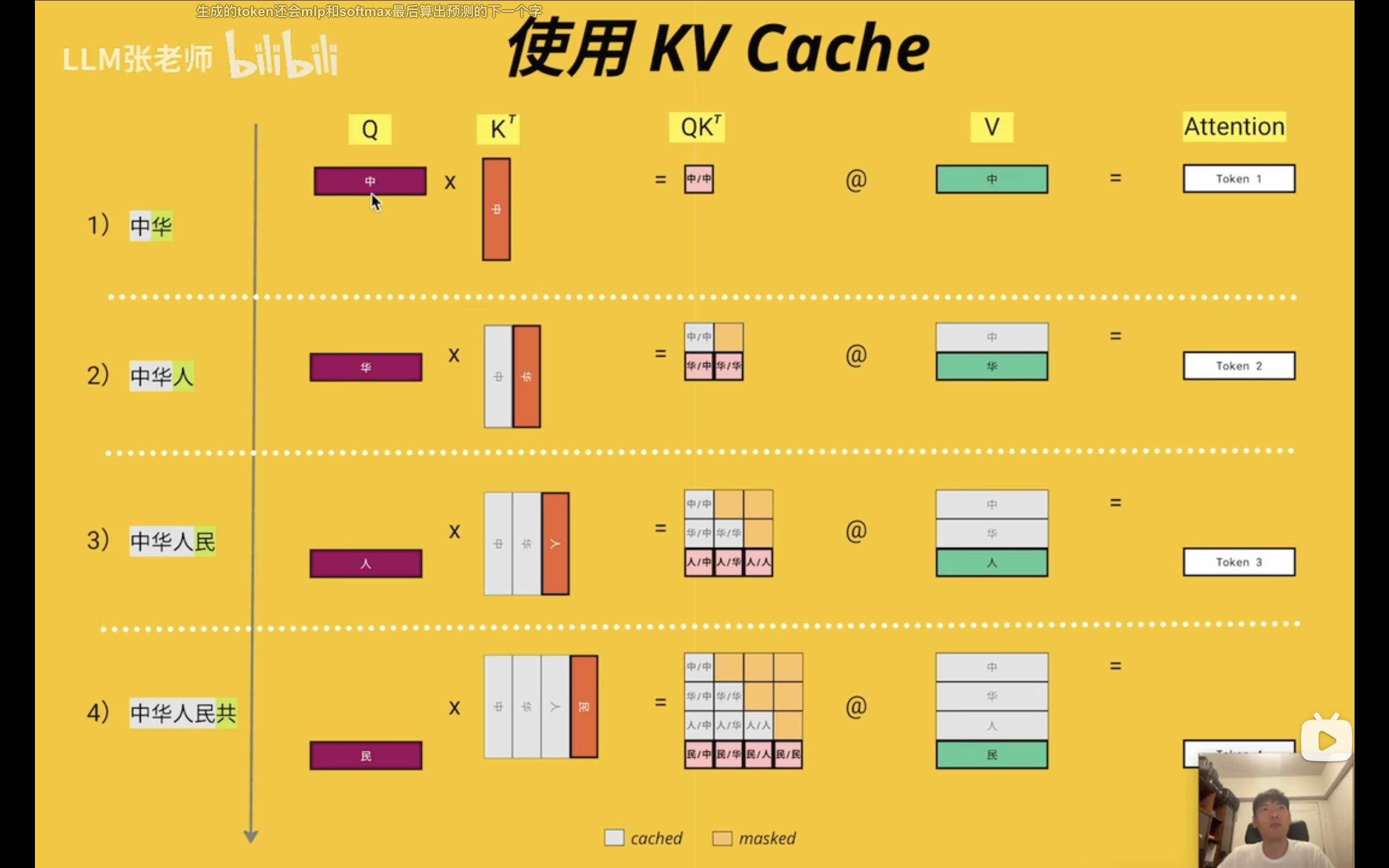
为什么可以kvcache
先看看kv的计算过程
场景:假设模型已经处理了 “The cat sat”,现在它预测出了下一个词是 “on”。我们的目标是计算出 “on” 这个新词的最终信息向量,这个向量需要包含前面所有词的上下文信息。
为了简化,我们假设向量的维度只有3维(在真实模型中是几千维),并且我们只看一个注意力头(真实模型是多头注意力)。
准备工作:已有的 KVCache
在计算 “on” 之前,模型已经处理了 “The”, “cat”, “sat”。所以,它的 KVCache 里已经存好了这三个词的 Key (K) 和 Value (V) 向量。我们假设它们是这样的(这些数字是模型通过学习得到的权重矩阵计算出来的):
-
K_The=[1, 0, 1] -
V_The=[0.1, 0.5, 0.2] -
K_cat=[0, 1, 1] -
V_cat=[0.3, 0.2, 0.8] -
K_sat=[1, 1, 0] -
V_sat=[0.7, 0.1, 0.4]
这些就是我们的历史信息库,已经准备就绪,无需再次计算。
开始计算:“on” 的上下文向量
现在,新词 “on” 来了。模型首先会为它生成自己的 Query (Q) 向量。Q 向量可以理解为 “on” 发出的一个“提问”,它要去问前面的每个词:“你和我有多相关?”
假设 “on” 的 Q 向量是:
Q_on=[1, 1, 2]
接下来,我们严格按照你引用的那句话的步骤来:
第1步:新字的 Q 和前面所有字的 K 进行计算(点积)
这一步是为了计算“相关性得分” (Attention Score)。我们用 Q_on 分别和 KVCache 里的每一个 K 向量做点积运算。
-
“on” 对 “The” 的关注度:
Score_on_The=Q_on·K_The
=[1, 1, 2]·[1, 0, 1]
= (1*1) + (1*0) + (2*1) = 3 -
“on” 对 “cat” 的关注度:
Score_on_cat=Q_on·K_cat
=[1, 1, 2]·[0, 1, 1]
= (1*0) + (1*1) + (2*1) = 3 -
“on” 对 “sat” 的关注度:
Score_on_sat=Q_on·K_sat
=[1, 1, 2]·[1, 1, 0]
= (1*1) + (1*1) + (2*0) = 2
我们得到了一组原始的注意力分数:[3, 3, 2]。从数字上看,“on” 似乎对 “The” 和 “cat” 的关注度一样,并且都比 “sat” 要高。
第2步:将分数转化为“注意力权重”(Scale 和 Softmax)
原始分数还不能直接用,需要进行两步处理,将其变成一个总和为1的“权重”或“概率分布”。
-
缩放 (Scale):为了防止梯度爆炸,需要将分数除以一个缩放因子,通常是K向量维度的平方根 (
sqrt(d_k))。我们这里维度是3,所以除以sqrt(3) ≈ 1.732。3 / 1.732 ≈ 1.733 / 1.732 ≈ 1.732 / 1.732 ≈ 1.15- 缩放后的分数:
[1.73, 1.73, 1.15]
-
Softmax:这个函数能把一组任意数字,转换成总和为1的概率分布,同时会放大数值大的,缩小数值小的。
softmax([1.73, 1.73, 1.15])会得到类似[0.45, 0.45, 0.10]这样的结果。
现在,我们得到了最终的注意力权重 (Attention Weights):
- 对 “The” 的权重:0.45
- 对 “cat” 的权重:0.45
- 对 “sat” 的权重:0.10
这组权重清晰地告诉我们:在构建 “on” 的信息时,模型认为应该重点参考 “The” 和 “cat” 的信息(各占45%的比重),而 “sat” 的信息相对次要(只占10%的比重)。
第3步:根据权重,去加权求和所有字的 V
这是最后一步,也是信息融合的一步。我们用上一步得到的权重,去乘以 KVCache 中对应的 V 向量。
Output_on = (权重_The * V_The) + (权重_cat * V_cat) + (权重_sat * V_sat)
Output_on = (0.45 * [0.1, 0.5, 0.2]) + (0.45 * [0.3, 0.2, 0.8]) + (0.10 * [0.7, 0.1, 0.4])
Output_on = [0.045, 0.225, 0.09] + [0.135, 0.09, 0.36] + [0.07, 0.01, 0.04]
把它们对应维度相加:
Output_on = [0.045 + 0.135 + 0.07, 0.225 + 0.09 + 0.01, 0.09 + 0.36 + 0.04]
Output_on = [0.25, 0.325, 0.49]
最终结果
这个最终计算出的向量 [0.25, 0.325, 0.49] 就是 “on” 这个词在当前上下文中全新的、融合了所有历史信息的表示。它不再是 “on” 最初的孤立含义,而是变成了一个和 “The cat sat” 紧密相关的 “on”。
这个向量随后会被送到 Transformer 的下一层(FFN层),继续进行处理。
总结一下:这个详细的过程,从 Q_on 的“提问”开始,到与 K 向量匹配得到“相关性”,再到用这个相关性(权重)去“提取” V 向量中的信息,最终“汇总”成自己的新信息,就是注意力机制的核心,也是 KVCache 发挥巨大作用的地方。