列内容跨节点复制
仲裁队列:基于Raft协议的新型队列
镜像队列配置:
// RabbitMQ镜像队列配置(用户:YA33)
@Configuration
public class RabbitMQHaConfig {@Beanpublic Queue highAvailableQueue() {Map<String, Object> args = new HashMap<>();// 镜像到所有节点args.put("x-ha-policy", "all");return new Queue("ha.queue", true, false, false, args);}
}七、性能优化实践
生产者优化
批量发送:
// Kafka批量发送优化(用户:YA33)
@Configuration
public class KafkaProducerConfig {@Beanpublic Map<String, Object> producerConfigs() {Map<String, Object> props = new HashMap<>();// 批量大小设置props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// 等待时间设置props.put(ProducerConfig.LINGER_MS_CONFIG, 10);// 压缩设置props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");return props;}
}消费者优化
并发消费:
// 并发消费者配置(用户:YA33)
@Configuration
public class KafkaConsumerConfig {@Beanpublic ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {ConcurrentKafkaListenerContainerFactory<String, String> factory =new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());// 设置并发消费者数量factory.setConcurrency(4);// 批量消费配置factory.setBatchListener(true);return factory;}
}Broker优化
Kafka服务器配置:
# 网络线程数
num.network.threads=4
# IO线程数
num.io.threads=8
# Socket缓冲区大小
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
# 日志保留策略
log.retention.hours=72
log.segment.bytes=1073741824八、监控与运维
关键监控指标
生产者监控:
发送成功率
发送延迟
批量发送大小
Broker监控:
磁盘使用率
网络吞吐量
请求处理延迟
消费者监控:
消费延迟
消费吞吐量
重平衡次数
告警策略
紧急告警:
消息积压超过阈值
消费者组停止消费
Broker节点宕机
警告告警:
磁盘使用率超过80%
网络延迟增长
消费速度下降
运维最佳实践
容量规划:定期评估业务增长,提前扩容
版本管理:制定升级策略,测试兼容性
备份策略:定期备份关键数据
灾难恢复:制定并演练容灾方案
九、总结与展望
消息队列作为分布式系统的核心组件,在现代架构中扮演着越来越重要的角色。通过本文的详细分析,我们可以看到:
技术选型要点
业务需求驱动:根据具体场景选择最适合的消息队列
性能与可靠性平衡:在吞吐量和数据一致性间找到平衡点
生态兼容性:考虑与现有技术栈的集成难度
发展趋势
云原生:Serverless、Kubernetes原生支持
多协议支持:统一接入多种消息协议
智能化:AI驱动的自动调优和故障预测
安全增强:端到端加密、更细粒度的权限控制
实践建议
从小规模开始:逐步验证技术方案的可行性
重视监控:建立完善的监控告警体系
定期演练:模拟故障场景,验证系统韧性
持续优化:根据业务发展不断调整架构
消息队列技术的选择和使用是一个需要综合考虑多方面因素的决策过程。希望本文能为您的技术选型和架构设计提供有价值的参考。