CorrectNav——基于VLM构建带“自我纠正飞轮”的VLN:通过「视觉输入和语言指令」预测导航动作,且从动作和感知层面生成自我修正数据
前言
近一两年来,视觉语言导航的工作集中出现,然这些VLN中成功率高的并不多,而本文要介绍的便是少数成功率较高的之一
第一部分 CorrectNav
1.1 引言与相关工作
1.1.1 引言
如CorrectNav原论文所说,作为一个视觉-语言-动作(VLA)任务,VLN要求模型动态感知环境,并按照给定指令进行导航。错误通常来源于两个方面:
- 对地标的误感知
- 对指令指定动作的误解
这些错误会在决策流程中传播,进而对运动预测产生负面影响。因此,应重点关注源自感知和动作的错误。此外,现实应用对模型推理时间有要求,这就要求自我纠错能力应通过训练隐式集成到模型中,而不是通过增加模块或推理过程来实现
对此,来自1 CFCS, School of Computer Science, Peking University、2PKU-AgiBot Lab的研究者提出了自我修正飞轮Self-correction Flywheel,这是一种新颖的导航后训练范式。该方法源于作者的观察:即使是经过充分训练的导航模型,在训练集上评估时仍会产生错误轨迹
- 其paper为《CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model》
作者包括
Zhuoyuan Yu1,2*, Yuxing Long1,2*, Zihan Yang1,2, Chengyan Zeng2, Hongwei Fan1,2, Jiyao Zhang1,2, Hao Dong1,2† - 其项目地址为:correctnav.github.io/
其GitHub地址则暂未公布

但作者并不将这些错误仅仅视为模型的不足,而是将其视为进一步提升模型的宝贵机会。他们的自我修正飞轮包括以下四个步骤:
- 在训练集上评估已训练好的模型,收集错误轨迹
- 设计一种自动化方法,能够检测偏差并精确定位错误轨迹中的具体位置
- 在识别出偏差后,从动作和感知两个角度生成自我修正数据
对于动作修正,收集能够有效从偏差中恢复的轨迹;
- 利用这些自我修正数据,推动导航模型的持续训练,从而提升其性能
完成上述四个步骤即为一次自我修正飞轮的循环。当对经过一轮自我修正训练的模型再次在训练集上进行评估时,会出现一个显著现象:CorrectNav能够识别出新的错误轨迹,从而生成新的自我修正数据,并进一步训练模型。此时,自我修正飞轮已经启动,导航模型的性能将随着多轮训练迭代不断提升
此外,作者还设计了一套导航微调方案,包括观察随机化、指令生成和通用多模态数据回忆。通过他们提出的微调和后训练策略,作者开发了一种新的基于单目RGB 的VLA 导航模型Correct-Nav。在VLN-CE 基准测试R2R-CE 和RxR-CE 上,CorrectNav 分别实现了65.1 % 和69.3 % 的成功率,超过了以往最先进模型8.2 % 和16.4 %
在多样化的室内外环境中进行的真实机器人测试表明,CorrectNav具备强大的纠错能力、动态障碍物规避能力和长指令跟随能力,优于现有的导航模型
1.1.2 相关工作
首先,对于视觉与语言导航
视觉与语言导航(VLN)指的是一个具身智能体根据自然语言指令导航至目标位置。诸如R2R和RxR等数据集,在离散化的MP3D环境中提供了导航指令和轨迹,而VLN-CE则将这些适配到连续场景
目前的VLN-CE模型大致可分为两类:
- 一类是基于拓扑图的方法,如BEVbert(An等,2023)和ETPnav(An等,2024),依赖多种传感器预测路径点
- 另一类是基于预训练视觉-语言模型VLM的模型,包括NaVid(Zhang等,2024a)、Uni-NaVid(Zhang等,2025)和NAVILA(Cheng等,2024),这些模型根据RGB观测端到端推断动作
现有方法通常采用辅助任务(Zhang等,2025,2024a)、指令增强(Wei等,2025b)和数据集扩展(Wei等,2025a)等技术来提升性能,但对错误纠正的关注较少。为了便于实际机器人应用,作者同样基于预训练VLM构建了CorrectNav。然而,作者强调错误纠正的价值,这有助于突破当前技术的性能瓶颈
其次,对于具身智能中的错误纠正
在具身智能任务中,错误通常是不可避免的
- 为了提升鲁棒性,具备纠正错误的能力至关重要。错误纠正方法已在操作任务中得到探索(Ha, Florence,and Song 2023;Ma 等 2023;Duan 等 2024;Liu, Bahety, and Song 2023)
- 然而,导航任务中的错误纠正研究较少。SmartWay(Shi 等 2025)采用闭源大模型对轨迹进行反思,并决定是否回溯
而 EnvolveNav(Lin 等 2025)则训练模型生成耗时的思维链,但提升有限
这些方法通常需要额外的模型或推理步骤,降低了效率,并阻碍了在现实世界中的部署
相比之下,CorrectNav通过自我纠正飞轮训练隐式地教授错误纠正,无需额外模块或冗长推理,从而便于在真实机器人上的部署
1.2 CorrectNav模型
1.2.1 模型结构(包含任务定义)
给定语言指令 ,视觉与语言导航任务要求模型在时间步
时,根据观测
预测下一个导航动作
最近,为了克服对多传感器的依赖,研究人员(Zhang 等,2024a,即NaVid)将观测简化为在导航过程中捕获的单目RGB 图像序列
CorrectNav 由三个模块组成:
- 视觉编码器
具体采用的SigLIP - 投影器
具体而言是一个两层MLP(Liu 等,2024) - 大语言模型LLM
具体是Qwen2
给定一段RGB 视频,视觉编码器从采样帧中提取视觉特征,生成。MLP 投影器将这些视觉特征映射到LLM 的语义空间,得到一系列视觉
利用视觉token 以及由任务指令
编码的文本token
,LLM
以自回归方式进行预测。在导航微调之前,CorrectNav 初始化自LLaVA-Video7B(Zhang 等,2024b)
1.2.2 三项导航微调任务:导航动作预测、基于轨迹的指令生成、通用多模态数据回顾
- 导航动作预测
作者从VLN-CE R2R 和RxR 在MP3D室内场景下的训练集划分中收集了oracle 导航轨迹。每条oracle 轨迹包含一条导航指令,以及逐步的RGB 观测和导航动作
为了增强视觉多样性,作者实施了一系列领域随机化策略。这些策略包括随机化相机高度、调整视场、变化观测分辨率以及改变照明条件,如图2 所示
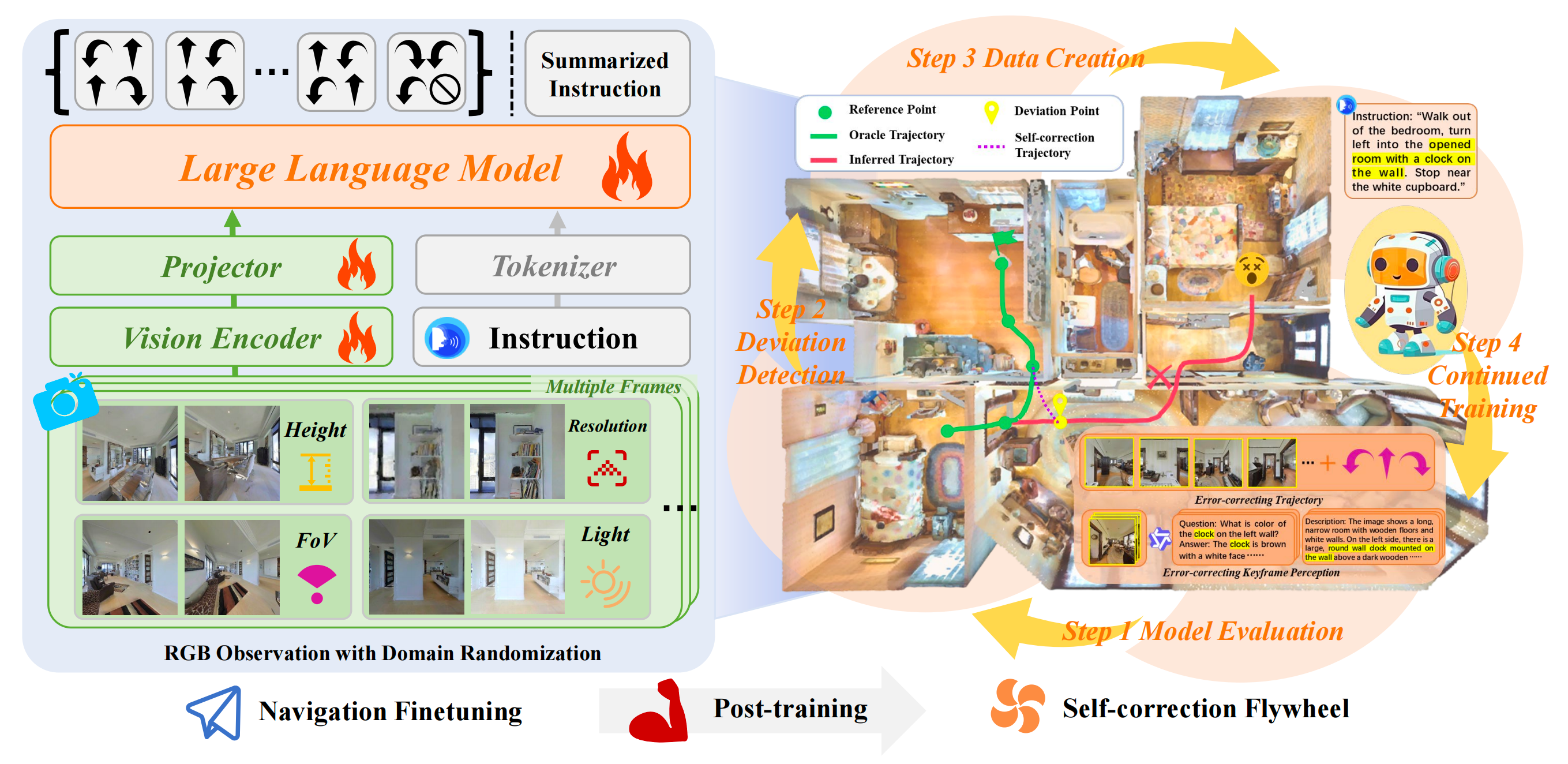
通过这些策略,作者收集了超过210 万步导航动作预测数据,其中包括来自R2R 的527 K样本和来自RxR 的158 万样本
在该任务中,作者将导航指令和逐步的RGB 观测
作为CorrectNav 的输入,并要求模型预测包含m 步的动作序列
- 基于轨迹的指令生成
在此任务中,作者从VLN-CER2R 和RxR 数据集中收集完整的oracle 导航轨迹。其中,10K 来自R2R,20K 来自RxR
CorrectNav 需要根据单目RGB 观测历史生成语言格式的导航指令。在训练过程中,作者输入整个oracle 轨迹的RGB 观测,并将相应的指令
- 通用多模态数据回顾
下游导航任务格式与通用多模态训练任务有显著差异。如果仅在导航任务上进行训练,会导致模型在训练过程中遗忘通用多模态能力
为了解决这一问题,作者引入了LLaVA-Video178K数据集(Zhang等,2024b)中的一部分视频数据。作者重点关注Activitynet-QA(Yu等,2019)和NextQA(Xiao等,2021),这两个数据集强调对时序和空间场景的理解,与作者的目标高度契合
因此,作者从ActivityQA和NextQA中随机采样了24万条训练实例,以保持模型的通用多模态能力
1.2.3 自我纠正飞轮后训练的4个步骤:训练集上评估、轨迹偏差检测、自我纠正数据生成、迭代训练
如上所述,为了教会导航模型如何从偏离中恢复,作者提出了一种新的后训练范式——自我纠正飞轮。一次训练迭代包括模型评估、偏差检测、自我纠正数据生成以及持续训练
这四个步骤可以在两端形成闭环,从而构建一个自我纠正的飞轮。通过多次训练迭代,可以显著提升自我纠正能力。整体流程在算法1中进行了概述,接下来将详细介绍每个步骤
1.2.3.1 步骤一:在训练集上进行模型评估
2R-CE 和RxR-CE 的训练集包含大量的指令与理想轨迹对。在数据集中,每一条理想轨迹由一系列有序的参考点定义,记作
- 在导航微调过程中,作者已经利用这些数据为CorrectNav 训练提供逐步的监督信号。尽管模型已经在这些数据上进行了训练,但作者发现,在训练集上评估时模型仍然会出现错误
但作者不以为坏,反以为好——意识到这是收集纠正数据的极好来源
毕竟训练数据集不仅包含丰富的数据,还包括真实的参考点 - 因此,作者收集了模型在训练集评估过程中产生的错误轨迹。这些轨迹可表示为
,其中
表示机器人在第
个时间步的位置
1.2.3.2 步骤二:轨迹偏差检测
由于收集到的误差轨迹缺乏标注,无法指示具体位置,当出现偏差时,作者开发了一种检测此类偏差的方法。其关键原理是通过测量误差轨迹与理想轨迹之间的距离来评估偏差
- 为了计算机器人位置
的距离,作者首先在参考点之间进行均匀插值,形成一个等间距的序列
对于每个机器人位置,作者定义
- 作者进一步将
- 设S为预设阈值。如果存在某一时刻
,满足
那么作者认为模型在处开始偏离理想轨迹。接近时刻
的观测可以被标记为误差校正的关键帧
1.2.3.3 步骤三:自我纠正数据生成
通过分析误差轨迹中的偏差,作者发现导航错误主要源自感知和动作。因此,作者提出了针对这两个方面的自我纠正任务和数据生成方法
- 纠错轨迹
为了教会模型如何从偏差中恢复,作者基于检测到的偏差收集纠错轨迹。给定一个理想轨迹,作者已经在第2 步中检测偏差点
及其对应的垂足
如果位于线段
上——
,则可以知道模型已经正确通过了
及所有之前的参考点,但在朝向
移动时略有偏离
随后,作者利用轨迹规划器生成一条新轨迹
该轨迹始于。因此,作者获得了一条纠错轨迹,可作为动作纠正的训练数据
训练方式类似于导航动作预测
为了确保模型专注于学习纠正行为,动作学习仅在纠错轨迹上进行,而
之前的轨迹仅用于提供观测历史
- 关键帧感知
为了真正赋予CorrectNav 纠错能力,作者不仅要教它该如何行动,还要教它为什么这样做。在视觉-语言导航过程中,错误往往源于导航模型在偏离位置
为了在纠错训练过程中增强CorrectNav 的多模态感知能力,作者选择在
随后,利用多模态大模型Qwen-VL-Plus,基于这些关键纠错帧生成视觉分析数据,如图2 右侧所示
在训练过程中,作者输入观测视频,并使用描述
作为目标,训练CorrectNav 理解当前观测;对于同一个视频,对于任意
,作者指示CorrectNav 根据当前观测(
) 回答
,激活Cor-rectNav 理解纠错行为
1.2.3.4 步骤四:模型继续训练
在收集到自我纠正数据后,继续对CorrectNav进行训练。为了提高效率,作者随机抽取一半的纠错轨迹及其对应的关键帧感知数据用于训练
- 此外,作者还引入了来自原始训练数据的oracle轨迹,以保持训练的稳定性。这些oracle轨迹的数量设定为所抽取纠错轨迹数量的一半
- 通过利用这些自动生成的数据,可以进一步训练CorrectNav,以增强其自我纠正能力。至此,完成了一轮自我纠正飞轮训练
- 多轮自我纠错迭代
当作者再次在训练集上测试自我纠错后的CorrectNav时,会出现新的错误轨迹。这些新的错误使我们能够生成新的纠错任务数据,用于CorrectNav的持续训练。这便启动了自我纠错飞轮机制,使得可以进行多轮自我纠错训练迭代、- 在实现细节上
CorrectNav 在配备 8 张 NVIDIA A100 GPU 的服务器上进行训练。导航微调过程需要 80 小时,而自我修正飞轮(Self-correction Flywheel)每次迭代消耗 20小时。在推理阶段,CorrectNav 以 16 帧采样的 RGB图像作为输入,并预测包含 4 个有效动作的动作块
// 待更